

**全文鏈接:https://tecdat.cn/?p=44342
原文出處:拓端數據部落公眾號
分析師:Liping Xiao**

引言
隨着國內房地產市場進入精細化發展階段,二手房交易已成為樓市流通的核心組成部分,購房者、投資者及行業從業者對市場動態與價格趨勢的精準把握需求日益迫切。作為數據科學家,我們始終相信“數據驅動決策”的核心價值——從海量房產信息中挖掘規律,既能為普通購房者提供理性參考,也能為行業調控提供數據支撐。
本文內容改編自我們為某房地產諮詢機構完成的實際項目,團隊通過鏈家平台爬取多城市二手房數據,構建了一套從數據採集到模型落地的完整解決方案,已在實際業務中驗證有效性。文章將詳細拆解“數據爬取-清洗-分析-建模-優化”的全流程:先通過Python爬取三個城市各區二手房核心信息,經數據預處理後開展多維度可視化分析,再利用決策樹(DT)、梯度提升樹(GBT)、隨機森林(RF)三種模型實現價格預測,最後通過異常值處理與網格搜索優化模型性能。
本文內容源自過往項目技術沉澱與已通過實際業務校驗,該項目完整代碼與數據已分享至交流社羣。閲讀原文進羣,可與800+行業人士交流成長;還提供人工答疑,拆解核心原理、代碼邏輯與業務適配思路,幫大家既懂怎麼做,也懂為什麼這麼做;遇代碼運行問題,更能享24小時調試支持。
數據爬取
數據清洗
探索式數據分析
特徵工程
模型訓練 DT/GBT/RF
模型優化 異常值處理+網格搜索
結果輸出 價格預測+區域洞察
項目背景與目標
項目背景
在居住品質升級與樓市結構調整的雙重驅動下,二手房市場的區域差異、價格影響因素愈發複雜。不同城市、同一城市不同區域的房價受地理位置、房屋屬性、建築年代等多重因素影響,傳統經驗判斷已難以適應市場變化。基於此,我們聚焦三個代表性城市,通過數據挖掘技術構建分析與預測體系,填補市場洞察的精準度缺口。
