

(<center>Java 大視界 -- 基於 Java 的大數據實時流處理在能源行業設備狀態監測與故障預測中的應用</center>)
引言:
嘿,親愛的 Java 和 大數據愛好者們,大家好!我是CSDN(全區域)四榜榜首青雲交!在《大數據新視界》和《 Java 大視界》系列的探索之旅中,我們已一同領略 Java 大數據在多個領域的非凡魅力。從智能教育領域用數據重塑教學模式,到智能安防領域構建堅不可摧的安全防線;從短視頻平台突破數據存儲難題,到智慧交通優化城市出行體驗等等,每一篇文章都像是一座燈塔,照亮了技術應用的新方向。如今,能源行業正站在智能化轉型的關鍵路口。傳統的設備管理方式在面對複雜工況和海量數據時,逐漸顯得力不從心。而 Java 大數據實時流處理技術,就像一把鑰匙,有望打開能源行業高效運維與智能管理的新大門。接下來,就讓我們一同走進《Java 大視界 – 基於 Java 的大數據實時流處理在能源行業設備狀態監測與故障預測中的應用》,探尋它將如何為能源行業帶來變革。

正文:
一、能源行業設備管理的現狀與挑戰
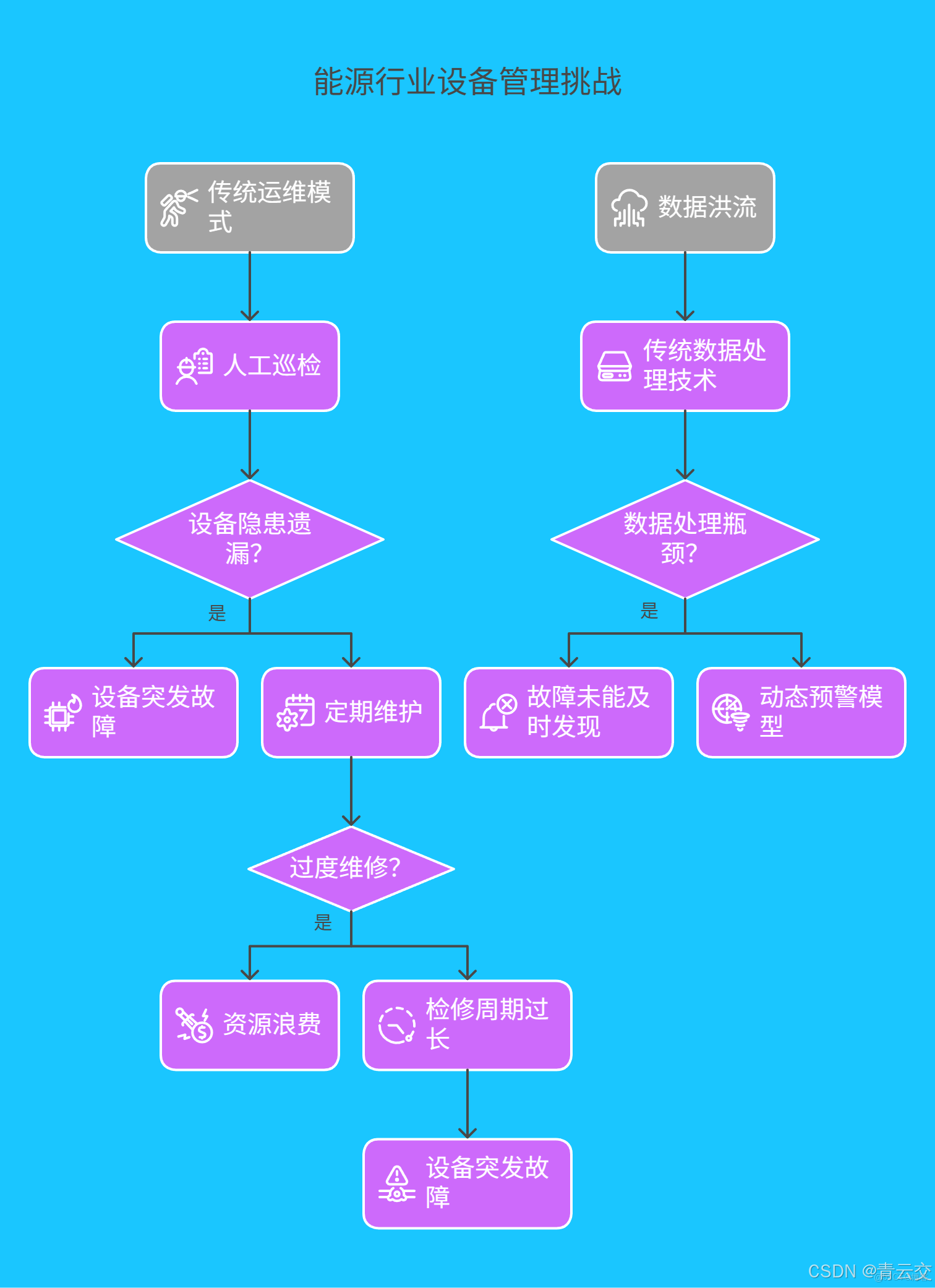
1.1 傳統運維模式的侷限性
傳統的能源設備運維,就如同在黑暗中摸索前行。以某大型火力發電廠為例,過去依賴人工巡檢,工程師們每天需要手持簡單的檢測工具,徒步檢查長達數十公里的管線和設備。即便如此,由於設備內部結構複雜,很多潛在問題僅憑肉眼和經驗難以察覺。據統計,約 30% 的設備隱患會被遺漏,這些隱患一旦爆發,就可能導致設備突發故障。2023 年,某熱電廠就因為汽輪機軸承異常振動未被及時發現,最終軸系斷裂,直接經濟損失超過 2000 萬元。而定期維護的方式也存在弊端,要麼過度維修造成資源浪費,要麼關鍵設備因檢修週期過長而突發故障,嚴重影響生產效率。
1.2 數據洪流與處理瓶頸
隨着能源設備的智能化程度越來越高,設備儼然成為了一座座 “數據工廠”。一座風電場的單颱風機,每分鐘就能產生超過 500 條傳感器數據,涵蓋轉速、扭矩、油温等 30 餘項指標。然而,傳統的數據批處理技術面對如此龐大且實時性極強的數據洪流,就像一輛老舊的馬車,難以跟上節奏。某光伏電站就曾因為採用 T + 1 的數據分析方式,導致組件熱斑故障未能及時發現和處理,最終年發電量損失高達 8% 。顯然,傳統方案無法及時捕捉設備運行過程中的細微變化,更難以建立有效的動態預警模型,這成為了能源行業智能化發展的一大阻礙。
二、Java 大數據實時流處理技術基石
2.1 多源異構數據的實時採集與匯聚
Java 憑藉其強大的跨平台能力和豐富的網絡編程庫,成為了能源數據採集的得力助手。通過 Socket 編程,Java 可以輕鬆與各類設備傳感器建立穩定連接,實時獲取數據。以智能電錶數據採集為例,以下是使用 Java 的 Socket 實現數據實時獲取的代碼,還採用了線程池來優化性能,確保高效採集:
import java.util.concurrent.*;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.HashMap;
import java.util.Map;
public class EnergySensorDataCollector {
