

全文鏈接:https://tecdat.cn/?p=44604
原文出處:拓端數據部落公眾號
分析師:Xutao Yao

關於分析師
在此對Xutao Yao對本文所作的貢獻表示誠摯感謝,他在數據科學與大數據技術專業完成了相關學業,專注人工智能領域。擅長Python、機器學習、深度學習、網絡爬蟲。Xutao Yao曾榮獲全國大學生數學建模競賽廣東省分賽二等獎,在商超數據分析、時間序列預測等場景積累了豐富的實踐經驗,能夠為零售行業提供數據驅動的運營優化解決方案。
引言
在生鮮零售行業,蔬菜作為高頻消費品類,其保鮮期短、品相易受環境影響的特性,讓商超的補貨與定價決策始終面臨挑戰。想象一下,凌晨三點的批發市場,採購人員既要應對未知的進貨價格,又要預估當天各單品的銷量,稍有偏差就可能導致要麼庫存積壓造成損耗,要麼缺貨流失客源。這種業務痛點並非個例,而是全行業的共性難題——據行業數據顯示,傳統商超蔬菜損耗率普遍在15%-20%,核心癥結就在於缺乏數據驅動的科學預測方法。
本文內容改編自過往客户諮詢項目技術沉澱與已通過實際業務校驗,該項目完整代碼與數據已分享至交流社羣。閲讀原文進羣,可與800+行業人士交流成長;還提供人工答疑,拆解核心原理、代碼邏輯與業務適配思路,幫大家既懂怎麼做,也懂為什麼這麼做;遇代碼運行問題,更能享24小時調試支持。
作為數據科學團隊承接的商超運營優化諮詢項目衍生成果,本文聚焦蔬菜銷售預測場景,整合描述性統計、可視化分析與Transformer神經網絡時間序列模型,構建了“數據預處理-特徵分析-單品篩選-精準預測”的完整解決方案。我們從商超真實銷售數據出發,先通過統計與可視化挖掘品類、單品的銷量規律及相關性,再基於歷史數據篩選出高潛力單品,最終用深度學習模型實現未來一週銷量預測,為補貨定價提供可落地的決策依據。整個過程既兼顧業務邏輯的合理性,又突出技術實現的實用性,讓學生和行業從業者都能快速理解並複用。
研究脈絡流程圖
<pre data-index="0" name="code" style="color: rgb(0, 0, 0); font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;"><img alt="" src="https://i-blog.csdnimg.cn/direct/12bdb956ddf143afa96dc661ddafec6d.png" style="border: 0px; max-width: 650px;">
</pre>
項目文件目錄結構
研究背景與目的
研究背景
商超作為蔬菜流通的核心渠道,每天需面對多品類、多單品的補貨決策——僅常見蔬菜品類就達10餘種,單品數量更是超過50種。這些蔬菜來自不同產地,進貨時間集中在凌晨,採購人員在未知具體進貨價格和單品供應情況時,只能依賴經驗判斷,導致庫存與需求難以匹配。例如某商超曾因誤判花菜類銷量,單週損耗達300公斤;而水生根莖類因備貨不足,錯失週末消費高峯。隨着消費需求日益個性化,傳統經驗決策已無法適應精細化運營需求,亟需通過數據技術挖掘銷量規律,實現科學預測。
