

最新案例動態,請查閲【案例共創】基於華為雲開發環境桌面版的人臉顏值打分。小夥伴們快來領取華為開發者空間進行實操吧!
本案例由開發者:南航金城學院-孫福清教師提供
一、概述
1. 案例介紹
本案例是基於華為雲主機的python開發環境,引導開發者學習和實踐人工智能計算機視覺的一個應用案例—基於計算機視覺python開源模塊opencv以及meidiapipe實現人臉顏值的打分量化。
華為開發者空間,是為全球開發者打造的專屬開發者空間,致力於為每位開發者提供一台雲主機、一套開發工具和雲上存儲空間,匯聚昇騰、鴻蒙、鯤鵬、GaussDB、歐拉等華為各項根技術的開發工具資源,並提供配套案例指導開發者 從開發編碼到應用調測,基於華為根技術生態高效便捷的知識學習、技術體驗、應用創新。
2. 適用對象
- 企業
- 個人開發者
- 高校學生
3. 案例時間
本案例總時長預計90分鐘。
4. 案例流程
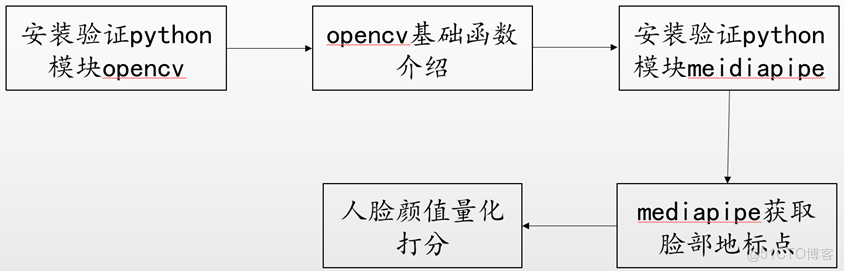
説明:
- 安裝驗證python模塊opencv;
- opencv基礎函數介紹;
- 安裝驗證python模塊mediapipe;
- mediapipe獲取臉部地標點;
- 人臉顏值量化打分。
按照上述步驟逐步進行學習和實驗。
5. 資源總覽
本案例預計花費0元。
|
資源名稱 |
規格 |
單價(元) |
時長(分鐘) |
|
華為開發者空間 - 雲主機 |
鯤鵬通用計算增強型 kc2 | 4vCPUs | 8G | Ubuntu
|
免費
|
90
|
二、開發者空間配置
1. 開發者空間配置
面向廣大開發者羣體,華為開發者空間提供一個隨時訪問的“開發桌面雲主機”、豐富的“預配置工具集合”和靈活使用的“場景化資源池”,開發者開箱即用,快速體驗華為根技術和資源。
進入華為開發者空間工作台界面,點擊打開雲主機 > 進入桌面連接雲主機。 如果還沒有領取雲主機進入工作台界面後點擊配置雲主機,選擇Ubuntu操作系統。
2 安裝驗證python模塊opencv
安裝驗證python模塊opencv,請參考空間案例《【案例共創】基於華為雲開發環境桌面版的剪刀手手勢識別》中的“二、安裝驗證 Python 模塊 opencv”。
3 opencv基礎函數介紹
opencv基礎函數介紹,請參考空間案例《【案例共創】基於華為雲開發環境桌面版的剪刀手手勢識別》中的“三、opencv 基礎函數介紹”。
4 安裝驗證python模塊mediapipe
安裝驗證python模塊mediapipe,請參考空間案例《【案例共創】基於華為雲開發環境桌面版的剪刀手手勢識別》中的“四、安裝驗證Python模塊mediapipe”。
5 Mediapipe獲取臉部的關鍵地標點
5.1 Mediapipe的臉部地標點face landmarks
"landmark"在醫學和生物學領域常被用來指代身體或面部的重要標誌或特徵,這些標誌或特徵在定位、測量或分析時具有重要作用。 Face Landmark,面部標誌,是指面部關鍵點檢測技術,它利用深度學習等技術,在圖像中精確地識別並定位出人臉的關鍵特徵點,如眼睛、鼻子和嘴巴的位置,在人臉識別、表情識別、美顏應用以及虛擬主播等領域具有廣泛的應用前景和巨大的潛力。 MediaPipe的face_mesh模塊能夠檢測人臉並提取468個3D面部地標點。這些地標點覆蓋了面部的各個部位,包括眼睛、眉毛、鼻子、嘴巴、下巴等: 眼睛:包括眼瞼、瞳孔等部位。 眉毛:覆蓋了眉毛的輪廓。 鼻子:包括鼻樑、鼻尖等部位。 嘴巴:包括嘴唇的輪廓和內部。 下巴:覆蓋了下巴的輪廓。 臉部輪廓:包括臉頰、顴骨等部位。
每個地標點都有一個唯一的索引編號和對應的 3D 座標(x, y, z)。

https://github.com/google-ai-edge/mediapipe/blob/master/mediapipe/modules/face_geometry/data/canonical_face_model_uv_visualization.png
這些地標點可以用於以下應用:
- 面部表情識別 通過分析地標點之間的相對位置和變化,可以識別出各種面部表情,例如微笑、皺眉、眨眼等。
- 虛擬現實和增強現實 利用地標點的三維座標信息,可以在虛擬環境中實時跟蹤和渲染人臉,實現更加自然的交互效果。
- 人機交互 通過檢測特定的面部動作(如點頭、搖頭等),可以實現非接觸式的人機交互
5.2 完成項目環境搭建
參照前面的案例,在華為雲主機上完成項目環境搭建:
- 完成《華為雲主機Linux Python開發環境配置》;
- 在華為雲主機上搭建本案例項目環境(此案例前半部分已介紹): 創建項目文件夾; 創建虛擬環境; 在虛擬環境中完成python開源模塊opencv和mediapipe安裝和驗證。

5.3 從臉部圖片中獲取地標點face landmarks
步驟1:準備臉部圖片(高清、大圖),可從網上下載無版權的數字人圖片,複製到項目文件夾。

步驟2:新建空白py代碼文件,準備編寫複製獲取臉部地標點的py示例代碼。
gedit facelandmarks.py
步驟3:獲取臉部地標點的示例代碼,複製編寫到py文件中。
import cv2
import mediapipe
#------------------------------------------------------------------------------
def imgHeightResize(img, fixedHeight):
imgResized = img
imgH,imgW,imgChs = imgResized.shape
ratioH = fixedHeight/imgH
imgResized = cv2.resize(img,None,fx=ratioH,fy=ratioH,interpolation=cv2.INTER_CUBIC)