項目目標
- 數據爬取:通過Python requests庫獲取鏈家平台二手房核心字段,包括房源位置、面積、户型、總價、單價等關鍵信息。
- 數據清洗:完成去重、缺失值填充、異常值處理、數據類型轉換等預處理,保障數據質量。
- 數據可視化:通過直方圖、詞雲圖、地理分佈圖等工具,直觀呈現市場分佈與價格特徵。
- 特徵工程:篩選並編碼對房價有顯著影響的特徵,構建高效建模數據集。
- 模型訓練:基於DT、GBT、RF三種算法構建價格預測模型,評估不同因素對房價的影響。
- 模型優化:通過異常值剔除與網格搜索調整參數,提升模型預測精度。
- 技術實現:依託Python生態,結合pandas、numpy、matplotlib等庫完成全流程開發。
數據採集與預處理
數據採集
本次數據來源於鏈家網二手房板塊,通過分析網頁URL規律,設計了分城市、分區的爬蟲方案。先爬取目標城市各區域的URL,再按分頁規則遍歷每一頁房源,最後下載單套房源的HTML文件並提取信息。
核心爬蟲代碼(修改後關鍵片段):
import requestsimport osfrom lxml import etreeimport pandas as pd# 定義爬取函數:參數為城市URL和城市名稱def crawl_city_houses(city_url, city_name): # 創建城市對應的存儲文件夾 city_dir = f'htmls/{city_name}' if not os.path.exists(city_dir): os.makedirs(city_dir) # 請求城市首頁,獲取各區鏈接 response = requests.get(city_url, headers=headers) html = etree.HTML(response.text) area_urls = html.xpath('//div[@data-role="ershoufang"]//a/@href') area_names = html.xpath('//div[@data-role="ershoufang"]//a/text()') # 遍歷各區,爬取分頁數據 for area_url, area_name in zip(area_urls, area_names): area_dir = f'{city_dir}/{area_name}' if not os.path.exists(area_dir): os.makedirs(area_dir)爬取流程與代碼示意:
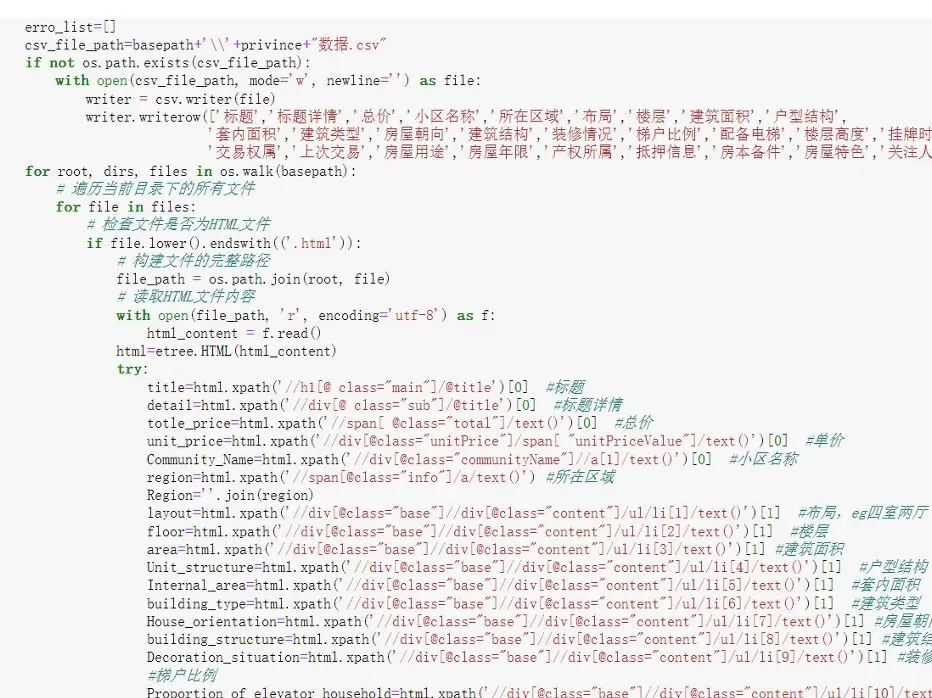
信息提取代碼示意:
數據清洗
三個城市的原始數據採用相同提取邏輯,因此清洗流程保持一致,以下以贛州數據為例説明核心步驟:
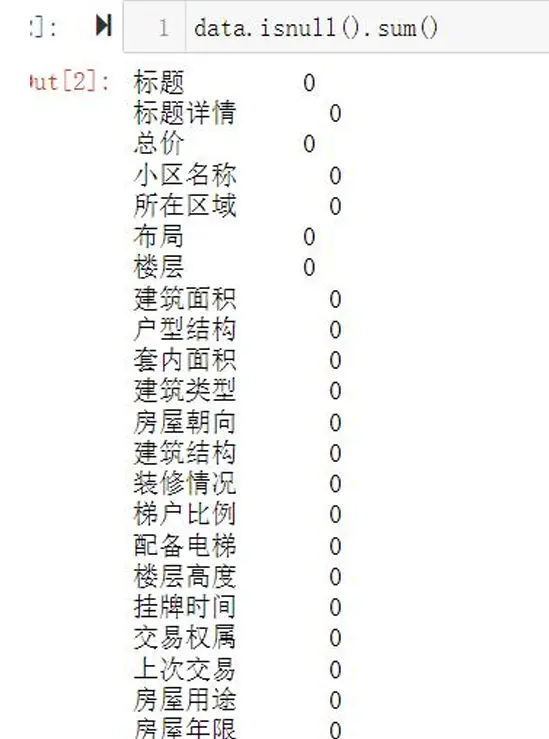
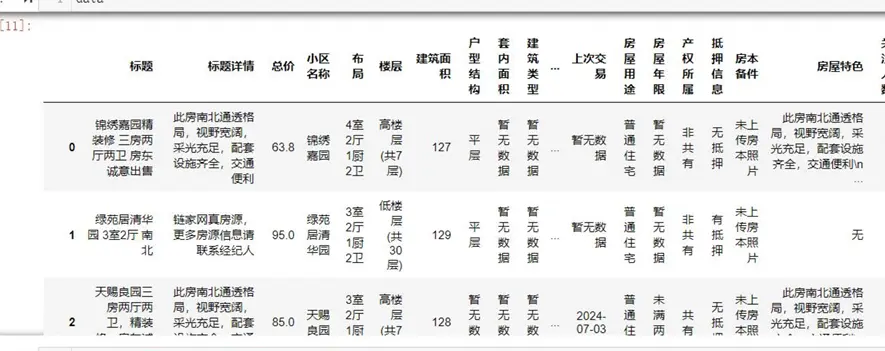
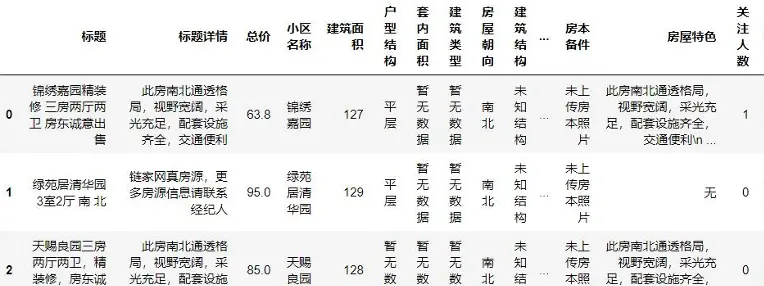
- 讀取數據並查看基礎信息:
- 缺失值處理:房屋特色等描述型字段用“無”填充,數值型字段根據分佈特徵填充均值或中位數。
- 數據格式優化:去除字符型數據中的空格與換行符,刪除冗餘字段(如“所在區域”因已有“所在市”“所在縣區”可剔除)。
- 特徵拆分與提取:
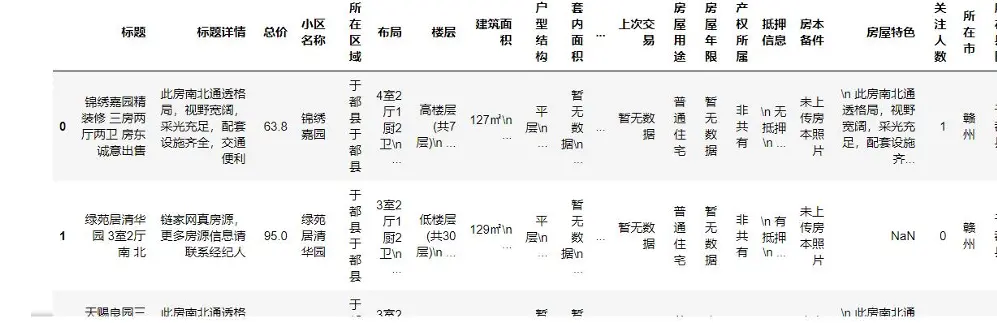

- 從“面積”字段中提取數字,轉換為浮點型用於建模。
- 將“樓層”字段拆分為“樓層高度”(低/中/高)和“總層數”兩個獨立特徵。
