

(<center>Java 大視界 -- Java 大數據機器學習模型在生物信息學基因功能預測中的優化與應用</center>)
引言:
嘿,親愛的 Java 和 大數據愛好者們,大家好!我是CSDN(全區域)四榜榜首青雲交!而今天,我們將踏入一個全新的領域 —— 生物信息學,在這裏,Java 大數據與機器學習模型將碰撞出怎樣的火花,又將如何助力人類破解基因的奧秘?讓我們帶着滿滿的好奇,開啓這場奇妙的探索之旅。

正文:
一、生物信息學中基因功能預測的背景與挑戰
1.1 基因功能預測:生命科學的 “核心拼圖”
在生命科學的宏大版圖中,基因功能預測無疑是最為關鍵的一塊拼圖。在醫學領域,癌症一直是人類健康的重大威脅。據世界衞生組織數據顯示,全球每年新增癌症病例超 1900 萬例,而傳統治療手段的平均有效率僅約 40%。通過精準的基因功能預測,科學家能夠找到癌細胞的 “命門”,開發出靶向治療藥物,部分癌症患者的治療有效率因此提升至 65% 以上。
在農業領域,我國作為農業大國,糧食安全至關重要。以水稻為例,通過基因功能預測培育出的抗病蟲害、耐鹽鹼水稻新品種,平均每畝可增產 10%-15%。這不僅能保障糧食供應,還能減少農藥使用,保護生態環境。由此可見,基因功能預測對人類社會的發展具有不可估量的價值。
1.2 傳統方法的 “困境與掙扎”
傳統的基因功能預測方法主要有基於序列相似性的方法和基於實驗的方法。基於序列相似性的方法,就像是通過外貌來判斷一個人的能力,當基因序列相似度低於 30% 時,預測準確率會大幅下降,甚至不足 50%。而基於實驗的方法,如基因敲除實驗,雖然結果較為準確,但面臨着諸多難題。它不僅耗時漫長,單次實驗平均需要 8-12 個月,成本也十分高昂,每次實驗耗費約 30-50 萬美元。此外,由於物種間的基因差異,實驗結果在臨牀轉化時成功率不足 10%,就像在黑暗中摸索,效率低且充滿不確定性。
二、Java 大數據與機器學習模型的 “黃金搭檔” 優勢
2.1 Java 大數據:基因數據處理的 “超級引擎”
Java 憑藉其獨特的優勢,成為基因數據處理的理想選擇。在數據採集環節,Java 通過 Socket 編程與生物傳感器實現實時交互,能夠以每秒萬級的速度採集基因數據。其強大的多線程處理能力,可將數據處理效率提升 3-5 倍。下面是一個基於 Java 多線程與 Hadoop 分佈式文件系統(HDFS)的數據讀取與預處理的完整代碼示例,代碼中包含了詳細的註釋,幫助大家更好地理解每一步操作:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