return imgResized
#------------------------------------------------------------------------------
if __name__ == '__main__':
imgOrg = cv2.imread("111.jpeg")
img = imgHeightResize(imgOrg, 640)
imgRGB = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
faceDetector=mediapipe.solutions.face_mesh.FaceMesh(
static_image_mode=False,
refine_landmarks=True,
max_num_faces=5,
min_detection_confidence=0.5,
min_tracking_confidence=0.5)
results = faceDetector.process(imgRGB)
if (results.multi_face_landmarks):
for faceLms in results.multi_face_landmarks:
mediapipe.solutions.drawing_utils.draw_landmarks(
image=img,
landmark_list=faceLms,
connections=mediapipe.solutions.face_mesh.FACEMESH_CONTOURS)
else:
cv2.putText(img,"no hands detected",(100,100),cv2.FONT_HERSHEY_COMPLEX,1,(0,0,255),2,8)
cv2.imshow("img",img)
cv2.waitKey(0)
cv2.destroyAllWindows()注意:圖片文件要真實存在。
步驟3:執行py代碼,顯示臉部地標點的圖片。
python3 facelandmarks.py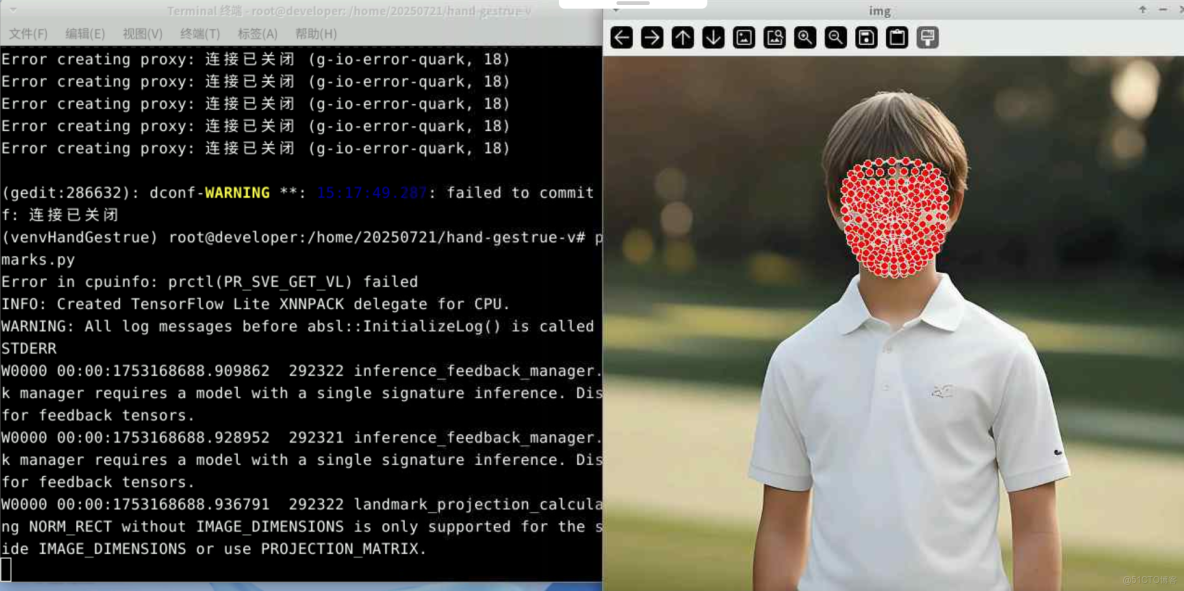
mediapipe成功從臉部圖片中檢測出人臉,獲取到臉部關鍵點,並且在圖片上繪製出臉部關鍵點。
5.4 過程代碼解析
過程1- 導入模塊
import mediapipe就可以直接使用模塊名字來引用其中的函數或者變量、宏等,例如:
mediapipe.solutions.face_mesh.FaceMesh(),
mediapipe.solutions.face_mesh.FACEMESH_CONTOURS有些網上的導入模塊代碼為:
import mediapipe as mp這其實是給mediapipe起個字符串數量更少的別名,減少代碼量,本質一樣,引用模塊的函數、變量或宏就變為:
mediapipe.solutions.face_mesh.FaceMesh(),
mediapipe.solutions.face_mesh.FACEMESH_CONTOURS過程2- opencv讀入圖片並調整尺寸大小適合顯示
見前面章節關於opencv基礎函數介紹部分
#-----------------------------------------------------------------------
def imgHeightResize(img, fixedHeight):
imgResized = img
imgH,imgW,imgChs = imgResized.shape
ratioH = fixedHeight/imgH
imgResized = cv2.resize(img,None,fx=ratioH,fy=ratioH,interpolation=cv2.INTER_CUBIC)
return imgResized
#-----------------------------------------------------------------------
if __name__ == '__main__':
imgOrg = cv2.imread("face.jpeg")
img = imgHeightResize(imgOrg, 640)過程3- 圖片轉換色彩空間
imgRGB = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)使用cv2.imread打開圖片會得到一個numpy數組[width,height],數組中每個元素就是一個像素點,像素點使用三維BGR表示[0-blue,1-gree,2-red] MediaPipe的像素點使用 RGB 表示,即[0-red,1-gree,2-blue] cv2.cvtColor 函數可以將圖像從一種顏色空間轉換為另一種顏色空間 BGR和RGB的區別:
- BGR:是 OpenCV 默認的顏色空間格式。它將圖像的每個像素表示為一個三通道的值,分別是藍色(Blue)、綠色(Green)和紅色(Red),順序為 BGR。
- RGB:是大多數圖像處理庫(如 PIL、Matplotlib 等)以及許多深度學習框架(如 TensorFlow、PyTorch 等)使用的顏色空間格式。它的順序是紅色(Red)、綠色(Green)和藍色(Blue)。
過程4- 創建手部檢測器並初始化
faceDetector=mediapipe.solutions.face_mesh.FaceMesh(
static_image_mode=False,
refine_landmarks=True,
max_num_faces=5,
