
4磁盤和文件系統
在第3章中概述了內核提供的一些頂級磁盤設備。本章將詳細討論如何在Linux系統中使用磁盤。你將學習如何對磁盤進行分區、創建和維護磁盤分區中的文件系統,以及如何使用交換空間。
磁盤設備的名稱如/dev/sda,即第一個SCSI子系統磁盤。這種塊設備代表整個磁盤,但磁盤內部有許多不同的組件和層。
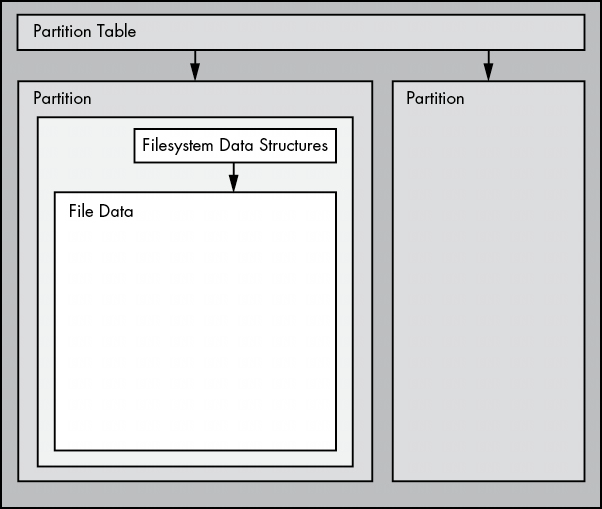
圖4-1展示了簡單 Linux 磁盤的示意圖(注意,該圖未按比例繪製)。通過本章的學習,你將瞭解每個部件的位置。
分區是整個磁盤的細分。在Linux中,它們在整個塊設備後面用數字表示,因此它們的名稱是/dev/sda1和/dev/sdb3。內核會將每個分區顯示為一個塊設備,就像顯示整個磁盤一樣。分區定義在磁盤的一小塊區域上,稱為分區表(也稱為磁盤標籤)。
在大型磁盤系統中,多個數據分區曾經很常見,因為老式PC只能從磁盤的某些部分啓動。此外,管理員還使用分區為操作系統區域保留一定的空間;例如,他們不希望用户將整個系統佔滿,導致關鍵服務無法運行。這種做法並非Unix獨有,你仍然會發現許多新的Windows系統在單個磁盤上設置了多個分區。此外,大多數系統都有單獨的交換分區。
內核允許你同時訪問整個磁盤和其中的一個分區,但除非你要複製整個磁盤,否則通常不會這樣做。
Linux邏輯卷管理器(LVM Logical Volume Manager)為傳統的磁盤設備和分區增加了更多靈活性,目前已在許多系統中使用。我們將在第4.4節介紹LVM。
分區的下一層是文件系統,也就是用户空間中常用的文件和目錄數據庫。我們將在第4.2節探討文件系統。
如圖4-1所示,如果要訪問文件中的數據,需要使用分區表中相應的分區位置,然後在該分區的文件系統數據庫中搜索所需的文件數據。
要訪問磁盤上的數據,Linux內核使用圖4-2所示的分層系統。SCSI子系統和第3.6節中描述的所有其他系統都用一個方框表示。請注意,你可以通過文件系統或直接通過磁盤設備來處理磁盤。本章將介紹這兩種方法的工作原理。為了簡化操作,圖4-2中沒有顯示 LVM,但它在塊設備接口中包含一些組件,在用户空間中包含一些管理組件。
要了解一切是如何組合在一起的,讓我們從最底層的分區開始。
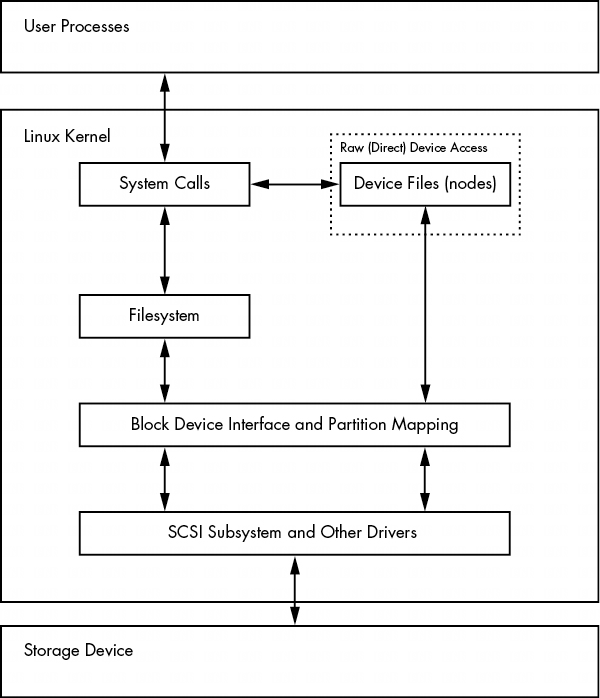
圖 4-2: 用於磁盤訪問的內核示意圖
4.1 對磁盤設備進行分區
分區表有很多種。分區表並沒有什麼特別之處--它只是一堆説明磁盤塊劃分方式的數據。
傳統的分區表可追溯到PC時代,是主引導記錄 (MBR Master Boot Record) 中的分區表,它有很多侷限性。大多數較新的系統使用全局唯一標識符分區表(GPT Globally Unique Identifier Partition Table GUID 分區表)。
下面介紹幾種Linux分區工具:
- parted("分區編輯器") 一種基於文本的工具,同時支持MBR和GPT。
- gparted parted 的圖形版本。
- fdisk 傳統的基於文本的Linux磁盤分區工具。最新版本的fdisk支持MBR、GPT和許多其他類型的分區表,但舊版本僅限於支持MBR。
由於fdisk已經支持MBR和GPT有一段時間了,而且運行單一命令即可輕鬆獲取分區標籤,因此我們將使用parted來顯示分區表。不過,在創建和更改分區表時,我們將使用fdisk。這將説明這兩種界面,以及為什麼許多人更喜歡fdisk界面,因為它具有交互性,而且在你查看之前,它不會對磁盤進行任何更改(我們稍後將討論這一點)。
注意:分區操作和文件系統操作之間有一個重要區別:分區表定義了磁盤上的簡單邊界,而文件系統是一個涉及面更廣的數據系統。因此,我們將使用不同的工具來分區和創建文件系統(參見第 4.2.2 節)。
4.1.1 查看分區表
可以使用parted -l查看系統的分區表。此示例輸出顯示了兩個磁盤設備的兩種不同分區表:
# parted -l
Model: ATA KINGSTON SM2280S (scsi)
1 Disk /dev/sda: 240GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 223GB 223GB primary ext4 boot
2 223GB 240GB 17.0GB extended
5 223GB 240GB 17.0GB logical linux-swap(v1)
Model: Generic Flash Disk (scsi)
2 Disk /dev/sdf: 4284MB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 1049kB 1050MB 1049MB myfirst
2 1050MB 4284MB 3235MB mysecond
第一個設備(/dev/sda)使用傳統的MBR分區表(parted將其稱為msdos),第二個設備(/dev/sdf)包含 GPT。請注意,這兩種表類型存儲了不同的參數集。特別是MBR表沒有 Namecolumn,因為在該方案下不存在名稱。(我在 GPT 中隨意選擇了 myfirst 和 mysecond 這兩個名稱)。
注意:讀取分區表時要注意單位大小。parted的輸出會根據parted認為最容易讀取的單位顯示近似大小。另一方面,fdisk -l顯示的是精確數字,但在大多數情況下,單位是512字節的"扇區",這可能會造成混淆,因為看起來你的磁盤和分區的實際大小是原來的兩倍。仔細查看fdisk分區表視圖也會發現扇區大小信息。
- MBR基礎知識
本例中的MBR表包含主分區、擴展分區和邏輯分區。主分區是對磁盤的正常細分,分區1就是一個例子。基本MBR有四個主分區的限制,因此如果想要超過四個,就必須指定一個作為擴展分區。擴展分區可細分為邏輯分區,操作系統可以像使用其他分區一樣使用這些邏輯分區。在本例中,分區2是包含邏輯分區5的擴展分區。
注意:分區列出的文件系統類型不一定與MBR條目中的系統ID字段相同。MBR系統ID只是一個標識分區類型的數字;例如83是Linux分區,82是Linux交換分區。不過,parted 會自行判斷該分區上的文件系統類型,從而提供更多信息。如果一定要知道MBR的系統ID,請使用 fdisk -l。
- LVM分區簡介
查看分區表時,如果看到標有LVM(Logical Volume Manager)的分區(分區類型代碼為8e)、名為/dev/dm-*的設備或"設備映射器"的引用,則説明系統使用了LVM。我們將從傳統的直接磁盤分區開始討論,它與使用LVM的系統上的分區略有不同。
為了讓大家心中有數,讓我們快速瀏覽一下使用LVM的系統(在VirtualBox上使用LVM新安裝的Ubuntu)的 parted -l 輸出示例。首先是實際分區表的描述,除了lvm 標誌外,它看起來與你想象的基本一致:
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sda: 10.7GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 10.7GB 10.7GB primary boot, lvm
還有一些設備看起來應該是分區,但卻被稱為磁盤:
Model: Linux device-mapper (linear) (dm)
Disk /dev/mapper/ubuntu--vg-swap_1: 1023MB
Sector size (logical/physical): 512B/512B
Partition Table: loop
Disk Flags:
Number Start End Size File system Flags
1 0.00B 1023MB 1023MB linux-swap(v1)
Model: Linux device-mapper (linear) (dm)
Disk /dev/mapper/ubuntu--vg-root: 9672MB
Sector size (logical/physical): 512B/512B
Partition Table: loop
Disk Flags:
Number Start End Size File system Flags
1 0.00B 9672MB 9672MB ext4
簡單的理解方式是,分區已經以某種方式從分區表中分離出來。你將在第 4.4 節看到實際情況。
注意使用fdisk -l,你將獲得更少的詳細輸出;在前一種情況下,除了一個LVM標籤的物理分區外,你將看不到其他任何東西。
初始內核讀取:初始讀取MBR表時,Linux內核會產生如下調試輸出(記住,可以用journalctl -k查看):
sda: sda1 sda2 < sda5 >
輸出中的 sda2 < sda5 > 部分表明 /dev/sda2 是一個擴展分區,包含一個邏輯分區 /dev/sda5。你通常會忽略擴展分區本身,因為你通常只關心訪問它所包含的邏輯分區。
4.1.2 修改分區表
查看分區表是一項相對簡單且無害的操作。更改分區表也相對簡單,但對磁盤進行此類更改存在風險。請牢記以下幾點:
- 更改分區表會導致很難恢復被刪除或重新定義的分區上的任何數據,因為這樣做會刪除這些分區上文件系統的位置。如果要分區的磁盤包含關鍵數據,請確保有備份。
- 確保目標磁盤上沒有當前正在使用的分區。這是一個值得關注的問題,因為大多數 Linux 發行版都會自動掛載任何檢測到的文件系統。(有關加載和卸載的更多信息,請參見第 4.2.3 節)。
準備就緒後,選擇分區程序。如果你想使用 parted,可以使用命令行 parted 實用程序或圖形界面,如 gparted;fdisk 在命令行下相當容易操作。這些實用程序都有在線幫助,很容易上手。(如果沒有備用磁盤,可以嘗試在閃存設備或類似設備上使用它們)。
不過,fdisk 和 parted 的工作方式有很大不同。使用 fdisk,你可以在對磁盤進行實際更改之前設計新的分區表,而且只有在你退出程序時才會進行更改。但使用 parted 時,分區會在你發出命令時創建、修改和刪除。在更改之前,你沒有機會查看分區表。
這些差異也是理解這兩個工具如何與內核交互的關鍵。fdisk 和 parted 都完全在用户空間修改分區;不需要內核支持重寫分區表,因為用户空間可以讀取和修改所有塊設備。
但在某些時候,內核必須讀取分區表,以便將分區顯示為塊設備,從而可以使用它們。fdisk 實用程序使用一種相對簡單的方法。在修改分區表後,fdisk 會發出一個系統調用,告訴內核應該重新讀取磁盤的分區表(你很快就會看到如何與 fdisk 交互的示例)。然後內核會生成調試輸出,你可以用 journalctl -k 查看。例如,如果在 /dev/sdf 上創建了兩個分區,就會看到下面的內容:
sdf: sdf1 sdf2
分區工具不使用這種全磁盤系統調用,而是在改變單個分區時向內核發出信號。處理單個分區更改後,內核不會產生前面的調試輸出。
有幾種方法可以查看分區變化:
- 使用 udevadm 查看內核事件變化。例如,命令 udevadm monitor --kernel 將顯示舊分區設備的刪除和新分區設備的添加。
- 檢查 /proc/partitions,獲取完整的分區信息。
- 檢查 /sys/block/device/,查看分區系統接口是否被更改;檢查 /dev,查看分區設備是否被更改。
如果絕對必須確認對分區表的修改,可以使用 blockdev 命令來執行 fdisk 發出的舊式系統調用。例如,要強制內核重新加載 /dev/sdf 上的分區表,請執行以下命令:
# blockdev --rereadpt /dev/sdf
4.1.3 創建分區表
讓我們在新的空磁盤上創建一個新的分區表,將剛才學到的知識運用到實際操作中。本示例顯示以下情況:
4GB 磁盤(未使用的小型 USB 閃存設備;如果您想效仿本示例,請使用手頭任何大小的設備), MBR類型的分區表。打算用 ext4填充的兩個分區:200MB 和 3.8GB。磁盤設備位於/dev/sdd;你需要用 lsblk 查找自己的設備位置。
你將使用 fdisk 來完成這項工作。請注意,這是一個交互式命令,因此在確保磁盤上沒有任何東西被掛載後,你將在命令提示符下輸入設備名稱:
# fdisk /dev/sdd
Command (m for help):
Command (m for help): p
Disk /dev/sdd: 4 GiB, 4284481536 bytes, 8368128 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x88f290cc
Device Boot Start End Sectors Size Id Type
/dev/sdd1 2048 8368127 8366080 4G c W95 FAT32 (LBA)
大多數設備已經包含一個FAT類型的分區,如/dev/sdd1中的這個分區。因為你想為Linux創建新的分區(當然,你肯定不需要這裏的任何東西),你可以像這樣刪除現有的分區:
Command (m for help): d
Selected partition 1
Partition 1 has been deleted.
