
Flink-Doris-Connector 作為 Apache Flink 與 Doris 之間的橋樑,打通了實時數據同步、維表關聯與高效寫入的關鍵鏈路。本文將深入解析 Flink-Doris-Connector 三大典型場景中的設計與實現,並結合 Flink CDC 詳細介紹了整庫同步的解決方案,助力構建更加高效、穩定的實時數據處理體系。
一、Apache Doris 簡介
Apache Doris 是一款基於 MPP 架構的高性能、實時的分析型數據庫,整體架構精簡,只有 FE 、BE 兩個系統模塊。其中 FE 主要負責接入請求、查詢解析、元數據管理和任務調度,BE 主要負責查詢執行和數據存儲。Apache Doris 支持標準 SQL 並且完全兼容 MySQL 協議,可以通過各類支持 MySQL 協議的客户端工具和 BI 軟件訪問存儲在 Apache Doris 中的數據庫。
在典型的數據集成和處理鏈路中,往往會對 TP 數據庫、用户行為日誌、時序性數據以及本地文件等數據源進行採集,經由數據集成工具或者 ETL 工具處理後寫入至實時數倉 Apache Doris 中,並由 Doris 對下游數據應用提供查詢和分析,例如典型的 BI 報表分析、OLAP 多維分析、Ad-hoc 即席查詢以及日誌檢索分析等多種數據應用場景。
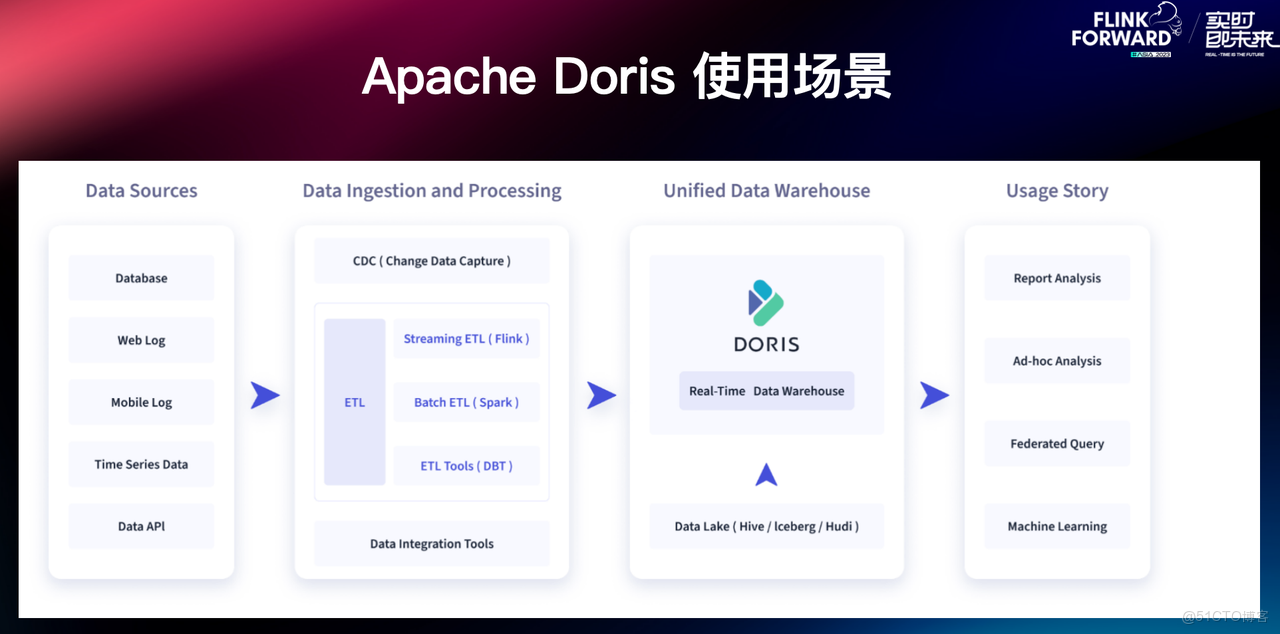
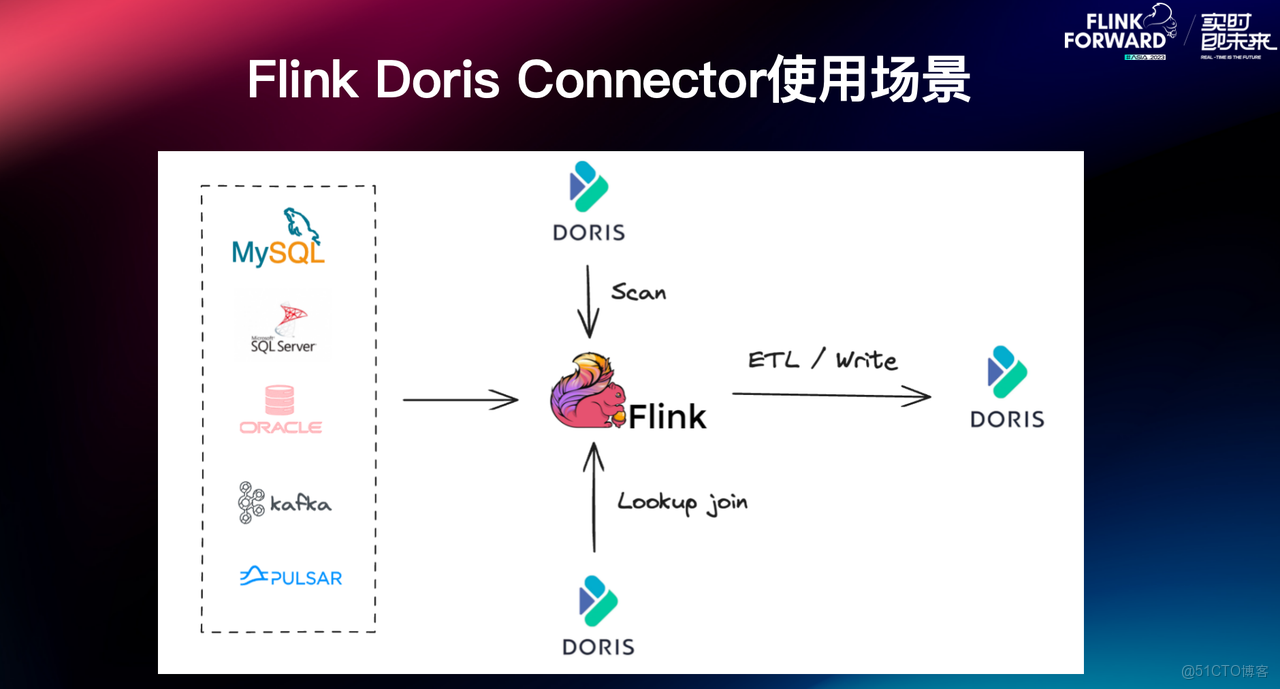
Flink-Doris-Connector 是 Apache Doris 與 Apache Flink 在實時數據處理 ETL 的結合,依託 Flink 提供的實時計算能力,構建高效的數據處理和分析鏈路。Flink-Doris-Connector 的使用場景主要分為三種:
- Scan:通常用來做數據同步或是跟其他數據源的聯合分析;
- Lookup Join:將實時流中的數據和 Doris 中的維度表進行 Join;