min_detection_confidence=0.5,
min_tracking_confidence=0.5)mediapipe.solutions.face_mesh.FaceMesh是MediaPipe提供的一個用於人臉檢測和麪部地標點提取的類,能夠實時從圖像或視頻中重建出人臉的3D網格,支持多達468個面部地標點。類在初始化時可以接收以下參數:
max_num_faces:最多檢測的人臉數量,默認值為1。 refine_landmarks:是否細化地標點(如眼睛和嘴巴)。如果設置為 True,會額外輸出針對眼睛虹膜的地標點,地標點總數會從468增加到478。 min_detection_confidence:人臉檢測的置信度閾值,範圍為[0, 1],默認值為 0.5。 min_tracking_confidence:人臉跟蹤的置信度閾值,範圍為[0, 1],默認值為 0.5。
過程5- 調用檢測器對讀入的圖片進行檢測
results = faceDetector.process(imgRGB)在使用mediapipe.solutions.face_mesh.FaceMesh的process方法時,返回的results(名字隨意)數據結構包含了人臉檢測和麪部地標點(face landmarks)的相關信息。 以下是results數據結構中各個字段的詳細解釋:
- results.multi_face_landmarks 這是一個列表,包含每個檢測到的人臉的地標點信息。每個元素是一個 mediapipe.framework.formats.landmark_pb2.LandmarkList對象,表示一個人臉的468個(或更多,取決於是否啓用細化地標點)地標點。 landmark:一個包含 468個(或更多)mediapipe.framework.formats.landmark_pb2.Landmark 對象的列表,每個對象表示一個地標點。 x:地標點的 x 座標(歸一化值,範圍為 [0, 1])。 y:地標點的 y 座標(歸一化值,範圍為 [0, 1])。 z:地標點的 z 座標(相對深度值,範圍為 [-1, 1],表示地標點相對於攝像頭的深度)。
- results.multi_face_world_landmarks 這是一個列表,包含每個檢測到的人臉的地標點在世界座標系中的三維座標信息。每個元素是一個 mediapipe.framework.formats.landmark_pb2.LandmarkList 對象,表示一個人臉的468個地標點。 landmark:一個包含468個 mediapipe.framework.formats.landmark_pb2.Landmark對象的列表,每個對象表示一個地標點。 x:地標點的 x 座標(世界座標系中的值,單位為米)。 y:地標點的 y 座標(世界座標系中的值,單位為米)。 z:地標點的 z 座標(世界座標系中的值,單位為米)。
- results.multi_face_blendshapes 這是一個列表,包含每個檢測到的人臉的表情混合形狀(blendshapes)信息。每個元素是一個mediapipe.framework.formats.classification_pb2.ClassificationResult對象,表示人臉的表情分類結果。 classification:一個包含 mediapipe.framework.formats.classification_pb2.Classification對象的列表,每個對象表示一個表情分類結果。 index:分類結果的索引。 score:分類的置信度分數(範圍為 [0, 1])。 label:分類的標籤(字符串,表示表情類型,如 "smile"、"frown" 等)。
過程6:對檢測到的臉部地標點進行點位和連線繪圖
if (results.multi_face_landmarks):
for faceLms in results.multi_face_landmarks:
mediapipe.solutions.drawing_utils.draw_landmarks(
image=img,
landmark_list=faceLms,
connections=mediapipe.solutions.face_mesh.FACEMESH_CONTOURS)示例代碼中使用mediapipe模塊內置的點位和連線繪製函數:
mediapipe.solutions.drawing_utils.draw_landmarks()函數原型:
mediapipe.python.solutions.drawing_utils.draw_landmarks(
image,
landmark_list,
connections=None,
landmark_drawing_spec=None,
connection_drawing_spec=None
)函數參數:
- image: 類型:numpy.ndarray 描述:輸入圖像,地標點將被繪製在這個圖像上。圖像應該是BGR格式(OpenCV 默認格式)。
- landmark_list: 類型:mediapipe.framework.formats.landmark_pb2.LandmarkList 描述:包含地標點信息的對象。每個地標點是一個mediapipe.framework.formats.landmark_pb2.Landmark對象,包含 x、y、z 座標。
- connections: 類型:list[tuple[int, int]] 描述:地標點之間的連接關係。每個元組表示兩個地標點的索引,用於繪製連接線。例如,[(0, 1), (1, 2)] 表示連接地標點0和1,以及地標點1和2。 默認值:None,如果不指定連接關係,則不會繪製連接線。
