

(<center>Java 大視界 -- 基於 Java 的大數據可視化在城市空氣質量監測與污染溯源中的應用</center>)
引言:
嘿,親愛的 Java 和 大數據愛好者們,大家好!我是CSDN(全區域)四榜榜首青雲交!在《大數據新視界》和《 Java 大視界》專欄的技術探索之旅中,我們曾以 Java 大數據為筆,在醫療、家居、農業等領域繪就創新藍圖。Java 大數據不斷突破技術邊界,重塑行業發展格局。如今,當城市空氣質量成為全民關注的焦點,這項技術又將如何化身 “數字環保衞士”,通過可視化手段揭開污染的神秘面紗?讓我們一同深入探索!

正文:
一、城市空氣質量監測與污染溯源的現狀與挑戰
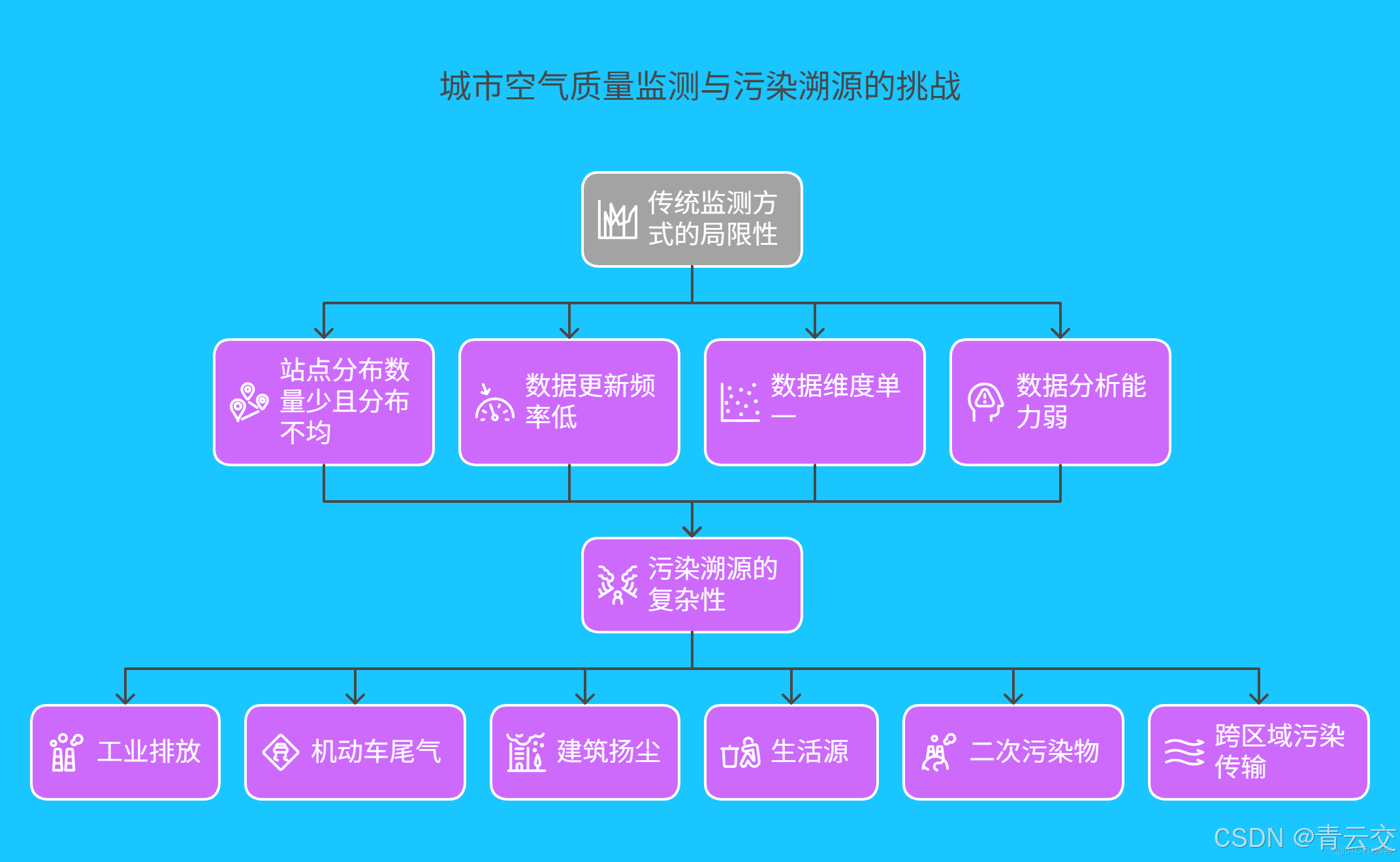
1.1 傳統監測方式的侷限性
傳統空氣質量監測體系猶如一張漏洞百出的網,難以滿足現代城市的監測需求。根據生態環境部 2023 年公開數據顯示,我國部分中小城市每千平方公里僅配備 0.3 個監測站點,大量工業園區、城鄉結合部成為監測盲區。例如,某工業城市因站點覆蓋不足,化工廠夜間偷排廢氣長達 6 小時才被發現,導致周邊居民出現呼吸道不適症狀後才啓動應急響應。此外,傳統監測手段的數據更新頻率極低,多數以小時甚至天為單位,在突發污染事件中,根本無法為應急決策提供及時有效的數據支持。
| 指標 | 傳統監測方式 | 存在問題 |
|---|---|---|
| 站點分佈 | 數量少且分佈不均 | 大量區域無法覆蓋,存在監測盲區 |
| 數據更新頻率 | 以小時或天為單位 | 無法滿足實時監測需求,應急響應滯後 |
| 數據維度 | 單一污染物濃度數據為主 | 難以進行多因素綜合分析,溯源能力弱 |
| 數據分析能力 | 依賴人工經驗 | 效率低,難以發現潛在規律和趨勢 |
1.2 污染溯源的複雜性
城市空氣污染成因錯綜複雜,工業排放、機動車尾氣、建築揚塵、生活源等污染源相互交織,且污染物在大氣中還會發生複雜的物理化學反應,生成二次污染物,進一步增加了溯源難度。以某沿海城市為例,夏季頻繁出現的臭氧超標問題,起初被認為是機動車尾氣所致,後經大數據深度分析發現,周邊石化企業排放的揮發性有機物(VOCs)與氮氧化物在光照條件下發生反應才是真正元兇。更棘手的是跨區域污染傳輸問題,北方某城市冬季霧霾中,竟有 30% 的污染物來自 500 公里外的燃煤電廠,這讓傳統監測手段束手無策。
二、Java 大數據可視化技術基礎
2.1 多源數據採集與整合
Java 憑藉其強大的網絡編程能力和豐富的開源生態,成為空氣質量數據採集的不二之選。我們通過 RESTful API 獲取氣象數據,利用 WebSocket 實時接收傳感器數據,並將數據存儲到 Hive 數據倉庫。
2.1.1 氣象數據採集(使用 HttpClient)
import java.io.IOException;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
// 氣象數據採集類
public class WeatherDataCollector {
// 主方法
public static void main(String[] args) {
// 創建HttpClient實例,用於發送HTTP請求
HttpClient client = HttpClient.newHttpClient();
// 替換為實際可用的氣象數據API地址,這裏使用示例地址
URI uri = URI.create("https://api.weather.com/data");
// 構建GET請求
HttpRequest request = HttpRequest.newBuilder()
