
摘要
本文基於 ClickBench 數據集,展示了 Apache Doris 如何通過選擇壓縮算法、調整數據頁大小與分桶數、優化編碼策略以及改進數據排序來提升壓縮效率。最終,相同數據集的壓縮空間從 16.08 GB 降至 8.2 GB,壓縮率提升 48.6%。通過合理的調整與優化,Doris 成功在保持查詢性能的同時顯著降低了存儲成本。
在分析型數據庫中,列式存儲是壓縮和查詢性能的核心基礎。它按列組織數據,同一列值類型一致且分佈相似,為編碼與壓縮算法提供極高空間局部性和可預測性。當存儲的值變化較小或重複頻繁時,列式佈局能夠減少冗餘存儲,並提升向量化掃描的 CPU 效率。
Apache Doris 作為一款典型的列式存儲引擎,可獨立存儲每一列數據。導入時,每列數據寫入近似固定大小的數據頁,經過編碼和壓縮處理,以實現更緊湊的存儲。在 Doris 中,數據的壓縮和解壓均以數據頁為單位,壓縮算法的上下文限制在單個數據頁內。因此,數據頁大小、編碼方式及壓縮算法都直接影響最終的壓縮效率和查詢性能。
在接下來的章節中,我們將結合基於 ClickBench 數據集,較為直觀的展示 Apache Doris 在存儲壓縮方面的優化思考及改進策略。 使讀者瞭解如何通過數據頁大小與分桶數調整、編碼策略優化、數據排序來提升壓縮效率。
一、數據集與基線結果
我們使用 ClickBench 公共數據集來進行本次測試。該數據集包含 10 個 tsv 文件,總大小約 70GB,包括網站訪問日誌類字段,如 URL、Referer、UserID 等。這類數據通常混合了短字符串與整數列,結構化特徵明顯。
在導入前先對原始數據進行文件級壓縮測試,以作為基線參考:
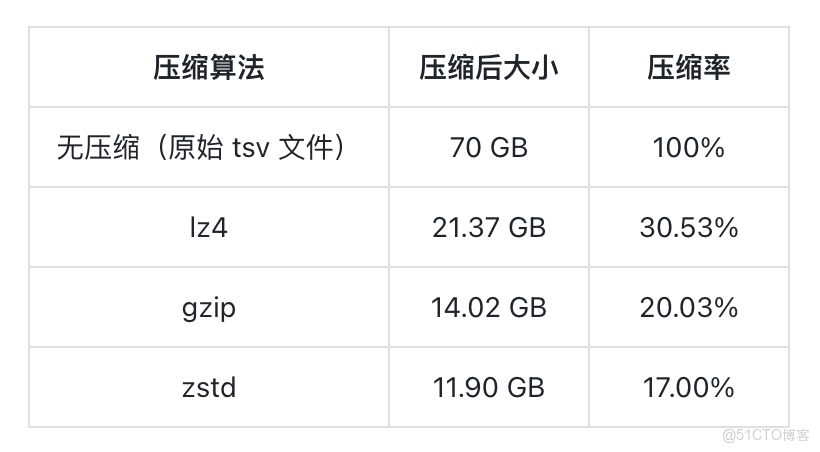
隨後將這批數據直接導入 Doris。使用默認建表參數,建表語句可參考:https://github.com/apache/doris/blob/master/tools/clickbench-tools/sql/create-clickbench-table.sql
數據導入後,整體存儲空間約為 16.08 GB。在 Doris 的列式存儲下,經過默認 LZ4 壓縮,已實現相較於原始文件(21.37 GB)1.33x 倍的壓縮效果。但如果從一個以高壓縮比著稱的列式系統角度來看,這一結果仍存在進一步的優化空間。
接下來從研發角度出發,依次對壓縮算法、數據頁參數與編碼方式、數據排序及特徵等層面介紹優化及改進思路。
二、選擇合適的壓縮算法
Doris 默認使用 LZ4 壓縮算法,因其解壓速度快且 CPU 佔用均衡,適合大多數查詢型負載。而在重複性強或結構化明顯的數據場景中,LZ4 的壓縮比較低。相較之下,ZSTD 提供更高的壓縮率,但會增加壓縮和解壓的 CPU 消耗。在使用時,可根據實際情況靈活選擇。
考慮到測試數據集中大量字符串字段存在相似前綴與重複片段的特徵,我們將默認的 LZ4 壓縮算法調整為 ZSTD,這可以通過在建表語句中設置表屬性實現:
CREATE TABLE IF NOT EXISTS hits (
....
