

原始博文鏈接
簡介
CRUD-Boy,這是一個很尷尬的名詞。Create、Retrieve、Update、Delete,像是四件法器,人人都喜歡提高併發、高可用,與之陪襯的便是缺乏藝術感和想象力的CRUD,可真要做一個工程應用還是得靠這玩意兒打天下。但它又是像是一柄達摩克利斯之劍,機械地使用它,也許真的會消磨掉人的熱忱,甚至要命。
千萬螻蟻築成大廈,CRUD連接你我。不會不行,只會也不行。總有那麼段時光是CRUD陪你度過的,那隻好儘量優雅一些吧,起碼寫完看起來還舒服一點。雖説是CRUD,但是本篇主要介紹R、查詢為主,其他的皆可觸類旁通。
簡史
SQL是CRUD的祖宗,數據庫是萬惡之源。從手寫SQL通過JDBC操作開始,逐步誕生了ORM(Object Relational Mapping)框架。首先解決的是返回值的處理,面向對象這一套東西就天生與數據返回的零散字段不和,得把字段裝起來變成一個對象。返回值的處理夠舒服了,接下來就是SQL的生成,一派MyBatis,一派Hibernate,Hibernate這一派被官方選中然後就出了個JPA(Java Persistent API),兩派各有千秋。MyBatis這一派更多的是擴展、插件,JPA這一派更多是封裝、整合、適配。好像也有拿MyBatis去實現JPA的,不過感覺理念上就不太合得上,目前為止好像也沒鬧出太大的動靜。
這篇主要説JPA這一派的查詢SQL構建。
Hibernate
要説JPA還是離不開Hibernate,畢竟源頭就是Hibernate。作為一款全自動框架,可以感覺到Hibernate是希望完全摒棄使用SQL, Hibernate通過Entity、ManyToOne、OneToMany、ManyToMany等概念將表和類、表與表之間的關係和類與類之間的關係進行相互對應描述,並且把返回值封裝後的實體全部管理了起來,形成了一套生命週期體系。
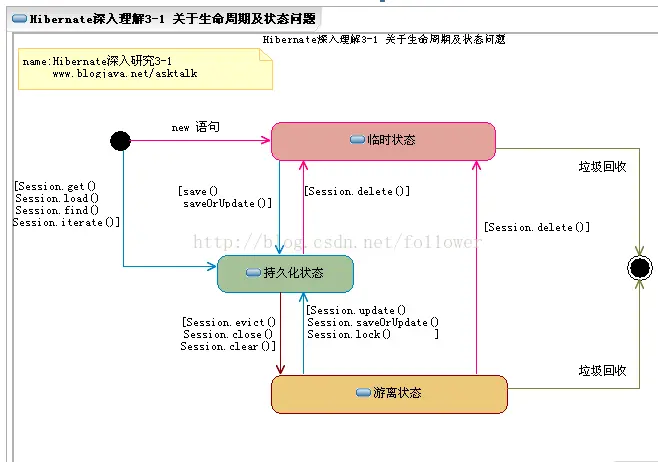
這種管理構成了Hibernate的一級緩存,在同一個Session下,可以不重複獲取相同數據,並且能夠延遲操作數據庫的時間,在事務提交時統一刷新處理提高效率。並且Hibernate可以感知到數據的更改,與數據庫進行自動同步。
優點是完全面向對象,描述問題和業務場景非常直接。
缺點也很明顯,極容易產生大量的SQL語句、自動更新對象讓人覺得有些“自作主張”(沒讓你存你怎麼自己就存上了)、SQL優化不方便、複雜查詢不方便、更新語句臃腫。
優點有點短,不過份量很重。缺點不是想改就改的缺點,為了實現優點,缺點也是不得已而為之。有些缺點確實挺致命的,導致應用的流行程度不如MyBatis高,但也在逐步改善。
JPA
JPA是一套持久化的規範,作為一套標準的接口,可以有各種各樣的實現,不過主要還是以Hibernate為主,畢竟JPA的主導者就是Hibernate的作者,本身的設計也大量借鑑了Hibernate。JPA的EntityManager基本上可以認為是和Hibernate的Session相互對應。個人覺得相較於Hibernate的接口,JPA的設計確實更加舒服一些。
首先列出示例代碼會用到的實體類,接下來介紹本篇的3個主要內容。
@Entity
@Table(name = "Gift")
@Data
@NoArgsConstructor
public class Gift implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String description;
private Double price;
private Double cost;
@ManyToOne
@JoinColumn(name = "buyer_id")
private Person buyer;
@Version
private Integer version;
@UpdateTimestamp
private Timestamp updateTime;
}
@Entity
@Getter
@Setter
@NoArgsConstructor
public class Person implements Serializable {
@Id
@GeneratedValue
private Long id;
private String personName;
public Person(String personName) {
this.personName = personName;
}
}實體類中有使用到Lombok註解,如果不清楚可以先了解一下,很不錯的一個代碼工具。
Criteria API