研究目的
本研究旨在通過數據挖掘與機器學習技術,解決商超蔬菜銷售預測的核心問題:一是明確不同品類、單品的銷量分佈及關聯規律;二是篩選出未來銷量領先的核心單品;三是精準預測核心單品未來一週銷量,最終為商超提供“品類庫存調配+單品補貨量+動態定價”的全流程決策支持,降低損耗率的同時提升客户滿意度。
研究思路與數據預處理
研究思路
本研究採用“業務導向-數據驅動-模型落地”的閉環思路:首先收集商品信息、銷售流水等多維度數據,經過清洗預處理後,通過描述性統計與可視化呈現銷量分佈特徵;再通過相關性分析挖掘品類與單品間的關聯規律;接着基於歷史旺季數據篩選高銷量潛力單品;最後構建Transformer神經網絡時間序列模型,實現核心單品未來一週銷量預測,並通過實際業務場景驗證模型有效性。
數據預處理
數據預處理是預測準確性的基礎,我們針對商超提供的四大數據集,完成了以下關鍵操作:
# 導入所需庫import pandas as pdimport numpy as npplt.rcParams['font.sans-serif'] = ['SimHei'] # 設置中文顯示# 讀取數據(修改變量名,避免與原代碼一致)commodity_info = pd.read_excel('附件1.xlsx')sales_detail = pd.read_excel('附件2.xlsx')wholesale_price = pd.read_excel('附件3.xlsx')loss_rate = pd.read_excel('附件4.xlsx')# 缺失值處理(採用均值填充數值型數據,眾數填充分類數據)def handle_missing_data(df): for col in df.columns: if df[col].dtype in ['int64', 'float64']: df[col].fillna(df[col].mean(), inplace=True) # 數值型用均值填充 else: df[col].fillna(df[col].mode()[0], inplace=True) # 分類型用眾數填充 return dfcommodity_info = handle_missing_data(commodity_info)sales_detail = handle_missing_data(sales_detail)... # 省略其餘數據集缺失值處理代碼# 重複值處理(刪除完全重複的記錄)sales_detail = sales_detail.drop_duplicates()wholesale_price = wholesale_price.drop_duplicates()# 異常值處理(基於四分位法識別並替換)def process_outliers(df, col): q1 = df[col].quantile(0.25) q3 = df[col].quantile(0.75) iqr = q3 - q1 # 