
你是小阿巴,剛入行的程序員。

這天,你接到一個私活:幫學校做個學生管理系統,要能管理學生信息、記錄成績、統計數據。
你一聽,這不簡單嗎?用 Java 寫個程序,把數據存到 Map 裏就搞定了。
public class StudentManagementSystem {
// 使用 Map 存儲學生信息,key 為學號,value 為學生信息字符串
private Map<Integer, String> studentMap = new HashMap<>();
// 添加學生
public void addStudent(int studentNo, String name, double score, int classId) {
String studentInfo = name + "," + score + "," + classId;
studentMap.put(studentNo, studentInfo);
}
// 查詢學生
public String getStudent(int studentNo) {
return studentMap.get(studentNo);
}
// 查詢所有學生
public void listAllStudents() {
for (Map.Entry<Integer, String> entry : studentMap.entrySet()) {
System.out.println("學號:" + entry.getKey() +
",信息:" + entry.getValue());
}
}
}結果一週後,甲方指着你的鼻子罵道:狗阿巴,我錄入的 500 個學生信息怎麼全沒了?!
你一查,原來昨晚服務器重啓了,導致內存裏的數據全部丟失!
你汗流浹背了:看來我得把數據保存到硬盤上……
於是你連夜改代碼,把數據存到了文本文件裏,這下數據就不會丟失了。
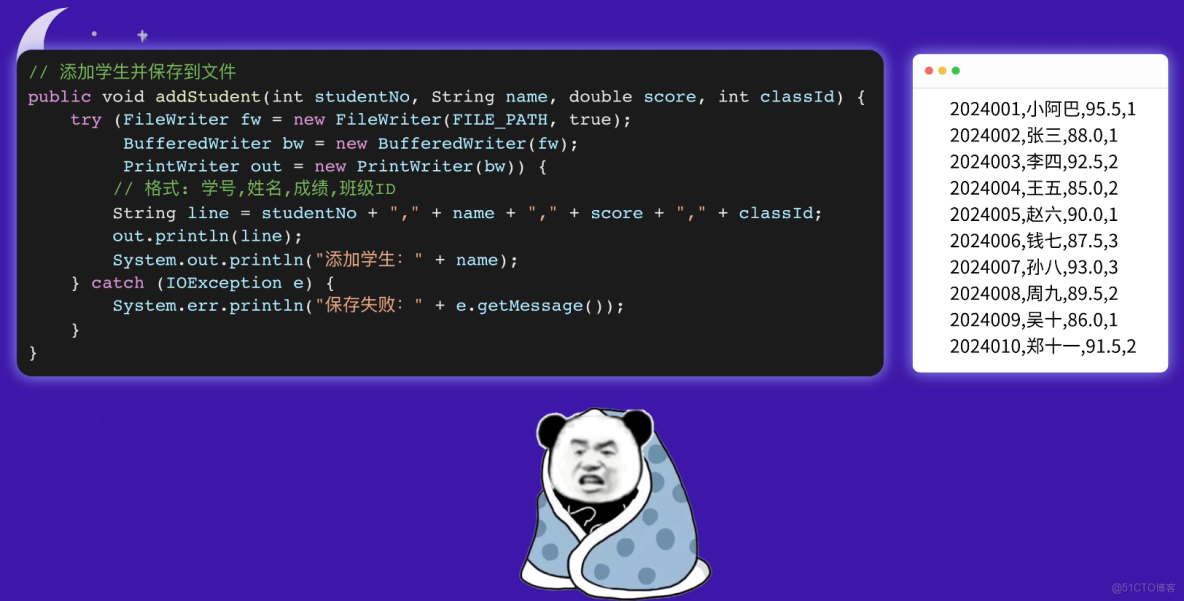
但接下來,甲方提出了各種不同的查詢數據需求,每個需求你都得寫一堆代碼邏輯,讓你越來越頭大。
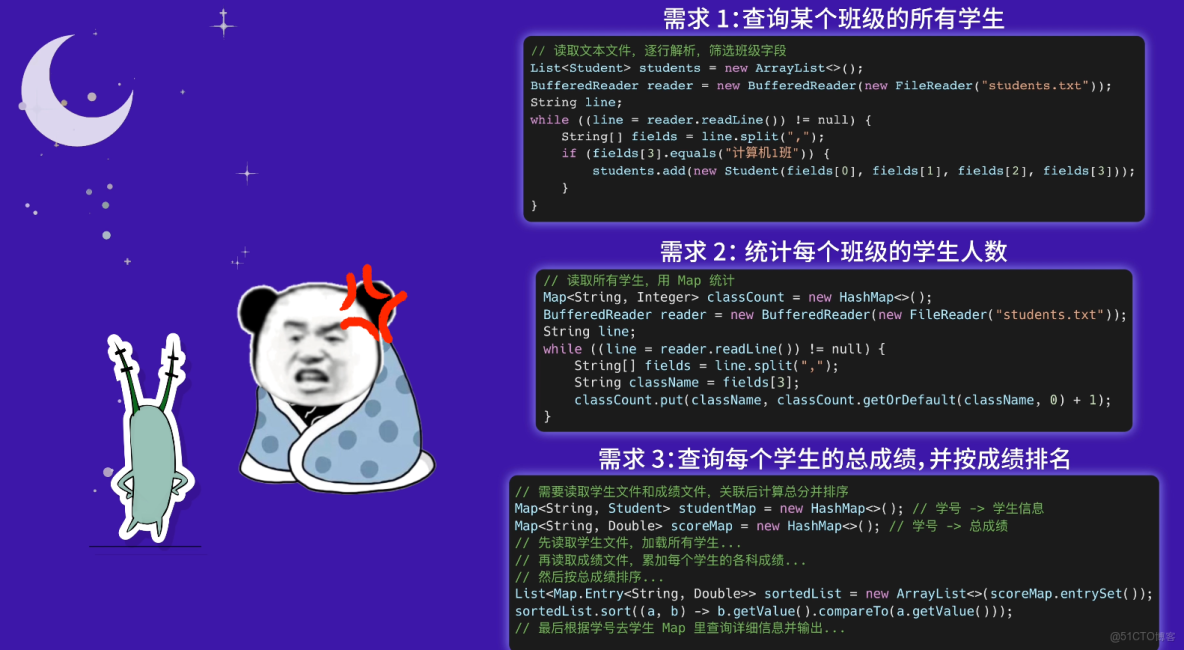
於是你找到號稱 “後端之狗” 的魚皮求助:有沒有更好的辦法管理數據啊?
魚皮笑了笑:當然要用數據庫啦!
你一臉懵:數據庫?那是啥?
⭐️ 推薦觀看本文對應視頻版:https://bilibili.com/video/BV1iJSLBbEyD
第一階段:認識數據庫
魚皮:數據庫就像一個超級 Excel 表格,可以存儲管理海量數據、快速靈活地查詢和篩選數據、在多個服務器間共享數據、並且能夠精確控制數據的讀寫權限。

你恍然大悟:啊,所以我應該用數據庫來管理學生信息。🤡
魚皮:沒錯,絕大多數項目的數據都存在數據庫裏,因此數據庫是後端程序員的必備技能。
數據庫主要分 2 大類:
1)關係型數據庫,比如 MySQL、Oracle、PostgreSQL,適合存儲相互之間有關聯的數據,比如學生和班級、訂單和商品。
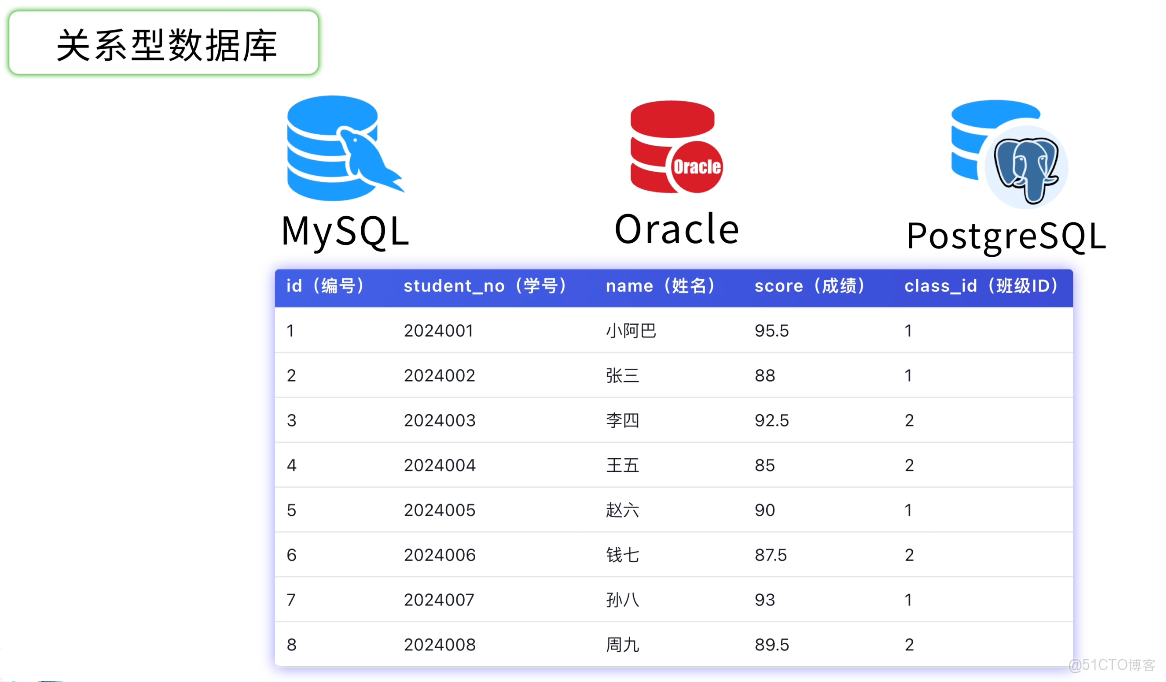
2)非關係型數據庫,比如 Redis(主要用於緩存和高速讀寫)、MongoDB(文檔型數據庫),它們在數據結構和使用場景上更靈活。