JPA在JDK1.5時引入,JDK1.6時JPA更新到2.0版本,帶來了許多新的特性和增強,對於本篇來説最重要的就是其中的Criteria API。説到這個還是要先提一下JPQL。和JPA類似,JPQL前身是HQL(Hibernate Query Language),目的為了全面適應面向對象和應對一些當時無法解決的複雜查詢。JPQL和SQL非常類似,一句話概括來説SQL是from Table而JPQL是from Object。
JPQL無法解決的問題主要是沒有動態調整語句的能力以及保證類型安全能力。而這兩點,尤其是第一點,正是Criteria API所能夠解決的。Criteria的核心是對查詢的描述和解析,通過一系列類和接口完整描述查詢的內容後就可以生成語法樹翻譯成為正確的SQL語句。
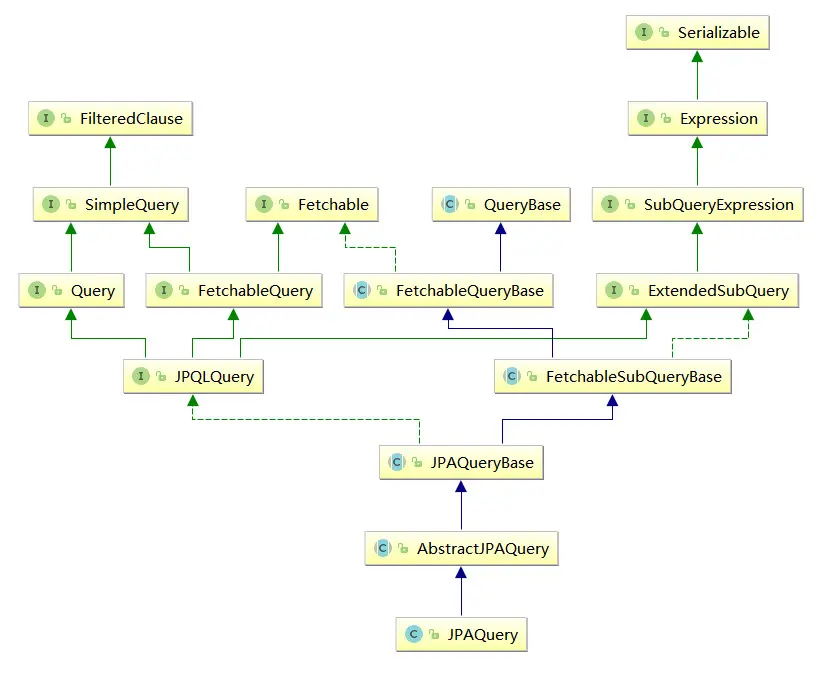
接口結構
以下是javax.persistence.criteria包下絕大部分接口的關係圖:
{% asset_img criteriaAPI.png criteriaAPI %}
內容不少,但是核心接口主要是三個:
- CriteriaBuilder:基本構建器,創建Criteria、Predicate等等
- Criteria:主要以CriteriaQuery來説,是整個查詢描述的主體
- Expression:表達式的核心接口,以Root和Predicate使用居多
Criteria可以保證類型安全,但並不是強制性的,如果需要保證類型安全則需要編寫額外的持久化元模型來構建表達。基本結構形似如下:
public class Person_ {
public static volatile SingularAttribute< Person,Long> id;
public static volatile SingularAttribute< Person,String> personName;
}元模型也可以通過Annotation Processor工具生成規範元模型,這部分不詳細描述,有興趣可以自查。
代碼示例
本篇所有的示例都是寫在SpringBoot項目下的測試類中
@SpringBootTest
@RunWith(SpringRunner.class)
public class QueryTest {
@PersistenceContext
private EntityManager entityManager;
@Test
public void testCriteria(){
// 簡單條件查詢
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Gift> simleQuery = cb.createQuery(Gift.class);
Root<Gift> simpleRoot = simleQuery.from(Gift.class);
simleQuery.where(cb.and(
cb.greaterThan(simpleRoot.get("cost"), 70),
cb.isNotNull(simpleRoot.get("name"))));
simleQuery.orderBy(cb.asc(simpleRoot.get("cost")));
TypedQuery<Gift> typedQuery = entityManager.createQuery(simleQuery);
List<Gift> result = typedQuery.getResultList();
System.out.println("count: "+result.size());
// join條件查詢
CriteriaQuery<Gift> joinQuery = cb.createQuery(Gift.class);
Root<Gift> joinRoot = joinQuery.from(Gift.class);
Join<Gift, Person> buyerJoin = joinRoot.join("buyer");
simleQuery.where(cb.and(
cb.greaterThan(simpleRoot.get("cost"), 70),
/*cb.equal(simpleRoot.get("buyer").get("personName"), "mike")*/
cb.equal(buyerJoin.get("personName"), "Mike")));
simleQuery.orderBy(cb.asc(simpleRoot.get("cost")));
TypedQuery<Gift> typedQuery2 = entityManager.createQuery(simleQuery);
List<Gift> result2 = typedQuery2.getResultList();
System.out.println("count: "+result2.size());