)
DUPLICATE KEY (CounterID, EventDate, UserID, EventTime, WatchID)
DISTRIBUTED BY HASH(UserID) BUCKETS 48
PROPERTIES (
"replication_num"="1",
"compression"="ZSTD");
經過該調整,表空間降至 12.9GB,相比 LZ4 減少了近 20%。雖然在導入階段 CPU 開銷略有上升,但查詢性能幾乎不受影響,表明 ZSTD 對典型分析型查詢的解壓成本是可接受的。
三、調整數據頁大小與分桶數
在 Doris 的列式存儲中,數據壓縮的基本單位是數據頁。每個數據頁在寫入之前經過編碼與壓縮,頁內數據的相似程度直接影響通用壓縮算法的效果。數據頁的大小選擇影響壓縮效率與查詢性能的平衡:過小的頁無法形成可識別的模式,而過大的頁會增加讀取開銷和內存負擔。
Doris 默認數據頁大小為 64KB,適合大部分場景。然而,對於具有明顯模式或高重複率的數據集,過小的頁會使數據被切得太碎,通用壓縮算法的效率會變差。因此,適當增大頁的大小可顯著提升壓縮效果。更大的頁可覆蓋更多連續數據,聚集相似值於同一壓縮上下文內,讓壓縮算法更充分地挖掘重複模式與統計特徵。
對於測試數據集來説,我們選擇將頁大小從默認的 64KB 調整為 1MB,並同時將分桶數從 48 減少到 4。分桶數越多,每個桶的數據越少,頁內數據的相似性降低,壓縮率就會下降。通過讓數據集中到更少的桶中,可以提高頁內數據的相似性,從而帶來更好的壓縮效果。
CREATE TABLE IF NOT EXISTS hits (
....
) DUPLICATE KEY (CounterID, EventDate, UserID, EventTime, WatchID)
DISTRIBUTED BY HASH(UserID) BUCKETS 4
PROPERTIES (
"replication_num"="1",
"compression"="ZSTD",
"storage_page_size"="1048576");
經過測試,存儲空間進一步減小到 10.71 GB。頁更大、桶更少,使得壓縮算法更有效去除冗餘。
不過,頁大小和分桶數並非越大越好。比如,在高併發查詢的場景中,過大的頁可能導致額外的 I/O 開銷;而在分析型和離線統計類負載中,1MB 的頁與較少的分桶數通常能取得最佳效果。因此,最佳取值應根據數據規模、查詢模式與導入方式進行綜合考慮。
四、優化編碼方式
此外,數據在頁內的編碼方式也與列式存儲壓縮效果密切相關。Doris 針對不同類型的數據採用了多種編碼策略:對整數默認使用 Bitshuffle 編碼 + LZ4 壓縮,對字符串則使用字典編碼或純二進制編碼。這些編碼在大多數場景中表現優異,但仍有進一步優化的空間。
01 問題定位
為明確編碼方式的改進方向,我們在 Doris 中新增一個系統表:information_schema.column_data_sizes。它精確展示每一列在壓縮前後的空間佔用情況(壓縮前uncompressed_bytes、壓縮後compressed_bytes、原始數據raw_data_bytes)以及根據這些數據計算出的壓縮比(ratio=compressed_bytes/uncompressed_bytes)。在系統表中執行如下查詢:
SELECT
COLUMN_NAME, COLUMN_TYPE,
sum(COMPRESSED_DATA_BYTES) AS compressed_bytes,
sum(UNCOMPRESSED_DATA_BYTES) AS uncompressed_bytes,
sum(RAW_DATA_BYTES) AS raw_data_bytes,
round(sum(COMPRESSED_DATA_BYTES) * 100.0 / sum(UNCOMPRESSED_DATA_BYTES), 2) as ratio
FROM information_schema.column_data_sizes
WHERE table_id = 1761704935641
GROUP BY COLUMN_NAME, COLUMN_TYPE
ORDER BY sum(COMPRESSED_DATA_BYTES) DESC;
查詢結果如下(部分節選):
+-----------------------+-------------+------------------+--------------------+----------------+--------+
| COLUMN_NAME | COLUMN_TYPE | compressed_bytes | uncompressed_bytes | raw_data_bytes | ratio |
+-----------------------+-------------+------------------+--------------------+----------------+--------+
| URL | STRING | 1747139004 | 9404393858 | 9038895826 | 18.58 |
| Referer | STRING | 1552943801 | 7023847152 | 6662498316 | 22.11 |
| Title | STRING | 1480554020 | 9838412581 | 9488276782 | 15.05 |
| OriginalURL | STRING | 810663093 | 5680006400 | 5317485214 | 14.27 |
| WatchID | BIGINT | 781560948 | 781560948 | 799979976 | 100.00 |
| URLHash | BIGINT | 760852247 | 766458338 | 799979976 | 99.27 |
| RefererHash | BIGINT | 743785927 | 747950617 | 799979976 | 99.44 |
| FUniqID | BIGINT | 389556325 | 512285220 | 799979976 | 76.04 |
