
坦白講,每次看性能測試排行榜,我都會下意識地先找找 Apache Doris 在哪個位置。
這次打開 JSONBench 的榜單,心情一如既往的期待加緊張。
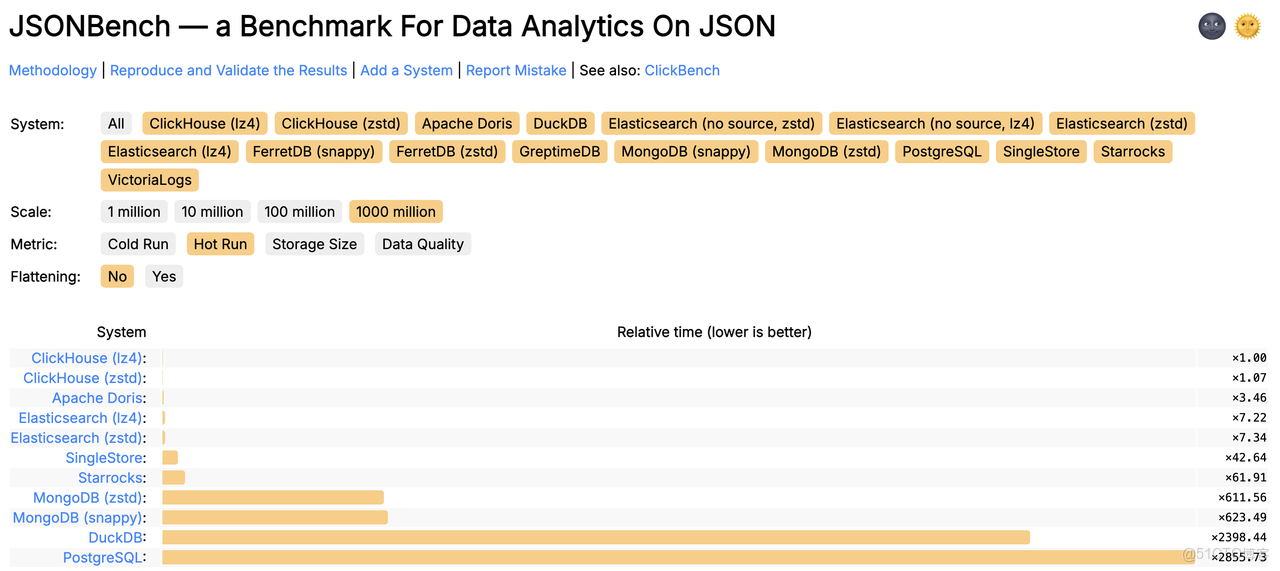
好在結果讓我鬆了一口氣:默認配置下就能排到第三,僅次於維護方 ClickHouse 的兩個版本。
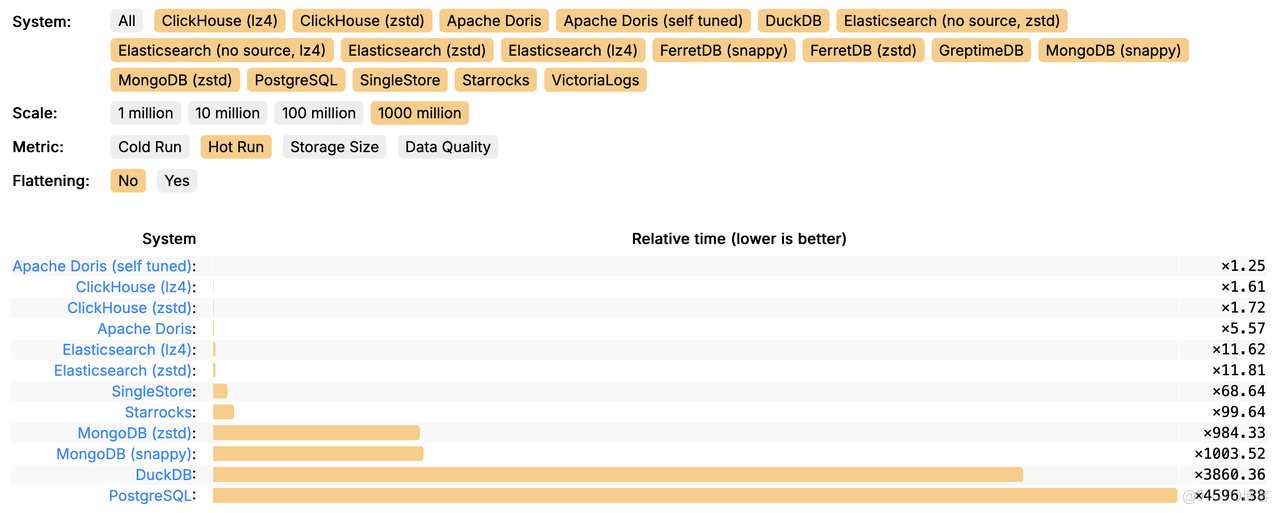
不過,Doris 只能止步於此了嗎?經過一系列優化後,查詢時長能不能再縮短點?和 ClickHouse 的差距在哪裏?
