
操作指南
操作指導
AI平台 國內直接訪問地址:https://sass.xiaoxuzhu.cn/
點擊【新系統登錄】

註冊後登錄即可。
選擇GPT-5.2大模型
GPT-4o 上半年那波爆火,確實把奧特曼都逼到“GPU 要融了”的邊緣🤣 也順手把“生圖 + 視覺理解”徹底捲成了各家大模型的標配賣點。但到了今年下半年,真正把存在感刷滿的反而是那根“香蕉”——Nano Banana 🍌為了把“王座”再搶回來,OpenAI 今天直接端上新菜:最新圖像視覺模型 GPT-Image-1.5。這也是繼 GPT-5.2 之後,OpenAI “紅色警報計劃”裏又一發狠招。省流版:
- 指令執行更準
- 編輯更細更穩
- 細節保留更完整
- 速度比之前快 4 倍 🚀
告別「抽卡式改圖」,這次是真的能指哪改哪了 😄GPT-Image-1.5 最大的提升,其實就四個字:精準編輯。以前用 AI 修圖,體驗就像遇到一個完全不聽需求的託尼老師:
你説“幫我修下劉海”,它理解成“要不直接剃光吧”。
改一點,畫面直接崩一片,全靠運氣反覆抽卡。但這代模型,終於聽得懂人話了。
你點哪兒,它就只動哪兒;
不讓它動的地方,真的能給你穩穩留住。更關鍵的是一致性拉滿:
光線不亂、構圖不飄、人物特徵前後統一,
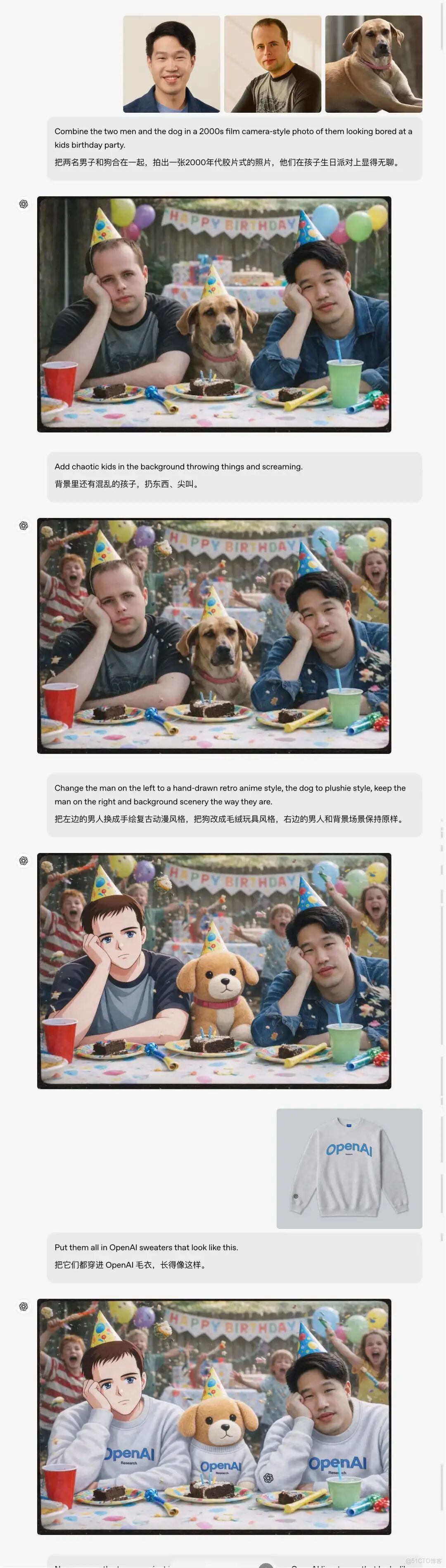
從首次生成 → 二次編輯 → 多輪修改,整個流程像在一個閉環裏完成。官方給的示例也挺直觀,一步步看下來就懂了 👇
- 先生成一張 2000 年代膠片風格的兒童生日派對照,畫面裏是兩個男人和一隻狗
- 接着 往背景里加一羣吵鬧、亂扔東西的小孩
- 再把 左邊的男人改成復古手繪風格,狗改成毛絨玩具,右邊男人和背景完全不動
- 然後 給所有人統一換上 OpenAI 毛衣
- 最後更狠:只保留那隻狗,直接把它丟進一場 OpenAI 的直播現場
重點不在“能不能生成”,而在於:
每一步改動,都是局部、可控、不中途翻車。一句話總結:
這次不再是拼運氣的“抽卡修圖”,
而是真正開始像在用 PS 一樣“精修 AI 圖像”了 🚀
上下滑動查看更多內容
一整套操作打完,畫面居然一點都沒亂,這事本身就很説明問題了。
這意味着 GPT-Image-1.5 已經不是在“碰運氣”畫圖,而是真的能理解畫面裏的結構關係,能做到增、刪、改、查都在線。
而且關鍵是——改得準,還穩得住,這才是當下真正拉開差距的技術護城河 💪。再説點更直觀的。
下面這些,都是我自己親手測過的案例 👀。你可能看過《千里江山圖》這幅傳世名作,
但説實話,你大概率還漏看了億點點細節。
而這些細節,恰恰就是這類模型最容易翻車、也最能體現功力的地方 🤯。

