
💡 本文價值提示
你是否遇到過這種情況:同一個 Prompt,有時候模型回答得一本正經,有時候卻胡言亂語?或者你想讓模型寫代碼,它卻給你編造了一個不存在的庫?
作為從大數據轉型而來的架構師,你習慣了 SQL 查詢結果的“確定性”(1+1 永遠等於 2)。但在 AI 的世界裏,“概率”才是王道。
本文將帶你深入 LLM 的“大腦皮層”,揭示控制模型輸出性格的兩個核心參數——Temperature 和 Top-P。掌握它們,你就能在“精準的業務邏輯”和“發散的創意生成”之間自由切換,真正駕馭模型,而不是被模型“抽獎”般的結果所困擾。
🎬 前情回顧與引入
👋 大家好!歡迎回到我們的**“大數據工程師轉型 AI 架構師”**系列。
在上一篇《拆解大模型“心臟”:BERT與GPT的相愛相殺(架構師進階指南)》中,我們學會了如何把萬事萬物變成向量,扔進向量數據庫裏做語義檢索。這讓我們擁有了強大的“記憶庫”(RAG 的基礎)。
但是,光有記憶是不夠的。當模型檢索到信息,準備開口説話時,它該怎麼説? 是像法官一樣字斟句酌?還是像脱口秀演員一樣天馬行空?
這就涉及到了大模型推理(Inference)階段最關鍵的**“控制論”**。今天,我們要打開大模型的黑盒,調整兩個決定它“性格”的旋鈕。
🎲 第一部分:大模型的本質——一場“文字接龍”的賭局
在理解參數之前,我們必須先打破一個幻想:大模型其實並不“思考”,它只是在“猜”下一個字。
當你輸入“今天天氣真”的時候,模型內部會計算詞庫中所有詞出現的概率分佈:
- “好”:概率 70%
- “不錯”:概率 20%
- “糟糕”:概率 9%
- “蘋果”:概率 0.001% (完全不通順)
模型本質上就是一個超高維度的概率預測機。
👉 架構師視角的差異:
- 傳統程序:
if input == "A" return "B"(確定性)。 - 大模型:
input "A" -> P(B)=0.8, P(C)=0.2(隨機性)。
那麼問題來了:模型是每次都選概率最大的那個詞嗎? 答案是:不一定。 這完全取決於你如何設置接下來的兩個參數。
🌡️ 第二部分:Temperature(温度)——給概率分佈“加熱”
Temperature 是最常用的參數,通常範圍在 0 到 2 之間。
1. 核心原理:冰與火之歌 🔥❄️
想象一下,模型的候選詞概率是一塊橡皮泥。
-
❄️ 低温 (Low Temperature, e.g., 0.1 - 0.3) :
- 效果:相當於把橡皮泥冷凍住。概率高的詞(山峯)會變得更高,概率低的詞(山谷)會變得更低。
- 行為:模型變得極其保守、自信、死板。它幾乎只選概率最高的那個詞。
- 人設:嚴謹的理工男、會計師、代碼審查員。
-
🔥 高温 (High Temperature, e.g., 0.7 - 1.0+) :
- 效果:相當於給橡皮泥加熱,它融化了,攤平了。原本概率高的詞,優勢不再明顯;原本概率低的詞,也有機會被選中。
- 行為:模型變得多樣、活躍、不可預測。它可能會選一些冷門的詞,帶來驚喜(或驚嚇)。
- 人設:浪漫的詩人、瘋癲的藝術家、醉酒的聊天伴侶。
2. 流程圖解:温度如何影響選擇
🎯 第三部分:Top-P (Nucleus Sampling) —— 設立“VIP 門檻”
除了温度,還有一個參數叫 Top-P(通常設為 0.1 到 1.0)。很多初學者容易把它和 Temperature 搞混。
1. 核心原理:切斷長尾 ✂️
如果説 Temperature 是改變概率分佈的形狀(變尖或變平),那麼 Top-P 就是在劃定候選池的範圍。
Top-P = 0.9 意味着:“只在累積概率達到 90% 的前幾個詞裏進行選擇,剩下的垃圾詞我看都不看。”
- 場景模擬:
- 詞庫裏有 10000 個詞。
- 前 5 個詞(蘋果、香蕉...)加起來概率就到了 90%。
- 如果 Top-P = 0.9,模型就只在這 5 個詞裏擲骰子。後面 9995 個詞(比如“拖拉機”、“外星人”)直接被截斷(Truncated)。
2. 為什麼要用 Top-P?