調優前後對比圖鎮樓,至於調優的具體思路,請一起往下看吧。
-
Apache Doris 排名 (Default)
-
Apache Doris 排名 (Unofficial Tuned)
JSONBench 簡介
JSONBench 是一個為 JSON 數據而生的數據分析 Benchmark,簡單來説,它由 10 億條來自真實生產環境的 JSON 數據、5 個針對 JSON 構造的特定 SQL 查詢組成,旨在對比各個數據庫系統對半結構化數據的處理能力。目前榜單包括 ClickHouse、MongoDB、Elasticsearch、DuckDB、PostgreSQL 等知名數據庫系統,截至目前,Doris 的性能表現是 Elasticsearch 的 2 倍,是 PostgreSQL 的 80 倍。
JSONBench 官網地址:jsonbench.com
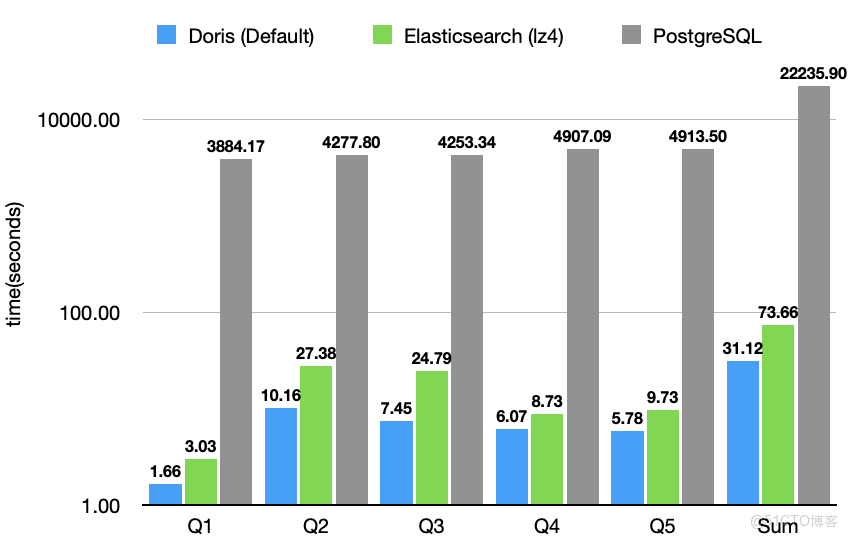
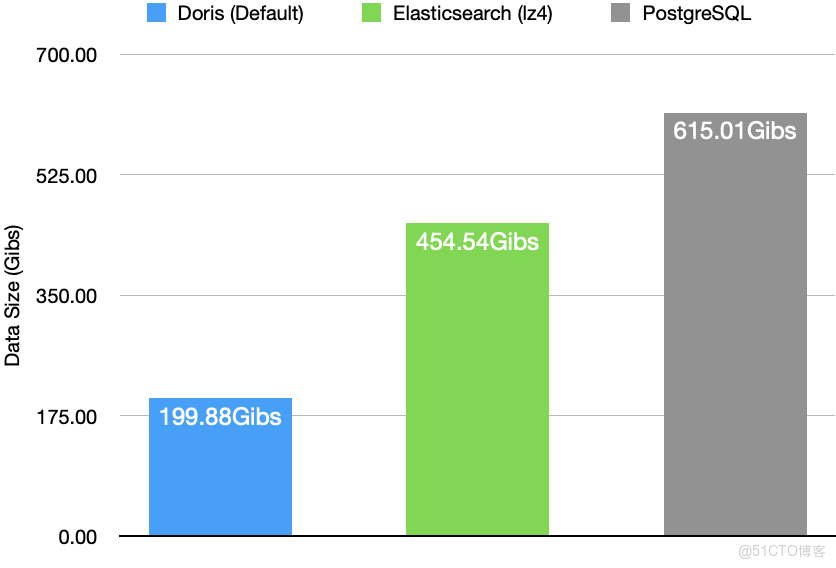
不僅在性能上 Apache Doris 領先其他同類產品,在數據集相同的情況下,Apache Doris 的存儲佔用是 Elasticsearch 的 1/2、PostgreSQL 的 1/3。
JSONBench 測試具體流程:首先在數據庫中創建一張名為 Bluesky 的表,並導入十億條真實的用户行為日誌數據。測試過程中,每個查詢重複執行三次,並且在每次查詢前清空操作系統的 Page Cache,以模擬冷熱查詢的不同場景。最終,通過綜合計算各查詢的執行耗時得出數據庫的性能排名。
在這個測試中,Apache Doris 使用了 Variant 數據類型來存儲 JSON 數據,默認的建表 Schema 如下:
CREATE TABLE bluesky (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`data` variant NOT NULL
)
DISTRIBUTED BY HASH(id) BUCKETS 32
PROPERTIES ("replication_num"="1");
Variant 是 Apache Doris 2.1 中引入一種新的數據類型 ,它可以存儲半結構化 JSON 數據,並且允許存儲包含不同數據類型(如整數、字符串、布爾值等)的複雜數據結構,而無需在表結構中提前定義具體的列。Variant 類型特別適用於處理複雜的嵌套結構,而這些結構可能隨時會發生變化。在寫入過程中,該類型可以自動根據列的結構、類型推斷列信息,動態合併寫入的 schema,並通過將 JSON 鍵及其對應的值存儲為列和動態子列。
- Apache Doris Variant 類型詳情
調優思路與原理
JSONBench 榜單排名依據各個數據庫系統在默認配置下的性能數據,那麼能否通過調優,讓 Apache Doris 進一步釋放性能潛力,實現更好的性能效果呢?
01 環境説明
- 測試機器:AWS M6i.8xlarge(32C128G);
- 操作系統:Ubuntu24.04;
- Apache Doris: 3.0.5;
02 Schema 結構化處理
由於 JSONBench 特定查詢中涉及到的 JSON 數據都是固定的提取路徑,換言之,半結構化數據的 Schema 是固定的,因此,我們可以藉助生成列,將常用的字段提取出來,實現半結構化數據和結構化數據結合的效果。類似的高頻訪問的 JSON 路徑或者需要計算的表達式,都可以使用該優化思路,添加對應的生成列來實現查詢加速。
- 查看 JSONBench 查詢
