

(<center>Java 大視界 -- 基於 Java 的大數據實時流處理在工業自動化生產線能源優化中的應用與實踐</center>)
引言:
嘿,親愛的 Java 和 大數據愛好者們,大家好!我是CSDN(全區域)四榜榜首青雲交!在珠三角某新能源汽車製造基地,深夜的生產車間依然燈火通明。隨着衝壓機的每一次起落,智能電錶的讀數以毫秒級頻率刷新,基於 Java 構建的實時流處理系統正以每秒處理 2 萬條數據的速度,實時分析着整個生產線的能耗狀態。突然,系統捕捉到焊接機器人的瞬時電流異常波動,0.3 秒內完成根因分析,並聯動 PLC 控制器動態調整焊接參數,成功避免一次因設備過載導致的能源浪費。工業和信息化部《2024 年工業能效提升行動計劃》指出,我國規模以上工業企業單位增加值能耗較發達國家仍高出 40%,而通過大數據實時優化,可使生產線綜合能耗降低 20%-30%。Java 憑藉其強大的高併發處理能力、跨平台兼容性以及豐富的開源生態,成為工業能源優化領域的核心技術支撐。某全球汽車製造巨頭引入基於 Java 的能源管理系統後,年度電費支出從 6.2 億元鋭減至 4.5 億元,用代碼書寫着工業節能的新篇章。

正文:
在 “雙碳” 目標與工業 4.0 戰略的雙重驅動下,工業自動化生產線正面臨着能源效率低下、浪費嚴重等痛點。傳統能源管理系統因數據處理滯後、分析模型粗放,難以滿足實時優化需求。Java 與大數據實時流處理技術的深度融合,為工業能源優化開闢了新路徑。本文將結合西門子、富士康等行業標杆案例,從數據採集、實時分析到策略執行,全面解析 Java 在工業能源優化領域的全棧技術實踐。
一、工業自動化生產線能源數據特徵與核心挑戰
1.1 能源數據的多維複雜性
工業生產線能源數據呈現 “五多三高” 特性,構建起復雜的數據生態體系:
| 維度 | 具體表現 | 典型應用場景 |
|---|---|---|
| 多源性 | 涵蓋智能電錶、傳感器、PLC 控制器、DCS 系統、設備日誌等 15 + 類數據源 | 數控機牀能耗實時監測 |
| 多態性 | 包含時序數據(電流、電壓、頻率)、結構化數據(設備運行參數)、非結構化數據(報警信息) | 噴塗機器人作業狀態監控 |
| 多尺度性 | 時間尺度從毫秒級設備脈衝信號到年度能耗報表,空間尺度覆蓋單台設備到全廠能源網絡 | 生產線全週期能耗分析 |
| 多關聯性 | 與生產計劃、設備健康度、環境温濕度、物料供應等 30 + 因素深度耦合 | 環境温度對製冷系統能耗的影響分析 |
| 多模態性 | 融合數字信號、模擬信號、圖像數據(如熱成像)等多種數據模態 | 設備熱損耗可視化分析 |
| 高實時性 | 需在 100ms 內完成異常能耗數據響應與優化策略下發 | 設備過載預警與自動調節 |
| 高精度性 | 能耗計量誤差需控制在 ±0.2% 以內,滿足成本核算與碳足跡精準追蹤要求 | 碳排放量精細化核算 |
| 高動態性 | 數據產生頻率最高可達 20kHz,隨生產節奏劇烈波動 | 衝壓設備週期性啓停能耗變化監測 |
1.2 能源優化的核心技術挑戰
工業能源優化需突破六大核心技術瓶頸,形成如下挑戰與解決方案矩陣:
| 挑戰維度 | 具體難題 | 技術應對方案 |
|---|---|---|
| 數據處理 | 每秒處理 10 萬級異構數據的同時保證計算精度 | Flink 狀態管理 + 滑動窗口聚合算法 |
| 實時決策 | 從數據採集到策略執行全鏈路延遲<300ms | 邊緣計算 + 內存計算技術 |
| 多系統協同 | 打通 EMS、MES、DCS 等異構系統的數據壁壘 | 工業互聯網協議適配層(OPC UA/MQTT) |
| 複雜工況適配 | 適應 24 小時不間斷、多批次切換、多設備聯動的複雜生產環境 | 強化學習動態策略優化 |
| 安全可靠 | 滿足工業級系統 99.999% 的可用性要求 | Kafka 集羣 + Flink Checkpoint 機制 |
| 成本控制 | 在提升能效的同時控制 IT 系統建設與運維成本 | 容器化部署 + 彈性資源調度 |

二、基於 Java 的實時流處理技術架構設計
2.1 分層技術架構解析
採用 “感知層 - 邊緣層 - 平台層 - 應用層” 四層架構,構建工業能源優化的數字底座:

2.2 核心技術深度實踐
2.2.1 工業數據實時採集與預處理
使用 Java 編寫邊緣端採集程序,實現多協議融合接入與數據預處理:
import com.serotonin.modbus4j.ModbusFactory;
import com.serotonin.modbus4j.ModbusMaster;
import com.serotonin.modbus4j.code.DataType;
import com.serotonin.modbus4j.exception.ErrorResponseException;
import com.serotonin.modbus4j.exception.ModbusInitException;
import com.serotonin.modbus4j.exception.ModbusTransportException;
import com.serotonin.modbus4j.ip.IpParameters;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class ModbusDataCollector {
private static final String HOST = "192.168.1.100";
private static final int PORT = 502;
private static final int SLAVE_ID = 1;
public static void main(String[] args) {
IpParameters ipParameters = new IpParameters();
ipParameters.setHost(HOST);
ipParameters.setPort(PORT);
ModbusFactory modbusFactory = new ModbusFactory();
try (ModbusMaster master = modbusFactory.createTcpMaster(ipParameters)) {
master.init();
// 讀取保持寄存器中的電壓數據(示例地址0)
int voltage = master.getValue(SLAVE_ID, DataType.HOLDING_REGISTER, 0, 1)[0];
// 讀取電流數據(示例地址1)
int current = master.getValue(SLAVE_ID, DataType.HOLDING_REGISTER, 1, 1)[0];
// 計算功率(簡化公式:P=UI)
double power = voltage * current;
EnergyData data = new EnergyData(System.currentTimeMillis(), "device001", power);
sendToKafka(data);
} catch (ModbusInitException | ModbusTransportException | ErrorResponseException e) {
e.printStackTrace();
}
}
private static void sendToKafka(EnergyData data) {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "com.example.EnergyDataSerializer");
try (KafkaProducer<String, EnergyData> producer = new KafkaProducer<>(props)) {
ProducerRecord<String, EnergyData> record = new ProducerRecord<>("energy-topic", data.getDeviceId(), data);
producer.send(record);
}
}
static class EnergyData {
private long timestamp;
private String deviceId;
private double power;
public EnergyData(long timestamp, String deviceId, double power) {
this.timestamp = timestamp;
this.deviceId = deviceId;
this.power = power;
