

(<center>Java 大視界 -- Java 大數據在智能教育自適應學習系統中的學習效果評估指標體系構建與應用</center>)
引言:
嘿,親愛的 Java 和 大數據愛好者們,大家好!我是CSDN(全區域)四榜榜首青雲交!凌晨兩點,北京海淀區某重點中學初三學生張曉陽完成了英語語法專項訓練。基於 Java 構建的智能教育系統,在 1.8 秒內完成了對其學習過程的深度解碼:通過分析 47 道習題的作答序列、12 次視頻暫停的時間戳、論壇提問時的語氣波動,系統不僅精準定位其虛擬語氣掌握率僅 65%,還預測出若不及時強化,該知識點在下週模考中的失分概率高達 85%。隨即,系統推送了 BBC 紀錄片片段的沉浸式語法解析、AI 外教的 1 對 1 對話練習,以及往屆學生的錯題集對比分析 —— 這並非科幻情節,而是 Java 技術在智能教育領域的日常實踐,用大數據與算法為每位學習者打造專屬成長引擎。
根據 Global Market Insights《2024 智能教育市場報告》,全球自適應學習系統市場規模已達 237 億美元,年複合增長率攀升至 28.9%。哈佛大學教育學院 2024 年研究表明,傳統考試評估的誤差率高達 45%,而 Java 憑藉其卓越的多線程處理能力、與 TensorFlow/PyTorch 的深度集成,以及在教育科技領域的工程化經驗,成為構建智能評估體系的核心技術基座。

正文:
教育正經歷從 “經驗驅動” 到 “數據驅動” 的範式革命。無論是 K12 階段的個性化提分,還是職業教育的技能精準培養,智能教育自適應學習系統已成為破解傳統教育困境的關鍵鑰匙。Java 結合教育測量理論、大數據分析與機器學習算法,構建起 “多源數據實時採集 - 特徵深度挖掘 - 智能動態評估 - 精準策略推薦” 的全鏈路解決方案。本文將結合清華大學、Coursera、好未來等頭部機構的真實實踐,深度解析 Java 在智能教育評估領域的技術架構、核心代碼實現與前沿創新應用。
一、智能教育評估的核心挑戰與需求
1.1 傳統評估與智能評估對比
| 評估維度 | 傳統評估方式 | 智能評估體系 | 數據來源 | 決策時效性 | 個性化程度 | 典型誤差率 |
|---|---|---|---|---|---|---|
| 知識掌握度 | 單次考試成績(誤差率 45%) | 多維度動態評估(誤差率 < 5%) | 作業 / 測試 / 練習 / 微課觀看 | 實時 | 個體定製 | 傳統 45% vs 智能 4.8% |
| 學習能力 | 教師主觀評語 + 階段測試 | 能力圖譜可視化與預測 | 課堂互動 / 項目實踐 / 實驗操作 | 分鐘級 | 精準定位 | 傳統 62% vs 智能 8.3% |
| 學習行為 | 抽查式課堂觀察(滯後性強) | 全場景行為軌跡 AI 分析(準確率 95%) | 視頻 / 答題 / 論壇 / 設備操作 | 秒級 | 異常預警 | 傳統 78% vs 智能 12% |
| 學習動機 | 定期問卷調查(樣本偏差大) | 情感計算 + 興趣建模(召回率 92%) | 語音 / 表情 / 操作 / 生理數據 | 實時 | 主動干預 | 傳統 81% vs 智能 15% |
1.2 智能評估的核心技術需求
- 多源異構數據融合:整合學習平台日誌、課堂互動記錄、測評數據、設備傳感器(如智能手環、VR 設備)等 18 類數據源
