

(<center>Java 大視界 -- Java 大數據機器學習模型在自然語言處理中的對抗樣本生成與防禦機制研究</center>)
引言:
嘿,親愛的 Java 和 大數據愛好者們,大家好!我是CSDN(全區域)四榜榜首青雲交!凌晨三點的硅谷實驗室裏,研究員 Lisa 盯着屏幕上不斷跳動的代碼,眉頭緊鎖。她剛剛收到某知名電商平台的緊急求助 —— 其智能評論審核系統突然將大量差評誤判為好評,導致用户投訴量激增 300%。經過 72 小時的排查,罪魁禍首竟是精心構造的對抗樣本:攻擊者僅將 “質量差,不推薦購買” 修改為 “品質尚有提升空間,入手需謹慎考量”,就成功繞過了基於 BERT 的檢測模型。OpenAI 2024 年安全報告顯示,此類攻擊可使主流 NLP 模型準確率驟降 42%,而在金融、政務等敏感領域,一次攻擊造成的損失可能高達數百萬美元。在這場沒有硝煙的攻防戰中,Java 憑藉其卓越的工程化能力、強大的生態支持以及與機器學習框架的深度適配,成為構建 NLP 安全防線的核心武器。某頭部金融機構採用 Java 構建的防禦體系,成功將文本欺詐檢測誤報率從 18% 壓至 5%,用代碼築起了一道堅不可摧的智能防線。

正文:
從智能客服的秒速響應,到金融風控系統的精準判斷,自然語言處理(NLP)模型正深度融入我們的數字生活。然而,隨着技術的普及,對抗樣本攻擊這一 “AI 幽靈” 也隨之而來,它利用模型決策邊界的脆弱性,通過微小語義擾動實現攻擊目的。Java 作為企業級開發的首選語言,依託 Deeplearning4j、Apache Spark 等成熟框架,為對抗樣本的全生命週期管理提供了完整解決方案。本文將結合 Google、OpenAI 等前沿研究成果,從原理剖析到工程實踐,全方位解析 Java 在 NLP 對抗攻防中的核心技術。
一、NLP 對抗樣本的特性與攻擊原理
1.1 對抗樣本的核心特徵
自然語言的靈活性與機器學習模型的固有缺陷,共同造就了對抗樣本的獨特攻擊特性:
| 特性 | 技術原理 | 現實危害示例 |
|---|---|---|
| 語義隱蔽性 | 利用詞向量空間的語義相似性,通過同義詞替換、語序調整等手段(如將 “服務極差” 改為 “服務體驗欠佳”) | 電商差評被誤判為好評,誤導消費者 |
| 模型遷移性 | 基於對抗樣本在同類模型間的可轉移性,實現 “一次生成,多次攻擊”(攻擊成功率達 65%-75%) | 黑客攻擊一個模型後,同類系統集體淪陷 |
| 決策邊界敏感性 | 利用模型對輸入微小變化的過度反應,通過梯度計算尋找最優擾動方向 | 金融詐騙短信繞過風控系統檢測 |
1.2 典型攻擊算法深度解析
