

文章和代碼已經歸檔至【Github倉庫:https://github.com/timerring/dive-into-AI 】或者公眾號【AIShareLab】回覆 R語言 也可獲取。
有時數據集來自多個地方,我們需要將兩個或多個數據集合併成一個數據集。合併數據框的操作包括縱向合併、橫向合併和按照某個共有變量合併。
1.縱向合併:rbind( )
要縱向合併兩個數據框,可以使用 rbind( )函數。被合併的兩個數據框必須擁有相同的變量,這種合併通常用於向數據框中添加觀測。例如:
data1 <- data.frame(id = 1:5,
sex = c("female", "male", "male", "female", "male"),
age = c(32, 46, 25, 42, 29))
data1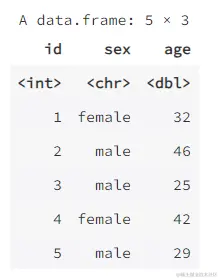
data2 <- data.frame(id = 6:10,
sex = c("male", "female", "male", "male", "female"),
age = c(52, 36, 28, 34, 26))
data2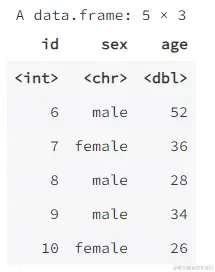
rbind(data1, data2)2. 橫向合併:cbind ( )
要橫向合併兩個數據框,可以使用 cbind( ) 函數。用於合併的兩個數據框必須擁有相同的行數,而且要以相同的順序排列。這種合併通常用於向數據框中添加變量。例如:
data3 <- data.frame(days = c(28, 57, 15, 7, 19),
outcome = c("discharge", "dead", "discharge", "transfer", "discharge"))
data3
cbind(data1, data3)3. 按照某個共有變量合併:merge( )
有時我們有多個相關的數據集,這些數據集有一個或多個共有變量,我們想把它們按照共有變量合併成一個大的數據集。函數 merge( ) 可以實現這個功能,例如:
data4 <- data.frame(id = c(2, 1, 3, 5, 4),
outcome = c("discharge", "dead", "discharge", "transfer", "discharge"))
data4
mydata <- merge(data1, data4, by = "id")
mydata
full\_join( )
dplyr 包中的 full\_join( ) 函數也能實現上述功能上面的命令等價於:
options(warn=-1) # 清爽顯示
library(dplyr)
mydata <- full_join(data1, data4, by = "id")
mydatadplyr 包提供了多種用於合併數據框的函數,例如 bind\_rows( )、bind\_cols( )、left\_join( )、right\_join( ) 等,你可以查看這些函數的幫助文檔瞭解它們的用法。
4. 數據框的長寬格式的轉換
基本包裏的函數 reshape( ) 可以對數據進行長寬格式之間的轉換。