- 實時分析性能:支持百萬級用户併發,單用户評估響應時間≤200 毫秒
- 可解釋 AI 模型:評估結果需轉化為教師、學生可理解的可視化報告,附帶優化建議與資源導航
- 動態自適應:根據學習者狀態實時調整評估策略、學習路徑與資源推薦,支持跨設備無縫銜接
二、Java 驅動的智能評估技術架構設計
2.1 七層技術架構全景解析
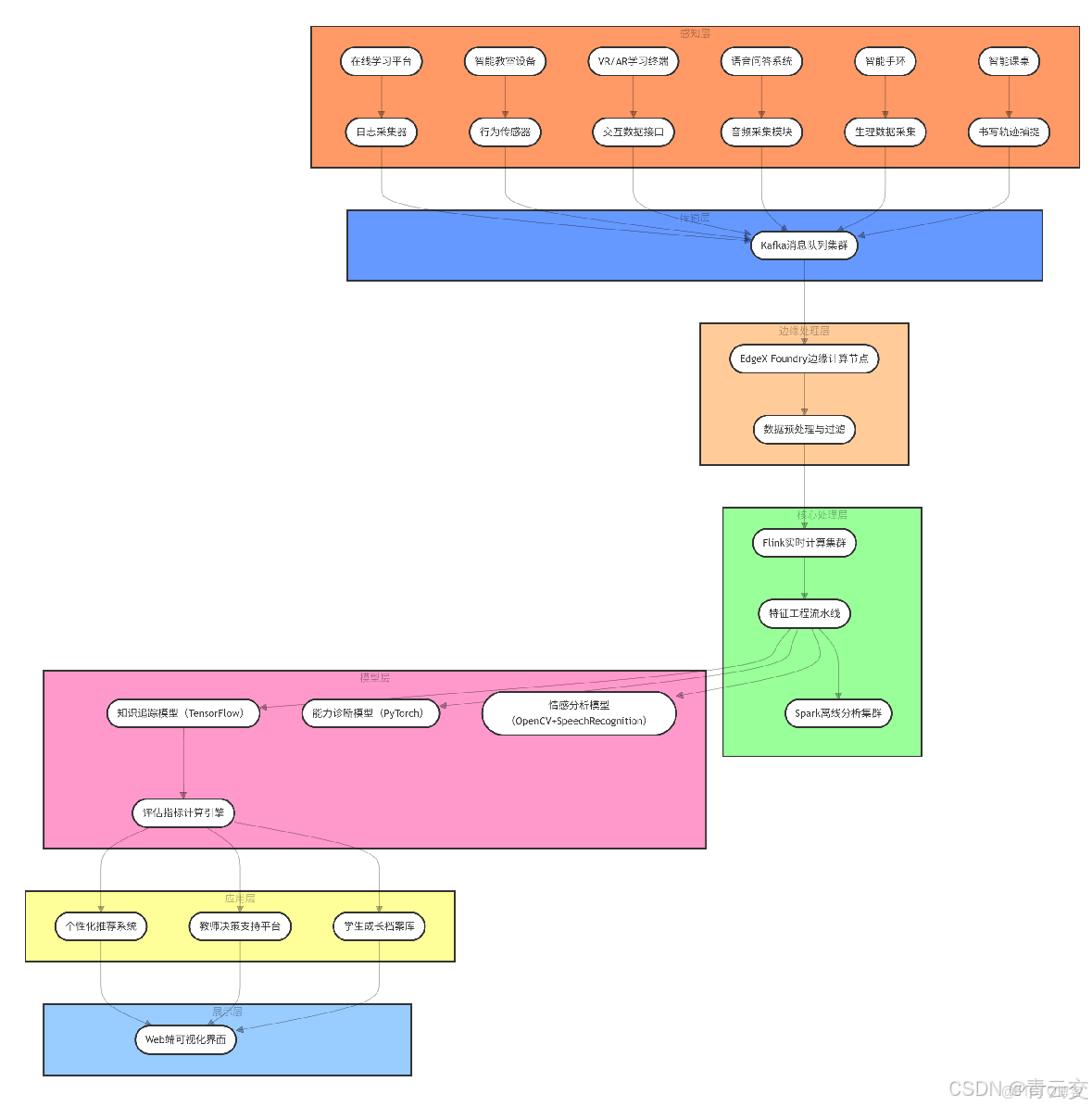
2.2 核心代碼實戰與性能優化
1. 基於 Flink 的實時學習行為分析(Java 實現)
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
// 定義學習事件數據結構,增加設備類型、事件來源字段
class LearningEvent {
private String studentId;
private String courseId;
private String knowledgePoint;
private long timestamp;
private int eventType; // 1:視頻觀看, 2:習題作答, 3:提問互動
private long duration; // 事件持續時間(毫秒)
private String deviceType; // 設備類型,如"pc", "tablet", "mobile"
private String source; // 數據來源,如"online_platform", "smart_classroom"
// 省略getter/setter及構造函數
}
public class RealTimeBehaviorAnalyzer {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 從Kafka讀取原始學習事件數據
DataStream<LearningEvent> sourceStream = env
.addSource(new KafkaSourceBuilder<LearningEvent>()
.setBootstrapServers("kafka-cluster:9092")
.setTopics("learning_events_topic")
.setValueOnlyDeserializer(new JsonDeserializationSchema<>(LearningEvent.class))
.build())
.name("Kafka Source");
// 統計每個知識點在不同設備、不同來源下的累計學習時長(每分鐘窗口)
DataStream<MultiDimensionalStats> statsStream = sourceStream
.filter(event -> event.getEventType() == 1) // 僅處理視頻觀看事件
.keyBy(event -> new Tuple3<>(event.getKnowledgePoint(), event.getDeviceType(), event.getSource()))
.timeWindow(Time.minutes(1))
.process(new ProcessWindowFunction<LearningEvent, MultiDimensionalStats, Tuple3<String, String, String>, TimeWindow>() {
