
目錄
stack和queue
前言
1. stack的基本使用
1.1 棧的基本概念
1.2 stack的基本使用
1.3 棧的模擬實現
2. queue的基本使用
2.1 隊列的基本概念
2.2 queue的基本使用
2.3 隊列的模擬實現
3. priority_queue(優先隊列)深度解析
3.1 優先隊列的概念
3.2 priority_queue的使用
4. 容器適配器深度理解
4.1 什麼是容器適配器?
4.2 為什麼選擇deque作為默認底層容器?
結語
模板進階
前言
5. 非類型模板參數
5.1 基本概念
5.2 非類型參數的限制
6. 模板特化
6.1 為什麼需要模板特化?
6.2 函數模板特化
6.3 類模板特化
6.3.1 全特化(Full Specialization)
6.3.2 偏特化(Partial Specialization)
7. 模板分離編譯
7.1 問題背景
7.2 問題原因分析
7.3 解決方案
方案1:聲明和定義放在同一文件(推薦)
方案2:顯式實例化(不推薦)
結語
stack和queue
前言
在C++標準模板庫(STL)中,stack(棧)和queue(隊列)作為兩種經典的線性數據結構,雖然功能相對簡單,卻在算法設計和系統開發中扮演着不可或缺的角色。與vector、list等直接容器不同,它們屬於容器適配器——通過封裝其他容器來實現特定接口。
棧的"後進先出"(LIFO)和隊列的"先進先出"(FIFO)特性,使得它們在解決特定類型問題時表現出色。無論是函數調用棧、表達式求值,還是任務調度、消息隊列,都能看到它們的身影。
本文將深入探討stack和queue的實現原理、使用技巧以及實際應用,幫助你全面掌握這兩種重要的數據結構。
1. stack的基本使用
1.1 棧的基本概念
棧是一種後進先出(LIFO)的數據結構,只允許在容器的一端進行插入和刪除操作。這就像一疊盤子,我們只能從最上面取放。
棧的核心操作:
push(): 元素入棧pop(): 元素出棧top(): 查看棧頂元素empty(): 判斷棧是否為空size(): 獲取棧中元素個數
1.2 stack的基本使用
stack相對於之前的string,vector和list,結構比較簡單
#include
#include
using namespace std;
void basicStackDemo() {
stack st;
// 入棧操作
st.push(1);
st.push(2);
st.push(3);
cout << "棧大小: " << st.size() << endl; // 3
cout << "棧頂元素: " << st.top() << endl; // 3
// 出棧操作
st.pop();
cout << "出棧後棧頂: " << st.top() << endl; // 2
// 遍歷棧(注意:棧沒有迭代器,只能邊pop邊訪問)
while (!st.empty()) {
cout << st.top() << " ";
st.pop();
}
// 輸出: 2 1
}1.3 棧的模擬實現
由於棧比較簡單,為了方便,我們可以調用其他的STL容器的功能函數來幫我們實現,下列的deque即為一個容器適配器,之後我們會初步講解
#include
#include
namespace my {
template>
class stack {
private:
Container _c; // 底層容器
public:
// 構造函數
stack() = default;
// 容量操作
bool empty() const { return _c.empty(); }
size_t size() const { return _c.size(); }
// 元素訪問
T& top() { return _c.back(); }
const T& top() const { return _c.back(); }
// 修改操作
void push(const T& value) { _c.push_back(value); }
void pop() { _c.pop_back(); }
// 交換
void swap(stack& other) { std::swap(_c, other._c); }
};
}
// 使用示例
void testMyStack() {
my::stack st;
st.push(1);
st.push(2);
st.push(3);
while (!st.empty()) {
cout << st.top() << " "; // 3 2 1
st.pop();
}
}2. queue的基本使用
2.1 隊列的基本概念
