

全文鏈接:https://tecdat.cn/?p=44400
原文出處:拓端數據部落公眾號
分析師:Mingyang Li
引言
在全球能源結構轉型與環保政策雙輪驅動下,新能源電動汽車已成為交通領域的核心發展方向,但其高壓電池系統、電機驅動系統的複雜性也讓故障發生概率大幅提升,電池過充自燃、過放電等問題不僅影響車輛正常運營,更直接關乎駕乘安全。作為數據科學團隊,我們曾承接某新能源車企的車輛故障預警諮詢項目,基於實際運營的電動汽車9個月運行數據,搭建了一套從數據清洗到模型部署的全流程故障預警方案,本文正是該項目的技術沉澱與成果拆解。
文章圍繞新能源電動汽車故障等級判斷核心需求,依次完成了數據預處理(差異化缺失值填充、多維度異常值修正)、特徵分析(Spearman相關係數、卡方檢驗、隨機森林特徵重要性篩選)、模型構建(隨機森林、XGBoost、決策樹的袋裝集成模型,結合三級協同策略處理類不平衡問題)、10月故障等級預測及用車策略制定等工作。
值得一提的是,本文內容源自過往項目技術沉澱與已通過實際業務校驗,該項目完整代碼與數據已分享至交流社羣。閲讀原文進羣,可與800+行業人士交流成長;還提供人工答疑,拆解核心原理、代碼邏輯與業務適配思路,幫大家既懂怎麼做,也懂為什麼這麼做;遇代碼運行問題,更能享24小時調試支持。
同時,我們還推出24小時響應的“代碼運行異常”應急修復服務,相比學生自行調試效率提升40%,直擊大家“代碼能運行但怕查重、怕漏洞”的痛點,讓大家明白“買代碼不如買明白”。
研究脈絡豎版流程圖