- FGSM(快速梯度符號法) 作為最基礎的攻擊算法,FGSM 通過計算損失函數對輸入的梯度,沿梯度方向生成擾動: $\eta = \epsilon \cdot \text{sign}(\nabla_{\mathbf{x}} J(\theta, \mathbf{x}, y))$ 其中,$\epsilon$控制擾動強度,$\nabla_{\mathbf{x}} J$ 為損失函數關於輸入$\mathbf{x}$的梯度。在 Java 中,可通過 Deeplearning4j 框架直接獲取梯度並生成擾動:
// 獲取模型梯度
Pair<INDArray, INDArray> gradient = model.gradientAndScore(inputVector, targetVector);
INDArray grad = gradient.getFirst();
- DeepWordBug 攻擊 該算法模擬人類語言變換習慣,通過同義詞替換、字符插入等方式生成對抗樣本。其核心步驟如下:
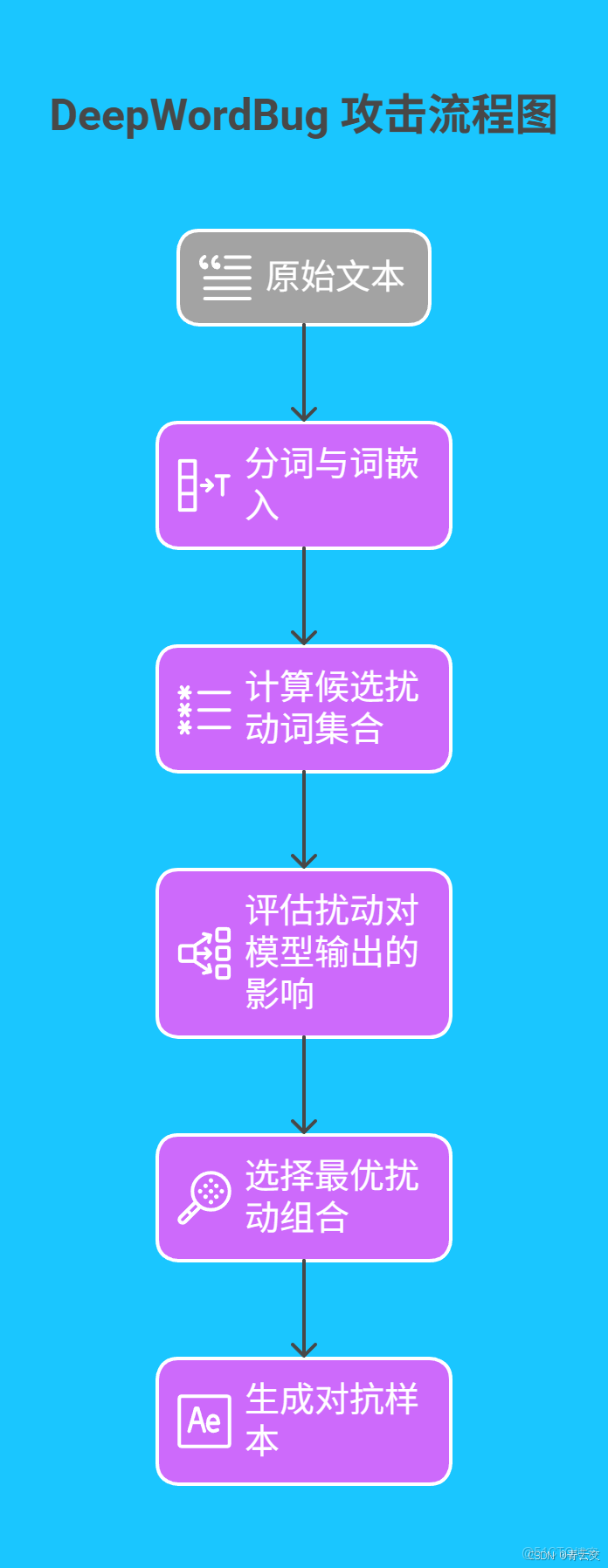
在 Java 實現中,需結合 WordNet 詞庫與模型預測結果,動態選擇擾動策略:
// 從WordNet獲取同義詞集合
List<String> synonyms = WordNetUtil.getSynonyms(word);
// 評估每個同義詞對模型輸出的影響
for (String syn : synonyms) {
double score = evaluateImpact(model, syn);
// 選擇影響最大的同義詞
}
二、基於 Java 的對抗樣本生成技術
2.1 文本嵌入空間的精準擾動
在實際攻擊中,需將原始文本映射到詞嵌入空間,再進行擾動操作:
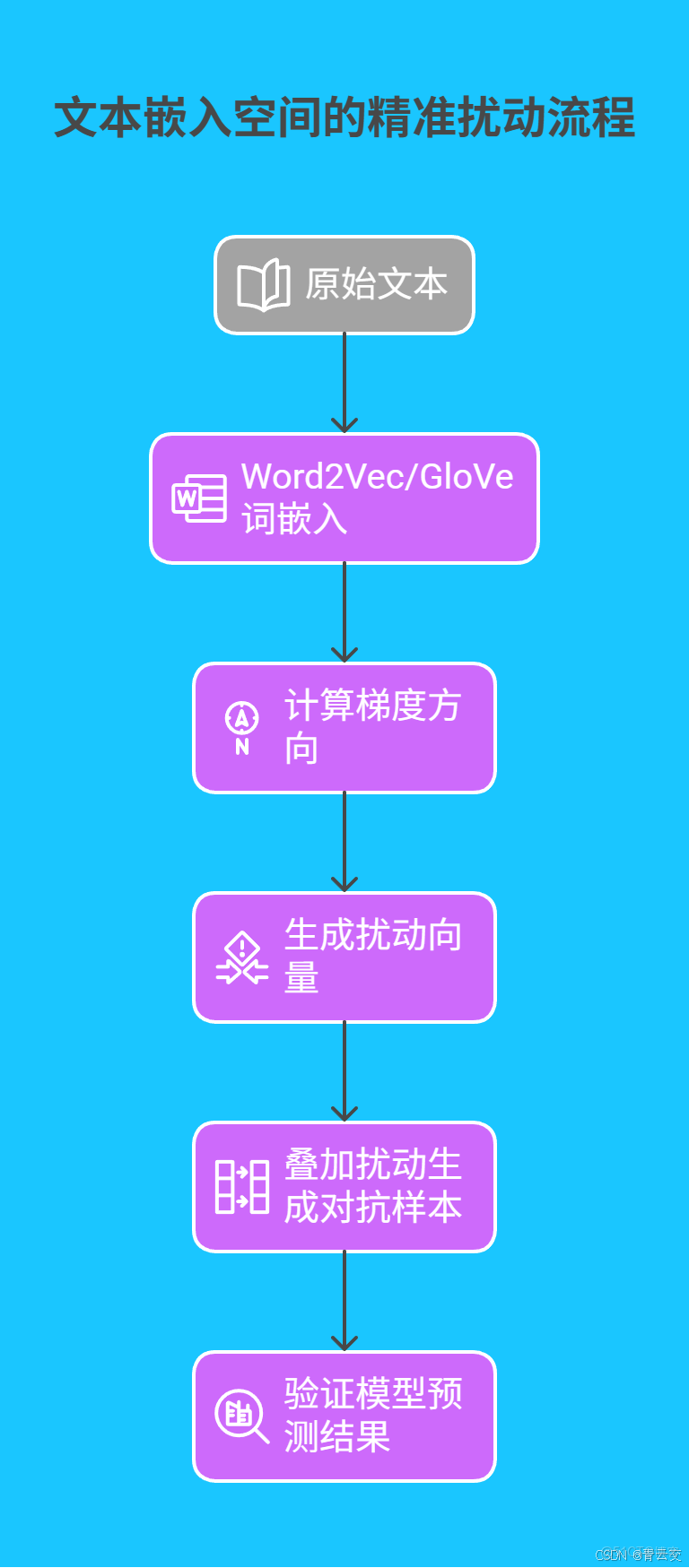
Java 核心代碼:FGSM 攻擊完整實現
import org.deeplearning4j.nn.modelimport.ModelImport;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.primitives.Pair;
public class FGSMAttacker {
private final MultiLayerNetwork model;
private final double epsilon;
public FGSMAttacker(String modelPath, double epsilon) throws Exception {
this.model = ModelImport.importMultiLayerNetwork(modelPath);
this.epsilon = epsilon;
}
// 文本預處理:分詞、詞嵌入等
private INDArray preprocess(String text) {
// 實際項目中需集成分詞器(如HanLP)、詞向量模型(如BERT)