在你明確寫入分區表之前,fdisk 不會進行更改,因此你還沒有修改磁盤。如果你犯了無法挽回的錯誤,使用 q 命令退出 fdisk,而不寫入更改。現在使用 n 命令創建第一個 200MB 分區:
Command (m for help): n
Partition type
p primary (0 primary, 0 extended, 4 free)
e extended (container for logical partitions)
Select (default p): p
Partition number (1-4, default 1): 1
First sector (2048-8368127, default 2048): 2048
Last sector, +sectors or +size{K,M,G,T,P} (2048-8368127, default 8368127): +200M
Created a new partition 1 of type 'Linux' and of size 200 MiB.
在這裏,fdisk 會提示你選擇 MBR 分區樣式、分區編號、分區起始和結束(或大小)。默認值通常就是你想要的。這裏唯一改變的是分區結束/大小,使用 + 語法指定大小和單位。
創建第二個分區的方法與此相同,但您將使用所有默認值,因此我們不再贅述。完成分區佈局後,使用 p(打印)命令查看:
Command (m for help): p
[--snip--]
Device Boot Start End Sectors Size Id Type
/dev/sdd1 2048 411647 409600 200M 83 Linux
/dev/sdd2 411648 8368127 7956480 3.8G 83 Linux
Command (m for help): w
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.
如果你對其他診斷信息感興趣,可以使用 journalctl -k 查看前面提到的內核讀取信息,但要記住,只有使用 fdisk 時才能看到這些信息。
至此,你已經掌握了開始分區磁盤的所有基礎知識,但如果你想了解有關磁盤的更多細節,請繼續閲讀。否則,請跳至第 4.2 節,瞭解如何在磁盤上安裝文件系統。
4.1.4 磁盤和分區幾何導航
任何帶有移動部件的設備都會給軟件系統帶來複雜性,因為有些物理元素是無法抽象的。硬盤也不例外;儘管可以將硬盤視為可隨機訪問任意塊的塊設備,但如果系統不注意如何在磁盤上佈局數據,就會對性能造成嚴重影響。
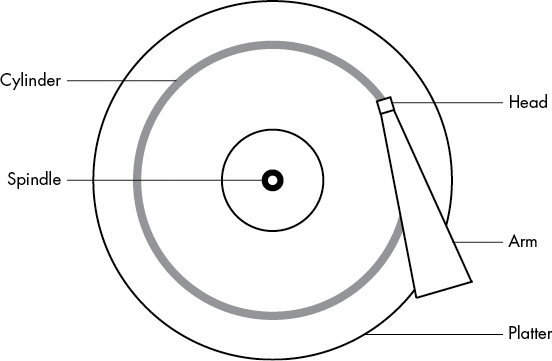
磁盤由主軸上的旋轉盤片和連接到移動臂上的磁頭組成,移動臂可橫掃磁盤的半徑。磁盤在磁頭下方旋轉時,磁頭讀取數據。當臂處於一個位置時,磁頭只能從一個固定的圓讀取數據。這個圓被稱為圓柱體,因為較大的磁盤有多個盤片,所有盤片都堆疊在一起,圍繞同一主軸旋轉。每個盤片可以有一個或兩個磁頭,分別位於盤片的頂部和/或底部,所有磁頭都連接在同一個臂上,並協同移動。由於磁臂會移動,因此磁盤上會有許多圓柱體,從圍繞中心的小圓柱體到圍繞磁盤外圍的大圓柱體。最後,還可以將圓柱體劃分為稱為扇區的片段。這種考慮磁盤幾何形狀的方法稱為 CHS,即圓柱體-磁頭-扇區;在較早的系統中,只要使用這三個參數尋址,就能找到磁盤的任何部分。
注意:磁道是單個磁頭訪問的圓柱體部分,因此在圖4-3中,圓柱體也是一個磁道。你不需要擔心磁道。
內核和各種分區程序可以告訴你磁盤報告的磁道數。不過,在任何半路出家的新硬盤上,報告的數值都是虛構的!使用 CHS 的傳統尋址方案無法與現代磁盤硬件相匹配,也無法解釋外層磁盤比內層磁盤能容納更多數據的事實。磁盤硬件支持邏輯塊尋址 (LBA),通過塊編號來尋址磁盤上的位置(這是一個更直接的接口),但 CHS 的殘餘仍然存在。例如,MBR 分區表包含 CHS 信息和 LBA 等價物,一些引導加載程序仍然愚蠢地相信 CHS 值(別擔心,大多數 Linux 引導加載程序使用 LBA 值)。
注意:扇區一詞容易引起混淆,因為 Linux 分區程序可能用它表示不同的值。
柱面的概念曾經對分區至關重要,因為柱面是分區的理想邊界。從圓柱體讀取數據流的速度非常快,因為磁頭可以在磁盤旋轉時不斷拾取數據。由一組相鄰的磁盤分區組成的分區也可以實現快速的連續數據訪問,因為磁頭不需要在磁盤分區之間移動太遠。
雖然磁盤的外觀與以往大致相同,但精確分區對齊的概念已經過時。一些舊的分區程序會抱怨,如果你不把分區精確地放在磁盤分區邊界上。請忽略這一點;你能做的不多,因為現代磁盤報告的 CHS 值並不真實。磁盤的 LBA 方案以及較新的分區實用程序中更好的邏輯可確保分區以合理的方式佈局。
4.1.5 從固態磁盤讀取數據
固態磁盤(SSD)等無移動部件的存儲設備在訪問特性方面與旋轉磁盤截然不同。
對它們來説,隨機存取不是問題,因為沒有磁頭在盤片上掃描,但某些特性會改變固態硬盤的性能。
影響固態硬盤性能的最重要因素之一是分區對齊。從固態硬盤讀取數據時,數據是以塊(稱為頁,不要與虛擬內存頁混淆)為單位讀取的,例如每次讀取 4,096 或 8,192 字節,而且讀取必須以該大小的倍數開始。這意味着,如果你的分區及其數據不在一個邊界上,你可能需要進行兩次讀取,而不是進行一次小的普通操作,比如讀取一個目錄的內容。較新版本的分區工具包含將新創建分區置於磁盤開頭適當偏移位置的邏輯,因此你可能不需要擔心分區對齊不當的問題。目前的分區工具不做任何計算,而只是將分區對齊到 1MB 邊界上,或者更準確地説,對齊到 2,048 個 512 字節的塊上。這是一種相當保守的方法,因為邊界對齊的頁面大小為 4,096、8,192 等,一直到 1,048,576。
不過,如果你好奇或想確保你的分區從邊界開始,你可以很容易地在 /sys/block 目錄中找到這些信息。下面是分區 /dev/sdf2 的示例:
$ cat /sys/block/sdf/sdf2/start
1953126
這裏的輸出是分區從設備起點開始的偏移量,單位為 512 字節(Linux 系統又把它稱為扇區,令人困惑)。如果該固態硬盤使用 4,096 字節的頁面,那麼一個頁面中有 8 個這樣的扇區。你所要做的就是看看能否將分區偏移量平均除以 8。在這種情況下,你做不到,所以分區無法達到最佳性能。
4.2 文件系統
內核與磁盤的用户空間之間的最後一環通常是文件系統;這就是你在運行 ls 和 cd 等命令時習慣與之交互的系統。如前所述,文件系統是一種數據庫形式;它提供了一種結構,將簡單的塊設備轉變為用户可以理解的複雜的文件和子目錄層次結構。
曾幾何時,所有文件系統都存在於專門用於數據存儲的磁盤和其他物理介質中。不過,文件系統的樹狀目錄結構和 I/O 接口非常靈活,因此文件系統現在可以執行多種任務,例如你在 /sys 和 /proc 中看到的系統接口。文件系統傳統上是在內核中實現的,但 Plan 9 的 9P 創新(https://en.wikipedia.org/wiki/9P_(protocol))激發了用户空間文件系統的發展。用户空間文件系統(FUSE)功能允許在 Linux 中使用用户空間文件系統。
虛擬文件系統(VFS)抽象層完善了文件系統的實現。正如 SCSI 子系統將不同設備類型和內核控制命令之間的通信標準化一樣,VFS 確保所有文件系統實現都支持標準接口,以便用户空間應用程序以相同的方式訪問文件和目錄。對 VFS 的支持使 Linux 能夠支持大量的文件系統。
4.2.1 文件系統類型
Linux 文件系統支持包括為 Linux 優化的本地設計、外來類型(如 Windows FAT 系列)、通用文件系統(如 ISO 9660)以及許多其他類型。下面列出了最常見的數據存儲文件系統類型。Linux 識別的類型名稱在文件系統名稱旁邊的括號中。
第四擴展文件系統(ext4)是 Linux 原生文件系統的最新版本。第二擴展文件系統(ext2)是 Linux 系統長期以來的默認設置,其靈感來源於傳統的 Unix 文件系統,如 Unix 文件系統(UFS)和快速文件系統(FFS)。第三擴展文件系統(ext3)增加了日誌功能(正常文件系統數據結構之外的小型緩存),以增強數據完整性並加快啓動速度。ext4 文件系統是一種漸進式改進,支持比 ext2 或 ext3 更大的文件以及更多的子目錄。
擴展文件系統系列具有一定的向後兼容性。例如,你可以將 ext2 和 ext3 文件系統相互掛載,也可以將 ext2 和 ext3 文件系統掛載為 ext4,但不能將 ext4 掛載為 ext2 或 ext3。
Btrfs或B樹文件系統(btrfs)是Linux原生的一種較新的文件系統,其擴展能力超過了ext4。
FAT文件系統(msdos、vfat、exfat)與微軟系統有關。
簡單的msdos 類型支持 MS-DOS 系統中非常原始的單例。大多數可移動閃存介質(如 SD 卡和 USB 驅動器)默認包含 vfat(最大 4GB)或 exfat(4GB 及以上)分區。Windows 系統可以使用基於 FAT 的文件系統或更先進的 NT 文件系統(ntfs)。
XFS 是一種高性能文件系統,某些發行版(如 Red Hat Enterprise Linux 7.0 及更高版本)默認使用 XFS。
HFS+ (hfsplus) 是大多數 Macintosh 系統使用的蘋果標準。
ISO 9660 (iso9660) 是一種光盤標準。大多數光盤都使用某種不同的 ISO 9660 標準。
長期以來,擴展文件系統系列完全可以為大多數用户所接受,而且它一直是事實上的標準,這不僅證明了它的實用性,也證明了它的適應性。Linux 開發社區傾向於完全替換不能滿足當前需求的組件,但每次 Extended 文件系統出現問題時,都會有人對其進行升級。儘管如此,文件系統技術還是取得了許多進步,而由於向後兼容性的要求,即使是 ext4 也無法利用這些進步。這些進步主要體現在與大量文件、大文件和類似情況有關的可擴展性增強方面。
在撰寫本文時,Btrfs 已成為一個主要 Linux 發行版的默認設置。如果這證明是成功的,那麼 Btrfs 很可能會取代 Extended 系列。
4.2.2 創建文件系統
如果你正在準備一個新的存儲設備,一旦完成了第 4.1 節所述的分區過程,就可以創建文件系統了。與分區一樣,創建文件系統也要在用户空間進行,因為用户空間進程可以直接訪問和操作塊設備。
mkfs實用程序可以創建多種文件系統。例如,你可以用這條命令在/dev/sdf2上創建一個ext4 分區:
# mkfs -t ext4 /dev/sdf2
mkfs 程序會自動確定設備中的塊數,並設置一些合理的默認值。除非你真的知道自己在做什麼,並想詳細閲讀文檔,否則不要更改它們。
創建文件系統時,mkfs 會在運行過程中打印診斷輸出,包括與超級塊相關的輸出。超級塊是文件系統數據庫頂層的關鍵組件,它非常重要,因此 mkfs 會創建大量備份,以防原始數據被破壞。考慮在運行 mkfs 時記錄一些超級塊的備份編號,以防磁盤發生故障時需要恢復超級塊(參見第 4.2.11 節)。
創建文件系統只能在添加新磁盤或重新分區舊磁盤後進行。對於每個沒有預先存在的數據(或有要刪除的數據)的新分區,只需創建一次文件系統。在現有文件系統上創建新文件系統會有效地破壞舊數據。
原來,mkfs 只是一系列文件系統創建程序 mkfs.fs 的前端,其中 fs 是一種文件系統類型。因此,當你運行 mkfs -t ext4 時,mkfs 會反過來運行 mkfs.ext4。
還有更多的間接操作。檢查命令後面的 mkfs.* 文件,你會看到下面的內容:
$ ls -l /sbin/mkfs.*
-rwxr-xr-x 1 root root 18592 Apr 9 23:32 /sbin/mkfs.bfs
-rwxr-xr-x 1 root root 482248 Feb 25 2022 /sbin/mkfs.btrfs
-rwxr-xr-x 1 root root 26728 Apr 9 23:32 /sbin/mkfs.cramfs
lrwxrwxrwx 1 root root 6 Jun 2 2022 /sbin/mkfs.ext2 -> mke2fs
lrwxrwxrwx 1 root root 6 Jun 2 2022 /sbin/mkfs.ext3 -> mke2fs
lrwxrwxrwx 1 root root 6 Jun 2 2022 /sbin/mkfs.ext4 -> mke2fs