你:這麼多數據庫,我該學哪個呢?
魚皮:建議新手從 MySQL 開始,因為它是主流的、容易入門的、開源的關係型數據庫。
你:那還等什麼,MySQL,啓動!
魚皮:別急,在學之前,得先了解幾個數據庫的基本概念。
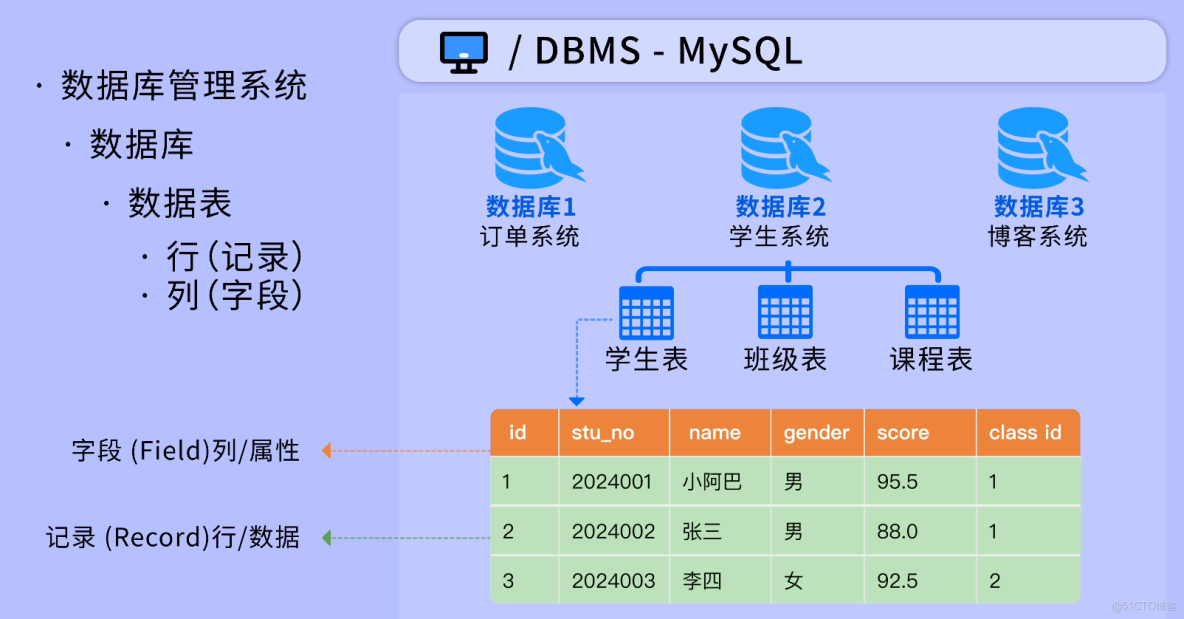
1)數據庫管理系統(DBMS):顧名思義就是用來管理數據庫的系統,比如 MySQL。它把數據存儲在硬盤上,斷電也不會丟失。
2)數據庫:一個 MySQL 系統可以管理多個數據庫,比如每個項目一個庫(學生系統一個庫、訂單系統一個庫),互不干擾。
3)表:一個數據庫可以有多張數據表,用來存儲某一類數據。
4)記錄:表由一行行記錄組成,每一行就是一條數據
5)字段:每一列對應一個字段,具有名稱和類型。比如姓名字段是文本類型、年齡字段是數字類型。
6)關聯
這是關係型數據庫的核心,表和表之間是有聯繫的,主要有 3 種關係。
1 對 1:比如學生表和學生檔案表,一個學生對應一份檔案
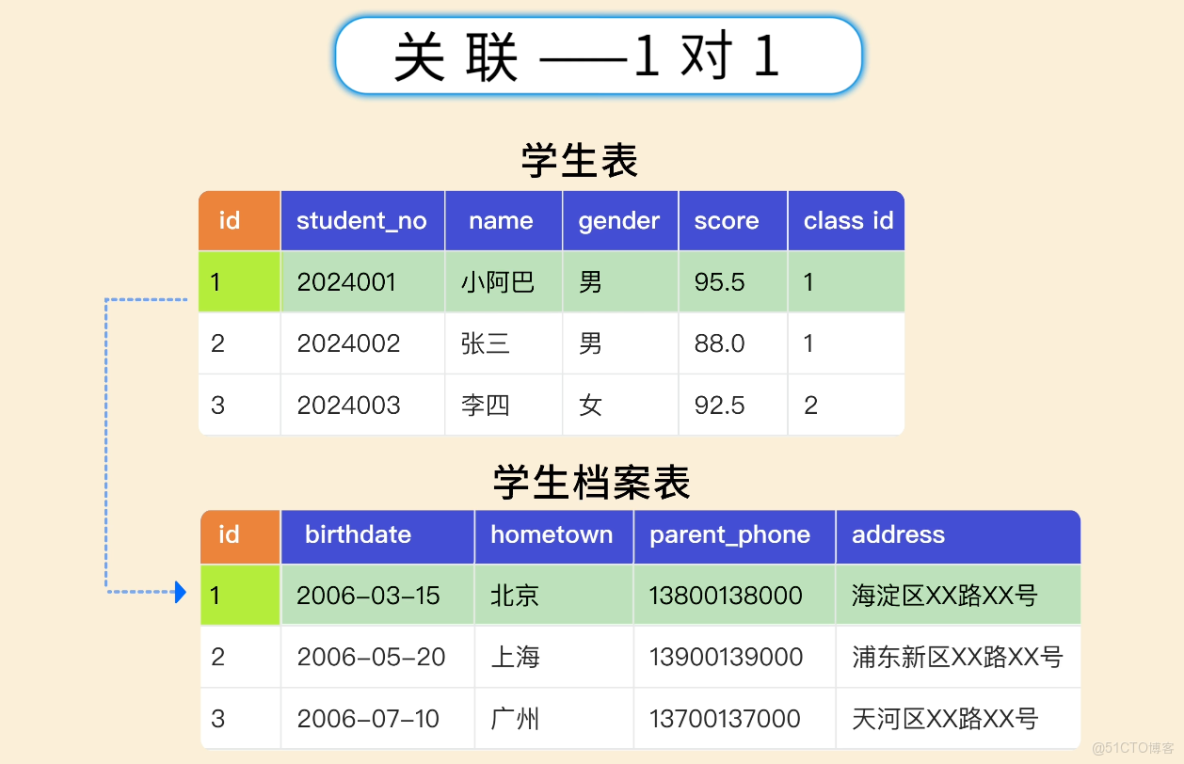
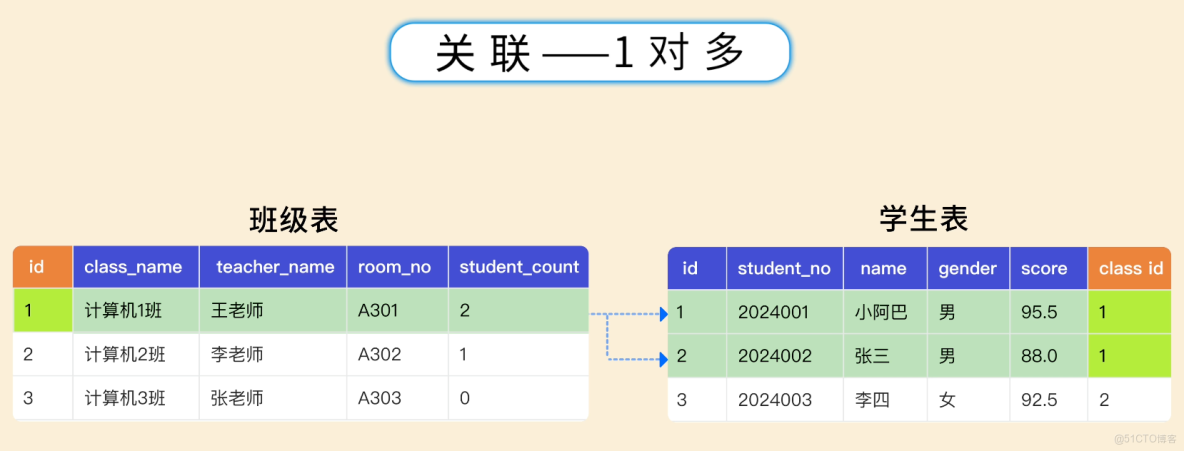
1 對多:比如班級表和學生表,一個班級有多個學生
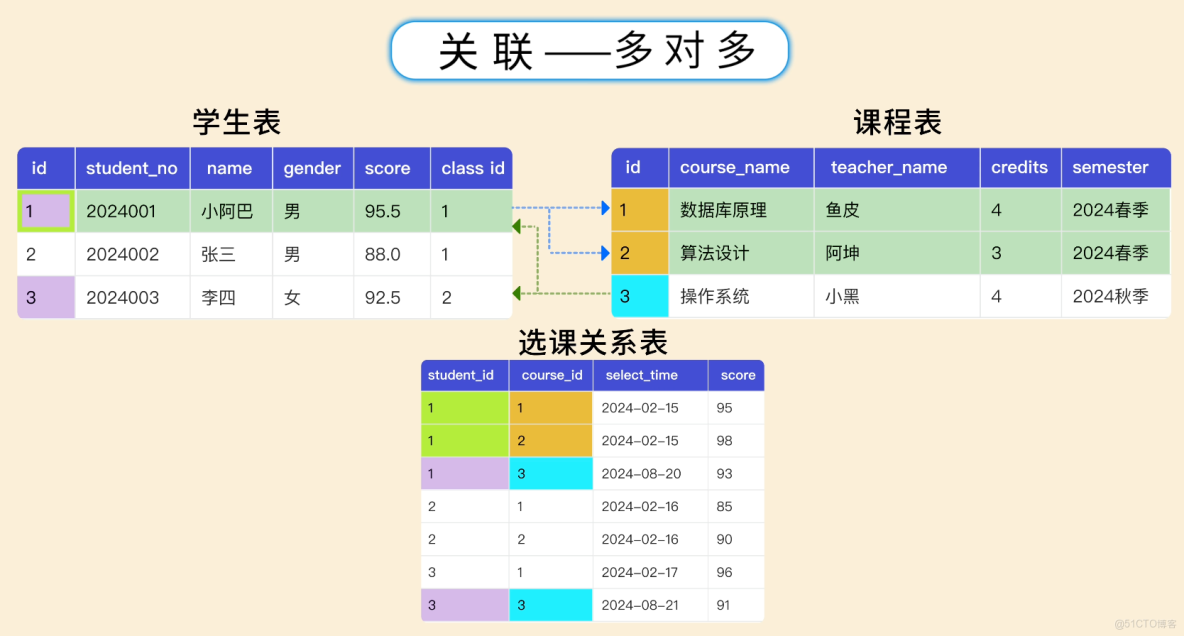
多對多:比如學生表和課程表,一個學生可以選多門課,一門課也可以被多個學生選
這些表和表之間的關聯形成了完整的業務系統。
你想了想:對哦,也就是説我可以根據學生關聯查詢到所屬的班級和選修的課程。
那怎麼操作數據庫呢?
魚皮:這就要用到 SQL 了。
SQL 是專門用來操作數據庫的 結構化查詢語言(Structured Query Language)。
你可以用 SQL 實現各種查詢,比如:
1)查詢所有學生:SELECT * FROM student;
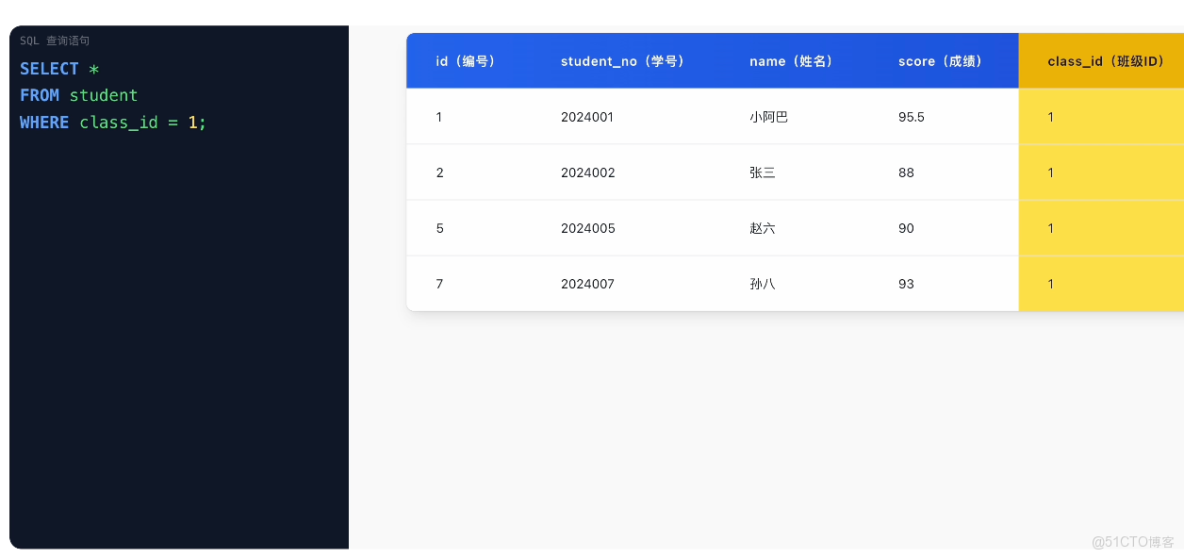
2)只查詢屬於某個班級的學生:SELECT * FROM student WHERE class_id = 1;
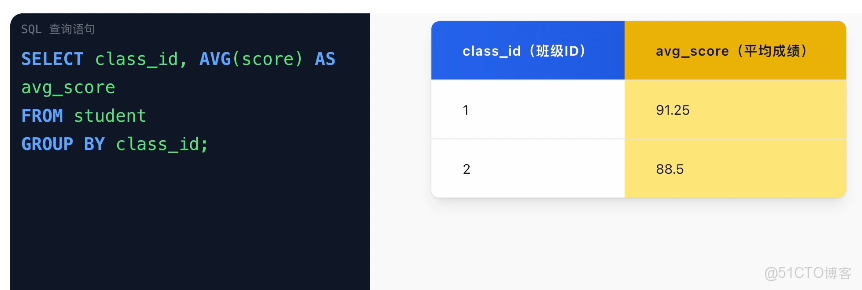
3)分組統計每個班級中所有學生的平均成績:SELECT class_id, AVG(score) FROM student GROUP BY class_id;
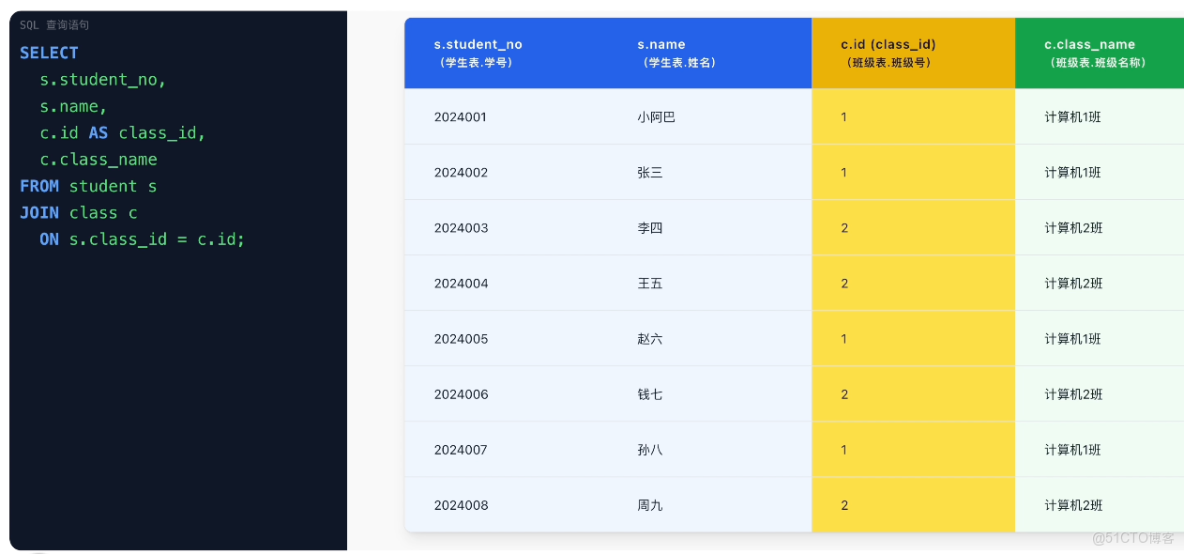
4)還可以同時查詢學生表和班級表,並把結果關聯在一起:SELECT s.name, c.class_name FROM student s JOIN class c ON s.class_id = c.id;
此外,不同的數據庫管理系統(比如 MySQL、Oracle、SQL Server)有自己的 “方言”,操作這些數據庫的 SQL 會有一點點小差別。