- landmark_drawing_spec: 類型:mediapipe.python.solutions.drawing_utils.DrawingSpec 或list[mediapipe.python.solutions.drawing_utils.DrawingSpec] 描述:用於自定義地標點的繪製樣式。可以指定顏色、點的大小等。如果傳遞一個列表,則每個地標點可以使用不同的樣式。 默認值:None,默認使用白色繪製地標點。
- connection_drawing_spec: 類型:mediapipe.python.solutions.drawing_utils.DrawingSpec 或list[mediapipe.python.solutions.drawing_utils.DrawingSpec] 描述:用於自定義連接線的繪製樣式。可以指定顏色、線的寬度等。如果傳遞一個列表,則每條連接線可以使用不同的樣式。 默認值:None,默認使用白色繪製連接線
landmark_drawing_spec和connection_drawing_spec被用來自定義地標點和連接線的繪製樣式。例如DrawingSpec 的參數包括: color:顏色,格式為 (B, G, R),例如 (0, 255, 0) 表示綠色。 thickness:線條或點的粗細。 circle_radius:地標點的半徑。 通過調整這些參數,可以實現不同的可視化效果。
可以按照自己的需求,自己編寫繪製點位和連線的函數,例如只需要某個繪製手指的地標點點位,不需要連線等。
5.5 地標點座標歸一化值轉換為圖片像素值
每個地標點為(x,y,z),值為(0-1),相對於圖像的長寬比例,需將xy的比例座標轉換成圖像像素座標:
- 比例座標x乘以寬度width,得到座標點的X軸的像素座標;
- 比例座標y乘以寬度height,得到座標點的Y軸的像素座標;
- 像素座標需要取整。
完整代碼:
import cv2
import mediapipe
#------------------------------------------------------------------------------
def imgHeightResize(img, fixedHeight):
imgResized = img
imgH,imgW,imgChs = imgResized.shape
ratioH = fixedHeight/imgH
imgResized = cv2.resize(img,None,fx=ratioH,fy=ratioH,interpolation=cv2.INTER_CUBIC)
return imgResized
#------------------------------------------------------------------------------
if __name__ == '__main__':
imgOrg = cv2.imread("111.jpeg")
img = imgHeightResize(imgOrg, 640)
imgRGB = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
faceDetector=mediapipe.solutions.face_mesh.FaceMesh(
static_image_mode=False,
refine_landmarks=True,
max_num_faces=5,
min_detection_confidence=0.5,
min_tracking_confidence=0.5)
results = faceDetector.process(imgRGB)
if (results.multi_face_landmarks):
for faceLms in results.multi_face_landmarks:
h, w , c = img.shape
for idx, coord in enumerate(faceLms.landmark):
cx = int(coord.x * w)
cy = int(coord.y * h)
cv2.circle(img, (cx, cy), 1, (255,0,0), -1)
img = cv2.putText(img,
str(idx), #點位旁邊標註序號
(cx, cy),
cv2.FONT_HERSHEY_SIMPLEX,
0.25,(0, 0, 0), 1, 1)
else:
cv2.putText(img,"no hands detected",(100,100),cv2.FONT_HERSHEY_COMPLEX,1,(0,0,255),2,8)
cv2.imshow("img",img)
cv2.waitKey(0)
cv2.destroyAllWindows()執行代碼,地標點座標從歸一化值轉換為圖片像素值並繪製到圖片上:
python3 facelandmarks.py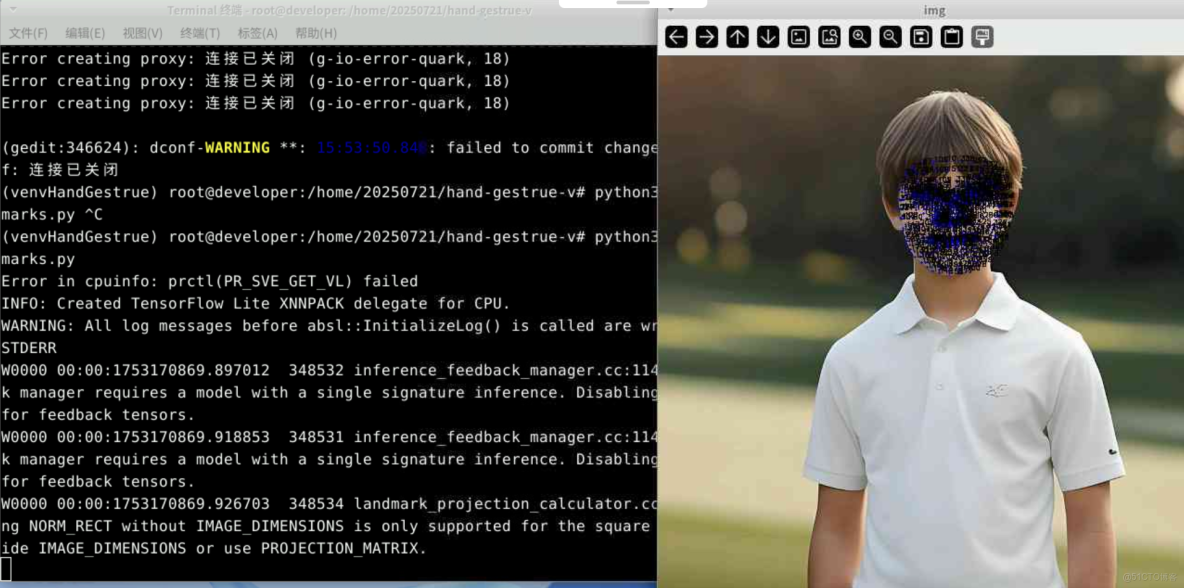
6 基於臉部地標點的顏值打分
6.1 美術的顏值指標
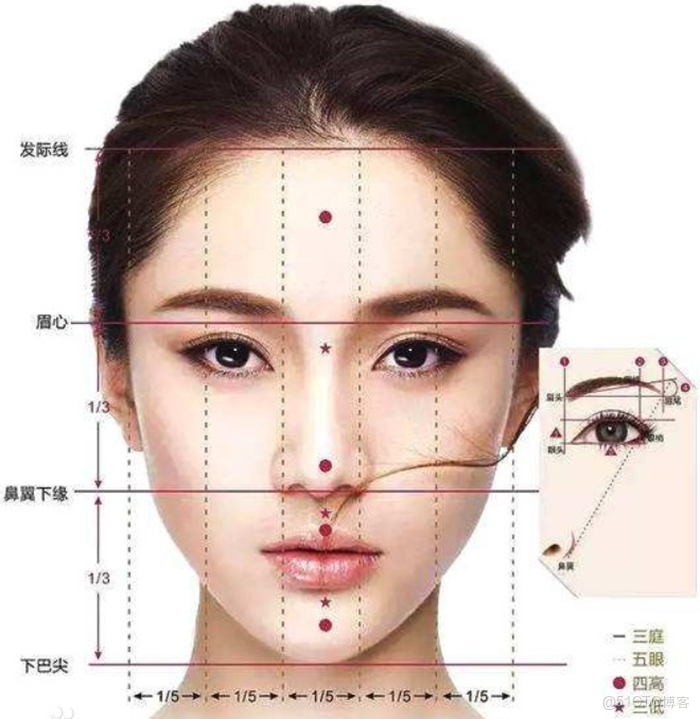
“三庭五眼”是中國傳統美學中用於衡量面部比例和顏值的重要標準,它基於面部的縱向和橫向比例關係,幫助判斷五官的協調性和整體美感。
三庭: “三庭”是指將面部的長度分為三等分,具體劃分如下: 上庭:從髮際線到眉骨。 中庭:從眉骨到鼻底。 下庭:從鼻底到下巴尖。 理想情況下,這三部分的長度應大致相等。