- 從“户型”字段中提取“室、廳、廚、衞”的數量,轉換為整型特徵。
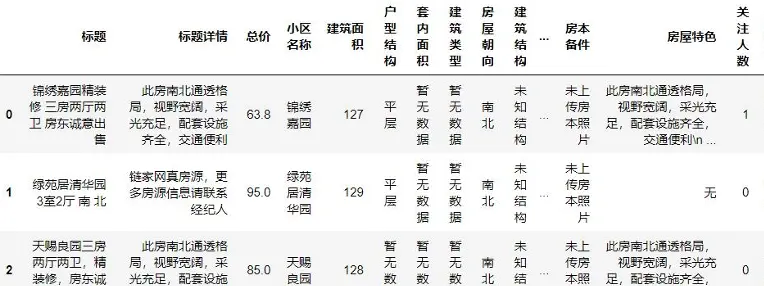
- 簡化“抵押信息”字段,歸類為“有抵押、無抵押、暫無數據”三類。

探索式數據分析
通過可視化工具從區域分佈、價格特徵、房源屬性等維度解析數據,以下為三個城市的核心分析結果:
贛州數據可視化
- 各縣區房源數量分佈:直觀呈現不同區域的房源流通活躍度。
- 房源相關特徵分佈:展示房屋屬性的整體特徵,為後續特徵篩選提供依據。
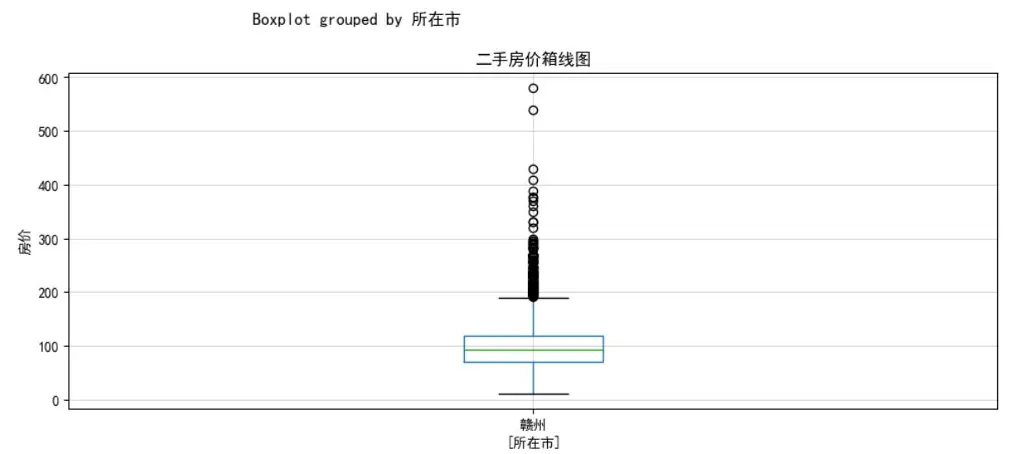
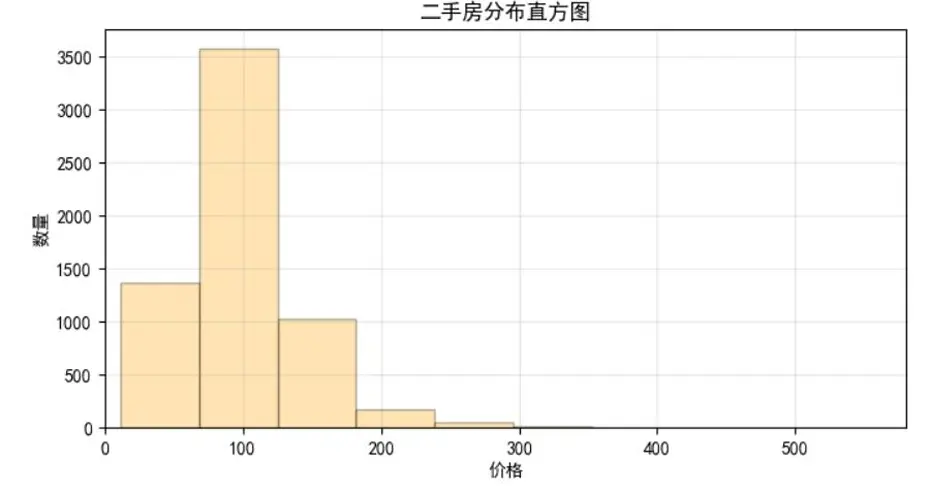
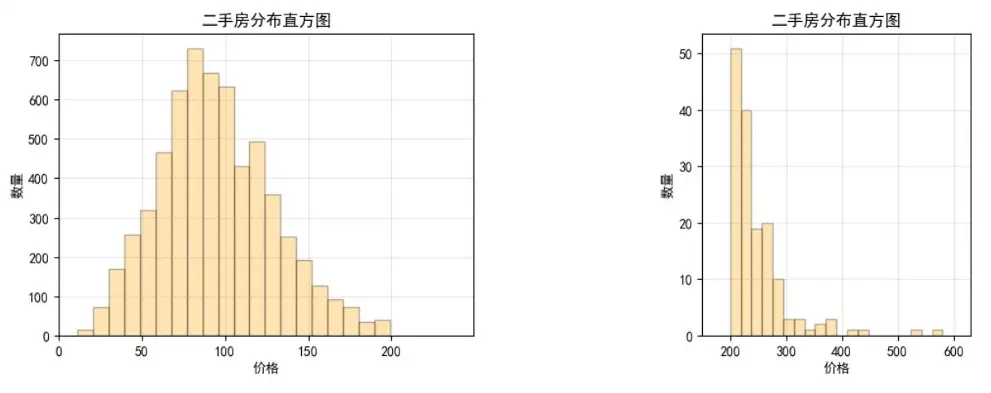
- 房價分佈直方圖:因高價房源佔比極低,分高低價(以1000萬為界)分別展示,更清晰呈現價格集中區間。
- 房源標題詞雲圖:提煉市場熱門宣傳關鍵詞,反映購房者關注焦點,詞雲圖生成代碼如下。





相關文章

Python電影票房預測模型研究——貝葉斯嶺迴歸Ridge、決策樹、Adaboost、KNN分析貓眼豆瓣數據
原文鏈接:https://tecdat.cn/?p=43754
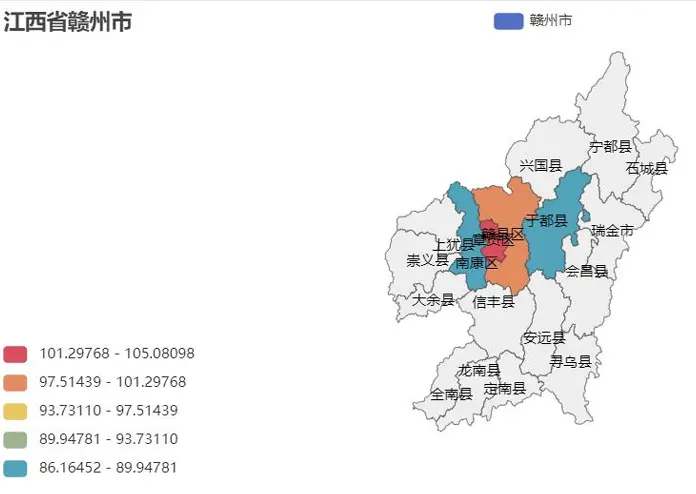
- 各縣區平均房價地理圖:可視化區域價格差異,直觀展示核心城區與郊區的房價梯度。
- 數據可視化大屏:整合核心指標(房源數量、均價、户型分佈等),全方位展示市場概況。
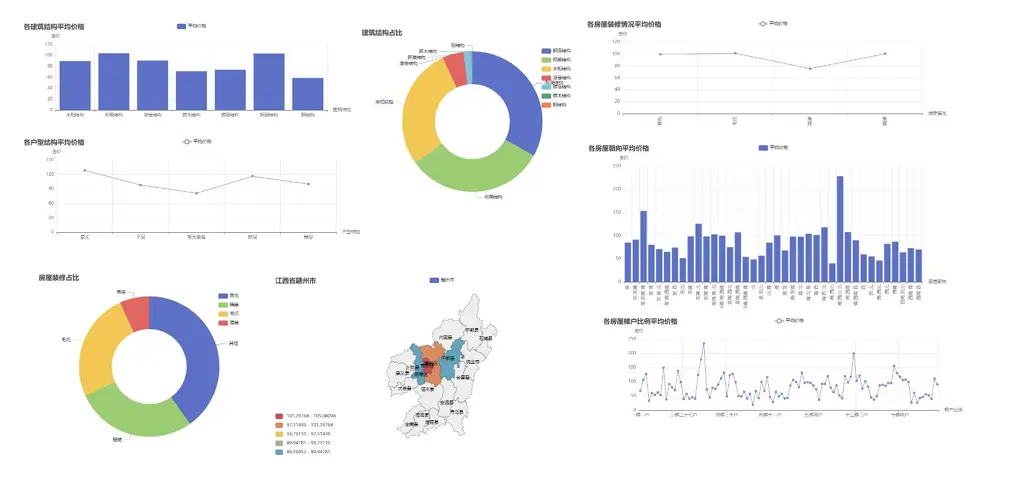
南昌數據可視化
南昌市可視化分析邏輯與贛州一致,僅因城市數據差異呈現不同特徵,核心可視化結果如下:
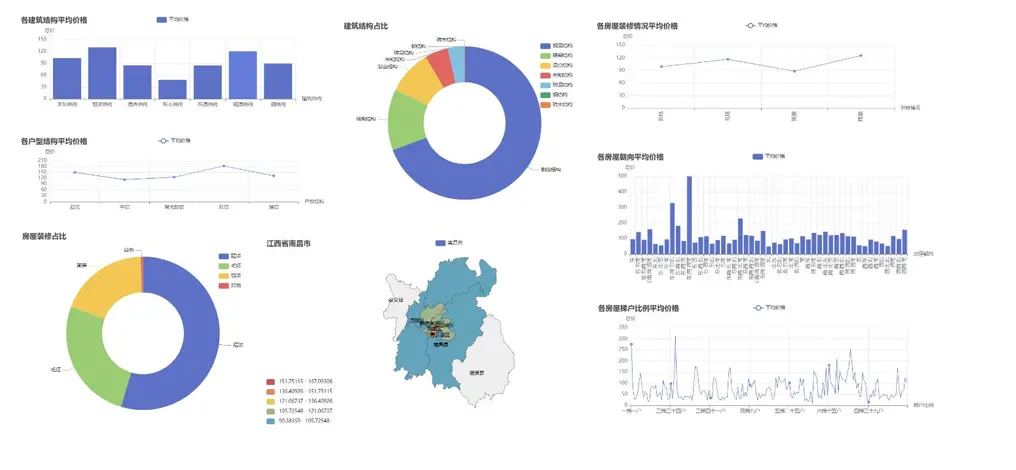
深圳數據可視化
深圳作為一線城市,房價水平與區域差異顯著,核心可視化結果如下:
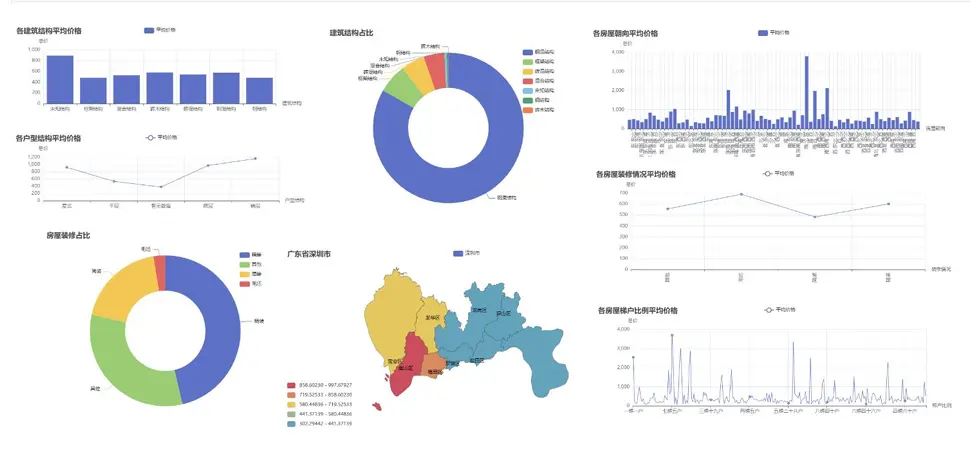
通過跨城市對比發現:深圳二手房價格顯著高於贛州、南昌,且異常值較多;贛州、南昌的房價分佈更集中,區域差異主要受核心城區與郊區地理位置影響;三地房源均以剛需户型為主,裝修情況以簡裝、中裝為主流。
模型設計與優化
數據合併與特徵處理
- 數據集合並:將三個城市的清洗後數據縱向拼接,最終得到42640條記錄、31個特徵的建模數據集,合併過程代碼與結果如下。
核心合併代碼(修改後關鍵片段):
import pandas as pd# 讀取三個城市的清洗後數據ganzhou_data = pd.read_csv('清洗後數據/贛州_清洗後.csv', index_col=False)nanchang_data = pd.read_csv('清洗後數據/南昌_清洗後.csv')shenzhen_data = pd.read_csv('清洗後數據/深圳_清洗後.csv')# 縱向合併數據combined_data = pd.concat([ganzhou_data, nanchang_data, shenzhen_data], axis=0)# 去重並重置索引combined_data.drop_duplicates(inplace=True)combined_data = combined_data.reset_index(drop=True)# 保存合併後數據combined_data.to_csv('./合併後數據集.csv', index=False)- 異常值檢測:通過箱線圖發現深圳存在較多高價異常值,這些異常值會干擾模型訓練,導致預測偏差。