-rwxr-xr-x 1 root root 47704 Mar 23 2022 /sbin/mkfs.fat
-rwxr-xr-x 1 root root 39088 Apr 9 23:32 /sbin/mkfs.minix
lrwxrwxrwx 1 root root 8 Mar 23 2022 /sbin/mkfs.msdos -> mkfs.fat
lrwxrwxrwx 1 root root 6 Nov 1 2022 /sbin/mkfs.ntfs -> mkntfs
lrwxrwxrwx 1 root root 8 Mar 23 2022 /sbin/mkfs.vfat -> mkfs.fat
-rwxr-xr-x 1 root root 371016 Feb 9 2022 /sbin/mkfs.xfs
正如你所見,mkfs.ext4 只是 mke2fs 的一個符號鏈接。如果你遇到的系統沒有特定的 mkfs 命令,或者在查找特定文件系統的文檔時,記住這一點很重要。每個文件系統的創建工具都有自己的手冊頁面,比如 mke2fs(8)。這在大多數系統上都不成問題,因為訪問 mkfs.ext4(8) 手冊頁面會跳轉到 mke2fs(8) 手冊頁面,但請記住這一點。
4.2.3 掛載文件系統
在Unix中,將文件系統附加到運行系統的過程稱為掛載。系統啓動時,內核會讀取一些配置數據,並根據配置數據掛載 root (/)。
要掛載文件系統,必須瞭解以下信息:
- 文件系統的設備、位置或標識符(如磁盤分區--實際文件系統數據所在位置)。一些特殊用途的文件系統,如 proc 和 sysfs,沒有位置。
- 文件系統類型。
- 掛載點--文件系統在當前系統目錄層次結構中的位置。掛載點總是一個普通目錄。例如,你可以使用 /music 作為包含音樂的文件系統的掛載點。掛載點不一定在 / 的正下方,可以在系統的任何位置。
掛載文件系統的常用術語是 “在掛載點上掛載設備”。要了解系統當前的文件系統狀態,可以運行 mount。輸出結果(可能很長)應該是這樣的:
$ mount
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
udev on /dev type devtmpfs (rw,nosuid,relatime,size=131517904k,nr_inodes=32879476,mode=755,inode64)
devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=000)
tmpfs on /run type tmpfs (rw,nosuid,nodev,noexec,relatime,size=26318024k,mode=755,inode64)
efivarfs on /sys/firmware/efi/efivars type efivarfs (rw,nosuid,nodev,noexec,relatime)
/dev/mapper/ubuntu--vg-ubuntu--lv on / type ext4 (rw,relatime,stripe=16)
securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime)
tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev,inode64)
tmpfs on /run/lock type tmpfs (rw,nosuid,nodev,noexec,relatime,size=5120k,inode64)
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot)
pstore on /sys/fs/pstore type pstore (rw,nosuid,nodev,noexec,relatime)
bpf on /sys/fs/bpf type bpf (rw,nosuid,nodev,noexec,relatime,mode=700)
systemd-1 on /proc/sys/fs/binfmt_misc type autofs (rw,relatime,fd=29,pgrp=1,timeout=0,minproto=5,maxproto=5,direct,pipe_ino=111116)
hugetlbfs on /dev/hugepages type hugetlbfs (rw,relatime,pagesize=2M)
mqueue on /dev/mqueue type mqueue (rw,nosuid,nodev,noexec,relatime)
debugfs on /sys/kernel/debug type debugfs (rw,nosuid,nodev,noexec,relatime)
tracefs on /sys/kernel/tracing type tracefs (rw,nosuid,nodev,noexec,relatime)
fusectl on /sys/fs/fuse/connections type fusectl (rw,nosuid,nodev,noexec,relatime)
configfs on /sys/kernel/config type configfs (rw,nosuid,nodev,noexec,relatime)
none on /run/credentials/systemd-sysusers.service type ramfs (ro,nosuid,nodev,noexec,relatime,mode=700)
tmpfs on /run/qemu type tmpfs (rw,nosuid,nodev,relatime,mode=755,inode64)
/var/lib/snapd/snaps/core20_2267.snap on /snap/core20/2267 type squashfs (ro,nodev,relatime,errors=continue,x-gdu.hide)
/var/lib/snapd/snaps/core20_2321.snap on /snap/core20/2321 type squashfs (ro,nodev,relatime,errors=continue,x-gdu.hide)
/var/lib/snapd/snaps/lxd_27950.snap on /snap/lxd/27950 type squashfs (ro,nodev,relatime,errors=continue,x-gdu.hide)
/var/lib/snapd/snaps/lxd_28384.snap on /snap/lxd/28384 type squashfs (ro,nodev,relatime,errors=continue,x-gdu.hide)
/var/lib/snapd/snaps/snapd_21467.snap on /snap/snapd/21467 type squashfs (ro,nodev,relatime,errors=continue,x-gdu.hide)
/dev/sda2 on /boot type ext4 (rw,relatime,stripe=16)
/dev/sda1 on /boot/efi type vfat (rw,relatime,fmask=0022,dmask=0022,codepage=437,iocharset=iso8859-1,shortname=mixed,errors=remount-ro)
binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_misc (rw,nosuid,nodev,noexec,relatime)
tmpfs on /run/snapd/ns type tmpfs (rw,nosuid,nodev,noexec,relatime,size=26318024k,mode=755,inode64)
nsfs on /run/snapd/ns/lxd.mnt type nsfs (rw)
tmpfs on /run/user/0 type tmpfs (rw,nosuid,nodev,relatime,size=26318020k,nr_inodes=6579505,mode=700,inode64)
/var/lib/snapd/snaps/snapd_21761.snap on /snap/snapd/21761 type squashfs (ro,nodev,relatime,errors=continue,x-gdu.hide)
tracefs on /sys/kernel/debug/tracing type tracefs (rw,nosuid,nodev,noexec,relatime)
/var/lib/snapd/snaps/core_17201.snap on /snap/core/17201 type squashfs (ro,nodev,relatime,errors=continue,x-gdu.hide)
/var/lib/snapd/snaps/unixbench_27.snap on /snap/unixbench/27 type squashfs (ro,nodev,relatime,errors=continue,x-gdu.hide)
每一行對應一個當前已掛載的文件系統,項目按以下順序排列:
- 設備,如 /dev/sda3。請注意,其中有些並不是真正的設備(例如 proc),而是真正設備名稱的替身,因為這些特殊用途的文件系統不需要設備。
- on
- 掛載點。
- type
- 文件系統類型,通常是一個簡短的標識符。
- 掛載選項(括號內)。詳情請參閲第 4.2.6 節。
要手動掛載文件系統,請使用如下掛載命令,並輸入文件系統類型、設備和所需的掛載點:
# mount -t type device mountpoint
例如,要掛載在 /home/extra 上設備 /dev/sdf2 上的第四擴展文件系統,請使用此命令:
# mount -t ext4 /dev/sdf2 /home/extra
通常情況下,你不需要提供 -t 類型選項,因為 mount 通常會為你計算出來。不過,有時有必要區分兩種相似的類型,例如各種 FAT 類型的文件系統。
要卸載(分離)文件系統,請使用如下 umount 命令:
# umount mountpoint
也可以使用文件系統的設備而不是掛載點卸載文件系統。
幾乎所有 Linux 系統都包含一個臨時掛載點 /mnt,通常用於測試。在試驗系統時可以隨意使用它,但如果你打算長期掛載文件系統,請尋找或製作另一個掛載點。
4.2.4 文件系統UUID
上一節討論的掛載文件系統的方法取決於設備名稱。然而,設備名稱可能會改變,因為它們取決於內核查找設備的順序。為了解決這個問題,你可以通過通用唯一標識符(UUID)來識別和掛載文件系統,UUID 是識別計算機系統中對象的唯一 “序列號 ”的行業標準。像 mke2fs 這樣的文件系統創建程序會在初始化文件系統數據結構時生成一個 UUID。
要查看設備列表以及系統中相應的文件系統和 UUID,請使用 blkid(塊 ID)程序:
# blkid
/dev/mapper/ubuntu--vg-ubuntu--lv: UUID="175bf7f1-cbce-408e-9acc-960ae03c2346" BLOCK_SIZE="4096" TYPE="ext4"
/dev/sda2: UUID="31ee66ca-70e9-469c-958c-c78a9c51443b" BLOCK_SIZE="4096" TYPE="ext4" PARTUUID="2dafe15f-abd2-4d2e-80a6-8afa7913253a"
/dev/sda3: UUID="405c0N-VEVy-eIe5-0Rj5-m9dm-FIAU-NBed6S" TYPE="LVM2_member" PARTUUID="a82236e6-bd79-4ae4-bdde-714db1a4d406"
/dev/sda1: UUID="28B0-F691" BLOCK_SIZE="512" TYPE="vfat" PARTUUID="3f328243-1a89-4b61-a0cb-acf6071f5e36"
/dev/loop1: TYPE="squashfs"