.uri(uri)
.build();
try {
// 發送請求並獲取響應,響應體以字符串形式獲取
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println("氣象數據: " + response.body());
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
}
2.1.2 空氣質量傳感器數據實時接收(使用 WebSocket)
import javax.websocket.*;
import javax.websocket.server.ServerEndpoint;
import java.io.IOException;
// WebSocket端點類,處理空氣質量數據流
@ServerEndpoint("/air-quality-stream")
public class AirQualityEndpoint {
// 連接建立時的回調方法
@OnOpen
public void onOpen(Session session) {
System.out.println("空氣質量數據流連接已建立");
}
// 接收到消息時的回調方法
@OnMessage
public void onMessage(String message, Session session) throws IOException {
// 這裏可以添加數據解析邏輯,例如將JSON字符串轉換為Java對象
System.out.println("接收到空氣質量數據: " + message);
session.getBasicRemote().sendText("數據已接收");
}
// 連接關閉時的回調方法
@OnClose
public void onClose(Session session) {
System.out.println("數據流連接已關閉");
}
}
2.1.3 Hive 數據倉庫建表語句
-- 創建空氣質量信息表
CREATE TABLE air_quality_info (
sensor_id string COMMENT '傳感器編號',
collect_time timestamp COMMENT '採集時間',
pm25 double COMMENT 'PM2.5濃度',
pm10 double COMMENT 'PM10濃度',
so2 double COMMENT '二氧化硫濃度',
no2 double COMMENT '二氧化氮濃度',
o3 double COMMENT '臭氧濃度',
co double COMMENT '一氧化碳濃度',
temperature double COMMENT '温度',
humidity double COMMENT '濕度',
wind_speed double COMMENT '風速',
wind_direction string COMMENT '風向'
)
-- 按城市名稱和日期進行分區
PARTITIONED BY (city_name string, data_date string)
-- 使用ORC格式存儲
STOED AS ORC
TBLPROPERTIES (
"orc.compress"="SNAPPY",
"description"="城市空氣質量與氣象數據表"
);
2.2 大數據處理框架的協同應用
Apache Spark 和 Apache Flink 在空氣質量數據分析中發揮着核心作用,二者分工協作,形成強大的數據處理能力。
2.2.1 Spark 批量數據分析
