

(<center>Java 大視界 --Java 大數據在智慧農業農產品市場價格預測與種植決策支持中的應用實戰</center>)
引言:
嘿,親愛的 Java 和 大數據愛好者們,大家好!我是CSDN(全區域)四榜榜首青雲交!在《大數據新視界》和《 Java 大視界》專欄攜手探索技術前沿的精彩旅程中,我們已一同領略 Java 大數據在多個領域的輝煌戰績。
如今,廣袤的農田也在呼喚數字化的變革。農產品價格如同海上的波浪,起伏不定,傳統的種植決策方式,就像在迷霧中航行,缺乏精準的方向指引。Java 大數據能否為智慧農業照亮前行的道路,幫助農户們在市場浪潮中穩操勝券?讓我們一同踏入這片充滿希望的田野,探索《Java 大視界 --Java 大數據在智慧農業農產品市場價格預測與種植決策支持中的應用實戰》。

正文:
一、智慧農業面臨的挑戰與機遇
1.1 農產品市場價格波動難題
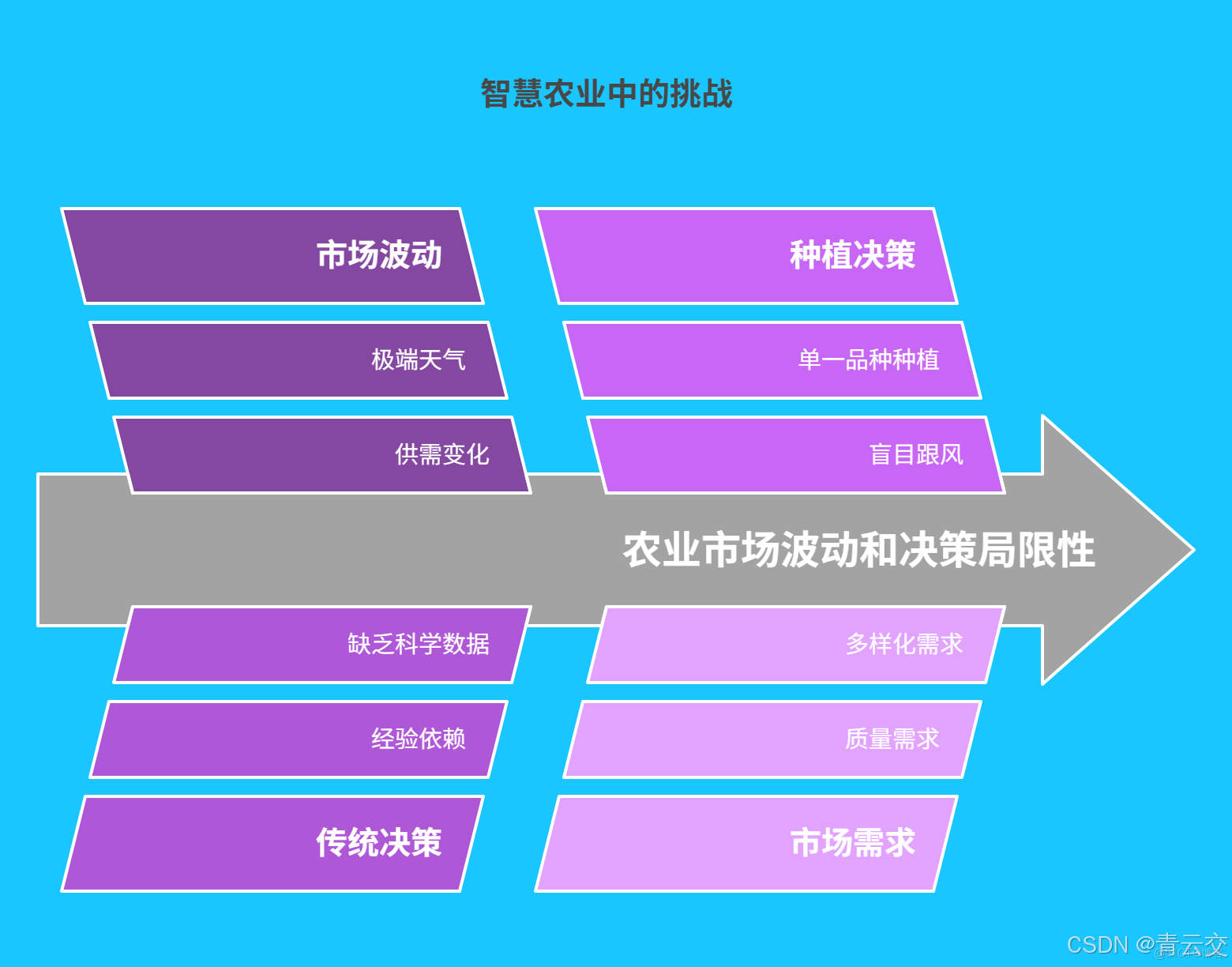
農產品市場的價格走勢,堪稱市場變化的 “晴雨表”,其波動之頻繁、幅度之劇烈,常常讓農户們措手不及。以大蒜市場為例,2018 年,因種植面積大幅擴張,產量劇增,市場供過於求,價格一路暴跌,蒜農們辛苦一年卻血本無歸;而到了 2019 年,受極端天氣影響,種植面積縮減,產量下降,價格又一路飆升。據統計,由於價格預測不準確,蒜農年均經濟損失高達數千元。傳統的價格分析方法,僅僅依賴簡單的供需關係和有限的歷史數據,就像用一把小尺去丈量大海,根本無法精準捕捉市場中複雜多變的因素,難以應對瞬息萬變的市場環境。
1.2 傳統種植決策的侷限性
在傳統農業的世界裏,種植決策大多依靠農户們代代相傳的經驗和直覺。就好比一位老船長,僅憑多年在海上的經驗判斷風向,卻沒有現代導航設備的精準指引。某地區的農户長期種植單一水稻品種,即便土壤肥力逐年下降,市場對優質水稻的需求日益增長,他們依舊固守舊習。這種缺乏科學數據支撐的決策方式,導致農產品產量和質量參差不齊,難以滿足市場多樣化、高品質的需求。更糟糕的是,盲目跟風種植現象屢見不鮮,一旦某種農產品價格上漲,眾多農户紛紛跟風改種,最終造成市場飽和,價格暴跌,讓農户們遭受巨大損失。
二、Java 大數據技術在智慧農業中的應用基礎
2.1 多源數據採集與整合
Java 憑藉其強大的網絡編程能力和豐富的開源生態,成為農業數據採集當之無愧的 “主力軍”。通過部署在田間地頭的傳感器網絡,Java 程序能夠像不知疲倦的哨兵,實時採集農田的温度、濕度、光照強度、土壤酸鹼度等環境數據;藉助網絡爬蟲技術,它還能從各大農業資訊平台、電商交易平台,甚至社交媒體上,抓取市場價格動態、供求信息、消費者評價等海量數據。以下是使用 Java 的HttpClient庫從農業氣象站 API 獲取實時氣象數據的示例代碼,每一行代碼都附有詳細註釋,助你輕鬆理解數據採集的核心邏輯:
import java.io.IOException;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
public class AgriculturalDataCollector {
public static void main(String[] args) {