/dev/loop6: TYPE="squashfs"
/dev/loop4: TYPE="squashfs"
/dev/loop2: TYPE="squashfs"
/dev/loop0: TYPE="squashfs"
/dev/loop7: TYPE="squashfs"
/dev/loop5: TYPE="squashfs"
/dev/loop3: TYPE="squashfs"
在本例中,blkid 發現了四個帶有數據的分區:兩個帶有 ext4 文件系統,一個帶有交換空間簽名(見第 4.3 節),一個帶有基於 FAT 的文件系統。Linux 本地分區都有標準 UUID,但 FAT 分區沒有。你可以用 FAT 卷序號(本例中為 4859-EFEA)來引用 FAT 分區。
要通過 UUID 掛載文件系統,請使用 UUID 掛載選項。例如,要將前面列表中的第一個文件系統掛載到 /home/extra 上,請輸入
# mount UUID=b600fe63-d2e9-461c-a5cd-d3b373a5e1d2 /home/extra
通常情況下,你不會像這樣通過 UUID 手動掛載文件系統,因為你通常知道設備,而且通過設備名掛載比通過瘋狂的 UUID 要容易得多。不過,瞭解 UUID 還是很重要的。首先,UUID 是啓動時在 /etc/fstab 中自動掛載非 LVM 文件系統的首選方式(參見第 4.2.8 節)。此外,許多發行版會在插入可移動媒體時使用 UUID 作為掛載點。在上例中,FAT 文件系統位於閃存卡上。有人登錄的 Ubuntu 系統會在插入時將該分區掛載到 /media/user/4859-EFEA。第 3 章所述的 udevd 守護進程會處理設備插入的初始事件。
如有必要,你可以更改文件系統的 UUID(例如,如果你從其他地方複製了完整的文件系統,現在需要將其與原始文件系統區分開來)。有關如何在 ext2/ext3/ext4 文件系統上執行此操作,請參閲 tune2fs(8) 手冊。
4.2.5 磁盤緩衝、緩存和文件系統
與其他 Unix 變種一樣,Linux 也會對寫入磁盤的數據進行緩衝。這意味着當進程請求更改時,內核通常不會立即將更改寫入文件系統。相反,它會將這些更改存儲在 RAM 中,直到內核確定將它們實際寫入磁盤的好時機。這種緩衝系統對用户是透明的,並能帶來非常顯著的性能提升。
使用umount卸載文件系統時,內核會自動與磁盤同步,將緩衝區中的更改寫入磁盤。你也可以在任何時候通過運行 sync 命令強制內核這樣做,該命令默認情況下會同步系統中的所有磁盤。如果由於某些原因無法在關閉系統前卸載文件系統,請務必先運行同步。
此外,內核使用 RAM 來緩存從磁盤讀取的數據塊。因此,如果一個或多個進程重複訪問一個文件,內核不必一次又一次地訪問磁盤,只需從緩存中讀取即可,從而節省了時間和資源。
4.2.6 文件系統掛載選項
改變掛載命令行為的方法有很多,在處理可移動媒體或執行系統維護時,你經常需要這樣做。事實上,mount 選項的總數是驚人的。內容豐富的 mount(8) 手冊頁面是一個很好的參考,但很難知道從哪裏開始,哪些可以安全地忽略。本節將介紹最有用的選項。
選項大致分為兩類:常規選項和文件系統特定選項。一般選項通常適用於所有文件系統類型,包括用於指定文件系統類型的 -t,如前所述。相比之下,文件系統專用選項只適用於特定的文件系統類型。
要激活文件系統選項,請使用 -o 開關,後面跟上選項。例如,-o remount,rw 會將已掛載為只讀的文件系統重新掛載為讀寫模式。
常規選項的語法很簡短。最重要的有
-r -r 選項以只讀模式掛載文件系統。這有很多用途,從寫保護到引導。訪問只讀設備(如 CD-ROM)時不需要指定該選項,系統會幫你完成(還會告訴你只讀狀態)。
-n -n 選項確保 mount 不會嘗試更新系統運行時掛載數據庫 /etc/mtab。默認情況下,mount 操作在無法寫入該文件時會失敗,因此該選項在啓動時非常重要,因為根分區(包括系統掛載數據庫)一開始是隻讀的。在單用户模式下嘗試修復系統問題時,你也會發現這個選項很方便,因為系統掛載數據庫當時可能不可用。
-t 類型選項指定文件系統類型。
長選項
對於不斷增加的掛載選項來説,像 -r 這樣的短選項過於有限;字母表中的字母太少,無法容納所有可能的選項。短選項也很麻煩,因為很難根據單個字母確定選項的含義。許多常規選項和所有文件系統特定選項都使用更長、更靈活的選項格式。
要在命令行中使用掛載長選項,以 -o 開頭,後面用逗號分隔相應的關鍵字。下面是一個完整的示例,長選項位於 -o 之後:
# mount -t vfat /dev/sde1 /dos -o ro,uid=1000
這裏的兩個長選項是ro和uid=1000。ro選項指定只讀模式,與-r短選項相同。uid=1000選項告訴內核將文件系統中的所有文件視作所有者為用户 ID 1000。
最有用的長選項是
- exec、noexec 啓用或禁用執行文件系統上的程序。
- suid, nosuid 啓用或禁用 setuid 程序。
- ro 以只讀模式掛載文件系統(與 -r 短選項一樣)。
- rw 以讀寫模式掛載文件系統。
4.2.7 重新掛載文件系統
有時需要更改當前已掛載文件系統的掛載選項;最常見的情況是需要在崩潰恢復期間使只讀文件系統可寫。在這種情況下,你需要在同一掛載點重新掛載文件系統。
以下命令以讀寫模式重新掛載根目錄(需要使用 -n 選項,因為當根目錄為只讀時,掛載命令無法寫入系統掛載數據庫):
# mount -n -o remount /
該命令假定 /etc/fstab 中有正確的 / 設備列表(如下一節所述)。如果沒有,則必須作為附加選項指定設備。
4.2.8 /etc/fstab 文件系統表
為了在啓動時掛載文件系統並省去掛載命令的繁瑣工作,Linux 系統在 /etc/fstab 中保存了文件系統和選項的永久列表。這是一個格式非常簡單的純文本文件,如清單 4-1 所示。
UUID=70ccd6e7-6ae6-44f6-812c-51aab8036d29 / ext4 errors=remount-ro 0 1
UUID=592dcfd1-58da-4769-9ea8-5f412a896980 none swap sw 0 0
/dev/sr0 /cdrom iso9660 ro,user,nosuid,noauto 0 0
每行對應一個文件系統,分為六個字段。這些字段從左到右依次為
- 設備或UUID:當前大多數Linux系統不再使用/etc/fstab中的設備,而是使用UUID。
- 掛載點: 表示文件系統的掛載位置。
- 文件系統類型 列表中可能找不到 swap;這是一個 swap 分區(見第 4.3 節)。
- 選項: 用逗號分隔的長選項。
- 供dump命令使用的備份信息: dump命令是一種早已過時的備份實用程序;該字段已不再適用。應始終將其設置為 0。
- 文件系統完整性測試順序:為確保 fsck 始終先在根文件系統上運行,應始終將其設置為:根文件系統為 1,硬盤或固態硬盤上任何其他本地連接的文件系統為 2。使用 0 可禁用所有其他文件系統的啓動檢查,包括只讀設備、交換和 /proc 文件系統(請參閲第 4.2.11 節中的 fsck 命令)。
使用mount時,如果要處理的文件系統位於/etc/fstab 中,則可以採取一些快捷方式。例如,如果使用清單 4-1 掛載CD-ROM,只需運行 mount /cdrom。
你也可以嘗試用這條命令同時掛載 /etc/fstab 中不包含 noauto 選項的所有條目:
# mount -a
清單 4-1 引入了一些新選項,即 errors、noauto 和 user,因為它們不適用於 /etc/fstab 文件之外。此外,你還會經常在這裏看到 defaults 選項。這些選項的定義如下:
- defaults 設置掛載默認值:讀寫模式、啓用設備文件、可執行文件、setuid 位等。當你不想給文件系統提供任何特殊選項,但又想填寫 /etc/fstab 中的所有字段時,請使用該選項。
- errors 這個特定於 ext2/3/4 的參數設置了當系統在掛載文件系統時出現問題時的內核行為。默認值通常是 errors=continue,即內核返回錯誤代碼並繼續運行。要讓內核以只讀模式再次嘗試掛載,請使用 errors=remount-ro。errors=panic 設置可讓內核(和系統)在掛載出現問題時停止運行。
- noauto 該選項會告訴 mount -a 命令忽略條目。使用該選項可防止啓動時掛載閃存等可移動媒體設備。
- user 該選項允許無權限用户在特定條目上運行 mount,這對於允許某些類型的可移動媒體訪問非常方便。由於用户可以通過其他系統在可移動介質上設置 setuid-root 文件,因此該選項還可以設置 nosuid、noexec 和 nodev(禁止使用特殊設備文件)。請記住,對於可移動媒體和其他一般情況,該選項現在的作用有限,因為大多數系統都使用 ubus 和其他機制來自動掛載插入的媒體。不過,在特殊情況下,如需控制特定目錄的掛載,該選項還是很有用的。
4.2.9 /etc/fstab的替代方案
雖然 /etc/fstab 文件是表示文件系統及其掛載點的傳統方法,但也有兩種替代方法。第一種是 /etc/fstab.d,它包含單獨的文件系統配置文件(每個文件系統一個文件)。這種思路與本書中的許多其他配置目錄非常相似。
第二種方法是為文件系統配置 systemd 單元。有關 systemd 及其單元的更多信息,請參見第 6 章。不過,systemd 單元配置通常由 /etc/fstab 文件生成(或基於 /etc/fstab 文件),因此在你的系統中可能會發現一些重疊。
4.2.10 文件系統容量
要查看當前掛載文件系統的大小和使用情況,請使用 df 命令。輸出可能非常廣泛(而且由於文件系統的專業化,輸出會越來越長),但其中應包括實際存儲設備的信息。
$ df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda1 214234312 127989560 75339204 63% /
/dev/sdd2 3043836 4632 2864872 1% /media/user/uuid
如果無法在df輸出中找到與特定目錄對應的正確行,請運行df dir命令,其中dir是要檢查的目錄。這會將輸出限制在該目錄的文件系統中。一個非常常用的命令是df .,它將輸出限制在保存當前目錄的設備上。
不難看出,這裏的兩個文件系統的大小分別為 215GB 和 3GB。不過,容量數字看起來可能有點奇怪,因為 127,989,560 加上 75,339,204 不等於 214,234,312 ,而 127,989,560 也不是 214,234,312 的 63%。在這兩種情況下,總容量的 5% 都沒有計算在內。事實上,這些空間是存在的,只是隱藏在預留塊中。當文件系統開始填滿時,只有超級用户才能使用預留塊。這項功能可以防止系統服務器在磁盤空間耗盡時立即癱瘓。
如果你的磁盤已滿,需要知道那些佔用空間的媒體文件都在哪裏,可以使用 du 命令。在沒有參數的情況下,du 會從當前工作目錄開始,打印目錄層次結構中每個目錄的磁盤使用情況。(這可能是一個很長的列表;如果你想看一個例子,只需運行 cd /; du 即可。無聊時按 CTRL-C)。du -s 命令打開摘要模式,只打印總計。要評估特定目錄中的所有內容(文件和子目錄),請切換到該目錄並運行 du -s *,注意可能有一些點目錄是該命令無法捕捉到的。
POSIX 標準定義塊大小為 512 字節。不過,這種大小較難讀取,因此大多數 Linux 發行版的 df 和 du 輸出默認為 1,024 字節的塊。如果堅持以 512 字節塊顯示數字,請設置 POSIXLY_CORRECT 環境變量。要明確指定 1,024 字節的數據塊,請使用 -k 選項(這兩個工具都支持)。df 和 du 程序還有一個 -m 選項,用於列出以 1MB 塊為單位的容量,以及一個 -h 選項,用於根據文件系統的總體大小,猜測最容易被人讀取的容量。
4.2.11 檢查和修復文件系統
Unix文件系統提供的優化功能得益於複雜的數據庫機制。要使文件系統無縫運行,內核必須相信掛載的文件系統沒有錯誤,並且硬件能可靠地存儲數據。如果存在錯誤,可能會導致數據丟失和系統崩潰。
除了硬件問題,文件系統錯誤通常是由於用户以粗魯的方式關閉系統(例如拔掉電源線)造成的。在這種情況下,內存中以前的文件系統緩存可能與磁盤上的數據不匹配,當你碰巧踢了電腦一腳時,系統也可能正在更改文件系統。雖然許多文件系統都支持日誌,使文件系統損壞的發生率大大降低,但你始終應該正確關閉系統。無論使用哪種文件系統,都有必要不時檢查文件系統,以確保一切正常。