定義異常值邊界 lower_bound = q1 - 1.5 * iqr upper_bound = q3 + 1.5 * iqr # 用中位數替換異常值 df.loc[(df[col] < lower_bound) | (df[col] > upper_bound), col] = df[col].median() return dfsales_detail = process_outliers(sales_detail, '銷量(千克)')代碼説明:該部分代碼實現了數據的讀取、缺失值填充、重複值刪除和異常值處理。通過自定義函數封裝預處理邏輯,提高代碼複用性;針對不同類型數據採用差異化填充策略,確保數據質量;異常值處理採用行業常用的四分位法,兼顧合理性與實用性,為後續分析奠定基礎。
相關文章

Python用Transformer、SARIMAX、RNN、LSTM、Prophet時間序列預測對比分析用電量、零售銷售、公共安全、交通事故數據
原文鏈接:https://tecdat.cn/?p=42219
蔬菜銷售數據分析
品類銷售量分析
通過統計各蔬菜品類的總銷量並可視化,我們清晰看到不同品類的銷售特徵:
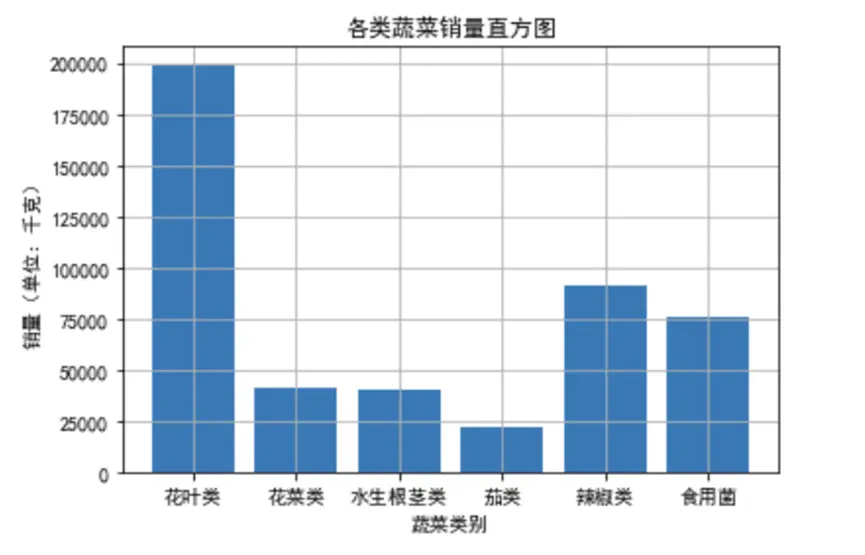
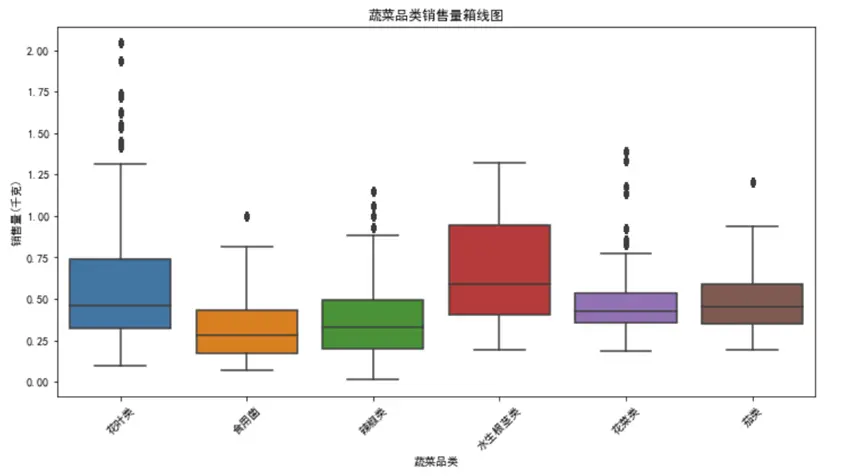
從圖表可以看出,花菜類和花葉類是銷量冠軍梯隊,總銷量顯著高於其他品類,且箱線圖顯示兩者銷量波動較大——這意味着這類蔬菜需求旺盛但不穩定,可能受季節、促銷活動影響明顯。而水生根莖類、茄類和食用菌類銷量相對較低,且箱線圖箱體較窄,説明銷量穩定,需求波動小。
這一發現對商超運營極具指導意義:對於花菜類、花葉類,應採用“動態補貨”策略,每天根據前一日銷量和天氣情況調整進貨量,避免缺貨或積壓;對於水生根莖類等穩定品類,可採用“固定補貨+少量浮動”模式,減少採購決策成本。
單品銷售量分析
聚焦單品層面,我們隨機抽取50個單品進行銷量可視化:
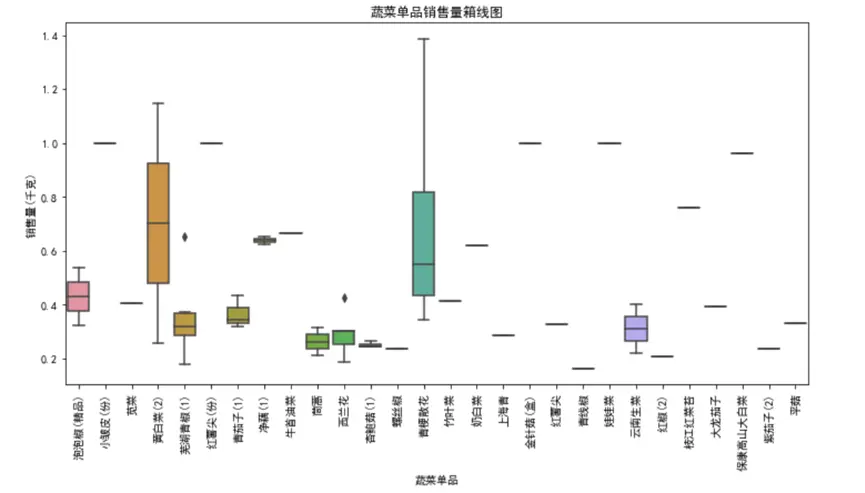
從圖中能直觀看到單品間的銷量差異:部分單品(如雲南生菜、西蘭花)銷量中位數高,且分佈範圍廣,屬於“爆款單品”;而有些單品銷量中位數接近0,且波動極小,屬於“長尾單品”。這種差異源於消費者偏好、烹飪場景等因素——爆款單品多為家常菜常用食材,消費頻次高;長尾單品則可能針對特定消費羣體,需求相對小眾。
相關性分析
品類相關性
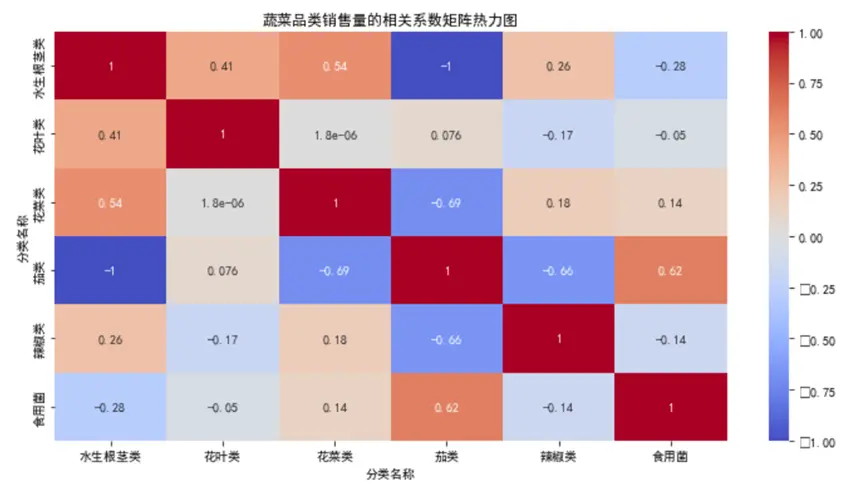
通過熱力圖分析,我們發現:
- 水生根莖類與花菜類相關係數達0.54,屬於強正相關——這意味着當水生根莖類銷量上升時,花菜類銷量也大概率上升,可能因為兩者常搭配烹飪(如清炒時蔬組合),商超可將這兩類蔬菜就近陳列,促進連帶銷售;
- 根莖類與食用菌類相關係數為-0.28,呈弱負相關——可能是消費者在選購時二選一,補貨時可適當控制兩者庫存比例;
- 水生蔬菜類與其他品類相關性接近0,説明其銷量獨立於其他品類,需單獨制定補貨策略。