-- 統計某城市2024年每月PM2.5平均濃度
SELECT
MONTH(collect_time) AS month,
AVG(pm25) AS avg_pm25
FROM
air_quality_info
WHERE
city_name = 'Beijing'
GROUP BY
MONTH(collect_time);
2.2.2 Flink 實時監測預警
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
// 空氣質量預警類
public class AirQualityAlarm {
// 主方法
public static void main(String[] args) throws Exception {
// 創建流處理執行環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 創建Table環境,用於執行SQL查詢
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// 添加數據源,這裏假設AirQualitySource為自定義的數據源類
DataStream<AirQualityData> stream = env.addSource(new AirQualitySource());
Table table = tEnv.fromDataStream(stream);
// 使用SQL查詢找出PM2.5或臭氧濃度超標的數據
Table alertTable = tEnv.sqlQuery("SELECT * FROM " +
table +
" WHERE pm25 > 75 OR o3 > 160");
// 將查詢結果轉換為流並打印輸出,用於預警展示
tEnv.toRetractStream(alertTable, AirQualityData.class).print();
// 執行流處理作業
env.execute("Air Quality Alarm System");
}
}
// 空氣質量數據實體類
class AirQualityData {
private String sensorId;
private double pm25;
private double o3;
// 省略其他屬性及getter和setter方法
}
三、大數據可視化核心技術
3.1 地理信息系統(GIS)融合
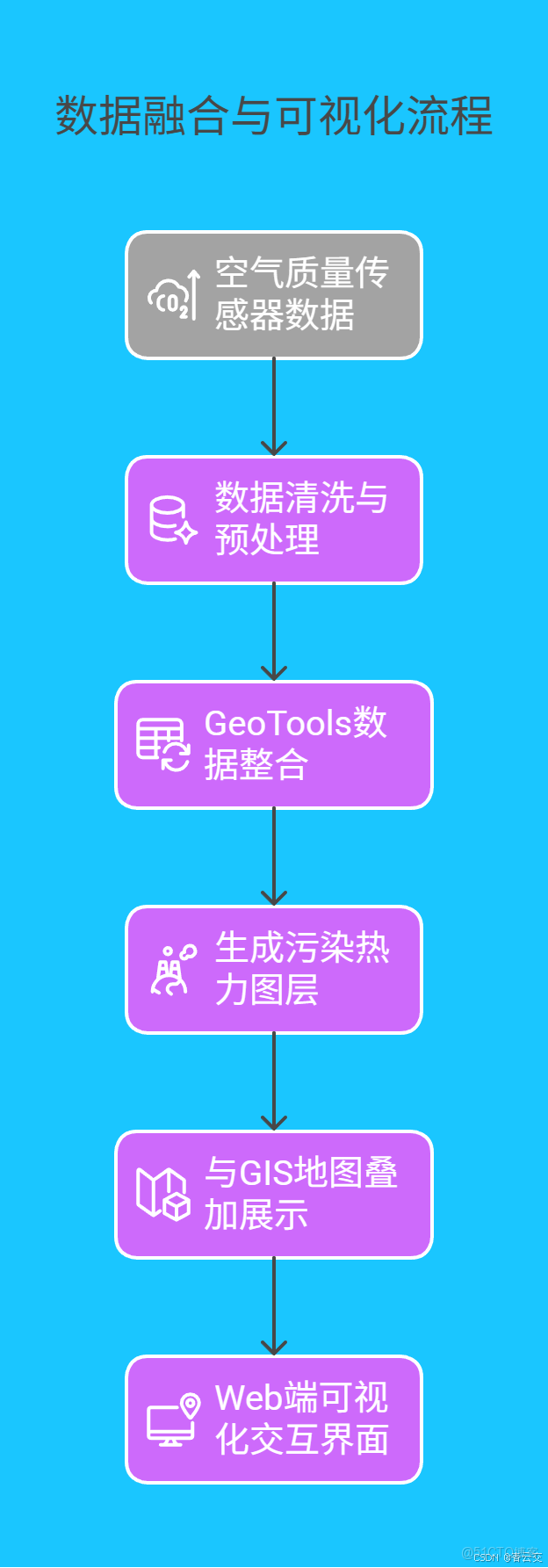
藉助 Java 的 GeoTools 庫,我們可以將空氣質量數據與地理信息深度融合,直觀展示污染分佈情況。
import org.geotools.data.DataStore;
import org.geotools.data.DataStoreFinder;
import org.geotools.data.simple.SimpleFeatureCollection;
import org.geotools.data.simple.SimpleFeatureSource;
import org.geotools.map.FeatureLayer;
import org.geotools.map.Layer;
import org.geotools.map.MapContent;
import org.geotools.styling.SLD;
import org.geotools.styling.Style;
import org.opengis.feature.Feature;
import java.io.File;