檢查文件系統的工具是 fsck。與 mkfs 程序一樣,Linux 支持的每種文件系統類型都有不同版本的 fsck。例如,在擴展文件系統系列(ext2/ext3/ext4)上運行時,fsck 會識別文件系統類型並啓動 e2fsck 工具。因此,除非 fsck 無法識別文件系統類型或你正在查找 e2fsck 手冊頁面,否則一般不需要鍵入 e2fsck。
本節介紹的信息專門針對擴展文件系統系列和 e2fsck。
要在交互式手動模式下運行 fsck,請將設備或掛載點(如 /etc/fstab 中所列)作為參數。例如
# fsck /dev/sdb1
切勿在已掛載的文件系統上使用 fsck--內核可能會在運行檢查時更改磁盤數據,導致運行時不匹配,從而使系統崩潰並損壞文件。只有一個例外:如果在單用户模式下只讀掛載根分區,則可以使用 fsck。
在手動模式下,fsck 會在通過時打印詳細的狀態報告,如果沒有問題,報告應該如下所示:
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/sdb1: 11/1976 files (0.0% non-contiguous), 265/7891 blocks
如果 fsck 在手動模式下發現問題,它會停止並提出與解決問題相關的問題。這些問題涉及文件系統的內部結構,例如重新連接鬆散的 inodes 和清除塊(inodes 是文件系統的構建塊;你將在第 4.6 節中看到它們是如何工作的)。當 fsck 要求你重新連接一個 inode 時,它發現了一個似乎沒有名稱的文件。重新連接此類文件時,fsck 會將文件放到文件系統中的 lost+found 目錄中,並用數字作為文件名。如果出現這種情況,你需要根據文件內容猜測文件名;原始文件名很可能已經不存在了。
一般來説,如果你剛剛不乾淨地關閉了系統,那麼就沒有必要繼續等待 fsck 修復過程了,因為 fsck 可能有很多小錯誤需要修復。幸運的是,e2fsck 有一個 -p 選項,它可以在不詢問的情況下自動修復普通問題,並在出現嚴重錯誤時中止。事實上,Linux 發行版都會在啓動時運行 fsck -p 的變種。(你可能還會看到 fsck -a,它也做同樣的事情)。
如果你懷疑你的系統發生了重大災難,比如硬件故障或設備配置錯誤,你需要決定採取什麼行動,因為 fsck 真的會把有更大問題的文件系統搞得一團糟。(如果 fsck 在手動模式下提出很多問題,這就是系統出現嚴重問題的一個信號)。
如果你認為發生了非常糟糕的事情,可以嘗試運行 fsck -n 來檢查文件系統,但不要修改任何內容。如果設備配置中存在你認為可以修復的問題(如線纜鬆動或分區表中的塊數不正確),請在真正運行 fsck 之前修復,否則很可能丟失大量數據。
如果你懷疑只有超級塊損壞了(例如,因為有人寫入了磁盤分區的開頭),你也許可以用 mkfs 創建的超級塊備份之一來恢復文件系統。使用 fsck -b num 將已損壞的超級塊替換為區塊編號為 num 的備用塊,並期待最好的結果。
如果不知道在哪裏可以找到備份超級塊,可以在設備上運行 mkfs -n 查看超級塊備份編號列表,而不會破壞數據。(再次提醒,確保使用 -n,否則會破壞文件系統)。
通常不需要手動檢查 ext3 和 ext4 文件系統,因為日誌可以確保數據完整性(請記住,日誌是一個尚未寫入文件系統特定位置的小型數據緩存)。如果你沒有乾淨利落地關閉系統,就會發現日誌中包含一些數據。要將 ext3 或 ext4 文件系統中的日誌刷新為常規文件系統數據庫,請按以下步驟運行 e2fsck:
# e2fsck -fy /dev/disk_device
不過,你可能希望在 ext2 模式下掛載已損壞的 ext3 或 ext4 文件系統,因為內核不會掛載日誌不為空的 ext3 或 ext4 文件系統。
磁盤問題更嚴重時,你的選擇就更少了:
- 你可以嘗試用 dd 從磁盤中提取整個文件系統映像,然後將其轉移到另一個大小相同的磁盤分區中。
- 可以嘗試儘可能修補文件系統,以只讀模式加載文件系統,並盡力挽救。
- 你也可以試試 debugfs。
在前兩種情況下,你仍然需要在掛載前修覆文件系統,除非你想手動拾取原始數據。如果你願意,可以輸入 fsck -y,選擇對所有 fsck 問題的回答都是 “y”,但這是不得已而為之,因為在修復過程中可能會出現你更願意手動處理的問題。
debugfs 工具允許你查看文件系統中的文件,並將它們複製到其他地方。默認情況下,它以只讀模式打開文件系統。如果你正在恢復數據,保持文件完好無損可能是個好主意,以免把事情搞得一團糟。
現在,如果你真的走投無路了--比如磁盤發生了災難性故障而又沒有備份--除了希望專業服務能 “刮掉盤片 ”之外,你能做的並不多。
4.2.12 特殊用途文件系統
並非所有文件系統都代表物理介質上的存儲。大多數 Unix 版本都有作為系統接口的文件系統。也就是説,文件系統不僅是在設備上存儲數據的工具,還能代表系統信息,如進程 ID 和內核診斷。這個想法可以追溯到 /dev 機制,它是使用文件作為 I/O 接口的早期模型。/proc 的想法來源於第八版的研究型 Unix,由 Tom J. Killian 實現,並在貝爾實驗室(包括許多最初的 Unix 設計者)創建 Plan 9 時得到加速--Plan 9 是一個將文件系統抽象提升到全新水平的研究型操作系統 (https://en.wikipedia.org/wiki/Plan_9_from_Bell_Labs)。
Linux 上常用的一些特殊文件系統類型包括
- proc掛載在/proc。proc是進程的縮寫。/pro 內的每個編號目錄指的是系統中當前進程的ID;每個目錄中的文件代表了該進程的各個方面。目錄 /proc/self 代表當前進程。Linux proc 文件系統包含大量額外的內核和硬件信息,如 /proc/cpuinfo 等文件。請記住,內核設計指南建議將與進程無關的信息從 /proc 移到 /sys,因此 /proc 中的系統信息可能不是最新的界面。
- sysfs 掛載在 /sys。(你在第 3 章中看到過)。
- tmpfs 掛載在 /run 和其他位置。使用 tmpfs,你可以將物理內存和交換空間用作臨時存儲空間。你可以將 tmpfs 掛載到你喜歡的位置,使用 size 和 nr_blocks 長選項來控制最大容量。不過,要注意不要把東西不斷地倒入 tmpfs 位置,因為你的系統最終會耗盡內存,程序也會開始崩潰。
- squashfs 一種只讀文件系統,其內容以壓縮格式存儲,並通過迴環設備按需提取。一個使用實例是 snap 軟件包管理系統,該系統將軟件包掛載在 /snap 目錄下。
- overlay 文件系統將目錄合併為一個複合文件系統。容器經常使用覆蓋文件系統;你將在第 17 章看到它們是如何工作的。
4.3 交換空間
磁盤上並非每個分區都包含文件系統。也可以用磁盤空間來增加機器上的內存。如果實際內存不足,Linux 虛擬內存系統會自動將內存碎片移入或移出磁盤存儲空間。這就是所謂的 “交換”(swapping),因為閒置程序的片段會被交換到磁盤上,以換取磁盤上的活動片段。用於存儲內存頁的磁盤區域稱為交換空間(或簡稱交換)。
free 命令的輸出包括以千字節為單位的當前交換使用情況,如下所示:
$ free
total used free
--snip--
Swap: 514072 189804 324268
要將整個磁盤分區用作交換空間,請按以下步驟操作:
- 確保分區為空。
- 運行 mkswap dev,其中 dev 是分區的設備。該命令會在分區上添加交換籤名,將其標記為交換空間(而不是文件系統或其他)。
- 執行 swapon dev 向內核註冊該空間。
創建交換分區後,你可以在/etc/fstab文件中加入一個新的交換條目,讓系統在機器啓動後立即使用交換空間。下面是一個使用 /dev/sda5 作為交換分區的示例條目:
/dev/sda5 none swap sw 0 0
交換籤名有 UUID,因此請記住,現在許多系統都使用 UUID 代替原始設備名。
4.3.2 使用文件作為交換空間
如果被迫重新分區磁盤以創建交換分區,你可以使用普通文件作為交換空間。這樣做不會有任何問題。
使用以下命令創建一個空文件,將其初始化為交換文件,並將其添加到交換池中:
# dd if=/dev/zero of=swap_file bs=1024k count=num_mb
# mkswap swap_file
# swapon swap_file
這裏,swap_file 是新交換文件的名稱,num_mb 是所需大小(以兆字節為單位)。
要從內核的活動池中刪除交換分區或文件,請使用 swapoff 命令。系統必須有足夠的剩餘內存(實際內存和交換內存的總和)來容納要移除的交換池中的任何活動頁面。
4.3.3 確定需要多少交換空間
曾幾何時,Unix 的傳統智慧認為,你應該保留至少兩倍於實際內存的交換空間。如今,不僅巨大的磁盤和內存容量給這個問題蒙上了陰影,我們使用系統的方式也發生了變化。一方面,磁盤空間如此充裕,分配超過兩倍的內存空間很有誘惑力。另一方面,由於實際內存太大,你可能根本用不上交換空間。
雙倍實際內存 "規則源於多用户登錄一台機器的時代。但並不是所有用户都處於活動狀態,因此,當活動用户需要更多內存時,可以交換掉非活動用户的內存,這樣就很方便了。
對於單用户機器來説,這一點可能仍然適用。如果你正在運行許多進程,交換掉非活動進程的部分內存,甚至是活動進程的非活動內存,一般都不會有問題。但是,如果你經常訪問交換空間,因為許多活動進程都想同時使用內存,你就會遇到嚴重的性能問題,因為磁盤 I/O(即使是固態硬盤)太慢了,跟不上系統其他部分的速度。唯一的解決辦法就是購買更多內存、終止某些進程或抱怨。
有時,Linux 內核可能會選擇交換進程,以獲得更多的磁盤緩存。為了防止這種行為,一些管理員會將某些系統配置為完全沒有交換空間。例如,高性能服務器絕不應占用交換空間,並應儘可能避免磁盤訪問。
在通用機器上配置無交換空間是很危險的。如果機器的實際內存和交換空間都完全耗盡,Linux 內核會調用內存不足(OOM)殺手殺死一個進程,以釋放一些內存。你顯然不希望這種情況發生在桌面應用程序上。另一方面,高性能服務器包括複雜的監控、冗餘和負載平衡系統,以確保它們永遠不會到達危險區域。
第 8 章將詳細介紹內存系統的工作原理。
4.4 邏輯卷管理器(Logical Volume Manager)
到目前為止,我們已經通過分區瞭解了磁盤的直接管理和使用,指定了存儲設備上某些數據的確切位置。我們知道,訪問像 /dev/sda1 這樣的塊設備時,會根據 /dev/sda 上的分區表找到特定設備上的某個位置,即使具體位置可能由硬件決定。
這種方法通常效果不錯,但也有一些缺點,尤其是在安裝後對磁盤進行更改時。例如,如果要升級磁盤,就必須安裝新磁盤、分區、添加文件系統,可能還要更改引導加載器和執行其他任務,最後才能切換到新磁盤。這個過程很容易出錯,而且需要多次重啓。當你想安裝額外的磁盤以獲得更大的容量時,情況可能更糟--在這種情況下,你必須為該磁盤上的文件系統選擇一個新的掛載點,並希望能在新舊磁盤之間手動分配數據。
LVM 通過在物理塊設備和文件系統之間添加另一層來解決這些問題。其原理是,選擇一組物理卷(通常只是塊設備,如磁盤分區),將其納入一個卷組,作為一種通用數據池。然後再從卷組中劃分出邏輯卷。
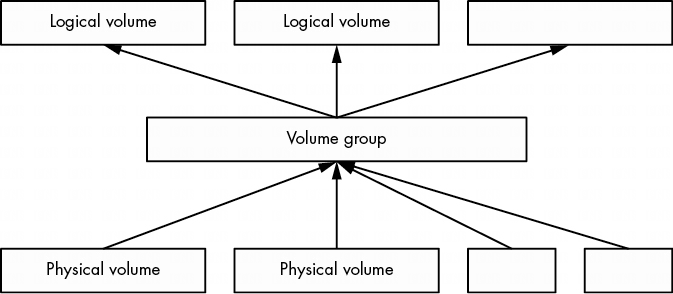
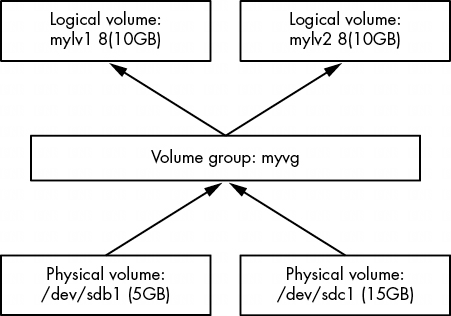
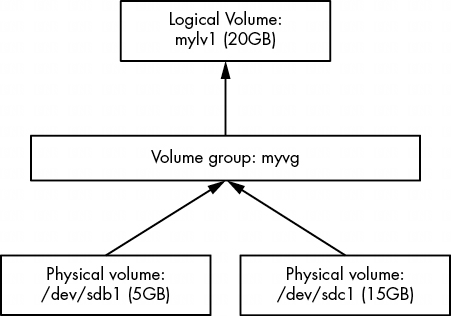
上圖顯示了一個卷組的組合示意圖。圖中顯示了多個物理卷和邏輯卷,但許多基於 LVM 的系統只有一個物理卷和兩個邏輯卷(根目錄和交換卷)。
邏輯卷只是塊設備,通常包含文件系統或交換籤名,因此可以認為卷組與其邏輯卷之間的關係類似於磁盤與其分區之間的關係。最重要的區別在於,你通常不需要定義邏輯卷在卷組中的佈局,LVM 會完成所有這些工作。
LVM 允許進行一些功能強大且極其有用的操作,例如
- 在卷組中添加更多 PV(如另一個磁盤),增加捲組的大小。
- 刪除 PV,只要有足夠的剩餘空間容納卷組內的現有邏輯卷。
- 調整邏輯卷的大小(並因此使用 fsadm 實用程序調整文件系統的大小)。