| UserID | BIGINT | 379008085 | 495166618 | 799979976 | 76.54 |
| HID | INT | 371392630 | 371392630 | 399989988 | 100.00 |
+-----------------------+-------------+------------------+--------------------+----------------+--------+
從結果可知出,字符串列(URL, Referer, Title, OriginalURL)佔據了壓縮後大部分空間,而部分 BIGINT 列(WatchID,URLHash,RefererHash)的壓縮率幾乎是 100%。這説明字符串編碼方式和整數編碼方式還需優化。
02 字符串編碼優化
這些存儲佔用大的字符串列(如 URL 與 Title)的長度大多都很短,平均長度不超過百字節。在 Doris 默認的字符串編碼策略中,這類數據的存儲方式並不完全高效。
字符串列默認採用 字典編碼 與 Plain Binary 編碼 的混合策略:系統在 segment 級別範圍內優先對一列數據構建字典頁,將重複字符串以索引形式存儲,以減少空間佔用;當字典頁超過設定大小上限時(默認 256KB),後續數據自動退化為 Plain Binary 格式,其佈局如下:
| binary1 | binary2 | ... | offset1 (fixed uint32) | offset2 (fixed uint32) | ...
這種格式在頁尾維護了一個定長的 uint32 數組,記錄每個字符串在頁內的偏移位置。而當短字符串量較多時,固定 4 字節的 offset 數組浪費空間。以 10 萬條短字符串為例,僅 offset 數組就需要約 400 KB,這是一筆不小的開銷,且壓縮算法幾乎無法對其有效壓縮。
為了解決這一問題,我們重新設計了頁內字符串的佈局,將存儲方式調整為“長度 加 內容”順序寫入:
| length1 (varuint32) | binary1 | length2 (varuint32) | binary2 | ...
這種設計省去了獨立的 offset 數組,通過變長整數(varuint32)直接記錄字符串長度,提高頁空間利用率。同時,數據的局部性得到改善,壓縮算法(如 ZSTD)可以更有效地捕捉重複模式。經過修改,字符串列的存儲空間進一步下降:
+-----------------------+-------------+------------------+--------------------+----------------+--------+
| COLUMN_NAME | COLUMN_TYPE | compressed_bytes | uncompressed_bytes | raw_data_bytes | ratio |
+-----------------------+-------------+------------------+--------------------+----------------+--------+
| URL | STRING | 1455177520 | 9057197818 | 9038895826 | 16.07 |
| Referer | STRING | 1331679271 | 6730874117 | 6662498316 | 19.78 |
| Title | STRING | 1122300920 | 9505664009 | 9488276782 | 11.81 |
| WatchID | BIGINT | 800004249 | 800004249 | 799979976 | 100.00 |
| OriginalURL | STRING | 768372911 | 5402777190 | 5317485214 | 14.22 |
+-----------------------+-------------+------------------+--------------------+----------------+--------+
03 整數編碼的優化
在進一步分析 BIGINT 列(如 WatchID、URLHash)時,我們發現其數據分佈特徵與普通遞增或低熵數據截然不同。這些列通常是哈希值或全局唯一 ID,熵值很高,默認使用的 Bitshuffle 編碼加 LZ4 壓縮效果幾乎為零。
基於這一發現,通過設置 integer_type_default_use_plain_encoding=false 禁用了對這些列的 Bitshuffle 編碼+ LZ4 壓縮,直接寫入原始字節序列再通過通用壓縮算法壓縮。這樣省去無效的 Shuffle 操作和 Padding,結合 ZSTD 壓縮算法,整體空間還略有下降,寫入和讀取性能也有所提升。
+-----------------------+-------------+------------------+--------------------+----------------+--------+
| COLUMN_NAME | COLUMN_TYPE | compressed_bytes | uncompressed_bytes | raw_data_bytes | ratio |
+-----------------------+-------------+------------------+--------------------+----------------+--------+
| WatchID | BIGINT | 800004249 | 800004249 | 799979976 | 100.00 |
| URLHash | BIGINT | 348739226 | 800004249 | 799979976 | 43.59 |
| RefererHash | BIGINT | 295833828 | 800004249 | 799979976 | 36.98 |
