
導讀:
大數據技術的發展歷程中,繼數據倉庫、數據湖之後,大數據平台的又一革新技術——湖倉一體近年來開始引起業內關注。市場發展催生的數據管理需求一直是數據技術革新的動力。比如數據倉庫如何存儲不同結構的數據?數據湖又如何避免因為缺乏治理導致的數據雜亂現象?今天的文章想跟大傢俱體聊聊我們的數棧如何解決這些問題。
你能看到👇👇👇
▫ 湖倉一體概念簡述
▫ 數棧的湖倉建設過程中有哪些痛點
▫ 湖倉一體如何針對性解決這些問題
背景
隨着進入21世紀第三個十年,大數據技術也從探索期、發展期逐漸邁向了普及期。現如今,越來越多的企業開始使用大數據技術輔助決策分析。數據倉庫自1990年數據倉庫之父比爾·恩門(Bill Inmon)提出以來,已經發展了三十餘年,各大雲廠商也紛紛推出如AWS Redshift、Google BigQuery、Snowflake等數據倉庫。
但隨着企業的現代化,各式各樣的數據結構、越來越高的實時性、快速變化的數據模型等現實情況導致數據倉庫已經不能滿足日益增長的企業需求,以Iceberg、Hudi為代表的數據湖便應運而生。開放的文件存儲、開放的文件格式、開放的元數據服務以及實時讀取與寫入等特點使它們受到大家的熱烈追捧,各大雲廠商也隨之紛紛提出自己的數據湖解決方案,因此有人説,數據湖是下一代大數據平台。
新的事物總有兩面性,一方面數據倉庫無法容納不同格式的數據,另一方面,數據湖缺乏結構和治理,會迅速淪為“數據沼澤”,兩種技術均面臨嚴重的侷限性。在此背景下,融合了數據倉庫與數據湖優點的新的架構模式”湖倉一體“被提了出來。
什麼是湖倉一體
一言蔽之,“湖倉一體”是一種新的架構模式,它將數據倉庫與數據湖的優勢充分結合,其數據存儲在數據湖低成本的存儲架構之上,擁有數據湖數據格式的靈活性,又繼承了數據倉庫數據的治理能力。
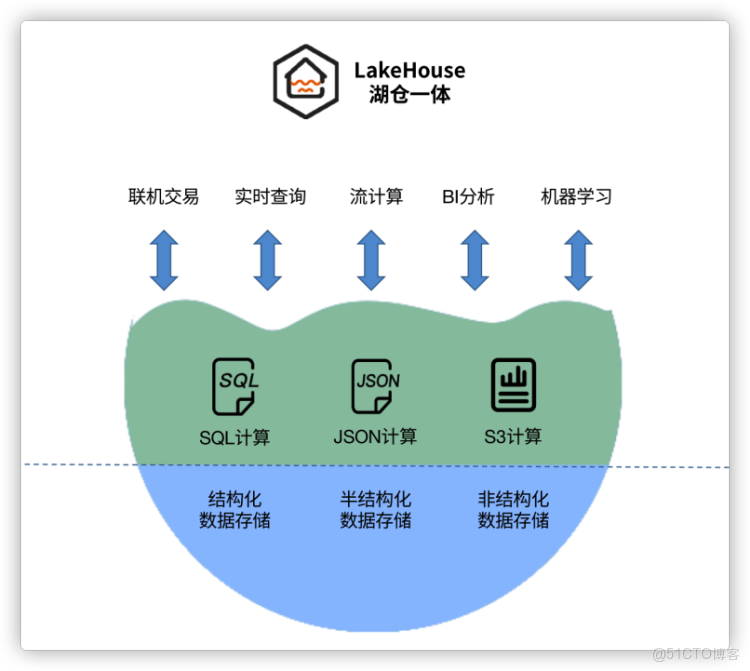
數棧在湖倉一體上的演進
