
1.簡介
Segnet、FCN都是基於VGG16的,但VGG16本身就是一個很大的網絡,參數多,故inference時運行慢,無法運用到實時場景。本文提出ENet分割算法,它在精確率和運行時間上作了權衡,能夠運用在移動端的實時分割任務中。
個人感覺ENet的思想跟GoogLeNe有點類似,就是本質都是為了解決參數過於密集(參數太多),而引入稀疏性,降低參數數量的量級,從而提升inference的速度。那麼如何引入稀疏性?主體思想就是:將一個大的卷積操作分解幾個卷積/池化的組合,即分解成一個block,作為構建網絡的基本模塊。

2.網絡結構
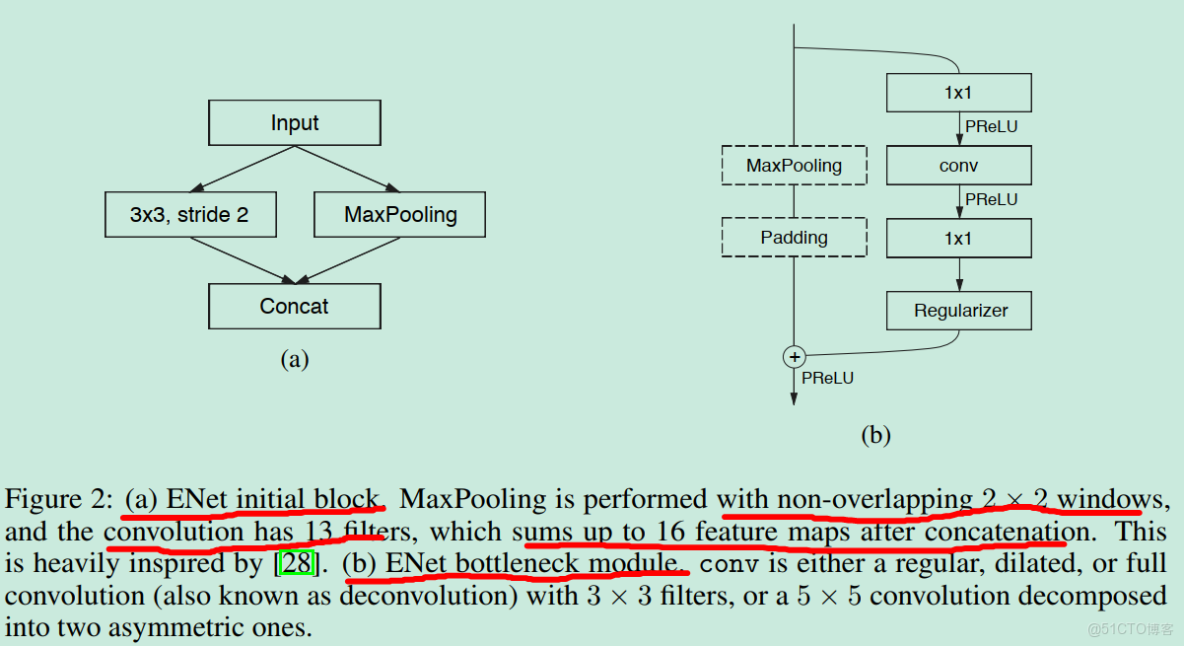
2.1.initial block
ENet有兩種block,一種是initial block,如圖(a)。它是ENet網絡的第一個模塊,也僅僅出現一次。initial block的主要作用就是先對輸入圖像進行下采樣,以降低後續feature map的size。該模塊的輸出size為輸入圖像size的一半,通道數為16,其中Conv路徑輸入13通道,MaxPooling輸出3通道(原來的RGB通道),故總共16通道。可以看出,輸入圖像首先經過initial block,feature map size就能將為一半,這無疑極大減少了後面的計算量,從而提升inference時的速度。
2.2.bottleneck module
另一種block是bottleneck module,該block是ENet的基本構成單元(如Inception之於GoogLeNet),如圖(b)。該模塊科充當Conv、DownSampling、UpSampling三個功能。它分為主分支和副分支:主分支是MaxPooling+Padding操作,該分支只有在下采樣時才起作用,其他情況下操作為空:副分支為1*1Conv+Conv+1*1Conv,第一個1*1Conv用來降低通道數,第二個Conv是正常的Conv,用於提取特徵信息,第三個1*1Conv是用於增加通道數。所以,這三個Conv連用起來的意思無疑很明顯了,先通過1*1Conv通道數降低維度,然後再用正常的Conv來提取特徵,最後再用1*1Conv拔通道數提升回去,從而能夠降低總的參數個數和計算量,故能夠提升速度。
那麼如何區別是Conv操作,是DownSampling操作,還是UpSampling操作?
(1)當是模塊作為DownSampling操作時,主分支開啓,主分支是一個kernel=2*2,stride=2的MaxPooling。副分支的第一個1*1Conv改為同樣的kernel=2*2,stride=2的MaxPooling,這樣主副分支才能同樣達到二倍下采樣的效果(注意,副分支的第二個Conv是需要通過padding保持feature mpa size不變,三種操作都如此)。副分支的第二個Conv應該是空洞卷積吧?
(2)當模塊作為Conv操作時,主分支屏蔽,副分支正常,其中副分支中間的Conv可以是正常Conv、空洞Conv,甚至是5*1Conv+1*5Conv的不對稱卷積(asymmetric convolution,這個不懂)。kernel_size可以是3*3或者5*5。但不管如何,都要通過padding維持feature map size不變。
(3)當模塊作為Upsampling操作時,主分支屏蔽,副分支的第二個Conv改為Deconvolution,即反捲積。但論文又提到上採樣用的是下采樣時的index,就如SegNet那樣。那究竟是使用Deconvolution還是使用index?
2.3.整體結構
ENet網絡的整體結構如下,可以看出encoder比decoder複雜。

3.設計選擇
3.1.特徵圖分辨率
在語義分割中,下采樣有兩個缺點:(1)空間信息的丟失,如邊緣形狀。而且強下采樣會損害精確率。(2)強下采樣就需要強上採樣才能回覆原來的分辨率,這意味着需要更大的模型複雜度。
但是,下采樣又有一個好處:能夠增大感受野。為了能夠增大感受野,又不丟失空間信息和增加模型複雜度,下采樣通過空洞卷積實現。
3.2.早期下采樣
早期下采樣是很重要的,因為原始輸入圖像的size很大,因此計算花費很大。ENET通過initial block大大降低了輸入size,輸出一小集合特徵圖。其依據就是:(1)可視化信息在空間上是高度冗餘的,因此它們可以被壓縮在一個更高效的表示裏。(2)前面的層並非直接對分類作出貢獻。
3.3.Decoder size
一般而言,在分割網絡中:encoder大,decoder小。因為encdoer的作用是從原始圖像中提取信息,而decoder只是對encoder的結果進行上採樣、微調信息。所以decdoer可以比encoder簡單些。
3.4.Nonlinear operations
3.5.Information-preserving dimensionality change
3.6.Factorizing filters
3.7.Dilated convolution
3.8.Regularization