

文章和代碼已經歸檔至【Github倉庫:https://github.com/timerring/dive-into-AI 】或者公眾號【AIShareLab】回覆 R語言 也可獲取。
在分析之前,先將數據集 birthwt 中的分類變量 low、race、smoke、ht 和 ui 轉換成因子。
library(MASS)
data(birthwt)
str(birthwt)
options(warn=-1)
library(dplyr)
birthwt <- birthwt %>%
mutate(low = factor(low, labels = c("no", "yes")),
race = factor(race, labels = c("white", "black", "other")),
smoke = factor(smoke, labels = c("no", "yes")),
ht = factor(ht, labels = c("no", "yes")),
ui = factor(ui, labels = c("no", "yes")))
str(birthwt)獲取數據框裏每個變量的常用統計量是一種快速探索數據集的方法,這可以通過下面的一個命令實現。
summary(birthwt)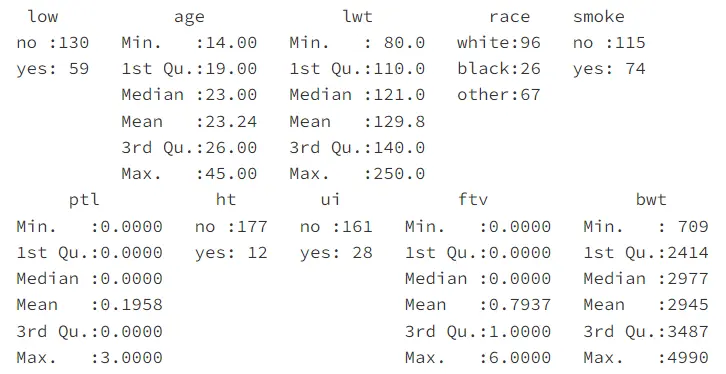
函數 summary( )可以對每個變量進行彙總統計。對於數值型變量,如 age、lwt、plt、ftv 和 bwt,函數 summary( )給出最小值、下四分位數、中位數、均值、上四分位數和最大值;對於分類變量,如 low、race、smoke、ht 和 ui,給出的則是頻數統計表。
epiDisplay 包的函數 summ( )作用於數據框可以得到另一種格式的彙總輸出,它將變量按行排列,把最小值和最大值放在最後兩列以方便查看數據的全距。
library(epiDisplay)
summ(birthwt)需要注意的是,對於因子型的變量,函數 summ( )把變量的各個水平當作數值計算統計量。
數值型變量的描述性統計分析
本節將討論數值型變量的集中趨勢、離散程度和分佈形狀等。這裏我們關注 3 個連續型變量:年齡(age)、母親懷孕前體重(lwt)和嬰兒出生時體重(bwt)。
cont.vars <- dplyr::select(birthwt, age, lwt, bwt)接下來,先計算這 3 個變量的描述性統計量,然後按照母親吸煙情況(smoke)分組考查描述性統計量。這裏 smoke 是一個二分類變量,我們在把它轉換成因子時已經為其兩個水平定義了標籤:“no”和“yes”。
除了上面提到的函數 summary( ),R 中還有很多用於計算特定統計量的函數(見第二章)。例如,計算變量 age 的樣本量、樣本均值和樣本標準差:
length(cont.vars$age)
mean(cont.vars$age)
sd(cont.vars$age)我們還可以用函數 sapply( )同時計算數據框中多個變量的指定統計量。例如,計算數據框 cont.vars 中各個變量的樣本標準差:
sapply(cont.vars, sd)基本包中沒有提供計算偏度和峯度的函數,我們可以根據公式自己計算,也可以調用其他包裏的函數計算,例如 Hmisc 包、psych 包和 pstecs 包等。這些包提供了種類繁多的計算統計量的函數,這幾個包在首次使用前需要先安裝。下面以 psych 包為例進行説明。psych 包被廣泛應用於計量心理學。