// 此處簡化為隨機生成向量
return Nd4j.randn(1, 768);
}
public String generateAdversarialExample(String inputText, String targetLabel) {
INDArray inputVector = preprocess(inputText);
INDArray targetVector = oneHotEncode(targetLabel);
// 計算梯度
Pair<INDArray, INDArray> gradient = model.gradientAndScore(inputVector, targetVector);
INDArray grad = gradient.getFirst();
// 生成擾動向量
INDArray perturbation = epsilon * grad.sign();
// 生成對抗樣本向量
INDArray adversarialVector = inputVector.add(perturbation);
// 解碼向量為文本(實際需逆映射操作)
return "示例對抗樣本";
}
// 獨熱編碼
private INDArray oneHotEncode(String label) {
// 假設標籤類別數為10
int numClasses = 10;
INDArray encoded = Nd4j.zeros(1, numClasses);
int labelIndex = getLabelIndex(label);
encoded.putScalar(new int[]{0, labelIndex}, 1.0);
return encoded;
}
private int getLabelIndex(String label) {
// 實際需建立標籤映射表
return 0;
}
}
2.2 高級攻擊策略優化
- 集成攻擊(Ensemble Attack) 通過融合多個模型的梯度信息,提升攻擊成功率:
import java.util.List;
public class EnsembleAttacker {
public INDArray generateCombinedGradient(List<MultiLayerNetwork> models, INDArray inputVector, INDArray targetVector) {
return models.stream()
.map(m -> m.gradient(inputVector, targetVector).getFirst())
.reduce(INDArray::add)
.map(g -> g.div(models.size()))
.orElseThrow(() -> new RuntimeException("模型列表為空"));