// 傳感器數據接口URL數組,可根據實際情況添加或修改
private static final String[] SENSOR_URLS = {
"http://windTurbine1.com/data",
"http://solarPanel2.com/data",
"http://transformer3.com/data"
};
// 創建固定大小線程池,線程數與傳感器數量相同,充分利用資源
private static final ExecutorService executor = Executors.newFixedThreadPool(SENSOR_URLS.length);
public static Map<String, String> collectData() {
Map<String, String> dataMap = new HashMap<>();
try {
// 用於存儲每個線程的Future對象,方便獲取線程執行結果
Map<String, Future<String>> futureMap = new HashMap<>();
for (String url : SENSOR_URLS) {
// 提交任務到線程池,並保存Future對象
Future<String> future = executor.submit(() -> fetchData(url));
futureMap.put(url, future);
}
// 等待所有線程執行完畢,並獲取每個線程的執行結果
for (Map.Entry<String, Future<String>> entry : futureMap.entrySet()) {
dataMap.put(entry.getKey(), entry.getValue().get());
}
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
} finally {
// 關閉線程池,釋放資源
executor.shutdown();
}
return dataMap;
}
private static String fetchData(String urlStr) {
try {
URL url = new URL(urlStr);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
int responseCode = connection.getResponseCode();
if (responseCode == HttpURLConnection.HTTP_OK) {
java.io.BufferedReader in = new java.io.BufferedReader(
new java.io.InputStreamReader(connection.getInputStream()));
String inputLine;
StringBuilder response = new StringBuilder();
while ((inputLine = in.readLine()) != null) {
response.append(inputLine);
}
in.close();