// 定義基因數據預處理任務類,實現Callable接口以便獲取任務執行結果
class GeneDataPreprocessor implements Callable<String> {
private String filePath;
public GeneDataPreprocessor(String filePath) {
this.filePath = filePath;
}
@Override
public String call() throws IOException {
// 加載Hadoop配置
Configuration conf = new Configuration();
// 獲取HDFS文件系統實例
FileSystem fs = FileSystem.get(conf);
// 創建文件路徑對象
Path path = new Path(filePath);
// 打開文件輸入流
FSDataInputStream in = fs.open(path);
// 使用BufferedReader讀取文件內容
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
StringBuilder processedData = new StringBuilder();
String line;
while ((line = reader.readLine()) != null) {
// 數據清洗:去除空行和不符合DNA序列規範的數據
if (!line.isEmpty() && line.matches("^[ATCG]+$")) {
processedData.append(line).append("\n");
}
}
reader.close();
in.close();
fs.close();
return processedData.toString();
}
}
public class GeneDataProcessing {
public static void main(String[] args) {
String[] filePaths = {
"hdfs://master:9000/gene_data/data1.fasta",
"hdfs://master:9000/gene_data/data2.fasta",
"hdfs://master:9000/gene_data/data3.fasta"
};
// 創建線程池,設置線程數量為3
ExecutorService executor = Executors.newFixedThreadPool(3);
List<Future<String>> futures = new ArrayList<>();
for (String filePath : filePaths) {
GeneDataPreprocessor processor = new GeneDataPreprocessor(filePath);
// 提交任務到線程池,並獲取任務執行結果的Future對象
Future<String> future = executor.submit(processor);
futures.add(future);
}
for (Future<String> future : futures) {
try {
System.out.println(future.get());
} catch (Exception e) {
e.printStackTrace();
}
}
executor.shutdown();
}
}
上述代碼實現了從 HDFS 中讀取基因數據文件,並通過多線程並行處理,對原始基因序列數據進行清洗,只保留符合 DNA 序列規範的數據。
2.2 機器學習模型:基因功能預測的 “智慧大腦”
機器學習模型能夠從海量的基因數據中挖掘出隱藏的規律和模式。以深度學習模型為例,通過構建多層卷積神經網絡(CNN),可以自動提取基因序列的特徵。下面通過一個簡單的基因功能預測 CNN 模型架構圖,幫助大家更直觀地理解模型結構:
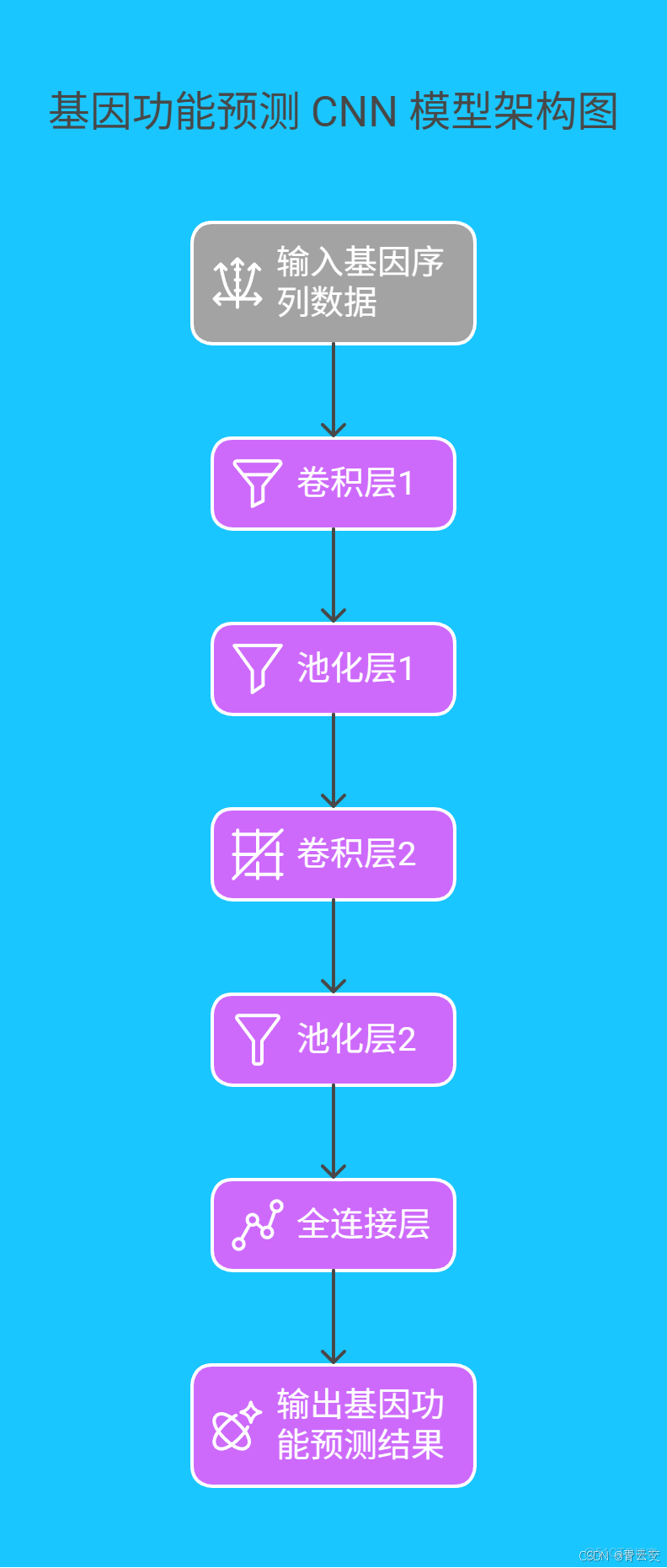
在實際訓練過程中,通過反向傳播算法不斷調整模型參數,以提高預測準確率。在公開的酵母基因數據集測試中,基於 CNN 的預測模型準確率可達 85% 以上,遠超傳統預測方法。
為了讓大家更清楚地瞭解不同機器學習模型在基因功能預測中的性能差異,下面通過一個表格進行對比:
| 模型類型 | 準確率(酵母基因數據集) | 訓練時間(小時) | 優勢 | 劣勢 |