import java.util.HashMap;
import java.util.Map;
// 空氣質量GIS可視化類
public class AirQualityGISVisual {
// 主方法
public static void main(String[] args) throws Exception {
// 加載Shapefile格式的地圖數據文件
File file = new File("city_map.shp");
Map<String, Object> map = new HashMap<>();
map.put("url", file.toURI().toURL());
// 通過DataStoreFinder獲取數據存儲對象
DataStore dataStore = DataStoreFinder.getDataStore(map);
// 獲取地圖數據的要素源
SimpleFeatureSource featureSource = dataStore.getFeatureSource("city_map");
// 獲取地圖要素集合
SimpleFeatureCollection collection = featureSource.getFeatures();
for (Feature feature : collection) {
String sensorId = feature.getAttribute("sensor_id").toString();
// 調用方法獲取實際的空氣質量數據,這裏使用模擬數據代替
double pm25 = getAirQualityData(sensorId).getPm25();
feature.setAttribute("pm25", pm25);
}
// 根據要素源的模式創建簡單樣式
Style style = SLD.createSimpleStyle(featureSource.getSchema());
// 創建要素圖層
Layer layer = new FeatureLayer(featureSource, style);
MapContent mapContent = new MapContent();
mapContent.addLayer(layer);
// 此處可接入可視化展示框架,如GeoServer、OpenLayers等進行展示
}
private static AirQualityData getAirQualityData(String sensorId) {
// 模擬返回空氣質量數據,實際需從數據庫或API獲取
return new AirQualityData(sensorId, 50.0);
}
}
// 空氣質量數據實體類
class AirQualityData {
private String sensorId;
private double pm25;
// 省略其他屬性及getter和setter方法
}
數據融合與可視化流程如下圖所示:
3.2 動態時序分析與預測可視化
利用 ECharts for Java 實現污染物濃度的動態展示,並結合 LSTM(長短期記憶網絡)模型進行趨勢預測,為空氣質量預警提供有力支持。
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.LSTM;
import org.deeplearning4j.nn.conf.layers.RnnOutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.dataset.api.preprocessor.DataNormalization;