同理可得,誰説《百駿圖》裏,不能突然出現一隻從現代穿越過來的網紅柴犬 Kabosu。

就連馬斯克和扎克伯格那場沒打成的籠中決鬥,在 GPT-Image-1.5 的加持下,一次性就成功把主角換成了奧特曼。臉沒崩,違和感也幾乎為零。

這次我們想要的是一張細節拉滿、寫實風格的極端仰拍照片:
馬斯克坐在珠江岸邊,一隻手隨意搭在廣州塔塔尖上。為了把“巨物感”拉到極致,還特地在他腳邊放了小到幾乎看不清的遊船和遊客。結果嘛——
它不僅聽懂了需求,還真理解了什麼叫「比例感」。
整體尺度、遠近關係、視覺衝擊,全都在線,看一眼就知道這不是普通合成 😄説白了,就是那種一眼離譜,但細想又很合理的感覺。

提示詞:一張細節豐富、逼真寫實的極端仰拍照片,畫面中的馬斯克正在坐在珠江岸邊,一隻手搭在廣州塔的塔尖上,為了體現巨大的體型比例,可在他的腳邊加入一些微小的遊船、觀光遊客等,2K,16:9
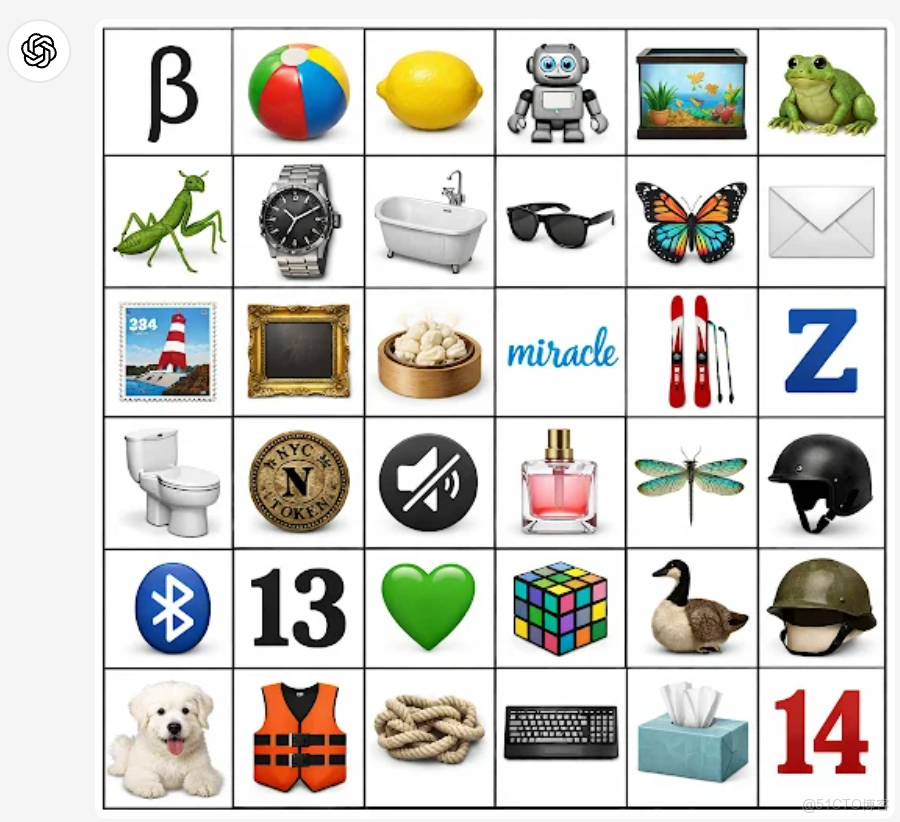
終於告別“鬼畫符”,但中文表現嘛……還有提升空間 😅和初代圖像模型比起來,GPT-Image-1.5 在“聽話”這件事上進步很大。複雜、細緻的指令它基本都能照做,而且還能穩穩地維持各個元素之間原本設定好的關係。官方放了個 6×6 網格 的示例圖,每一行都有明確要求:希臘字母、動物、物品、圖標、單詞輪番上陣,結果排得那叫一個整齊。説真的,強迫症看到都會默默點個贊,太治癒了 🤌✨
