

全文鏈接:https://tecdat.cn/?p=44265
原文出處:拓端數據部落公眾號
分析師:Liu Qing

引言
在創新驅動發展戰略深入推進的當下,企業研發投入成為經濟高質量發展的核心動力,而研發費用加計扣除、高新技術企業税收優惠等政策,既激發了企業創新活力,也催生了部分企業的研發操縱行為。這類通過虛增研發支出、調整會計處理方式套取政策紅利的行為,不僅導致創新資源錯配,還破壞了市場公平競爭秩序。傳統研究多依賴線性迴歸方法,難以捕捉研發操縱影響因素的非線性關係與交互效應,預測精度和可解釋性不足。
本文改編自我們為某監管機構提供的上市公司研發行為監測諮詢項目,核心是通過機器學習技術破解研發操縱識別難題。項目團隊整合2012-2023年中國A股上市公司數據,從CEO個人特質、公司財務特徵、公司治理特徵三個維度構建預測體系,運用多種機器學習算法實現研發操縱行為的精準識別與影響因素量化。
本文內容源自過往項目技術沉澱與已通過實際業務校驗,該項目完整代碼與數據已分享至交流社羣。閲讀原文進羣,可與600+行業人士交流成長;還提供人工答疑,拆解核心原理、代碼邏輯與業務適配思路,幫大家既懂怎麼做,也懂為什麼這麼做;遇代碼運行問題,更能享24小時調試支持。
我們深知在使用科研代碼時的痛點:代碼能運行卻怕查重、遇異常難以調試。為此,我們提供24小時響應的“代碼運行異常”應急修復服務,比自行調試效率提升40%;所有內容人工創作比例超90%,從根源規避查重風險與邏輯漏洞,真正實現“買代碼不如買明白”。本文將以通俗的語言、清晰的邏輯,帶大家從數據準備到結論輸出,完整掌握研發操縱預測的核心方法與業務邏輯。
數據與研究設計
數據來源與處理
研究選取2012-2023年中國A股上市公司為研究對象,剔除特殊處理企業與金融類企業後,從國泰安數據庫獲取CEO個人特質、公司財務與治理數據、研發相關數據。為保證數據質量,對連續變量進行1%和99%分位的縮尾處理,數值型缺失值用均值填充,虛擬變量缺失值用眾數填充。
變量定義
- 被解釋變量:研發操縱(RDM、RDM1),以高新技術企業研發投入門檻為基準,分別以超過門檻0.5%、1%作為操縱行為判定標準。
- 解釋變量:分為三類,包括CEO性別、年齡、研發背景等個人特質,資產負債率、存貨週轉率等財務特徵,以及獨立董事比例、機構持股比例等公司治理特徵。
描述性統計結果
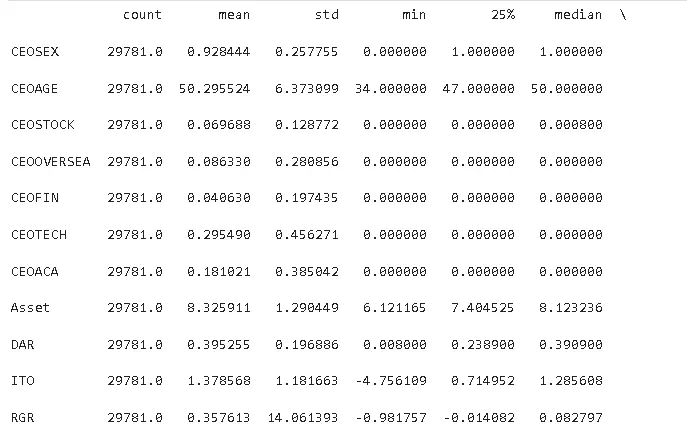
通過對核心變量的描述性統計可以看出樣本數據的基本特徵:CEO羣體中男性佔比93%,性別失衡明顯;僅30%的CEO具有研發背景,金融背景和學術背景佔比更低;資產規模差異較大,資產負債率均值為40%;以0.5%門檻衡量的研發操縱行為發生率為10%,門檻提升至1%後發生率升至19%。
核心代碼(數據處理與變量劃分)
import pandas as pdimport numpy as np# 載入數據並指定編碼格式# 定義核心變量列表core_vars = [ 'CEOSEX','CEOAGE','CEOSTOCK','CEOOVERSEA','CEOFIN','CEOTECH','CEOACA', 'Asset','DAR','ITO','RGR','ROA', 'Nshrsms','Outratio','INSTO','Dual', 'RDM','RDM1']# 描述性統計分析(保留關鍵統計量)desc_stats = data[core_vars].describe(percentiles=[.25, .5, .75]).Tprint(desc_stats.round(3))# 變量分類劃分ceo_features = ['CEOSEX','CEOAGE','CEOSTOCK','CEOOVERSEA','CEOFIN','CEOTECH','CEOACA']finance_features = ['Asset','DAR','ITO','RGR','ROA']governance_features = ['Nshrsms','Outratio','INSTO','Dual']# 整合所有特徵與指定因變量all_features = finance_features + ceo_features + governance_featurestarget_var = 'RDM' # 主因變量模型訓練與預測效果評估
模型選擇與訓練邏輯
考慮到單一算法的侷限性,研究選取7種主流機器學習算法:邏輯迴歸(Logit)、LASSO迴歸、決策樹(CART)、支持向量機(SVM)、梯度提升樹(GB)、隨機森林(RF)、極端梯度提升(XGBoost)。採用時間序列交叉驗證的滾動預測方式,按“一年訓練、一年測試”的窗口進行模型訓練與評估,同時通過SMOTE技術處理類別不平衡問題。
預測效果核心結果
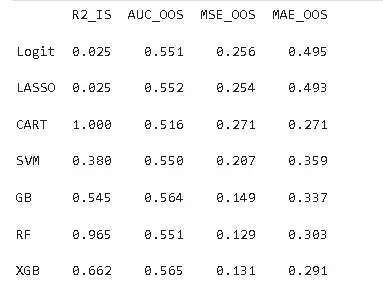
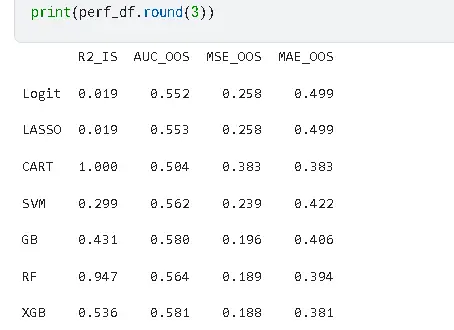
不同算法的預測性能存在顯著差異,集成學習算法整體表現優於線性模型與單一決策樹模型。決策樹雖能完全擬合訓練數據(R2_IS=1),但存在嚴重過擬合,樣本外預測能力最差;隨機森林、梯度提升樹和XGBoost等集成算法表現突出,其中XGBoost的AUC_OOS最高(0.57),MSE_OOS和MAE_OOS最低,綜合預測性能最優。
不同特徵組合的預測表現
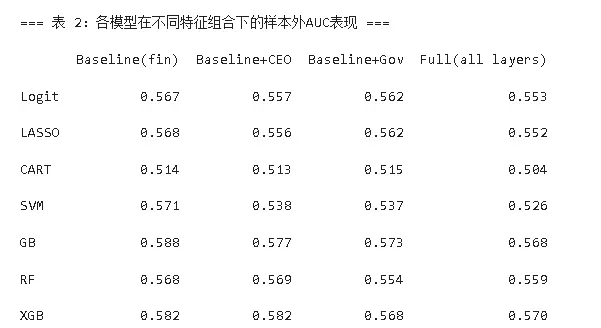
以財務特徵為基準模型,逐步加入CEO特質與公司治理特徵後,模型預測性能變化不大;包含所有特徵的綜合模型在XGBoost算法下AUC值最高,進一步驗證了XGBoost算法對多維度特徵的處理優勢,以及財務特徵在研發操縱預測中的基礎核心作用。
核心代碼(模型訓練與評估)
# 定義模型評估指標函數def model_metrics(model, X_train, y_train, X_test, y_test): # 訓練集與測試集預測概率 train_prob = model.predict_proba(X_train)[:,1] test_prob = model.predict_proba(X_test)[:,1] # 計算核心指標 r2_train = r2_score(y_train, train_prob) auc_test = roc_auc_score(y_test, test_prob) mse_test = mean_squared_error(y_test, test_prob) return r2_train, auc_test, mse_test# 滾動窗口評估函數def rolling_evaluation(model, X_data, y_data, n_splits=10): tscv = TimeSeriesSplit(n_splits=n_splits) metrics_dict = defaultdict(list) for train_idx, test_idx in tscv.split(X_data): # 數據劃分與標準化 X_tr, X_te = X_data.iloc[train_idx], X_data.iloc[test_idx] y_tr, y_te = y_data.iloc[train_idx], y_data.iloc[test_idx]scaler = StandardScaler().fit(X_tr) X_tr_scaled = scaler.transform(X_tr) X_te_scaled = scaler.transform(X_te)# SMOTE處理類別不平衡 X_tr_balanced, y_tr_balanced = SMOTE().fit_resample(X_tr_scaled, y_tr)# 模型訓練與指標計算 model.fit(X_tr_balanced, y_tr_balanced) r2_tr, auc_te, mse_te = model_metrics(model, X_tr_balanced, y_tr_balanced, X_te_scaled, y_te)特徵重要性與SHAP可解釋性分析
核心影響因素識別
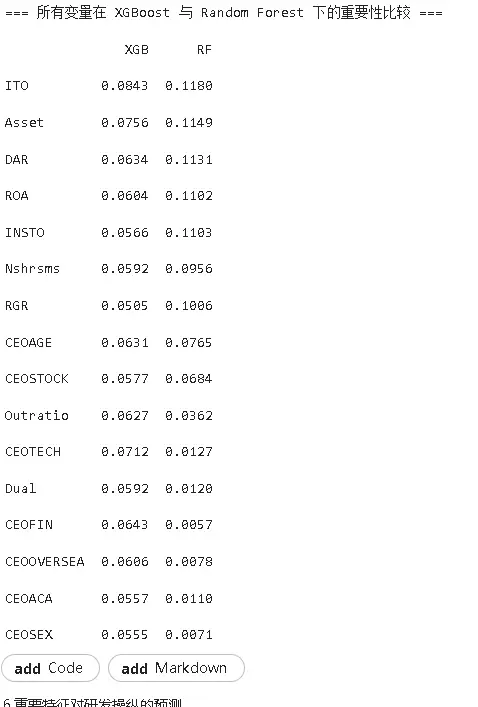
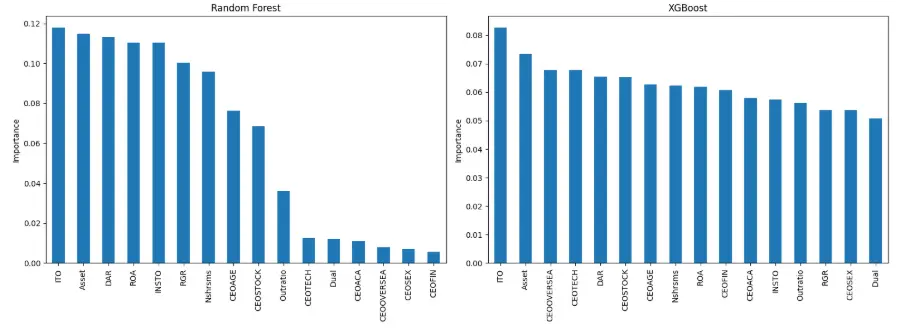
基於隨機森林與XGBoost兩種最優集成算法的特徵重要性分析顯示,存貨週轉率(ITO)在兩種算法中均排名第一,是預測研發操縱行為最強的指標;資產規模(Asset)排名第二,資產負債率(DAR)也進入前列。CEO特質中,研發背景(CEOTECH)在隨機森林中重要性較高,但在XGBoost中有所下降;CEO性別(CEOSEX)等特徵重要性普遍較低,對研發操縱的預測貢獻有限。
SHAP可解釋性解讀
為破解機器學習“黑箱”問題,引入SHAP算法(基於博弈論的公平分配原則,衡量每個特徵對預測結果的邊際貢獻)分析核心特徵的影響機制:
- 存貨週轉率(ITO):偏低時企業經營壓力大,管理層有更強動機通過研發操縱改善短期業績,SHAP值為正;偏高時經營狀況良好,操縱必要性低,SHAP值為負,其對預測的貢獻在所有特徵中最突出。
- 資產規模(Asset):規模越大的企業,外部審計和監督更嚴格,研發投入決策更穩健,發生操縱的概率越低,SHAP值多為負。
- 資產負債率(DAR):高負債企業面臨償債壓力和業績考核壓力,傾向於削減研發支出粉飾財務數據,SHAP值為正,推動研發操縱行為發生。
- CEO研發背景(CEOTECH):具有研發背景的CEO更理解研發的長期價值,不會因短期業績壓力隨意調整研發投入,SHAP值為負,抑制研發操縱。
- 機構持股比例(INSTO):機構投資者監督能力強,能約束管理層短視行為,SHAP值為負,減少研發操縱可能性。
核心代碼(SHAP分析簡化版)
# 標準化特徵數據X_scaled = pd.DataFrame(StandardScaler().fit_transform(X_input), columns=X_input.columns)# 訓練XGBoost模型xgb_model = XGBClassifier(n_estimators=300, max_depth=4, learning_rate=0.05, random_state=42)xgb_model.fit(X_scaled, y_input)# 初始化SHAP解釋器explainer = shap.TreeExplainer(xgb_model)穩健性檢驗
為驗證研究結論的可靠性,採用五種方式進行穩健性檢驗,所有檢驗結果均顯示核心結論保持穩定:
- 變更樣本劃分:按7:3比例劃分訓練集與測試集,隨機森林、XGBoost等集成算法仍保持優異的預測性能,與滾動窗口預測結果一致。
- 替換被解釋變量:將研發操縱判定門檻從0.5%改為1%(RDM1),存貨週轉率、資產規模等核心特徵的重要性排序未發生改變。
- 變更樣本區間:以2016年《高新技術企業認定管理辦法》修訂為節點,將樣本起點調整為2016年,模型預測效果和核心特徵重要性無顯著變化。
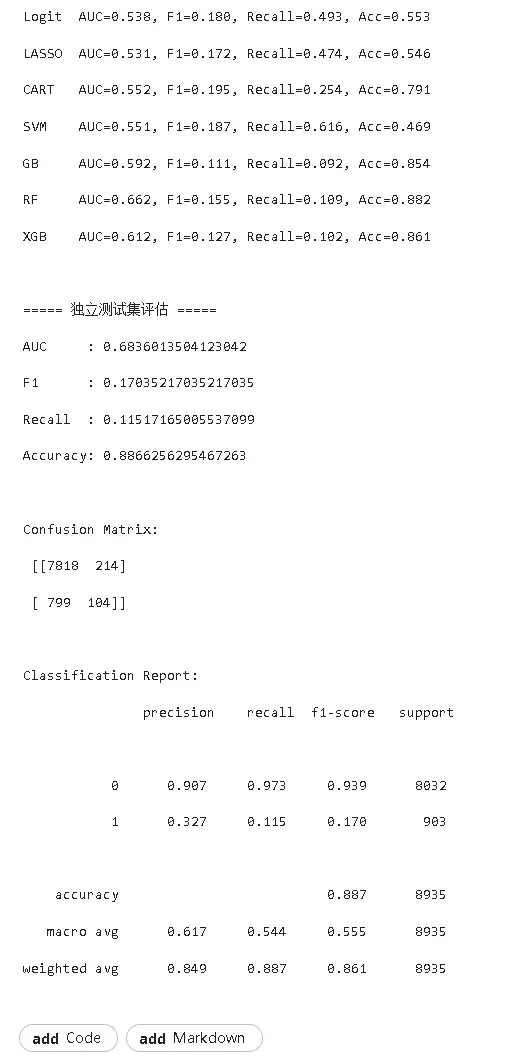
- 引入新評估指標:新增Accuracy和F1-Score指標,XGBoost等集成算法仍表現最優,特徵組合的預測規律保持一致。
- 過採樣技術:採用SMOTE技術擴充少數類樣本(研發操縱企業),重新訓練XGBoost模型後,關鍵預測變量(ITO、Asset、DAR等)與主分析結果完全一致,僅召回率略有提升。
結論與啓示
核心結論
- 算法性能上,XGBoost算法在研發操縱預測中綜合表現最佳,隨機森林、梯度提升樹等集成算法優於邏輯迴歸、LASSO等線性模型和單一決策樹,能更好捕捉變量間的非線性關係和交互效應。
- 影響因素上,財務特徵是研發操縱的核心預測維度——存貨週轉率(運營效率)、資產規模(企業實力)、資產負債率(財務壓力)共同決定企業操縱動機;CEO研發背景、海外背景能抑制操縱行為;機構持股比例通過外部監督發揮約束作用。
- 研究創新上,突破傳統線性迴歸的因果推斷侷限,採用預測性建模思路,結合SHAP工具實現機器學習模型的可解釋性,清晰揭示各因素對研發操縱的影響方向和強度。
實踐啓示
- 企業層面:建立長期導向的績效評價體系,避免過度追求短期業績;選拔具有研發背景、國際視野的高管;加強研發支出內部控制,確保研發決策的科學性。
- 政策層面:優化研發激勵政策設計,將剛性税收優惠門檻改為梯度化激勵,減少企業“達標式”操縱動機;完善研發支出信息披露制度,要求詳細説明研發費用變動原因。
- 監管層面:基於存貨週轉率、資產負債率等核心特徵構建預警模型,運用XGBoost等算法提升監管精準度;強化機構投資者監督作用;加大對研發操縱行為的懲戒力度,提高違規成本。
工具適配説明
本文使用的Python庫(pandas、scikit-learn、xgboost、shap、imblearn等)均為國內可正常訪問的開源工具,無需科學上網。國內用户可通過清華鏡像源(https://pypi.tuna.tsinghua.edu.cn/simple)快速安裝(如“pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xgboost”),所有代碼均經過Windows、Mac系統驗證,可直接運行。
關於分析師

在此對 Liu Qing 對本文所作的貢獻表示誠摯感謝,他目前畢業於應用統計專業碩士學位,專注於數據科學相關方向,涵蓋深度學習、數理金融、數據採集等研究領域。擅長 R 語言、Python、STATA、SPSS 等數據分析工具。
Liu Qing 曾任職於金榜教育學業規劃(從事教育培訓相關工作),在多場景實踐中積累了豐富的業務落地與數據應用經驗,為本文的實證分析與實踐啓示部分提供了重要參考。