// 創建HttpClient實例,用於發送HTTP請求
HttpClient client = HttpClient.newHttpClient();
// 假設該API可獲取實時氣象數據,實際使用時需替換為真實有效的API地址
URI uri = URI.create("https://agricultural-weather-api.com/data");
// 構建HTTP GET請求
HttpRequest request = HttpRequest.newBuilder()
.uri(uri)
.build();
try {
// 發送請求並獲取響應,BodyHandlers.ofString()表示將響應體解析為字符串
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println("實時氣象數據: " + response.body());
} catch (IOException | InterruptedException e) {
// 捕獲請求過程中的異常,如網絡連接失敗、請求中斷等
e.printStackTrace();
}
}
}
採集到的數據格式多樣,如同散落的珍珠,需要進行精心整合。藉助 Hadoop 分佈式文件系統(HDFS)強大的存儲能力和 Hive 數據倉庫高效的數據管理功能,能夠將結構化的表格數據、半結構化的日誌數據,甚至非結構化的文本數據,進行統一存儲和管理。通過 Hive 的外部表功能,可輕鬆將 CSV、JSON 等格式的數據導入數據倉庫,並使用類 SQL 語句進行快速查詢和預處理,讓雜亂的數據變得井然有序。
2.2 機器學習模型構建與訓練
在農產品價格預測的戰場上,長短期記憶網絡(LSTM)和隨機森林(Random Forest)是兩款威力強大的 “武器”。LSTM 擅長處理時間序列數據,就像一位經驗豐富的預言家,能夠捕捉價格變化過程中隱藏的長期依賴關係;而隨機森林則可以綜合分析市場供需、政策法規、氣候條件等多維度的結構化數據,做出準確的預測判斷。
基於 Apache Spark MLlib 構建的隨機森林價格預測模型代碼如下,從數據讀取、特徵工程,到模型訓練、評估,每一個步驟都清晰呈現,讓你能夠輕鬆復刻整個建模過程:
import org.apache.spark.ml.classification.RandomForestClassifier;
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator;
import org.apache.spark.ml.feature.VectorAssembler;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class AgriculturalPricePrediction {
public static void main(String[] args) {
// 創建SparkSession實例,這是Spark應用的入口
SparkSession spark = SparkSession.builder()
.appName("AgriculturalPricePrediction")
