
在機器學習的分類算法裏,有一類算法特別 “直觀”—— 它不用複雜的概率計算,也不用繞人的公式,而是像我們日常生活中的 “判斷流程” 一樣,一步一步得出結論。它就是決策樹(Decision Tree)。
本文會從一個真實的銀行貸款場景切入,幫你看懂決策樹的判斷邏輯,再抽象出決策樹的核心定義和結構,終於講清它如何幫我們解決分類問題。全程無複雜公式,純入門友好,看完就能學會 “用決策樹做判斷”。
一、從銀行貸款案例,看懂決策樹的 “日常邏輯”
大家先從一個銀行的實際挑戰説起:銀行給用户放貸款前,最關心的是 “該用户能不能按時還款”。如果憑感覺判斷,很容易出錯;但假設有一套固定的判斷流程,就能高效又準確。
銀行根據經驗,總結出了三個影響 “還款能力” 的關鍵特徵:
- 是否擁有房產(有 / 無)
- 是否結婚 / 否)就是(
- 平均月收入(>6000 元 / ≤6000 元)
一棵簡單的決策樹:就是然後,銀行制定了一套判斷流程 —— 這套流程,其實就
1. 詳細判斷流程(跟着走一遍就懂)
我們拿 3 個申請貸款的用户舉例,跟着流程判斷:
- 用户 A:沒房產、沒結婚、月收入 8000 元第一步:看 “是否有房產”→ 無;第二步:看 “是否結婚”→ 否;第三步:看 “月收入”→ >6000 元;結論:可以償還貸款。
- 用户 B:沒房產、沒結婚、月收入 5000 元第一步:無房產;第二步:沒結婚;第三步:月收入≤6000 元;結論:不能償還貸款。
- 用户 C:沒房產、已結婚、月收入 4000 元第一步:無房產;第二步:已結婚;結論:可以償還貸款(不用看月收入了)。
2. 把流程畫成 “樹”:決策樹的直觀形態
我們把上面的判斷流程,用 “樹” 的形式畫出來:
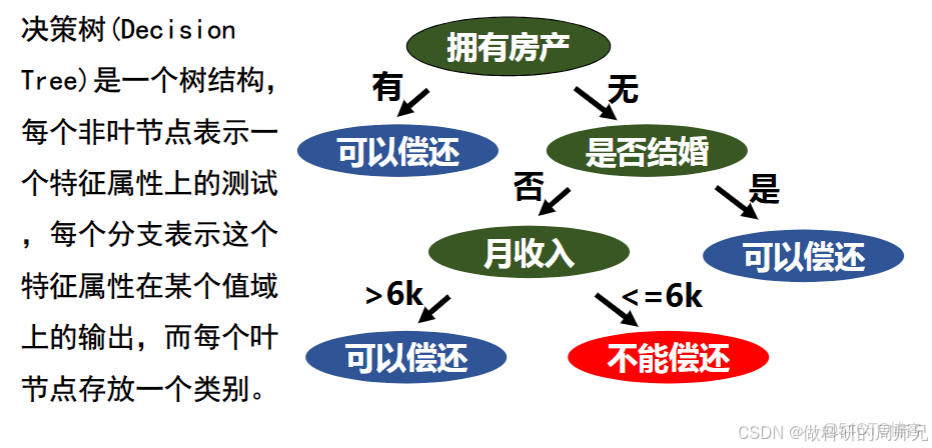
圖片來源於網絡,僅供學習參考
決策樹最本質的樣子。就是從這個 “樹” 裏,我們能清晰看到:每一步判斷對應一個 “節點”,每一個選擇對應一個 “分支”,末了的結論對應一個 “葉子”—— 這就
二、決策樹的正式定義:拆解開的 “樹結構”
從上面的貸款案例,大家能夠抽象出決策樹的正式定義:決策樹是一種基於 “樹結構” 的分類器,它通過對特徵屬性的逐步測試,將數據分到不同的類別中。整個樹由 “非葉節點”“分支” 和 “葉節點” 三部分組成,每一部分都有明確的作用。
我們結合貸款案例,逐一拆解這三個核心組成部分:
1. 非葉節點:“大家要判斷什麼?”
非葉節點(也叫 “內部節點”)代表一個特徵屬性的測試—— 簡單説,就是 “這一步我們要問哪個問題”。比如貸款案例中的 “是否擁有房產”“是否結婚”“平均月收入”,都是非葉節點:它們的作用是提出 “測試問題”,引導後續的判斷方向。
非葉節點有個特點:它下面一定會分出多個分支(因為一個特徵至少有 2 個取值,比如 “有房產” 和 “無房產”),不會直接出結論。
什麼?”就是2. 分支:“這個問題的答案
分支代表非葉節點(特徵測試)在某個值域上的輸出—— 也就是 “問題的具體答案”。比如 “是否擁有房產” 這個非葉節點,分出的 “有” 和 “無” 就是兩個分支;“平均月收入” 分出的 “>6k” 和 “≤6k” 也是分支。
每個分支都對應一個 “下一步方向”:要麼指向另一個非葉節點(需要繼續判斷),要麼指向葉節點(直接出結論)。
3. 葉節點:“最終結論是什麼?”