它可以防止模型在高温下“徹底發瘋”。即使 Temperature 很高,Top-P 也能保證模型選的詞至少是“靠譜圈子”裏的,避免選出概率極低、邏輯完全不通的詞。
🏗️ 第四部分:架構師的決策指南——場景化配置
作為架構師,你的價值不在於知道這些參數的定義,而在於針對不同的業務場景,制定最佳的參數組合策略。
這是我為你總結的 **“黃金配置表”**:
| 業務場景 | 推薦 Temp | 推薦 Top-P | 理由 | 風險提示 |
|---|---|---|---|---|
| 代碼生成 / SQL 轉換 | 1.0 | 代碼容錯率極低,必須精準,不能有隨機性。 | 設為 0 時,模型可能陷入重複循環。 | |
| 數據提取 (JSON) | 0 - 0.1 | 1.0 | 格式必須嚴格,Key/Value 不能亂編。 | 同上。 |
| RAG (知識庫問答) | 0.1 - 0.3 | 0.9 | 基於事實回答,需要嚴謹,但保留微小潤色空間。 | 温度過高會導致“幻覺”,編造文檔裏沒有的內容。 |
| 通用聊天機器人 | 0.5 - 0.7 | 0.9 | 需要像人一樣自然,太死板會像復讀機。 | 偶爾會一本正經地胡説八道。 |
| 創意寫作 / 營銷文案 | 0.8 - 1.0 | 0.8 - 0.9 | 需要腦洞,拒絕陳詞濫調。 | 邏輯性可能變差,需要人工審核。 |
💡 架構師的實戰心法:
- 控制幻覺 (Hallucination): 在金融、醫療等嚴肅場景,Temperature 必須壓低。你絕對不希望 AI 幫你生成的財務報表裏出現一個隨機數字。
- 互斥關係: 雖然 OpenAI 文檔建議“Temperature 和 Top-P 最好只調一個”,但在實際工程中,通常的做法是:固定 Top-P (如 0.9) 以保證下限,然後動態調整 Temperature 以控制上限。
- 方差測試: 如何驗證你的 Prompt 是否穩定?把 Temperature 設為 0.7,連續調用 5 次。如果 5 次結果意思完全不一樣,説明你的 Prompt 約束力不夠,或者模型本身對該領域知識掌握不牢。
📝 實踐任務:親手“調戲”模型
不要光看,去寫代碼!使用 Python 調用 API 時,嘗試修改這兩個參數:
import openai
def get_response(prompt, temp):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=temp, # <--- 關鍵在這裏
