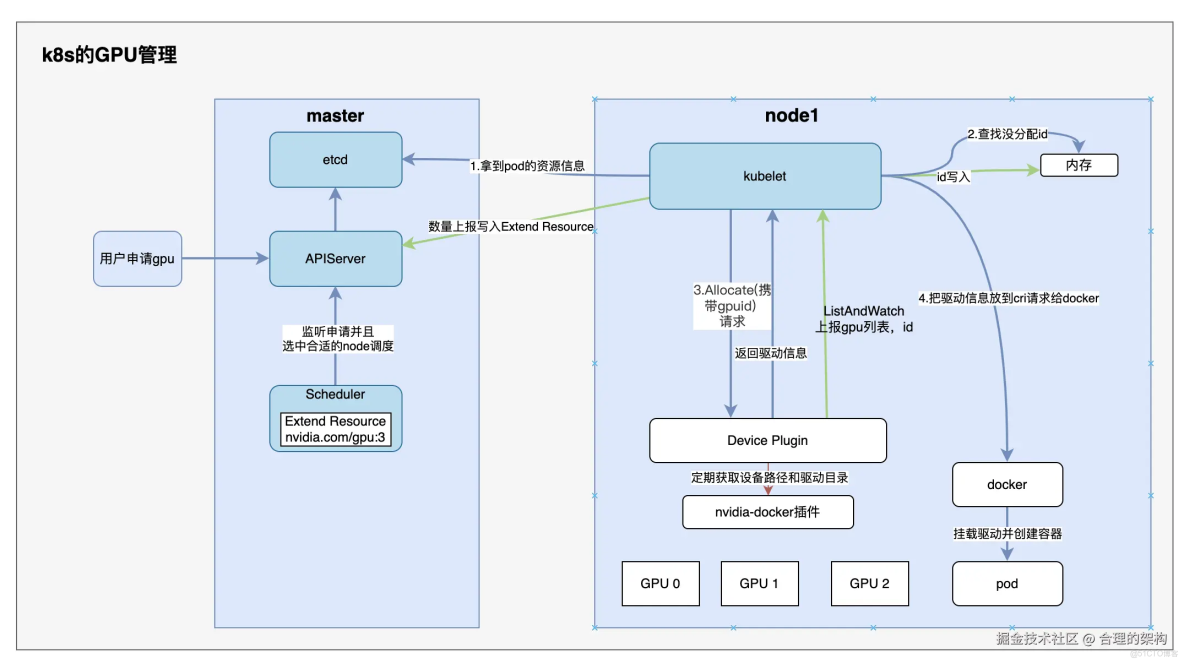
Kubernetes通過Device Plugin機制實現GPU資源管理,其核心流程可分為四個階段:
- 設備發現與上報
- NVIDIA GPU Device Plugin通過ListAndWatch API定期向kubelet彙報節點上的GPU設備列表(如GPU0/1/2)
- kubelet將GPU數量(nvidia.com/gpu:3)以Extended Resource形式通過心跳上報給API Server
- 資源調度
- Pod在limits字段聲明nvidia.com/gpu需求後,調度器根據節點GPU緩存進行匹配
- 調度成功後對應kubelet會持有GPU分配的元數據
- 設備分配
- kubelet通過Allocate()請求向Device Plugin傳遞分配的GPU ID
- 插件根據ID查詢設備路徑和驅動目錄(如通過nvidia-docker獲取信息)
- 容器注入
- kubelet將設備信息注入CRI請求,由運行時(如Docker)完成GPU設備的容器掛載
- 最終容器獲得可見的GPU設備和驅動目錄訪問權限
整個流程實現了從硬件抽象到容器調度的自動化管理,用户僅需聲明資源需求即可使用GPU能力。
重點:圖