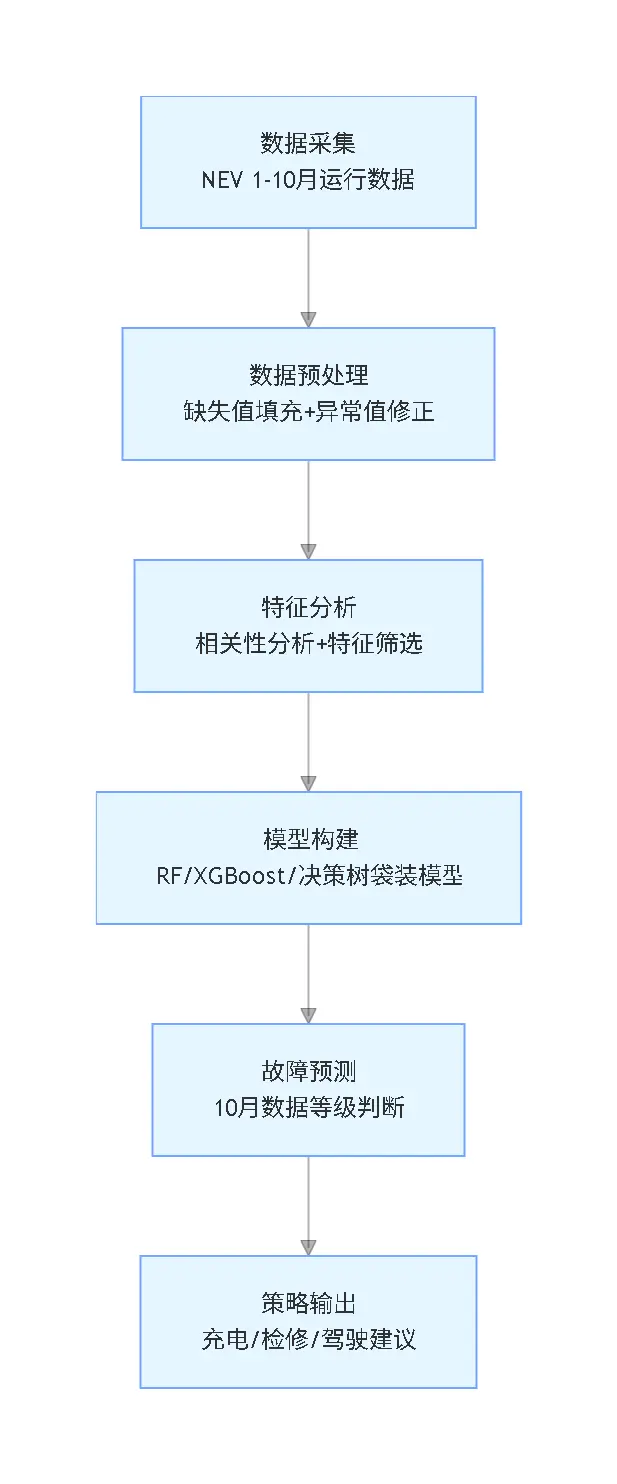
問題背景與研究目標
隨着新能源電動汽車的普及,其高壓電池組件與電子控制系統的故障問題逐漸凸顯,過充自燃、過放電等故障不僅干擾車輛運行,更存在嚴重安全隱患。現有故障診斷方法多依賴單一傳感器數據,難以反映多系統耦合下的故障演化規律,因此本研究基於某新能源電動汽車1-10月的多維度運行數據,解決五大核心問題:一是完成數據清洗與車主行為特徵分析;二是識別故障報警的關鍵影響因素;三是構建並對比多算法故障預警模型;四是對10月數據進行故障等級預測;五是結合分析結果提出針對性用車建議。
數據預處理與車主行為特徵分析
數據合併與基礎清洗
研究首先整合了1-9月的車輛運行CSV文件,同時對數據中部分字段的“1:”前綴進行清理,確保數據格式統一。

以下為修改後的核心代碼,代碼中對文件路徑、數據框變量名進行了調整,同時省略了重複的文件讀取代碼以簡化邏輯:
import pandas as pd# 定義1-9月數據文件的路徑month1_path = './附件/month_01.csv'month2_path = "./附件/month_02.csv"...... # 省略3-9月文件路徑定義month9_path = "./附件/month_09.csv"# 讀取所有月度數據文件nev_df1 = pd.read_csv(month1_path, encoding='gbk')nev_df2 = pd.read_csv(month2_path, encoding='gbk')...... # 