五眼: “五眼”是指將面部的寬度分為五等分,每份的寬度大致等於一隻眼睛的寬度: 兩眼內眥(內眼角)之間的距離為一隻眼睛的寬度。 兩眼外眥(外眼角)到同側髮際線的距離各為一隻眼睛的寬度。 兩眼之間的間距也應為一隻眼睛的寬度。
美學意義 協調性:符合“三庭五眼”標準的面部,通常被認為五官位置協調,整體美感更佳。 個性化:雖然“三庭五眼”是理想標準,但現實中很少有人完全符合這一比例。個性化的面部特徵(如獨特的眼型或眉型)也能增加顏值。 文化差異:不同文化對美的定義有所不同。例如,東亞文化中更偏好“丹鳳眼”,而歐美文化中則對“方下頜”有更高的評價。
現代應用 在整形醫學和美容領域,“三庭五眼”常被用作參考標準,幫助醫生和美容師評估和調整面部比例,以達到更協調的視覺效果:
嘴唇和鼻子寬度的達芬奇衡量公式: 臉是人體最奇妙的部位,雖然只有眼、嘴、鼻等幾個器官,但大小、組合方式、位置的不同,卻能變化出千姿百態的臉。
美國研究人員在達·芬奇的畫中,發現了他創造美麗的公式:臉寬是鼻寬的四倍,前額的高度、鼻子的長度以及下頜骨高度都相等。 科學家們發現,較小的嘴是文藝復興時期的首選標準,達·芬奇認為嘴寬是鼻寬的1.5倍時最吸引人。而現代科學家們研究發現,嘴寬是鼻寬的1.6倍時(黃金分割點0.618),才是最吸引人的面貌。

6.2 基於臉部地標點計算五眼指標
這裏給出的簡單的算法思想:
步驟1:提取指標相關的地標點的座標點數據。
臉輪廓的最左側點-23 臉輪廓的最右側點-45 左眼的左眼角-33 左眼的右眼角-133 右眼的左眼角-362 右眼的右眼角-263

步驟2:計算指標。
- 計算臉部寬度 = 從最左到最右的距離;
- 計算兩眼寬度的平均值 = (右眼寬度 + 左眼寬度)/2;
- 計算 五個部位寬度 分別與 眼寬平均 之間的 差,使用臉寬進行歸一化: a、寬度1 : 絕對值(左眼左眼角 - 臉最左 - 平均眼寬)/ 臉寬; b、寬度2 : 絕對值(左眼右眼角 - 左眼左眼角 - 平均眼寬)/ 臉寬; c、寬度3 : 絕對值(右眼左眼角 - 左眼右眼角 - 平均眼寬)/ 臉寬; d、寬度4 : 絕對值(右眼右眼角 - 右眼左眼角 - 平均眼寬)/ 臉寬; e、寬度5 : 絕對值(臉最右 - 右眼右眼角 - 平均眼寬)/ 臉寬。
- L2範數-計算五個寬度值歸一化值的平方和,再開平方。
6.3 基於臉部地標點計算三庭指標
算法想法: 提取出指標相關的地標點的座標:
- 臉輪廓的最上側邊緣10
- 臉輪廓的最下側邊緣152
- 眉心9
- 鼻翼下緣 2

計算指標:
- 臉長度 = 臉輪廓的最下側邊緣152 - 臉輪廓的最上側邊緣10
- 中庭距離 = 鼻翼下緣02 - 眉心9
- 下庭距離 = 臉輪廓的最下側邊緣152 - 鼻翼下緣02
- 三庭指標 = 絕對值(下庭距離 - 中庭距離)* 100 / 臉長度
這裏不計算上庭,是因為mediapipe提取的地標點沒有髮際線的點,只有額頭的點。
6.4 基於臉部地標點計算嘴寬與鼻框的達芬奇衡量公式
算法思想 步驟1-提取指標相關的地標點座標:
- 嘴唇左角 61
- 嘴唇右角 291
- 鼻翼左緣 129
- 鼻翼右緣 358
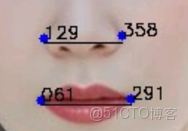
步驟2-計算指標:
- 嘴寬 = 嘴唇右角 291 - 嘴唇左角 61
- 鼻寬 = 鼻翼右緣 358 - 鼻翼左緣 129
- 指標 = 鼻寬 / 嘴寬
6.5 過程介紹
過程1:準備2張臉部圖片(高清、大圖)
準備2張圖片,複製到項目文件夾,實現兩張臉部的幾個顏值指標的人臉顏值比拼

過程2:新建空白py文件,編寫代碼,實現兩張臉部的人臉顏值比拼
gedit faceBeauty.py
faceBeauty.py完整代碼:
import cv2
import mediapipe as mp
import numpy as np
import math
import sys
#-------------------------------------
def imgshow_keypoint(img,idxstr,cx,cy):
cv2.circle(img, (cx, cy), 3, (255,0,0), -1)
cv2.putText(img, idxstr, (cx, cy), cv2.FONT_HERSHEY_SIMPLEX, 0.4,(0, 0, 0), 1, 1)
#-------------------------------------
def imgshow_metric(img,idxstr,n):
#參數1-目標圖像
#參數2-文本
#參數3-起始座標,文本左側的左上角座標(默認) 或 左下角,
#參數4-字體
#參數5-字體基本大小的比例因子
#參數6-文本顏色
#參數7-文本線條的粗細
#參數8-文本線條的形狀
#參數9-文本在起始座標的左上角false(default),還是左下角True
imgH,imgW,imgChs = img.shape
textSpace = np.full((40,imgW,3),255,np.uint8)
textImg = np.vstack((textSpace,img))
cv2.putText(textImg,idxstr,(10,20),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,0,0),1, 8)
#cv2.imshow(("textImg%d"%n),textImg)
return textImg
#-------------------------------------
def imgshow_line(img,start_cx,start_cy,end_cx,end_cy):
#參數1-img:你想要繪製圖形的那幅圖像。
#參數2-(x,y):線條的起點座標點
#參數3-(x,y):線條的終點座標點.