- Real-time ETL:使用 Flink 清洗數據再實時寫入 Doris 中。
二、Flink-Doris-Connector 典型場景的設計與實現
本章節結合 Scan、Lookup Join、Write 這三種場景,介紹 Flink-Doris-Connector 的設計與實現。
01 Scan 場景
Scan 場景指將 Doris 中的存量數據快速提取出來,當從 Doris 中讀取大量數據時,使用傳統的 JDBC 方法可能會面臨性能瓶頸。因此 Flink-Doris-Connector 中可以藉助 Doris Source ,充分利用 Doris 的分佈式架構和 Flink 的並行處理能力,從而實現了更高效的數據同步。
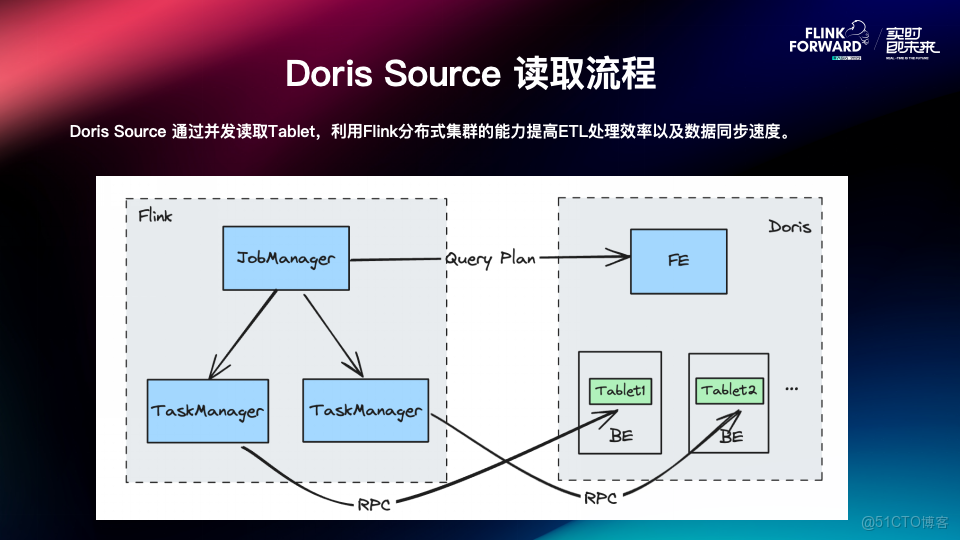
Doris Source 讀取流程
- Job Manager 向 FE 端發起請求查詢計劃,FE 會返回要查詢的數據對應的 BE 以及 Tablet;
- 根據不同的 BE,將請求分發給不同的 TaskManager;
- 通過 Task Manager 直接讀取每個 BE 上對應 Tablet 的數據。
通過這種方式,我們可以利用 Flink 分佈式處理的能力從而提高整個數據同步的效率。
02 Lookup Join 場景
對於維度表存儲在 Doris 中的場景,可通過 Lookup Join 實現對實時流數據與 Doris 維度表的關聯查詢。
JDBC Connector
Doris 支持 MySQL 協議,所以可以直接使用 JDBC Connector 進行 Lookup Join,但是這一方式存在一定的侷限:
- Jdbc Connector 中的 Lookup Join 是同步查詢的操作,會導致實時流中每條數據都要等待 Doris 查詢的結果,增加了延遲。
- 僅支持單條數據查詢,在上游數據量吞吐較高時,容易造成性能瓶頸和反壓。