隨着客户業務的不斷髮展,數棧作為一套數據中台也遇到了越來越多的挑戰。在克服這些挑戰的同時,我們也深感自身還有很多不足的地方。
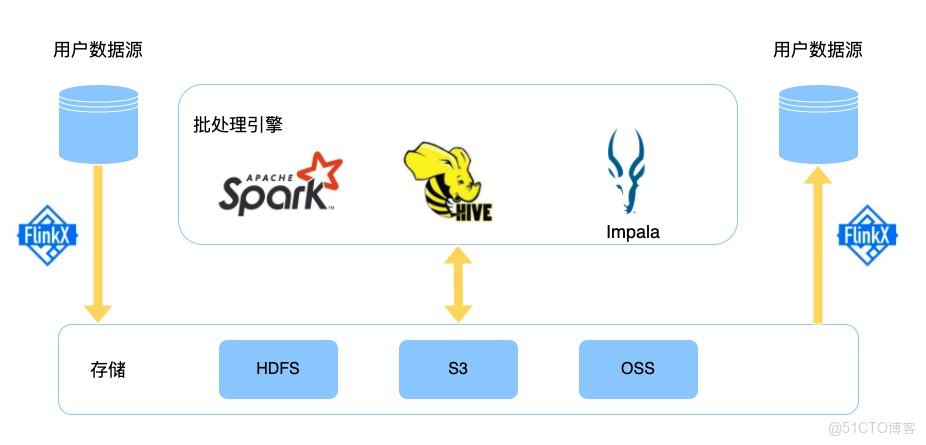
數棧離線數倉
如圖所示,用户業務數據通過FlinkX導入Hive數倉,通過Spark引擎處理業務邏輯,最終通過FlinkX再寫回用户數據源。
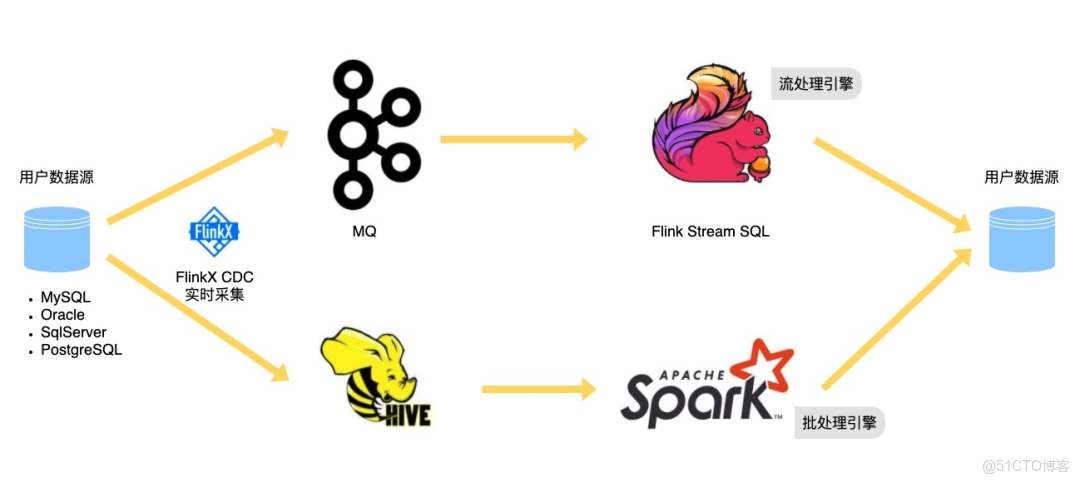
數棧實時數倉
如圖所示,實時數倉有兩條鏈路:一條是實時鏈路,採集到的CDC數據寫往消息隊列,通過FlinkStreamSQL實時計算,最終寫到Kudu、HBase等高效讀寫的數據源;另一條是準實時鏈路,採集到的CDC數據寫往Hive表,通過Spark SQL計算。
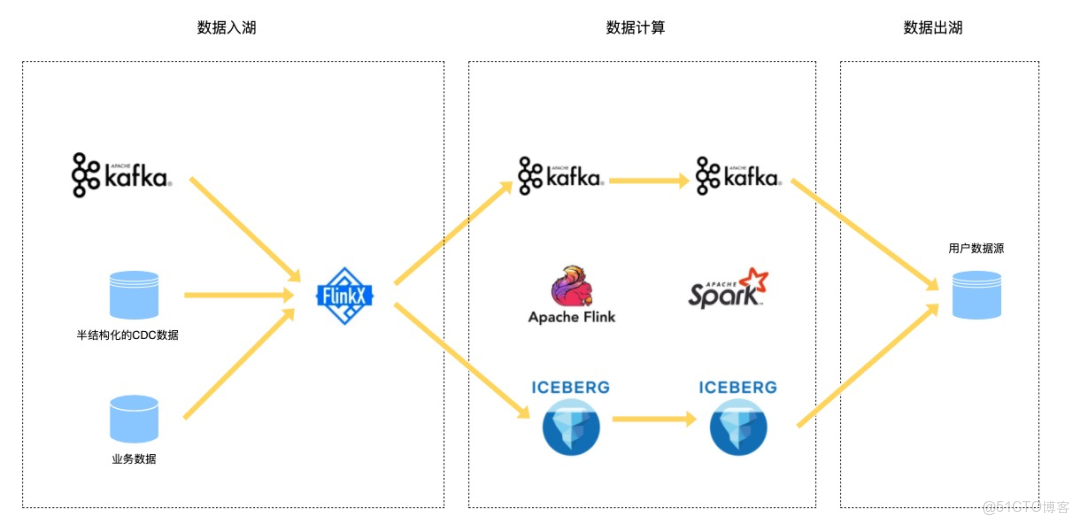
引入數據湖
由於數棧流計算引擎使用的是Flink,在調研Iceberg、Hudi兩款開源數據湖項目之後,Iceberg相比於Hudi來説,與Flink集成更便捷,生態上也更友好,因此我們決定採用Iceberg作為我們的第一款數據湖產品,後續將逐個支持Hudi等其他數據湖。關於Iceberg的一些特點這裏就不過多贅述了,下面是引入數據湖後的數倉鏈路:
結構化、半結構化及非結構化的數據通過FlinkX做ETL處理後寫入Iceberg數據湖或者寫回消息隊列。接着數據在消息隊列和數據湖中通過Flink和Spark引擎不斷流轉與計算,最終寫到Kudu、HBase等高效讀寫的數據源。
數棧在湖倉建設中的痛點
批流分離,運維費錢費力
目前離線數倉的做法是先使用FlinkX將數據採集到Hive表中,然後再通過Hive SQL或者Spark SQL計算,最後寫回Hive;實時數倉的做法是數據從源表的Kafka中讀取,通過FlinkStreamSQL計算,最後寫到kudu或HBase。