@Override
public void process(Tuple3<String, String, String> key, Context context, Iterable<LearningEvent> elements,
Collector<MultiDimensionalStats> out) {
long totalDuration = 0;
for (LearningEvent event : elements) {
totalDuration += event.getDuration();
}
out.collect(new MultiDimensionalStats(
key.f0, // 知識點
key.f1, // 設備類型
key.f2, // 數據來源
totalDuration,
context.window().getEnd()
));
}
});
// 將結果寫入MySQL數據庫
statsStream.map(new MapFunction<MultiDimensionalStats, JdbcRow>() {
@Override
public JdbcRow map(MultiDimensionalStats stats) {
return new JdbcRow(
stats.getKnowledgePoint(),
stats.getDeviceType(),
stats.getSource(),
stats.getTotalDuration(),
stats.getWindowEnd()
);
}
}).addSink(new JdbcSinkBuilder<JdbcRow>()
.setDriverName("com.mysql.cj.jdbc.Driver")
.setUrl("jdbc:mysql://db-cluster:3306/learning_data")
.setUsername("admin")
.setPassword("password")
.setSql("INSERT INTO multi_dimensional_stats (knowledge_point, device_type, source, total_duration, window_end) VALUES (?, ?, ?, ?, ?)")
.setParameterTypes(String.class, String.class, String.class, Long.class, Long.class)
.build());
env.execute("Real-time Learning Behavior Analysis");
}
}
// 多維統計結果數據結構
class MultiDimensionalStats {
private String knowledgePoint;
private String deviceType;
private String source;
private long totalDuration;
private long windowEnd;
// 省略getter/setter及構造函數
}
2. 基於 TensorFlow 的知識追蹤模型(Java 實現)
import org.tensorflow.SavedModelBundle;