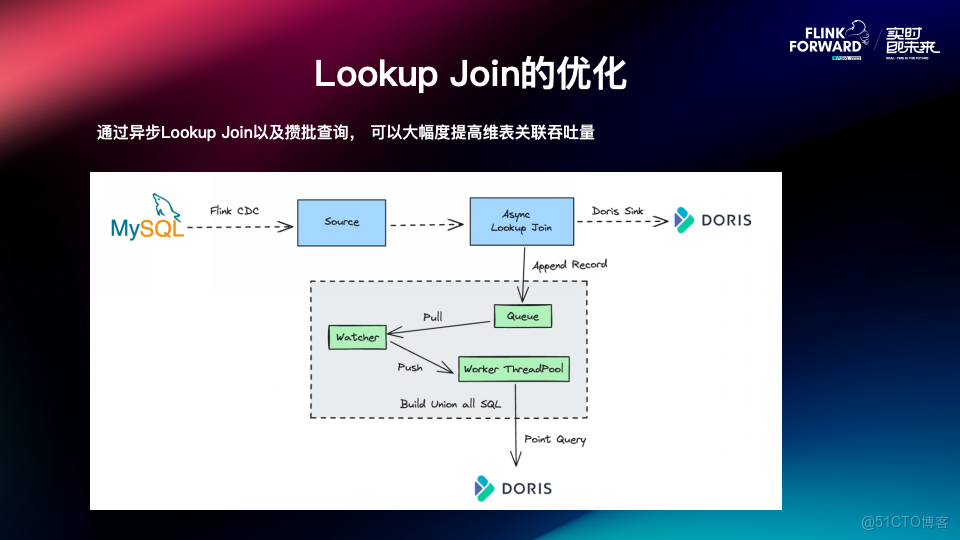
Flink-Doris-Connector 的優化
因此針對 Lookup Join 場景 ,Flink-Doris-Connector 實現了異步 Lookup Join 和攢批查詢的優化:
- 支持異步 Lookup Join: 異步 Lookup Join 意味着實時流中的數據不需要顯式等待每條記錄的查詢結果,可以大大的降低延遲性。
- 支持攢批查詢: 將實時流的數據追加到隊列 Queue 中,後台通過監聽線程 Watcher,將隊列裏面的數據取出來再推送到查詢執行的 Worker 線程池中,Worker 線程會將收到的這一批數據拼接成一個 Union All 的查詢,同時向 Doris 發起 Query 查詢。
通過異步 Lookup join 以及攢批查詢,可以在上游數據量比較大的時候大幅度提高維表關聯吞吐量,保障了數據讀取與處理的高效性。
03 實時 ETL 場景
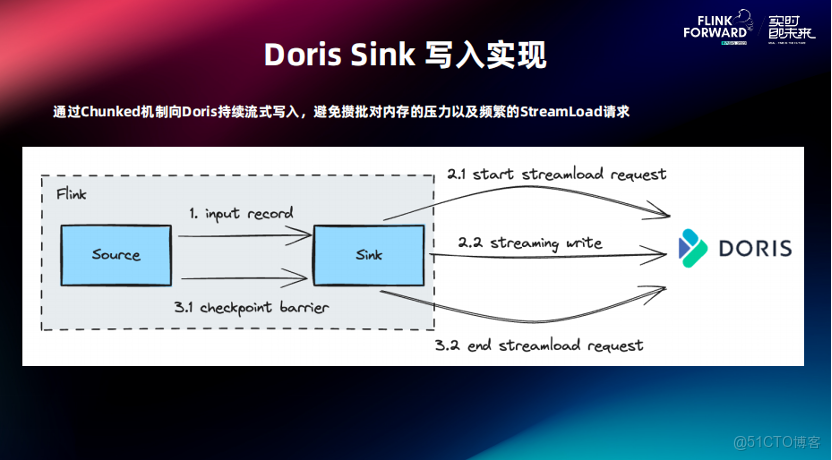
對於實時寫入來説,Doris Sink 的寫入是基於 Stream Load 的導入方式去實現的。Stream Load 是 Apache Doris 中最為常見的數據導入方式之一,支持通過 HTTP 協議將本地文件或數據流導入到 Doris 中。主要流程如下:
- Sink 端在接收到數據後會開啓一個 Stream Load 的長鏈接請求。在 Checkpoint 期間,它會將接收到的數據以 Chunk 的形式持續發送到 Doris 中。
- Checkpoint 時,會對剛才發起的 Stream Load 的請求進行提交,提交完成後,數據才會可見。
如何保證數據寫入的 Exactly-Once 語義
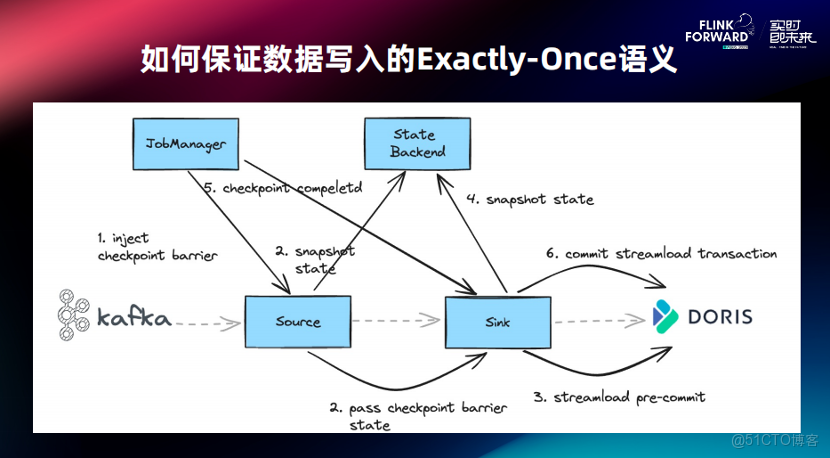
那麼,如何保證數據寫入期間,端到端數據的精確一次性?