return response.toString();
} else {
return "Error: " + responseCode;
}
} catch (Exception e) {
e.printStackTrace();
return "Fetch failed";
}
}
}
採集到的數據格式各異,需要進行歸一化處理。利用 Java 8 的 Stream API 結合 Apache Commons Lang3 工具庫,可以快速完成時間戳校準、異常值剔除等操作,確保數據的準確性和一致性:
import org.apache.commons.lang3.time.DateUtils;
import java.util.List;
import java.util.stream.Collectors;
public class EnergyDataPreprocessor {
public static List<EnergySensorData> cleanData(List<EnergySensorData> rawData) {
// 剔除温度異常數據,假設正常範圍為 -20℃ 到 120℃
return rawData.stream()
.filter(data -> data.getTemperature() >= -20 && data.getTemperature() <= 120)
.map(data -> {
// 統一時間戳格式,精確到分鐘
data.setTimestamp(DateUtils.truncate(data.getTimestamp(), java.util.Calendar.MINUTE));
return data;
})
.collect(Collectors.toList());
}
// 模擬EnergySensorData類,包含設備相關數據
static class EnergySensorData {
private double temperature;
private double vibration;
private java.util.Date timestamp;
// 省略getter/setter方法
}
}
2.2 實時流處理引擎的核心能力
Apache Flink 作為 Java 生態中強大的實時處理引擎,在能源領域大顯身手。它的 CEP(複雜事件處理)引擎能夠敏鋭捕捉設備運行過程中的異常模式。比如,當風力發電機葉片振動頻率連續 3 次超過閾值,並且油温同時驟升時,CEP 引擎會立即觸發預警。以下是基於 Flink 的設備異常檢測代碼示例,詳細展示瞭如何定義異常模式、提取異常數據:
import org.apache.flink.cep.CEP;
import org.apache.flink.cep.PatternSelectFunction;
import org.apache.flink.cep.PatternStream;
import org.apache.flink.cep.pattern.Pattern;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.OutputTag;
import java.util.List;
