
💎 本文價值提示
- 思維重塑:幫你徹底打破 Java/Spark 的“多線程/多進程”固有思維,理解 Python 獨特的“單線程 + 事件循環”模型。
- 實戰落地:手把手教你用
Asyncio+httpx構建一個生產級的 LLM 高併發請求器。 - 避坑指南:揭秘 90% 轉行工程師都會踩的“阻塞陷阱”和“CPU 密集型誤區”。
- 適用人羣:Java 開發、大數據工程師、正在轉型 AI 應用架構的後端開發者。
👋 嗨,各位大數據老司機們!
作為一名在大數據領域摸爬滾打多年的工程師,你一定對 Java 的多線程(Thread Pool) 或者 Spark 的分佈式並行(Executor) 如數家珍。
當你轉型做 AI Agent 或 RAG(檢索增強生成)架構時,你可能會遇到這樣一個場景:
業務方甩給你 10,000 個 Prompt,讓你調用 OpenAI 或 DeepSeek 的 API 跑批處理。
你的第一反應是不是:“這簡單!開個 50 線程的 ThreadPool,一把梭哈!”
🛑 且慢!在 Python 的世界裏,這麼做可能是在“自廢武功”。
因為 Python 有一個讓無數 Java 程序員頭禿的“特產”——**GIL(全局解釋器鎖)**。如果你還在用寫 Java 的方式寫 Python,你的 AI 應用可能連 10% 的性能都跑不出來。
今天,我們就來聊聊 Python AI 工程化的核心武器:**Asyncio(異步 I/O)**。
01 🤯 顛覆認知:從“人海戰術”到“影分身術”
要理解 Python 的 Asyncio,首先得忘掉 Java 的多線程模型。
☕ Java/大數據模型:人海戰術
在 Java(Pre-NIO 時代)或 Spark 中,處理併發通常意味着增加資源。
- 場景:餐廳有 100 桌客人。
- 策略:僱傭 100 個服務員(線程)。每桌配一個服務員,客人點菜、等菜、吃飯,服務員全程死守在旁邊。
- 代價:操作系統開銷大,內存佔用高,上下文切換頻繁。
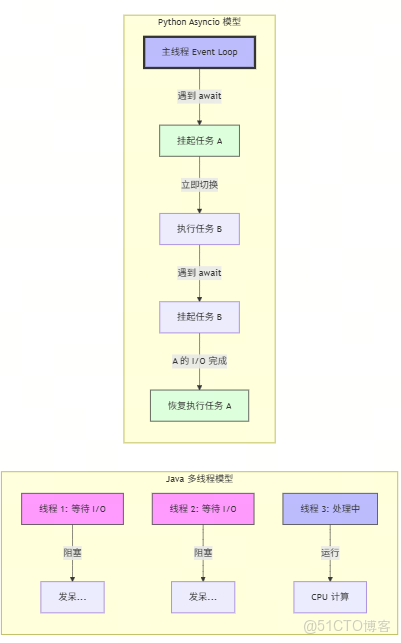
🐍 Python Asyncio 模型:影分身術
Python 由於 GIL 的存在,同一時刻只能有一個線程在執行字節碼。這意味着你僱傭 100 個服務員(線程),其實只有 1 個能動,其他的都在排隊拿鎖。
所以,Python 選擇了另一種流派:**Event Loop(事件循環)**。
- 場景:餐廳有 100 桌客人。
- 策略:**只僱傭 1 個超級服務員(單線程)**。
- 操作:
- 服務員去 A 桌點菜,把單子扔給廚房(I/O 請求發出)。
- 關鍵點:服務員不等待廚房做菜,而是立刻轉身去 B 桌點菜(釋放控制權)。
- 當廚房喊“A 桌菜好了”(Callback/Future 完成),服務員再回來把菜端給 A 桌。
這就是 Asyncio 的本質:單線程 + 協作式多任務。它不靠增加人手,而是靠榨乾這一個人的所有等待時間。
👇 一張圖看懂區別:
02 🛠️ 核心語法:Async 與 Await 的“契約”
在 Python 中,要實現這種“影分身”,你需要兩個魔法詞:
async def:告訴 Python,“我是一個協程(Coroutine),我可能會暫停”。await:告訴 Python,“這裏要等很久(比如請求 LLM API),你先去忙別的,結果出來了叫我”。
⚠️ 最大的坑:不要讓服務員“睡着”!