你:天吶,相當於我要多學一門語言,而且還要學方言!
魚皮:別擔心,SQL 的核心語法都是通用的。

而且你現在只需要知道 SQL 是用來操作數據庫的就夠了,
有時間再到我開發的 免費 SQL 學習網站 邊練邊學,而且後續我還會出視頻專門講 SQL 哦。
你:關注了關注了~
魚皮:那接下來咱們就開始實戰學習吧,先把 MySQL 裝上並且操作一波。
第二階段:實戰應用
基礎操作
機智如你,直接打開 官網 下載了 MySQL 數據庫,並且成功安裝運行。
但是怎麼操作 MySQL 呢?
魚皮:可以使用官方提供的 命令行工具,先輸入命令,輸入默認設置的用户名和密碼,就能連上數據庫並進行操作了。
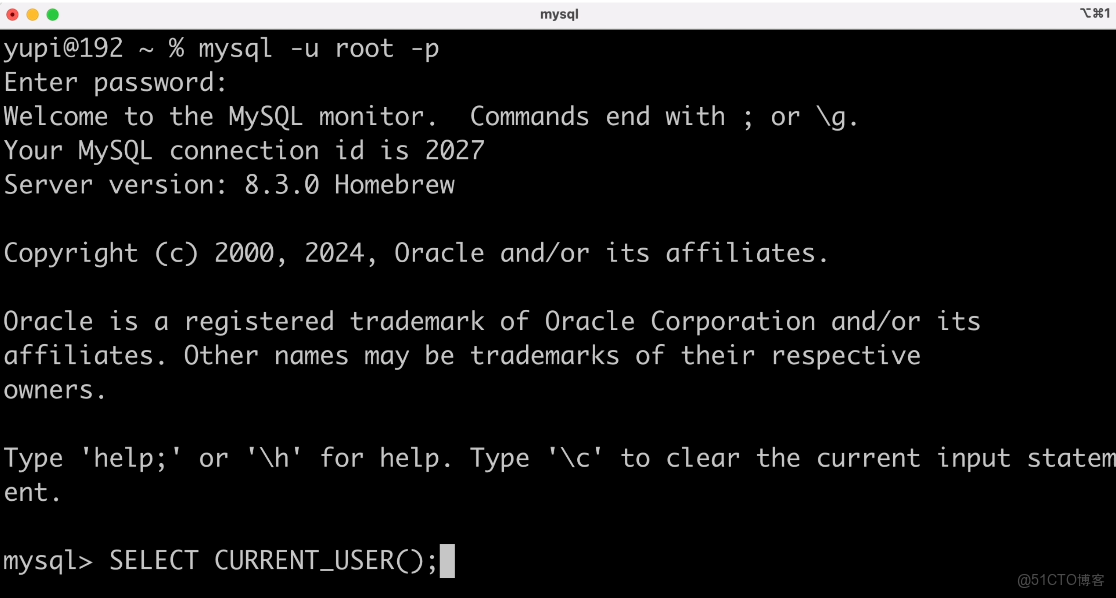
你:root 是什麼?
魚皮:root 是數據庫的超級管理員賬號,擁有所有權限。
不過命令行看着不直觀,我建議你裝個 MySQL 可視化工具(比如 Navicat、DataGrip),能像使用 Excel 一樣管理數據庫,數據一目瞭然。
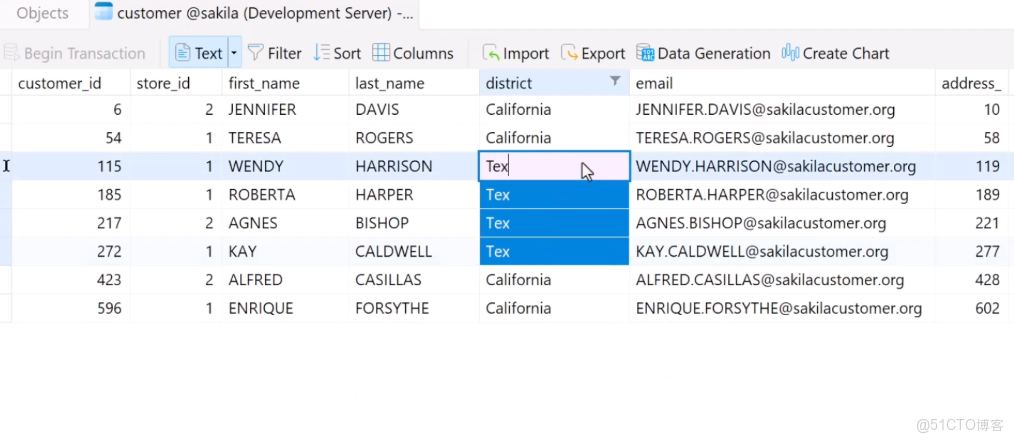
你:哇,確實方便多了!
魚皮:接下來我帶你實際操作一遍,用數據庫來管理學生信息。
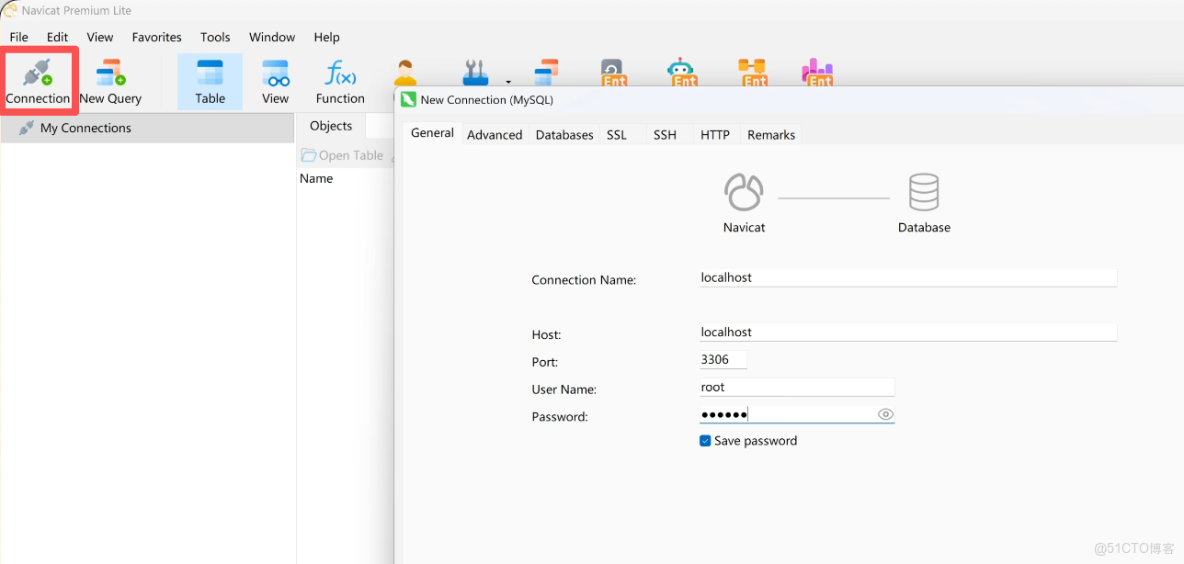
1)首先連接數據庫
點擊左上角創建連接,選擇數據庫的類別,然後輸入數據庫配置信息,點擊確認,就連接成功了。
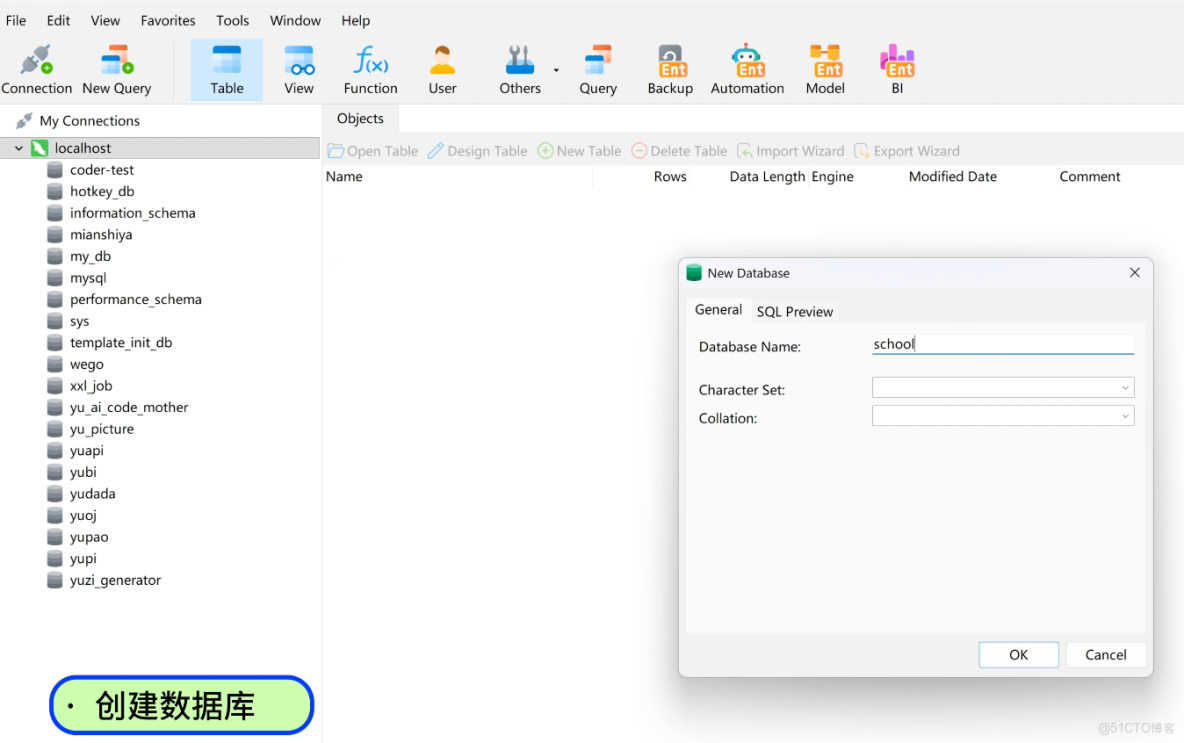
2)然後來創建一個數據庫
右鍵點擊數據庫連接,選擇 “新建數據庫”,命名為 school,點擊確認,就創建成功了。
對應的 SQL 語句是 CREATE DATABASE school;
3)接下來我們要創建表
魚皮:想一想,如果要設計一個存儲學生信息的表,需要哪些字段?
你:學號、姓名、成績、班級。
魚皮:沒錯,每個字段還要指定類型。
- 學號用 int 整數類型
- 姓名用 varchar 文本類型
- 成績用 decimal 小數類型(保留 2 位小數)
- 班級用 int 整數類型(表示班級編號)
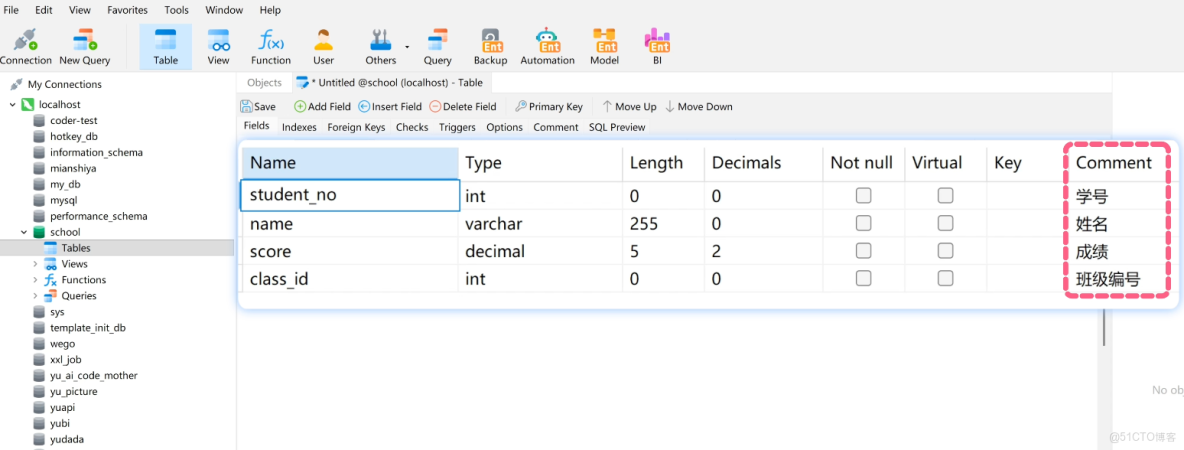
除了類型,創建表時還要設置一些 約束,比如:
- 主鍵:每條數據的唯一標識,一般建議每個表單獨加一列 id 字段,作為主鍵
- 非空:某些字段不能為空,比如姓名不能為空
- 唯一:值不能重複,比如每個學號都是唯一的
- 外鍵:建立表之間的關聯關係,比如學生表的 class_id 可以設為外鍵,關聯到班級表的 id,保證數據的完整性。但實際開發中外鍵存在性能問題,用的沒那麼多。
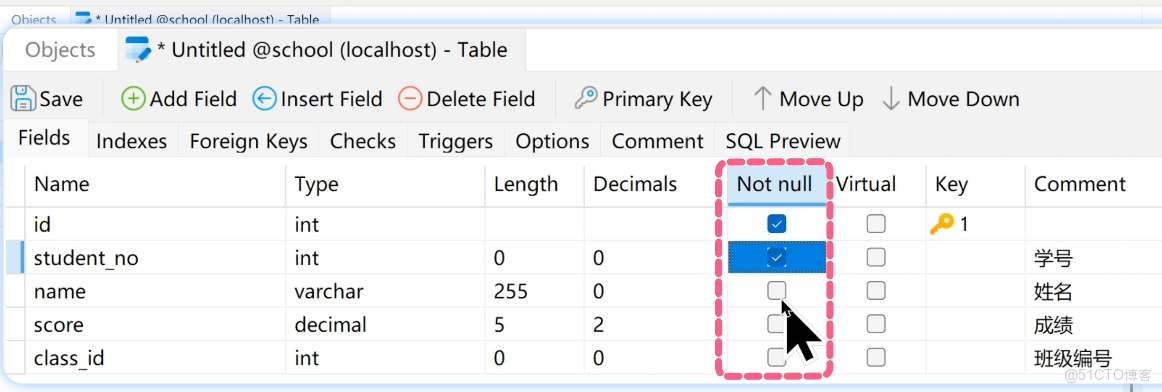
設計好表結構之後,點擊保存,數據表就創建成功了。
對應的 SQL 語句類似這樣:
CREATE TABLE student (
id INT PRIMARY KEY AUTO_INCREMENT, # 主鍵,自動遞增