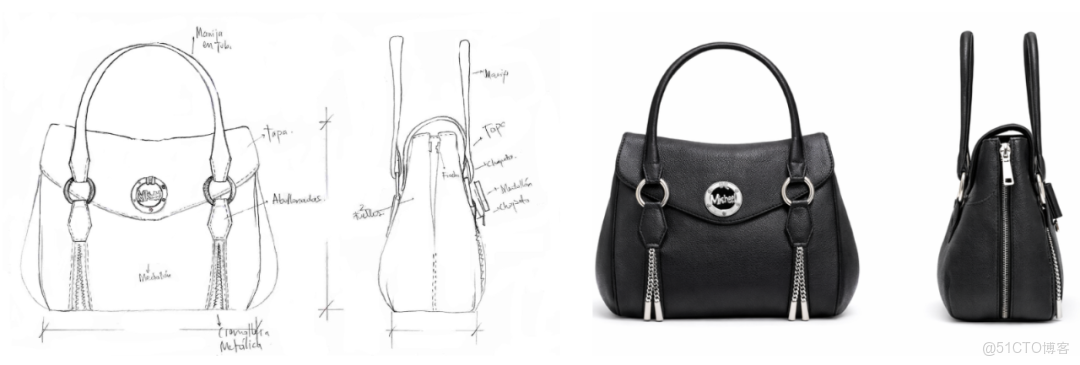
經過實測,把線稿轉成真實圖片這種操作,現在也成了基操。
文本渲染這塊也明顯更強了👍
現在對那種密集內容、小字號的處理更穩更細。舉個例子,把一整段 Markdown 直接轉成報紙風格的文章排版完全沒問題,像 GPT-5.2 的發佈説明、性能跑分對比這些內容,都能排得很自然。關鍵是格式不亂、數字不丟、細節很準,讀起來就像已經編輯過一樣,而不是“AI 隨便排一下”的感覺 📰✨

這個功能乍一聽好像沒啥存在感,但真到要做海報、宣傳圖、信息圖的時候,你就會發現——這玩意兒就是剛需啊 😅在 Nano Banana Pro 之前,生成式 AI 的文字渲染基本屬於“抽象藝術”,能不能看懂全靠腦補。現在總算是能入眼了,這點必須承認 👍
不過話也不能説太滿,還是得潑點冷水:GPT-Image-1.5 在英文上確實很強,但一到中文就直接翻車🚑我讓它畫一組「擎天柱征服火星」的中文漫畫,結果它給我整出了一套全新的“火星文體系”👽
看得出來它很努力,但真的……一個字都不認識 😂

亦或者讓其生成一張古人在牆壁寫水調歌頭的圖片,不僅文字錯漏百出,握筆姿勢還居然是拿鋼筆的手法。

整體體驗還不錯👍
速度是真的快,直接提了 4 倍。一邊還在畫圖,另一邊已經能同時開好幾個新任務跑起來了,隨便試、隨便改,試錯成本一下子降了很多🚀。
對物體和常識的理解也還挺靠譜,比如我隨口問了句“往水裏加鹽雞蛋會怎樣”,它給出的畫面還真有點那意思,看着挺像那麼回事😄。