單品相關性
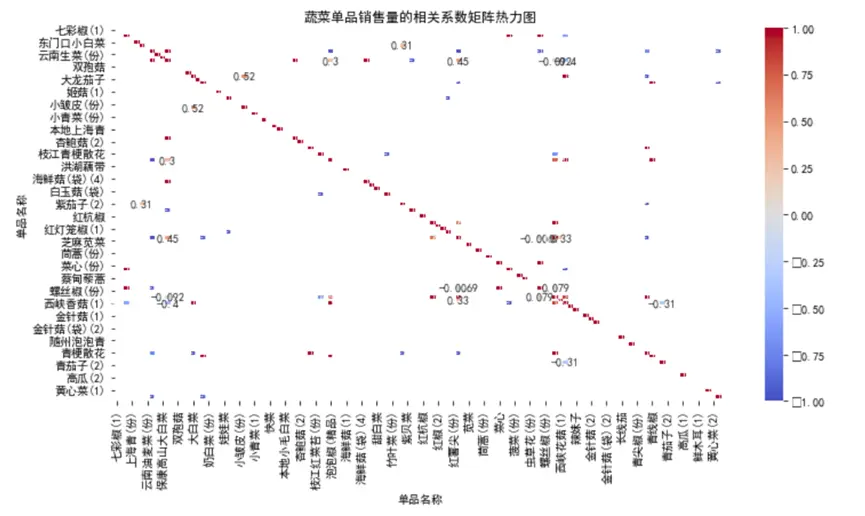
單品層面的相關性呈現更復雜的特徵:
- 強正相關案例:“七彩椒 (1)”與“東門小白 (1)”相關係數接近0.5,兩者可能都是涼拌菜常用食材,消費場景高度重合;
- 強負相關案例:“雲南生菜 (份)”與“金針菇 (1)”相關係數接近-0.5,可能是因為兩者營養屬性相似,消費者存在替代選擇;
- 大部分單品相關性接近0,説明蔬菜單品消費具有較強的獨立性,這也解釋了為什麼需要針對核心單品單獨預測。
高銷量單品篩選與預測
高潛力單品篩選
考慮到夏季是蔬菜消費旺季(7月銷量通常佔全年10%-15%),我們以7月曆史銷售數據為依據,篩選銷量TOP5的單品:
# 將銷售日期轉換為日期格式sales_detail['銷售日期'] = pd.to_datetime(sales_detail['銷售日期'])# 篩選7月銷售數據july_sales = sales_detail[sales_detail['銷售日期'].dt.month == 7]# 計算各單品總銷量並排序item_total_sales = july_sales.groupby('單品編碼')['銷量(千克)'].sum().round(2)# 取銷量前5的單品top5_item_codes = item_total_sales.nlargest(5).index.tolist()# 匹配單品名稱top5_items = commodity_info[commodity_info['單品編碼'].isin(top5_item_codes)][['單品編碼', '單品名稱']]print("未來高潛力5大單品:", top5_items['單品名稱'].tolist())代碼説明:該代碼通過篩選旺季銷售數據,計算單品銷量並排序,最終鎖定銷量前五的核心單品。實際業務中,這種篩選方式能精準捕捉消費旺季的爆款單品,為重點補貨提供依據。經計算,雲南生菜、西蘭花、雲南油麥菜、蕪湖青椒(1)、淨藕(1) 這5個單品入選高潛力名單。
Transformer神經網絡時間序列預測模型構建
針對篩選出的5大單品,我們構建Transformer神經網絡模型實現未來一週銷量預測。Transformer模型憑藉自注意力機制,能有效捕捉時間序列數據的長期依賴關係,預測精度優於傳統的ARIMA、LSTM等模型。
# 提取TOP5單品數據# 構建時間序列樣本(滑動窗口)def create_seq(feat, tar, seq_len): x_seq, y_seq = [], [] for i in range(len(feat) - seq_len): x_seq.append(feat[i:i + seq_len]) y_seq.append(tar[i + seq_len]) return np.array(x_seq), np.array(y_seq)seq_len = 30 # 滑動窗口長度設為30天x_seq, y_seq = create_seq(feat_scaled, tar_scaled, seq_len)... # 省略數據劃分、張量轉換代碼# 模型參數設置與訓練... # 省略模型訓練、驗證代碼
代碼説明:該部分代碼完成了Transformer模型的核心構建流程,包括時間序列樣本生成、模型結構定義、參數配置。