
機器學習作為實現人工智能的核心方法,通過特定算法從數據中自主學習,獲得完成目標任務的技能。
與傳統基於知識的方法相比,機器學習有可能突破人類現有知識的上限,發現人類尚未察覺的新規律、新方案,甚至展現出“超人”般的智能。
如今,人工智能展現出的強大能力——包括人們常談論的AI 威脅,很大程度上源於機器學習:只有通過自主學習的機器,才有可能超越其創造者,具備難以預料的強大能力。
樣例:區分水果
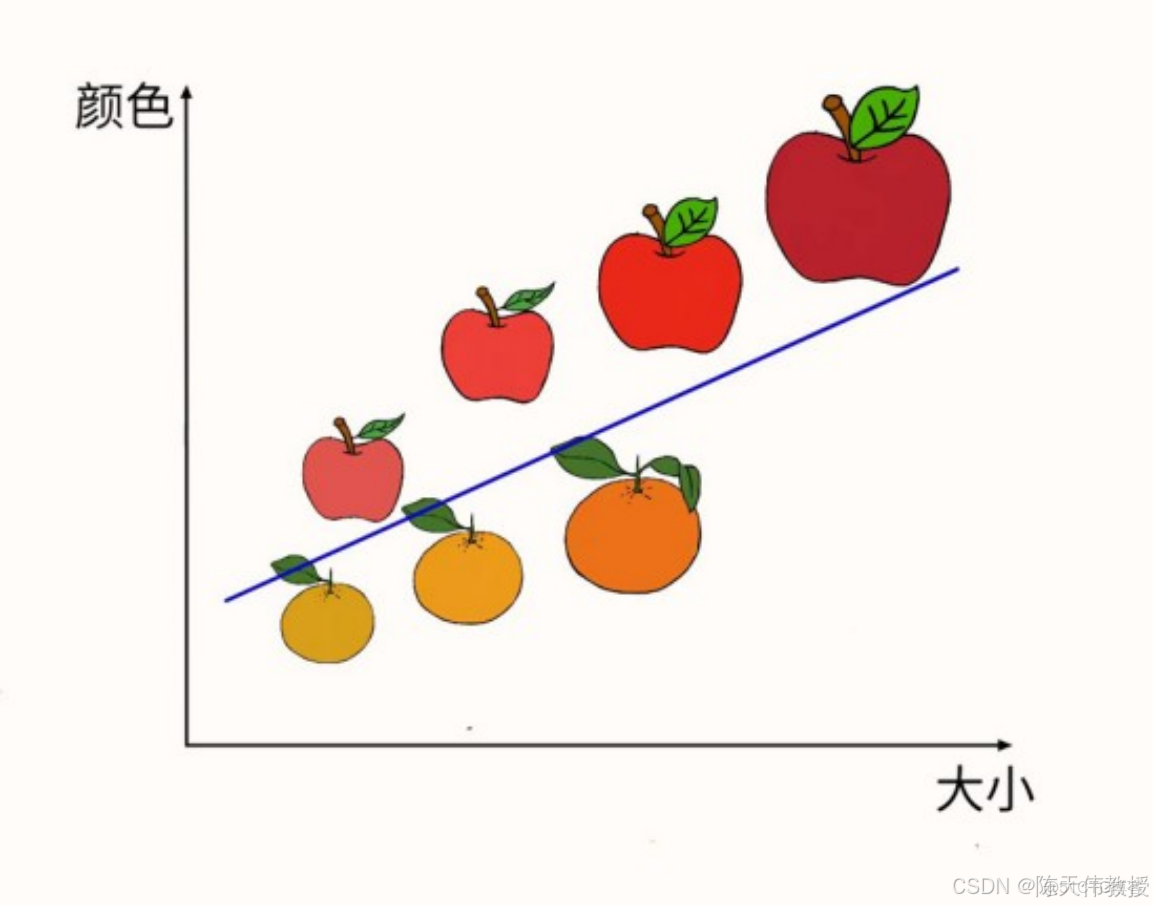
目標:對蘋果和桔子進行分類, 將這一目標表示為數學形式,即希望分類正確率越高越好,或錯誤率越低越好。
知識:例如,“又大又紅的更可能是蘋果,而較小且顏色偏橙黃色的是桔子”。
模型:構建一個簡單模型,如 Y=a × 顏色 + b × 大小,其中 a 和 b 為待學習的參數。
數據:收集蘋果和桔子的樣本,並分別標記(例如,蘋果標記為 T=1,桔子標記為 T=0)。算法:通過調整 a 和 b 的值,使得預測值 Y 儘可能接近標記 T。
完成學習後,就得到了一個能夠對蘋果和桔子進行分類的模型。
圖中的藍色直線代表模型對應的分類邊界,上方為蘋果,下方為桔子。對於新樣本,只需判斷其位於分類邊界的哪一側,即可確定其歸屬。
知識卡片
機器學習是利用恰當的算法,從數據中獲得經驗,對基於知識設計的初始模型進行改進,從而更有效地完成任務目標的方法。
機器學習的主要成份包括:
知識: 提供大框架、設計準則、初始模型結構。例如,圖像中物體的類別具有空間不變性。
模型: 是知識累積的場所。例如,圖像識別所用的卷積神經網絡。
數據: 是學習的糧食,是知識源。例如,大量帶標籤的圖像數據集。
目標: 是學習的方向,定義了系統要優化的指標。例如,最小化圖像分類錯誤率。
算法: 是學習的具體步驟。例如,反向傳播算法。
本文章為轉載內容,我們尊重原作者對文章享有的著作權。如有內容錯誤或侵權問題,歡迎原作者聯繫我們進行內容更正或刪除文章。