左為原圖,右為生成的圖片。提示詞:如果往水中加入大量鹽,生成一張圖片,展示雞蛋會發生什麼。
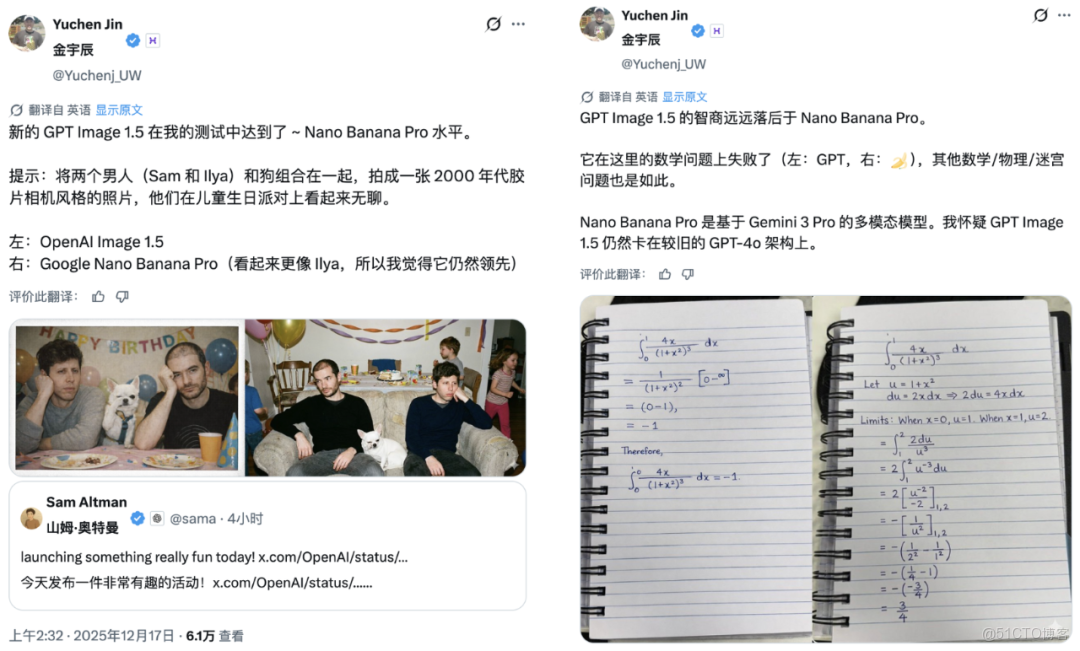
博主 @Yuchenj_UW 的看法是:GPT-Image-1.5 在生成效果上,基本已經摸到了 Nano Banana Pro 的「專業級」門檻;但在智商/推理能力這塊明顯跟不上,尤其是做數學題時差距更大,像物理題、迷宮類問題的表現也要遜色不少。🤔📉
你的下一位設計師,真的非得是人嗎?🤖
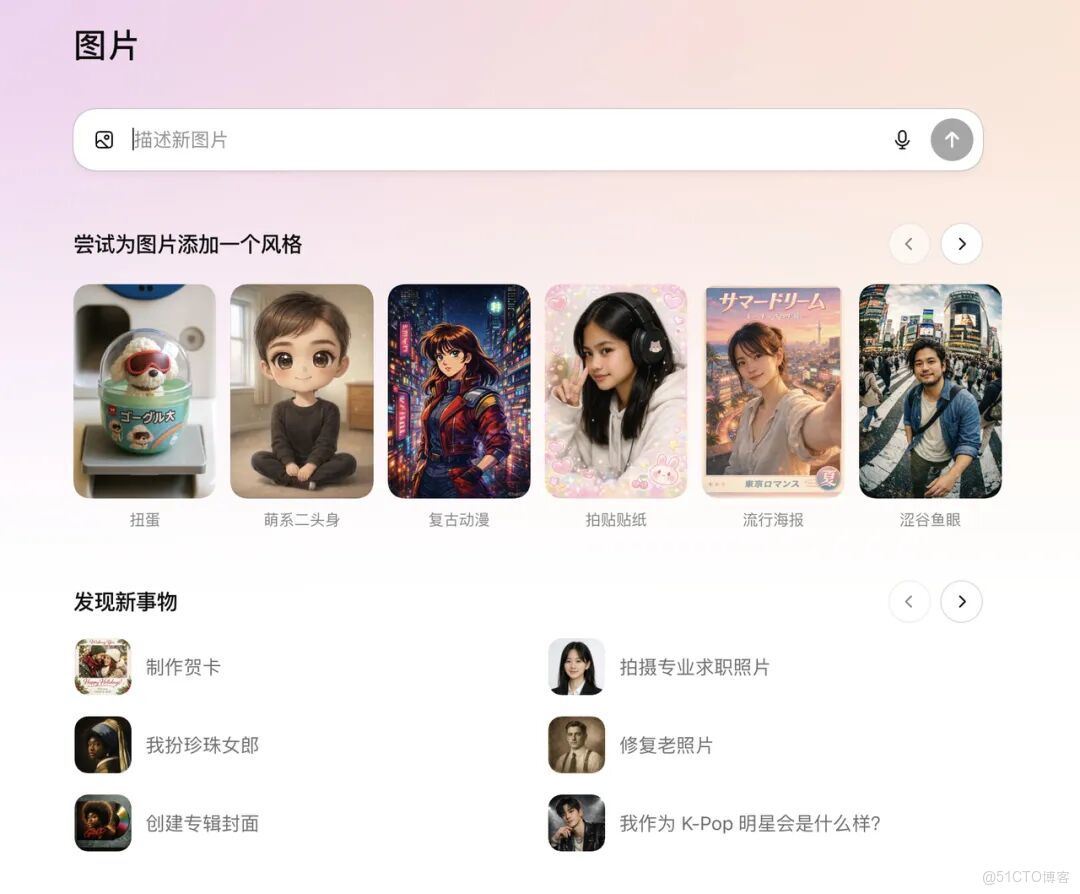
ChatGPT 這次直接申請出戰。OpenAI 最近在 ChatGPT 裏單獨搞了個圖像創作入口,不管網頁端還是手機端,側邊欄一眼就能看到。點進去就是一整套預設風格、熱門提示詞,而且還會持續更新。
更省事的是——只要傳一次人像,後面生成的圖全是你本人,不用每次都反覆喂圖,懶人狂喜 😎。不過説句實在的,這套玩法 Nano Banana 沒有,但國內的生圖模型早就玩得很熟了。從這個角度看,GPT-Image-1.5 更像是在“摸着國內同行的石頭過河”。有意思的是,奧特曼剛剛還在社交媒體上曬了成果:
用 GPT-Image-1.5 生成了一組聖誕主題的性感月曆男模照🎄🔥
懂的都懂,這波算是官方親自下場帶節奏了。AI 當設計師這事兒,看來是真的要成日常了。

