
1 模型架構描述
Diffusion-TS的模型結構始於將時間序列數據輸入一個基於Transformer的編碼器進行編碼,以獲得其全局的向量表示。解碼器隨後對這些表示進行解碼,其輸出通過一個權重矩陣進行映射後分流:一部分送入趨勢合成層,另一部分進入傅里葉合成層。輸入全連接神經網絡(FFN)的部分經處理後,對已經過自注意力機制和交叉注意力機制處理的時序特徵進行非線性變換和維度提升,此舉顯著增強了模型從加噪輸入中捕獲複雜依賴關係的能力。處理後的特徵再與解碼器的中間輸出向量進行逐元素相加,以整合信息。圖1清晰地展示了這一解碼器架構。
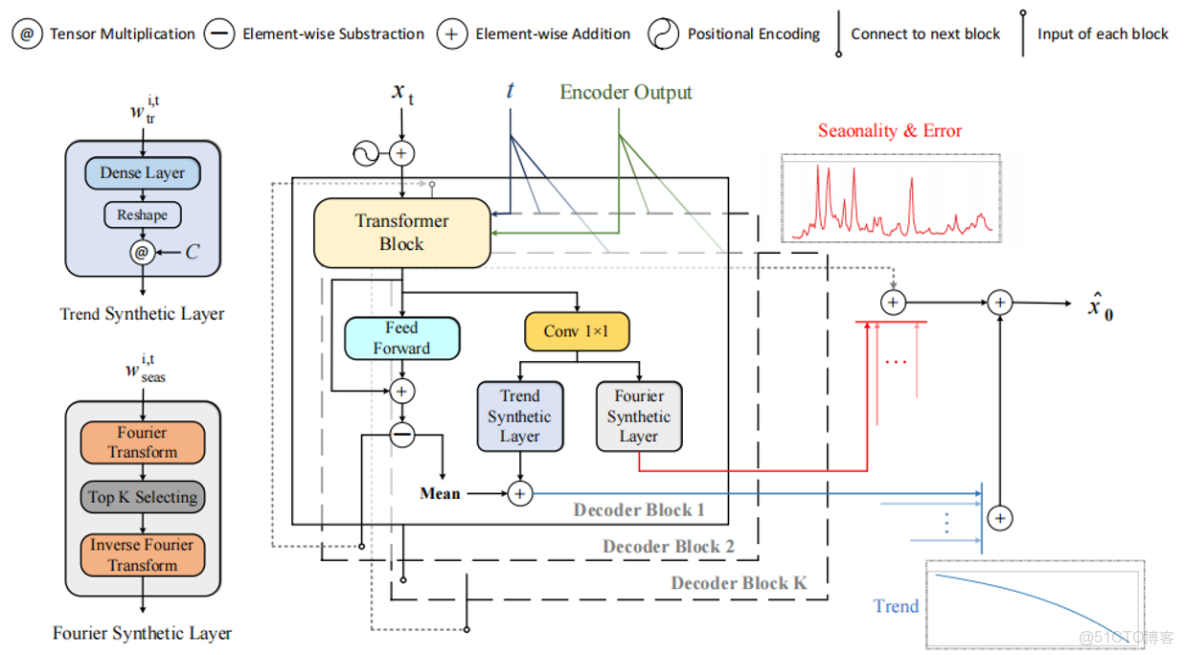
圖1 Diffusion-TS的模型結構圖
在趨勢提取方面,模型通過讓Transformer、FFN及加減運算協同工作,專注於學習一個相對簡化的任務——預測序列的“基線”或“平均水平”。這個基線本質上是趨勢成分最核心的體現,即模型對去除噪聲和季節性波動後序列平滑基線的估計(表示為“Mean”)。具體而言,Transformer層產生中間特徵表示

,其中一部分用於計算均值

。隨後,模型使用多項式迴歸器來顯式地建模趨勢成分

,其公式如下:

其中,C是一個由向量

的冪次構成的矩陣(多項式空間),p是一個較小的階數(例如3),用於模擬低頻行為。這個設計旨在捕獲平滑、緩慢變化的趨勢。隨後,

減去該趨勢成分得到一個去趨勢的信號,此信號被傳遞給傅里葉合成層進一步提取季節性成分。該層基於傅里葉級數,通過選擇頻域中振幅最大的K個分量來建模季節性,其數學表達為:
} \cos\left(2\pi f_{k}j + \Phi_{i,t}^{(k)}\right)")
這裏,
}")
和
}")
分別是第k個頻率分量的振幅和相位,通過離散傅里葉變換 F得到,fk是對應的傅里葉頻率。最終,原始信號的估計 x^0由趨勢、季節性和殘差(由最後一個解碼器塊的輸出 R表示)相加重構而成:

這種顯式的、基於公式的分解是模型可解釋性和高生成質量的關鍵來源。
2 擴散過程與條件生成機制
原始擴散模型的反向過程由
 = \mathcal{N}(x_{t-1}; \mu_{\theta}(x_{t}, t), \Sigma_{\theta}(x_{t}, t))")
描述,其目標是從噪聲 xT中通過去噪過程還原出原始數據 x0。這個過程本質上是無條件的,模型的核心是學習原始數據分佈 p(x0)。Diffusion-TS的一個關鍵設計是修改了訓練目標,它不直接預測噪聲 ϵ,而是訓練神經網絡直接預測一個對原始樣本的估計
")
,並結合了一個傅里葉基損失(Fourier-based loss)項
 - FFT(\hat{x}_{0})\|_{2}^{2}")
來增強頻域重建的準確性。最終的總損失函數為:

這個設計迫使模型同時優化時域和頻域特徵。這一設計的關鍵優勢在於,它解決了單一時域損失MSE在捕獲複雜週期模式上的不足。MSE項保證生成序列在時間維度上的基本保真度,而FFT損失則專門確保其週期性行為的真實性。
原始擴散模型的反向過程由
 = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t))")
描述,其目標是從噪聲

中還原原始數據

。這個過程是無條件的,模型主要學習原始數據分佈
")
。為了支持條件生成,Diffusion-TS引入了分類器引導機制。該方法通過後驗概率分佈
 = \prod_{t=1}^{T} p(x_{t-1} x_t, y)")
進行近似採樣,並基於
 \propto p(x_{t-1}\mid x_t) \cdot p(y\mid x_{t-1}, x_t)")
推導梯度計算過程,具體步驟如圖2所示。

圖2 分類器引導擴散模型的條件概率梯度推導
其核心改進是在原始擴散模型的反向傳播中加入了外部條件y ,引導生成過程產生符合條件的時間序列。相應的對數概率梯度分解為:
 = \nabla_{x_{t-1}} \log p(x_{t-1}\mid x_t) + \nabla_{x_{t-1}} \log p(y\mid x_{t-1})")
其中,無條件擴散模型的先驗概率確保生成數據符合真實分佈,而分類器梯度則評估當前中間結果

符合目標條件y的程度,並提供調整方向。該梯度信號通常由預訓練的判別模型提供。
在插補和預測等具體任務中,條件採樣方法表示為:
 = \tilde{x}_0(x_t, t, \theta) + \eta \nabla_{x_t} \left\| x_a - \tilde{x}_a(x_t, t, \theta) \right\|_2^2 + \gamma \log p(x_{t-1} \mid x_t)")
這裏,
")
是經梯度引導修正後的最終預測結果,
")
是Diffusion-TS的無條件預測值。該方法在原始擴散模型的先驗概率似然項基礎上增加了重構損失項
 \right\|_2^2")
,旨在使生成樣本中與條件對應的部分

儘可能接近真實值。先驗概率作為正則項,防止生成過程為過度擬合條件而偏離真實數據分佈,從而保持生成樣本的多樣性和真實性。梯度項引導

變化,使得模型預測的

在條件部分

上逼近真實值。這種設計極具靈活性:同一個預訓練的Diffusion-TS模型只需在採樣時更換引導函數(如從插值條件改為預測條件),即可適應不同下游任務,實現“即插即用”。值得注意的是,
 := \sqrt{\bar{\alpha}_t} x_a + \sqrt{1 - \bar{\alpha}_t} \epsilon")
表示將真實條件