import java.util.Map;
public class EnergyEquipmentAnomalyDetection {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 假設從Kafka獲取設備傳感器數據,可根據實際數據源調整
DataStream<EnergySensorData> dataStream = env.addSource(new KafkaSensorSource());
// 定義異常模式:振動值連續3次超過閾值且温度上升
Pattern<EnergySensorData, ?> pattern = Pattern.<EnergySensorData>begin("start")
.where(data -> data.getVibration() > 80)
.next("next")
.where(data -> data.getVibration() > 80)
.next("end")
.where(data -> data.getVibration() > 80 && data.getTemperature() > data.getPreviousTemperature());
PatternStream<EnergySensorData> patternStream = CEP.pattern(dataStream.keyBy(EnergySensorData::getEquipmentId), pattern);
// 提取異常數據,將正常數據和異常數據分流
OutputTag<EnergySensorData> normalData = new OutputTag<>("normal") {};
DataStream<AnomalyEvent> anomalyStream = patternStream.select(
normalData,
(PatternSelectFunction<Map<String, List<EnergySensorData>>, AnomalyEvent>) patternMap -> {
EnergySensorData lastData = patternMap.get("end").get(0);
return new AnomalyEvent(lastData.getEquipmentId(), "Vibration & Temperature Anomaly", lastData.getTimestamp());
}
);
anomalyStream.print("Anomaly Alert: ");
env.execute("Energy Equipment Anomaly Detection");
}
// 模擬異常事件類,記錄異常設備ID、異常信息和時間
static class AnomalyEvent {
private String equipmentId;
private String message;
private java.util.Date timestamp;
public AnomalyEvent(String equipmentId, String message, java.util.Date timestamp) {