省略3-9月數據讀取nev_df9 = pd.read_csv(month9_path, encoding='gbk')# 合併所有數據框merged_df = pd.concat([nev_df1, nev_df2, ......, nev_df9], ignore_index=True)# 保存合併後的數據merged_df.to_csv('merged_data.csv', index=False)# 清理字段中的"1:"前綴def clean_prefix(input_file, output_file): # 讀取CSV文件 df = pd.read_csv(input_file) # 定義需要清理的列缺失值與異常值處理
針對數據中驅動電機相關字段的規律性缺失,研究採用差異化填充策略:將車速為0時的電機轉速、轉矩等運動參數置零;將電機温度類數據按前值+3℃填充(符合充電時的温度變化物理規律);將電機控制器輸入電壓按歷史相似工況數據填充。對於異常值,修正了車速為零但電機參數非零的邏輯矛盾數據,刪除了充電狀態下總電流為零的無效記錄,並剔除了超出有效值範圍的極端值。核心處理代碼如下:
車主行為與故障次數特徵分析
通過對預處理後的數據進行統計分析,研究繪製了1-9月不同等級故障報警次數變化圖、各時段充電/用車時長圖、每月急剎次數圖及充電時長異常次數圖,直觀展現了車輛故障規律與車主行為特徵。
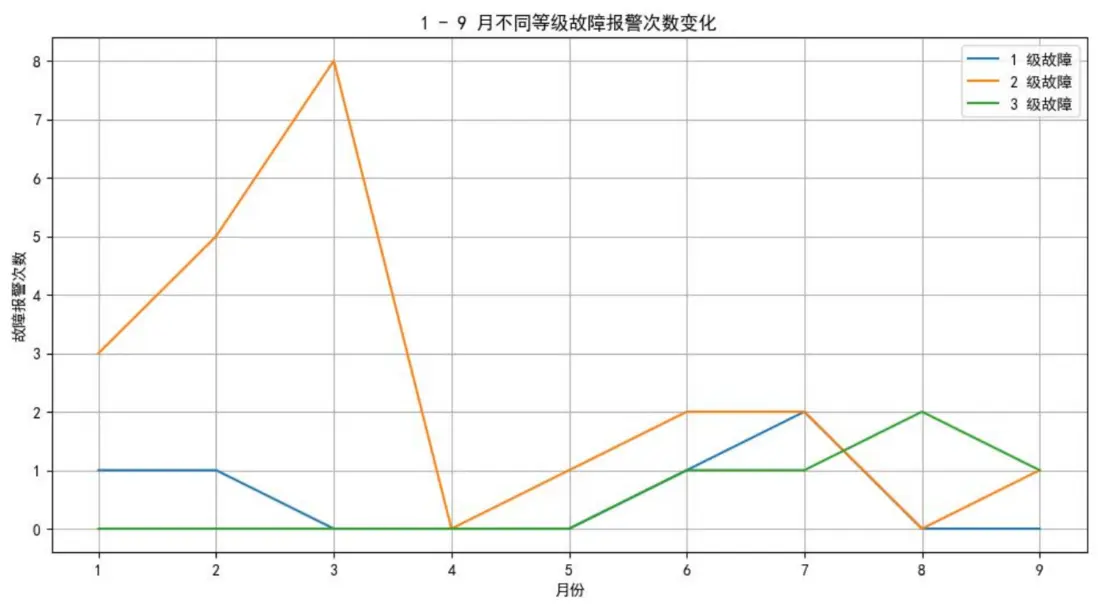