student_no INT UNIQUE NOT NULL, # 學號,唯一且非空
name VARCHAR(50) NOT NULL, # 姓名,非空
score DECIMAL(5,2), # 成績,最多 5 位數字,2 位小數
class_id INT # 班級編號
);4)然後我們就可以操作數據表了。主要有 4 類核心操作 —— 增刪改查。
先插入幾條學生數據:
INSERT INTO student (student_no, name, score, class_id)
VALUES (2024001, '小阿巴', 95.5, 1);然後查詢所有學生數據:
SELECT * FROM student;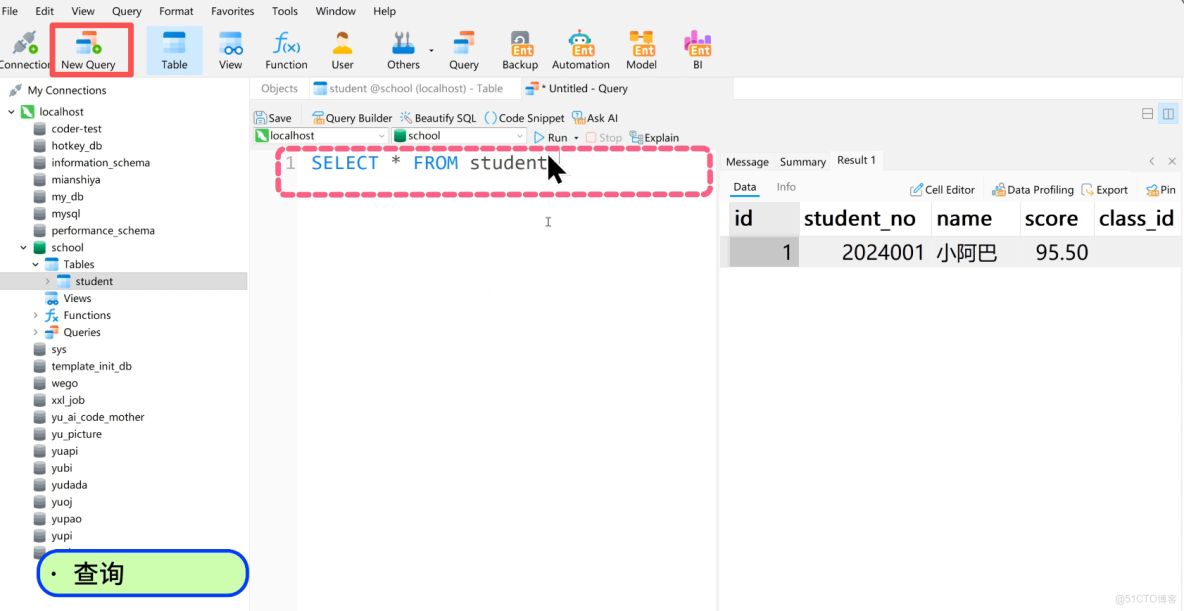
修改某條數據,把你的成績改成滿分:
UPDATE student SET score = 100 WHERE student_no = 2024001;
SELECT * FROM student;最後刪除某條數據:
DELETE FROM student WHERE student_no = 2024001;
SELECT * FROM student;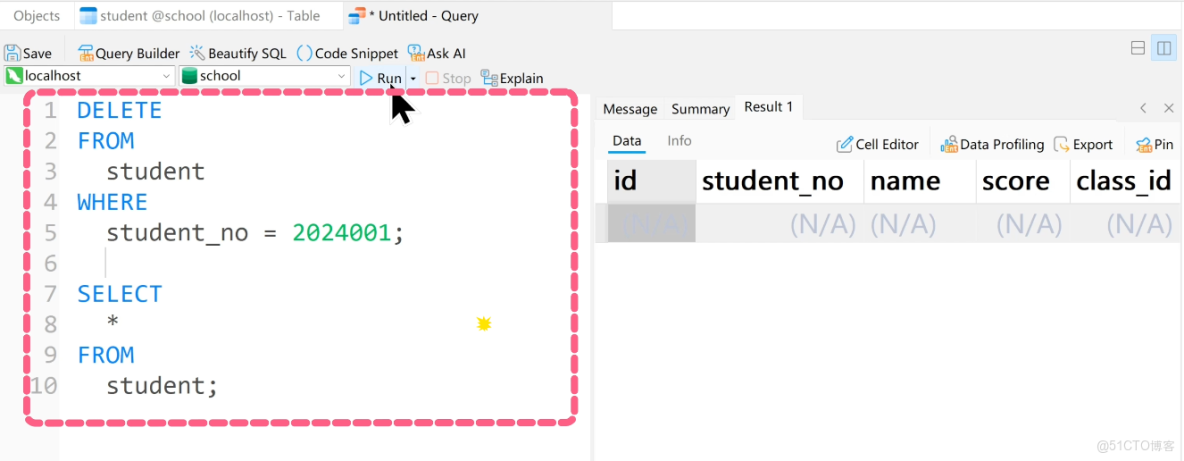
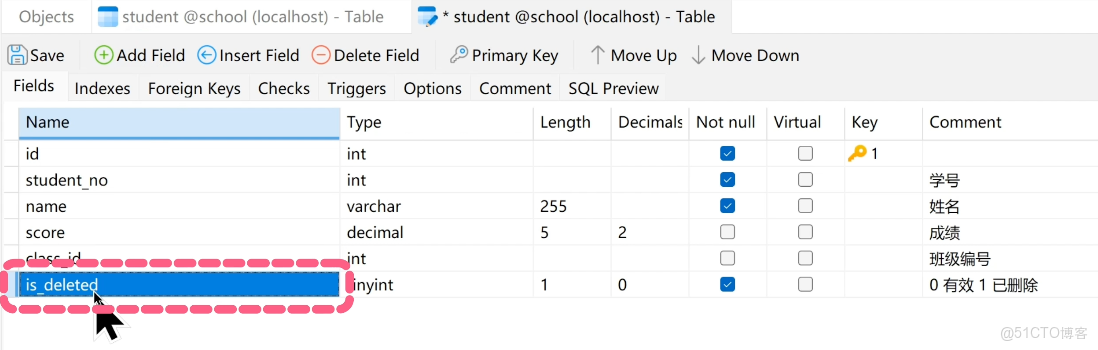
魚皮:注意,刪除掉的數據就再也找不回來了!
因此實際項目中建議使用 邏輯刪除,就是加個 is_deleted 字段來標記數據是否失效,而不是真的刪除數據,這樣即使誤刪也能恢復。
客户端操作
你很是興奮:用可視化工具真方便啊,但是我怎麼用代碼操作數據庫呢?
魚皮:主流編程語言都有操作數據庫的 SDK,比如使用 Java 的 JDBC,需要先加載對應數據庫的驅動、然後獲取連接、編寫 SQL 語句並執行、最後收集結果並關閉連接。
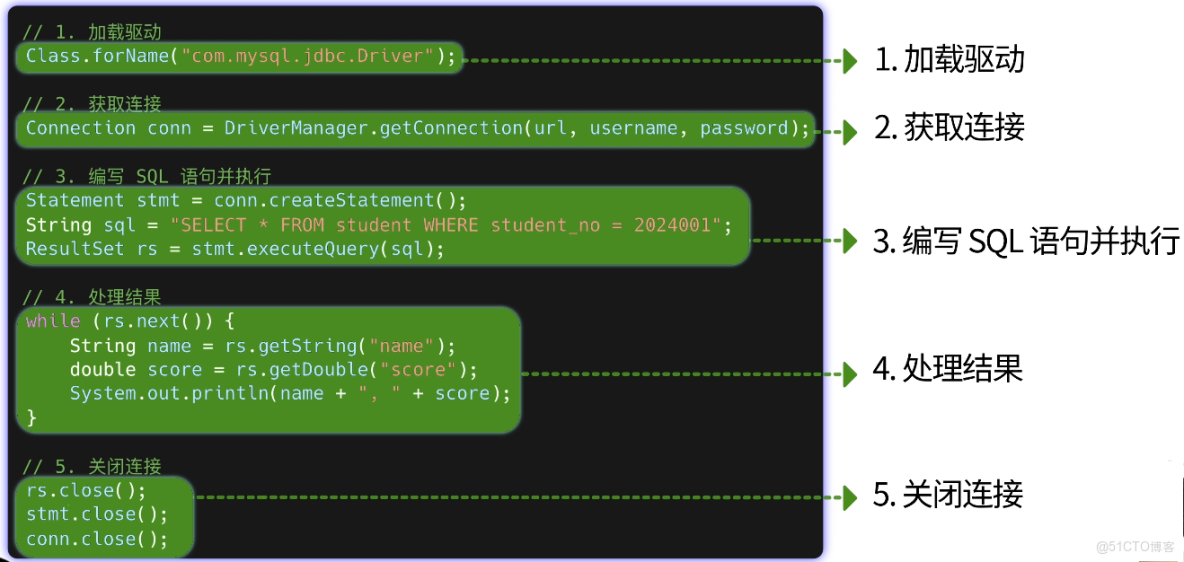
你撓了撓頭:我就查詢 1 次數據庫,都要寫這麼多代碼麼?而且我根本不會寫 SQL 語句啊!
魚皮笑道:沒關係,實際開發中我們會使用 ORM 對象關係映射框架,可以把數據庫的表映射成 Java 對象,像操作對象一樣操作數據庫。
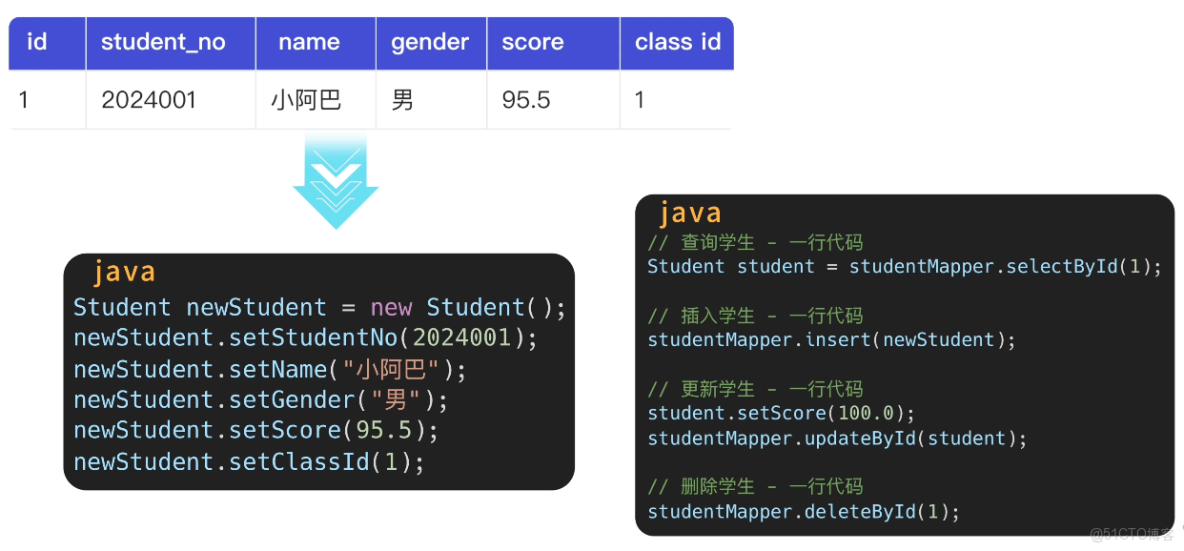
比如 Java 的 MyBatis 框架,可以讓你用更簡潔的方式執行 SQL:
// MyBatis 方式:只需要寫 SQL,框架自動處理連接和結果映射
Student student = studentMapper.selectByStudentNo(2024001);
System.out.println(student.getName());還有它的增強版 MyBatis Plus 和 MyBatis Flex,提供了更多開箱即用的功能,連 SQL 都不用寫!直接調用現成的方法,幾行代碼就能實現增刪改查,告別 SQL Boy!