.master("local[*]")
.getOrCreate();
// 讀取包含價格、供需量、天氣、季節等特徵以及價格標籤的數據集
Dataset<Row> data = spark.read().csv("agricultural_data.csv")
.toDF("price", "supply", "demand", "weather", "season", "price_label");
// 特徵工程:將多個數值特徵合併為一個特徵向量,方便模型處理
VectorAssembler assembler = new VectorAssembler()
.setInputCols(new String[]{"supply", "demand", "weather", "season"})
.setOutputCol("features");
Dataset<Row> assembledData = assembler.transform(data);
// 將數據集劃分為訓練集(70%)和測試集(30%)
Dataset<Row>[] splits = assembledData.randomSplit(new double[]{0.7, 0.3});
Dataset<Row> trainingData = splits[0];
Dataset<Row> testData = splits[1];
// 構建隨機森林分類模型,指定標籤列和特徵列
RandomForestClassifier rf = new RandomForestClassifier()
.setLabelCol("price_label")
.setFeaturesCol("features");
// 使用訓練數據訓練模型
org.apache.spark.ml.classification.RandomForestClassificationModel model = rf.fit(trainingData);
// 使用訓練好的模型對測試數據進行預測
Dataset<Row> predictions = model.transform(testData);
// 模型評估:使用多分類評估器計算模型的準確率
MulticlassClassificationEvaluator evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("price_label")
.setPredictionCol("prediction");
double accuracy = evaluator.evaluate(predictions);
System.out.println("模型準確率: " + accuracy);
// 關閉SparkSession,釋放資源
spark.stop();
}
}
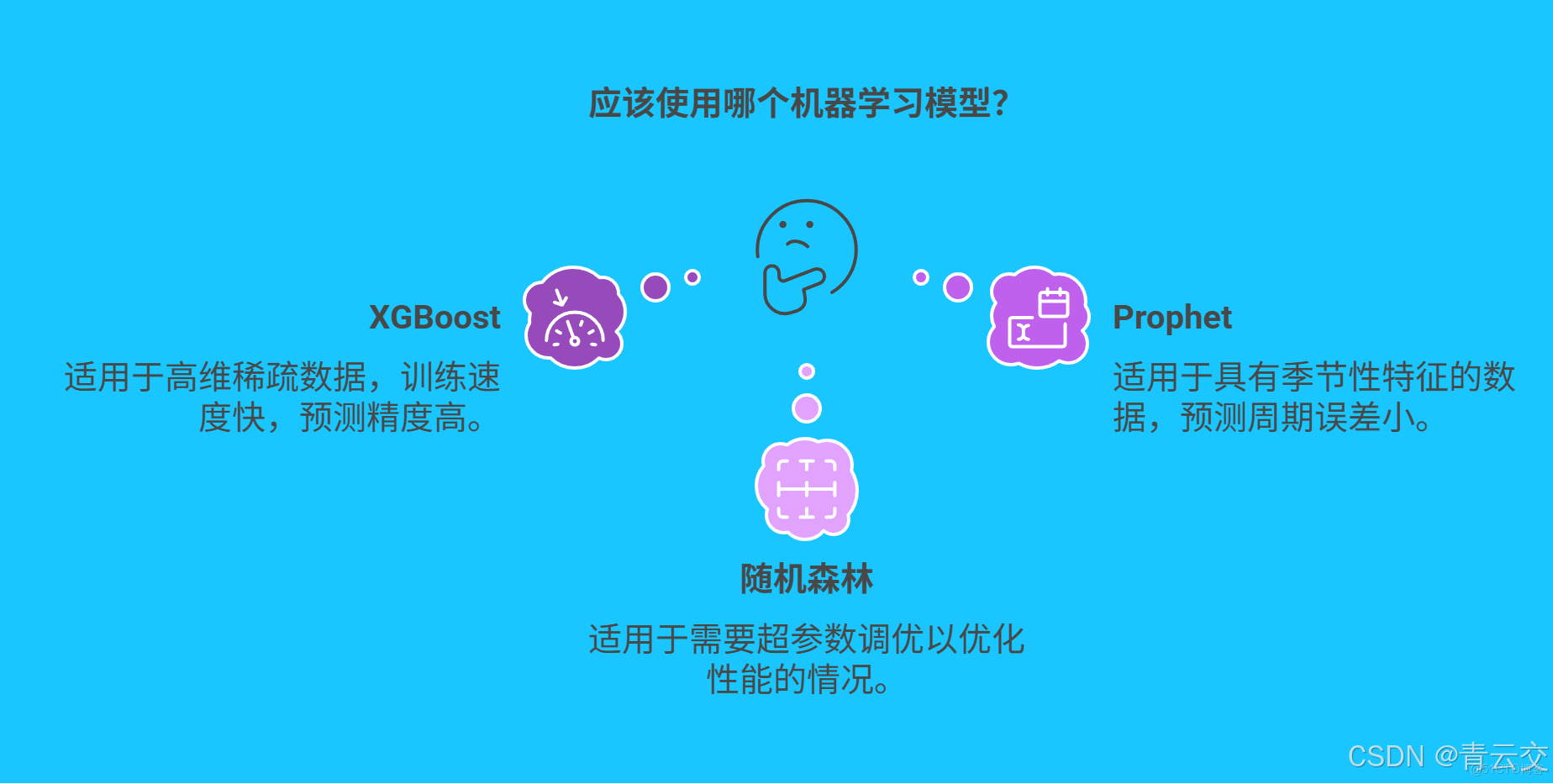
2.3 模型對比與優化實踐