來都來了,我們也順手給奧特曼換了幾套皮膚。貼紙風、搖頭娃娃風、素描風,預計今天過後,奧特曼又要成為互聯網上最忙的男人。

有個細節很值得點贊,當你要求生成預設方案時,OpenAI 會公開預設的提示詞。從這一點來看,OpenAI 確實 open 了。
除此之外,製作賀卡、創建專輯封面,修復老照片,拍攝專業求職照片等也都是非常實用的預設方案。比如,那張經典的魯迅和泰戈爾的合照,經過修復後,其實效果還是挺不錯。

OpenAI 應用 CEO Fidji Simo 在博客裏提到一個挺有意思的觀點:人類的思考並不只是文字。很多真正有創意的想法,其實最早是以畫面、聲音、動作,甚至某種模式的形式出現在腦海裏的。她也順勢透露了 ChatGPT 的進化方向——它正在從一個“你問我答、以文字為主”的工具,慢慢變成一個更直覺、更貼合真實工作場景的助手。從純文本走向多媒體、動態界面,是這條路上非常關鍵的一步。不少人第一次玩 ChatGPT,就是拿它來生成圖片。但問題也來了:聊天框本身其實並不適合幹這事。圖像創作和編輯,本質上是另一種完全不同的任務,需要更大的視覺空間和更自由的操作方式。所以 OpenAI 乾脆不折騰聊天框了,直接給圖像生成單獨做了個入口,讓它更像一個創意工作室,而不是在對話裏“硬擠”出來的功能。整體思路很清晰:該聊天的地方聊天,該創作的地方,就給你一個真正適合創作的環境 🎨✨
當然可以~我幫你換一種更自然、偏“IT自媒體博主”的説法👇😊
OpenAI 的規劃顯然不止這些。接下來,ChatGPT 還會加入更多視覺化設計,整體體驗會繼續升級。
