
前言
TeleTron是基於Megatron-LM二開的項目主要對視頻訓練做了大量優化
1.Ulysses Context Parallel (上下文並行)原理
下面的例子主要展示的是 Image Tokens(最複雜的部分)。
TeleTron 中 DiT 模型處理長序列的核心機制:如何通過 SeqAllToAll4D 在“序列並行”和“頭並行”之間轉換。
- 4 個大框 (GPU 0 - GPU 3):代表參與並行計算的 4 張顯卡。
- 小色塊:代表數據張量(Tensor)。
- 顏色:代表數據最初屬於哪個 GPU(即屬於序列的哪一部分)。
- 文字:
H0-H3代表注意力頭(Heads),S0-S3代表序列片段(Sequence Chunks)。
1.1 初始狀態 (Sequence Parallel)
- 長序列被切分為 4 段(S0, S1, S2, S3)。
- GPU 0 只有 S0,但它擁有 S0 的所有注意力頭 (Head 0-3)。
- 問題:Attention 需要計算全局關聯,GPU 0 只有 S0,看不到 S1-S3,無法直接計算全局 Attention。

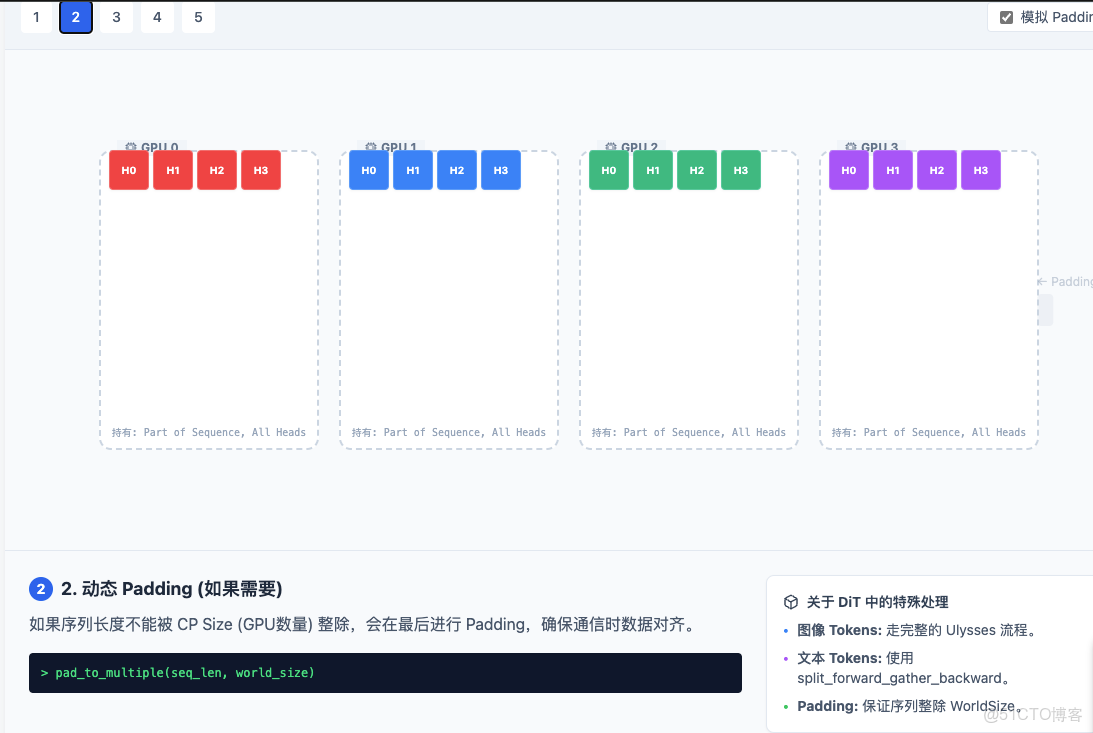
1.2 動態Padding
如果序列長度是 101,GPU 是 4 個。101 % 4≠ 0。pad.py 會在 All-to-All 之前將序列補齊到 104(能被 4 整除),確保每個 GPU 分到的數據塊大小一致,否則通信原語會報錯。
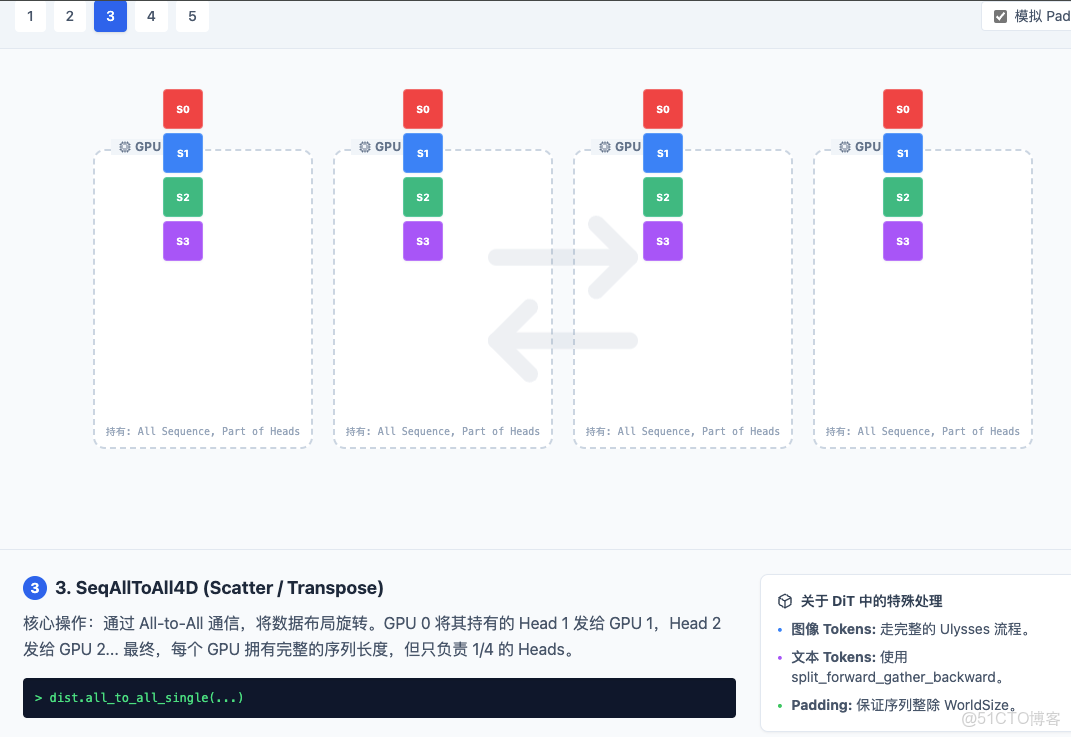
1.3 SeqAllToAll4D (Scatter)
- 這是 Ulysses 的核心魔法。它執行了一個轉置 (Transpose) 操作。
- 觀察動畫:GPU 0 把 Head 1 發給 GPU 1,Head 2 發給 GPU 2,Head 3 發給 GPU 3。同時它也接收了別人的 Head 0。
- 結果:現在 GPU 0 擁有了 S0, S1, S2, S3 的全部數據,但只包含 Head 0
1.4 Attention 計算