import org.nd4j.linalg.dataset.api.preprocessor.NormalizerStandardize;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.lossfunctions.LossFunctions;
import java.io.File;
import java.io.FileInputStream;
import java.util.ArrayList;
import java.util.List;
// 污染預測類
public class PollutionPrediction {
// 主方法
public static void main(String[] args) throws Exception {
// 從Excel文件中讀取歷史PM2.5數據
List<Double> pm25Data = readPM25Data("pm25_history.xlsx");
int sequenceLength = 10; // 時間序列長度
List<INDArray> inputList = new ArrayList<>();
List<INDArray> labelList = new ArrayList<>();
for (int i = 0; i <= pm25Data.size() - sequenceLength - 1; i++) {
// 將數據轉換為適合LSTM輸入的格式
INDArray input = Nd4j.create(pm25Data.subList(i, i + sequenceLength)).reshape(1, sequenceLength, 1);
INDArray label = Nd4j.create(pm25Data.subList(i + sequenceLength, i + sequenceLength + 1)).reshape(1, 1);
inputList.add(input);
labelList.add(label);
}
INDArray inputArray = Nd4j.concat(0, inputList.toArray(new INDArray[0]));
INDArray labelArray = Nd4j.concat(0, labelList.toArray(new INDArray[0]));
DataSet dataSet = new DataSet(inputArray, labelArray);
// 創建數據集迭代器,設置批次大小等參數
DataSetIterator iterator = dataSet.iterateMiniBatches(32, 1, true, 12345);
// 數據歸一化處理
DataNormalization normalizer = new NormalizerStandardize();
normalizer.fit(dataSet);
normalizer.transform(dataSet);
// 構建LSTM神經網絡配置
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(12345) // 設置隨機種子
.updater(new org.deeplearning4j.optimize.api.Updater() {
// 自定義更新策略,這裏可根據需求配置
})
.list()