在這兩條鏈路中,開發人員首先不得不維護兩套自研的框架:FlinkX和FlinkStreamSQL;運維人員不得不對Hive SQL、Spark SQL和Flink SQL任務有一定的瞭解;數據開發也不得不熟悉Hive SQL、Spark SQL和Flink SQL的語法及參數配置。這樣的一整套數倉開發、使用、運維起來,成本不可謂不巨大。
代碼重複,採算資源浪費
FlinkX和FlinkStreamSQL在創建之初,一個面向同步,一個面向計算。但隨着業務的不斷髮展,這兩個其實越來越相似了。FlinkX在同步時也需要做一定程度的計算,將數據清洗後寫入目標表。而FlinkStreamSQL如果不進行計算只是單純的寫庫,那麼就是同步功能。
因此後續在新增數據源類型的時候,FlinkX和FlinkStreamSQL需要各增加一個類似的connector,而這個connector中80%的代碼都是相似的。在面對數據源相關的bug時,FlinkX和FlinkStreamSQL都需要進行修復。兩套框架所帶來的是兩倍的人力成本。
缺乏治理,湖倉變成沼澤
在引入Iceberg數據湖後,絕大部分數據都未經處理就寫入進去了。由於缺乏catalog級別的元數據管理,想要從大量原始數據中找到想要的業務數據如同沙中淘金。不同的業務人員在使用完各自的數據後不知如何整理,就導致了數據雜亂不堪,並衍生出了大量的小文件。大量的小文件嚴重拖累了Hadoop集羣的效率,使數據湖淪為了數據沼澤。
數棧邁向湖倉一體
痛點的解決方案
為了解決以上痛點,數棧做了以下改動:
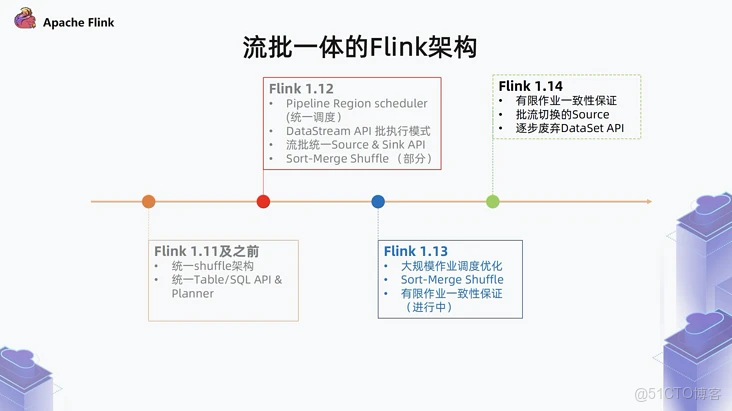
1、啓用Flink做主計算引擎
Flink在1.12版本實現了Source&Sink API的流批一體,並且社區也在不斷向着流批一體的方向發展,因此我們選用Flink作為主要的計算引擎。至此,無論是離線、實時數倉還是數據湖,只需要一套Flink SQL任務即可完成業務的處理。得益於Flink在數據處理上的行業領先水平,我們可以基於Flink流批一體,使用Flink作為湖倉的主要計算引擎,一舉解決運維成本高,操作難度大的問題。