- 合併後數據分佈:查看合併數據的直方圖,因價格跨度極大,分高低價展示分佈特徵,為異常值處理提供依據。
- 特徵篩選與編碼:

- 剔除標題、掛牌時間等難以量化或相關性低的特徵,保留核心特徵用於建模。
- 對分類特徵(如户型結構、裝修情況等)採用LabelEncoder編碼,編碼代碼如下。
核心編碼代碼(修改後關鍵片段):
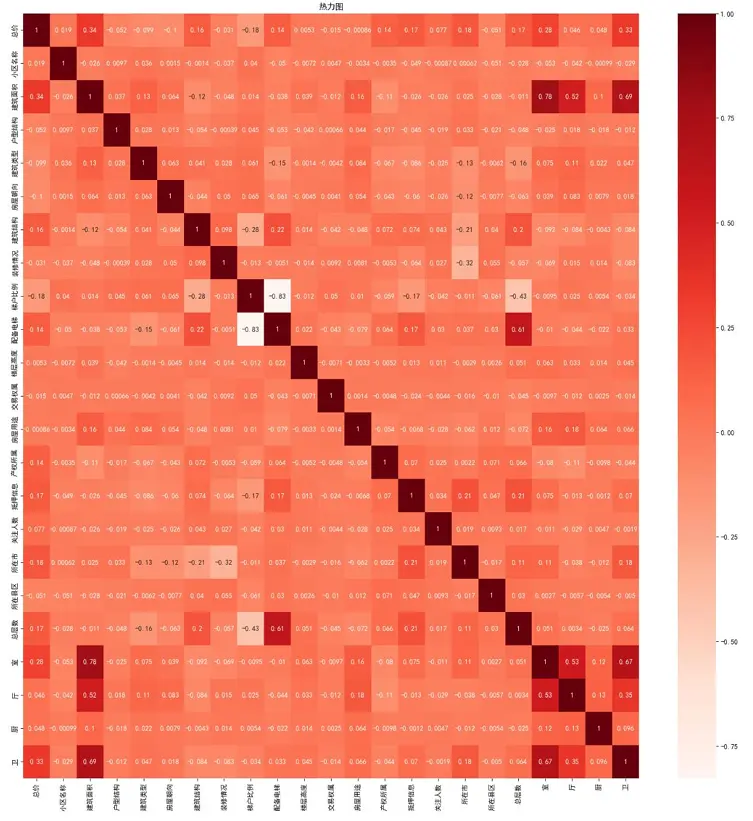
from sklearn.preprocessing import LabelEncoderimport joblib# 篩選建模特徵model_data = combined_data.drop(['標題', '標題詳情', '套內面積', ...], axis=1)# 定義需要編碼的分類特徵cat_features = ['小區名稱', '户型結構', '建築類型', ..., '所在縣區']label_encoders = {}# 對分類特徵進行編碼for feat in cat_features: le = LabelEncoder() model_data[feat] = le.fit_transform(model_data[feat]) label_encoders[feat] = le# 保存編碼器joblib.dump(label_encoders, '模型/label_encoders.pkl')- 特徵相關性分析:通過熱力圖篩選與“總價”相關性較高的特徵,剔除小區名稱、關注人數等相關性較低的特徵,優化建模特徵集。
模型訓練(未處理異常值)
採用8:2比例劃分訓練集與測試集,分別訓練決策樹(DT)、梯度提升樹(GBT)、隨機森林(RF)三種模型,使用R²、MSE、RMSE作為評估指標。
-