#參數4-color:形狀的顏色。以BGR為例,需要傳入一個元組,(255,0,0)代表藍色。對於灰度圖只需要傳入灰度值。
#參數5-thickness:線條的粗細。如果給一個閉合圖形(如矩形)設置為 -1,那麼這個圖形就會被填充。默認值是1.
#參數6-linetype:線條的類型。默認8。cv2.LINE_AA為抗鋸齒,這樣看起來會非常平滑。
#參數7-shift:縮放參數,一般不用
#y座標稍微下移,給關鍵點標註的序號留下空位
cv2.line(img, (start_cx, (start_cy+3)), (end_cx, (end_cy+3)), (0,0,0), 1)
#-------------------------------------
def beauty_five_eyes(img,faceLandMarks):
h, w , c = img.shape
metricSpace = np.full((80,w,3),255,np.uint8)
metricImg = np.vstack((img,metricSpace))
# 臉輪廓的最左側點
faceLeft = faceLandMarks.landmark[234];
faceLeft_cx, faceLeft_cy = int(faceLeft.x * w), int(faceLeft.y * h);
imgshow_keypoint(metricImg,'234',faceLeft_cx,faceLeft_cy)
# 臉輪廓的最右側點
faceRight = faceLandMarks.landmark[454];
faceRight_cx, faceRight_cy = int(faceRight.x * w), int(faceRight.y * h);
imgshow_keypoint(metricImg,'454',faceRight_cx,faceRight_cy)
# 臉輪廓的最上側邊緣
faceTop = faceLandMarks.landmark[10];
faceTop_cx, faceTop_cy = int(faceTop.x * w), int(faceTop.y * h);
imgshow_keypoint(metricImg,'010',faceTop_cx,faceTop_cy)
# 臉輪廓的最下側邊緣
faceBottom = faceLandMarks.landmark[152];
faceBottom_cx, faceBottom_cy = int(faceBottom.x * w), int(faceBottom.y * h);
imgshow_keypoint(metricImg,'152',faceBottom_cx,faceBottom_cy)
# 左眼的左眼角
leftEyeLeftConer = faceLandMarks.landmark[33];
leftEyeLeftConer_cx, leftEyeLeftConer_cy = int(leftEyeLeftConer.x * w), int(leftEyeLeftConer.y * h);
imgshow_keypoint(metricImg,'033',leftEyeLeftConer_cx,leftEyeLeftConer_cy)
# 左眼的右眼角
leftEyeRightConer = faceLandMarks.landmark[133];
leftEyeRightConer_cx, leftEyeRightConer_cy = int(leftEyeRightConer.x * w), int(leftEyeRightConer.y * h);
imgshow_keypoint(metricImg,'133',leftEyeRightConer_cx,leftEyeRightConer_cy)
# 右眼的左眼角362
rightEyeLeftConer = faceLandMarks.landmark[362];
rightEyeLeftConer_cx, rightEyeLeftConer_cy = int(rightEyeLeftConer.x * w), int(rightEyeLeftConer.y * h);
imgshow_keypoint(metricImg,'362',rightEyeLeftConer_cx,rightEyeLeftConer_cy)
# 右眼的右眼角263
rightEyeRightConer = faceLandMarks.landmark[263];
rightEyeRightConer_cx, rightEyeRightConer_cy = int(rightEyeRightConer.x * w), int(rightEyeRightConer.y * h);
imgshow_keypoint(metricImg,'263',rightEyeRightConer_cx,rightEyeRightConer_cy)
w1 = leftEyeLeftConer_cx - faceLeft_cx
w2 = leftEyeRightConer_cx - leftEyeLeftConer_cx
w3 = rightEyeLeftConer_cx - leftEyeRightConer_cx
w4 = rightEyeRightConer_cx - rightEyeLeftConer_cx
w5 = faceRight_cx - rightEyeRightConer_cx
# 從最左到最右的距離
faceWidth = faceRight_cx - faceLeft_cx
# 兩眼寬度的平均值 = (右眼寬度 + 左眼寬度)/2
leftEyeWidth = (leftEyeRightConer_cx - leftEyeLeftConer_cx)
rightEyeWidth = (rightEyeRightConer_cx - rightEyeLeftConer_cx)
eyeWidthMean = (leftEyeWidth + rightEyeWidth) / 2
# 計算 五個部位寬度 分別與 眼寬平均 之間的 差,使用臉寬進行歸一化
# 寬度1 : 左眼左眼角 - 臉最左
# 寬度2 : 左眼右眼角 - 左眼左眼角
# 寬度3 : 右眼左眼角 - 左眼右眼角
# 寬度4 : 右眼右眼角 - 右眼左眼角
# 寬度5 : 臉最右 - 右眼右眼角
gap1 = np.abs(w1 - eyeWidthMean) * 100 / faceWidth
gap2 = np.abs(w2 - eyeWidthMean) * 100 / faceWidth
gap3 = np.abs(w3 - eyeWidthMean) * 100 / faceWidth
gap4 = np.abs(w4 - eyeWidthMean) * 100 / faceWidth
gap5 = np.abs(w5 - eyeWidthMean) * 100 / faceWidth
#L2範數-所有元素的平方和,再開平方
Five_Eye_Metrics = math.sqrt( math.pow(gap1,2) +
math.pow(gap2,2) +
math.pow(gap3,2) +
math.pow(gap4,2) +
math.pow(gap5,2) )
imgshow_line(metricImg, faceLeft_cx, faceTop_cy, faceLeft_cx, faceBottom_cy )
imgshow_line(metricImg, faceRight_cx, faceTop_cy, faceRight_cx, faceBottom_cy )
imgshow_line(metricImg, leftEyeLeftConer_cx, faceTop_cy, leftEyeLeftConer_cx, faceBottom_cy )
imgshow_line(metricImg, leftEyeRightConer_cx, faceTop_cy, leftEyeRightConer_cx, faceBottom_cy )
imgshow_line(metricImg, rightEyeLeftConer_cx, faceTop_cy, rightEyeLeftConer_cx, faceBottom_cy )
imgshow_line(metricImg, rightEyeRightConer_cx, faceTop_cy, rightEyeRightConer_cx, faceBottom_cy )
cv2.putText(metricImg,
("w1=%d,w2=%d,w3=%d,w4=%d,w5=%d"%(w1,w2,w3,w4,w5)),
(10,20+h),
cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,0,0),1)
cv2.putText(metricImg,
('FiveEyeMetricC = {:.2f}'.format(Five_Eye_Metrics)),
(10,40+20+h),
cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,0,0),1)
return metricImg
#-------------------------------------