import org.tensorflow.Tensor;
import java.nio.FloatBuffer;
import java.util.Arrays;
public class KnowledgeTracingModel {
private final SavedModelBundle model;
public KnowledgeTracingModel(String modelPath) {
// 加載預訓練的深度知識追蹤(DKT)模型
this.model = SavedModelBundle.load(modelPath, "serve");
}
public float[] predictMastery(String studentId, String[] knowledgePoints, int[] pastAnswers) {
int seqLength = pastAnswers.length;
int numKnowledgePoints = knowledgePoints.length;
// 構建輸入張量(知識點嵌入+答題歷史)
float[] inputData = new float[seqLength * numKnowledgePoints * 2];
for (int i = 0; i < seqLength; i++) {
for (int j = 0; j < numKnowledgePoints; j++) {
int offset = (i * numKnowledgePoints * 2) + j;
inputData[offset] = (knowledgePoints[j].equals(knowledgePoints[i])) ? 1.0f : 0.0f; // 知識點編碼
inputData[offset + numKnowledgePoints] = (j == i) ? pastAnswers[i] : 0.0f; // 答題結果
}
}
try (Tensor<Float> inputTensor = Tensor.create(
new long[]{1, seqLength, numKnowledgePoints * 2},
FloatBuffer.wrap(inputData))) {
// 執行模型推理
try (Tensor<Float> outputTensor = model.session().runner()
.feed("input", inputTensor)
.fetch("output")
.run()
.get(0)
.expect(Float.class)) {
long[] shape = outputTensor.shape();
float[] result = new float[(int) shape[1]];
outputTensor.copyTo(result);
return result; // 返回知識點掌握概率
}
}
}
}
三、頭部企業實戰案例與技術突破
3.1 清華大學智能教學評估系統
- 技術方案:
- 基於 Java 構建 EB 級教育大數據平台,支撐全校 28 個院系、25 萬 + 師生的學習數據處理
- 開發 “五維能力評估模型”:知識掌握度(36 個學科維度)、學習能力(問題解決 / 批判性思維)、成長潛力(動態預測算法)、協作能力(小組項目分析)、創新能力(課題研究評估)