隊列是一種先進先出(FIFO)的數據結構,元素從隊尾進入,從隊頭離開。這就像現實生活中的排隊,先來的人先接受服務。
隊列的核心操作:
push(): 元素入隊pop(): 元素出隊front(): 查看隊頭元素back(): 查看隊尾元素empty(): 判斷隊列是否為空size(): 獲取隊列元素個數
2.2 queue的基本使用
#include
#include
using namespace std;
void basicQueueDemo() {
queue q;
// 入隊操作
q.push(1);
q.push(2);
q.push(3);
cout << "隊列大小: " << q.size() << endl; // 3
cout << "隊頭元素: " << q.front() << endl; // 1
cout << "隊尾元素: " << q.back() << endl; // 3
// 出隊操作
q.pop();
cout << "出隊後隊頭: " << q.front() << endl; // 2
// 遍歷隊列
while (!q.empty()) {
cout << q.front() << " ";
q.pop();
}
// 輸出: 2 3
}2.3 隊列的模擬實現
#include
namespace my {
template>
class queue {
private:
Container _c;
public:
queue() = default;
// 容量操作
bool empty() const { return _c.empty(); }
size_t size() const { return _c.size(); }
// 元素訪問
T& front() { return _c.front(); }
const T& front() const { return _c.front(); }
T& back() { return _c.back(); }
const T& back() const { return _c.back(); }
// 修改操作
void push(const T& value) { _c.push_back(value); }
void pop() { _c.pop_front(); }
void swap(queue& other) { std::swap(_c, other._c); }
};
}3. priority_queue(優先隊列)深度解析
3.1 優先隊列的概念

優先隊列是一種特殊的隊列,元素出隊的順序不是按照入隊順序,而是按照元素的優先級。默認情況下,C++中的priority_queue是大頂堆。
因此priority_queue的底層結構為堆
由於priority_queue仍為隊列,因此仍具有以下操作
empty():檢測容器是否為空
size():返回容器中有效元素個數
front():返回容器中第一個元素的引用
push_back():在容器尾部插入元素
pop_back():刪除容器尾部元素
標準容器類vector和deque滿足這些需求。默認情況下,如果沒有為特定的priority_queue 類實例化指定容器類,則使用vector。
3.2 priority_queue的使用
#include
#include
#include
void priorityQueueDemo() {
// 默認大頂堆
priority_queue max_heap;
max_heap.push(3);
max_heap.push(1);
max_heap.push(4);
max_heap.push(2);
cout << "大頂堆頂部: " << max_heap.top() << endl; // 4
// 小頂堆
priority_queue, greater> min_heap;
min_heap.push(3);
min_heap.push(1);
min_heap.push(4);
min_heap.push(2);
cout << "小頂堆頂部: " << min_heap.top() << endl; // 1
},>4. 容器適配器深度理解
4.1 什麼是容器適配器?
容器適配器不是獨立的容器,而是對現有容器的封裝,提供特定的接口。可以簡單理解為容器適配器是對於一個容器的特定功能的實現
例如stack實現先進後出,queue實現先進先出
而vector和list並不具有這些特徵
STL中的容器適配器包括:
stack: 棧適配器queue: 隊列適配器priority_queue: 優先隊列適配器
其中stack和queue均使用的是deque
4.2 為什麼選擇deque作為默認底層容器?