this.equipmentId = equipmentId;
this.message = message;
this.timestamp = timestamp;
}
// 省略getter/setter方法
}
}
Flink 的狀態管理機制也發揮着重要作用,它可以存儲設備的歷史運行數據,為故障預測模型提供豐富的上下文信息。例如,通過滑動窗口統計設備近 1 小時的平均轉速,判斷其是否偏離正常波動範圍,從而更準確地預測設備故障。
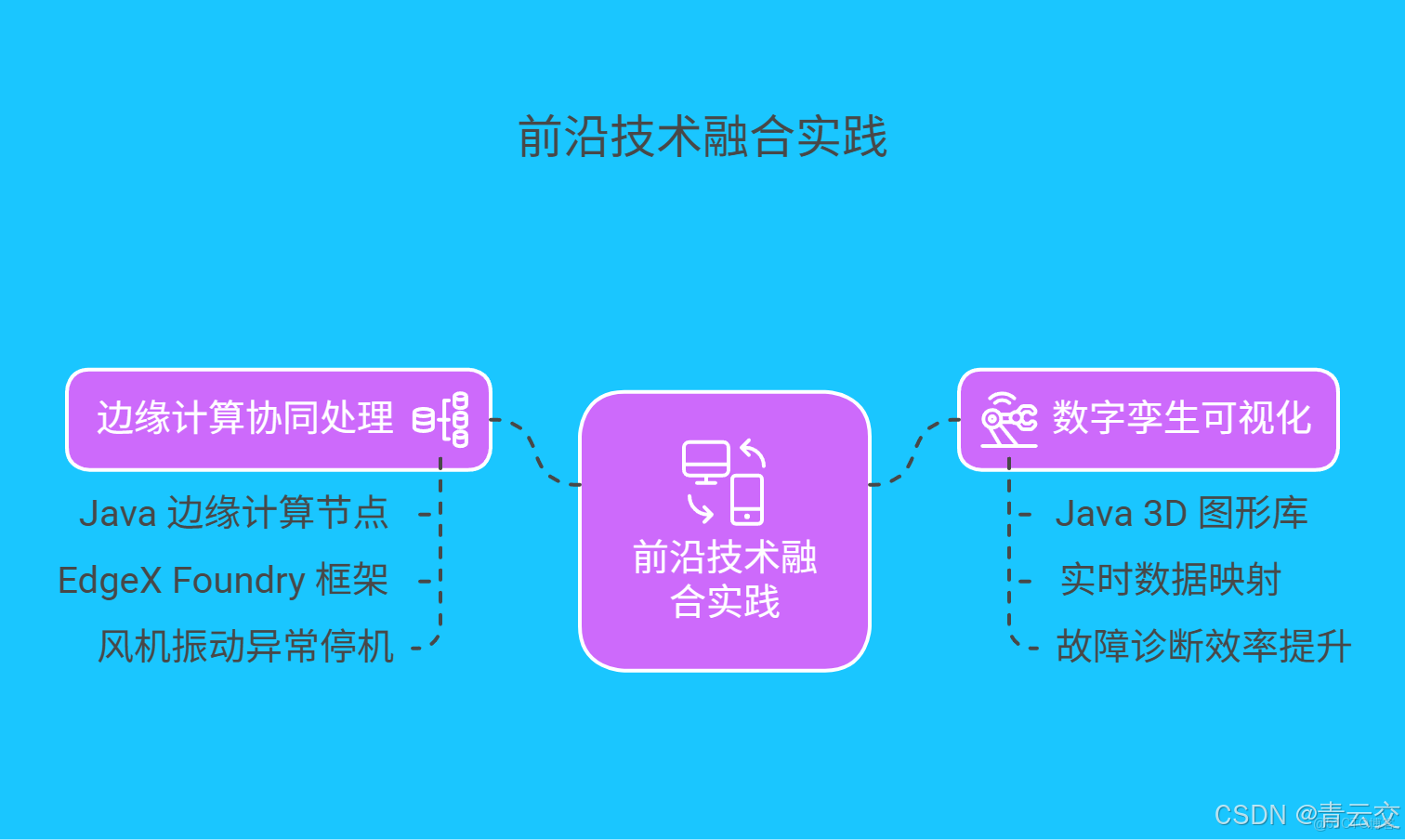
2.3 前沿技術融合實踐
- 邊緣計算協同處理:在能源設備現場,如風機、變電站等地,部署基於 Java 的邊緣計算節點,例如結合 EdgeX Foundry 框架與 Java 開發。這樣可以實現數據的預處理和本地決策,大大減少數據向雲端傳輸的壓力。當風機葉片出現振動異常時,邊緣節點能夠立即觸發停機指令,同時將關鍵數據上傳至雲端進行進一步分析。
- 數字孿生可視化:利用 Java 的 3D 圖形庫,如 JOGL ,構建能源設備的數字孿生模型。將實時監測到的數據映射到虛擬設備上,運維人員通過 Web 界面,就能直觀地查看設備內部結構和運行狀態。某燃氣輪機廠採用這一技術後,故障診斷效率提升了 60% ,極大地提高了運維效率。
三、Java 大數據在能源設備運維的創新應用
3.1 設備健康狀態實時監測
基於 Java 大數據實時流處理技術構建的設備健康度評分系統,就像一位 “智能醫生”,能夠將上千項傳感器指標轉化為直觀的健康指數。某核電站引入該系統後,將反應堆冷卻泵的運行狀態劃分為 “健康”“預警”“故障” 三個等級,並通過熱力圖進行可視化展示。運維人員通過電腦或移動設備,就能實時掌握全廠設備的健康狀況。系統運行後,設備異常發現時間從平均 4 小時縮短至 15 分鐘,大大提高了設備的安全性和可靠性。
3.2 故障預測與主動維護
融合 LSTM(長短期記憶網絡)與隨機森林算法,Java 可以構建高精度的故障預測模型。某石油煉化企業對裂解爐進行預測性維護時,通過實時分析爐膛壓力、進料温度等 12 項關鍵參數,該模型能夠提前 72 小時預測出爐管結焦風險,準確率高達 93% 。與傳統維護模式相比,該企業年度非計劃停機時間減少了 40% ,維修成本降低了 28% ,經濟效益顯著提升。以下是故障預測模型的關鍵代碼實現,還增加了動態閾值調整功能,使模型更加智能:
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.LSTM;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.lossfunctions.LossFunctions;
public class EnergyEquipmentFailurePrediction {
// 動態閾值調整參數,根據模型預測情況動態調整
private static double thresholdMultiplier = 1.2;
public static MultiLayerNetwork buildLSTMModel() {
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(12345)