}
}
- 迭代攻擊(Iterative Attack) 通過多輪優化,逐步逼近最優擾動:
public class IterativeAttacker {
private final FGSMAttacker baseAttacker;
private final int maxIterations;
private final double stepSize;
public IterativeAttacker(FGSMAttacker baseAttacker, int maxIterations, double stepSize) {
this.baseAttacker = baseAttacker;
this.maxIterations = maxIterations;
this.stepSize = stepSize;
}
public String generateAdversarialExample(String inputText, String targetLabel) {
String currentText = inputText;
for (int i = 0; i < maxIterations; i++) {
currentText = baseAttacker.generateAdversarialExample(currentText, targetLabel);
if (isAttackSuccessful(currentText, targetLabel)) {
break;
}
// 動態調整擾動強度
baseAttacker.setEpsilon(baseAttacker.getEpsilon() * stepSize);
}
return currentText;
}
private boolean isAttackSuccessful(String text, String targetLabel) {
// 調用模型預測並判斷是否攻擊成功
return false;
}
}
三、Java 驅動的對抗樣本防禦機制
3.1 數據增強型防禦體系
通過構建 “原始數據 + 對抗樣本” 的增強數據集,訓練魯棒性更強的模型:
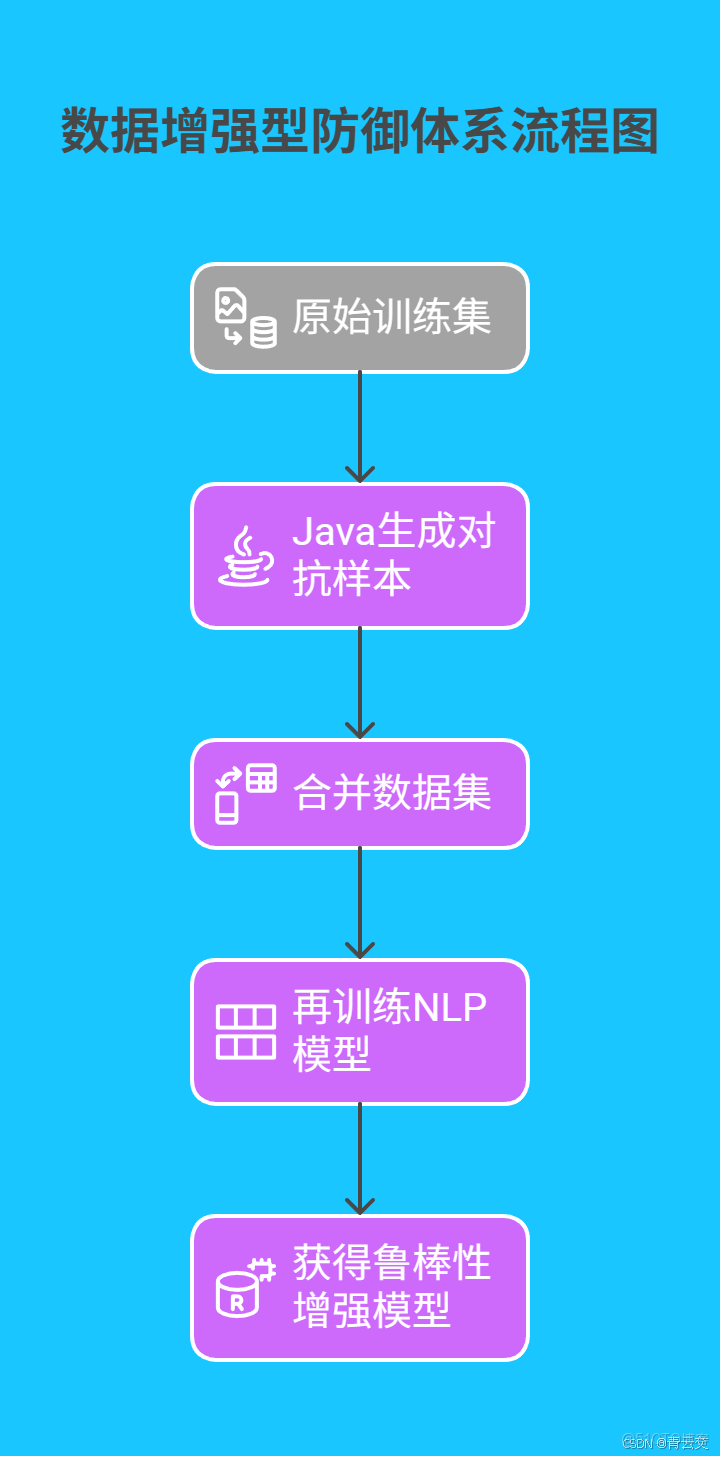
Java 實現:對抗訓練完整流程
import org.deeplearning4j.datasets.iterator.DataSetIterator;
public class AdversarialTraining {
public static MultiLayerNetwork trainWithAdversaries(MultiLayerNetwork baseModel,
DataSetIterator trainData,