您可以在不重啓機器的情況下完成所有這些操作,而且在大多數情況下無需卸載任何文件系統。雖然添加新的物理磁盤硬件可能需要關機,但云計算環境通常允許你即時添加新的塊存儲設備,這使得 LVM 成為需要這種靈活性的系統的最佳選擇。
我們將對 LVM 進行適度詳細的探討。首先,我們將瞭解如何與邏輯卷及其組件進行交互和操作,然後我們將仔細研究 LVM 是如何工作的,以及它所基於的內核驅動程序。不過,這裏的討論對於理解本書的其他內容並不重要,所以如果你覺得太枯燥,可以跳到第 5 章。
4.4.1使用LVM
LVM 有許多管理卷和卷羣的用户空間工具。這些工具大多基於 lvm 命令,它是一個交互式通用工具。還有一些單獨的命令(只是 LVM 的符號鏈接)用於執行特定任務。例如,vgs 命令與在交互式 lvm 工具的 lvm> 提示符下鍵入 vgs 的效果相同,而且你會發現 vgs(通常在 /sbin)是 lvm 的符號鏈接。我們將在本書中使用這些命令。
在接下來的幾節中,我們將介紹使用邏輯卷的系統組件。最初的示例來自使用 LVM 分區選項的標準 Ubuntu 安裝,因此許多名稱都包含 Ubuntu 字樣。不過,這些技術細節都不是該發行版所特有的。
列出並理解卷組
剛才提到的 vgs 命令顯示了系統當前配置的卷組。輸出相當簡潔。下面是在我們的 LVM 安裝示例中可能看到的內容:
# vgs
VG #PV #LV #SN Attr VSize VFree
ubuntu-vg 1 2 0 wz--n- <10.00g 36.00m
第一行是標題,每一行代表一個卷組。列數如下
- VG 卷組名稱。ubuntu-vg 是 Ubuntu 安裝程序在使用 LVM 配置系統時指定的通用名稱。
-
PV 卷組存儲的物理卷數量。
-
LV 卷組內邏輯卷的數量。
-
邏輯卷快照的數量。我們不會詳細介紹。
- Attr 卷組的若干狀態屬性。這裏,w(可寫)、z(可調整大小)和 n(正常分配策略)處於活動狀態。
- VSize 卷組大小。
- VFree 卷組中未分配的空間大小。
這個卷組概要足以滿足大多數目的。如果想更深入地瞭解某個卷組,可以使用 vgdisplay 命令,它對了解卷組的屬性非常有用。下面是使用 vgdisplay 顯示的同一個卷組:
你以前看到過其中的一些內容,但還有一些新項目值得注意:
~# vgdisplay
--- Volume group ---
VG Name ubuntu-vg
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 3
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 1
Open LV 1
Max PV 0
Cur PV 1
Act PV 1
VG Size 890.08 GiB
PE Size 4.00 MiB
Total PE 227861
Alloc PE / Size 227861 / 890.08 GiB
Free PE / Size 0 / 0
VG UUID 2h4MuD-CKO0-nsoF-R6Ks-uMtm-Eqjz-tPhf5a
- Open LV 當前正在使用的邏輯卷的數量。
- Cur PV 卷組包含的物理卷數量。
- Act LV 卷組中活動物理卷的數量。
- VG UUID 卷組的通用唯一標識符。一個系統中可能有多個同名的卷組;在這種情況下,UUID 可以幫助你隔離某個卷組。大多數 LVM 工具(如 vgrename,它可以幫助你解決類似情況)都接受 UUID 作為卷組名稱的替代。請注意,你會看到很多不同的 UUID;LVM 的每個組件都有一個 UUID。
物理範圍(在 vgdisplay 輸出中縮寫為 PE)是物理卷的一部分,與塊很相似,但規模更大。在本例中,PE 大小為 4MB。可以看到,該卷組上的大部分 PE 都在使用中,但這並不值得大驚小怪。這只是為邏輯分區(本例中為文件系統和交換空間)分配的卷組空間大小,並不反映文件系統的實際使用情況。
與卷組類似,列出邏輯卷的命令是 lvs(簡短列出)和 lvdisplay(詳細顯示)。下面是 lvs 的示例:
# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
ubuntu-lv ubuntu-vg -wi-ao---- 890.08g
在基本的 LVM 配置中,只有前四列需要了解,其餘列可能是空的,這裏就是這種情況(我們將不介紹這些列)。這裏的相關列是
- LV 邏輯卷名稱。
- VG 邏輯加密卷所在的加密卷組。
- Attr 邏輯加密卷的屬性。這裏有 w(可寫)、i(繼承分配策略)、a(活動)和 o(打開)。在更高級的卷組配置中,更多的槽位處於活動狀態,尤其是第一、第七和第九槽位。
- LSize 邏輯加密卷的大小。
運行更詳細的 lvdisplay 可以幫助瞭解邏輯卷在系統中的位置。下面是一個邏輯卷的輸出結果:
# lvdisplay /dev/ubuntu-vg/ubuntu-lv
--- Logical volume ---
LV Path /dev/ubuntu-vg/ubuntu-lv
LV Name ubuntu-lv
VG Name ubuntu-vg
LV UUID 7cEznr-0SRd-PMhD-Yojp-bw5R-DxbL-q0aYUB
LV Write Access read/write
LV Creation host, time ubuntu-server, 2024-04-09 16:55:44 +0800
LV Status available
# open 1
LV Size 890.08 GiB
Current LE 227861
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:0
這裏有很多有趣的內容,而且大部分內容不言自明(注意邏輯卷的 UUID 與卷組的 UUID 不同)。也許你還沒有看到的最重要的東西是第一項: LV 路徑,即邏輯加密卷的設備路徑。有些系統(但不是所有系統)將其用作文件系統或交換空間的掛載點(在 systemd 掛載單元或 /etc/fstab 中)。
雖然你可以看到邏輯卷塊設備的主設備號和次設備號(這裏是 253 和 0),以及一些看起來像設備路徑的東西,但它實際上並不是內核使用的路徑。快速查看/dev/ubuntu-vg/root就會發現另有隱情:
# ls -l /dev/ubuntu-vg/ubuntu-lv
lrwxrwxrwx 1 root root 7 Jul 10 16:27 /dev/ubuntu-vg/ubuntu-lv -> ../dm-0
如你所見,這只是一個指向 /dev/dm-0 的符號鏈接。讓我們來簡單瞭解一下。
LVM 在系統上完成設置工作後,邏輯卷塊設備就可以在 /dev/dm-0 和 /dev/dm-1 等位置上使用,而且可以按任意順序排列。由於這些設備名稱的不可預測性,LVM 還會根據卷組和邏輯卷名稱創建符號鏈接,指向具有穩定名稱的設備。在上一節的 /dev/ubuntu-vg/root 中,我們已經看到了這一點。
在大多數實現中,符號鏈接還有一個額外的位置: /dev/mapper。這裏的名稱格式也是基於卷組和邏輯卷,但沒有目錄層次結構;相反,鏈接的名稱就像 ubuntu--vg-root 一樣。在這裏,udev 將卷組中的單破折號轉換為雙破折號,然後用單破折號分隔卷組和邏輯卷名稱。
許多系統在 /etc/fstab、systemd 和引導加載器配置中使用 /dev/mapper 中的鏈接,以便將系統指向用於文件系統和交換空間的邏輯卷。
無論如何,這些符號鏈接都指向邏輯卷的塊設備,你可以像使用其他塊設備一樣與它們交互:創建文件系統、創建交換分區等。
在 /dev/mapper 附近,你還會看到一個名為 control 的文件。你可能會對這個文件感到奇怪,為什麼真正的塊設備文件都以 dm- 開頭;這是否與 /dev/mapper 有某種巧合?我們將在本章結尾討論這些問題。
LVM 的最後一個主要部分是物理卷(PV)。一個卷組由一個或多個 PV 組成。雖然 PV 看起來像是 LVM 系統的一個簡單部分,但它包含的信息比我們看到的要多一些。與卷組和邏輯卷一樣,查看 PV 的 LVM 命令是 pvs(查看簡短列表)和 pvdisplay(查看更深入的信息)。下面是我們示例系統的 pvs 顯示:
# pvs
PV VG Fmt Attr PSize PFree
/dev/sda1 ubuntu-vg lvm2 a-- <10.00g 36.00m
# pvdisplay
--- Physical volume ---
PV Name /dev/sda1
VG Name ubuntu-vg
PV Size <10.00 GiB / not usable 2.00 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 2559
Free PE 9
Allocated PE 2550
PV UUID v2Qb1A-XC2e-2G4l-NdgJ-lnan-rjm5-47eMe5
通過前面對卷組和邏輯卷的討論,你應該可以理解大部分輸出結果。下面是一些注意事項:
除塊設備外,PV 沒有特殊名稱。邏輯卷所需的所有名稱都在卷組及以上級別。不過,PV 確實有一個 UUID,這是組成卷組所必需的。
在這種情況下,PE 的數量與卷組中的使用量相匹配(我們在前面已經看到),因為這是卷組中唯一的 PV。
有一小部分空間被 LVM 標為不可用,因為它不足以填滿一個完整的 PE。
pvs 輸出屬性中的 a 與 pvdisplay 輸出中的 Allocatable 相對應,它簡單地表示如果要為卷組中的邏輯卷分配空間,LVM 可以選擇使用這個 PV。不過,在本例中,只有 9 個未分配的 PE(總計 36MB),因此可用於新邏輯卷的空間並不多。
如前所述,PV 所包含的信息不僅僅是它們各自對卷組的貢獻。每個 PV 都包含物理卷元數據、卷組及其邏輯卷的大量信息。我們稍後將探討 PV 元數據,但首先讓我們親身體驗一下,看看我們所學到的知識是如何融會貫通的。
讓我們來看一個例子,看看如何用兩個磁盤設備創建一個新卷組和一些邏輯卷。我們將把兩個容量分別為 5GB 和 15GB 的磁盤設備合併為一個卷組,然後將該空間劃分為兩個容量各為 10GB 的邏輯卷--如果沒有 LVM,這幾乎是不可能完成的任務。這裏顯示的示例使用的是 VirtualBox 磁盤。雖然這些容量在任何現代系統上都很小,但足以説明問題。
圖 4-5 顯示了卷示意圖。新磁盤位於 /dev/sdb 和 /dev/sdc,新卷組名為 myvg,兩個新邏輯卷名為 mylv1 和 mylv2。
第一項任務是在每個磁盤上創建一個分區,併為 LVM 貼上標籤。使用分區類型 ID 8e,用分區程序(見第 4.1.2 節)完成這項工作,這樣分區表看起來就像這樣:
不一定要對磁盤進行分區才能使其成為 PV。PV 可以是任何塊設備,甚至是整個磁盤設備,如 /dev/sdb。不過,分區可以從磁盤啓動,還提供了將塊設備識別為 LVM 物理卷的方法。
有了 /dev/sdb1 和 /dev/sdc1 這兩個新分區,使用 LVM 的第一步就是將其中一個分區指定為 PV,並將其分配給一個新卷組。只需一條命令 vgcreate 就能完成這項任務。下面是創建名為 myvg 的卷組的方法,初始 PV 為 /dev/sdb1:
# vgcreate myvg /dev/sdb1
Physical volume "/dev/sdb1" successfully created.
Volume group "myvg" successfully created
您也可以使用 pvcreate 命令在單獨步驟中首先創建一個 PV。不過,如果當前沒有任何分區,vgcreate 會在分區上執行此步驟。
此時,大多數系統會自動檢測到新的卷組;請運行 vgs 等命令進行驗證(請注意,除了您剛剛創建的卷組外,系統上可能還會顯示其他現有的卷組):
# vgs
VG #PV #LV #SN Attr VSize VFree
myvg 1 0 0 wz--n- <5.23g <5.23g
如果看不到新的卷組,請先嚐試運行 pvscan。如果系統不能自動檢測 LVM 的更改,那麼每次更改時都需要運行 pvscan。
現在,你可以使用 vgextend 命令將位於 /dev/sdc1 的第二個 PV 添加到卷組中:
# vgextend myvg /dev/sdc1
Physical volume "/dev/sdc1" successfully created.