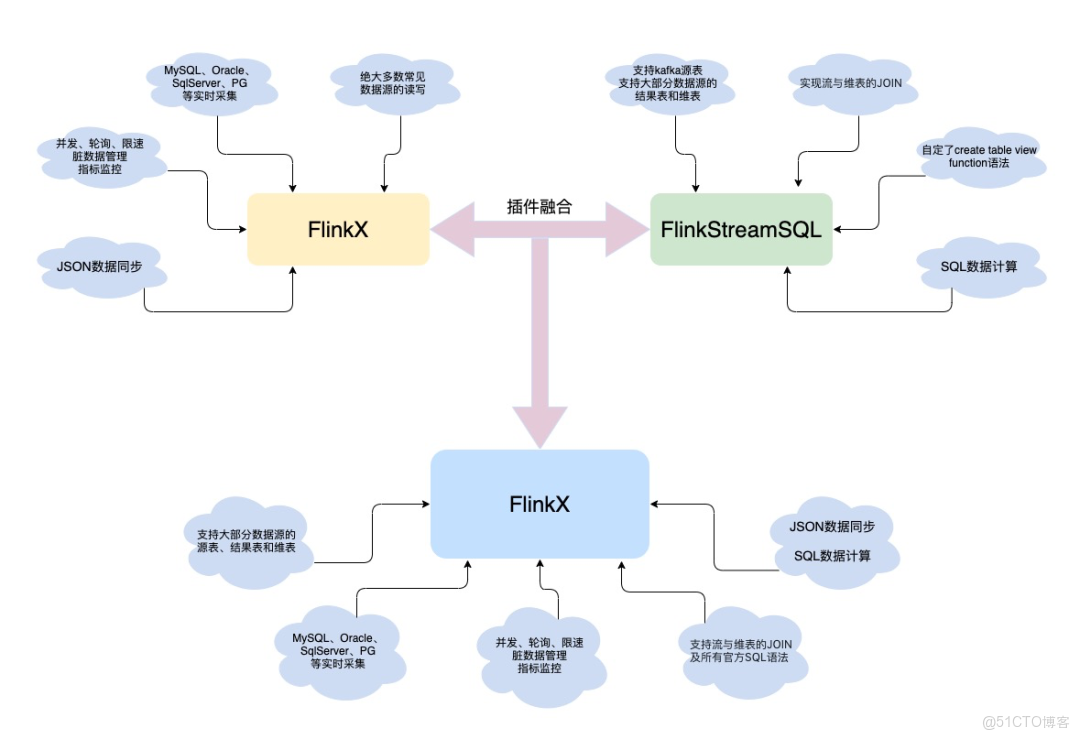
2、融合代碼重複的兩套插件
如上文提到的,FlinkX與FlinkStreamSQL在插件層80%的代碼是重複的,因此我們不需要維護兩套重複的插件。我們將兩套框架的優點相結合,寫出了全新的FlinkX。融合後的FlinkX繼承了原JSON的數據同步功能,並且也能使用強大的SQL語言。無論數據是離線的還是實時的,數據無論是入倉、入湖還是計算,藉助全新的FlinkX均能輕易處理。
3、統一湖倉數據源中心
引入數據源中心統一管理中台中使用到的數據源,可以方便中台管理員管理數據源,控制數據源的使用權限。同時將散列在各項目中的元數據模塊統一到數據源中心中,可以方便使用者查看某數據源的使用情況。針對Iceberg數據湖數據源設置更細粒度的catalog管理,防止淪為數據沼澤。對於底層存儲在HDFS上的數據源,如Hive、Iceberg等,增加小文件合併功能,手動的或自動的定時合併小文件,徹底解決小文件問題。

數棧湖倉一體架構
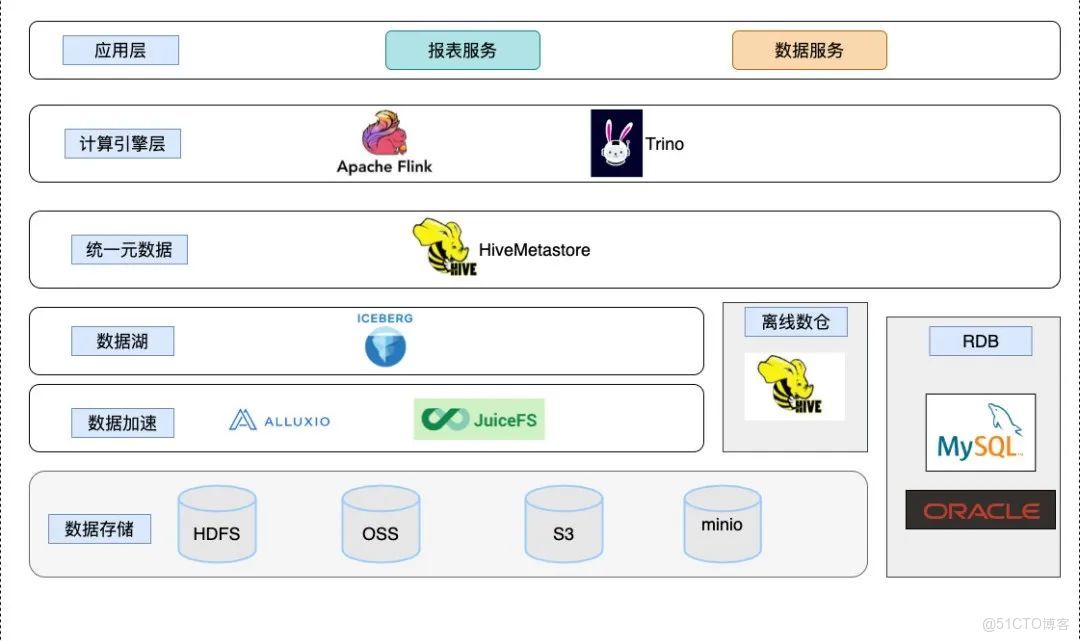
基於上述所説,讓我們一起來看看,我們通過 Flinkx 將數據入湖(Iceberg)、入倉(hive) 之後,數棧上湖倉一體的結構是如何實現的:
在引入Iceberg 之後我們不僅可以統一對接各種格式的數據存儲,包括結構化半結構化數據,並且底層存儲上支持對OSS,S3,HDFS 等存儲系統,而利用Iceberg 的特性也可以提供對ACID、表結構變更,基於Snapshot 讀取歷史數據等功能的支持,同時數棧在上一層統一了元數據中心,使用統一的元數據存儲,不僅僅可以管理數據湖的存儲,而且可以做到對原有的數據倉庫進行統一管理,在表結構層做到統一入口,在上層計算的時候可以看到全局的表信息,而不是孤立的多個源的表信息。