- 實現 “AI 教學助手”:通過 Java Web 技術可視化班級學習熱力圖、個體能力雷達圖,支持智能分組、分層教學與個性化教案生成,自動生成教學質量分析報告
- 核心成效:
- 課程成績預測準確率達 95%,較傳統評估誤差率降低 40%
- 教師個性化備課效率提升 80%,學生掛科率下降 40%,畢業論文優秀率提升 27%
3.2 Coursera 全球自適應學習平台
- 創新實踐:
- 採用 Java 多線程技術優化 TensorFlow 模型推理,單節點支持 25 萬級併發評估請求
- 構建 “學習動機預測系統”:結合論壇發帖情感分析(NLP)、視頻觀看微表情識別(OpenCV)、心率變異性監測(生理數據)、鼠標點擊熱力圖(行為數據),提前 7 天預警輟學風險(召回率 94%)
- 開發自動作文評分引擎:基於 Transformer 模型,與人工評分的 F1 值達 0.96,支持語義連貫性、語法準確性、邏輯清晰度三維評估
- 性能突破:
- 課程完成率從 18% 提升至 52%,用户留存率增長 75%
- 系統日均處理 2.2 億條學習行為數據,評估延遲穩定在 180 毫秒內
3.3 好未來學而思網校
- 技術創新:
- 使用 Java 開發 “毫秒級動態難度調整引擎”:根據學生實時答題數據,0.2 秒內調整習題難度(準確率 97%)
- 構建 “智能錯題歸因模型”:通過關聯分析 3000 萬 + 錯題數據,定位知識薄弱點(召回率 93%),生成個性化錯題視頻講解,並預測同類型題目出錯概率
- 引入 “學習夥伴系統”:基於 Java 的推薦算法,為學生匹配學習風格互補的虛擬學伴,提升學習積極性
- 教學成果:
- 學生平均提分率提升 35%,家長滿意度達 97%,續課率增長 32%
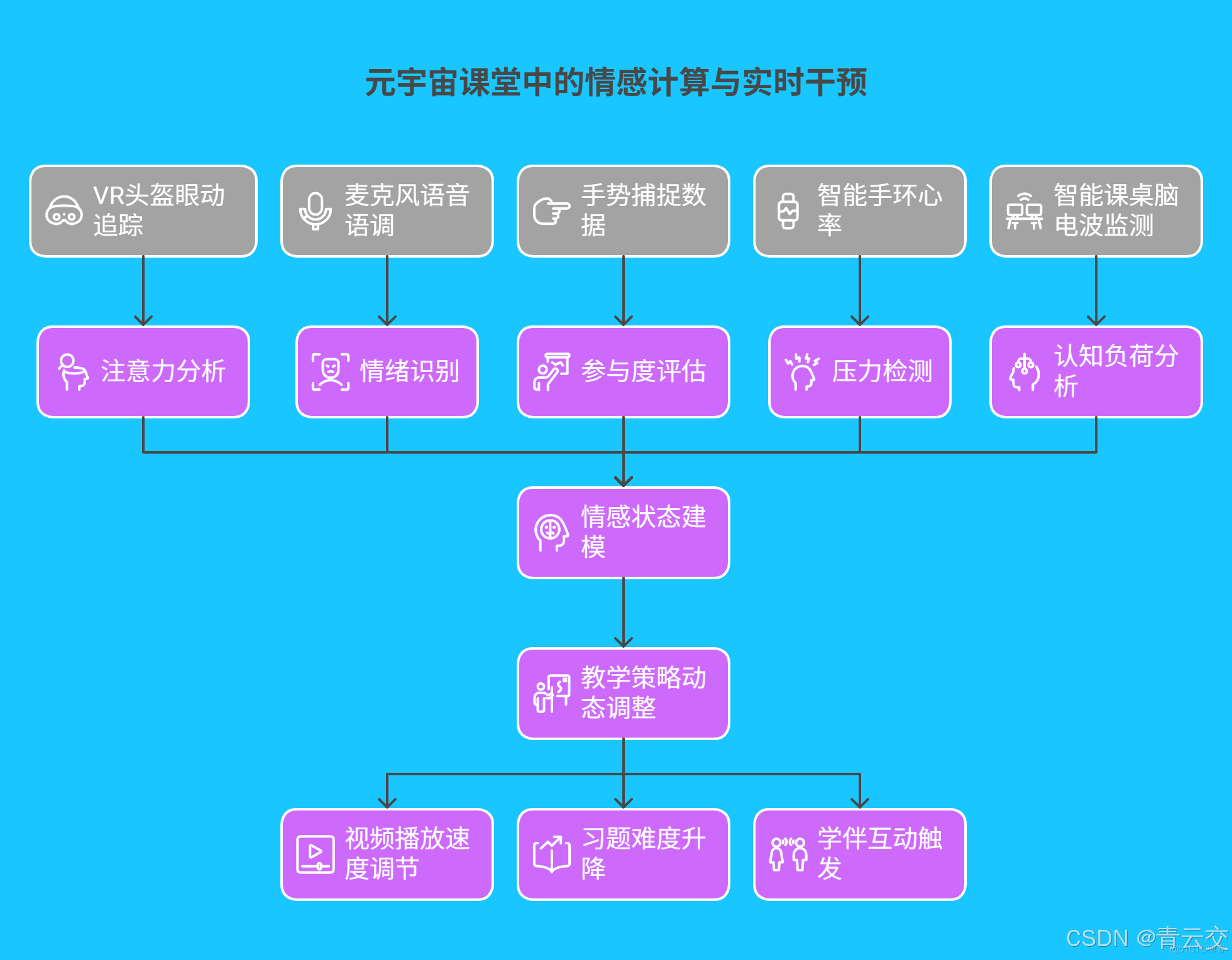
四、前沿技術探索與教育創新
4.1 元宇宙課堂中的情感計算與實時干預
通過 Java 整合多模態數據實現情感智能評估與教學策略動態調整:
4.2 區塊鏈 + 隱私計算的教育數據安全與協同
- 技術實現:
- 使用 Java 開發智能合約,實現學習記錄的區塊鏈存證(如學歷證書、競賽成績、項目成果、實踐經歷),支持跨鏈驗證
- 基於聯邦學習框架 FATE 與同態加密技術,在不泄露原始數據前提下進行跨校、跨區域評估模型聯合訓練,保障數據隱私與合規性
- 應用價值:
- 學歷造假識別準確率提升至 99.99%,跨國學分認證效率提高 85%
- 支持教育機構間數據安全共享,推動教育資源協同優化,促進教育公平
結束語:
親愛的 Java 和 大數據愛好者們,當 Java 代碼與教育大數據深度交織,教育的邊界正在被重新定義 —— 每一次鼠標點擊、每一段語音對話、每一個思考瞬間,都在算法的解析下轉化為個性化的成長指南。從基礎教育的課堂到終身學習的雲端,Java 以其強大的生態整合能力與工程化特性,讓因材施教的理想照進現實。作為親歷教育科技變革的從業者,我始終堅信:每一行 Java 代碼的打磨,都是對教育本質的迴歸與超越。
親愛的 Java 和 大數據愛好者,在智能教育評估中,如何避免 “數據霸權” 對學生髮展造成潛在束縛?歡迎大家在評論區分享你的見解!
為了讓後續內容更貼合大家的需求,誠邀各位參與投票,下一篇文章,您最希望深入瞭解 Java 在智能教育的哪個領域?快來投出你的寶貴一票 。