| FUniqID | BIGINT | 169720968 | 800004249 | 799979976 | 21.22 |
| UserID | BIGINT | 169536965 | 800004249 | 799979976 | 21.19 |
+-----------------------+-------------+------------------+--------------------+----------------+--------+
04 優化效果
基於字符串和整數編碼方式的改進,結合前面壓縮算法與頁參數的調整,表空間從最初的 16.08 GB 進一步降至 8.27 GB,整體壓縮率較初始階段提升約 48.6%。在此基礎上,基於 ClickBench 查詢集的測試結果顯示,系統在熱查詢場景下保持了與原有版本相同的性能,而在冷查詢場景下的性能提升近一倍,實現了壓縮率與查詢效率的雙重收益。

五、數據本身的排序與特徵
數據的排序與特徵也是決定壓縮效率的關鍵因素,常被忽視。列式存儲的壓縮效果依賴於相鄰數據的相似性,若表的數據分佈或排序與列值變化方向不一致,相似性將被打散,壓縮算法難以識別模式。
在實際測試中,這種排序差異的影響非常顯著。以剛才測試的 ClickBench 數據為例,通過系統表 information_schema.column_data_sizes,我們發現佔用空間最大的列是 URL 列,壓縮後約為 1.36 GB。
SELECT
COLUMN_NAME,COLUMN_TYPE,
sum(COMPRESSED_DATA_BYTES) AS compressed_bytes,
sum(UNCOMPRESSED_DATA_BYTES) as uncompressed_bytes,
sum(RAW_DATA_BYTES) as raw_data_bytes,
round(sum(COMPRESSED_DATA_BYTES) * 100.0 / sum(UNCOMPRESSED_DATA_BYTES), 2) as ratio
FROM information_schema.column_data_sizes
WHERE table_id=1761728747278
GROUP BY COLUMN_NAME, COLUMN_TYPE
ORDER BY sum(COMPRESSED_DATA_BYTES) desc limit 1;
+-----------------------+-------------+------------------+--------------------+----------------+--------+
| COLUMN_NAME | COLUMN_TYPE | compressed_bytes | uncompressed_bytes | raw_data_bytes | ratio |
+-----------------------+-------------+------------------+--------------------+----------------+--------+
| URL | STRING | 1456833417 | 9144581584 | 9038895826 | 15.93 |
+-----------------------+-------------+------------------+--------------------+----------------+--------+
將該列數據導入到一個僅包含 URL 一列並按照 URL 排序的新表中:
create table t1(
`URL` varchar(8000) NOT NULL
) DUPLICATE KEY (URL)
DISTRIBUTED BY HASH(URL) BUCKETS 1
PROPERTIES ( "replication_num"="1", "storage_page_size"="1048576");
insert into t1 select URL from hits;
查看新表中該列的數據大小,為 0.72 GB:
+-------------+-------------+------------------+--------------------+----------------+-------+
| COLUMN_NAME | COLUMN_TYPE | compressed_bytes | uncompressed_bytes | raw_data_bytes | ratio |
+-------------+-------------+------------------+--------------------+----------------+-------+
| URL | VARCHAR | 773983002 | 9148474115 | 9038895826 | 8.46 |
+-------------+-------------+------------------+--------------------+----------------+-------+
可以看到,在僅調整了排序與數據聚集方式後,壓縮後數據大小從 1.36 GB 減少到了 0.72 GB,壓縮比從 15.9% 提升到 8.46%,壓縮空間幾乎減少了一半。這充分説明了數據的有序性與局部相似性對壓縮率的決定性影響。
因此,當用户發現 Doris 的壓縮率與其他系統存在差異時,除了壓縮算法與參數的區別,更常見的原因在於數據排序和分佈模式的不同。壓縮算法的效率對數據本身的排序極為敏感,合理設計排序鍵、分桶列、分桶數與導入方式,往往能帶來更大的收益。因此,理解數據的分佈特徵、控制其在物理層面的佈局,是提升 Doris 存儲效率的核心手段。
六、結束語
在實際場景中,實現高壓縮比的數據存儲充滿挑戰,但列式存儲系統 Doris 讓這一目標變得可行。經過一系列針對性優化,最終數據的存儲空間從最初的 16.08 GB 降至 8.2 GB,整體壓縮率提升超過 48%。這一結果並非來自某一個獨立的技術點,而是多層次調整疊加的結果:壓縮算法的優化、頁大小與分桶參數的調整,以及對數據特徵的深入理解共同作用,才讓壓縮效率得到顯著提升。