Volume group "myvg" successfully extended
現在運行 vgs 會顯示兩個 PV,大小是兩個分區的總和:
# vgs
VG #PV #LV #SN Attr VSize VFree
myvg 2 0 0 wz--n- <20.16g <20.16g
塊設備級的最後一步是創建邏輯卷。如前所述,我們將創建兩個各 10GB 的邏輯卷,但也可以嘗試其他可能性,如創建一個大邏輯卷或多個小邏輯卷。
lvcreate 命令在卷組中分配一個新的邏輯卷。創建簡單邏輯卷的唯一複雜之處在於,當每個卷組不止一個邏輯卷時,如何確定邏輯卷的大小,以及指定邏輯卷的類型。請記住,PV 被劃分為擴展;可用 PE 的數量可能與您所需的大小不完全一致。如果你是第一次使用 LVM,就不必太在意 PE。
使用 lvcreate 時,可以使用 --size 選項以字節為單位的數字容量指定邏輯卷的大小,也可以使用 --extents 選項以 PE 的數量指定邏輯卷的大小。
因此,為了瞭解其工作原理,並完成圖 4-5 中的 LVM 原理圖,我們將使用 --size 創建名為 mylv1 和 mylv2 的邏輯卷:
# lvcreate --size 10g --type linear -n mylv1 myvg
Logical volume "mylv1" created.
# lvcreate --size 10g --type linear -n mylv2 myvg
Logical volume "mylv2" created.
這裏的類型是線性映射,是不需要冗餘或其他特殊功能時最簡單的類型(我們在本書中不會使用其他類型)。在這種情況下,--type linear 是可選的,因為它是默認映射。
運行這些命令後,使用 lvs 命令驗證邏輯卷是否存在,然後使用 vgdisplay 仔細查看卷組的當前狀態:
# vgdisplay myvg
--- Volume group ---
VG Name myvg
System ID
Format lvm2
Metadata Areas 2
Metadata Sequence No 4
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 2
Open LV 0
Max PV 0
Cur PV 2
Act PV 2
VG Size 20.16 GiB
PE Size 4.00 MiB
Total PE 5162
Alloc PE / Size 5120 / 20.00 GiB
Free PE / Size 42 / 168.00 MiB
VG UUID 1pHrOe-e5zy-TUtK-5gnN-SpDY-shM8-Cbokf3
請注意有 42 個空閒 PE,因為我們為邏輯卷選擇的大小並沒有佔用卷組中的所有可用擴展。
有了新的邏輯卷,現在就可以像其他普通磁盤分區一樣,在設備上放置文件系統並加載它們,從而使用它們了。如前所述,/dev/mapper 和(本例中)卷組的/dev/myvg 目錄中會有指向設備的符號鏈接。因此,舉例來説,你可以運行以下三條命令來創建文件系統、臨時加載文件系統並查看邏輯卷的實際空間:
# mkfs -t ext4 /dev/mapper/myvg-mylv1
mke2fs 1.44.1 (24-Mar-2018)
Creating filesystem with 2621440 4k blocks and 655360 inodes
Filesystem UUID: 83cc4119-625c-49d1-88c4-e2359a15a887
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
# mount /dev/mapper/myvg-mylv1 /mnt
# df /mnt
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/myvg-mylv1 10255636 36888 9678076 1% /mnt
我們還沒有研究過對另一個邏輯卷 mylv2 的任何操作,因此讓我們用它來使這個示例更有趣。假如你發現你並沒有真正使用第二個邏輯卷。你決定刪除它,並調整第一個邏輯卷的大小,以佔用卷組的剩餘空間。圖 4-6 顯示了我們的目標。
假定你已經移動或備份了要刪除的邏輯捲上的重要內容,並且當前系統沒有使用該邏輯卷(也就是説,你已經卸載了它),那麼首先使用 lvremove 命令將其刪除。使用該命令操作邏輯加密卷時,將使用不同的語法,即用斜線分隔加密卷組和邏輯加密卷名稱(myvg/mylv2):
# lvremove myvg/mylv2
Do you really want to remove and DISCARD active logical volume myvg/mylv2? [y/n]: y
Logical volume "mylv2" successfully removed
運行 lvremove 時要小心。由於您在執行其他 LVM 命令時沒有使用過這種語法,因此可能會不小心用空格代替斜線。在這種情況下,如果你犯了這個錯誤,lvremove 就會假定你想刪除 myvg 和 mylv2 卷組上的所有邏輯卷(你幾乎肯定沒有名為 mylv2 的卷組,但這不是目前最大的問題)。因此,如果你不注意,你可能會刪除卷組上的所有邏輯卷,而不僅僅是一個。
從這個交互過程中可以看出,lvremove 會反覆檢查你是否真的想刪除每個要刪除的邏輯卷,以防止你出錯。它也不會試圖刪除正在使用的卷。不過,不要以為別人問你任何問題,你都應該回答 “是”。
現在你可以調整第一個邏輯卷 mylv1 的大小了。 即使卷正在使用且其文件系統已加載,你也可以這樣做。不過,重要的是要明白有兩個步驟。要使用較大的邏輯卷,需要調整邏輯卷和邏輯卷內文件系統的大小(也可以在掛載邏輯卷時進行)。不過,由於這是一個很常見的操作,因此調整邏輯卷大小的 lvresize 命令有一個選項 (-r),可以為你同時調整文件系統的大小。
為了説明起見,讓我們使用兩個不同的命令來看看它是如何工作的。有幾種方法可以指定邏輯卷的大小變化,但在本例中,最直接的方法是將卷組中的所有空閒 PE 添加到邏輯卷中。回想一下,你可以用 vgdisplay 找到這個數字;在我們正在運行的示例中,它是 2 602。下面是 lvresize 命令,用於將所有空閒 PE 添加到 mylv1:
# lvresize -l +2602 myvg/mylv1
Size of logical volume myvg/mylv1 changed from 10.00 GiB (2560 extents) to 20.16 GiB (5162 extents).
Logical volume myvg/mylv1 successfully resized.
現在需要調整內部文件系統的大小。可以使用 fsadm 命令來完成。使用 -v 選項)觀察它在詳細説明模式下的運行情況也很有趣:
# fsadm -v resize /dev/mapper/myvg-mylv1
fsadm: "ext4" filesystem found on "/dev/mapper/myvg-mylv1".
fsadm: Device "/dev/mapper/myvg-mylv1" size is 21650997248 bytes
fsadm: Parsing tune2fs -l "/dev/mapper/myvg-mylv1"
fsadm: Resizing filesystem on device "/dev/mapper/myvg-mylv1" to 21650997248 bytes (2621440 -> 5285888 blocks of 4096 bytes)
fsadm: Executing resize2fs /dev/mapper/myvg-mylv1 5285888
resize2fs 1.44.1 (24-Mar-2018)
Filesystem at /dev/mapper/myvg-mylv1 is mounted on /mnt; on-line resizing required
old_desc_blocks = 2, new_desc_blocks = 3
The filesystem on /dev/mapper/myvg-mylv1 is now 5285888 (4k) blocks long.
從輸出結果可以看出,fsadm 只是一個腳本,它知道如何將參數轉換為文件系統專用工具(如 resize2fs)使用的參數。默認情況下,如果你不指定大小,它會簡單地調整大小以適應整個設備。
既然已經瞭解了調整卷大小的細節,你可能正在尋找捷徑。更簡單的方法是使用不同的語法指定大小,然後讓 lvresize 為你執行分區大小調整,只需執行以下命令即可:
# lvresize -r -l +100%FREE myvg/mylv1
你可以在掛載 ext2/ext3/ext4 文件系統時對其進行擴展,這一點相當不錯。遺憾的是,它不能反向操作。你不能在掛載文件系統時縮小它。不僅必須卸載文件系統,而且縮小邏輯卷的過程需要反向操作。因此,手動調整分區大小時,需要先調整分區大小,然後再調整邏輯卷大小,確保新邏輯卷的大小仍足以容納文件系統。同樣,使用帶有 -r 選項的 lvresize 會更方便,因為它可以幫你協調文件系統和邏輯卷的大小。
參考資料
- 軟件測試精品書籍文檔下載持續更新 https://github.com/china-testing/python-testing-examples 請點贊,謝謝!
- 本文涉及的python測試開發庫 謝謝點贊! https://github.com/china-testing/python_cn_resouce
- python精品書籍下載 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品書籍下載 https://www.cnblogs.com/testing-/p/17438558.html
4.4.2 LVM 實現
在介紹了 LVM 比較實用的操作基礎知識後,我們現在可以簡單瞭解一下它的實現。與本書中幾乎所有其他主題一樣,LVM 包含許多層和組件,內核和用户空間的各部分之間有相當細緻的分離。
很快你就會看到,查找 PV 以發現卷組和邏輯卷的結構有些複雜,Linux 內核寧願不處理其中的任何部分。內核空間沒有理由做這些事情;PV 只是塊設備,而用户空間可以隨機訪問塊設備。事實上,LVM(更具體地説,當前系統中的 LVM2)本身只是一套了解 LVM 結構的用户空間實用程序的名稱。
另一方面,內核負責將邏輯卷塊設備上的位置請求路由到實際設備上的真實位置。設備映射器(有時簡稱為 devmapper)就是這項工作的驅動程序,它是夾在普通塊設備和文件系統之間的一個新層。顧名思義,設備映射器所執行的任務就像跟蹤地圖一樣;你幾乎可以把它想象成把街道地址轉換為全球經緯度座標之類的絕對位置。(這是一種虛擬化形式;我們將在本書其他部分看到的虛擬內存也是基於類似的概念)。
在 LVM 用户空間工具和設備映射器之間有一些粘合劑:一些在用户空間運行的實用程序,用於管理內核中的設備映射。讓我們從 LVM 開始,看看 LVM 方面和內核方面的情況。
在執行任何操作之前,LVM 實用程序必須首先掃描可用的塊設備,以查找物理卷。LVM 必須在用户空間執行的步驟大致如下:
- 查找系統中的所有 PV。
- 按 UUID 查找 PV 所屬的所有卷組(此信息包含在 PV 中)。
- 驗證所有內容是否完整(即屬於卷組的所有必要 PV 都已存在)。
- 查找卷組中的所有邏輯卷。
- 找出將數據從 PV 映射到邏輯卷的方案。
每個 PV 的開頭都有一個標頭,用於標識卷、卷組和其中的邏輯卷。LVM 實用程序可以將這些信息放在一起,並確定是否存在卷組(及其邏輯卷)所需的所有 PV。如果一切正常,LVM 就可以將信息傳遞給內核。
如果您對 PV 上 LVM 頭文件的外觀感興趣,可以運行如下命令:
# dd if=/dev/sdb1 count=1000 | strings | less
在本例中,我們使用 /dev/sdb1 作為 PV。別指望輸出結果會很漂亮,但它確實顯示了 LVM 所需的信息。
任何 LVM 實用程序,如 pvscan、lvs 或 vgcreate,都可以執行掃描和處理 PV 的工作。
LVM 根據 PV 上的所有標頭確定邏輯卷的結構後,會與內核的設備映射器驅動程序通信,以初始化邏輯卷的塊設備並加載其映射表。它通過 /dev/mapper/control 設備文件上的 ioctl(2) 系統調用(常用的內核接口)來實現這一功能。要監控這種交互並不現實,但可以使用 dmsetup 命令查看結果的細節。