)
return response.choices[0].message.content
prompt = "請用三個詞形容一下大數據工程師。"
# 實驗 1:嚴謹模式
print(f"Temp=0.1: {get_response(prompt, 0.1)}")
# 輸出可能是:專業、嚴謹、技術控 (每次運行幾乎都一樣)
# 實驗 2:瘋癲模式
print(f"Temp=1.2: {get_response(prompt, 1.2)}")
# 輸出可能是:數據的馴獸師、鍵盤上的舞者、熬夜冠軍 (每次運行都不同,甚至出現怪詞)
🧠 總結:從原理到架構的思維導圖
讓我們用一張圖來總結今天的內容,這是你作為架構師知識庫中的重要拼圖:
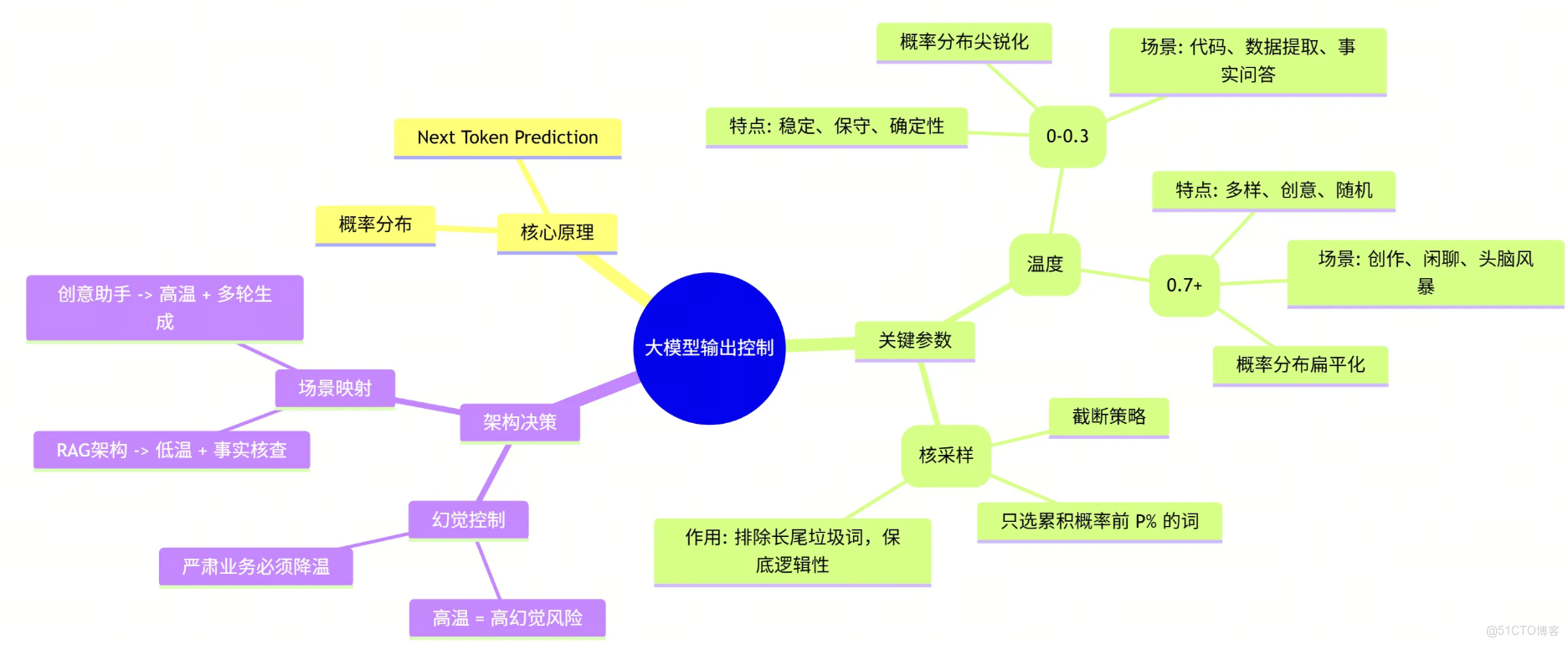
🧩 架構師的完整拼圖:LLM 核心鏈路覆盤
至此,我們已經完成了 “大模型基礎理論” 這一專題的全部學習。作為架構師,當你再次審視一個 AI 應用時,不應再把它看作一個黑盒,而是一條清晰的數據流水線:
- 🧱 數據入口 (Tokenization) : 一切始於分詞。它是計費的單位,也是上下文窗口的物理限制。你明白了為什麼中文和英文的消耗不同,也懂得了如何在有限的窗口內“精打細算”。
- 🧠 核心引擎 (Transformer) : 這是心臟。通過 Attention 機制,模型不再是死記硬背,而是學會了“關注”上下文的關聯。你瞭解了 Encoder(理解)與 Decoder(生成)的區別,從而能為不同的業務選擇正確的模型架構。
- 🌉 語義橋樑 (Embedding) : 這是連接人類語言與機器數學的隧道。通過向量化,我們將模糊的“語義”變成了可計算的“距離”。這是你構建企業級知識庫(RAG)和語義搜索的基石。
- 🎛️ 輸出控制 (Temperature) : 這是最後一道閥門。通過調整概率分佈,你掌握了模型的“性格”。你不再被動接受結果,而是主動權衡“精準”與“創意”,讓模型在嚴謹的邏輯與發散的思維間自由切換。
這四個環節,構成了大模型應用的“骨架”。 掌握了它們,你就擁有了透過現象看本質的能力,不再被層出不窮的新名詞迷惑,而是能從底層原理出發,設計出穩健、高效的 AI 架構。
💬 互動話題
你在使用 ChatGPT 或開發應用時,有沒有遇到過因為 Temperature 設置過高而產生的“神回覆”或離譜的幻覺?
歡迎在評論區分享你的“翻車現場”,讓我們一起看看 AI 喝醉了是什麼樣子!👇👇👇