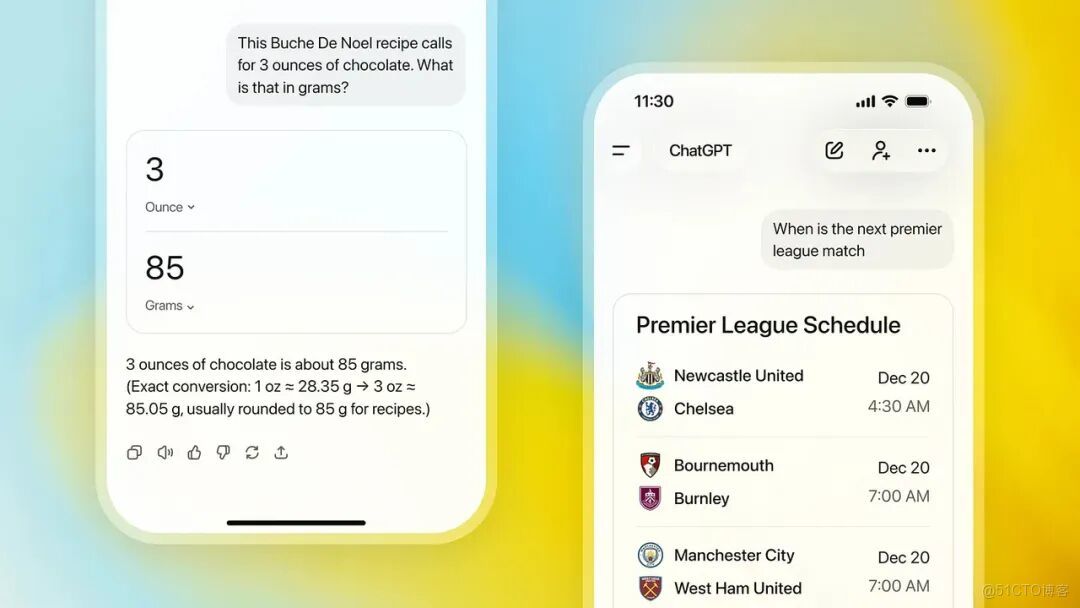
比如以後你用它來搜索信息,結果裏會有更多圖片,而且來源也更清晰可信。像單位換算、查體育比分這種場景,用户真正想要的是一眼就懂的可視化結果,而不是讀一大段文字説明。簡單説,就是少廢話,多直觀,用起來更爽🚀
可以明顯感覺到,寫作這件事本身也在被重塑 ✍️
以後 ChatGPT 裏會直接內置寫作編輯模塊,邊聊邊改,改完還能一鍵導出 PDF,或者直接拉起郵件發出去,整個流程非常順。説白了,它早就不只是“會聊天的模型”了,而是在往多模態工作台的方向進化。而且這波升級不只照顧普通用户,開發者同樣有得玩 🚀
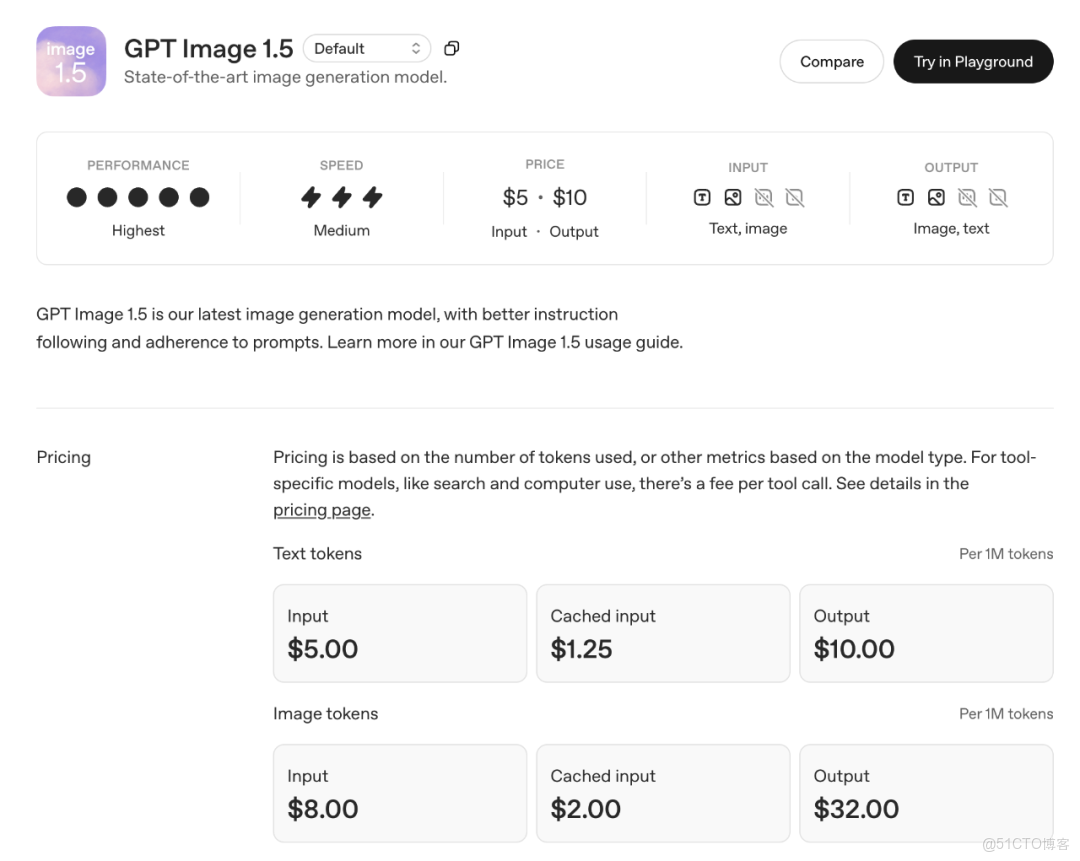
通過 API 就能直接用上 GPT-Image-1.5。和 GPT-Image-1 比起來,1.5 在品牌元素和關鍵視覺的一致性上強了不少,特別適合電商、品牌營銷這種要批量出圖、但又不能跑偏風格的場景。更實在的是——圖像輸入輸出成本直接降了 20%,同樣的預算,能多生成不少圖,性價比拉滿 💰整體看下來,這已經不是“功能加一點”的升級,而是生產力工具形態在變。你怎麼看?😄
降價疊加提效,這一波組合拳打得確實挺到位的 👍
另外,迪士尼上週也官宣了一件大事:向 OpenAI 投了 10 億美元,雙方正式牽手合作 🎬🤝根據這份 為期三年的授權協議,OpenAI 旗下的 Sora 和圖像生成模型,都可以直接生成 迪士尼、漫威、皮克斯以及星球大戰相關角色。
如果進展順利,相關功能預計 明年初上線,想象空間一下子就拉滿了 🚀✨