// 查詢指定數據
CriteriaQuery<javax.persistence.Tuple> tupleQuery = cb.createTupleQuery();
Root<Gift> specRoot = tupleQuery.from(Gift.class);
tupleQuery.select(cb.tuple(
specRoot.get("id"),
specRoot.get("name"),
specRoot.get("price")));
tupleQuery.where(cb.and(
cb.greaterThan(simpleRoot.get("cost"), 70),
cb.isNotNull(simpleRoot.get("name"))));
tupleQuery.orderBy(cb.asc(simpleRoot.get("cost")));
TypedQuery<javax.persistence.Tuple> typedQuery3 = entityManager.createQuery(tupleQuery);
List<javax.persistence.Tuple> result3 = typedQuery3.getResultList();
System.out.println("count: "+result2.size());
// 複雜查詢示例
// 使用case...when進行sum操作
CriteriaQuery<javax.persistence.Tuple> sumQuery = cb.createTupleQuery();
Root<Gift> sumRoot = sumQuery.from(Gift.class);
Expression<Integer> flag = cb.selectCase(sumRoot.get("name"))
.when("金塊", 100)
.when("銀塊", 90)
.when("銅塊", 30)
.when("塑料", 10)
.otherwise(0).as(Integer.class);
sumQuery.select(cb.tuple(cb.sum(flag)));
sumQuery.groupBy(sumRoot.get("buyer").get("personName"));
javax.persistence.Tuple singleResult = entityManager.createQuery(sumQuery).getSingleResult();
System.out.println(singleResult.get(0));
// 使用排序函數
CriteriaQuery<Gift> orderQuery = cb.createQuery(Gift.class);
Root<Gift> orderRoot = orderQuery.from(Gift.class);
orderQuery.orderBy(cb.desc(
cb.function("FIELD",null, orderRoot.get("name"),
cb.literal("金塊"),
cb.literal("銀塊"),
cb.literal("銅塊"),
cb.literal("塑料"))));
}
}總的來説,主體(CriteriaQuery)、條件、排序、聚合等內容的創建都由CriteriaBuilder創建,查詢的字段一般通過Root獲取,排序、組合等通過查詢主體操作。處理完一個查詢一般需要三個基本對象:CriteriaBuilder、CriteriaQuery、Root。
Querydsl
Querydsl是一個基於各種ORM之上的一個通用查詢框架,專注於通過Java API構建類型安全的SQL查詢,使用它的API類庫可以寫出“Java代碼的sql“。目前Querydsl支持多種平台,包括:JPA、原生SQL、MongoDB、Lucence和JDO等。
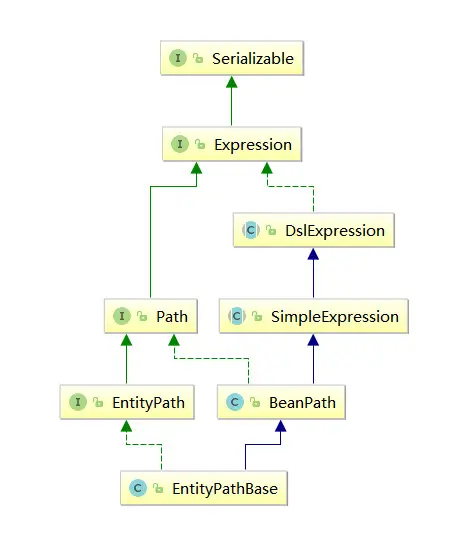
接口結構
以下是com.querydsl.core.types包下大部分接口以及其他部分核心接口的關係圖:
{% asset_img QueryDslAPI.png QueryDslAPI %}
可以看到Querydsl整個API的設計更加集中到Expression這點上,這也是Querydsl能夠以流式API書寫代碼的原因之一。不過這張結構圖拿來直接和Criteria比是不太妥當的,首先這僅僅是Querydsl整個包的一部分,其次個人認為Querydsl的這些API更加專注於“interface”這個概念,而Criteria這邊因為JPA是一個規範,所以它的API更偏向於對實現類的指導。在實現類上也可以窺得一二,Criteria API的實現類一般就是接口名加上Impl後綴,只實現一個Criteria下的接口(當然具體實現沒有這麼簡單),而Querydsl的實現類一般是組合實現相應的基礎接口。以下是兩個Querydsl應用於JPA時的核心類JPAQuery、EntityPathBase的類圖。