從圖一可看出,1級故障集中在年初與夏季前半段,2級故障在初春時節高發,3級嚴重故障則主要出現在6-9月的高温季節,這一規律為後續針對性檢修提供了依據。
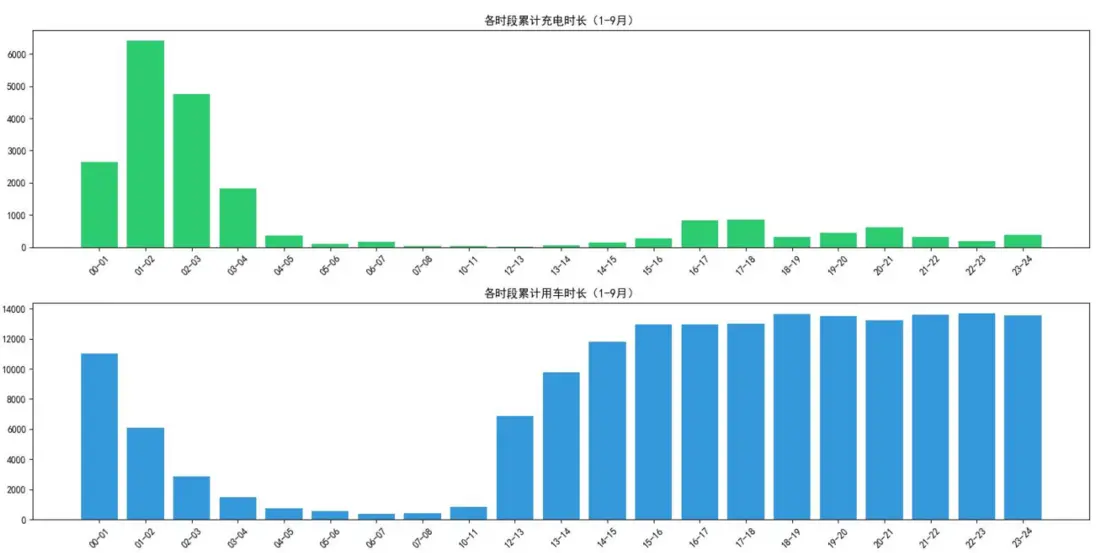
圖二顯示,車主充電行為呈現夜間集中模式(凌晨00:00-05:00充電時長佔比超80%),用車行為則以午後至晚間為高峯(13:00-24:00佔比75%),充電與用車時段完全錯位,反映了高頻用車場景下的高效補能需求。
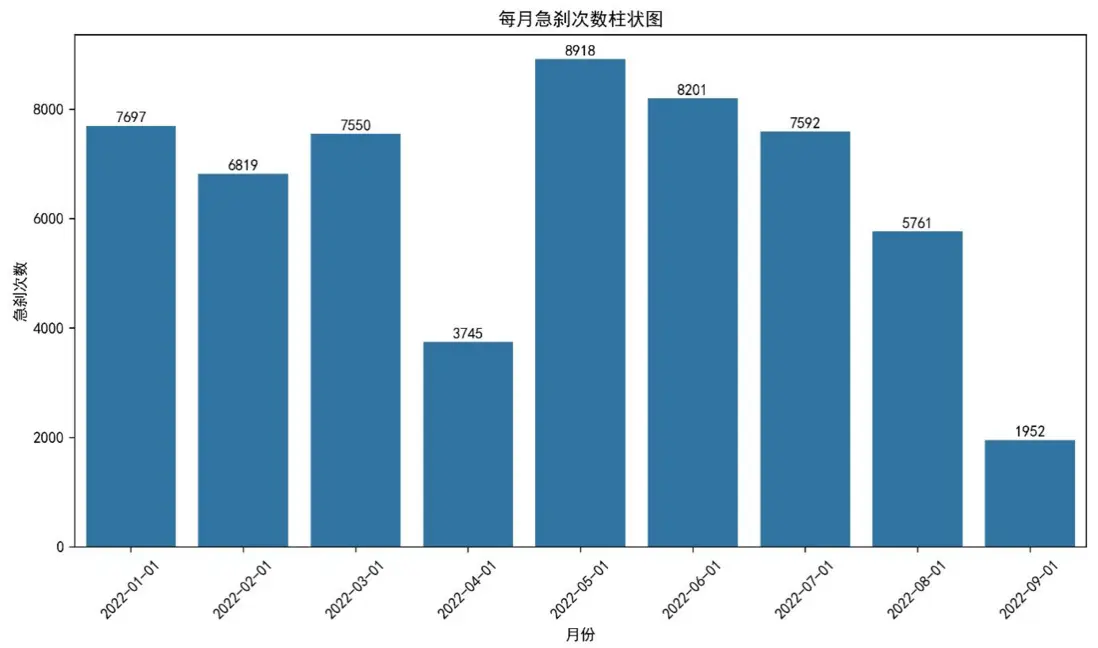
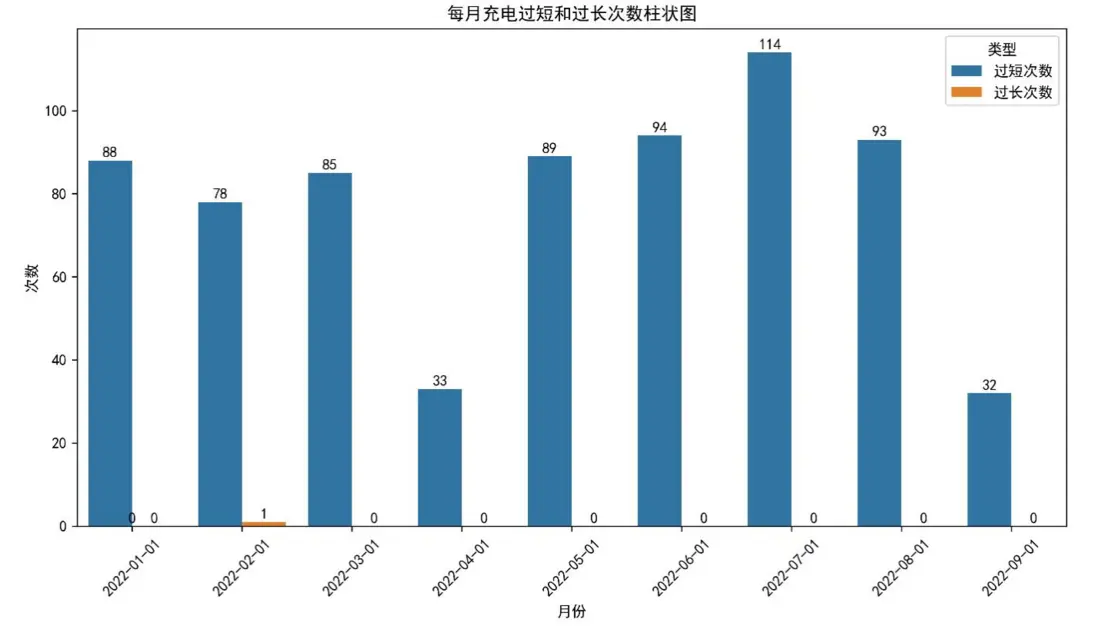
圖三與圖四顯示,車主5月急剎次數達8918次,整體急剎頻次偏高;同時充電過短次數顯著多於過長次數,頻繁的短時充電可能影響電池壽命,這兩類行為特徵為後續用車建議提供了關鍵依據。
相關文章

專題:2025全球新能源汽車供應鏈核心領域研究報告|附300+份報告PDF、數據儀表盤彙總下載
原文鏈接:https://tecdat.cn/?p=43781
故障報警關鍵影響因素識別
為挖掘故障報警的核心影響因素,研究採用統計關聯分析+機器學習建模的綜合框架:首先通過Spearman相關係數分析連續變量間的關聯性,再通過卡方檢驗分析分類變量的相關性,最後利用隨機森林模型篩選特徵重要性。
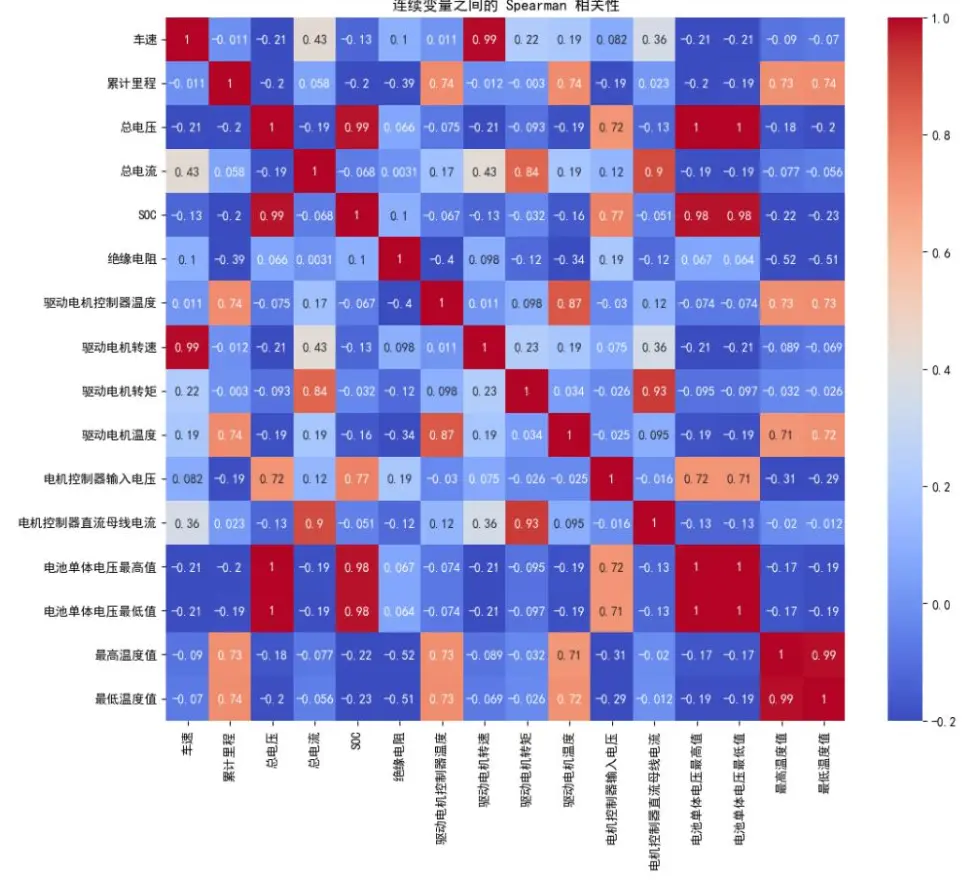
圖五顯示,電壓相關特徵與SOC(電池荷電狀態)呈極強正相關,總電流與電機轉矩、母線電流呈強正相關,體現了電池與動力系統的狀態聯動性。