下面以 datasets 包裏的數據集 Indometh 為例進行説明。該數據集是關於藥物吲哚美辛(indometacin)的藥物代謝動力學數據,一共有 6 名試驗對象,每名試驗對象在連續的 8 小時內定時測定了血液中的藥物濃度,共有 11 次的測定值。該資料是長格式,下面將其轉換為寬格式。
data(Indometh)
head(Indometh,12) # 這裏增加一行,預覽數據前 12 行,方便對比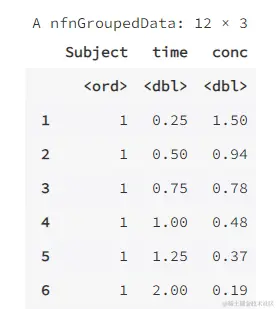
wide <- reshape(Indometh, v.names = "conc", idvar = "Subject", timevar = "time", direction = "wide")
wideIndometh:這是一個數據框或數據集,表示要進行重塑操作的原始數據。v.names:這是一個字符串,表示要重塑的值變量的名稱。在這種情況下,"conc"表示原始數據中的濃度變量。idvar:這是一個字符串或向量,表示標識變量的名稱或變量列表。在這種情況下,"Subject"表示原始數據中的主體標識變量。timevar:這是一個字符串,表示時間變量的名稱。在這種情況下,"time"表示原始數據中的時間變量。direction:這是一個字符串,表示重塑的方向。在這種情況下,"wide"表示要將數據從長格式重塑為寬格式。
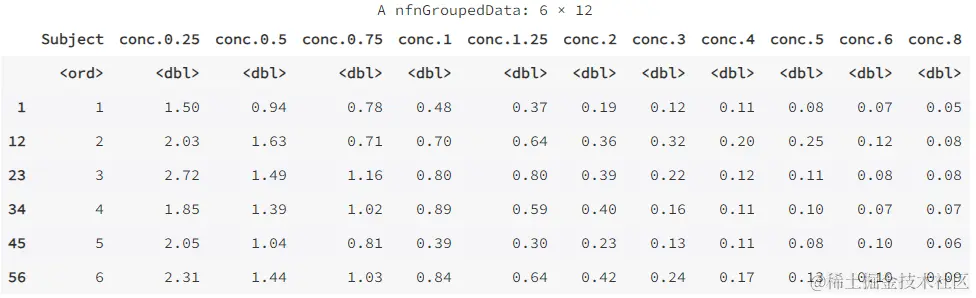
我們還可以將寬格式數據 wide 重新轉換為長格式:
long <- reshape(wide, idvar = "Subject", varying = list(2:12),
v.names = "conc", direction = "long")
head(long, 12)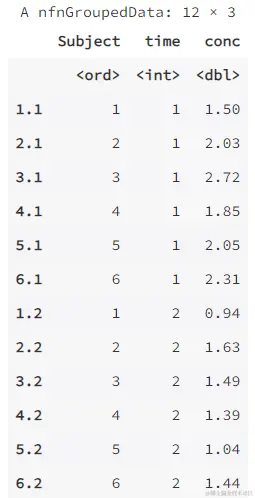
函數 reshape( ) 功能強大,但裏面的參數很多,使用起來略顯不便。
tidyr 包以一種比較簡潔統一的格式實現數據長寬格式的轉換,其中,函數 pivot_wider( ) 用於把長格式數據轉換為寬格式,而函數 pivot_longer( ) 用於把寬格式數據轉換為長格式。上面的結果也可以用下述命令得到:
library(tidyr)
wide <- pivot_wider(as.data.frame(Indometh),
names_from = time,
values_from = conc)
wide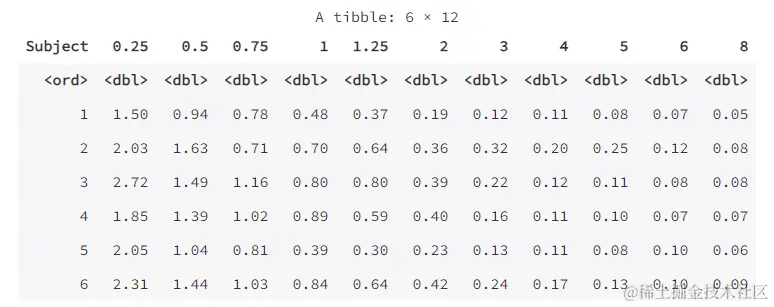
注意在上面的函數 pivot\_wider( ) 中,我們用函數 as.data.frame( ) 將數據 Indometh 轉換成了數據框,這是因為其默認類型不是數據框。數據框 wide 也能重新轉換為長格式:
long <- pivot_longer(wide, -Subject,
names_to = "time", values_to = "conc")
long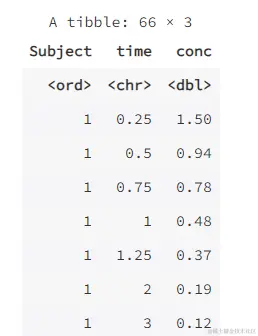
一個“整潔”的數據集(tidy data)應該滿足:每一行代表一個觀測,每一列代表一個變量。在對醫學數據進行分析之前,通常情況下應先把數據集轉換為長格式,因為 R 中的大多數函數都支持這種格式的數據。
tidyr 包中的 gather() 和 spread() 同樣可以用於長型、寬型數據類型轉換,詳見 Cookbook for R。