以 Kafka 同步到 Drois 的 Checkpoint 過程為例:
- Checkpoint 時,Source 端會接收到 Checkpoint Barrier;
- Source 端接收到 Barrier 後,首先會對自身做一個快照,同時會將 Checkpoint Barrier 下發到 Sink 端;
- Sink 端接收到 Barrier 後,執行 Pre-commit 提交,成功後數據就會完整寫入到 Doris,由於此處執行的是預提交,所以在 Doris 上,此時對用户來説數據是不可見的;
- 將 Pre-Commit 成功的事務 ID 保存到狀態中;
- 所有的算子 Checkpoint 都做完後,Job Manager 會下發本次 Checkpoint 完成的通知;
- Sink 端會對剛才 Pre-commit 成功的事務進行一次提交。
通過這種兩階段提交,就可以實現端到端的精確一次性。
實時性與 Exactly-Once
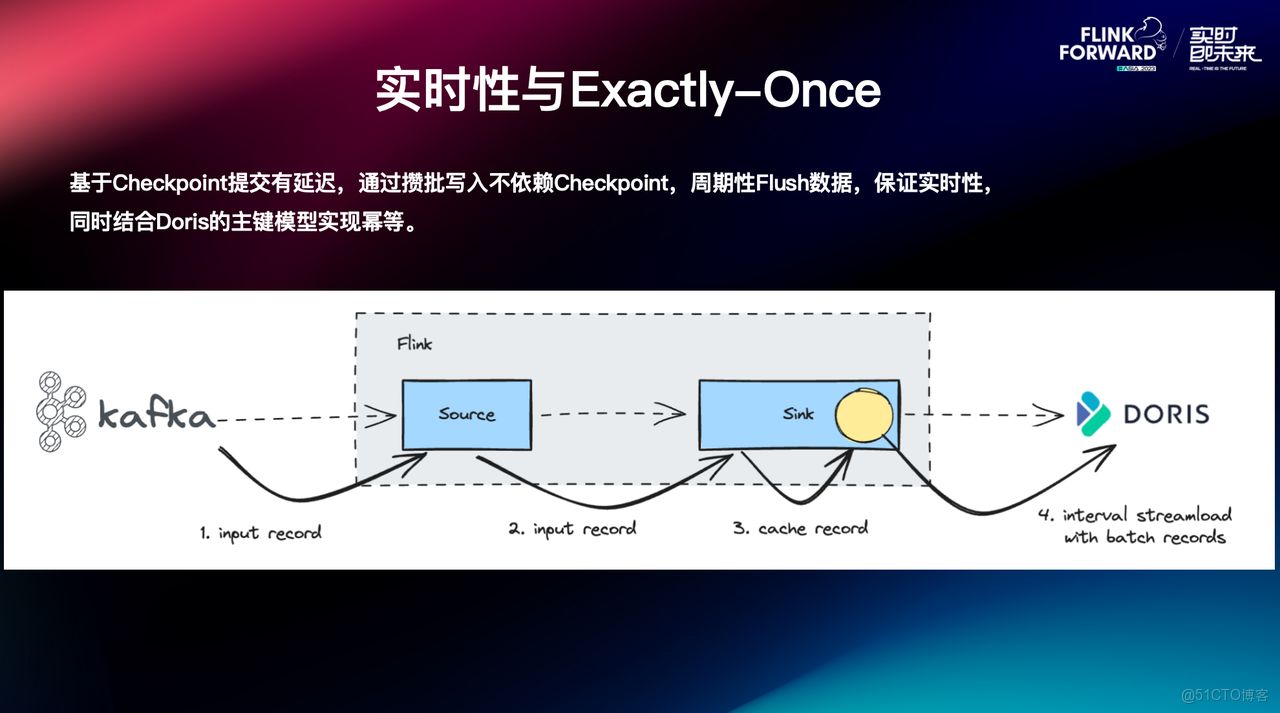
上面提到,Doris Sink 端的寫入與 Checkpoint 綁定,數據寫入 Doris 的延遲性取決於 Checkpoint 的間隔。但在一些用户的場景下,希望數據可以實時寫入,但是 Checkpoint 不能做的太頻繁,同時對於一些作業來説,如果 Checkpoint 太頻繁會消耗大量資源,針對該情況,Flink-Doris-Connector 引入了攢批機制,以平衡實時性與資源消耗之間的矛盾。
攢批的實現原理是 Sink 端接收上游數據之後,不會立即將每條數據單獨寫入 Doris,而是先在內存中進行緩存,然後通過對應參數設置,將緩存數據提交到 Doris 中。結合攢批寫入和 Doris 中的主鍵模型,可以確保數據寫入的冪等性。
通過引入攢批機制,既滿足了用户對數據實時寫入的需求,又避免了頻繁 Checkpoint 帶來的資源消耗問題,從而實現性能與效率的優化。