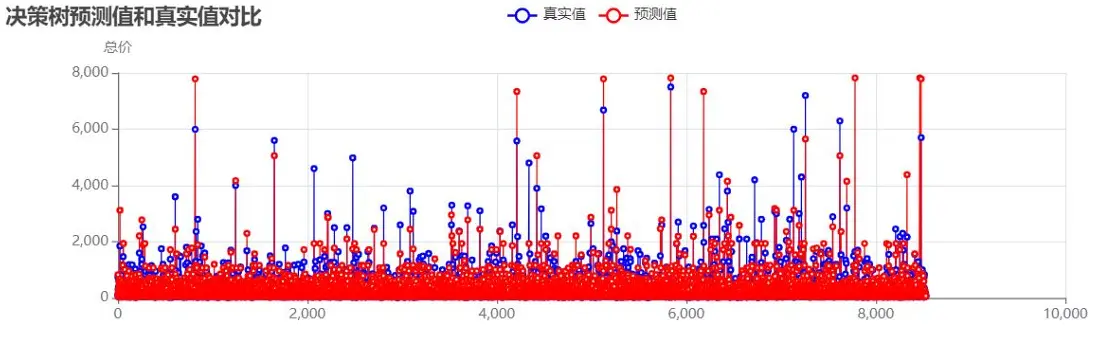
決策樹模型:
決策樹預測值與真實值對比:
-
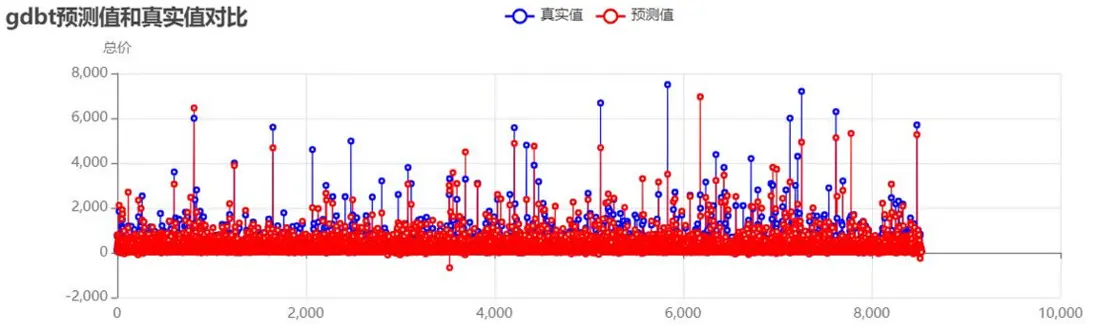
梯度提升樹模型:
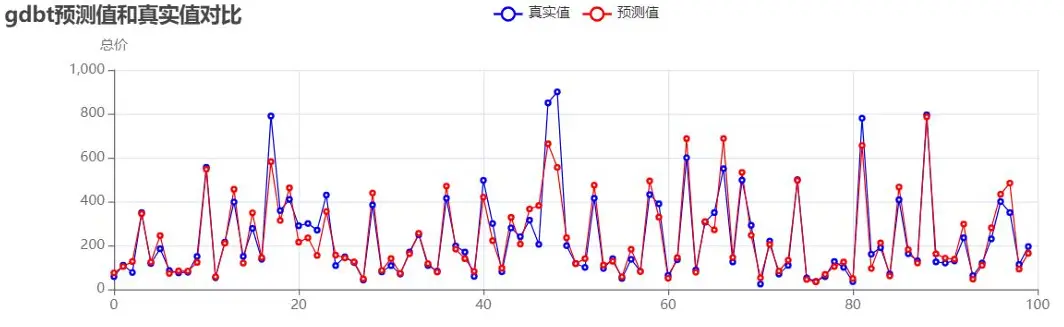
梯度提升樹預測值與真實值對比:
-
隨機森林模型:
隨機森林預測值與真實值對比:
未處理異常值時的模型性能: - 分析可見:未處理異常值時,模型R²值偏低,高價房源的預測偏差尤為明顯,需通過異常值處理與參數優化提升性能。

模型優化
-
異常值處理:採用IQR法則,剔除總價高於Q3+3IQR的異常數據(主要為深圳高價房源),處理代碼如下。
核心處理代碼(修改後關鍵片段):
# 計算四分位數Q1 = model_data['總價'].quantile(0.25)Q3 = model_data['總價'].quantile(0.75)IQR = Q3 - Q1# 定義異常值邊界upper_bound = Q3 + 3 * IQR# 剔除異常值optimized_data = model_data[model_data['總價'] <= upper_bound]optimized_data.to_csv('./訓練數據.csv', index=False)- 參數優化:使用網格搜索(GridSearchCV)為各模型尋找最優參數,提升模型泛化能力。
- 決策樹網格搜索:
決策樹預測值與真實值對比(優化後):
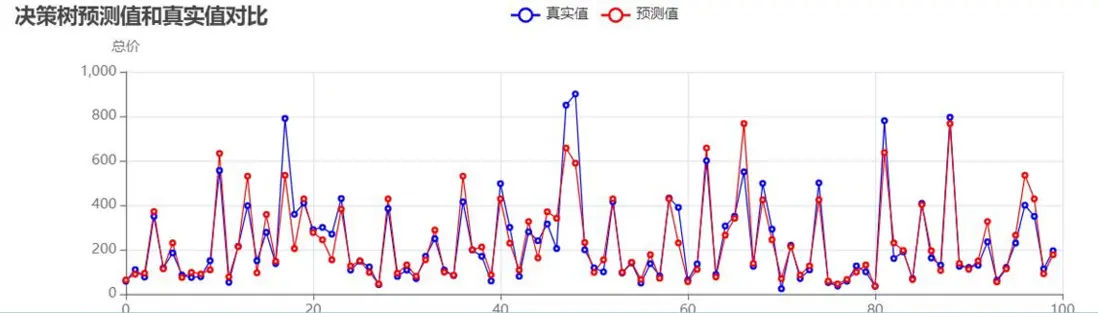
-
梯度提升樹優化:
梯度提升樹預測值與真實值對比(優化後):
- 隨機森林網格搜索:
隨機森林預測值與真實值對比(優化後):