在統一元數據之後,我們需要一個能基於已經構建的元數據之上對數據湖,數據倉庫進行計算的工具,在Hadoop 生態上,類似的計算工具有很多,包括Trino,Flink,Spark等。當前這個結構上,我們可以根據客户的業務場景進行選擇,如果客户已經有數據倉庫,並且想借助數據湖來進行上層的業務構建的話,能支持跨源的Flink,Trino用來查詢就是一個合適的選擇,同時客户對查詢交互性能有要求的話,那麼Trino 的MPP 架構提供的橫向擴展的特性就會是一個不錯的選擇。
數棧對於未來的展望
數棧當前通過引入Iceberg和改造FlinkX ,統一了實時和離線的數據集成和計算和存儲能力,可以在數棧上實現基本的湖倉庫一體。未來我們希望數棧具有跨源能力,不只是在單一的Hadoop 生態裏面構建湖倉一體,而且可以基於企業已有的傳統數據存儲比如MySQL、Oracle倉庫(不需要將數據從MySQL、Oracle 等倉庫抽到統一的數據中心),通過統一的元數據中心註冊不同的catalog進行隔離,加上新建設的數據湖,在上層的Flink計算引擎做到湖倉一體的能力。
在存儲層,我們希望可以做到對當前HDFS和S3 的支持,同時也可以支持本地和雲端存儲;並且在存儲層面我們要做到自動進行數據管理,包括對小文件進行定期合併,對遠程文件數據進行加速,並對數據構建索引,統一的元數據管理等等;我們的目標是實現存儲層的Data warehouse as a servrice。
要做到上面的規劃,我們還有很多功能要去優化和整合,未來我們會實時關注和參與Iceberg、Hudi、Flink 社區,關注社區的規劃和發展,結合我們當前已有的統一的數據開發平台進行不斷的迭代,到達DasS的能力,讓企業和用户能在湖倉一體的架構下提升數據價值。