- Apache Doris 生成列詳情
CREATE TABLE bluesky (
kind VARCHAR(100) GENERATED ALWAYS AS (get_json_string(data, '$.kind')) NOT NULL,
operation VARCHAR(100) GENERATED ALWAYS AS (get_json_string(data, '$.commit.operation')) NULL,
collection VARCHAR(100) GENERATED ALWAYS AS (get_json_string(data, '$.commit.collection')) NULL,
did VARCHAR(100) GENERATED ALWAYS AS (get_json_string(data,'$.did')) NOT NULL,
time DATETIME GENERATED ALWAYS AS (from_microsecond(get_json_bigint(data, '$.time_us'))) NOT NULL,
`data` variant NOT NULL
)
DUPLICATE KEY (kind, operation, collection)
DISTRIBUTED BY HASH(collection, did) BUCKETS 32
PROPERTIES ("replication_num"="1");
除了可以減少查詢時提取數據的開銷,還可以用展平出來的列作為分區列,使得數據分佈更均衡。
需要注意的是,查詢的 SQL 語句也要改為使用展平列的版本:
// JSONBench 原始查詢:
SELECT cast(data['commit']['collection'] AS TEXT ) AS event, COUNT(*) AS count FROM bluesky GROUP BY event ORDER BY count DESC;
SELECT cast(data['commit']['collection'] AS TEXT ) AS event, COUNT(*) AS count, COUNT(DISTINCT cast(data['did'] AS TEXT )) AS users FROM bluesky WHERE cast(data['kind'] AS TEXT ) = 'commit' AND cast(data['commit']['operation'] AS TEXT ) = 'create' GROUP BY event ORDER BY count DESC;
SELECT cast(data['commit']['collection'] AS TEXT ) AS event, HOUR(from_microsecond(CAST(data['time_us'] AS BIGINT))) AS hour_of_day, COUNT(*) AS count FROM bluesky WHERE cast(data['kind'] AS TEXT ) = 'commit' AND cast(data['commit']['operation'] AS TEXT ) = 'create' AND cast(data['commit']['collection'] AS TEXT ) IN ('app.bsky.feed.post', 'app.bsky.feed.repost', 'app.bsky.feed.like') GROUP BY event, hour_of_day ORDER BY hour_of_day, event;
