
本文價值提示 🌟
正在從 Java/Scala 大數據棧轉型 AI 開發? 習慣了編譯器的嚴格檢查,卻被 Python 的
AttributeError折磨得睡不着? 本文將教你如何用 Type Hints 和 Pydantic 構建嚴謹的 AI 數據契約,讓你的 Python 代碼擁有“靜態語言”般的健壯性,從此告別腳本式的“裸奔”開發!
🐍 前言:當大數據老兵遇上“隨性”的 Python
作為一名在大數據領域摸爬滾打多年的工程師,你的肌肉記憶裏可能刻滿了 Java 的嚴謹和 Scala 的優雅。
你習慣了:
- 定義變量前先想好類型 (
List<String>); - 依靠 IDE 的智能提示(IntelliJ IDEA YYDS);
- 相信編譯器是最後的防線,紅線不消,代碼不跑。
然而,當你轉型 AI 應用架構(AI Agent / RAG)時,Python 成了繞不開的“新歡”。起初,你可能覺得它真香:
- “哇,不用寫分號!”
- “哇,
Map<String, Object>只要寫{}!”
但隨着代碼行數從 100 行膨脹到 10,000 行,噩夢開始了:
- “這個
items到底是個列表還是字典?” - “誰把
config裏的timeout傳成了字符串?” - “生產環境半夜報警:
NoneType object has no attribute 'get'...”
在大數據時代,我們處理的是結構化數據(Schema on Write);而在 AI 時代,我們面對的是 LLM 吐出的非結構化文本和複雜的 JSON。
如果繼續用寫 Airflow 腳本的方式寫 AI 架構,你的系統就像在沙灘上蓋樓——隨時會塌。
今天,我們就來補上轉型路上的第一塊短板:強類型與數據契約。
🛡️ 第一招:Type Hints —— 找回“靜態語言”的安全感
Python 3.5+ 引入了 Type Hints(類型提示)。雖然 Python 虛擬機在運行時依然是動態的(不會因為類型不對而報錯),但它給了 IDE 和靜態分析工具一個“契約”。
這就像是在告訴你的隊友(和一個月後的自己):“這裏只能傳整數,傳字符串我就跟你急!”
🔍 大數據工程師的“類型映射表”
為了讓你秒懂,我們來做一個 Java/Scala 到 Python 的映射:
|
概念
|
Java / Scala (大數據棧)
|
Python 3.10+ (AI 棧)
|
説明
|
|
基礎類型 |
|
|
Python 一切皆對象
|
|
列表 |
|
|
3.9+ 後不再需要導入 List
|
|
字典/Map |
|
|
清晰定義 Key-Value 類型
|
|
可空類型 |
|
`T
|
None`
|
|
聯合類型 |
|
`int
|
str`
|
|
任意類型 |
|
|
最後的逃生艙,慎用!
|
❌ 拒絕“膠水代碼”風格
來看看典型的“裸奔”代碼:
def process_data(items, config):
# items 是啥?config 裏有啥?全靠猜!
# 這種代碼維護起來就是災難
res = []
for i in items:
if i > config['threshold']:
res.append(str(i))
return res✅ 擁抱“工程化”風格
加上類型提示後,代碼瞬間清晰:
from typing import Any
# 顯式定義:items 是整數列表,config 是字典,返回字符串列表
def process_data(items: list[int], config: dict[str, Any]) -> list[str]:
"""
處理數據並返回字符串列表。
"""
# 即使 config 是 Any,我們至少知道 items 是安全的
threshold = config.get('threshold', 0)
results: list[str] = []
for i in items:
if i > threshold:
results.append(str(i))
return results💡 小貼士:配合 VS Code 的 Pylance 插件或 PyCharm,當你試圖把 str 放進 list[int] 時,編輯器會標紅警告,就像 Java 編譯器一樣!
👮 第二招:Pydantic —— 運行時的“數據守門員”
Type Hints 只是“防君子不防小人”(運行時不報錯)。但在 AI 系統中,我們需要處理 LLM 返回的不可控 JSON,這時候就需要 Pydantic 出場了。
在大數據領域,它約等於: Scala Case Class + 自動校驗邏輯 + JSON 序列化/反序列化器。
它是 OpenAI SDK、LangChain、LlamaIndex 背後的核心依賴。
🏗️ 定義你的數據契約 (Schema)
假設我們要調用 LLM,我們需要嚴格控制配置參數。這裏我們重點介紹 @field_validator,它是 Pydantic 的靈魂,允許你編寫自定義的校驗和清洗邏輯。
from pydantic import BaseModel, Field, field_validator
class LLMConfig(BaseModel):
# Field 類似 Java 的註解,定義元數據和約束
model_name: str = Field(default="gpt-4", description="模型名稱")
# 自動校驗:temperature 必須在 0.0 到 1.0 之間
temperature: float = Field(default=0.7, ge=0.0, le=1.0)
# 必填項
api_key: str = Field(..., description="OpenAI API Key")
# ✨ 核心黑科技:@field_validator
# 場景:校驗 API Key 格式,並自動去除首尾空格
@field_validator('api_key')
@classmethod
def validate_api_key(cls, v: str) -> str:
# 1. 數據清洗 (Cleaning)
v = v.strip()
# 2. 業務規則校驗 (Validation)
if not v.startswith("sk-"):
# 拋出 ValueError,Pydantic 會捕獲並生成友好的錯誤信息
raise ValueError("無效的 API Key,必須以 'sk-' 開頭")
# 3. 返回處理後的值
return v
# 場景:校驗模型白名單
@field_validator('model_name')
@classmethod
def check_model(cls, v: str) -> str:
allowed = ["gpt-4", "gpt-3.5-turbo", "deepseek-chat"]
if v not in allowed:
raise ValueError(f"不支持的模型: {v}, 僅支持: {allowed}")
return v💥 它是如何拯救你的?