應用方法
以結合JPA使用為例,需要引入querydsl-jpa和querydsl-apt以及編譯插件com.querydsl.apt.jpa.JPAAnnotationProcessor,使用maven時,示例如下:
<dependencies>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-jpa</artifactId>
<version>${querydsl.version}</version>
</dependency>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-apt</artifactId>
<version>${querydsl.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>com.mysema.maven</groupId>
<artifactId>apt-maven-plugin</artifactId>
<version>1.1.3</version>
<executions>
<execution>
<goals>
<goal>process</goal>
</goals>
<configuration>
<outputDirectory>target/generated-sources/java</outputDirectory>
<processor>com.querydsl.apt.jpa.JPAAnnotationProcessor</processor>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>編寫完實體類後,運行maven的compile命令,就會在outputDirectory指定的目錄下生成對應的查詢類型。
示例代碼
@SpringBootTest
@RunWith(SpringRunner.class)
public class QueryTest {
@PersistenceContext
private EntityManager entityManager;
@Test
public void testQuerydsl(){
QGift gift = QGift.gift;
JPAQueryFactory factory = new JPAQueryFactory(entityManager);
// 簡單條件查詢
List<Gift> simpleResult = factory.selectFrom(gift)
.where(
gift.cost.gt(70),
gift.name.isNotNull()
).fetch();
System.out.println("count: "+simpleResult.size());
// join條件查詢
QPerson person = QPerson.person;
List<Gift> joinResult = factory.selectFrom(gift)
.leftJoin(person)
.on(gift.buyer.id.eq(person.id)) // 示範操作,實體類沒有使用關聯的時候可以這麼處理
.where(
gift.cost.gt(70),
person.personName.isNotNull()
).fetch();
System.out.println("count: "+joinResult.size());
// 查詢指定數據
List<Tuple> tupleResult = factory.select(
gift.id,
gift.name,
gift.price
).from(gift).where(
gift.cost.gt(70),
gift.name.isNotNull()
).orderBy(gift.cost.asc()).fetch();
System.out.println("count: "+tupleResult.size());
// 複雜查詢示例
// 使用case...when進行sum操作
List<Tuple> sumResult = factory.select(gift.buyer.personName,
gift.name
.when("金塊").then(100)
.when("銀塊").then(90)
.when("銅塊").then(30)
.when("塑料").then(10)
.otherwise(0)