因為 GPU 0 現在擁有了全序列(S0-S3)的 Head 0 數據,它可以直接進行標準的 Attention 計算(Q、K、V 都在本地了)。這就是為什麼叫“Context Parallel”——每個 GPU 處理一部分 Context(這裏是按 Head 劃分)。

1.5 SeqAllToAll4D (Gather)
- 計算完 Attention 後,數據是按 Head 劃分的。為了進行下一層網絡(如 MLP)的計算,必須還原回按 Sequence 劃分的佈局。
- 執行逆向操作,數據飛回各自原本的 GPU。
2. 為什麼需要 All-to-All?(核心矛盾)
在計算下列公式時,存在一個矛盾:
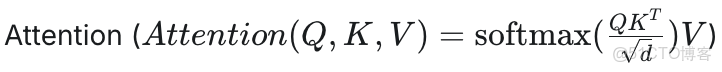
- 輸入狀態(為了存下長序列): 我們把超長的序列切幾段,每張卡存一段。
- 卡1擁有: 序列的第 0~100 個字,所有的 注意力頭。
- 卡2擁有: 序列的第 101~200 個字,所有的 注意力頭。
- 計算需求(Self-Attention): 第 0 個字(卡1)需要和第 199 個字(卡2)計算相關性。
- 問題: 如果不通信,卡1根本看不到卡2裏的數據,無法計算全局 Attention。
3. All-to-All 做了什麼?(維度交換)
SeqAllToAll4D 在這裏執行了一個 “洗牌” 操作。它讓所有顯卡互相交換數據,從而改變數據的切分維度。
- 操作前(序列並行):
- 卡1:拿着 部分序列 (Seq 1/N),但是有 全部特徵頭 (Heads All)。
- 卡2:拿着 部分序列 (Seq 2/N),但是有 全部特徵頭 (Heads All)。
(此時無法做全局 Attention)
⬇️ 執行 All-to-All 通信 ⬇️
(卡1把它的第2個頭的數據發給卡2,卡2把它的第1個頭的數據發給卡1...)
- 操作後(頭並行):
- 卡1:拿着 全部序列 (Seq All),但是隻有 部分特徵頭 (Head 1/N)。
- 卡2:拿着 全部序列 (Seq All),但是隻有 部分特徵頭 (Head 2/N)。