.layer(0, new LSTM.Builder().nIn(1).nOut(64).activation(Activation.TANH).build())
.layer(1, new RnnOutputLayer.Builder(LossFunctions.LossFunction.MSE)
.nIn(64).nOut(1).activation(Activation.IDENTITY).build())
.build();
MultiLayerNetwork model = new MultiLayerNetwork(conf);
model.init();
// 訓練模型
for (int i = 0; i < 100; i++) {
model.fit(iterator);
}
//使用最後一個時間序列進行預測
INDArray lastSequence = inputArray.getRow(inputArray.rows() - 1);
List<Double> predictionList = new ArrayList<>();
for (int i = 0; i < 7; i++) {
INDArray prediction = model.output(lastSequence);
predictionList.add(prediction.getDouble(0));
// 更新時間序列,用於下一次預測
lastSequence = Nd4j.concat(1, lastSequence.getColumns(1, sequenceLength - 1), prediction);
}
System.out.println("未來7天PM2.5預測值: " + predictionList);
}
private static List<Double> readPM25Data(String filePath) throws Exception {
List<Double> dataList = new ArrayList<>();
FileInputStream file = new FileInputStream(new File(filePath));
XSSFWorkbook workbook = new XSSFWorkbook(file);
XSSFSheet sheet = workbook.getSheetAt(0);
for (Row row : sheet) {
Cell cell = row.getCell(1);
if (cell != null) {
dataList.add(cell.getNumericCellValue());
}
}
workbook.close();
file.close();
return dataList;
}
}
預測結果通過折線圖可視化展示:
四、污染溯源分析與可視化應用
4.1 時空關聯分析
通過 Spark SQL 對空氣質量數據進行時空維度交叉分析,能夠精準定位污染高發的區域和時段。
-- 分析工作日早晚高峯與PM2.5濃度關係
SELECT
CASE
WHEN HOUR(collect_time) BETWEEN 7 AND 9 OR HOUR(collect_time) BETWEEN 17 AND 19 THEN '高峯時段'
ELSE '非高峯時段'
END AS time_period,
AVG(pm25) AS avg_pm25
FROM
air_quality_info
WHERE
DAYOFWEEK(collect_time) NOT IN (1, 7)
GROUP BY
CASE