SELECT cast(data['did'] AS TEXT ) AS user_id, MIN(from_microsecond(CAST(data['time_us'] AS BIGINT))) AS first_post_ts FROM bluesky WHERE cast(data['kind'] AS TEXT ) = 'commit' AND cast(data['commit']['operation'] AS TEXT ) = 'create' AND cast(data['commit']['collection'] AS TEXT ) = 'app.bsky.feed.post' GROUP BY user_id ORDER BY first_post_ts ASC LIMIT 3;
SELECT cast(data['did'] AS TEXT ) AS user_id, MILLISECONDS_DIFF(MAX(from_microsecond(CAST(data['time_us'] AS BIGINT))),MIN(from_microsecond(CAST(data['time_us'] AS BIGINT)))) AS activity_span FROM bluesky WHERE cast(data['kind'] AS TEXT ) = 'commit' AND cast(data['commit']['operation'] AS TEXT ) = 'create' AND cast(data['commit']['collection'] AS TEXT ) = 'app.bsky.feed.post' GROUP BY user_id ORDER BY activity_span DESC LIMIT 3;
// 使用展平列改寫的查詢:
SELECT collection AS event, COUNT(*) AS count FROM bluesky GROUP BY event ORDER BY count DESC;
SELECT collection AS event, COUNT(*) AS count, COUNT(DISTINCT did) AS users FROM bluesky WHERE kind = 'commit' AND operation = 'create' GROUP BY event ORDER BY count DESC;
SELECT collection AS event, HOUR(time) AS hour_of_day, COUNT(*) AS count FROM bluesky WHERE kind = 'commit' AND operation = 'create' AND collection IN ('app.bsky.feed.post', 'app.bsky.feed.repost', 'app.bsky.feed.like') GROUP BY event, hour_of_day ORDER BY hour_of_day, event;
SELECT did AS user_id, MIN(time) AS first_post_ts FROM bluesky WHERE kind = 'commit' AND operation = 'create' AND collection = 'app.bsky.feed.post' GROUP BY user_id ORDER BY first_post_ts ASC LIMIT 3;
