

遷移學習
背景
在深度神經網絡算法的應用過程中,如果我們面對的是數據規模較大的問題,那麼在搭建好深度神經網絡模型後,我們要花費大量的算力和時間去訓練模型和優化參數,最後耗費了這麼多資源得到的模型只能解決這一個問題,性價比非常低。
如果用這麼多資源訓練的模型能夠解決同一類問題,那麼模型的性價比會提高很多,這就促使使用遷移模型解決同一類問題的方法出現。因為該方法的出現,我們通過對一個訓練好的模型進行細微調整,就能將其應用到相似的問題中,最後還能取得很好的效果;另外,對於原始數據較少的問題,我們也能夠通過採用遷移模型進行有效解決,所以,如果能夠選取合適的遷移學習方法,則會對解決我們所面臨的問題有很大的幫助。
一句話總結:對同一類問題,使用已訓練好的模型進行微調來作為適配新問題的模型,這個操作就是遷移學習
遷移學習介紹
遷移學習(Transfer Learning)是一種機器學習方法,它利用一個已經訓練好的模型來解決新的問題。在深度學習中,遷移學習通常指的是將一個預訓練的神經網絡模型應用於新的任務或數據集上,以減少訓練時間和提高模型性能。或者説遷移學習就是把一個領域(即源領域)的知識,遷移到另外一個領域(即目標領域),使得目標領域能夠取得更好的學習效果。
形象化理解遷移學習,就是利用已有的知識來解決新問題。這就好比,Google 和百度的關係,dota和LOL關係, KFC 和 麥當勞的關係, 同一類型的事業, 不用自己完全從頭做, 借鑑對方的經驗, 往往能節省很多時間.。有這樣的思路,可以不用花大量時間精力重新訓練一個無比龐大的神經網絡, 只要借鑑一個已經訓練好的神經網絡就行。
遷移學習的作用和應用場景
- 數據稀缺:當目標數據集較小且難以收集大量標註數據時,遷移學習可以幫助利用已有的大型數據集上的預訓練模型,從而減少對大量標註數據的依賴。
- 加快訓練速度:使用預訓練模型可以大大減少在新任務上的訓練時間,因為大部分權重已經被優化過了,只需對特定層的權重進行微調即可。
- 提高模型性能:預訓練模型通常在大型數據集上經過長時間訓練,具有較好的特徵提取能力。通過遷移學習,可以在新任務上獲得更好的性能。
- 跨領域應用:遷移學習不僅限於計算機視覺領域,還可以應用於自然語言處理、語音識別等多個領域。
- 微調與凍結:在遷移學習中,常見的做法是凍結預訓練模型的部分層(通常是前面的幾層),只對後面的層進行微調。這樣可以保持模型的基本特徵提取能力,同時適應新的任務。
遷移學習理解
- 遷移學習允許我們將一個預訓練模型應用於新的任務。通過微調(Fine-Tuning)預訓練模型,我們可以利用已經學習到的特徵表示,使模型更好地適應特定任務。
假設現在有兩個任務一個是TASK A,一個是TASK B。其中TASK B是我們的目標任務,進行貓狗分類。TASK A是其他人做出來的網絡模型(預訓練模型)。
TASK A可能是個非常大的任務,它對數據、計算資源和時間的要求都非常高,但好處是,這些是別人已經訓練好的任務。
TASK B是我們的目標任務,這個任務沒有那麼大,因為它的樣本量只有幾百張圖像,沒有到上千萬這樣的級別。樣本量小帶來的好處是計算量小,但壞處是如果需要訓練一個更加複雜模型時,樣本量就不夠了。
這時候,我們可以把TASK A訓練好的模型結構和權重直接應用到TASK B上,,但是需要注意以下兩個問題:
(1)輸入問題。輸入相對來説比較簡單,無論哪個TASK,它的輸入都是圖像,我們只要保證兩個任務中輸入圖像的像素相同即可。
(2)輸出問題。TASK A的輸出可能是為了區分1000個類別,但是我們的TASK B簡單很多,只分為兩類。
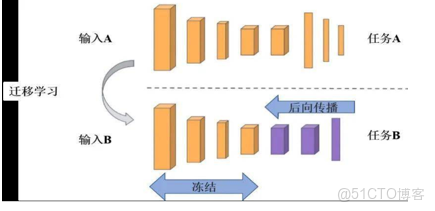
那麼如何解決輸出問題呢?
- 最簡單的辦法就是把TASK A整個模型中最後面的那幾層輸出(通常是全連接層),替換成TASK B想要的形式,例如,貓狗分類,只需要最終輸出兩個節點。
- 我們要清楚,一般在圖像分類的問題當中,卷積神經網絡最前面的層用於識別圖像最基本的特徵,比如物體的輪廓,顏色,紋理等等,而後面的層才是提取圖像抽象特徵的關鍵,因此我們只需要使用TASK A前面的網絡層級,對後面的全連接層進行重新訓練即可(模型微調)。
遷移學習的幾種方式
- 凍結預訓練模型的全部輸入層和隱層,只訓練自己定製的全連接層(輸出層)。
- 凍結預訓練模型的部分網絡層,訓練剩下的網絡層和全連接層。
- 獲取預訓練模型的參數值作為新模型參數的初始化的值,然後拋開預訓練模型,只訓練自己定製的網絡模型,以此增加新模型的收斂速度。
網絡層凍結
概述
當我們想要對一個預訓練模型進行微調(fine-tuning),或者僅僅只想訓練模型中的某些特定層時,就需要用到“凍結”這個概念了。凍結部分參數的意思是在模型訓練過程中保持這些參數不變,這在遷移學習中非常常見。
什麼是凍結?
凍結是指在模型訓練過程中,阻止模型的一部分參數進行更新。在深度學習中,我們經常使用預訓練模型作為初始權重,然後僅對特定層進行微調。
凍結整個模型
如果你希望凍結整個模型,你可以這樣操作:
import torch.nn as nn
from torchvision import models
model = models.resnet18(pretrained=True)
for param in model.parameters(): #返回模型所有網絡層的權重係數
param.requires_grad = False
#上面的代碼將會凍結整個ResNet18模型的所有參數。此時如果繼續訓練模型,所有參數都不會更新。凍結模型的特定部分
如果你只需要凍結模型的某些部分網絡層,可以按照下面的方式來做:
# 假設model是一個ResNet18模型
for name, param in model.named_parameters():#返回網絡層名字和其對應的權重係數
if 'layer4' not in name: # 只凍結除了layer4之外的所有層
param.requires_grad = False解凍
解凍就是將之前凍結的參數重新變為可訓練狀態,這可以通過將requires_grad屬性設置為True來完成。
for name, param in model.named_parameters():
if 'layer4' in name: # 只解凍layer4
param.requires_grad = True