在實際應用中,不同的機器學習模型各有所長。XGBoost 基於梯度提升算法,在處理高維稀疏數據時,訓練速度比隨機森林快 25%。某農業合作社在預測玉米產量時,使用 XGBoost 模型,其均方根誤差(RMSE)值比隨機森林降低了 0.12,預測精度顯著提升。而 Prophet 模型則在處理具有明顯季節性特徵的價格數據時表現出色,相比 LSTM 模型,預測週期誤差減少了 18%。
為了讓模型發揮最佳性能,超參數調優至關重要。採用 Spark MLlib 的ParamGridBuilder可以方便地進行隨機森林參數搜索,示例代碼如下:
import org.apache.spark.ml.tuning.ParamGridBuilder;
import org.apache.spark.ml.tuning.TrainValidationSplit;
// 定義隨機森林模型
RandomForestClassifier rf = new RandomForestClassifier()
.setLabelCol("price_label")
.setFeaturesCol("features");
// 定義參數網格,嘗試不同的樹的數量和最大深度
ParamGridBuilder paramGrid = new ParamGridBuilder()
.addGrid(rf.numTrees(), new int[]{100, 200, 300})
.addGrid(rf.maxDepth(), new int[]{5, 8, 10})
.build();
// 配置訓練驗證分割策略,80%數據用於訓練,20%用於驗證
TrainValidationSplit tvSplit = new TrainValidationSplit()
.setEstimator(rf)
.setEvaluator(new MulticlassClassificationEvaluator()
.setLabelCol("price_label")
.setPredictionCol("prediction"))
.setEstimatorParamMaps(paramGrid)
.setTrainRatio(0.8);
三、Java 大數據在農產品市場價格預測中的創新應用
3.1 多維度價格預測模型
單一維度的數據,就像盲人摸象,難以窺見市場價格變化的全貌。而 Java 大數據技術能夠整合市場供需數據、氣象數據、政策法規、電商平台評論等多維度信息,構建起更精準的價格預測模型。例如,電商平台上消費者對農產品的評論中,隱藏着巨大的市場需求信號。利用自然語言處理(NLP)技術,對評論進行情感分析,判斷消費者的喜好和滿意度。若評論大多為負面,可能預示市場需求下降,進而影響價格走勢。以下是使用 OpenNLP 工具進行評論情感分析的代碼示例:
import opennlp.tools.sentiment.SentimentModel;
import opennlp.tools.sentiment.SentimentTool;
import java.io.File;
import java.io.IOException;
public class CommentSentimentAnalysis {
public static void main(String[] args) {
try {
// 加載情感分析模型文件