很多轉型的同學會寫出這樣的代碼:
import time
import asyncio
async def bad_code():
# ❌ 錯誤!這叫“同步阻塞”
# 這相當於服務員在等菜的時候,直接在大廳睡着了!
# 整個餐廳(Event Loop)都會停擺,沒人服務其他桌了。
time.sleep(5)
print("醒了")
async def good_code():
# ✅ 正確!這叫“異步掛起”
# 服務員説:“我要等5秒,這期間我去幹別的。”
await asyncio.sleep(5)
print("醒了")
記住:在 async 函數裏,千萬別用 time.sleep(),也別用 requests 庫(它是同步的),要用 aiohttp 或 httpx!
03 🚀 實戰:構建高併發 LLM 請求器
光説不練假把式。假設我們要處理 50 個 Prompt,如果串行調用,每個耗時 2 秒,總共要 100 秒。 我們的目標是:利用 Asyncio 併發,但要限制併發數(防止 API Rate Limit 報錯)。
我們將使用以下“三劍客”:
- 🗡️
httpx:現代化的異步 HTTP 客户端(比 requests 強)。 - 🛡️
asyncio.Semaphore:信號量,用來控制併發度(類比 Spark 的 Executor 數量)。 - ⚡
asyncio.gather:併發執行器(類比 Spark 的 Action)。
📝 完整代碼實現
import asyncio
import httpx
import time
import random
# 模擬 LLM API (使用 httpbin 模擬延遲)
MOCK_API_URL = "https://httpbin.org/delay/{delay}"
class LLMClient:
def __init__(self, concurrency_limit: int = 5):
# 🚦 核心組件:信號量
# 就像餐廳只有 5 個盤子,發完就得等別人還回來才能繼續發
self.semaphore = asyncio.Semaphore(concurrency_limit)
# 建立長連接池,複用 TCP 連接
self.client = httpx.AsyncClient(timeout=30.0)
async def close(self):
await self.client.aclose()
async def fetch_completion(self, prompt_id: int):
# 模擬 1~2 秒的 API 延遲
delay = random.uniform(1.0, 2.0)
url = MOCK_API_URL.format(delay=f"{delay:.2f}")
# 🔒 自動獲取鎖,退出時自動釋放
async with self.semaphore:
print(f"🚀 [開始] 任務 ID: {prompt_id} | 正在請求...")
start_time = time.perf_counter()
try:
# 👉 關鍵時刻:await 讓出控制權!
# 此時 Event Loop 會立刻去處理下一個任務
resp = await self.client.get(url)
resp.raise_for_status()
elapsed = time.perf_counter() - start_time
print(f"✅ [完成] 任務 ID: {prompt_id} | 耗時: {elapsed:.2f}s")
return {"id": prompt_id, "status": "success"}
except Exception as e:
print(f"❌ [失敗] 任務 ID: {prompt_id} | 錯誤: {e}")
return {"id": prompt_id, "status": "error"}
async def main():
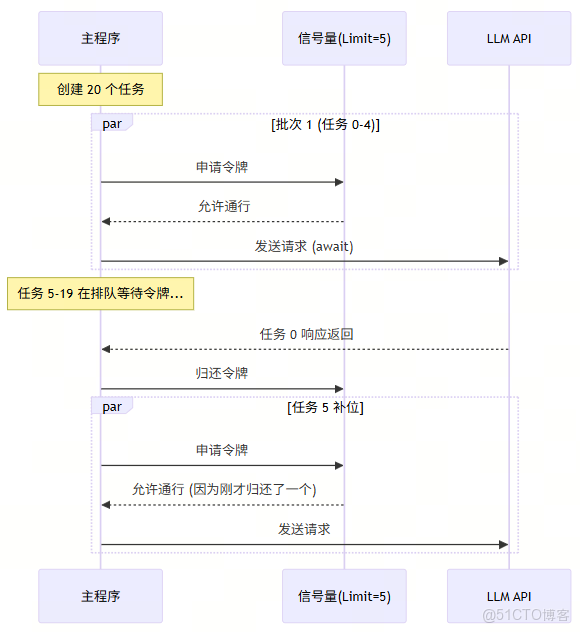
# 準備 20 個任務
total_tasks = 20
# 限制同時只能有 5 個請求在飛
client = LLMClient(concurrency_limit=5)
print(f"🔥 開始處理 {total_tasks} 個請求,併發限制: 5")
start_global = time.perf_counter()
try:
# 1. 創建任務列表(此時還沒開始跑)
tasks = [client.fetch_completion(i) for i in range(total_tasks)]
# 2. 🚀 發射!併發執行所有任務
# 這就像 Spark 的 collect(),等待所有結果返回
results = await asyncio.gather(*tasks)
finally:
await client.close()
total_time = time.perf_counter() - start_global
print(f"\n🎉 全部搞定!總耗時: {total_time:.2f}s")
# 理論上,如果是串行,耗時應該是 所有任務耗時之和 (約 30s)
# 實際上,耗時應該是 (總任務數 / 併發數) * 平均耗時 (約 6-8s)
if __name__ == "__main__":
asyncio.run(main())
📊 運行邏輯圖解
04 💣 避坑指南:大數據工程師常犯的錯
❌ 錯誤一:在 Async 函數裏做 CPU 密集型計算
場景:你收到 LLM 的回覆後,想用正則表達式清洗一下數據,或者算個向量餘弦相似度。後果:整個 Event Loop 卡死。因為 Python 是單線程的,你在算數學題,服務員就沒法去端菜了。解法:對於 CPU 密集型任務,請使用 loop.run_in_executor 把它扔到線程池或進程池裏去,別佔用主線程。
❌ 錯誤二:忘記 await
場景:result = client.get(url)後果:你得到的不是 Response,而是一個 Coroutine 對象。就像你點完菜,服務員給了你一張排隊小票,你卻以為那是菜,直接拿起來吃(報錯)。
❌ 錯誤三:濫用 try...except 吞掉異常
場景:在 gather 中如果不妥善處理異常,一個任務報錯可能會導致整個批次崩潰,或者異常被靜默吞噬。解法:在每個子任務內部進行 try...except 捕獲,確保返回結構化的錯誤信息(如上文代碼所示)。
05 📝 總結
從 Java/Spark 轉型 Python AI 架構,Asyncio 是你必須跨越的第一道坎。
- Java 多線程 是“大力出奇跡”,靠資源堆砌解決併發。
- Python Asyncio 是“四兩撥千斤”,靠極致的時間管理解決 I/O 等待。
對於 LLM 應用這種極度依賴網絡 I/O(請求 API 往往需要幾秒甚至幾十秒)的場景,Asyncio 簡直是天作之合。掌握了它,你就能用最小的資源,構建出吞吐量驚人的 AI Agent。
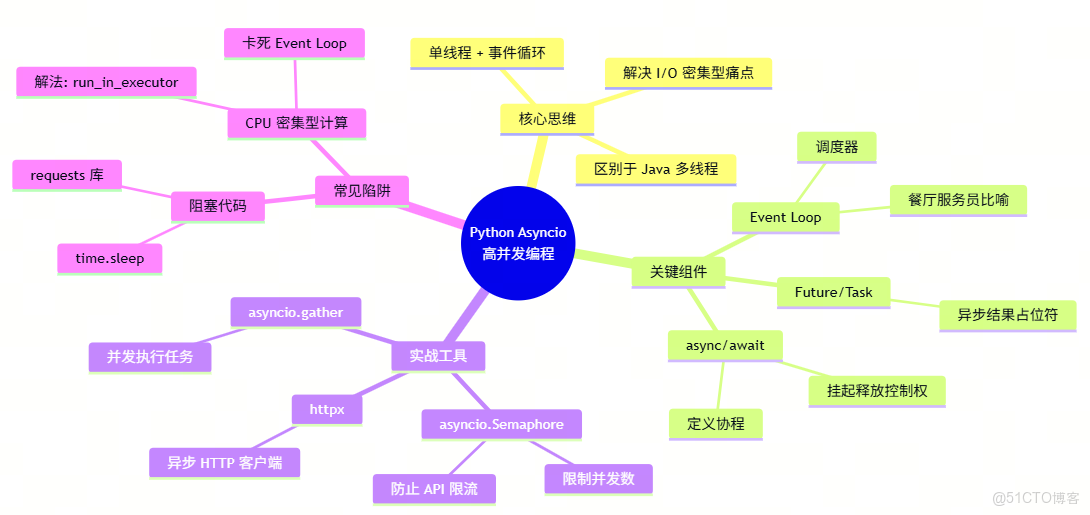
🧠 本文思維導圖
下期預告:搞定了高併發,LLM 生成的內容像打字機一樣一個字一個字蹦出來是怎麼實現的?下一篇我們將深入 **Python 生成器 (Generators) 與流式響應 (Streaming)**,敬請期待!
👇 覺得有用?點個“在看”,讓更多大數據兄弟看到!