WHEN HOUR(collect_time) BETWEEN 7 AND 9 OR HOUR(collect_time) BETWEEN 17 AND 19 THEN '高峯時段'
ELSE '非高峯時段'
END;
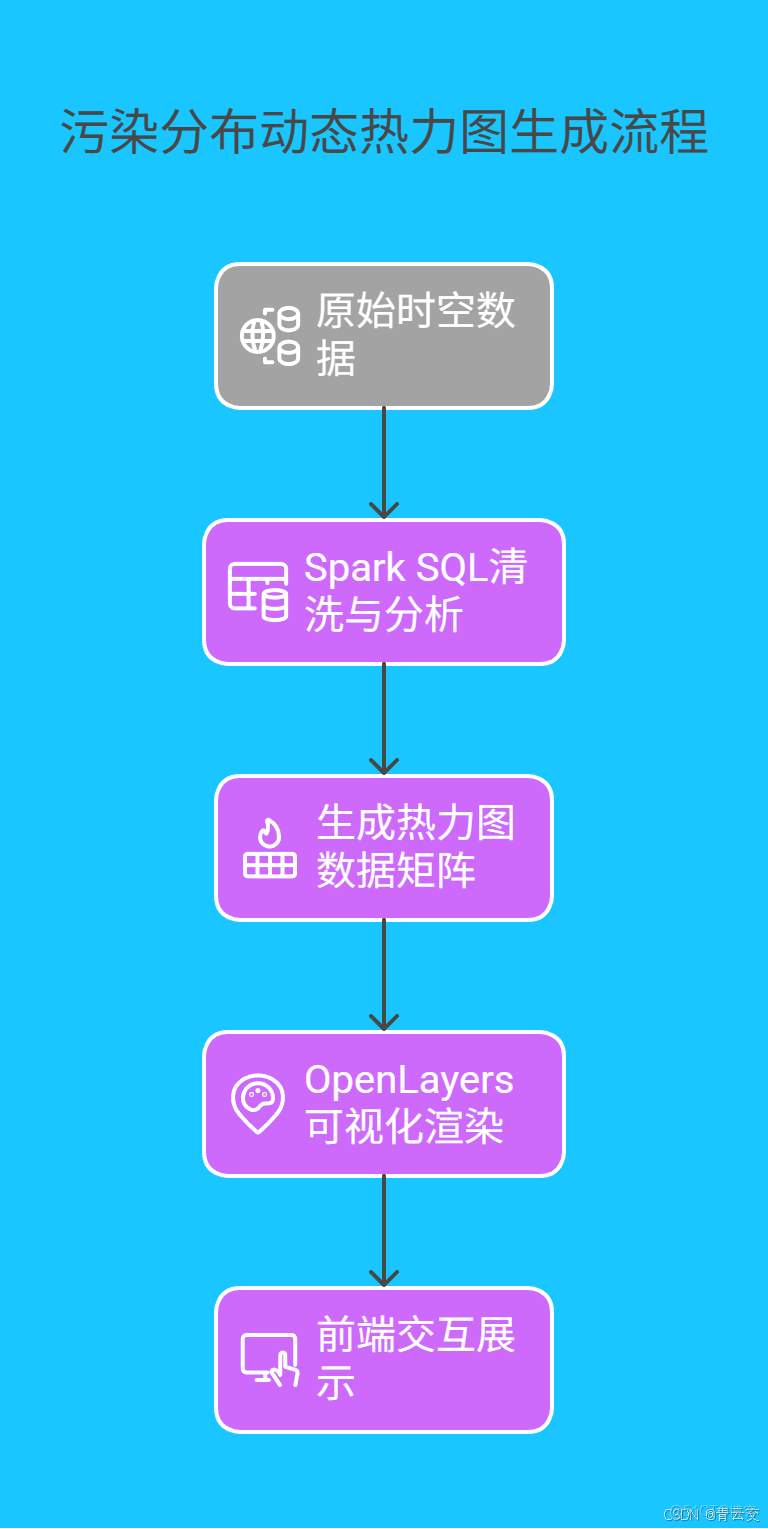
結合 GIS 地圖,利用動態熱力圖展示不同時段、區域的污染分佈。通過示意圖呈現數據流向:
4.2 污染源貢獻度量化
引入隨機森林算法構建污染源解析模型,對工業排放、機動車尾氣等 12 類污染源進行量化分析,完整代碼如下:
import org.apache.spark.ml.classification.RandomForestClassifier;
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator;
import org.apache.spark.ml.feature.VectorAssembler;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class PollutionSourceAnalysis {
public static void main(String[] args) {
// 初始化SparkSession
SparkSession spark = SparkSession.builder()
.appName("PollutionSourceAnalysis")
.master("local[*]")
.config("spark.sql.warehouse.dir", "file:///C:/tmp/spark-warehouse")
.getOrCreate();
// 讀取污染數據CSV文件,假設包含特徵列和污染源類型列
Dataset<Row> data = spark.read()
.option("header", "true")
.option("inferSchema", "true")
.csv("pollution_data.csv");
// 特徵組合,將多個特徵列合併為一個向量列
VectorAssembler assembler = new VectorAssembler()
.setInputCols(new String[]{"pm25", "pm10", "so2", "no2", "o3", "co",
"temperature", "humidity", "wind_speed"})
.setOutputCol("features");
Dataset<Row> assembledData = assembler.transform(data);
// 劃分訓練集和測試集
Dataset<Row>[] splits = assembledData.randomSplit(new double[]{0.7, 0.3});
Dataset<Row> trainingData = splits[0];
Dataset<Row> testData = splits[1];
// 構建隨機森林分類器
RandomForestClassifier rf = new RandomForestClassifier()
.setLabelCol("source_type")
.setFeaturesCol("features")
.setNumTrees(100)
.setMaxDepth(5)
.setSeed(12345);
org.apache.spark.ml.classification.RandomForestClassificationModel model = rf.fit(trainingData);