三、基於 Flink CDC 的整庫同步方案
以上是對 Flink-Doris-Connector 的典型場景和實現原理介紹,接下來我們來看它在實際業務中的一個重要應用——整庫同步。相比底層實現,整庫同步更偏向具體使用場景。下面我們基於前面介紹的能力,進一步探討如何通過 Flink CDC 實現 TP 數據庫到 Doris 的高效、自動化同步。
01 整庫同步痛點
在數據遷移過程中,用户通常希望可以儘快將數據遷移到 Doris 中,然而在同步 TP 數據庫時,整庫同步往往面臨以下幾點挑戰:
- 建表:
- 存量表的快速批量創建:TP 數據庫中往往存在成千上萬的表,這些表的結構各異,對於存量表而言需要逐一在 Doris 中創建對應的表結構;
- 同步任務開啓後,新增表的自動創建與同步: 為了保證數據的完整性和實時性,同步工具需要實時監控 TP 數據庫的變化,並自動在 Doris 中創建和同步新表。
- 元數據映射: 上下游之間字段元數據的便捷映射,包括字段類型的轉換、字段名稱的對應修改等。
- DDL 自動同步: 增加、刪除列等操作會導致數據庫結構發生變化,進而影響到數據同步。因此,同步工具需要能夠實時捕獲 DDL 並動態地更新 Doris 表結構,以確保數據的準確性和一致性。
- 開箱即用: 零代碼,低門檻,理想的同步工具只需進行簡單配置,即可實現數據的遷移和同步。
02 基於 Flink CDC 實現整庫同步
在數據抽取方面,Flink-Doris-Connector 借用了 Flink CDC 的特性能力:
- 增量快照讀取
- 無鎖讀取與併發讀取:不論存量數據量多大,都可以通過橫向提高 Flink 的併發提升數據讀取速度。
- 斷點續傳:當存量數據比較大時,可能面臨同步中斷的情況,CDC 支持中斷任務的銜接同步。
- 豐富數據源支持,Flink CDC 支持多種數據庫,如 MySQL、Oracle、SQLServer 等。