// STL中的默認定義
template > class stack;
template > class queue;deque(雙端隊列):是一種雙開口的"連續"空間的數據結構,雙開口的含義是:可以在頭尾兩端 進行插入和刪除操作,且時間複雜度為O(1),與vector比較,頭插效率高,不需要搬移元素;與 list比較,空間利用率比較高。
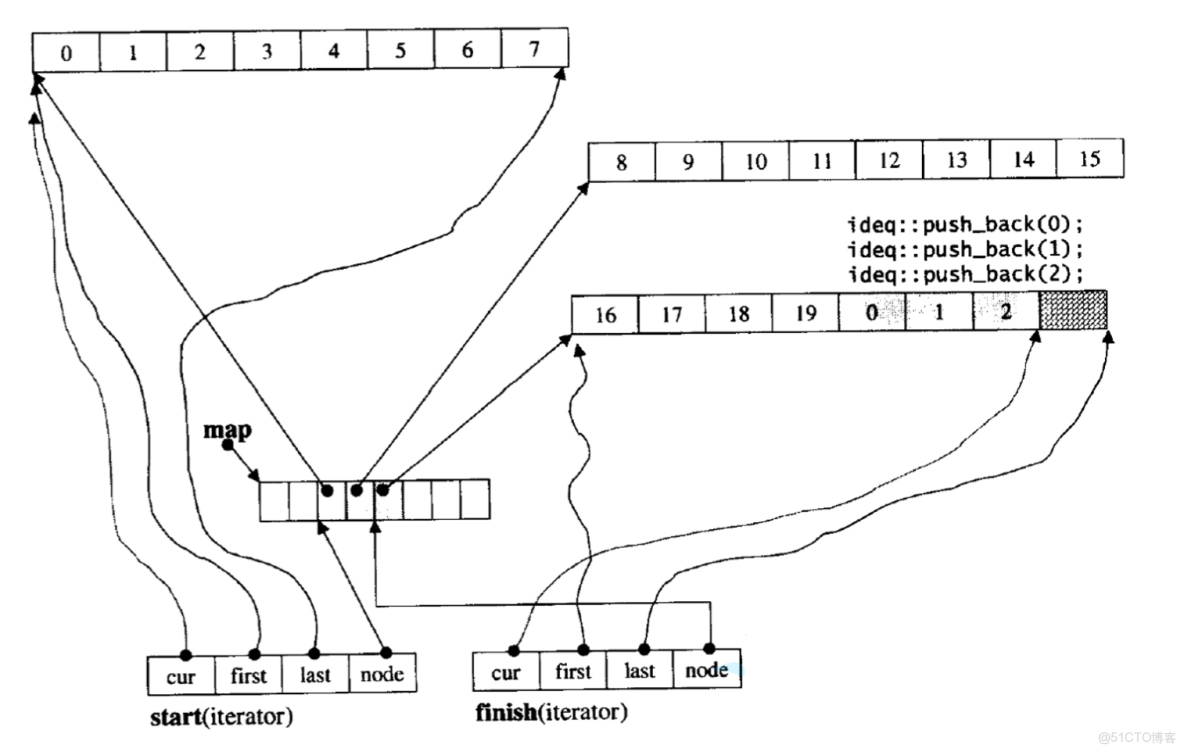
deque先是由一個中控台(map)構成,每個中控台節點包含cur,first,last,node四個指針
first代表一個數組的首地址
last代表一個數組的尾地址
cur則用來遍歷數組中的元素
node代表該中控台節點的位置
因此deque結合了list和vector的優點,相當於幾個數組以鏈表的形式連接起來
選擇deque的原因:
- 綜合性能優秀:
- 頭部尾部操作都是O(1)
- 不需要vector的擴容拷貝開銷
- 比list緩存友好,內存局部性更好
- 適合適配器需求:
- stack只需要
push_back、pop_back、back - queue需要
push_back、pop_front、front、back - deque完美支持這些操作
- 內存效率:
- 分段連續存儲,擴容代價小
- 空間利用率高於list
結語
stack和queue作為C++ STL中的容器適配器,雖然接口簡單,卻在算法設計和系統開發中發揮着重要作用。通過本文的學習,我們應該:
- 理解棧和隊列的基本特性和操作
- 掌握容器適配器的設計思想
- 熟悉優先隊列的原理和使用
- 能夠根據場景選擇合適的容器
- 理解底層容器的選擇策略
在實際開發中,當遇到具有LIFO或FIFO特性的問題時,不要忘記這些簡單而強大的工具。它們往往能以最優雅的方式解決看似複雜的問題。
\
模板進階
前言
在前一篇文章中,我們學習了模板的基礎知識,瞭解了函數模板和類模板的基本用法。但在實際開發中,我們常常會遇到更復雜的場景:需要固定大小的容器、針對特定類型進行特殊處理、或者將模板代碼分文件組織等。
C++模板系統提供了強大的進階特性來解決這些問題,包括非類型模板參數、模板特化、以及處理分離編譯的策略。這些特性讓我們能夠編寫更加靈活、高效的泛型代碼。
5. 非類型模板參數
5.1 基本概念
非類型模板參數允許我們使用常量作為模板參數,而不僅僅是類型。這使得我們可以在編譯期確定某些值,生成更加特化的代碼。
template // N是非類型模板參數
class Array {
private:
T _data[N]; // 使用N作為數組大小
size_t _size = N;
public:
size_t size() const { return _size; }
T& operator[](size_t index) { return _data[index]; }
const T& operator[](size_t index) const { return _data[index]; }
};
// 使用示例
void demo() {
Array arr1; // 創建大小為5的int數組
Array arr2; // 創建大小為10的double數組
Array arr3; // 使用默認大小10
},>,>5.2 非類型參數的限制
注意:
1. 浮點數、類對象以及字符串是不允許作為非類型模板參數的。
2. 非類型的模板參數必須在編譯期就能確認結果。
// 允許的類型:
template class A {}; // 整型
template class B {}; // 無符號整型
template class C {}; // 布爾類型
template class D {}; // 指針類型
template class E {}; // 函數引用
// 不允許的類型:
// template class F {}; // 錯誤:浮點數不允許
// template<:string str=""> class G {}; // 錯誤:類對象不允許
// template class H {}; // 錯誤:字符串字面量不允許*>6. 模板特化
6.1 為什麼需要模板特化?
假設我們實現一個判斷是否相等的函數模板
// 通用模板
template