// 模型預測
Dataset<Row> predictions = model.transform(testData);
// 模型評估
MulticlassClassificationEvaluator evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("source_type")
.setPredictionCol("prediction")
.setMetricName("accuracy");
double accuracy = evaluator.evaluate(predictions);
System.out.println("模型準確率: " + accuracy);
// 輸出特徵重要性
for (double importance : model.featureImportances().toArray()) {
System.out.println("特徵重要性: " + importance);
}
spark.stop();
}
}
分析結果通過桑基圖可視化,直觀展示各污染源與污染物間的關聯:

五、經典案例深度剖析
5.1 北京市空氣質量監測與治理實踐
北京作為超大型城市,依託 Java 大數據可視化技術構建了全面監測體系。部署 2100 餘個監測站點,整合氣象、交通等 6 類數據,通過 Spark 每日處理超 500GB 歷史數據,Flink 實現分鐘級異常響應。
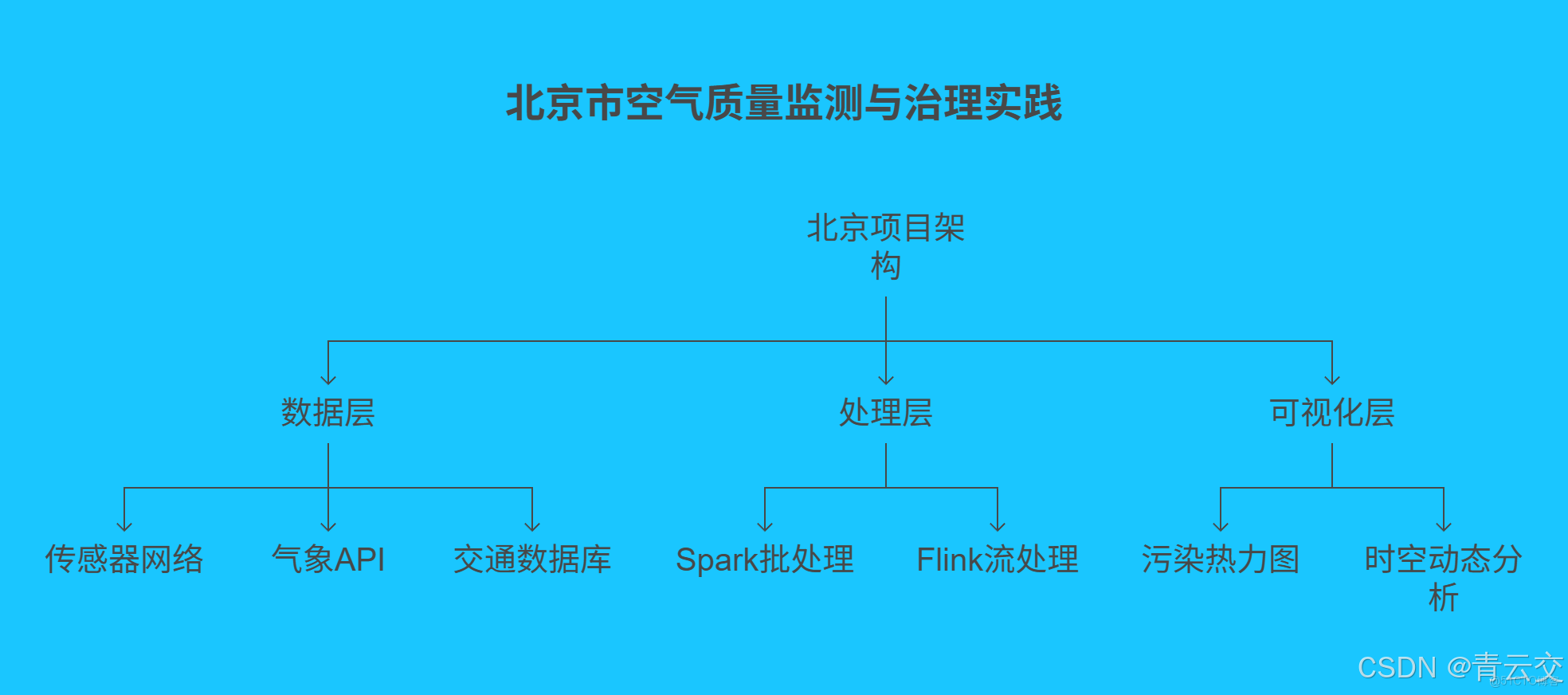
利用隨機森林算法定位機動車尾氣貢獻度達 38%,推動新能源汽車推廣;結合 LSTM 模型預測 PM2.5 趨勢,2023 年預警準確率達 91%,助力 PM2.5 年均濃度從 58μg/m³ 降至 30μg/m³。
5.2 深圳市臭氧污染專項治理
深圳針對夏季臭氧污染,搭建 Java 大數據平台。整合 1200 家企業排放數據、加油站油氣回收數據,通過 Flink 實時監測 VOCs 與 NOx 濃度。
| 指標 | 2021 年 | 2023 年 | 降幅 |
|---|---|---|---|
| 臭氧超標天數 | 45 天 | 28 天 | 37.8% |
| VOCs 排放量 | 12.5 萬噸 | 8.2 萬噸 | 34.4% |
| 利用桑基圖鎖定石化企業與加油站為主要污染源,推動 35 家企業技術改造,並實施加油站錯峯卸油,使臭氧超標天數顯著下降。 |
六、技術優化與未來展望
6.1 技術優化方向
- 邊緣計算融合:在傳感器端部署 Java 微服務,實現數據預處理與異常檢測,減少 50% 以上傳輸壓力
- AI 模型升級:引入圖神經網絡(GNN),結合地理空間信息,提升 20% 污染源定位精度
- 交互體驗增強:基於 WebGL 實現 3D 可視化,支持污染源擴散動態模擬
6.2 未來發展趨勢
Java 大數據將在以下領域持續發力:
- 全球聯防:構建跨國數據共享平台,應對跨境污染傳輸
- 健康服務:結合可穿戴設備,提供個性化空氣質量健康建議
- 雙碳目標:與碳排放數據融合,助力城市碳中和規劃
結束語:
親愛的 Java 和 大數據愛好者們,從智慧醫療到綠色環保,Java 大數據在《大數據新視界》和《 Java 大視界》專欄中不斷創造奇蹟。在空氣質量監測領域,它以代碼為盾、數據為矛,守護着城市的藍天白雲。
親愛的 Java 和 大數據愛好者,你在實際項目中遇到過哪些數據可視化難題?認為哪種算法最適合污染源動態追蹤?歡迎在評論區分享您的寶貴經驗與見解。
為了讓後續內容更貼合大家的需求,誠邀各位參與投票,選出您最期待的 Java 大數據應用方向?快來投出你的寶貴一票。