psych 包裏的函數 describe( )可以計算變量忽略缺失值後的樣本量、均值、標準差、中位數、截尾均值、絕對中位差、最小值、最大值、全距、偏度、峯度和均值的標準誤等。
例如:
R.Version()
library(psych)
describe(cont.vars)在很多時候我們還想計算某個分類變量各個類別下的統計量。在 R 中完成這個任務有多種方式,下面先從基本包的函數 aggregate( )和 tapply( )開始介紹。
aggregate(cont.vars, by = list(smoke = birthwt$smoke), mean)
aggregate(cont.vars, by = list(smoke = birthwt$smoke), sd)函數 aggregate( )中的參數 by 必須設為 list。如果直接使用 list(birthwt$smoke),則上面分組列的名稱將會是“Group.1”而不是“smoke”。我們還可以在 list 裏面設置多個分類變量,例如:
aggregate(cont.vars,
by = list(smoke = birthwt$smoke, race = birthwt$race),
mean)這裏的分類變量有 2 個,其中 smoke 有 2 個類別,race 有 3 個類別,上面的命令按照這兩個變量各類別的所有組合(共 6 組)計算均值。
當然,你也可以使用下面任一方式寫:
aggregate(birthwt[,c("age","lwt","bwt")],
by = list(smoke = birthwt$smoke, race = birthwt$race),
mean)
aggregate(cbind(age, lwt, bwt)~smoke+race, birthwt, mean)函數 tapply( )可以實現類似的功能,不同的是它的第一個參數必須是一個變量,第二個參數名是 INDEX 而不是 by。例如,計算變量 bwt 在母親不同吸煙情況下的均值,可以輸入:
tapply(birthwt$bwt, INDEX = birthwt$smoke, mean)
# no 3055.69565217391 yes 2771.91891891892epiDisplay 包裏的函數 summ( )也可以實現類似的功能,不同的是該函數裏的統計量是固定的,而且函數的輸出包含一個按照分類變量繪製的有序點圖,如下圖所示。
summ(birthwt$bwt, by = birthwt$smoke)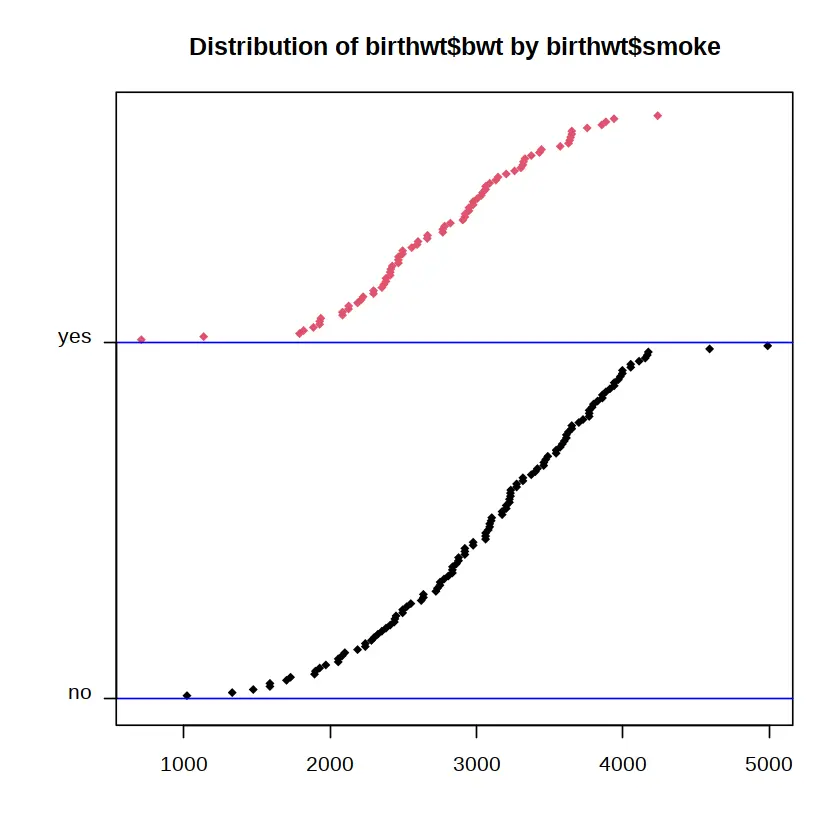
用函數 summ( )輸出的有序點圖探索數值型變量的分佈尤其是數據的密集趨勢和異常值非常方便。
psych 包裏的函數 describeBy( )也可以分組計算與函數 describe( )相同的統計量,例如:
describeBy(cont.vars, birthwt$smoke)函數 describeBy( )雖然很方便,但它不能指定任意函數,所以擴展性較差。實際上,在第 3 章介紹的 dplyr 包裏的函數 group_by( )和 summarise( )就能非常靈活地計算分組統計量。例如:
library(dplyr)
birthwt %>%
group_by(smoke) %>%
summarise(Mean.bwt = mean(bwt), Sd.bwt = sd(bwt))數據分析者可以選擇自己最習慣的方式計算和展示描述性統計量。最後一種方式的思路最清晰,結果最簡潔。