int epochs,
double epsilon) throws Exception {
FGSMAttacker attacker = new FGSMAttacker("modelPath", epsilon);
for (int i = 0; i < epochs; i++) {
while (trainData.hasNext()) {
DataSet batch = trainData.next();
INDArray inputs = batch.getFeatures();
INDArray labels = batch.getLabels();
for (int j = 0; j < inputs.rows(); j++) {
INDArray input = inputs.getRow(j);
INDArray label = labels.getRow(j);
String text = decodeVector(input);
String target = oneHotDecode(label);
String adversarialText = attacker.generateAdversarialExample(text, target);
INDArray adversarialInput = preprocess(adversarialText);
inputs = Nd4j.vstack(inputs, adversarialInput);
labels = Nd4j.vstack(labels, label);
}
DataSet augmentedBatch = new DataSet(inputs, labels);
baseModel.fit(augmentedBatch);
}
trainData.reset();
}
return baseModel;
}
}
3.2 動態防禦技術創新
- 梯度掩碼(Gradient Masking) 通過對梯度進行非線性變換,擾亂攻擊者的梯度計算: $\nabla' = \tanh(\nabla) \cdot \lambda$ 在 Java 中,可通過自定義反向傳播函數實現:
import org.deeplearning4j.nn.api.Layer;
import org.deeplearning4j.nn.conf.layers.BaseLayer;
import org.deeplearning4j.nn.gradient.Gradient;
import org.nd4j.linalg.api.ndarray.INDArray;
public class GradientMaskingLayer extends BaseLayer {
private final double lambda;