通過前向擴散過程加噪至時間步t後的狀態。在生成過程中,會將生成樣本里對應已知條件

的部分強制替換為該加噪真實值,以確保去噪過程中已知部分始終與真實條件嚴格匹配,增強條件生成的一致性。此後,利用新的

還原出

。
3 採樣算法與優化
擴散模型的反向過程可劃分為早期“創造階段”和後期“平滑階段”。論文中提出了重構引導採樣算法,如圖3中的算法1所示。該算法從完全噪聲
")
開始迭代去噪。在每個時間步,它從原始預測的

中分割出對應原始條件數據

的部分和需生成的部分

,將兩者拼接成完整序列後計算重構損失

。接着執行一次無條件去噪,使用

和

計算均值

,並從構造的分佈中採樣出

。隨後計算模型先驗損失

(即採樣得到的

與理論均值

的差異)。關鍵的第7步對應上述梯度引導更新公式,第8步則執行引導後的去噪過程,重新計算均值並採樣得到新的

。
")
操作將新採樣的

中對應已知條件

的部分,用真實條件數據加上時間步t-1的對應噪聲替換,以確保條件一致性。

圖3 重構採樣算法偽代碼
算法2是算法1的優化版本,其核心改進是引入了動態調整的梯度更新次數K[t],該參數表示在擴散時間步t重複執行梯度更新的次數。在噪聲較多的早期創造階段,設置較大的K[t]值,通過多次梯度更新強條件引導,確保生成樣本的基礎結構與給定條件高度一致。在噪聲較少、數據已較清晰的後期平滑階段,則設置較小的K[t]值,減少不必要的計算開銷,加速採樣過程,因此階段過度優化收益已不顯著。
4 核心收穫與創新啓發
通過研讀Diffusion-TS的相關文獻,我在改進基礎條件生成模型方面獲得了一些收穫以及創新思路。
主要收穫如下:
1. 可解釋性驅動的架構設計:Diffusion-TS將季節性-趨勢分解技術融入擴散模型的去噪網絡是一大創新。通過編碼器-解碼器架構中的趨勢合成層與傅里葉合成層,模型能顯式學習時間序列的趨勢、週期項和殘差等成分。這不僅提升了生成質量,其可解釋的生成結果(可分解為具體時間模式)還為條件生成提供了語義層面的控制基礎。
2. 基於重構的訓練目標:與傳統擴散模型預測噪聲不同,Diffusion-TS直接預測原始樣本

並結合傅里葉域損失。此設計迫使模型在去噪中同步優化時域和頻域特徵,尤其適合強週期性的時間序列數據,使條件生成能更精準地保持序列的頻譜特性。
3. 靈活的條件控制機制:其提出的基於重構指導的採樣算法,利用預訓練擴散模型的條件得分估計,通過梯度更新引導生成樣本滿足約束(如已知片段),無需修改模型即可適配插值、預測等任務。這種“即插即用”的方式避免了傳統方法需重新訓練的問題。
由此衍生的創新思路包括:
1. 分層條件控制:可借鑑其分解架構,在條件生成時對趨勢項和季節項分別施加不同約束。例如預測任務中,可用外部變量指導趨勢生成,同時通過週期模板約束季節項,實現更細粒度的控制。
2. 動態權重機制:文獻中的冷啓動實驗表明模型在數據缺失時仍穩定。由此可延伸出自適應權重策略——根據條件信息的完整度動態調整傅里葉損失與重構損失的權重。條件信息少時,增大頻域約束權重以利用週期先驗;條件信息充足時,則側重時域重構精度。
3. 多尺度條件融合:參考其編碼器提取全局特徵的能力,可在條件生成時設計多尺度條件注入機制。例如,局部條件(如近期歷史值)通過交叉注意力注入解碼器,而全局條件(如整體統計量)作為擴散步長的嵌入向量,從而增強對長短週期條件的協同利用能力。