bool equals(const T& a, const T& b) {
return a == b;
}模板提供了通用實現,但某些特定類型可能需要特殊處理:
對於浮點數,我們需要考慮精度問題
template<>
bool equals(const double& a, const double& b) {
return std::abs(a - b) < 1e-10;
}對於字符串,我們需利用strcmp來比較大小
template<>
bool equals(const char* const& a, const char* const& b) {
return std::strcmp(a, b) == 0;
}可以看到equals對於一些基本數據類型,如整型,字符的判斷無誤,但若是字符串甚至是自定義類型對比則不能草率地使用==來判斷
因此對於這些特殊情況,我們需要以模板來專門實現幾個函數
6.2 函數模板特化
函數模板特化允許我們為特定類型提供特殊實現:
函數模板的特化步驟:
1. 必須要先有一個基礎的函數模板
2. 關鍵字template後面接一對空的尖括號<>
3. 函數名後跟一對尖括號,尖括號中指定需要特化的類型
4. 函數形參表: 必須要和模板函數的基礎參數類型完全相同,如果不同編譯器可能會報一些奇怪的錯誤。
// 基礎函數模板
template
int compare(const T& a, const T& b) {
if (a < b) return -1;
if (b < a) return 1;
return 0;
}
// 特化版本:針對C風格字符串
template<>
int compare(const char* const& a, const char* const& b) {
return std::strcmp(a, b);
}
// 特化版本:針對double(處理浮點精度)
template<>
int compare(const double& a, const double& b) {
if (std::abs(a - b) < 1e-10) return 0;
return a < b ? -1 : 1;
}注意:函數模板特化在實際開發中較少使用,通常更推薦使用函數重載:
// 使用重載代替特化(更簡單清晰)
int compare(const char* a, const char* b) {
return std::strcmp(a, b);
}6.3 類模板特化
6.3.1 全特化(Full Specialization)
全特化是指為模板的所有參數都提供具體類型:
// 通用類模板
template
class Pair {
private:
T1 _first;
T2 _second;
public:
Pair(const T1& f, const T2& s) : _first(f), _second(s) {}
void print() const {
std::cout << "Generic: (" << _first << ", " << _second << ")" << std::endl;
}
};
// 全特化:兩個參數都是int
template<>
class Pair {
private:
int _first;
int _second;
public:
Pair(int f, int s) : _first(f), _second(s) {}
void print() const {
std::cout << "IntPair: (" << _first << ", " << _second << ")" << std::endl;
}
// 特化版本特有的方法
int sum() const { return _first + _second; }
};
void demoFullSpecialization() {
Pair p1(3.14, "pi");
Pair p2(10, 20);
p1.print(); // 輸出: Generic: (3.14, pi)
p2.print(); // 輸出: IntPair: (10, 20)
std::cout << "Sum: " << p2.sum() << std::endl; // 輸出: Sum: 30
},>,>,>6.3.2 偏特化(Partial Specialization)