SELECT did AS user_id, MILLISECONDS_DIFF(MAX(time),MIN(time)) AS activity_span FROM bluesky WHERE kind = 'commit' AND operation = 'create' AND collection = 'app.bsky.feed.post' GROUP BY user_id ORDER BY activity_span DESC LIMIT 3;
03 Page Cache 調整
調整查詢語句後,開啓 profile,執行完整的查詢測試:
set enable_profile=true;
進入 FE 8030 端口的 Web 頁面,找到相關 profile 進行分析,此時發現 SCAN Operator 中的 Page Cache 命中率較低,導致熱讀測試過程中存在一部分冷讀操作。
- CachedPagesNum: 1.258K (1258)
- TotalPagesNum: 7.422K (7422)
這種情況通常是由於 Page Cache 容量不足,無法完整緩存 Bluesky 表中的數據。建議在 be.conf 中添加配置項 storage_page_cache_limit=60%,將 Page Cache 的大小從默認的內存總量的 20% 提升至 60%。重新運行測試後,可以觀察到冷讀問題已得到解決。
- CachedPagesNum: 7.316K (7316)
- TotalPagesNum: 7.316K (7316)
04 最大化並行度
為了進一步挖掘 Doris 的性能潛力,可以將 Session 變量中的parallel_pipeline_task_num設為 32,因為本次 Benchmark 測試機器m6i.8xlarge為 32 核,所以我們將並行度設置為 32 以最大程度發揮 CPU 的計算能力。
// 單個 Fragment 的並行度
set global parallel_pipeline_task_num=32;
調優結果
經過上述對 Schema、Query、內存限制、CPU 等參數的調整,我們對比了調優前後 Doris 的性能表現以及一些其他數據庫系統的成績,有如下結果:
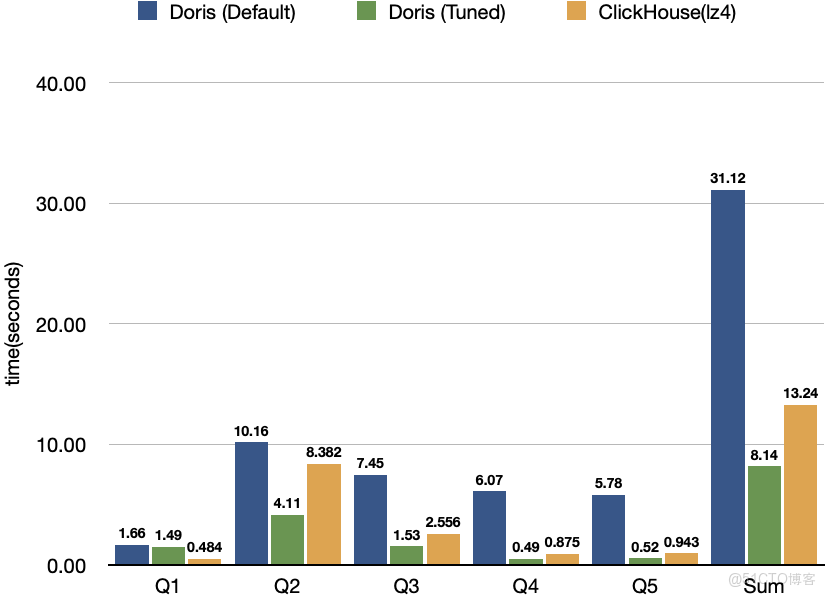
可以看到,對比調優前的 Doris,調優後 Doris 查詢整體耗時降低了 74%,對比原榜單第一的 ClickHouse 產品實現了 39% 的領先優勢。
總結與展望
通過對 Schema 的結構化處理、查詢語句的優化、緩存配置的調整以及並行參數的設置,Apache Doris 整體查詢耗時顯著下降,並超越 ClickHouse。
在默認設置下,Doris 在 10 億條 JSON 的查詢耗時與 ClickHouse 仍有數秒的差異。然而,依託於 Doris 在 JSON 處理、Variant 類型支持及生成列等能力的加持,經調優後,其半結構化數據處理性能獲得了進一步顯著提升,並在同類數據庫中表現出明顯的領先優勢。
未來,Apache Doris 將繼續打磨在半結構化領域的數據處理能力,為用户帶來更加優質、高效的分析體驗,包括:
- 優化 Variant 類型稀疏列的存儲空間,支持萬列以上的子列;
- 優化萬列大寬表的內存佔用;
- 支持 Variant 子列根據列名的 Pattern 自定義類型、索引等。
推薦閲讀
-
Apache Doris 針對半結構化數據分析的解決方案及典型場景
-
揭秘 Variant 數據類型:靈活應對半結構化數據,JSON 查詢提速超 8 倍,存儲空間節省 65%