|---|---|---|---|---|
| 基於序列相似性 | 50% | - | 簡單直觀 | 準確率低,依賴相似基因庫 |
| 支持向量機(SVM) | 82% | 12 | 適合小樣本,泛化能力強 | 核函數選擇困難 |
| 卷積神經網絡(CNN) | 85% | 20 | 自動提取特徵,準確率高 | 訓練時間長,參數多 |
| 遞歸神經網絡(RNN) | 83% | 18 | 適合處理序列數據 | 容易出現梯度消失 / 爆炸 |
三、Java 大數據機器學習模型的經典應用案例
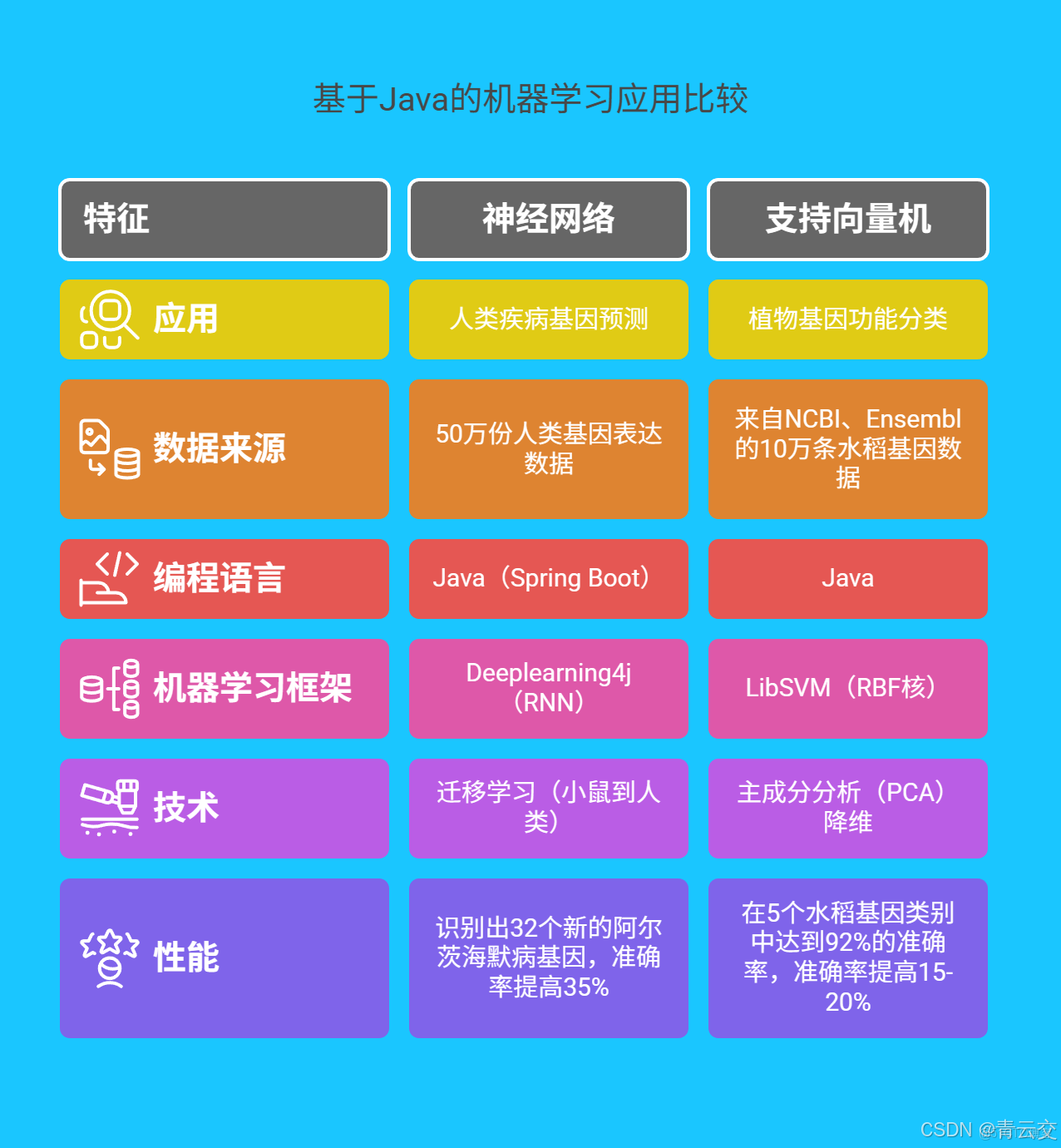
3.1 神經網絡在人類疾病基因預測中的 “精準狙擊”
美國某頂尖科研團隊利用 Java 開發了一套基於深度學習的基因功能預測系統。他們整合了來自全球的 50 萬份人類基因表達數據,涵蓋 20 餘種常見疾病。系統採用 Java Spring Boot 框架搭建後端服務,通過 Deeplearning4j(基於 Java 的深度學習框架)構建多層遞歸神經網絡(RNN)模型。
在訓練過程中,研究人員採用遷移學習策略,將在小鼠基因數據上預訓練的模型參數,遷移到人類基因數據訓練中,這一策略使訓練時間縮短了 40%。經過 3 個月的迭代優化,該模型成功識別出 32 個與阿爾茨海默病相關的新基因,為疾病的早期診斷和治療提供了全新的靶點。與傳統方法相比,該模型在相同數據集上的準確率提升了 35%,充分展現了 Java 大數據與機器學習結合的強大威力。
3.2 支持向量機(SVM)在植物基因功能分類中的 “智慧分揀”
我國農業科學院的研究團隊針對水稻基因功能分類難題,運用 Java 和 SVM 模型展開研究。他們首先使用 Java 編寫爬蟲程序,從 NCBI、Ensembl 等權威生物數據庫中採集了 10 萬條水稻基因數據。然後通過主成分分析(PCA)算法,利用 Java 實現數據降維,將基因數據的特徵維度從 500 維降至 50 維,大幅提高了數據處理效率。
基於 LibSVM 庫(Java 版本)構建 SVM 分類模型,研究人員對不同的核函數進行了大量實驗。最終發現,採用徑向基函數(RBF)作為核函數時,模型性能最佳。經過反覆調參優化,該模型在水稻抗病基因、抗逆基因等 5 個功能類別的分類準確率達到 92%,為水稻育種提供了精準的基因篩選工具。與其他傳統分類算法相比,SVM 模型在分類準確率上提高了 15% - 20%。