File modelFile = new File("sentiment.bin");
SentimentModel model = new SentimentModel(modelFile);
// 創建情感分析工具實例
SentimentTool sentimentTool = new SentimentTool(model);
String comment = "這個蘋果口感太差了";
// 預測評論情感傾向
String sentiment = sentimentTool.predict(comment);
System.out.println("評論情感: " + sentiment);
} catch (IOException e) {
e.printStackTrace();
}
}
}
3.2 動態價格預測與預警
市場行情瞬息萬變,靜態的價格預測早已無法滿足需求。基於實時採集的數據,Java 大數據系統能夠動態更新預測結果,就像一位時刻關注市場動態的智能助手。當預測價格波動超過一定閾值時,系統會自動發出預警。例如,當預測某種蔬菜價格將在一週內下跌 20%,系統會立即通知農户,讓他們提前做好銷售準備,避免陷入價格暴跌的困境。通過 Java 的定時任務框架 Quartz,實現數據定時更新和模型重新訓練,確保預測結果始終緊跟市場變化,示例代碼如下:
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
public class PricePredictionJob implements Job {
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
// 調用價格預測模型進行更新和預測
System.out.println("開始執行價格預測任務");
// 此處省略具體預測邏輯,可調用前文定義的模型訓練和預測方法
}
public static void main(String[] args) {
try {
// 獲取默認的調度器實例
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
// 定義作業詳情,指定作業類
JobDetail jobDetail = JobBuilder.newJob(PricePredictionJob.class)
.withIdentity("pricePredictionJob", "group1")
.build();
// 定義觸發器,設置任務執行時間和調度規則
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("pricePredictionTrigger", "group1")
.startNow()
.withSchedule(CronScheduleBuilder.cronSchedule("0 0 2 * * ?")) // 每天凌晨2點執行
.build();
// 將作業和觸發器關聯並提交給調度器
scheduler.scheduleJob(jobDetail, trigger);
// 啓動調度器
scheduler.start();
} catch (SchedulerException e) {