### 三庭指標:three courts ###
def beauty_three_courts(img,faceLandMarks):
h, w , c = img.shape
metricSpace = np.full((60,w,3),255,np.uint8)
metricImg = np.vstack((img,metricSpace))
# 臉輪廓的最左側點
faceLeft = faceLandMarks.landmark[234];
faceLeft_cx, faceLeft_cy = int(faceLeft.x * w), int(faceLeft.y * h);
imgshow_keypoint(metricImg,'234',faceLeft_cx,faceLeft_cy)
# 臉輪廓的最右側點
faceRight = faceLandMarks.landmark[454];
faceRight_cx, faceRight_cy = int(faceRight.x * w), int(faceRight.y * h);
imgshow_keypoint(metricImg,'454',faceRight_cx,faceRight_cy)
# 臉輪廓的最上側邊緣
faceTop = faceLandMarks.landmark[10];
faceTop_cx, faceTop_cy = int(faceTop.x * w), int(faceTop.y * h);
imgshow_keypoint(metricImg,'010',faceTop_cx,faceTop_cy)
# 臉輪廓的最下側邊緣
faceBottom = faceLandMarks.landmark[152];
faceBottom_cx, faceBottom_cy = int(faceBottom.x * w), int(faceBottom.y * h);
imgshow_keypoint(metricImg,'152',faceBottom_cx,faceBottom_cy)
# 眉心
eyebrowMiddle = faceLandMarks.landmark[9];
eyebrowMiddle_cx, eyebrowMiddle_cy = int(eyebrowMiddle.x * w), int(eyebrowMiddle.y * h);
imgshow_keypoint(metricImg,'009',eyebrowMiddle_cx,eyebrowMiddle_cy)
# 鼻翼下緣 2
noseBottom = faceLandMarks.landmark[2];
noseBottom_cx, noseBottom_cy = int(noseBottom.x * w), int(noseBottom.y * h);
imgshow_keypoint(metricImg,'002',noseBottom_cx,noseBottom_cy)
# 三庭:
# 衡量公式1:三庭高度相等,上庭:距離1(髮際線-眉心);中庭:距離2(鼻子底部--眉心);下庭:距離3(下巴尖-鼻子底部)
# 注意,臉部網格,臉部最上端是額頭中央,不是髮際線,有偏差。只計算中庭和下庭的偏差
# 指標A:下庭 與 中庭 之間距離偏差,在使用 臉長(臉部上方和下方距離) 進行歸一化
Top_Down = faceBottom_cy - faceTop_cy
sectionUpper = eyebrowMiddle_cy - faceTop_cy
sectionMiddle = noseBottom_cy - eyebrowMiddle_cy
sectionDown = faceBottom_cy - noseBottom_cy
# (中庭 - 下庭)/臉長
MetricThreeSection_A = np.abs(sectionDown - sectionMiddle) * 100 / Top_Down
imgshow_line(metricImg, faceLeft_cx, eyebrowMiddle_cy, faceRight_cx, eyebrowMiddle_cy )
imgshow_line(metricImg, faceLeft_cx, noseBottom_cy, faceRight_cx, noseBottom_cy )
imgshow_line(metricImg, faceLeft_cx, faceBottom_cy, faceRight_cx, faceBottom_cy )
cv2.putText(metricImg,
("h1=%d,h2=%d,h3=%d,faceHeight=%d"%(sectionUpper,sectionMiddle,sectionDown,Top_Down)),
(10,20+h),
cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,0,0),1)
cv2.putText(metricImg,
('ThreeSectionMetricA = {:.2f}'.format(MetricThreeSection_A)),
(10,30+20+h),
cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,0,0),1)
return metricImg
#-------------------------------------
### 達芬奇指標:嘴唇寬度 是 鼻翼寬度的1.6倍(0.618) ###
def beauty_davinci(img,faceLandMarks):
h, w , c = img.shape
metricSpace = np.full((60,w,3),255,np.uint8)
metricImg = np.vstack((img,metricSpace))
# 嘴唇左角 61
lipLeft = faceLandMarks.landmark[61];
lipLeft_cx = int(lipLeft.x * w)
lipLeft_cy = int(lipLeft.y * h)
imgshow_keypoint(metricImg,'061',lipLeft_cx,lipLeft_cy)
# 嘴唇右角 291
lipRight = faceLandMarks.landmark[291];
lipRight_cx = int(lipRight.x * w)
lipRight_cy = int(lipRight.y * h)
imgshow_keypoint(metricImg,'291',lipRight_cx,lipRight_cy)
# 鼻翼左緣 129
noseLeft = faceLandMarks.landmark[129];
noseLeft_cx = int(noseLeft.x * w)
noseLeft_cy = int(noseLeft.y * h)
imgshow_keypoint(metricImg,'129',noseLeft_cx,noseLeft_cy)
# 鼻翼右緣 358
noseRight358 = faceLandMarks.landmark[358];
noseRight358_cx = int(noseRight358.x * w)
noseRight358_cy = int(noseRight358.y * h)
imgshow_keypoint(metricImg,'358',noseRight358_cx,noseRight358_cy)
# 鼻翼右緣 344
#noseRight344 = faceLandMarks.landmark[344];
#noseRight344_cx = int(noseRight344.x * w)
#noseRight344_cy = int(noseRight344.y * h)
#imgshow_keypoint(img,'344',noseRight344_cx,noseRight344_cy)
#metricDavinci344 = (lipRight_cx - lipLeft_cx) / (noseRight344_cx - noseLeft_cx)
#metricDavinci358 = (lipRight_cx - lipLeft_cx) / (noseRight358_cx - noseLeft_cx)
noseWidth = (noseRight358_cx - noseLeft_cx)
lipWidth = lipRight_cx - lipLeft_cx
metricDavinci = noseWidth / lipWidth
imgshow_line(metricImg, lipLeft_cx, lipLeft_cy, lipRight_cx, lipLeft_cy )
imgshow_line(metricImg, noseLeft_cx, noseLeft_cy, noseRight358_cx, noseLeft_cy )
cv2.putText(metricImg,
("noseWidth=%d,lipWidth=%d"%(noseWidth,lipWidth)),
(10,20+h),
cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,0,0),1)
cv2.putText(metricImg,
('metricDavinci={:.2f}'.format(metricDavinci)),