四、Java 大數據機器學習模型面臨的挑戰與破局之道
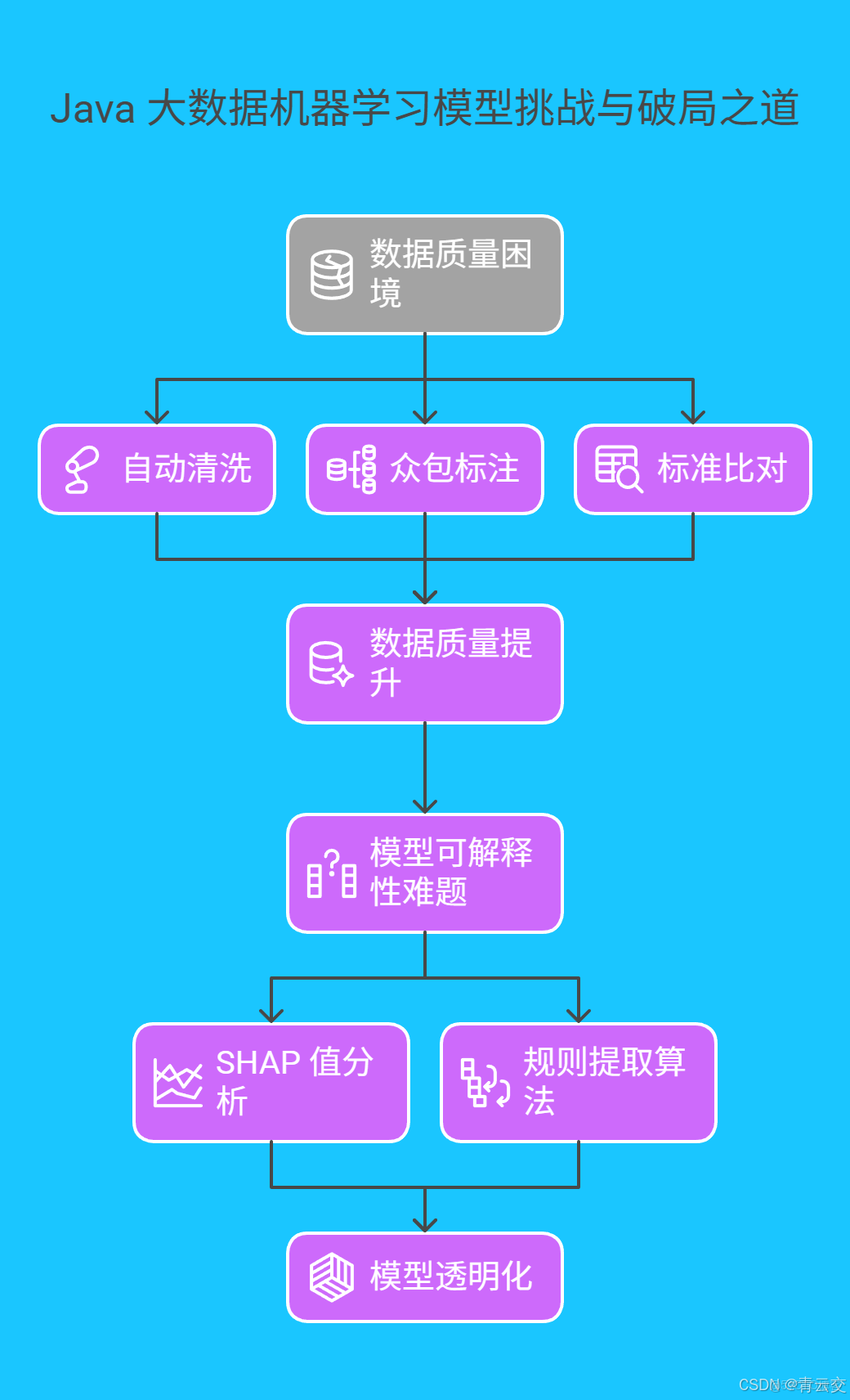
4.1 數據質量困境與 “淨化方案”
生物信息學數據存在着 “噪聲大、標註亂” 的問題。據統計,公共基因數據庫中約 20% 的數據存在錯誤標註。為了解決這一問題,我們可以採用 “三重校驗” 機制:
- 自動清洗:利用 Java 編寫數據清洗腳本,通過正則表達式和統計分析,自動過濾異常數據。例如,使用正則表達式匹配 DNA 序列規範,剔除不符合格式的數據。
- 眾包標註:引入眾包標註模式,發動全球科研人員參與數據標註。通過設置獎勵機制,提高標註的準確性和效率。
- 標準比對:建立權威的基因功能標註標準庫,通過餘弦相似度算法比對新數據與標準庫的匹配度,確保標註的準確性。
4.2 模型可解釋性難題與 “透明化探索”
機器學習模型的 “黑盒” 特性,使得科研人員難以理解預測結果的依據。目前,研究人員嘗試了多種方法來破解這一難題。其中,SHAP(SHapley Additive exPlanations)值分析是一種有效的手段,它可以量化每個基因特徵對預測結果的貢獻度。我們使用 Java 編寫可視化程序,將 SHAP 值以熱力圖的形式展示出來,使模型的決策過程一目瞭然。
此外,還可以開發基於規則提取的可解釋性算法,從複雜的模型中提取出人類可理解的規則。例如,“當基因 A 表達量高於閾值,且基因 B 存在特定突變時,該基因具有疾病相關功能”。通過這些方法,逐步揭開機器學習模型的神秘面紗,讓其預測結果更加可信和可解釋。
結束語:
親愛的 Java 和 大數據愛好者,在生物信息學這片充滿未知與挑戰的領域,Java 大數據與機器學習模型攜手共進,為基因功能預測帶來了新的曙光。從數據處理的 “千頭萬緒” 到模型預測的 “抽絲剝繭”,再到挑戰應對的 “迎難而上”,每一個環節都凝聚着技術的智慧與創新的力量。
親愛的 Java 和 大數據愛好者,在你看來,Java 大數據與機器學習模型的結合,還能在生物信息學的哪些細分領域發揮更大的作用?或者在實際應用過程中,你遇到過哪些有趣的問題和解決方案?歡迎大家在評論區分享你的見解!
為了讓後續內容更貼合大家的需求,誠邀各位參與投票,對於 Java 大數據機器學習模型在生物信息學的應用,你最感興趣的是哪個方面?快來投出你的寶貴一票,點此鏈接投票 。