你感嘆道:這才是人寫的代碼啊!優雅,真是優雅~
魚皮提醒道:但是,框架不是萬能的,有些複雜查詢的 SQL 還要自己手寫,不過現在有 AI 了,寫個 SQL 還不是手拿把掐的?
你:明白了,我這就用框架重寫學生管理系統。
第三階段:數據庫特性
索引
一個月後,你重寫的學生管理系統正式上線,不僅得到了甲方的好評,而且很快火遍了全國高校。
你內心暗爽:數據庫也不過如此嘛~

但你沒想到,隨着學生數據量的暴漲和表結構的擴展,你的數據庫查詢速度也越來越慢,光是查詢某個班級的學生竟然都要等好幾秒!
你有些驚訝:我這 SQL 也不復雜啊,怎麼查詢這麼慢?
魚皮:加個索引試試?
你:索引?那是啥?
魚皮:索引就是數據庫的目錄。你現在查數據,數據庫得一行一行全表掃描,數據量越大速度越慢。加了索引後,數據庫可以通過索引快速定位到數據,就像通過書的目錄快速翻到某一頁。
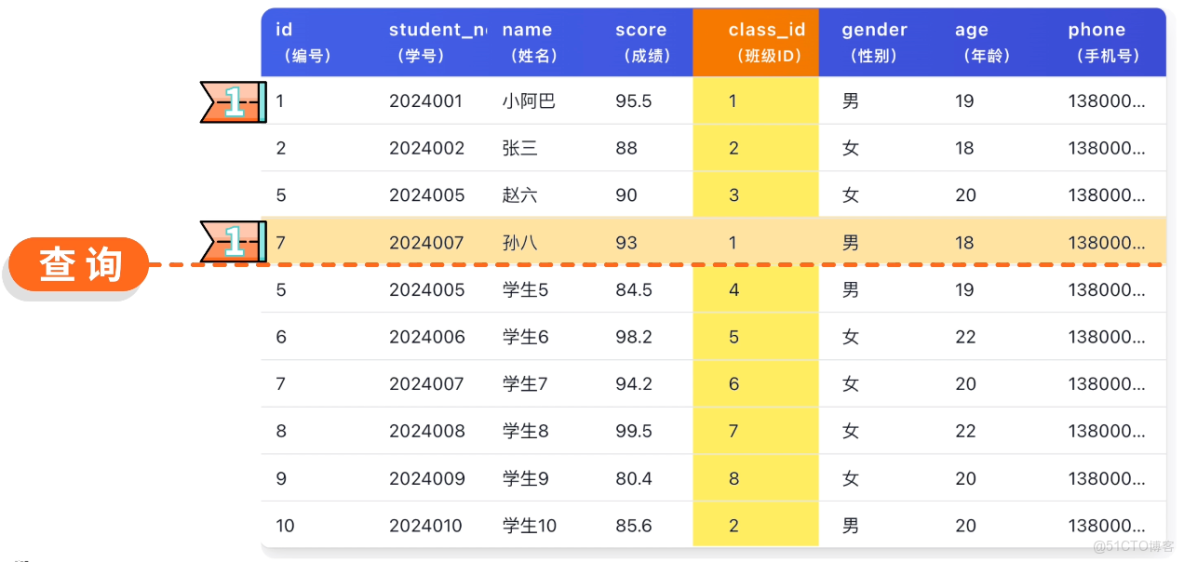
你恍然大悟:對啊,老師經常按班級查詢學生,不妨給班級字段添加索引。
CREATE INDEX idx_class_id ON student(class_id);添加索引後,你再次測試查詢,竟然只要幾十毫秒!
你激動得跳了起來:索引太香了,我要給所有字段都加索引~
魚皮擺擺手:別,索引可不是越多越好!
你愣住了:為啥?
魚皮:索引雖然能加快查詢,但也有代價。
- 一方面會增加寫入數據(增刪改)的開銷。因為每次寫入數據,索引也要更新。
- 此外,索引本身也是數據,要佔用更多的存儲空間。
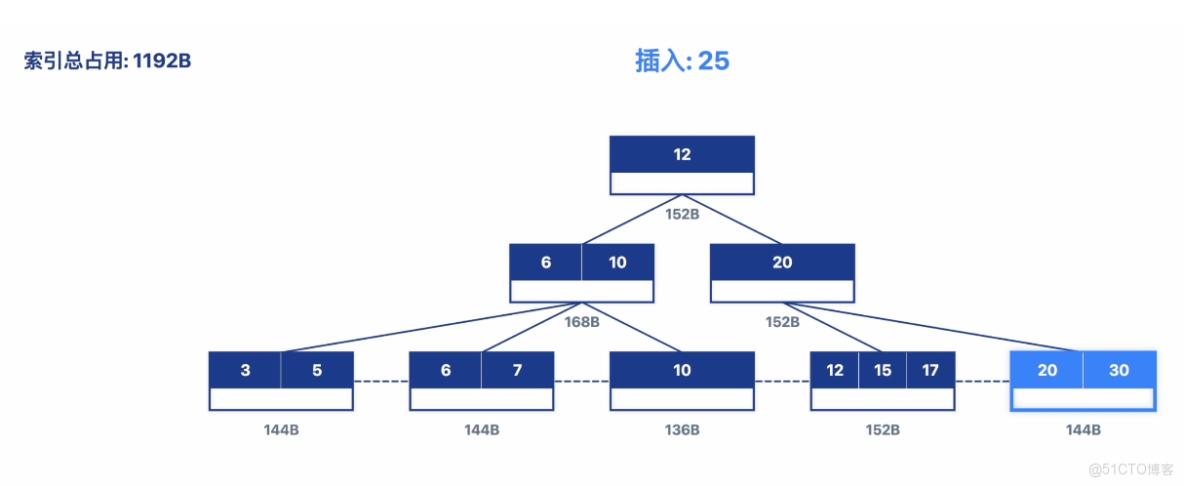
所以,要在經常用來查詢、並且數據區分度高的字段上合理添加索引。比如班級 ID、學號這種字段適合加索引,但性別字段(只有男女兩個值)就不適合。
事務
又過了幾天,甲方又提新需求了。
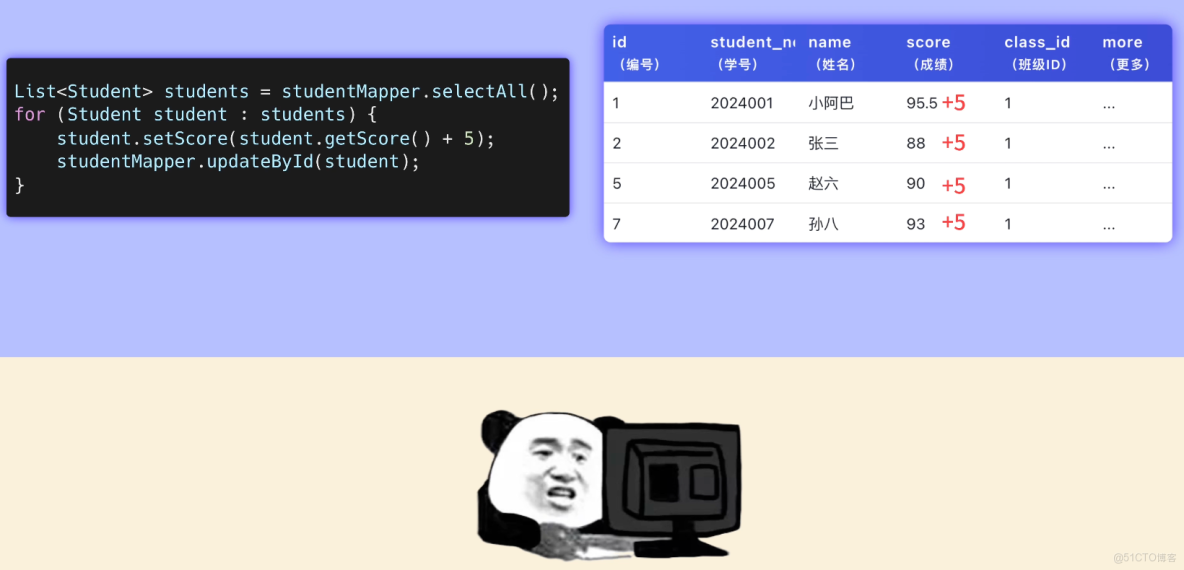
甲方:小阿巴,有老師反饋題目判錯了,需要批量把所有學生的成績都加 5 分。
你信心滿滿:簡單,不就是個批量更新操作麼?
你寫了一段代碼,循環更新所有學生的成績。
沒想到,越自信 Bug 越多,功能剛剛上線,就收到了投訴:怎麼有些學生的成績改了,有些沒改?
你查看了下日誌,發現前面學生的成績更新成功了,但由於網絡波動,導致後面的學生都沒更新。
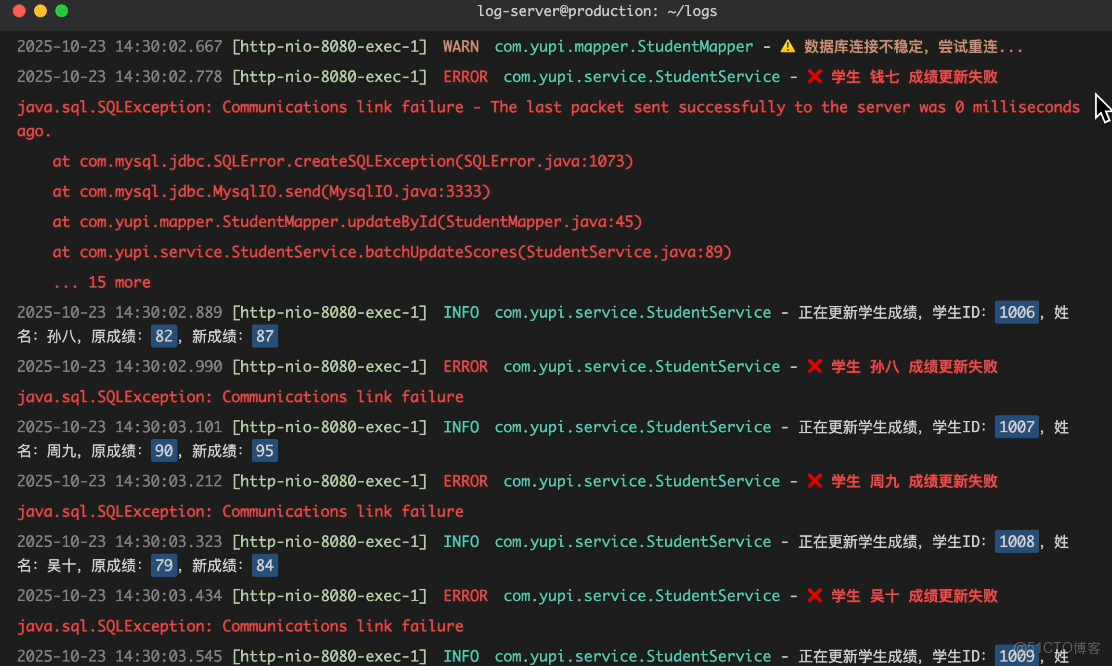
你急壞了:咋辦,這樣就不公平了啊!
魚皮看了看你的代碼:這是典型的數據一致性問題,你需要用 事務 來解決。
你:啥是事務?
魚皮:事務就是把多個操作捆綁在一起,要麼全部成功,要麼全部失敗。