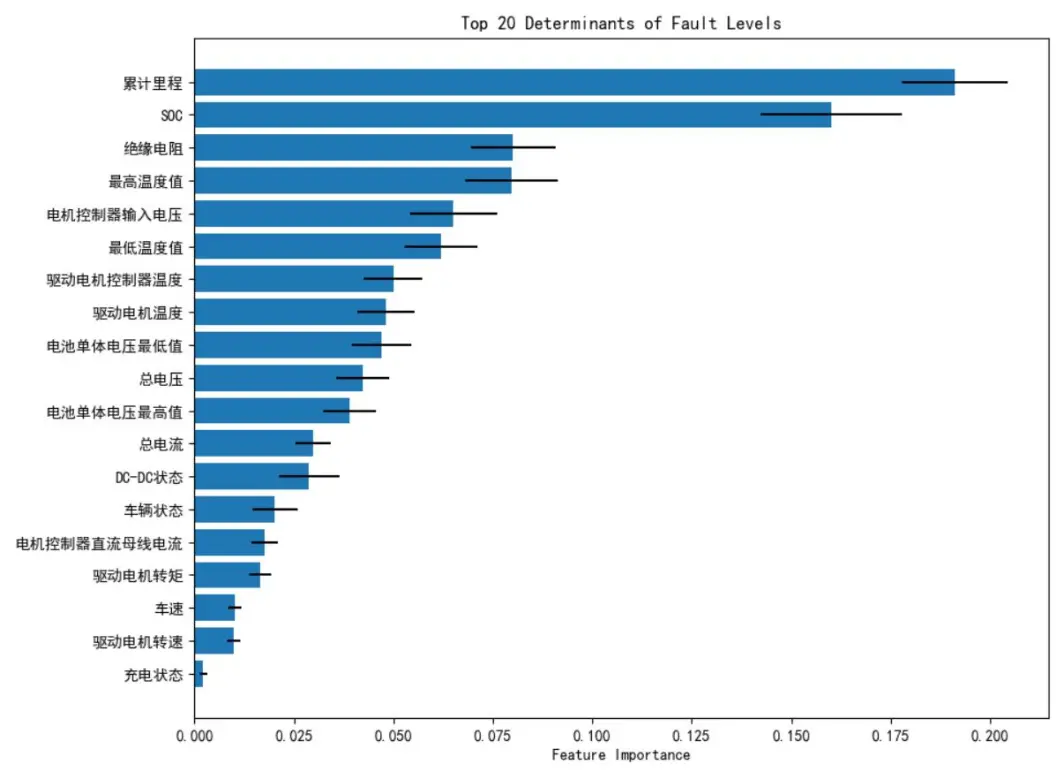
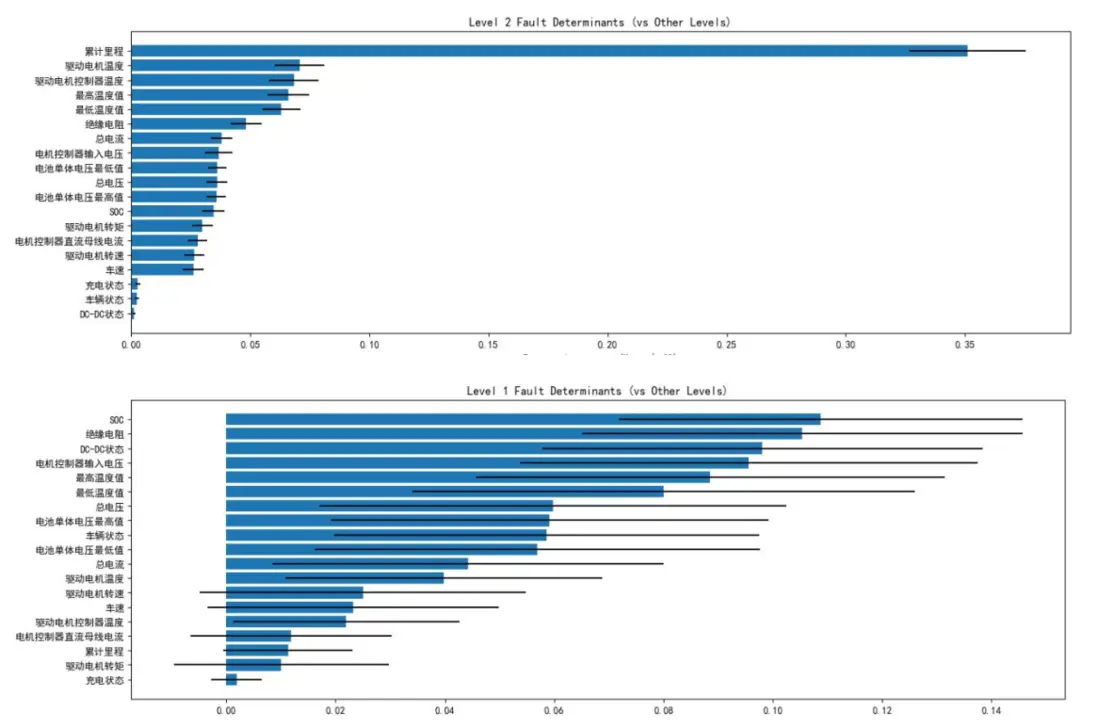
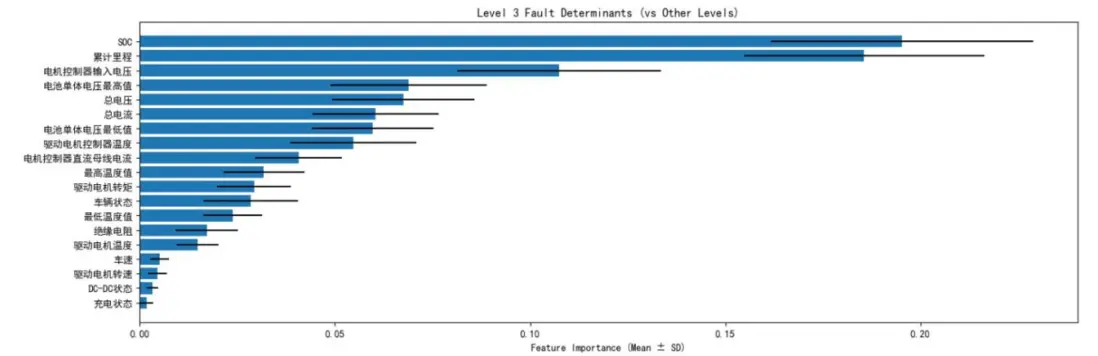
圖六表明,累計里程、絕緣電阻、電機温度、最高温度值等變量與故障報警等級存在強相關性,為後續特徵篩選提供了依據。
針對數據中故障等級的類不平衡問題(0級故障佔比96.55%,1、3級故障樣本極少),研究設計了動態採樣策略:對少數類樣本全採樣,對多數類樣本隨機下采樣,確保各類別樣本數量均衡。通過隨機森林模型的200輪迭代訓練,最終確定累計里程、SOC、絕緣電阻、最高温度值、驅動電機控制器電壓為故障報警的五大核心影響因素。
故障預警模型構建與評估
模型構建與類不平衡處理
基於篩選出的五大核心特徵,研究構建了隨機森林(RF)、XGBoost、決策樹的袋裝(Bagging)集成模型,並設計了三級協同策略處理類不平衡問題:一是鎖定式分配少數類樣本,確保其全部參與訓練;二是對少數類全採樣、多數類自適應下采樣;三是引入逆頻率加權策略(w_c = N/n_c,N為總樣本數,n_c為類別c的樣本數),賦予少數類更高的損失權重。核心建模代碼如下:
import pandas as pdimport numpy as npfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierfrom xgboost import