
目錄
寫在前面
一、知識蒸餾(KD):讓大模型當老師,小模型當學生
1.怎麼教?軟標籤與推理過程一起學
2.多老師合作與自我學習
二、數據集蒸餾(DD):把萬噸數據壓縮成一勺精華
1.兩種核心方法
2.智能數據篩選
三、KD+DD組合拳:實戰中的高效搭配
四、未來挑戰:瘦身不能丟“靈魂”

寫在前面
我們來看一篇關於大型語言模型的知識蒸餾與數據集蒸餾的綜述,主要講了兩大技術:知識蒸餾(KD)和數據集蒸餾(DD)。簡單説,KD是讓笨重的大模型(老師)把本事教給輕巧的小模型(學生),而DD則是把海量訓練數據濃縮成一小瓶“精華液”,讓訓練效率暴增。下面我用大白話展開説説核心內容,並配上原文裏的示意圖幫你理解。
論文地址:https://arxiv.org/pdf/2504.14772
一、知識蒸餾(KD):讓大模型當老師,小模型當學生
知識蒸餾的核心思想是“授人以漁”。比如GPT-4這樣的大模型雖然厲害,但部署成本太高,KD就能把它複雜的推理能力“教”給更小的模型。
1.怎麼教?軟標籤與推理過程一起學
傳統方法只讓學生模仿老師的最終答案(硬標籤),但KD讓學生學習老師輸出的“概率分佈”(軟標籤)。比如老師判斷“圖片是貓”的置信度是90%,“是狗”是10%,學生不僅要學“貓”這個結果,還要學這種不確定性。

更高級的“理性蒸餾”還會讓學生學習老師的思考過程(比如解數學題時的步驟),而不僅是答案。
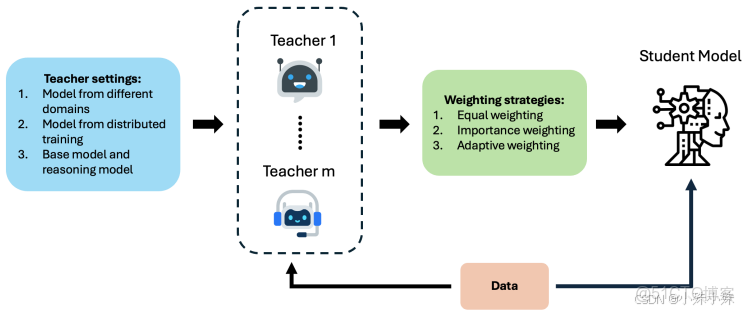
2.多老師合作與自我學習
有些場景會請多個專業老師(比如醫療、法律模型各一個)同時教一個學生,整合不同領域的知識。還有一種“自蒸餾”,讓模型自己教自己——用深層網絡部分教淺層部分,相當於學霸給自己劃重點。
二、數據集蒸餾(DD):把萬噸數據壓縮成一勺精華
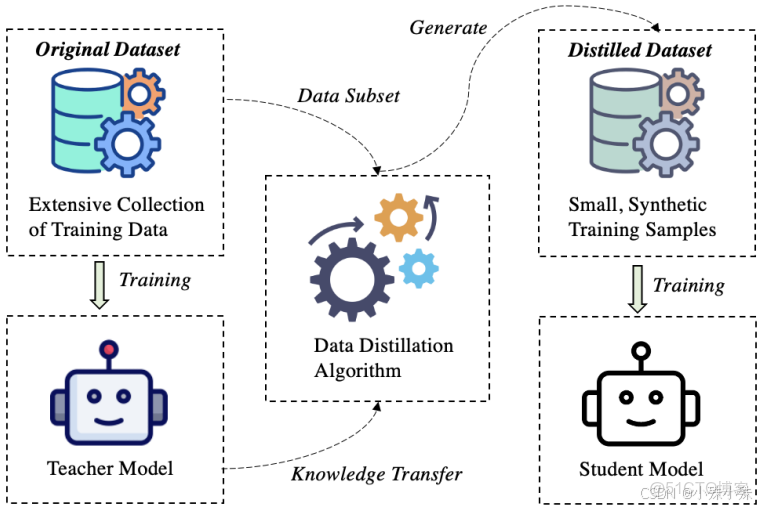
如果原始數據相當於一整座圖書館,DD就是做成一張精華知識卡片。它能將百萬級數據壓縮到幾百條,但訓練效果接近原數據集。
1.兩種核心方法
(1)優化法:通過算法反覆調整合成數據,讓用小數據訓練模型的梯度變化與用大數據時一致。
(2)生成法:用AI生成數據(比如GPT合成問答對),替代部分真實數據。
2.智能數據篩選
類似挑重點複習,DD會優先選擇多樣性強、信息量大的數據。比如用嵌入模型計算文本相似度,去除重複內容;或用困惑度評分過濾低質量文本。
三、KD+DD組合拳:實戰中的高效搭配
在醫療、教育等領域,結合兩者能大幅降低成本。例如:
1.醫療診斷:用DD提煉病歷數據,再通過KD讓小模型學會大模型的診斷邏輯;
2.教育評分:將批改作文的大模型知識蒸餾到輕量模型,快速評估學生作業;
3.生物信息:壓縮蛋白質數據後,用小模型預測結構,效率提升70%。
四、未來挑戰:瘦身不能丟“靈魂”
當前技術仍面臨三大難題:
1.保留深層能力:小模型容易丟失邏輯鏈推理等複雜技能;
2.動態更新難:老師模型升級後,學生模型可能跟不上;
3.可靠性風險:若老師模型有偏見,學生會“學歪”,需要增加不確定性校準。
總結來説,這篇論文系統梳理了大語言模型的知識蒸餾(KD)與數據集蒸餾(DD)技術,探討了如何通過這兩種互補的範式來壓縮模型規模、提升數據效率,同時保留模型的複雜推理能力和語言多樣性,並分析了其集成方法、應用場景以及未來在可持續、資源高效的大型語言模型發展中所面臨的挑戰與方向。