就像你給別人投幣,你扣除硬幣和對方增加硬幣必須同時成功,不能讓硬幣憑空消失對吧?
你:對對對,那批量改成績也是,要麼所有學生都加 5 分,要麼都不加。
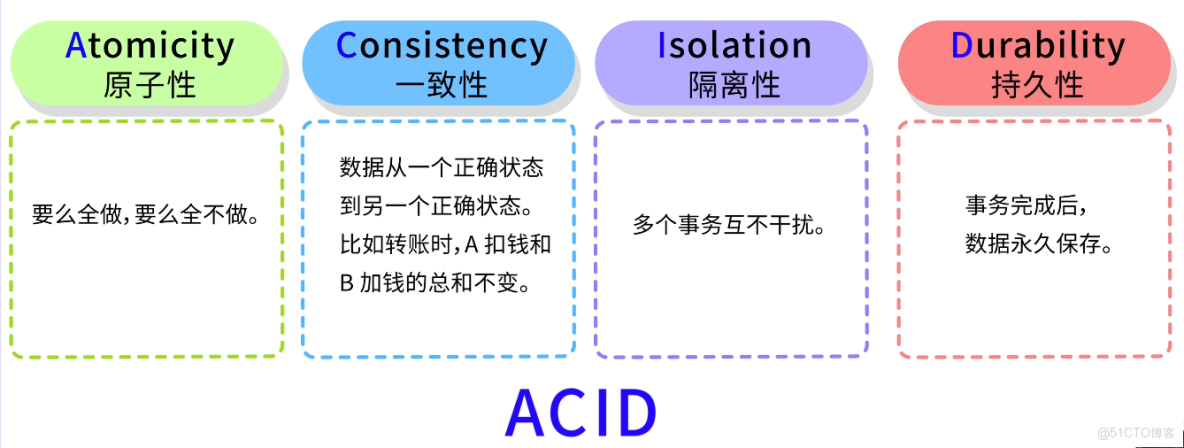
魚皮:沒錯,數據庫事務有 4 個特性,簡稱 ACID:
- 原子性(Atomicity):要麼全做,要麼全不做。
- 一致性(Consistency):數據從一個正確狀態到另一個正確狀態。比如轉賬時,A 扣錢和 B 加錢的總和不變。
- 隔離性(Isolation):多個事務互不干擾。
- 持久性(Durability):事務完成後,數據永久保存。
你:那怎麼使用事務呢?
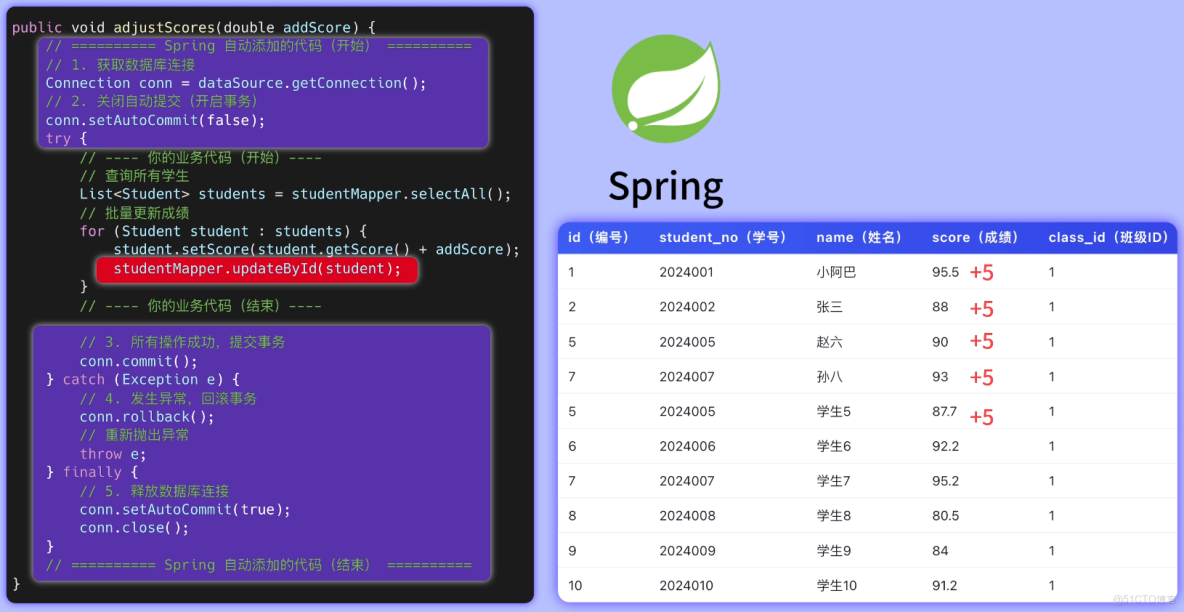
魚皮:如果直接用原始的 JDBC,需要手動控制事務,比較麻煩。
但如果在 Spring 框架中,只需要加一個 @Transactional 註解就搞定了:

Spring 會自動幫你管理事務。如果中間任何一步出錯,拋出了指定的異常,整個事務會自動回滾,將數據恢復到原來的狀態,保證要麼所有學生都加分成功,要麼都不加。
你:原來這麼簡單啊,我這就用事務重寫代碼!
其他
魚皮:MySQL 還有一些其他特性,比如視圖可以用來簡化複雜查詢、存儲過程可以批量執行 SQL、觸發器可以自動觸發操作。
1)視圖:視圖是一個虛擬表,把複雜查詢封裝起來重複使用。比如你經常要統計每個班級的平均成績,每次都寫一長串 SQL 太麻煩,可以創建一個視圖,以後直接查視圖就行。
2)存儲過程:可以批量執行 SQL。比如每天定時同步數據,寫個存儲過程,定時調用就行。
3)觸發器:可以自動觸發操作。比如每次添加用户,自動生成一條操作日誌,不用手動寫代碼。

你感嘆道:原來數據庫還有這麼多功能,我學不完了啊……
魚皮笑了:別擔心,這些在實際開發中用得不多,先簡單瞭解就好。
第四階段:生產環境實踐
幾年後,你已經成為小有名氣的 “學生管理系統大師”,還成立了自己的工作室。
沒事兒就對着新來的實習生阿坤吹牛皮:你阿巴哥我啊,精通數據庫,索引、事務耍的賊溜兒~

然而某天上午,學校的運維同學打來電話:阿巴阿巴,系統出問題了,所有操作都一直 轉圈、超時! 好像是數據庫卡死了!
你大驚:什麼?!我都加索引了,還能卡死?