內容 IP + AI 生成,這事兒的想象空間真的不小 🚀
更關鍵的是,GPT-Image-1.5 的出現,算是一個明顯的分水嶺——圖像生成工具,終於開始從「好玩」走向「好用」。之前很多 AI 改圖工具都有個通病:一動就翻車,風格、人物、細節全亂,基本談不上穩定性。但 GPT-Image-1.5 至少在這條路上邁出了實打實的一步 👍。它已經開始具備類似後期編輯的能力,能像 Nano Banana Pro 那樣控細節,讓畫面前後保持一致,而不是每次重來。在模型本身還沒拉開巨大差距的情況下,GPT-Image-1.5 選擇了另一條更聰明的路:用更成熟的生成預設和功能設計,正面硬剛新版 Nano Banana。比如獨立的圖像創作入口、現成的濾鏡庫這些看似不起眼的設計,其實正好戳中了普通用户的痛點 🎯。説白了,大多數人並不追求“最強模型”。他們要的是:
- 上手快
- 不用反覆調參數
- 出圖效果大概率靠譜
只要八九不離十,就已經很香了 😄。模型能力領先只是起點,真正的護城河,是能不能把這些能力打包成好用、易用、讓人願意天天用的產品。這一點上,GPT-Image-1.5 已經給了一個挺有説服力的答案。
感受
好用的功能太多太多,我就不在這個一一列舉了,有興趣的可以自行嘗試。
有提供免費的授權碼可體驗~
有提供免費的授權碼可體驗~
有提供免費的授權碼可體驗~
私信虛竹哥,獲取體驗碼~國內可直接使用~

我是虛竹哥,目標是帶十萬人玩轉AI。