- 無縫對接 Flink 現有生態,方便與 Flink 已有Source 和 Sink 結合使用。
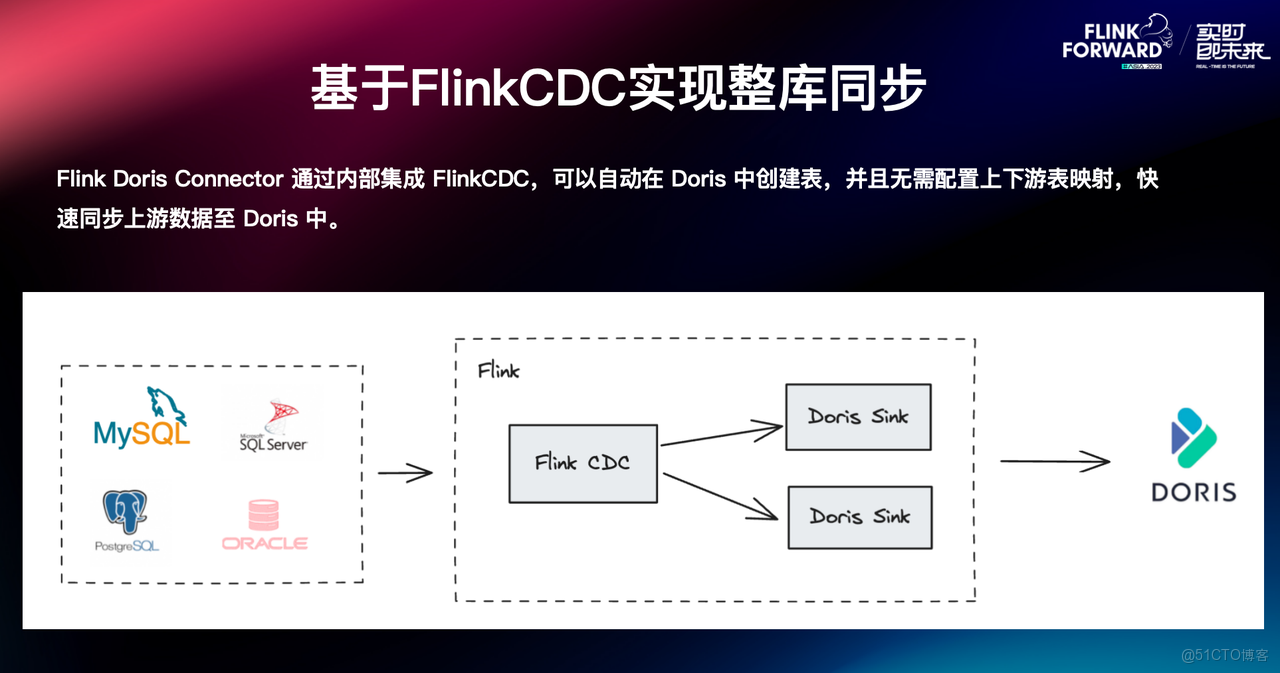
一鍵建表與元數據自動映射
Flink-Doris-Connector 中集成了 Flink CDC 等能力,可以讓用户只提交一個操作,就能進行整庫同步的操作。其主要原理是 Flink CDC Source 在接收到上游的數據源之後,會進行分流處理,不同的表用不同的 Sink。同時在最新的 Connector 版本中,也支持單個 Sink 同步多張表,支持新增表的創建和同步。
集成 Flink CDC 的功能後,用户僅需通過 Flink-Doris-Connector 提交任務,就可以在 Doris 自動創建所需的表,而無需配置上下游表之間的顯式關聯,實現數據快速同步。
當 Flink 任務啓動後,Doris-Flink-Connector 將自動識別對應的 Doris 表是否存在。如果表不存在,Doris Flink Connector 會自動創建表,並根據 Table 名稱進行分流,從而實現下游多個表的 Sink 接入;如果表存在,則直接啓動同步任務。
這一改進,不僅簡化了配置流程,還使得新增表的創建和同步更加便捷,從而提升數據處理的整體效率。
Light Schema Change 與 DDL 自動同步
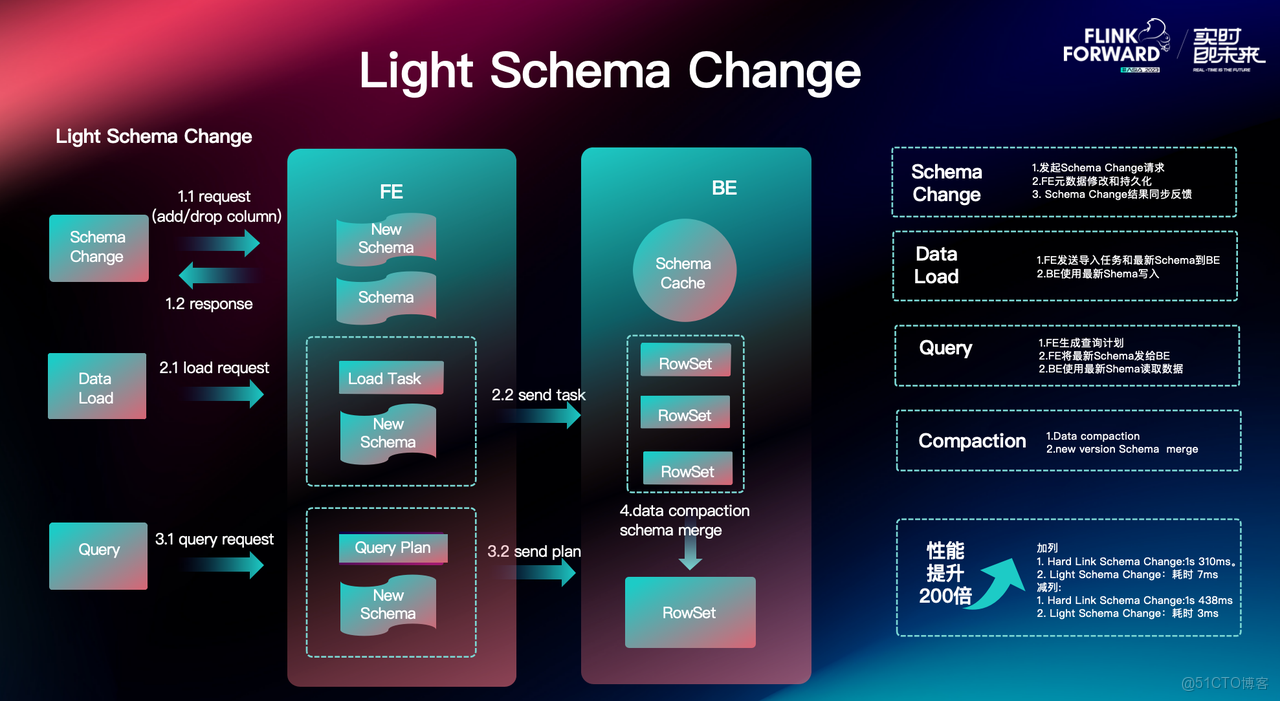
在 Apache Doris 1.2 版本之前,Schema Change 操作比較繁瑣,需要手動增改數據列。在上游 TP 數據庫發生表結構變更時,需要暫停數據同步任務、待 Doris 中的 Schema Change 完成後再重啓任務。
自 Apache Doris 1.2 版本起,我們引入了輕量級的 Light Schema Change 機制,極大地簡化了操作流程,常見的增減列場景其處理速度可達毫秒級。Light Schema Change 機制原理如下:
- Schema Change:
- 客户端向 FE 發起增減列的請求;
- FE 在接收到請求後,修改當前元數據,並將最新的 Schema 持久化;
- FE 向客户端同步 Schema Change 的結果;
- Data Load:
- 當後續導入任務發起時,FE 將導入任務與最新的 Schema 信息發送給 BE;
- 在數據寫入過程中,BE 的每個 Rowset 都會存儲當前導入的 Schema 信息;
- Query:
- FE 將查詢計劃與最新的 Schema 一起發送給 BE;
- BE 使用最新 Schema 執行查詢計劃;
- Compaction:
- 在 BE 中,對參與合併的 Rowset 版本進行比較;
- 根據最新的 Schema Change 信息進行數據合併。
經測試,與早期的 Schema Change 相比,Light Schema Change 的數據同步性能有了數百倍的提升,
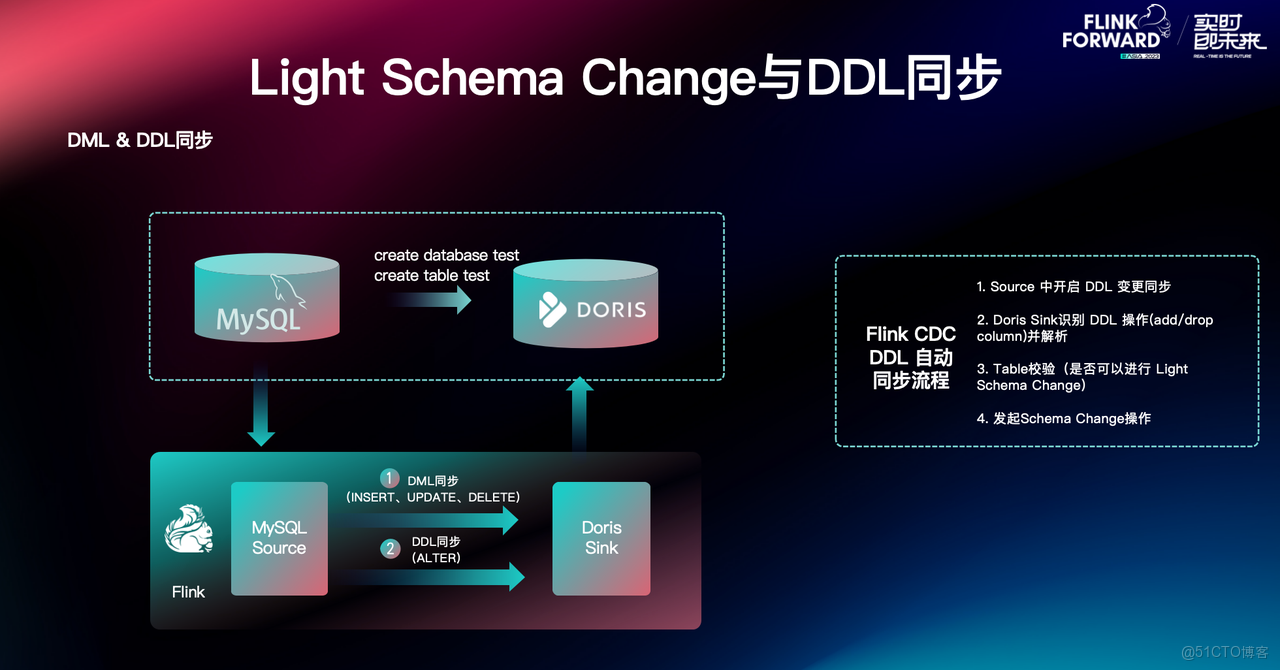
Light Schema Change 與 Flink-Doris-Connector 的結合,通過 Flink CDC 可以實現 DDL 的自動同步,具體步驟如下:
- Source 端捕獲上游 Schema Change 信息,開啓 DDL 變更同步;
- Doris Sink 端識別並解析 DDL 操作(加減列);
- Table 校驗,判斷是否可以進行 Light Schema Change;
- 發起 Schema Change 操作;
基於這一實現,Doris 能自動獲取到 DDL 語句並在毫秒級即可完成 Schema Change 操作,在上游 TP 數據庫發生表結構變更時,數據同步任務無需暫停。
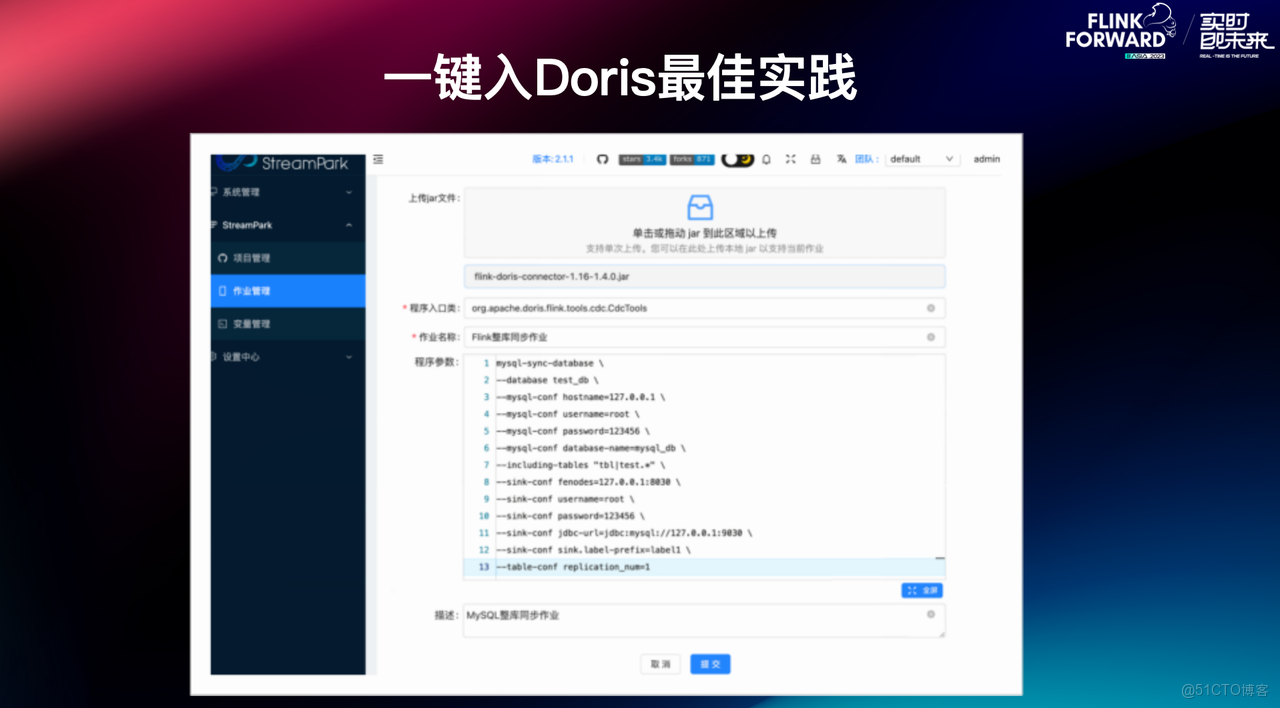
開箱即用:MySQL 整庫同步示例