emmm…… 對了,我想到了!
趕緊重啓數據庫,重啓解決所有問題!嘿嘿嘿哈哈哈哈~

結果重啓沒多久,數據庫又卡死了!
你徹底懵了:嗚嗚嗚,怎麼辦啊!
這時,你身旁的阿坤突然雞叫起來:我來!
為什麼系統會崩潰?
阿坤:我們先看看為什麼系統會崩潰?
開啓 MySQL 的慢查詢日誌功能,有兩種方式。
1)通過 SQL 命令(臨時開啓)
# 開啓慢查詢日誌功能
SET GLOBAL slow_query_log = 1;
# 設置慢查詢閾值(超過幾秒算是慢查詢)
SET GLOBAL long_query_time = 5;
# 修改日誌文件位置(可選)
SET GLOBAL slow_query_log_file = '/path/to/slow.log';2)修改配置文件(永久生效)
# 在 [mysqld] 部分設置參數
slow_query_log = 1
long_query_time = 5
slow_query_log_file = /path/to/slow.log你看,有些 SQL 語句執行了幾十秒!
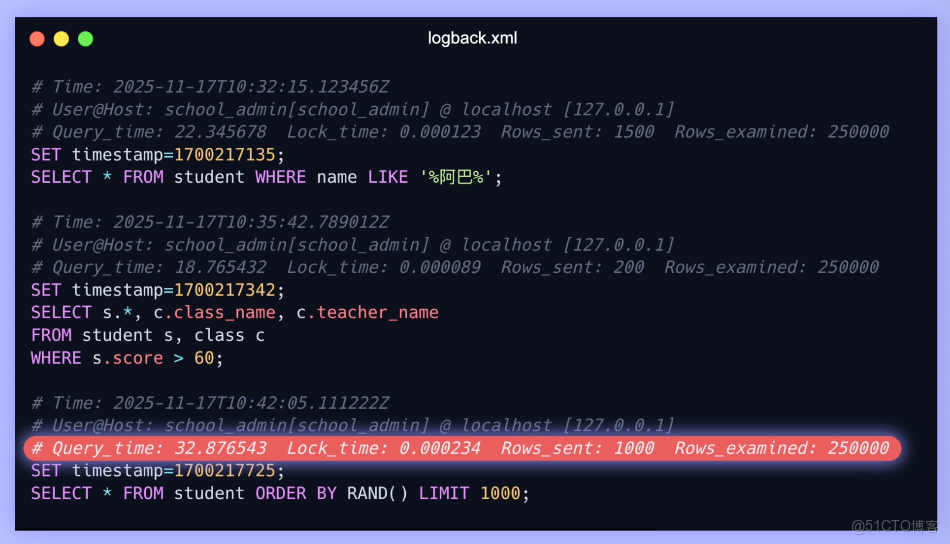
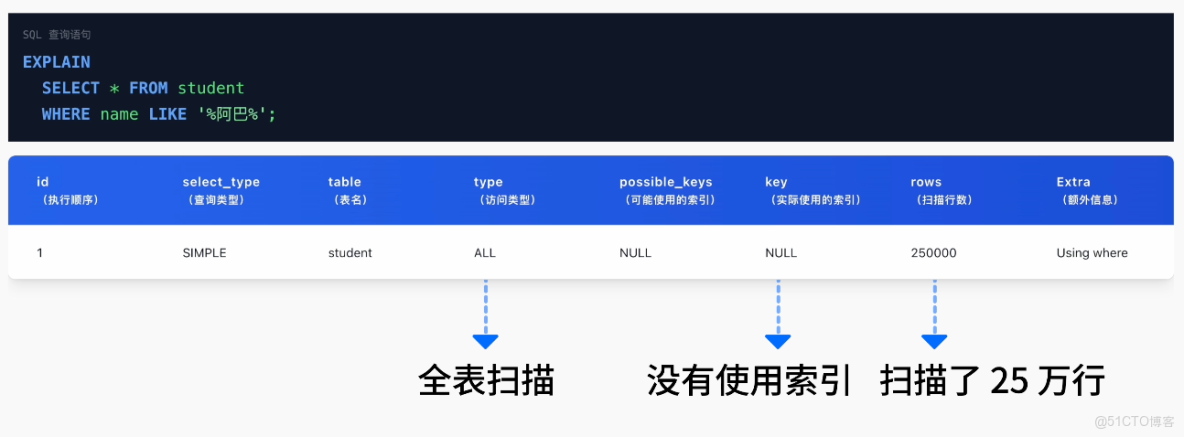
使用 Explain 命令分析下這些查詢,原來沒有正確使用索引,導致了全表掃描,把數據庫拖垮了。
這些慢查詢就是罪魁禍首,它們會 長時間霸佔數據庫連接和 CPU 資源。當大量用户同時執行慢查詢,數據庫連接池很快被耗盡,新的請求因為無法獲取連接、全部阻塞,導致數據庫 “卡死”。
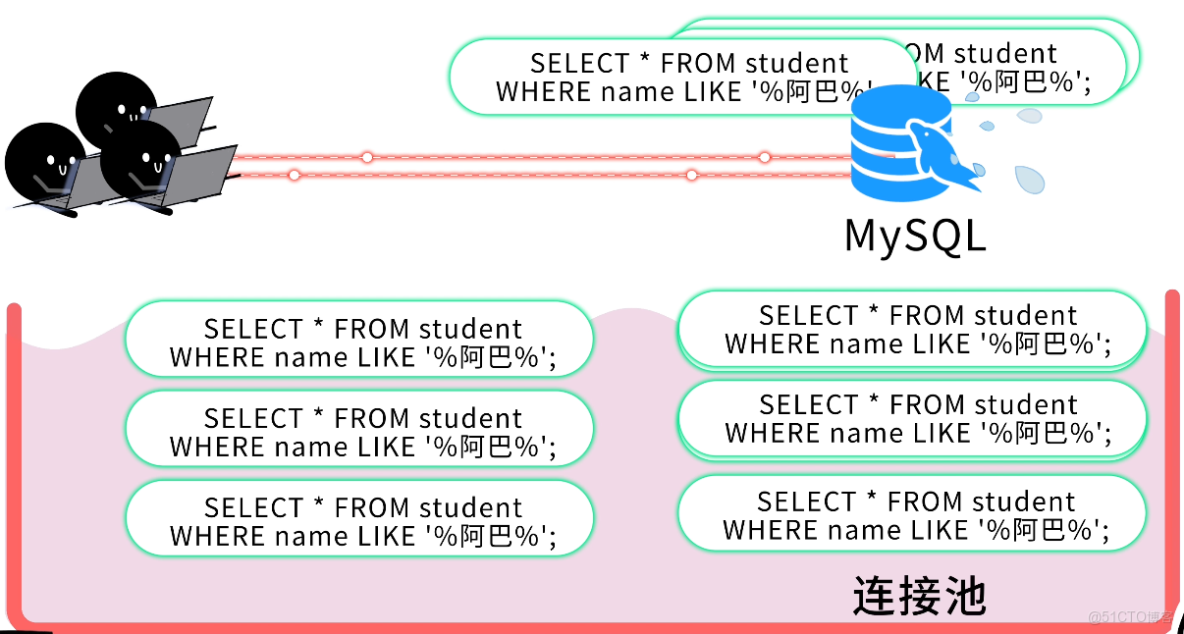
你慚愧地低下頭:我知道了,生產環境一定要開啓慢查詢日誌,及時發現慢 SQL 並優化。
數據丟失了怎麼辦?
屋漏偏逢連夜雨,你很快又收到了投訴,説是有的學生數據丟失了!
你很是疑惑:MySQL 不是有日誌(Redo Log 和 Binlog)來保證數據持久性嗎?怎麼會丟數據呢?
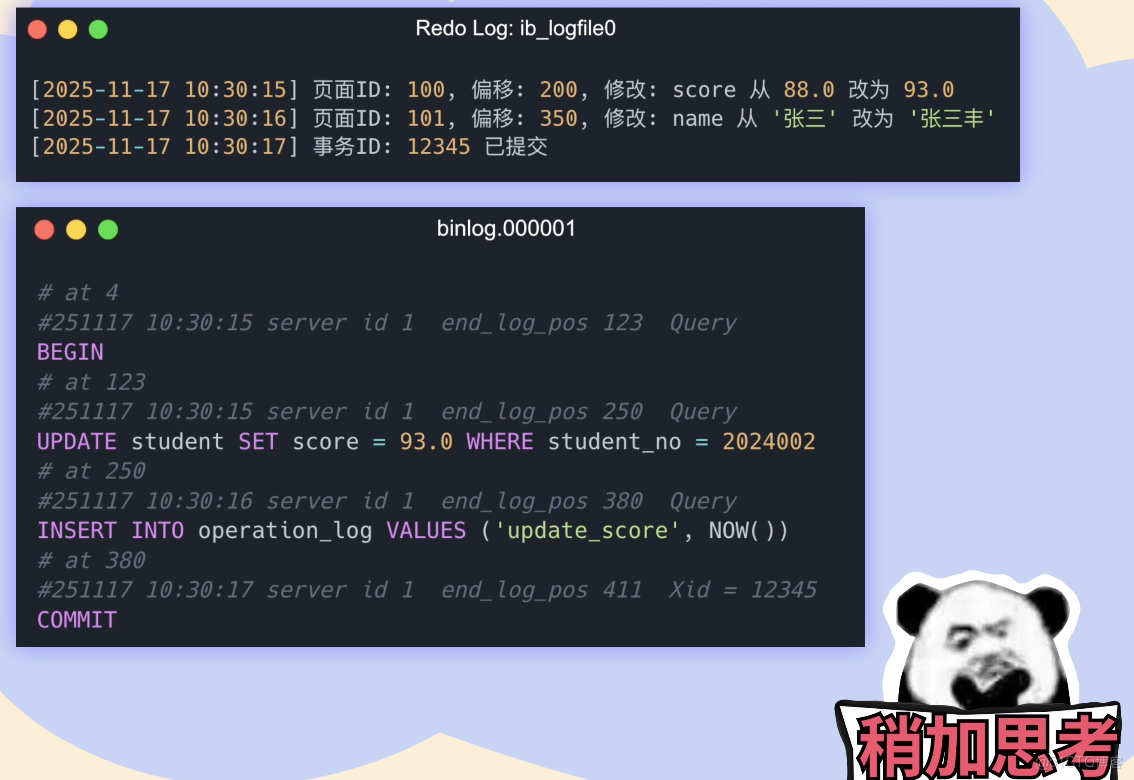
經過排查,原來是服務器的硬盤被一個學生不小心踹壞了!
你難受得像持矢了一樣:真是人在家中坐,Bug 天上來。