}
// Getter/Setter方法
public long getTimestamp() {
return timestamp;
}
public String getDeviceId() {
return deviceId;
}
public double getPower() {
return power;
}
}
}
2.2.2 實時能耗分析與智能決策
基於 Flink 實現複雜事件處理與動態策略優化:
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
public class EnergyOptimization {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<EnergyData> energyStream = env.addSource(new KafkaSource<>("energy-topic"));
// 計算5分鐘內設備平均功率
DataStream<Tuple2<String, Double>> avgPowerStream = energyStream
.keyBy(EnergyData::getDeviceId)
.timeWindow(Time.minutes(5))
.aggregate(new PowerAverageAggregator());
// 檢測能耗異常(超過歷史均值130%)
DataStream<EnergyData> anomalyStream = avgPowerStream
.connect(energyStream)
.process(new AnomalyDetectionProcessFunction());
// 觸發能源優化策略
anomalyStream.process(new EnergyOptimizationProcessFunction());
env.execute("Industrial Energy Optimization");
}
// 自定義聚合函數計算平均功率
static class PowerAverageAggregator implements AggregateFunction<EnergyData, Tuple2<Long, Double>, Double> {
@Override
public Tuple2<Long, Double> createAccumulator() {
return Tuple2.of(0L, 0.0);
}
@Override
public Tuple2<Long, Double> add(EnergyData value, Tuple2<Long, Double> accumulator) {
return Tuple2.of(accumulator.f0 + 1, accumulator.f1 + value.getPower());
}
@Override
public Double getResult(Tuple2<Long, Double> accumulator) {
return accumulator.f1 / accumulator.f0;
}
@Override
public Tuple2<Long, Double> merge(Tuple2<Long, Double> a, Tuple2<Long, Double> b) {
return Tuple2.of(a.f0 + b.f0, a.f1 + b.f1);
}
}
// 異常檢測函數(簡化示例)
static class AnomalyDetectionProcessFunction extends ProcessFunction<Tuple2<String, Double>, EnergyData> {
@Override
public void processElement(Tuple2<String, Double> avgPower, Context ctx, Collector<EnergyData> out) {
String deviceId = avgPower.f0;
double currentAvgPower = avgPower.f1;
// 假設從HBase獲取歷史均值(簡化邏輯)
double historicalAvgPower = getHistoricalAvgPower(deviceId);