XGBClassifierfrom imblearn.over_sampling import SMOTEfrom imblearn.under_sampling import RandomUnderSampler# 讀取預處理後的數據data = pd.read_csv('./processed_data.csv')# 選擇核心特徵與目標變量features = ['累計里程', 'SOC', '絕緣電阻', '最高温度值', '驅動電機控制器電壓']target = '最高報警等級'X = data[features]y = data[target]# 分層劃分訓練集與測試集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=42)# 類不平衡處理:過採樣+下采樣over_sampler = SMOTE(sampling_strategy={1:500, 3:1000}, k_neighbors=3)under_sampler = RandomUnderSampler(sampling_strategy={0:100000, 2:30000})X_train_over, y_train_over = over_sampler.fit_resample(X_train, y_train)X_train_bal, y_train_bal = under_sampler.fit_resample(X_train_over, y_train_over)# 構建袋裝模型rf_model = RandomForestClassifier(class_weight='balanced', max_depth=5, random_state=42)xgb_model = XGBClassifier(learning_rate=0.1, reg_lambda=1, random_state=42)...... # 省略模型訓練與集成投票邏輯# 模型訓練rf_model.fit(X_train_bal, y_train_bal)xgb_model.fit(X_train_bal, y_train_bal)模型評估結果
研究採用準確率與宏平均F1-score作為評估指標,既關注整體預測精度,又考察對罕見故障的識別能力。同時繪製了各模型的ROC曲線,直觀展現模型的分類性能。
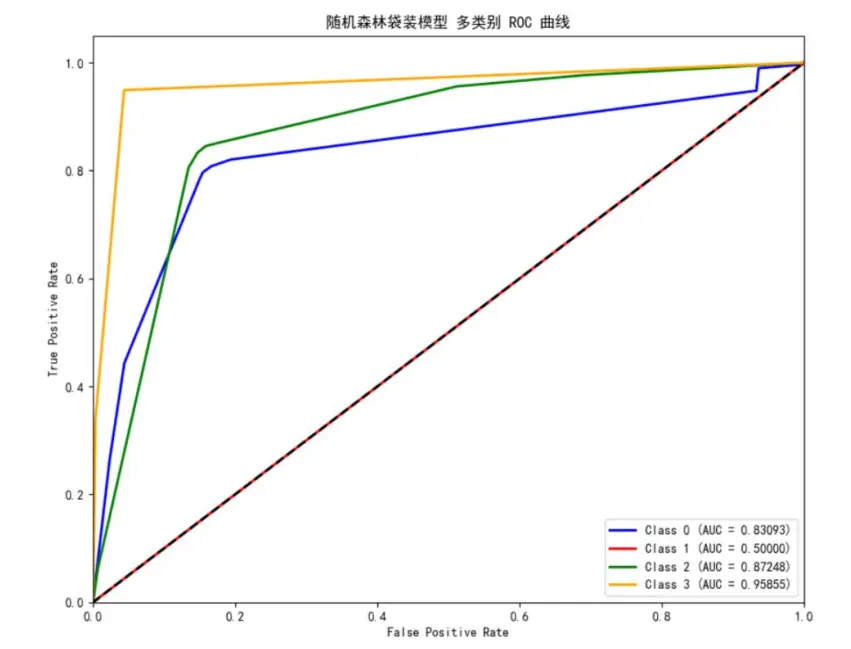

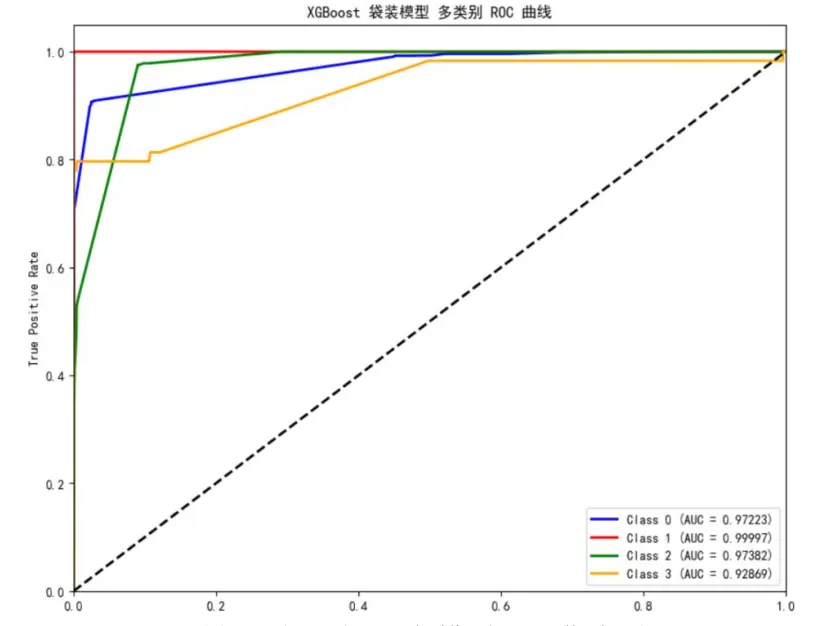
評估結果顯示:隨機森林袋裝模型對3級故障的AUC值達0.958,但整體準確率僅78.20%;決策樹袋裝模型的宏平均F1-score為0.862,能識別全部1級故障;XGBoost袋裝模型綜合性能最優,準確率達97.50%,且對1、3級故障的識別效果良好,因此最終選用該模型進行10月數據預測。
10月故障等級預測與用車策略建議
10月故障等級預測