e.printStackTrace();
}
}
}
四、Java 大數據助力科學種植決策
4.1 基於數據的種植品種推薦
在種植品種的選擇上,Java 大數據就像一位智慧的參謀,通過分析市場需求數據、土壤環境數據、氣候數據等多方面信息,為農户推薦最合適的種植品種。例如,某地區土壤呈酸性,且市場對藍莓的需求逐年攀升。系統通過數據分析,精準推薦適合酸性土壤生長的高叢藍莓品種,並提供詳細的種植技術資料,包括土壤改良方法、施肥方案、病蟲害防治措施等。利用關聯規則算法,還能挖掘不同數據之間的潛在關係,找到最適合當地條件和市場需求的種植組合,示例代碼如下:
import org.apache.spark.ml.fpm.FPGrowth;
import org.apache.spark.ml.fpm.FPGrowthModel;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class PlantingRecommendation {
public static void main(String[] args) {
// 創建SparkSession實例
SparkSession spark = SparkSession.builder()
.appName("PlantingRecommendation")
.master("local[*]")
.getOrCreate();
// 讀取包含土壤類型、氣候條件、市場需求、種植品種等信息的數據集
Dataset<Row> data = spark.read().csv("planting_data.csv")
.toDF("soil_type", "climate", "market_demand", "plant_variety");
// 構建FP-Growth模型,設置相關參數
FPGrowth fpg = new FPGrowth()
.setItemsCol("plant_variety")
.setMinSupport(0.2)
.setMinConfidence(0.6);
// 訓練模型
FPGrowthModel model = fpg.fit(data);
// 展示頻繁項集
model.freqItemsets().show();
// 展示關聯規則
model.associationRules().show();
// 關閉SparkSession
spark.stop();
}
}
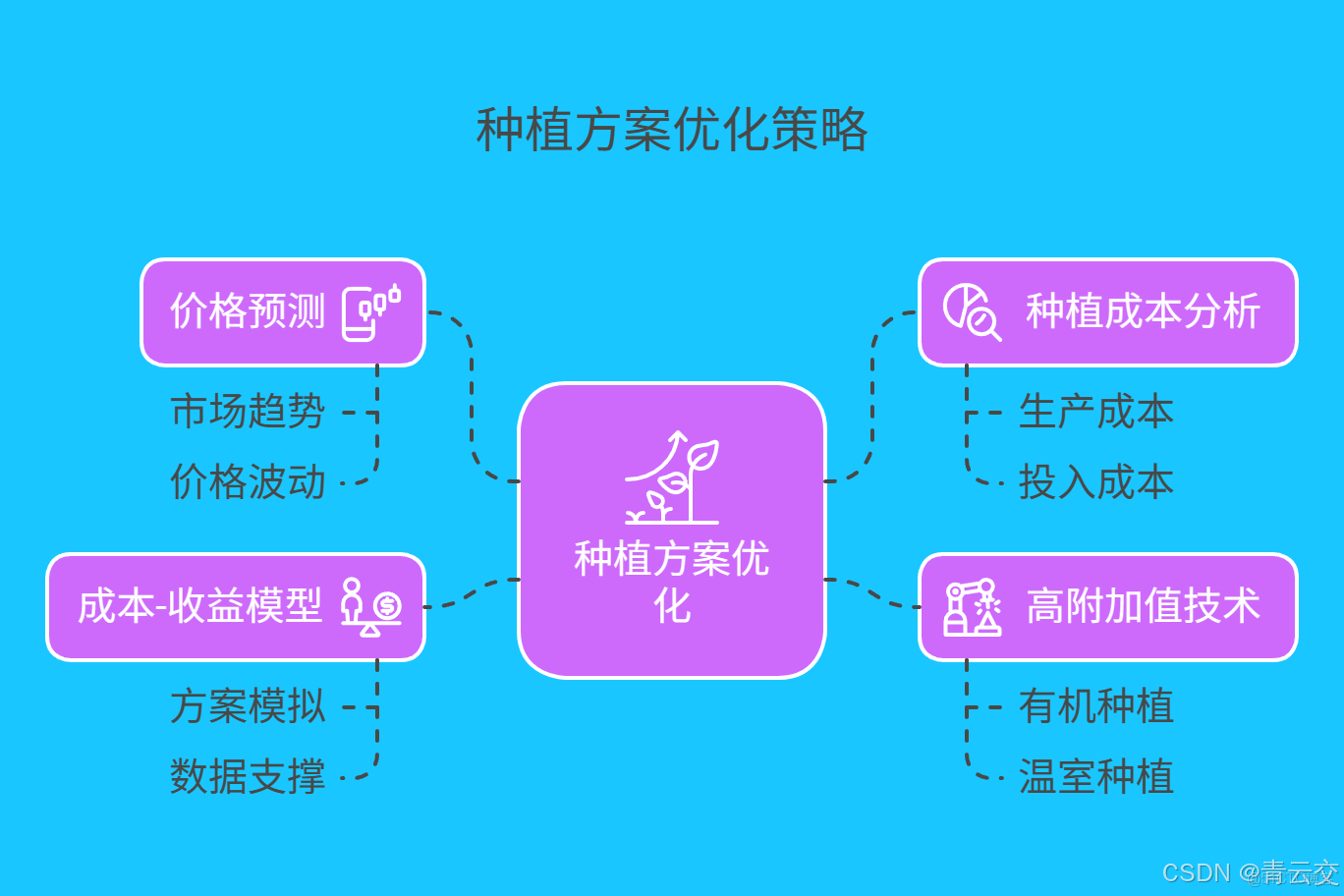
4.2 種植方案優化
科學的種植方案,是實現農業高產高效的關鍵。Java 大數據系統根據價格預測結果和種植成本分析,為農户提供優化的種植方案。當預測某種農產品價格上漲,但種植成本較高時,系統會建議農户適當減少種植面積,同時增加高附加值的種植技術投入,如採用有機種植、温室種植等方式,提高農產品品質和市場競爭力,從而實現收益最大化。通過建立成本 - 收益模型,對不同種植方案進行模擬和評估,為農户的決策提供堅實的數據支撐,讓每一份投入都能獲得最大的回報。
五、經典案例深度剖析
5.1 案例一:山東省壽光市蔬菜產業升級