if (currentAvgPower > historicalAvgPower * 1.3) {
// 輸出異常數據
out.collect(new EnergyData(System.currentTimeMillis(), deviceId, currentAvgPower));
}
}
private double getHistoricalAvgPower(String deviceId) {
// 實際需從HBase查詢
return 0.0;
}
}
// 能源優化策略執行函數(簡化示例)
static class EnergyOptimizationProcessFunction extends ProcessFunction<EnergyData, Void> {
@Override
public void processElement(EnergyData data, Context ctx, Collector<Void> out) {
String deviceId = data.getDeviceId();
double power = data.getPower();
// 調用優化策略(如調整設備參數)
executeOptimizationStrategy(deviceId, power);
}
private void executeOptimizationStrategy(String deviceId, double power) {
// 實際需調用微服務接口控制設備
}
}
}
三、行業標杆案例深度拆解
3.1 西門子安貝格數字化工廠實踐
作為全球工業 4.0 樣板工廠,西門子安貝格的能源優化方案具有里程碑意義:
- 技術架構:
- 部署 Flink 集羣處理每秒 8000 + 條設備數據
- 構建數字孿生模型實現能耗預測
- 採用強化學習算法動態調節生產線功率分配
- 實施效果:
- 生產線綜合能耗降低 22.3%(數據來源:西門子 2024 年報)
- 設備待機能耗減少 41%
- 年節省電費 1500 萬歐元
- 碳排放強度下降 19%
3.2 富士康精密製造能源優化工程
在深圳龍華園區的精密製造車間,Java 技術創造了驚人效益:
| 優化維度 | 優化前 | 優化後 | 核心技術應用 |
|---|---|---|---|
| 注塑機能耗 | 352 kWh / 小時 | 278 kWh / 小時 | Flink 實時負載預測 + 動態調頻技術 |
| 空壓系統能耗 | 210 kWh / 小時 | 155 kWh / 小時 | 基於強化學習的壓力協同控制算法 |
| AGV 物流系統 | 85 kWh / 天 | 62 kWh / 天 | 路徑優化與能源回收策略 |
| 全廠綜合能耗 | - | 降低 25.6% | 多系統數據融合 + 智能決策引擎 |
| 能源管理效率 | 人工巡檢為主 | 自動化率 98% | 實時監控 + 智能預警 + 自動調節 |
四、系統可靠性與擴展性保障體系
4.1 高可用架構設計
構建 “雙活集羣 + 異地容災” 的高可靠架構:
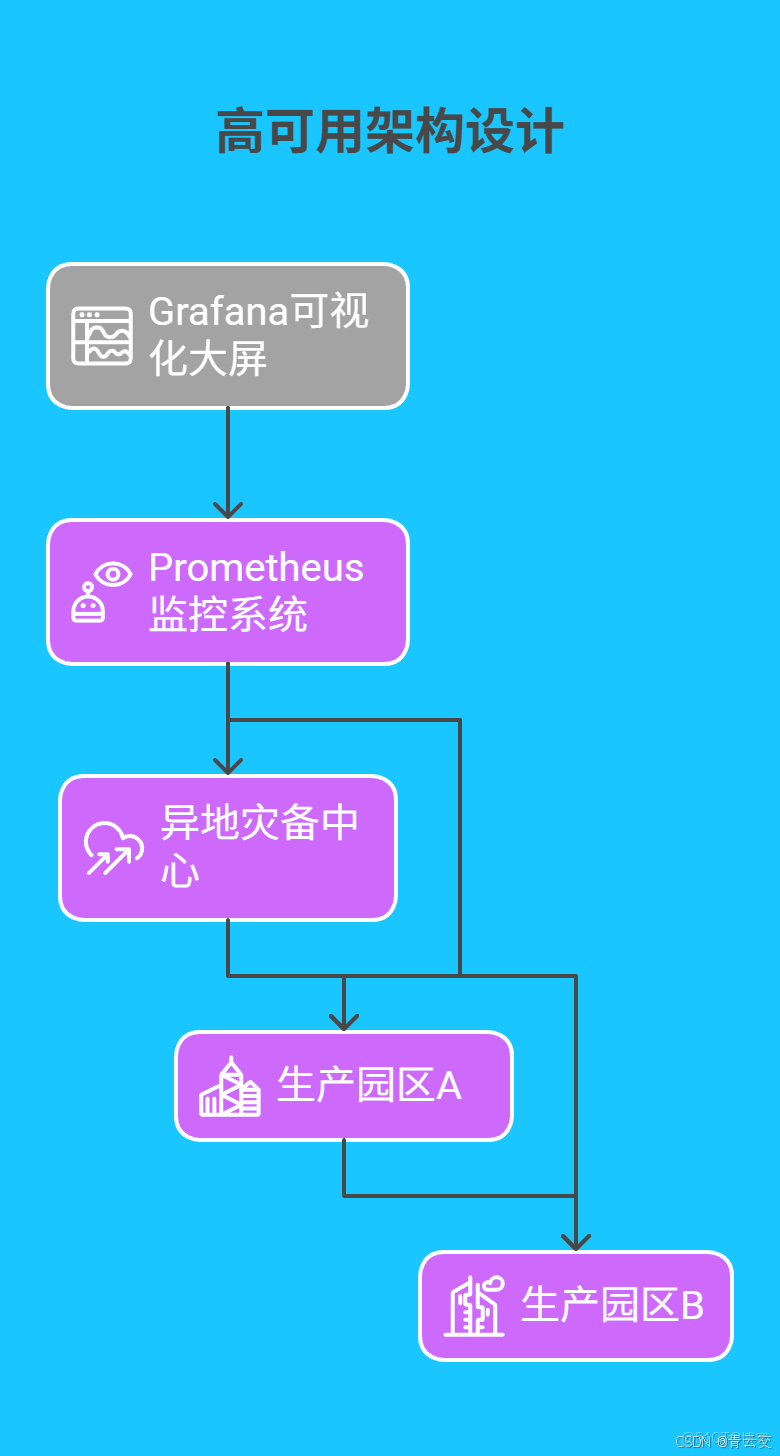
4.2 彈性資源調度策略
基於 Kubernetes 實現動態資源管理:
- 水平自動擴縮容:當 Flink 任務延遲超過 80ms 時,自動新增 3 個 TaskManager 實例
- 垂直資源調整:非生產高峯時段,將集羣資源利用率從 75% 降至 40%
- 優先級調度:保障實時分析任務的 CPU 搶佔優先級高於離線計算任務
- 智能熔斷機制:當系統負載超過閾值時,自動暫停非關鍵業務數據處理
結束語:
親愛的 Java 和 大數據愛好者們,在工業自動化的浪潮中,Java 編寫的代碼如同精密的數字引擎,驅動着工業生產線向綠色、智能邁進。從設備參數的精準調節,到全廠能源的智能調度,每一行代碼的背後,都是對工業能效提升的不懈追求。作為一名深耕工業互聯網領域十餘年的技術從業者,我始終堅信:代碼不僅能改變生產方式,更能重塑工業未來。
親愛的 Java 和 大數據愛好者,在工業能源優化項目中,您認為最難攻克的技術難點是什麼?是多源數據融合、實時算法優化,還是系統穩定性保障?歡迎大家在評論區分享你的見解!
為了讓後續內容更貼合大家的需求,誠邀各位參與投票,下一篇文章,你希望瞭解 Java 在哪個工業場景的深度應用?快來投出你的寶貴一票 。