其中滑動窗口長度設為30天,是基於蔬菜消費的月度週期規律;模型採用1層Transformer編碼器,兼顧預測精度與訓練效率,適合商超的實時決策需求。
未來一週銷量預測結果
我們利用訓練好的模型,對5大單品2023年7月1日-7月7日的銷量進行預測,結果如下表所示:
| 日期
單品 |
7月1日 | 7月2日 | 7月3日 | 7月4日 | 7月5日 | 7月6日 | 7月7日 |
|---|---|---|---|---|---|---|---|
| 雲南生菜 | 0.684534 | 0.692654 | 0.660538 | 0.660538 | 0.659944 | 0.670226 | 0.642454 |
| 西蘭花 | 0.286450 | 0.218427 | 0.197506 | 0.048544 | 0.158596 | 0.165053 | 0.296418 |
| 雲南油麥菜 | 0.521593 | 0.473783 | 0.508353 | 0.523837 | 0.503916 | 0.520471 | 0.520471 |
| 蕪湖青椒(1) | 0.533661 | 0.528405 | 0.502025 | 0.513878 | 0.468838 | 0.455892 | 0.509148 |
| 淨藕(1) | 1.416018 | 1.393671 | 1.398774 | 1.359892 | 1.373874 | 1.406514 | 1.375432 |
注:表中數據為歸一化後數值,實際銷量需乘以對應times(單品每日售賣次數)計算。
從預測結果來看,淨藕(1)的歸一化銷量顯著高於其他單品,是未來一週的核心補貨單品;雲南生菜、雲南油麥菜銷量相對穩定;西蘭花銷量波動較大,7月4日出現銷量低谷,商超需針對性減少當日進貨量。
結論與業務建議
核心結論
- 品類特徵差異顯著:花菜類、花葉類屬於高銷量波動型品類,水生根莖類、茄類屬於低銷量穩定型品類,不同品類需採用差異化補貨策略;
- 單品相關性有跡可循:部分單品存在明顯的正/負相關關係,可通過陳列調整、組合促銷提升連帶銷量;
- Transformer模型預測精準:基於時間序列的Transformer模型能有效捕捉蔬菜銷量的變化規律,為核心單品的短期銷量預測提供可靠支撐。
業務落地建議
- 動態補貨策略:針對TOP5高潛力單品,每日根據預測銷量調整進貨量,淨藕(1)需重點保障庫存,西蘭花則根據預測低谷期減少備貨;
- 陳列優化:將強正相關的單品(如水生根莖類與花菜類)就近陳列,提升消費者連帶購買率;
- 損耗控制:針對低銷量長尾單品,採用“小批量、多頻次”補貨模式,減少庫存積壓造成的損耗。