唉,我怎麼把數據找回來啊?
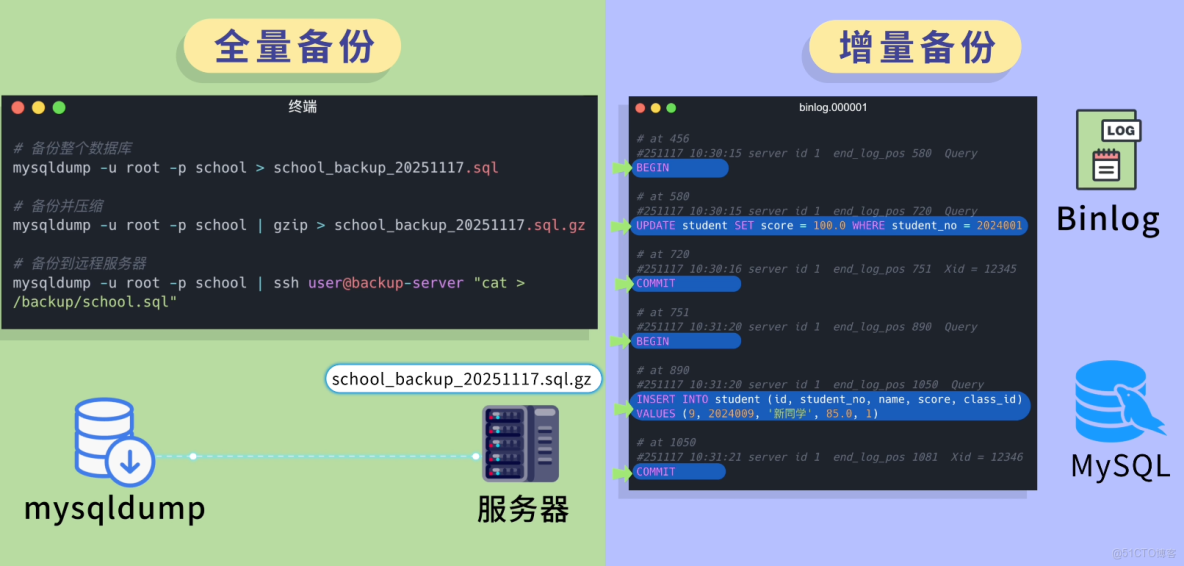
阿坤:別怕,幸好魚皮哥之前設置了備份。一方面定期做 全量備份,比如利用 mysqldump 工具每天凌晨備份一次併發送到其他服務器上;再配合 增量備份,利用 Binlog(二進制日誌)記錄每次的數據修改操作,這樣即使數據庫崩了,也能恢復到最近的狀態。
怎麼保證系統不會再崩?
你鬆了一口氣:那怎麼保證數據庫不會再宕機呢?
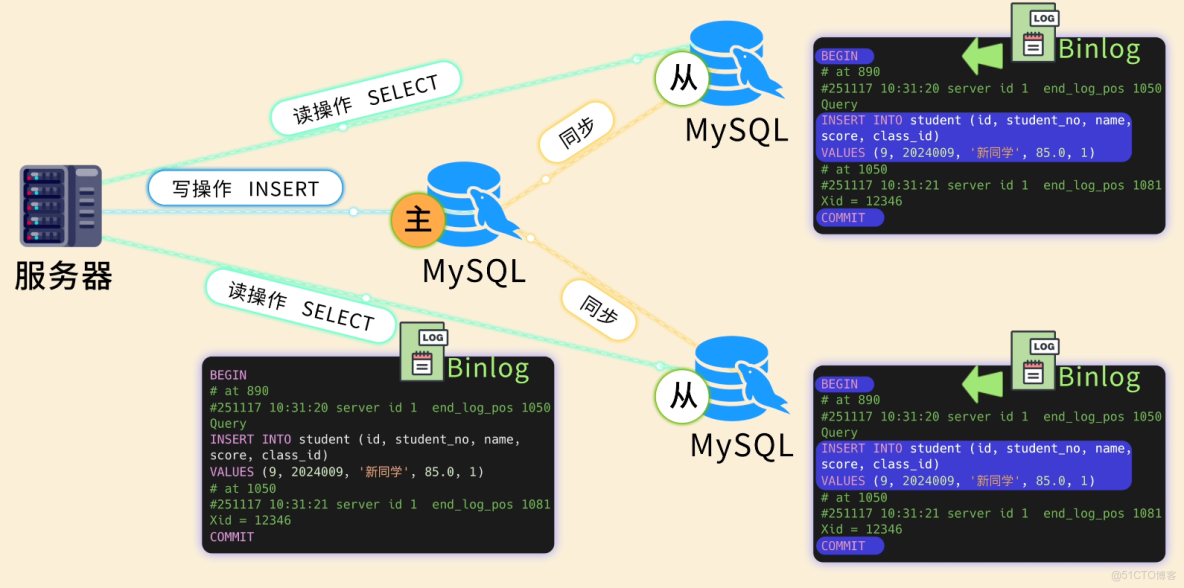
阿坤:可以搭建 MySQL 高可用集羣,典型的是 一主多從 架構。
主庫(Master)專門負責寫操作(增刪改),並通過 Binlog 記錄每一次數據變更操作。
從庫(Slave) 拉取主庫的 Binlog 到本地文件中,然後回放數據變更操作,實現數據同步。我們可以利用從庫來承擔絕大部分的讀操作,這叫 讀寫分離,能大大提升併發能力。
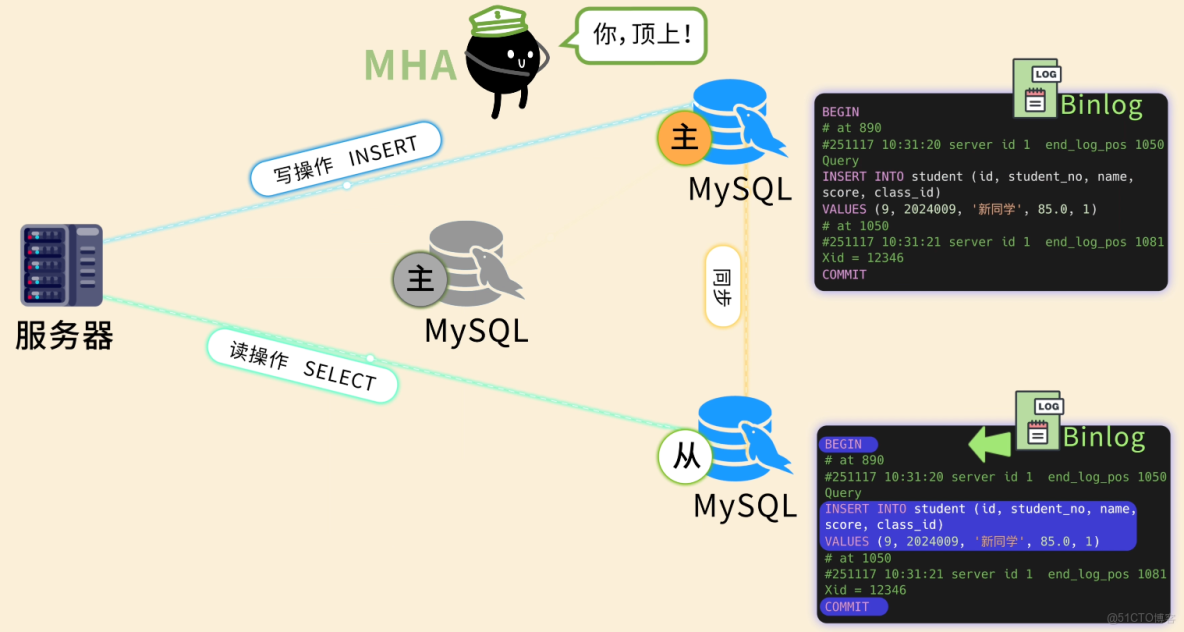
當主庫出現故障時,利用 MHA 等工具,自動將一個從庫提升為新的主庫,並調整其他從庫的指向,實現故障的自動切換。
數據量大了怎麼辦?
你很是驚訝:之前完全沒聽説過這些啊……
阿坤用看流浪狗的眼神看了你一眼:阿巴哥哥,如果數據量特別大,一個庫存不下怎麼辦?
你啞口無言:阿巴阿巴……
阿坤笑了:當然是 分庫分表 啦!比如
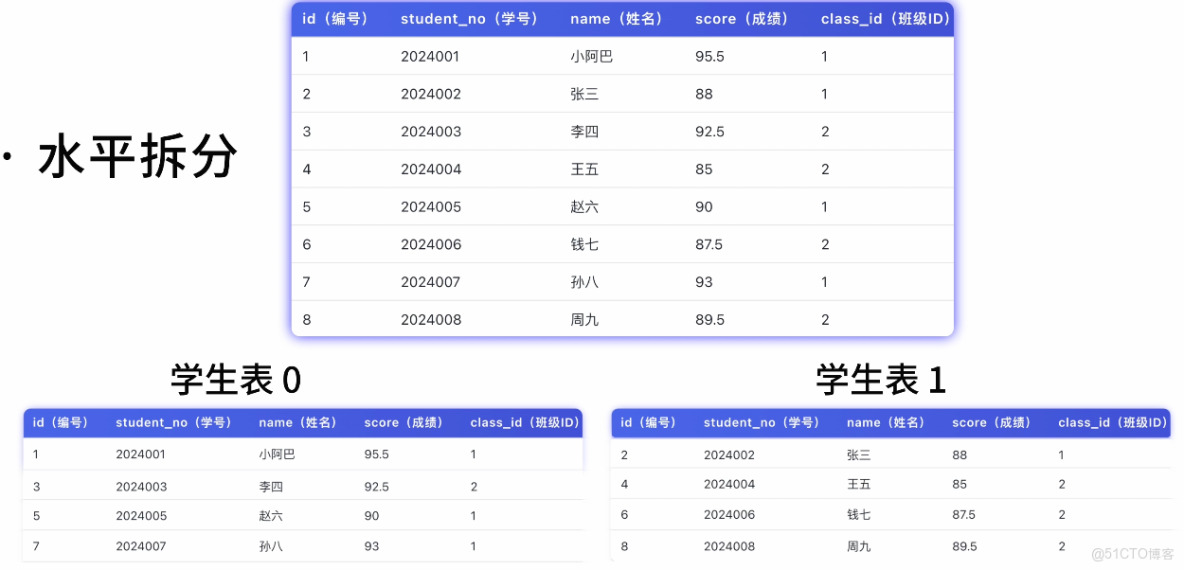
1)水平拆分:把同一張表的數據分散到多個表或多個庫中。比如根據學生 ID 的尾號,奇數的存到表 1,偶數的存到表 2。
2)垂直拆分:按業務功能來拆分庫,比如把學生基本信息、成績信息、選課信息分別存到不同的庫中。
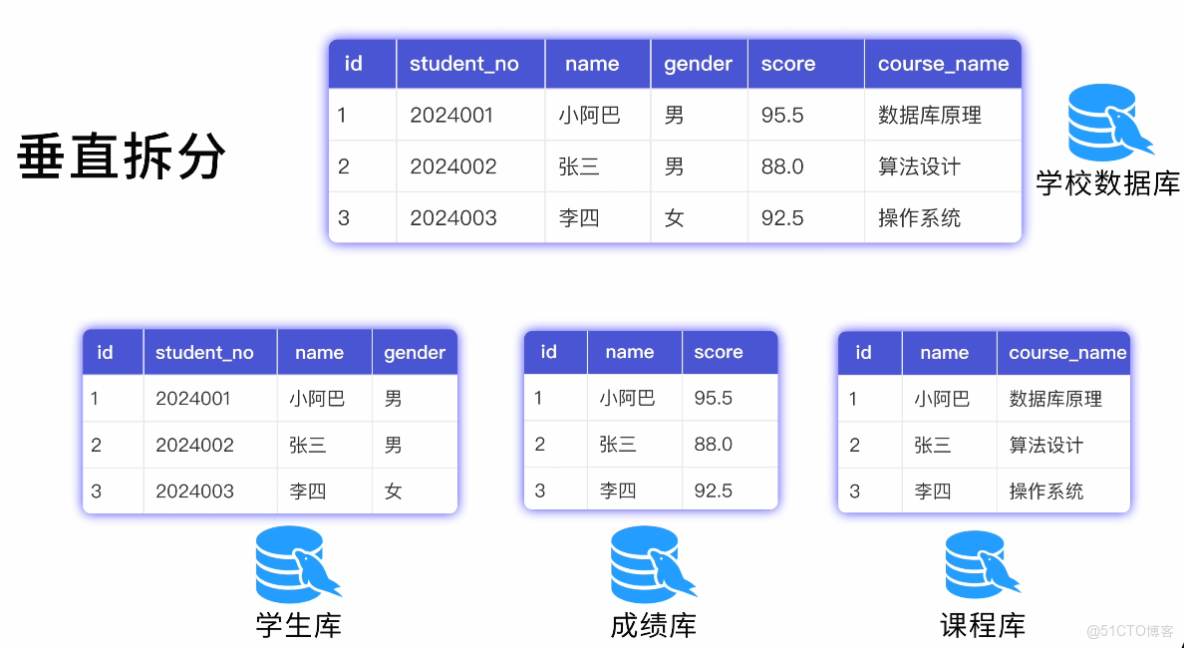
你徹底服了:妙啊,這樣就能存儲海量數據了!
其他實踐
這時魚皮走過來拍了拍阿坤的肩膀:小夥子年輕有為啊!
小阿巴,MySQL 生產環境實踐的知識點還有很多。比如:
1)權限管理:不要所有人都用 root 賬號,風險太大,要給不同的人分配不同的權限。
2)雲數據庫服務:提供了現成的 MySQL 集羣架構、監控系統、自動備份、數據遷移等,比自己運維省心多了。
3)調優技巧:硬件優化、數據庫配置優化、庫表設計優化、SQL 優化、連接池優化等等。
4)常見問題:還有死鎖排查、大表的在線變更、數據遷移、主從延遲處理等等,遇到了再去解決。
你羞愧地抬不起頭:我以為自己已經掌握了數據庫,原來只是學了個皮毛……

第五階段:深入底層原理
於是,你主動找到阿坤:我想深入學習 MySQL,不能只停留在會用的層面,請問怎麼學習底層原理啊?
阿坤有些驚訝:咦?你不 背八股文 的麼?刷刷題就好了呀!
你震驚了:現在的實習生,竟然恐怖如斯!
魚皮:阿坤你別逗他了,其實我們可以帶着問題學習。比如 MySQL 是如何實現高效查詢的 ?
你想了想:加索引?
魚皮:對,但這只是使用層面。底層實現有很多技術,比如高效的存儲引擎(InnoDB)、優秀的索引結構(B+ 樹)、緩衝池機制、查詢優化器等等。
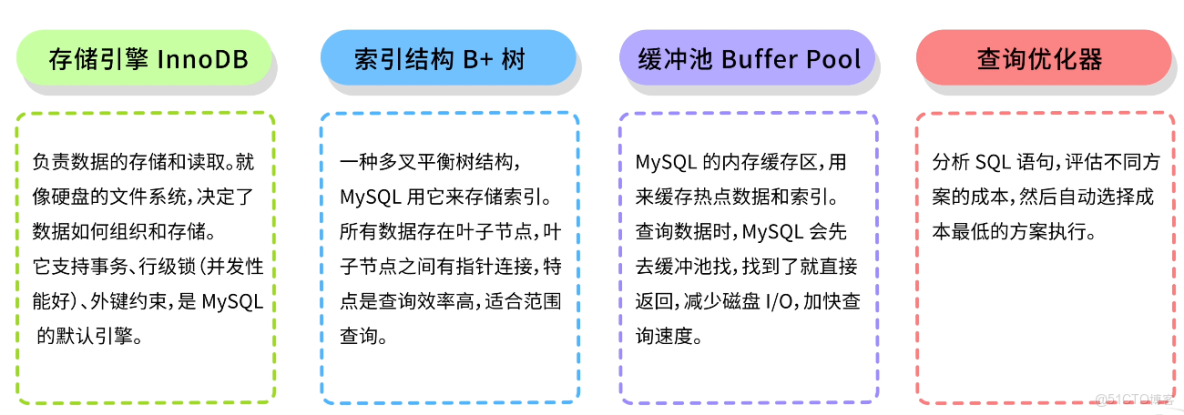
比如我考考你,下面兩個 SQL 語句哪個執行更快?
# SQL 1: 使用 OR
SELECT * FROM student WHERE class_id = 1 OR class_id = 2;
# SQL 2: 使用 IN
SELECT * FROM student WHERE class_id IN (1, 2);你:額…… 第 2 個?因為它更簡短。
魚皮:哼哼,答案是 幾乎一樣快!因為 MySQL 的查詢優化器非常智能,它會分析語句、將它們處理成相同的邏輯結構,再去執行。
這就是 MySQL 能高效查詢的原因之一,帶着這些問題去閲讀相關文章,或者直接像阿坤説的刷一刷 MySQL 面試題,就能快速學會很多核心知識點。

如果想系統學習,可以看看《MySQL 是怎樣運行的》、《高性能 MySQL》這幾本書。

要記住,學習底層原理不只是為了應付面試,而是為了更好地使用 MySQL,遇到問題時能夠快速定位和解決。
你:好的,我這就去學!
結尾
若干年後,你已經成為了大廠的數據庫專家。不僅能熟練設計庫表、優化性能,搭個 MySQL 集羣也是手拿把掐的。

你也像魚皮當時一樣,耐心地給新人分享學習數據庫的經驗:數據庫是實戰型技術,一定要多動手實踐。

再次遇到魚皮是在一條昏暗的小巷,此時的他年過 35,灰頭土臉。你什麼都沒説,只是給他點了個贊,投了 2 個幣,不打擾,是你的温柔。

更詳細的 MySQL 數據庫學習路線,可以在編程導航免費閲讀哦。
更多
💻 編程學習交流:編程導航 📃 簡歷快速製作:老魚簡歷 ✏️ 面試刷題神器:面試鴨