(此時可以做 Attention 了!因為卡1擁有所有序列的 Head 1 信息,它可以在 Head 1 的維度上計算第 0 個字和第 199 個字的關係
4. TeleTron 的區別對待
理解了 All-to-All 是在做“切分維度的轉換”,我們就能看懂 TeleTron 為什麼要對文本特殊處理。
4.1 圖像 Tokens (Long Sequence) - 必須做 All-to-All
圖像序列太長了(比如 4K 分辨率),單卡顯存根本存不下完整的序列 (𝑄,𝐾,𝑉)
- All-to-All #1: 把切散的序列拼湊回來,同時把 Heads 切散分給各卡。
- 計算 Attention: 每張卡算自己那部分 Heads 的全局 Attention。
- All-to-All #2: 再次通信,把 Heads 拼湊回來,重新把序列切散(為了省顯存)。
- 代價: 兩次巨大的通信開銷。
4.2 . 文本 Tokens (Short Sequence) - 優化方案
文本通常很短(幾十到幾百個 Token),或者是作為 Condition(條件)。
- 現狀: 單卡完全存得下完整的文本序列。
- TeleTron 的邏輯: 既然單卡能存下完整的文本序列,為什麼還要浪費時間做那兩次昂貴的 All-to-All 來切分 Heads 呢?
- 優化操作:
- Split Forward (切分): 僅僅是將文本數據簡單地切分或複製,使其在物理位置上與圖像數據所在的設備對齊(Align),以便後續做 Cross-Attention 或者拼接。
- Skip All-to-All: 直接跳過 了圖像那種“序列換頭”的複雜通信過程。
- 計算: 直接利用本地數據參與計算。
- Gather Backward (聚合): 反向傳播時,簡單地把梯度收集起來即可。
5. 總結
All-to-All 在這裏就是 “為了讓原本被切碎的長序列能看到彼此,暫時把注意力頭(Heads)切碎來換取視野” 的操作。
TeleTron 對文本的優化在於:文本不夠長,不需要“切碎頭換視野”,直接處理即可,從而省下了昂貴的通信費。