偏特化是指只特化部分模板參數,或者對參數類型添加約束:
部分參數特化:
// 通用模板
template
class Triple {
public:
Triple() { std::cout << "Triple" << std::endl; }
};
// 偏特化:第三個參數固定為int
template
class Triple {
public:
Triple() { std::cout << "Triple" << std::endl; }
};
// 偏特化:第二、三個參數固定
template
class Triple {
public:
Triple() { std::cout << "Triple" << std::endl; }
};
void demoPartialSpecialization() {
Triple t1; // 通用版本
Triple t2; // 第一個偏特化
Triple t3; // 第二個偏特化
},>,>,>,>,>,>,>,>類型約束特化:
如果模板參數被特例化為指針或引用,那麼就會強制性調用含指針或引用的模板
//兩個參數偏特化為指針類型
template
class Data
{
public:
Data() {cout<<"Data" <
class Data
{
public:
Data(const T1& d1, const T2& d2)
: _d1(d1)
, _d2(d2)
{
cout<<"Data" < d1; // 調用特化的int版本
Data d2; // 調用基礎的模板
Data d3; // 調用特化的指針版本
Data d4(1, 2); // 調用特化的指針版本
}&,>;>&,>&,>;}>*,>*,>7. 模板分離編譯
7.1 問題背景
當模板的聲明和定義分離到不同文件時,會出現鏈接錯誤:
假設我們有一個頭文件math_utils.h和兩個原文件math_utils.cpp和main.cpp
// math_utils.h
template
T add(const T& a, const T& b);// math_utils.cpp
template
T add(const T& a, const T& b) {
return a + b;
}// main.cpp
#include "math_utils.h"
int main() {
int result = add(1, 2); // 鏈接錯誤:undefined reference
return 0;
}7.2 問題原因分析
編譯過程:
- 編譯math_utils.cpp:編譯器看到模板定義,但沒有看到具體實例化,不會生成代碼
- 編譯main.cpp:編譯器看到模板聲明,生成對
add<int>的調用 - 鏈接階段:找不到
add<int>的實現,鏈接失敗
原因:
模板之所以叫模板,就只是一張圖紙,只有你需要才會構造出相應的函數實例
.h中的模板add為聲明,編譯器看見了因此main中的add不會報錯,但當實際調用中無法找到add函數,但是math_utils.cpp中存在啊?實際上不存在,因為math_utils.cpp中的add函數為模板,在鏈接過程中add函數模板並沒有生成相應的實例,因為math_utils.cpp中沒有調用add函數,main.cpp無法遠程在math_utils.cpp中用add模板,不然也沒有鏈接這個過程
7.3 解決方案
方案1:聲明和定義放在同一文件(推薦)
// math_utils.h
template
T add(const T& a, const T& b) {
return a + b;
}
// 或者使用.hpp後綴明確表示這是包含實現的頭文件
// math_utils.hpp方案2:顯式實例化(不推薦)
結語
通過本文的學習,我們深入探討了C++模板的進階特性:
- 非類型模板參數:在編譯期確定值,實現固定大小的容器和編譯期計算
- 模板特化:為特定類型提供特殊實現,包括全特化和偏特化
- 分離編譯問題:理解模板的編譯模型,掌握正確的代碼組織方式
這些進階特性讓我們能夠編寫更加高效、靈活的泛型代碼。但需要注意的是,強大的能力也帶來了複雜性,在實際項目中應該:
- 優先使用簡單的模板特性
- 只在性能關鍵路徑使用高級特性
- 保持代碼的可讀性和可維護性
- 充分測試各種特化版本