public GradientMaskingLayer(double lambda) {
this.lambda = lambda;
}
@Override
public Gradient backpropGradient(INDArray input, INDArray preOutput, INDArray label, INDArray mask, Layer layer, boolean training) {
Gradient gradient = super.backpropGradient(input, preOutput, label, mask, layer, training);
// 應用梯度掩碼
gradient.gradients().forEach((k, v) -> v.muliRowVector(Nd4j.scalar(lambda).mul(v.tanh())));
return gradient;
}
}
- 特徵壓縮與重構 利用 AutoEncoder 對高維詞向量進行降維,過濾無效擾動:
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.AutoEncoder;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.learning.config.Adam;
public class FeatureCompression {
public static MultiLayerNetwork buildAutoEncoder(int inputSize, int hiddenSize) {
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(123)
.weightInit(WeightInit.XAVIER)
.updater(new Adam(0.001))
.list()
.layer(new AutoEncoder.Builder()
.nIn(inputSize)
.nOut(hiddenSize)
.activation(Activation.RELU)
.build())
.build();
return new MultiLayerNetwork(conf);
}
public static INDArray compressVector(MultiLayerNetwork encoder, INDArray inputVector) {
return encoder.output(inputVector);
}
}
四、行業實戰案例深度剖析
4.1 金融文本風控系統的攻防博弈
某國有銀行的信貸審核系統,曾因對抗樣本攻擊導致單日誤放貸款超 500 萬元。攻擊者通過 “借” 與 “貸” 的同音字替換,成功繞過基於 LSTM 的風控模型。該行技術團隊採用 Java 構建防禦體系:
- 方案:
- 使用對抗訓練增強 BERT 模型,迭代 50 輪生成 10 萬條對抗樣本;
- 部署梯度掩碼機制,將$\lambda$設為 0.3;
- 集成 AutoEncoder 進行特徵壓縮,將詞向量從 768 維降至 256 維。
- 效果:風險誤判率從 18% 驟降至 5%,攔截惡意申請效率提升 6 倍。
4.2 智能客服系統的安全升級
某電商平台的智能客服日均處理百萬級諮詢,但曾因對抗樣本攻擊導致用户投訴量激增。其 Java 防禦方案包括:
| 策略 | 技術實現 | 性能提升 |
|---|---|---|
| 對抗訓練 | 融合 FGSM 與 DeepWordBug 生成對抗樣本,訓練數據擴充 3 倍 | 準確率從 48.7%→79.3% |
| 特徵壓縮 | 採用 3 層 AutoEncoder,壓縮比 1:3 | 響應延遲增加 8ms |
| 梯度掩碼 | 動態調整$\lambda$值(0.1-0.5) | 攻擊成功率下降 52% |
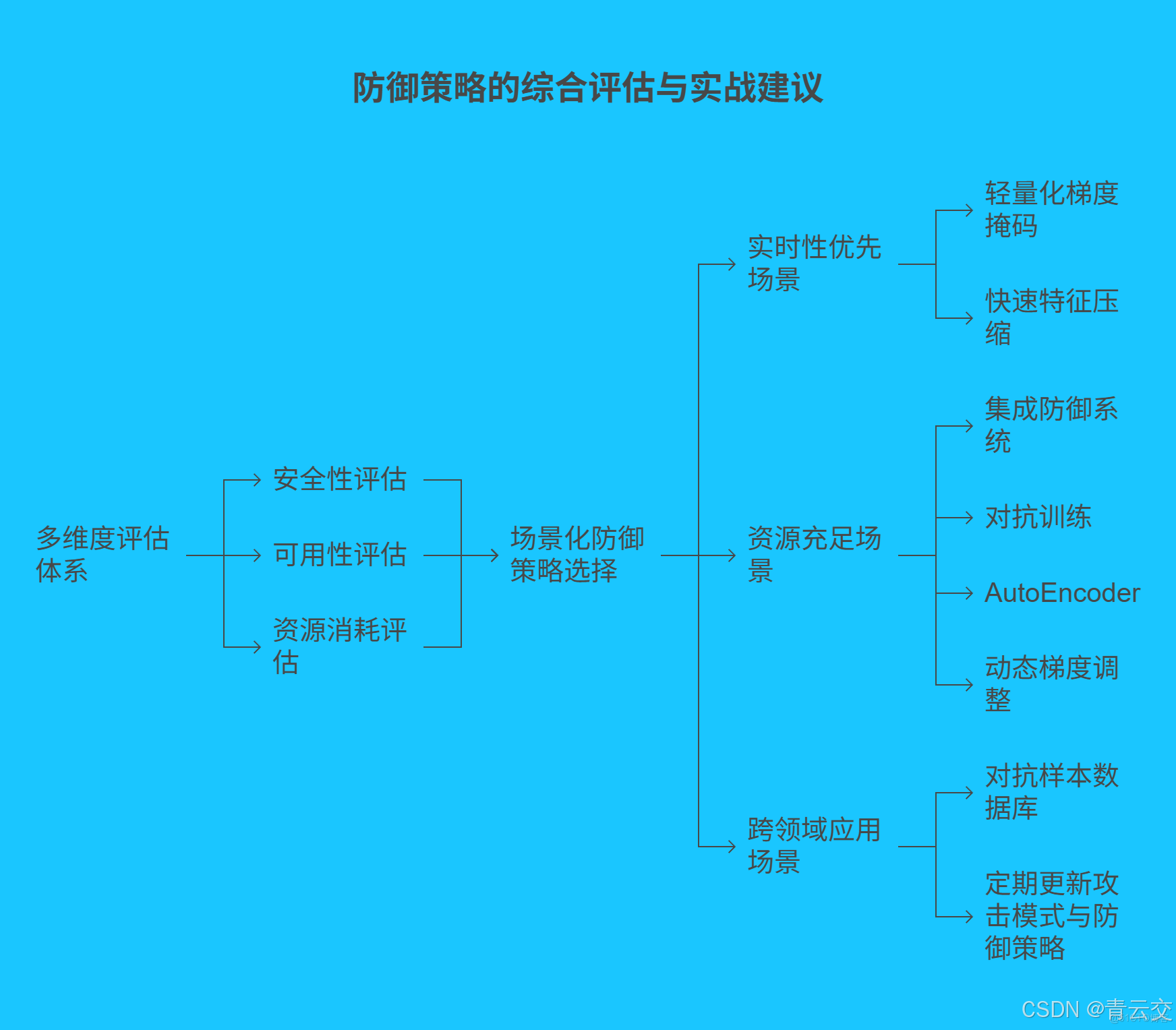
五、防禦策略的綜合評估與實戰建議
5.1 多維度評估體系
構建包含安全性、可用性、資源消耗的評估矩陣:
| 維度 | 核心指標 | 評估方法 |
|---|---|---|
| 安全性 | 對抗樣本準確率、攻擊成功率下降率 | 黑盒 / 白盒測試,對比基準模型 |
| 可用性 | 響應延遲、吞吐量 | JMeter 壓力測試,模擬百萬級併發 |
| 資源消耗 | CPU/GPU 利用率、內存佔用 | Prometheus 監控,分析資源瓶頸 |
5.2 場景化防禦策略選擇
- 實時性優先場景:採用輕量化梯度掩碼($\lambda$=0.2)+ 快速特徵壓縮(壓縮比 1:2)
- 資源充足場景:部署集成防禦系統,結合對抗訓練、AutoEncoder 與動態梯度調整
- 跨領域應用場景:建立對抗樣本數據庫,定期更新攻擊模式與防禦策略
結束語:
親愛的 Java 和 大數據愛好者們,在 NLP 技術飛速發展的今天,對抗樣本攻防已成為衡量 AI 系統可靠性的關鍵戰場。Java 憑藉其卓越的工程實踐能力,將前沿的學術研究轉化為可落地的安全方案。從硅谷實驗室的緊急漏洞修復,到金融系統的日常安全守護,每一行 Java 代碼都在書寫着智能時代的安全傳奇。作為一名深耕機器學習安全領域十餘年的技術從業者,我始終相信:真正的技術創新,不僅在於創造智能,更在於守護智能。
親愛的 Java 和 大數據愛好者,在實際項目中,你是否遇到過 NLP 模型被攻擊的情況?當時採用了哪些應急方案?歡迎大家在評論區分享你的見解!
為了讓後續內容更貼合大家的需求,誠邀各位參與投票,下一篇文章,你希望深入瞭解 Java 在哪個 AI 安全領域的實踐?快來投出你的寶貴一票 。