.weightInit(org.deeplearning4j.nn.weights.WeightInit.XAVIER)
.list()
.layer(new LSTM.Builder()
.nIn(10) // 假設輸入10個特徵
.nOut(50)
.activation(Activation.TANH)
.build())
.layer(new LSTM.Builder()
.nIn(50)
.nOut(50)
.activation(Activation.TANH)
.build())
.layer(new OutputLayer.Builder()
.nOut(2) // 正常/故障二分類
.activation(Activation.SOFTMAX)
.lossFunction(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.build())
.build();
return new MultiLayerNetwork(conf);
}
public static void main(String[] args) {
MultiLayerNetwork model = buildLSTMModel();
model.init();
// 假設從Flink實時數據流獲取訓練數據,可根據實際數據源調整
DataSetIterator dataIterator = new EnergySensorDataIterator();
while (dataIterator.hasNext()) {
DataSet batch = dataIterator.next();
INDArray features = batch.getFeatureMatrix();
INDArray labels = batch.getLabels();
model.fit(features, labels);
// 動態調整預測閾值
INDArray predictions = model.output(features);
double avgConfidence = predictions.meanNumber().doubleValue();
if (avgConfidence > 0.7) {
thresholdMultiplier = 1.0;
} else if (avgConfidence < 0.3) {
thresholdMultiplier = 1.5;
}
}
// 預測新數據並應用動態閾值
INDArray newData = dataIterator.next().getFeatureMatrix();
INDArray prediction = model.output(newData);
boolean isAnomaly = prediction.getDouble(0, 1) > 0.5 * thresholdMultiplier;
System.out.println("預測結果: " + isAnomaly);
}
}
3.3 能源生產優化與節能增效