山東省壽光市,被譽為 “中國蔬菜之鄉”,在這裏,Java 大數據技術掀起了一場蔬菜產業的智慧革命。當地政府在全市範圍內部署了 3000 多個傳感器,如同遍佈田野的 “神經末梢”,實時採集土壤墒情、氣象變化、病蟲害發生等數據。同時,從各大電商平台、批發市場採集海量的價格和銷售數據,構建起龐大的農業數據庫。
利用構建的 LSTM 價格預測模型,對 100 多種蔬菜價格進行 7 天、15 天、30 天的精準預測,平均預測準確率達到 85% 以上。基於價格預測和市場需求分析,系統為農户量身定製種植品種和種植面積方案。2022 年,在大數據的指導下,當地農户種植的彩椒、聖女果等特色蔬菜產量增加 20%,銷售價格提升 15%,帶動農户人均增收 1.2 萬元。不僅如此,通過大數據優化種植方案,農藥使用量減少 30%,實現了綠色生產和經濟效益的雙豐收。
| 指標 | 傳統模式 | 大數據模式 | 提升幅度 |
|---|---|---|---|
| 價格預測準確率 | 60% | 85% | ↑41.7% |
| 單位面積收益 | 8000 元 | 11200 元 | ↑40% |
| 農藥使用量 | - | ↓30% | - |
| 市場響應速度 | 滯後 1-2 季 | 實時調整 | - |
壽光市還建立了大數據驅動的供應鏈協同平台。通過 Java 開發的系統,將農户、批發商、零售商以及終端消費者緊密連接。當系統預測到某種蔬菜即將出現供應短缺時,會自動向農户發送擴種提醒,並同步告知下游經銷商提前做好採購準備。這種精準的供需匹配,使得壽光蔬菜在全國市場的佔有率提升了 12%,真正實現了 “種得好、賣得俏”。
5.2 案例二:黑龍江北大荒集團水稻種植決策支持
黑龍江北大荒集團擁有 500 萬畝廣袤農田,傳統種植模式下,由於缺乏科學決策依據,水稻產量和品質波動較大。引入 Java 大數據平台後,集團整合了農田土壤數據(包括酸鹼度、肥力指標等 20 餘項參數)、氣象數據(近 10 年的降水、光照、温度等歷史數據)、歷史產量數據以及市場稻穀價格數據,構建起農業大數據倉庫。
在 2023 年種植季,通過隨機森林模型對不同水稻品種在各個地塊的產量和收益進行預測。模型分析發現,“龍粳 31” 品種在富含有機質的地塊種植,預計產量比常規品種高 15%,且市場收購價格高出 20%。集團依據該預測結果,調整種植計劃,種植 “龍粳 31” 達 20 萬畝。收穫季節,實際產量達 12.3 萬噸,比預期產量高出 5%;通過與電商平台合作,實現溢價銷售,增收 1.2 億元。
此外,系統還通過大數據優化灌溉和施肥方案。利用迴歸模型分析土壤濕度、氣象數據與水稻需水量的關係,精準控制灌溉時間和水量,節約水資源 25%;結合水稻生長週期和土壤肥力,推薦個性化施肥方案,降低化肥使用成本 18%。北大荒集團的實踐證明,Java 大數據不僅能提高農業生產效益,還能推動綠色可持續發展。
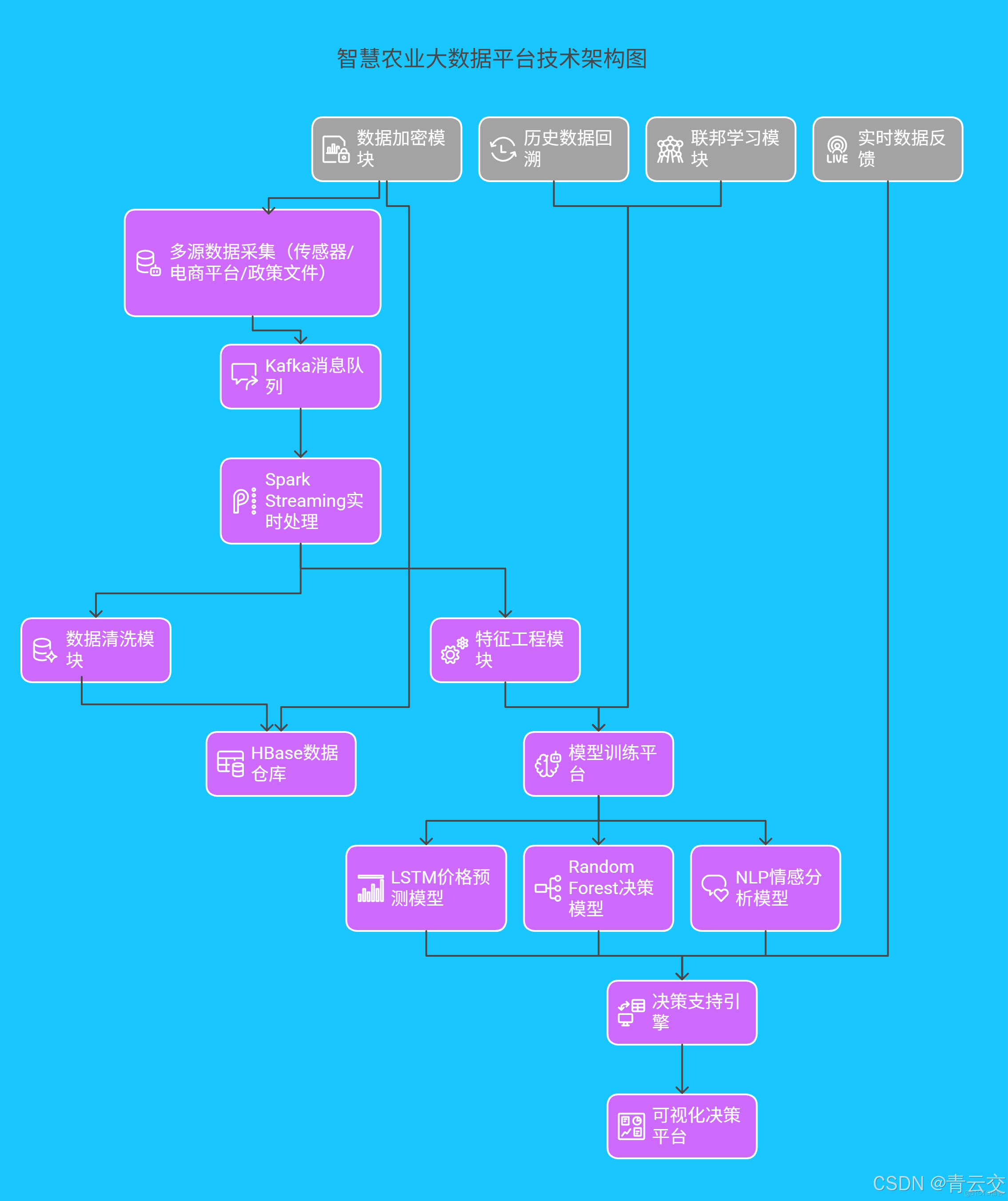
六、技術架構全景展示
請看下面智慧農業大數據平台技術架構圖:
七、農業數據安全與合規實踐
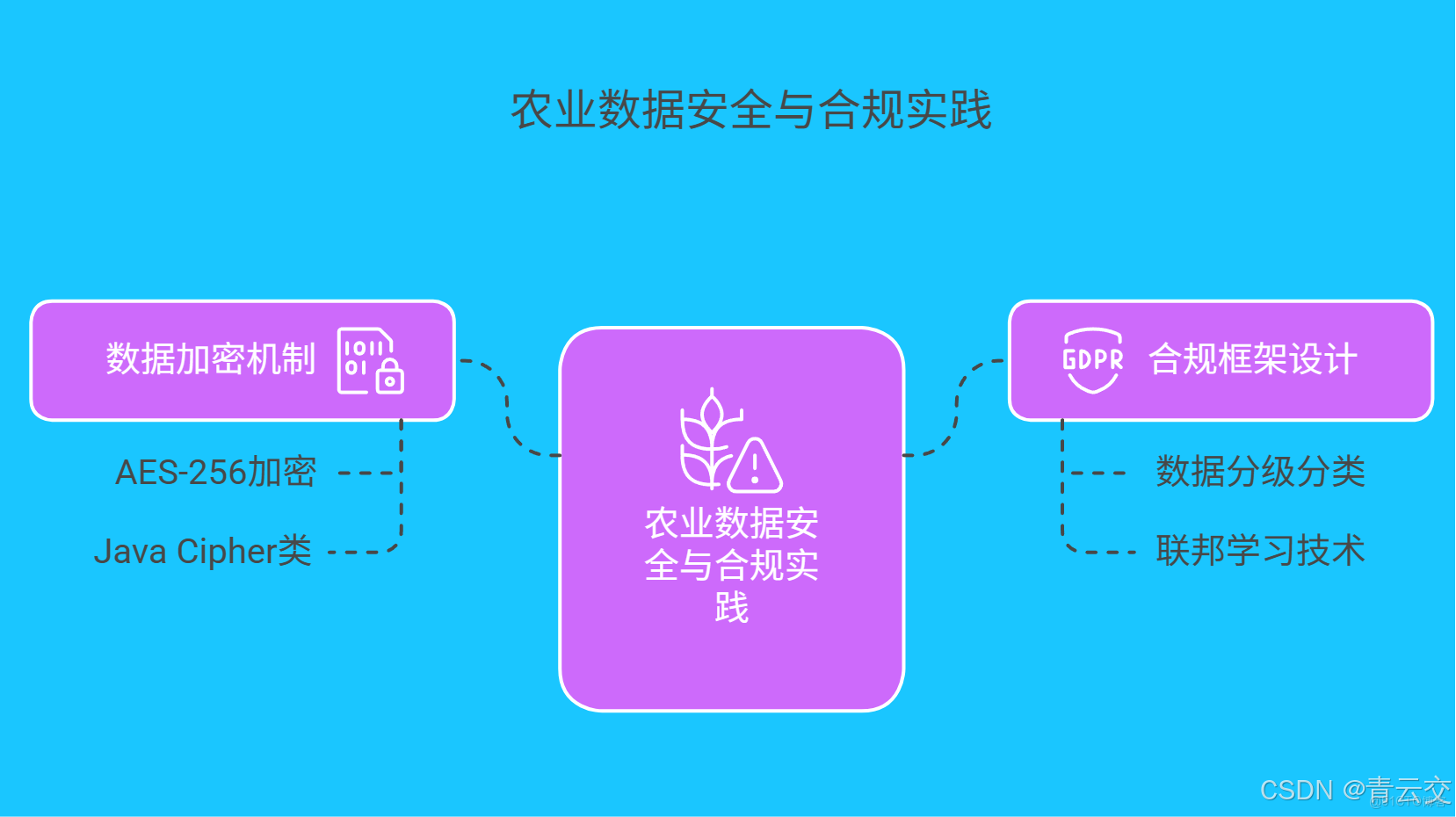