對於用户來講,只要有 Flink 客户端,通過上圖的操作就可以提交整庫同步作業。支持傳入 Flink 的配置,比如併發設置、Checkpoint 間隔等,也支持正則表達式去配置需要同步的表, 同時可以將 Flink CDC Source 和 Doris Sink 的配置直接透傳給具體的 Connector。通過這種方式,用户可以很便捷地提交整庫同步作業。
03 Flink-Doris-Connector 核心優勢
基於以上優化,可以完美解決用户的痛點:
- 自動建表,即存量表與增量表的自動創建,無需用户提前在 Doris 中預先創建對應的表結構;
- 自動映射上下游字段,無需手動寫入上下游字段間的匹配規則,節省大量人力成本;
- 增減列無感同步,及時獲取上游 DDL 語句並自動在 Doris 中實現毫秒級 Schema Change,無需停服、數據同步任務平穩運行;
- 開箱即用,降低學習成本,更專注業務本身。
04 最佳實踐
在生產環境中,若作業數量較多,直接採用上述提交方式的作業管理複雜度較高。通常建議藉助任務託管平台(如 StreamPark),實現對作業的統一創建、監控與運維,從而提升任務管理效率與系統穩定性。
四、未來規劃
未來,基於 Flink-Doris-Connector 的能力規劃如下:
- 支持實時讀取。目前 Doris Source 只是把數據 Scan 出來,是一個有界流的讀取,後續會支持 CDC 的場景,可以使用 Flink 來對 Doris 中的數據進行流式的讀取。
- Sink 一流多表。目前Flink-Doris-Connector支持單個 Sink 同步多張表,但是 Stream Load 的導入方式還是隻支持單個表的導入。所以在表特別多的時候,需要在 Sink 端維護大量 StreamLoad 的連接,在後續會做到單個 Stream Load 的連接支持多張表的寫入。
- 整庫同步方面,支持更多的上游數據源,滿足更多數據同步場景。