.sum()
).from(gift).groupBy(gift.buyer).fetch();
// 使用排序函數
StringTemplate orderExp = Expressions.stringTemplate("FIELD({0},{1},{2},{3},{4})",
gift.name,
"金塊", "銀塊", "銅塊", "塑料");
List<Gift> orderResult = factory.selectFrom(gift).orderBy(orderExp.desc()).fetch();
}
}可以感受到Querydsl所構建的查詢確實和構建SQL十分相似,所有操作都起始於Factory,元模型的結構能夠快速獲取字段對應的java屬性並且封裝了一些常用的方法,通過流式API構建的過程非常舒服。
Spring-Data
Spring Data作為Spring的一個子項目,其目的是提供一個簡便、可靠的基於Spring的持久化編程模型,同時保留底層數據存儲的特性。為了減少各種持久化工具實現數據訪問層所需的樣板代碼數量,Spring Data提供了一層二次抽象、封裝。這個子項目的子項目Spring Data JPA便是Spring Data針對JPA的整合。
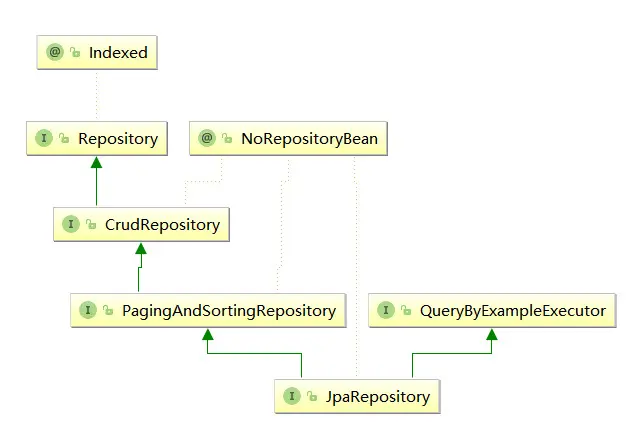
Spring Data抽象封裝的核心接口是Repository,它將Domain(領域)類或者Domain類的ID類型作為類型參數進行管理,通過進一步的繼承處理提供各種功能,例如CrudRepository提供了基本的CRUD功能。
領域驅動設計
Repository這個名稱取得非常有意圖,它來自於領域驅動設計(Domain Driven Design)的概念,DDD的核心在於提倡使用充血模型,規範出界限上下文建立對應的領域。充血模型簡單來説就是統一處理數據和行為,模型結構能夠完整地表達業務的一個領域,而不是建立一個數據對象然後使用各種service對象去執行方法。在DDD的概念下,接觸到需求第一步就是考慮領域模型,而不是將其切割成數據和行為,然後數據用數據庫實現,造成需求的首肢分離。DDD讓你首先考慮的是業務的各個領域,而不是數據。
DDD中的倉儲即為Repository,領域模型中的對象自從創建後不會一直留在內存活動,當它不活動時會被持久化到DB中,當需要的時候會重建該對象,倉儲即提供相關接口來幫助我們管理對象。
DDD的內容不是一兩句可以説清楚的,比較抽象,真正落地也不會很簡單。在本篇討論的範圍內,瞭解其核心思想即可,也有助於理解Spring Data為什麼這麼做。即便是不瞭解DDD,使用Spring Data的時候也還是會感覺到非常自然。
代碼示例
Spring Data的學習和應用還是應該參照官方文檔比較好,雖然看起來比較長,但是內容不算太多,也不是很深的東西,畢竟目標是簡化操作。這裏給出一些代碼,便可有個直觀的感受。
@SpringBootTest
@RunWith(SpringRunner.class)
public class QueryTest {
@Autowired
private GiftRepository giftRepository;
@Test
public void testSpringData(){
// 單個查詢
Gift gift = giftRepository.findById(1L).orElse(null);
// 條件查詢
List<Gift> result = giftRepository.findAll(new Specification<Gift>() {
@Override
public Predicate toPredicate(Root<Gift> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
Join<Gift, Person> buyerJoin = root.join("buyer");
Predicate predicate = cb.and(cb.greaterThan(root.get("cost"), 70),
cb.equal(buyerJoin.get("personName"), "Mike"));
query.orderBy(cb.asc(root.get("cost")));
return predicate;
}
});
// 分頁查詢
PageRequest page = PageRequest.of(0, 10);
Page<Gift> pageResult = giftRepository.findAll(new Specification<Gift>() {
@Override