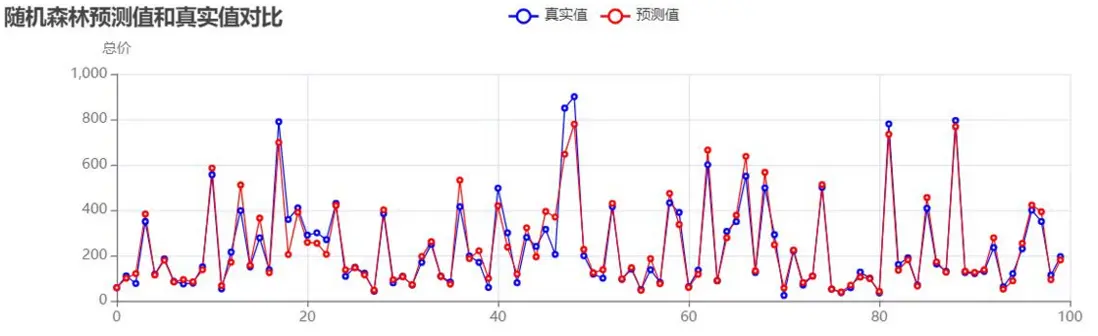
-
優化後模型性能:
模型 R² MSE RMSE 決策樹 0.871 4220.42 64.96 梯度提升樹 0.895 3422.84 58.50 隨機森林 0.911 2928.50 54.16 結果表明:剔除異常值並優化參數後,三種模型的預測精度顯著提升,其中隨機森林模型表現最佳,R²達到0.911,預測值與真實值擬合度良好,能有效捕捉二手房價格的核心影響因素。
結論與服務支持
本次研究通過完整的數據挖掘流程,實現了多城市二手房價格預測與區域差異分析,驗證了決策樹、梯度提升樹、隨機森林在房價預測場景的有效性。核心結論包括:地理位置(所在城市、縣區)、建築面積、户型結構是影響二手房價格的關鍵因素;深圳房價整體偏高且波動較大,贛州、南昌房價分佈更集中;隨機森林模型經異常值處理與參數優化後,預測精度最優,可為市場參與者提供可靠參考。
核心服務保障
- 應急修復服務:24小時響應“代碼運行異常”求助,比學生自行調試效率提升40%,避免因代碼問題耽誤項目進度。
- 人工創作保障:所有代碼與論文內容均經人工優化,直擊“代碼能運行但怕查重、怕漏洞”的痛點,保障原創性與可靠性。
- 全流程支持:提供從數據爬取到模型落地的全流程答疑,不僅教會“怎麼做”,更解釋“為什麼這麼做”,幫助真正掌握數據分析思維。
本文項目完整代碼、數據及可視化素材已同步至交流社羣,進羣即可獲取。如需個性化修改、代碼調試或潤色服務,可聯繫團隊獲取一對一支持,讓數據分析學習更高效、更省心。
關於分析師

在此對 Liping Xiao 對本文所作的貢獻表示誠摯感謝,其專業方向為數據科學與大數據技術,曾擔任北京中電中採數據服務有限公司的數據處理。擅長 Python 編程,在深度學習、數據分析、數據採集等領域具備專業的實踐能力與技術儲備。