使用 dmsetup info 命令可以獲得設備映射器當前服務的映射設備清單。下面是本章前面創建的一個邏輯卷可能得到的結果:
# dmsetup info
Name: myvg-mylv1
State: ACTIVE
Read Ahead: 256
Tables present: LIVE
Open count: 0
Event number: 0
Major, minor: 253, 1
Number of targets: 2
UUID: LVM-1pHrOee5zyTUtK5gnNSpDYshM8Cbokf3OfwX4T0w2XncjGrwct7nwGhpp7l7J5aQ
設備的主編號和次編號與映射設備的 /dev/dm-* 設備文件相對應;該設備映射器的主編號為 253。因為次要序號是 1,所以設備文件被命名為 /dev/dm-1。請注意,內核為映射設備提供了一個名稱和另一個 UUID。LVM 向內核提供了這些信息(內核 UUID 只是卷組和邏輯卷 UUID 的連接)。
還記得/dev/mapper/myvg-mylv1 這樣的符號鏈接嗎? udev 通過使用第 3.5.2 節所述的規則文件,根據來自設備映射器的新設備創建這些鏈接。
你也可以通過 dmsetup table 命令查看 LVM 提供給設備映射器的表。下面是我們之前的例子,當時有兩個 10GB 的邏輯卷(mylv1 和 mylv2),分佈在兩個 5GB (/dev/sdb1)和 15GB (/dev/sdc1)的物理捲上:
# dmsetup table
myvg-mylv2: 0 10960896 linear 8:17 2048
myvg-mylv2: 10960896 10010624 linear 8:33 20973568
myvg-mylv1: 0 20971520 linear 8:33 2048
每一行都提供了特定映射設備的映射段。對於設備 myvg-mylv2,有兩段,而對於 myvg-mylv1,只有一段。名稱後面的字段依次是
- 映射設備的起始偏移量。單位是 512 字節的 “扇區”,也就是你在許多其他設備中看到的正常塊大小。
- 段的長度。
- 映射方案。這裏是簡單的一對一線性方案。
- 源設備的主設備號和次設備號對,即 LVM 所稱的物理卷。這裏 8:17 代表 /dev/sdb1,8:33 代表 /dev/sdc1。
- 源設備上的起始偏移。
有趣的是,在我們的例子中,LVM 選擇將 /dev/sdc1 中的空間用於我們創建的第一個邏輯卷(mylv1)。LVM 決定要以連續的方式佈局第一個 10GB 邏輯卷,而唯一的辦法就是在 /dev/sdc1 上這樣做。然而,在創建第二個邏輯加密卷(mylv2)時,LVM 別無選擇,只能將其分為兩段,分佈在兩個 PV 上。圖 4-7 顯示了這種安排。
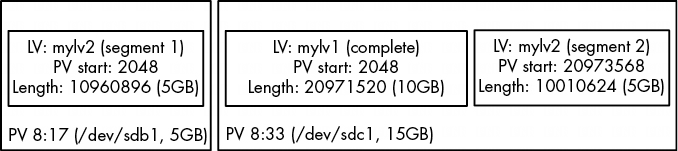
圖 4-7: LVM 如何安排 mylv1 和 mylv2
此外,當我們移除 mylv2 並擴展 mylv1 以適應卷組中的剩餘空間時,PV 中的原始起始偏移量仍保留在 /dev/sdc1 上,但其他一切都發生了變化,以包括 PV 的剩餘部分:
# dmsetup table
myvg-mylv1: 0 31326208 linear 8:33 2048
myvg-mylv1: 31326208 10960896 linear 8:17 2048
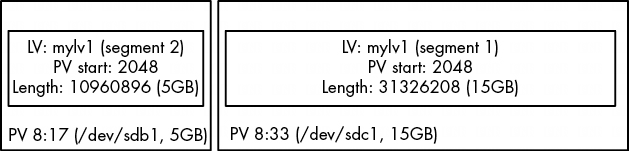
圖 4-8: 刪除 mylv2 並擴展 mylv1 後的安排
你可以在虛擬機上盡情試驗邏輯卷和設備映射器,看看映射結果如何。許多功能(如軟件 RAID 和加密磁盤)都建立在設備映射器上。
4.5 展望未來: 磁盤和用户空間
在 Unix 系統中與磁盤相關的組件中,用户空間和內核之間的界限可能很難描述。如前所述,內核處理來自設備的原始塊 I/O,而用户空間工具可以通過設備文件使用塊 I/O。不過,用户空間通常只將塊 I/O 用於初始化操作,如分區、文件系統創建和交換空間創建。在正常使用中,用户空間只使用內核在塊 I/O 上提供的文件系統支持。同樣,在虛擬內存系統中處理交換空間時,內核也會處理大部分繁瑣的細節。
本章剩餘部分將簡要介紹 Linux 文件系統的內部結構。這是比較高級的內容,你當然不需要了解這些內容就能繼續閲讀本書。如果你是第一次閲讀本書,請跳到下一章,開始學習 Linux 如何啓動。
4.6 傳統文件系統的內部結構
傳統的 Unix 文件系統有兩個主要組成部分:一個可以存儲數據的數據塊池和一個管理數據池的數據庫系統。數據庫以 inode 數據結構為中心。Inode 是一組描述特定文件的數據,包括文件類型、權限以及最重要的文件數據在數據池中的位置。inode 由 inode 表中列出的數字標識。
文件名和目錄也作為 inode 實現。目錄 inode 包含與其他 inode 相對應的文件名和鏈接列表。
為了提供一個真實的例子,我創建了一個新的文件系統,將其掛載,並將目錄更改為掛載點。然後,我使用這些命令添加了一些文件和目錄:
$ mkdir dir_1
$ mkdir dir_2
$ echo a > dir_1/file_1
$ echo b > dir_1/file_2
$ echo c > dir_1/file_3
$ echo d > dir_2/file_4
$ ln dir_1/file_3 dir_2/file_5
請注意,我創建的 dir_2/file_5 是 dir_1/file_3 的硬鏈接,這意味着這兩個文件名實際上代表的是同一個文件(稍後將詳細介紹)。你可以自己試試。不一定要在新的文件系統上進行。
如果要查看該文件系統中的目錄,其內容將如圖 4-9 所示。
注意
如果你在自己的系統上嘗試這樣做,inode 數字可能會有所不同,特別是如果你運行命令在現有文件系統上創建文件和目錄的話。具體的數字並不重要,重要的是它們指向的數據。
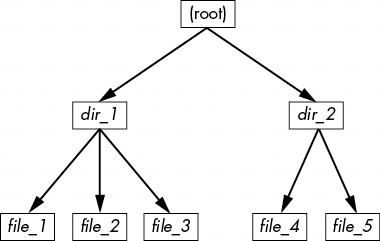
如圖 4-10 所示,文件系統的實際佈局是一組 inodes,看起來並不像用户級表示那樣簡潔。
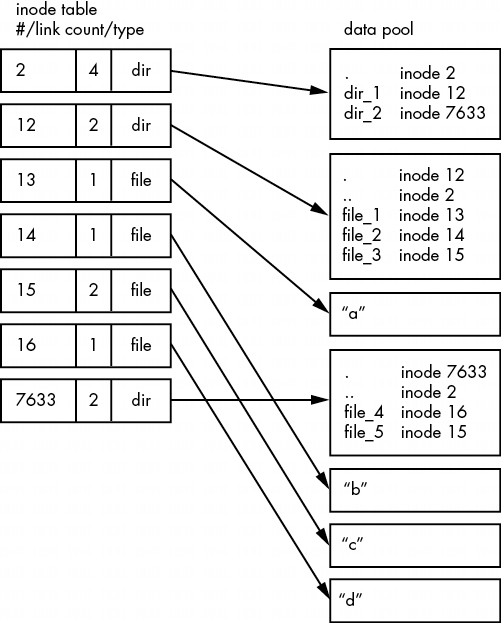
如何理解這一點?對於任何 ext2/3/4 文件系統,都是從 2 號節點開始,也就是根節點(儘量不要與系統根文件系統混淆)。從圖 4-10 中的 inode 表可以看出,這是一個目錄 inode (dir),因此可以按照箭頭指向數據池,在那裏可以看到根目錄的內容:名為 dir_1 和 dir_2 的兩個條目分別對應 inode 12 和 7633。要查看這些條目,請返回到 inode 表,查看其中任何一個 inode。
要查看該文件系統中的 dir_1/文件_2,內核會執行以下操作:
- 確定路徑的組成部分:名為 dir_1 的目錄,以及名為 file_2 的組成部分。
- 跟蹤根節點到其目錄數據。
- 在第 2 節的目錄數據中找到名為 dir_1 的目錄,它指向第 12 節。
- 在 inode 表中查找 inode 12,確認它是一個目錄 inode。
- 根據 inode 12 的數據鏈接找到其目錄信息(數據池中向下的第二個方框)。
- 在節點 12 的目錄數據中找到路徑的第二個部分(file_2)。該條目指向節點 14。
- 在目錄表中查找 Inode 14。這是一個文件節點。
- 此時,內核知道了文件的屬性,可以通過 14 號節點的數據鏈路打開文件。
這種由 inode 指向目錄數據結構、由目錄數據結構指向 inode 的系統,可以創建我們熟悉的文件系統層次結構。此外,請注意目錄 inodes 包含 .(當前目錄)和 .(父目錄,根目錄除外)的條目。這樣就很容易獲得參考點,並沿着目錄結構向下導航。
4.6.1 Inode 詳情和鏈接計數
使用 ls -i 命令可以查看任何目錄的節點編號。下面是本例中根目錄下的內容(如需更詳細的 inode 信息,請使用 stat 命令):
$ ls -i
12 dir_1 7633 dir_2
你可能想知道 inode 表中的鏈接計數。你已經在普通 ls -l 命令的輸出中看到了鏈接計數,但很可能忽略了它。鏈接計數與圖 4-9 中的文件,尤其是 “硬鏈接 ”文件_5 有什麼關係?鏈接計數字段是指向一個 inode 的目錄條目總數(在所有目錄中)。大多數文件的鏈接計數都是 1,因為它們在目錄條目中只出現過一次。這是意料之中的。大多數情況下,當你創建一個文件時,你會創建一個新的目錄條目和一個新的 inode。但 inode 15 出現了兩次。首先,它被創建為 dir_1/file_3,然後又被鏈接為 dir_2/file_5。硬鏈接就是在目錄中手動創建一個條目,指向一個已經存在的 inode。使用 ln 命令(不帶 -s 選項)可以手動創建新的硬鏈接。
這也是刪除文件有時被稱為取消鏈接的原因。如果運行 rm dir_1/file_2,內核會在 inode 12 的目錄條目中搜索名為 file_2 的條目。一旦發現 file_2 與 inode 14 相對應,內核就會刪除該目錄項,然後從 inode 14 的鏈接計數中減去 1。這樣,inode 14 的鏈接計數將為 0,內核將知道不再有任何名稱鏈接到該 inode。因此,內核現在可以刪除該 inode 及其相關數據。
然而,如果運行 rm dir_1/file_3,最終結果是 inode 15 的鏈接計數從 2 變為 1(因為 dir_2/file_5 仍指向該處),內核知道不能刪除該 inode。
鏈接計數對目錄的作用也是一樣的。請注意,inode 12 的鏈接計數是 2,因為那裏有兩個 inode 鏈接:一個是 inode 2 目錄條目中的 dir_1,另一個是它自己的目錄條目中的自引用(.)。如果創建一個新的目錄 dir_1/dir_3,則第 12 個節點的鏈接數將變為 3,因為新目錄將包含一個父(...)條目,該條目鏈接回第 12 個節點,就像第 12 個節點的父鏈接指向第 2 個節點一樣。
鏈接計數中有一個小例外。根節點 2 的鏈接數為 4,但圖 4-10 只顯示了三個目錄條目鏈接。第四個 "鏈接位於文件系統的超級塊中,因為超級塊會告訴你在哪裏可以找到根節點。
不要害怕在你的系統上做實驗。創建一個目錄結構,然後使用 ls -i 或 stat 來瀏覽各個部分是無害的。你不需要是 root 用户(除非你掛載並創建了一個新的文件系統)。
4.6.2 塊分配
我們的討論還缺少一個部分。在為新文件分配數據池區塊時,文件系統如何知道哪些區塊正在使用,哪些是可用的?最基本的方法之一是使用一種名為 “塊位圖 ”的附加管理數據結構。在這種方案中,文件系統保留一系列字節,每一位對應數據池中的一個區塊。值為 0 表示該數據塊是空閒的,值為 1 表示該數據塊正在使用中。因此,分配和取消分配區塊就是一個比特翻轉的問題。
當 inode 表數據與塊分配數據不匹配或鏈接計數不正確時,文件系統就會出現問題;例如,當你沒有乾淨利落地關閉系統時就會出現這種情況。因此,如第 4.2.11 節所述,檢查文件系統時,fsck 程序會遍歷 inode 表和目錄結構,生成新的鏈接計數和新的塊分配映射(如塊位圖),然後將新生成的數據與磁盤上的文件系統進行比較。如果出現不匹配,fsck 必須修復鏈接計數,並決定如何處理在遍歷目錄結構時沒有出現的任何節點和/或數據。大多數 fsck 程序會將這些 “孤兒 ”變成文件系統丟失+找到目錄中的新文件。
4.6.3 在用户空間中處理文件系統
在用户空間中處理文件和目錄時,不必太擔心它們下面的執行情況。進程應通過內核系統調用訪問已掛載文件系統的文件和目錄內容。但奇怪的是,你確實可以訪問某些似乎不適合在用户空間中訪問的文件系統信息,特別是 stat() 系統調用會返回 inode 編號和鏈接計數。
當你不維護文件系統時,是否需要擔心 inode 編號、鏈接計數和其他執行細節?一般來説,不需要。用户模式程序可以訪問這些內容主要是為了向後兼容。此外,並非所有 Linux 中的文件系統都有這些文件系統內部結構。VFS 接口層可確保系統調用總是返回 inode 編號和鏈接計數,但這些數字並不一定意味着什麼。
你可能無法在非傳統文件系統上執行傳統的 Unix 文件系統操作。例如,你無法使用 ln 在掛載的 VFAT 文件系統上創建硬鏈接,因為它的目錄條目結構是為 Windows 而不是 Unix/Linux 設計的,不支持這一概念。
幸運的是,Linux 系統上用户空間可用的系統調用提供了足夠的抽象性,可以讓你輕鬆訪問文件--你不需要知道任何底層實現,就能訪問文件。此外,文件名格式靈活,還支持混合大小寫,因此很容易支持其他分層式文件系統。
請記住,特定的文件系統支持並不一定需要在內核中提供。例如,在用户空間文件系統中,內核只需充當系統調用的通道。