(10,30+20+h),
cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,0,0),1)
return metricImg
#-------------------------------------
def faceLandmarksBeauty(selfUrl,digitalUrl,processedImgUrl,text):
model1=mp.solutions.face_mesh.FaceMesh(
static_image_mode=False,
refine_landmarks=True,
max_num_faces=5,
min_detection_confidence=0.5,
min_tracking_confidence=0.5,
)
model2=mp.solutions.face_mesh.FaceMesh(
static_image_mode=False,
refine_landmarks=True,
max_num_faces=5,
min_detection_confidence=0.5,
min_tracking_confidence=0.5,
)
selfImg = cv2.imread(selfUrl)
imgH,imgW,imgChs = selfImg.shape
sizedH = 640
sizedW = int ( (sizedH/imgH)*imgW )
selfImg = cv2.resize(selfImg,(sizedW,sizedH),fx=0,fy=0,interpolation=cv2.INTER_CUBIC)
img_RGB = cv2.cvtColor(selfImg, cv2.COLOR_BGR2RGB)
results = model1.process(img_RGB)
if results.multi_face_landmarks:
for faceLms in results.multi_face_landmarks:
selfFiveeyesImg=beauty_five_eyes(selfImg, faceLms)
selfThreecourtsImg=beauty_three_courts(selfImg, faceLms)
selfDavinciImg=beauty_davinci(selfImg, faceLms)
else:
print("no face detected!")
cv2.putText(selfFiveeyesImg,text,(10,sizedH-30),cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),2,8)
cv2.putText(selfThreecourtsImg,text,(10,sizedH-30),cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),2,8)
cv2.putText(selfDavinciImg,text,(10,sizedH-30),cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),2,8)
digitalImg = cv2.imread(digitalUrl)
imgH,imgW,imgChs = digitalImg.shape
sizedH = 640
sizedW = int ( (sizedH/imgH)*imgW )
digitalImg = cv2.resize(digitalImg,(sizedW,sizedH),fx=0,fy=0,interpolation=cv2.INTER_CUBIC)
img_RGB = cv2.cvtColor(digitalImg, cv2.COLOR_BGR2RGB)
results = model2.process(img_RGB)
if results.multi_face_landmarks:
for faceLms in results.multi_face_landmarks:
digitalFiveeyesImg=beauty_five_eyes(digitalImg, faceLms)
digitalThreecourtsImg=beauty_three_courts(digitalImg, faceLms)
digitalDavinciImg=beauty_davinci(digitalImg, faceLms)
else:
print("no face detected!")
cv2.putText(digitalFiveeyesImg,text,(10,sizedH-30),cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),2,8)
cv2.putText(digitalThreecourtsImg,text,(10,sizedH-30),cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),2,8)
cv2.putText(digitalDavinciImg,text,(10,sizedH-30),cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),2,8)
metricFiveeyesImg = np.hstack((selfFiveeyesImg,digitalFiveeyesImg))
metricThreecourtsImg = np.hstack((selfThreecourtsImg,digitalThreecourtsImg))
metricDavinciImg = np.hstack((selfDavinciImg,digitalDavinciImg))
cv2.imwrite(processedImgUrl+"metric-five-eyes.jpeg", metricFiveeyesImg)
cv2.imwrite(processedImgUrl+"metric-three-courts.jpeg", metricThreecourtsImg)
cv2.imwrite(processedImgUrl+"metric-davinci.jpeg", metricDavinciImg)
cv2.imshow("metric-five-eyes.jpeg", metricFiveeyesImg)
cv2.imshow("metric-three-courts.jpeg", metricThreecourtsImg)
cv2.imshow("metric-davinci.jpeg", metricDavinciImg)
#-------------------------------------
if __name__ == '__main__':
# 檢查命令行參數 python your_script.py example.txt
if len(sys.argv) < 3:
print("請提供文件名作為命令行參數!python3 faceBeauty.py 111.jpg 222.jpg")
sys.exit(1)
# selfImg
selfImgUrl = sys.argv[1]
try:
with open(selfImgUrl, 'r', encoding='utf-8') as file:
print(f"文件 '{selfImgUrl}' 找到")
except FileNotFoundError:
print(f"錯誤:文件 '{selfImgUrl}' 未找到!")
sys.exit(1)
except Exception as e:
print(f"發生錯誤:{e}")
sys.exit(1)
# selfImg
digitalImgUrl = sys.argv[2]
try:
with open(digitalImgUrl, 'r', encoding='utf-8') as file:
print(f"文件 '{digitalImgUrl}' 找到")
except FileNotFoundError:
print(f"錯誤:文件 '{digitalImgUrl}' 未找到!")
sys.exit(1)
except Exception as e:
print(f"發生錯誤:{e}")
sys.exit(1)
#savedImgUrl = "./pictures/saved/2020104701-metric-fiveeyes.jpg"
savedImgUrl = "./pictures/saved/"
faceLandmarksBeauty(selfImgUrl,digitalImgUrl,savedImgUrl,
"test")
#frame = cv2.imread(savedImgUrl)
#cv2.imshow("frame",frame)
cv2.waitKey(0)
cv2.destroyAllWindows()過程3:帶兩張人臉圖片文件名參數執行代碼
python3 faceBeauty.py 111.jpeg 222.jpeg
人臉對比:



6.6 算法優化
開發者可以根據自己人臉與網上數字人的人臉顏值對比,看看是否合理,以及調整計算顏值指標的算法。
三、反饋改進建議
如您在案例實操過程中遇到問題或有改進建議,可以到論壇帖評論區反饋即可,我們會及時響應處理,謝謝!