通過實時分析設備能耗數據,Java 大數據可以挖掘出巨大的節能潛力。某鋼鐵企業利用這一技術,對高爐鼓風機的運行參數進行實時監測和分析,並利用遺傳算法動態調整風機轉速。同時,結合實時電價數據,優化生產時段。系統運行半年後,噸鋼能耗降低了 12% ,年節約電費超過 5000 萬元,實現了經濟效益和環境效益的雙贏。
四、標杆案例深度剖析
4.1 案例一:國家電網智能變電站升級
國家電網某 500kV 變電站部署 Java 大數據實時處理平台後,實現了華麗蜕變:
- 技術架構:接入 2000 多路傳感器,日均處理 15TB 實時數據,強大的數據處理能力為設備監測和分析提供了堅實基礎;
- 監測能力:基於 Flink 的實時計算,設備異常檢測延遲從分鐘級大幅降至 500 毫秒,能夠迅速發現設備異常;
- 預測效果:變壓器油色譜分析模型提前 14 天預警絕緣故障,準確率高達 95% ,有效預防故障發生;
- 經濟效益:年度非計劃停電時間減少 85% ,供電可靠性提升至 99.999% ,為用户提供了更穩定的電力供應。
| 指標 | 傳統方案 | 智能方案 | 提升幅度 |
|---|---|---|---|
| 異常檢測延遲 | 5 分鐘 | 500 毫秒 | ↓98.3% |
| 故障預測準確率 | 62% | 95% | ↑53.2% |
| 年停電損失(萬元) | 2800 | 420 | ↓85% |
4.2 案例二:海上風電場智能運維
某海上風電場面臨着惡劣的環境條件和複雜的設備運維挑戰,引入 Java 大數據方案後成功實現智能化轉型:
- 數據融合:整合氣象數據(風速、風向、浪高)、風機運行數據(葉片角度、發電機功率、齒輪箱温度)以及無人機巡檢圖像數據,構建多維度數據模型。通過 Java 編寫數據融合算法,將不同格式、不同頻率的數據統一處理,例如將每分鐘採集的傳感器數據與每小時更新的氣象數據進行時間對齊關聯。
- 預測模型:基於 LSTM 的齒輪箱故障預測模型,通過分析振動頻譜、油温變化率等特徵,可提前 30 天預警軸承磨損。模型訓練階段,利用 Java 多線程技術加速數據預處理和模型迭代,將原本需要 72 小時的訓練時間縮短至 24 小時。部署後,成功避免 3 次重大齒輪箱故障,單次故障可減少直接經濟損失超 150 萬元。
- 運維優化:開發智能運維調度系統,根據故障預測結果和氣象條件動態規劃維護路線。當預測到某颱風機將出現葉片結冰風險時,系統自動規劃最近的維護船航線,並結合實時海況調整出發時間。通過該系統,單颱風機年均可利用率從 88% 提升至 96%,年發電量增加 120 萬度,相當於滿足約 500 户家庭一年的用電量。

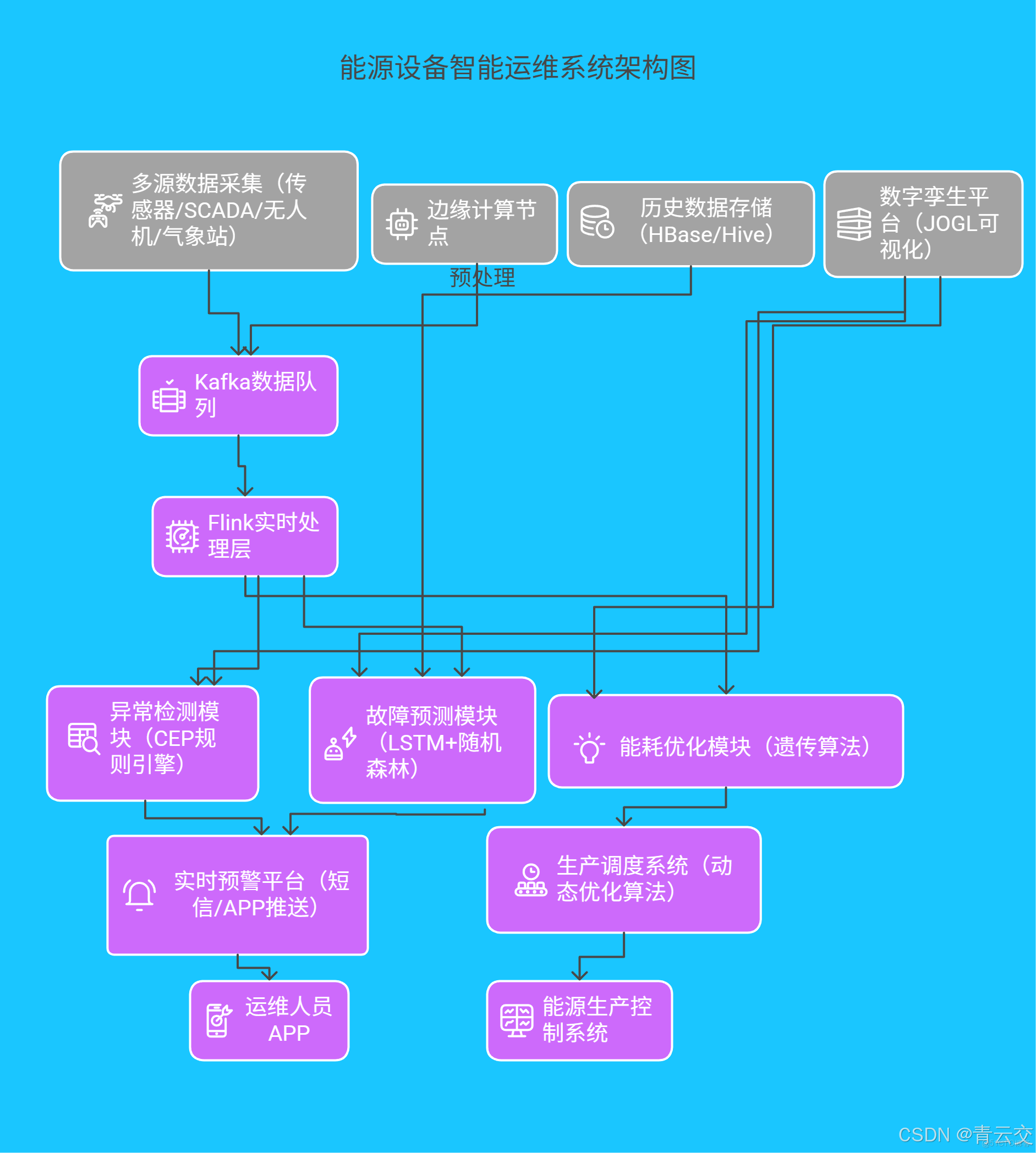
五、技術架構全景呈現
請看如下能源設備智能運維繫統架構圖:
結束語:
親愛的 Java 和 大數據愛好者們,從打破傳統運維困局到重塑能源生產新範式,Java 大數據實時流處理技術正以 “數字引擎” 的姿態,驅動能源行業邁向智能化未來。
親愛的 Java 和 大數據愛好者,在能源設備智能化運維的道路上,你認為還有哪些技術難題需要攻克?對於 Java 大數據與邊緣計算、數字孿生的進一步融合,你有哪些期待和想法?歡迎在評論區分享您的寶貴經驗與見解。
為了讓後續內容更貼合大家的需求,誠邀各位參與投票,Java 大數據的下一個技術巔峯,由你決定!快來投出你的寶貴一票。