public Predicate toPredicate(Root<Gift> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
query.orderBy(cb.asc(root.get("cost")));
return cb.and(
cb.greaterThan(root.get("cost"), 70),
cb.isNotNull(root.get("name")));
}
}, page);
}
@Test
public void testSpringDataWithDsl(){
// 結合Querydsl
QGift gift = QGift.gift;
PageRequest page = PageRequest.of(0, 10);
giftRepository.findAll(gift.cost.lt(10).and(gift.name.isNotNull()), page);
}
}核心優勢
説了一堆DDD的內容,實際用下來最直觀的感受就是不直接使用EntityManager來統一管理各個實體對象,而是採用對應的Repository來進行操作,整個DAO層由根據Repository生成的代理類進行掌控,數據的處理被劃分到各個對應的Repository中。使用ID查詢單個對象、使用條件查詢、持久化對象等基本高頻操作非常方便、直接。
使用Criteria時,查詢的條件封裝成為Specification,核心方法toPredicate直接將CriteriaBuilder、CriteriaQuery、Root三大核心傳入,減少重複的模板代碼。同時其和Querydsl結合良好,Querydsl生成的條件對象也可以直接交由對應的Repository進行處理。
不過相比於原生Criteria API和Querydsl來説,拋開設計的理念不談,個人覺得最具優勢的還是如下幾點:
- 簡單查詢封裝完備,能夠解析方法名直接作為CRUD方法
- 加鎖操作便捷
- 強力的分頁處理能力
注意事項
方便是方便,但Spring-Data只是一層封裝,內部核心還是JPA、Hibernate那一套東西,生命週期這些基本概念還是得學,在Spring Data這套API下,事務提交時、使用悲觀鎖查詢時還是會自動更新屬性被修改的對象,這點尤其容易被忽略造成想不到的錯誤。調用save方法依然可能會被延遲執行,到事務提交時再統一處理。
總結
擁有JPA Criteria API之後,基本可以消滅醜陋的SQL拼接,除了from語句的子查詢無法處理(畢竟返回值內容不符合面向對象)之外,基本上一般的SQL都是可以構建出來的。個人覺得單論MyBatis使用各式各樣的輔助標籤編寫XML來説,使用Criteria明顯更加舒服。Querydsl的封裝更是將使用java編寫sql的能力發揮到了極致,個人覺得如果願意, 拿MyBatis的邏輯來處理也不成問題,封裝一下對Tuple的映射,就又是一個XML轉java代碼的樣例,順便連生命週期那一套都給“抹掉”了,不過可行性有待驗證。
原生Criteria、Querydsl、SpringData、SpringData結合Querydsl,可選的方式還是比較多的。儘管Querydsl可能寫起來更舒服,但是要適應動態特性,必然會在代碼中嵌入一些if else for的東西,可能就沒這麼簡潔流暢了,而且最終還是要翻譯到Criteria那裏去。話又説回來,Querydsl與spring web方案還有個很不錯的整合,直接能夠把Http參數轉化成為Predicate,摘抄一段官方文檔的內容:
// url param
?firstname=Dave&lastname=Matthews
// resolved to dsl predicate
QUser.user.firstname.eq("Dave").and(QUser.user.lastname.eq("Matthews"))@Controller
class UserController {
@Autowired UserRepository repository;
@RequestMapping(value = "/", method = RequestMethod.GET)
String index(Model model,
@QuerydslPredicate(root = User.class) Predicate predicate,
Pageable pageable,
@RequestParam MultiValueMap<String, String> parameters) {
model.addAttribute("users", repository.findAll(predicate, pageable));
return "index";
}
}具體怎麼選還是視具體情況而定,不過相信有了這些工具和框架,CRUD能夠少一些枯燥繁瑣。