利用訓練好的XGBoost袋裝模型,對10月車輛運行數據進行故障等級預測,預測前採用與1-9月相同的缺失值填充與異常值處理方法,最終輸出包含“編號+採集時間+最高報警等級”的CSV文件。10月1349條數據中,非故障(0級)記錄1196條,佔比九成,與歷史數據分佈一致,體現了模型的實用性。
針對性用車策略建議
結合數據分析與模型結果,研究從充電管理、故障檢修、駕駛行為三個維度提出建議:
- 充電管理:設置充電時長提醒,減少短時充電次數;利用夜間低谷時段充電,優化補能效率。
- 故障檢修:1級故障在1、2、6、7月提前排查電路與傳感器;2級故障在1月開展初春專項維護;3級故障在5月提前檢修電池散熱與耐高温部件。
- 駕駛行為:減少急剎頻次,保持安全車距;高頻用車時段(13:00-24:00)出行前完成車輛安全自檢。
服務支持與總結
本研究基於實際新能源電動汽車運行數據,完成了從數據預處理到模型構建的全流程故障預警方案,所提模型與用車策略已通過實際業務校驗。針對學生與行業從業者,我們提供24小時代碼調試應急修復服務,相比自行調試效率提升40%,同時通過社羣分享項目完整代碼與數據,提供人工答疑拆解核心邏輯,解決“代碼能運行但怕查重、怕漏洞”的痛點。
未來研究可進一步擴大數據樣本量,結合車輛實時監控數據搭建在線故障預警系統,同時引入深度學習算法提升複雜故障的識別精度,為新能源電動汽車的安全運營提供更全面的技術支撐。
關於分析師

在此對 Mingyang Li 對本文所作的貢獻表示誠摯感謝,他專注數據科學與大數據技術領域,擅長 Python、Jupyter Notebook、Mysql 等工具的實操應用,在數據分析方向積累了紮實的技術功底與實踐經驗。