葉節點是決策樹的 “終點”,它存放着一個具體的類別—— 也就是我們最終要得到的分類結果。比如貸款案例中的 “可以償還” 和 “不能償還”,都是葉節點:一旦判斷走到葉節點,就不用再往下走了,直接取葉節點的類別作為結果。
葉節點的特點:它下面沒有任何分支,是 “判斷的終點”。
三、決策樹的核心作用:從 “訓練” 到 “分類”
決策樹不是天生就有的,它必須通過 “訓練數據” 構建出來;構建好之後,就能用它對 “未知數據” 做分類。這兩步是決策樹的核心應用流程,我們結合貸款場景講清楚:
1. 第一步:用訓練數據 “構建決策樹”
否還款”(類別)。就是銀行不會憑空想出上面的判斷流程,而是通過 “過去的貸款素材”(也就是訓練數據)總結出來的。訓練數據裏包括很多 “歷史用户” 的信息:每個用户的 “是否有房產、是否結婚、月收入”(特徵),以及 “最終
比如訓練數據裏有 100 個用户,銀行發現:
- 有房產的 80 個用户裏,90% 都還款了 → 所以 “有房產” 直接對應 “可以償還”;
- 沒房產但結婚的 15 個用户裏,80% 還款了 → 所以 “沒房產 + 結婚” 對應 “可以償還”;
- 沒房產沒結婚的 5 個用户裏,只有月收入 > 6k 的 2 人還款了 → 於是要加 “月收入” 的判斷。
“決策樹的訓練”。就是依據分析訓練數據中 “特徵” 和 “類別” 的關係,銀行就能構建出前面那棵 “貸款決策樹”—— 該過程就
2. 第二步:用構建好的決策樹 “分類未知內容”
當有新用户(未知數據)申請貸款時,銀行就用已經構建好的決策樹做判斷:從決策樹的 “根節點”(第一個非葉節點,比如 “是否擁有房產”)開始,根據新用户的特徵,一步步順着分支往下走,直到走到葉節點,葉節點的類別就是 “這個用户是否能還款” 的分類結果。
通過比如新用户 “小李”:沒房產、沒結婚、月收入 7000 元。判斷流程:根節點(無房產)→ 下一個節點(沒結婚)→ 下一個節點(月收入 > 6k)→ 葉節點(可以償還)。最終分類結果:小李能夠償還貸款。
這個過程就像 “順着地圖找終點”,非常直觀,不用做任何複雜計算 —— 這也是決策樹比其他算法(比如樸素貝葉斯)更易理解的原因。
四、入門必知的 2 個關鍵提示
1. 看懂決策樹的核心:“從根到葉,一步一步走”
對入門者來説,不用一開始就糾結 “決策樹怎麼構建”,先學會 “怎麼用現成的決策樹做判斷”。記住一個簡單手段:從根節點(第一個判斷)開始,根據數據的特徵選分支,一直走到葉節點,葉節點的類別就是結果。就像走迷宮一樣,跟着分支走,終點就是答案。
2. 決策樹的本質:“分而治之” 的思想
決策樹能解決分類問題,核心是 “分而治之”—— 把 “判斷用户是否還款” 這個複雜疑問,拆成 “先看房產→再看婚姻→最後看收入” 這三個簡單的小判斷。每個小判斷都很容易做,把這些小判斷的結果彙總起來,就處理了複雜的大問題。這種 “拆複雜、做簡單” 的思路,也是很多機器學習算法的核心,理解它能幫你更快入門其他算法。
總結
決策樹是機器學習入門階段最 “接地氣” 的分類算法之一:它像一張 “判斷流程圖”,用 “非葉節點提難題、分支給答案、葉節點出結論” 的方式,把繁瑣的分類疑問變得直觀又簡單。
對剛入門的同學來説,你不需要一開始就掌握決策樹的構建細節(比如怎麼選第一個判斷的特徵),先試着 “順着決策樹走一遍判斷流程”,比如用貸款案例中的樹,給身邊的人 “模擬判貸款”,就能輕鬆理解它的核心邏輯。
下一篇我們會深入講 “決策樹怎麼構建”(比如為什麼先判斷 “房產” 而不是 “收入”),但對現在的你來説,先吃透 “判斷流程”,就是理解決策樹的最好開始~