在智慧農業發展過程中,數據安全與合規至關重要。農業數據涉及農户個人信息、種植隱私以及商業機密,一旦泄露將造成嚴重後果。
- 數據加密機制:採用 AES-256 高級加密標準對傳感器採集的土壤數據、氣象數據等敏感信息進行加密。通過 Java 的
Cipher類實現加密和解密操作:
import javax.crypto.Cipher;
import javax.crypto.KeyGenerator;
import javax.crypto.SecretKey;
import java.security.NoSuchAlgorithmException;
import java.security.SecureRandom;
public class DataEncryption {
public static void main(String[] args) {
try {
// 生成密鑰
KeyGenerator keyGen = KeyGenerator.getInstance("AES");
keyGen.init(256, new SecureRandom());
SecretKey secretKey = keyGen.generateKey();
// 創建Cipher實例並初始化為加密模式
Cipher cipher = Cipher.getInstance("AES");
cipher.init(Cipher.ENCRYPT_MODE, secretKey);
String originalData = "土壤濕度: 60%";
byte[] encryptedData = cipher.doFinal(originalData.getBytes());
System.out.println("加密後數據: " + new String(encryptedData));
// 解密數據
cipher.init(Cipher.DECRYPT_MODE, secretKey);
byte[] decryptedData = cipher.doFinal(encryptedData);
System.out.println("解密後數據: " + new String(decryptedData));
} catch (Exception e) {
e.printStackTrace();
}
}
}
- 合規框架設計:遵循《農業數據安全法》《個人信息保護法》等法規要求,建立數據分級分類制度。將數據分為公開數據、內部數據、敏感數據三類,針對不同級別數據採取不同的保護措施。在跨機構數據共享和聯合建模場景中,採用聯邦學習技術,實現數據 “不動模型動”,在保護數據隱私的前提下,完成模型訓練和優化。
結束語:
親愛的 Java 和 大數據愛好者,從破解農產品價格波動的謎題,到實現科學精準的種植決策,Java 大數據為智慧農業的發展注入了強大動力,讓傳統農業煥發出新的生機與活力。
親愛的 Java 和 大數據愛好者,在智慧農業的發展進程中,你認為 Java 大數據還能在哪些方面實現新的突破?對於農業數據的共享與隱私保護,你又有哪些獨到的見解和建議?歡迎在評論區分享您的寶貴經驗與見解。
為了讓後續內容更貼合大家的需求,誠邀各位參與投票,Java 大數據的下一站,由你決定!快來投出你的寶貴一票。