當你嘗試實例化這個類時,Pydantic 會像守門員一樣攔截錯誤:
# ✅ 場景 1:自動清洗與校驗
# 用户不小心多複製了空格?沒關係,validate_api_key 會自動 strip()
conf = LLMConfig(api_key=" sk-123456... ")
print(f"Key已清洗: '{conf.api_key}'") # 輸出: 'sk-123456...'
# ❌ 場景 2:格式錯誤
# 報錯:Value error, 無效的 API Key,必須以 'sk-' 開頭
try:
conf = LLMConfig(api_key="wrong-key")
except Exception as e:
print(e)
# ❌ 場景 3:數值越界
# 報錯:Input should be less than or equal to 1.0
conf = LLMConfig(api_key="sk-123", temperature=1.5)🚀 實戰:構建一個 RAG 系統的“數據流水線”
讓我們把視角拉高,看看在一個真實的 RAG(檢索增強生成)系統中,如何利用這些工具保證數據流的純淨。
業務流程圖
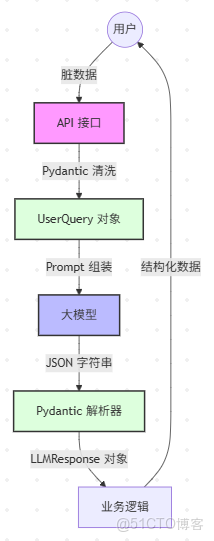
核心代碼實現
我們需要定義兩個核心類:UserQuery(輸入)和 LLMResponse(輸出)。
1. 輸入清洗:拒絕垃圾進(Garbage In)
class UserQuery(BaseModel):
# 限制輸入長度,防止 Token 爆炸
query_text: str = Field(..., min_length=1, max_length=500)
top_k: int = Field(default=3, ge=1, le=10)
# 再次使用 @field_validator 進行文本標準化
@field_validator('query_text')
@classmethod
def clean_whitespace(cls, v: str) -> str:
"""自動清洗:去除首尾空格,合併中間多餘空格"""
# " 如何 學習 Python " -> "如何 學習 Python"
return " ".join(v.split())
# 測試
raw_input = {"query_text": " 如何學習 Python ", "top_k": 5}
query = UserQuery.model_validate(raw_input)
print(f"清洗後: '{query.query_text}'")
# 輸出: '如何學習 Python' —— 舒服了!2. 輸出解析:拒絕垃圾出(Garbage Out)
LLM 返回的通常是一大坨 JSON 字符串,手動解析非常容易出錯。
class TokenUsage(BaseModel):
total_tokens: int
class LLMResponse(BaseModel):
content: str
usage: TokenUsage
# 模擬 LLM 返回的 JSON 字符串
llm_json_str = '{"content": "Python 很棒", "usage": {"total_tokens": 100}}'
# 一行代碼完成解析 + 校驗
response = LLMResponse.model_validate_json(llm_json_str)
# 像操作 Java 對象一樣使用它(IDE 會自動補全!)
print(response.content)
print(response.usage.total_tokens)🛠️ 終極武器:Mypy —— 你的“靜態編譯器”
寫了 Type Hints 如果不檢查,就等於寫了註釋不看。
在大數據開發中,我們有 javac 或 scalac。在 Python 中,我們有 Mypy。
建議在你的 CI/CD 流程中加入這一步:
pip install mypy
mypy your_project_folder/它會掃描你的代碼,找出所有類型不匹配的地方。比如你把 str 傳給了需要 int 的函數,它會直接報錯,阻止你上線。
📝 總結
從大數據工程師轉型 AI 架構師,Python 不再是寫腳本的玩具,而是承載核心業務邏輯的基石。
通過 Type Hints 和 Pydantic,我們做到了:
- 可讀性:代碼即文檔,參數類型一目瞭然。
- 健壯性:利用
@field_validator守住數據入口,拒絕髒數據污染 AI 上下文。 - 開發效率:IDE 智能補全,重構不再心驚膽戰。
這不僅僅是語法糖,更是一種工程思維的覺醒。
🧠 本文思維導圖
下期預告:搞定了數據結構,但 LLM API 響應太慢怎麼辦?下一篇我們將深入 Python 高併發編程 (Asyncio),教你如何像 Netty 一樣處理海量 I/O 請求!
👇 點個“在看”,代碼無 Bug!