

全文鏈接:https://tecdat.cn/?p=44650
原文出處:拓端數據部落公眾號

關於分析師

在此對 Jiajun Tang 對本文所作的貢獻表示誠摯感謝,他在浙江工商大學完成了應用統計專業的碩士學位,專注數據分析領域。擅長 Python、stata、spss、機器學習、深度學習、數據分析 。
Jiajun Tang 曾在科技領域從事數據分析師相關工作,參與過多源異構數據處理、用户滿意度建模等項目,積累了豐富的數據分析與機器學習建模實踐經驗。最近的參與包括為汽車行業客户提供基於數據分析的用户體驗優化與決策支持方案,助力企業精準把握市場需求,構建差異化競爭優勢。
專題:汽車用户滿意度多維度數據分析與建模實踐
引言
在汽車市場競爭日趨激烈的當下,用户滿意度已成為企業核心競爭力的關鍵指標,精準挖掘用户體驗痛點、量化各維度影響因素對滿意度的作用機制,是車企優化產品設計與服務體系的核心需求。作為數據科學家,我們始終致力於通過數據分析技術為企業提供可落地的決策支撐,而用户滿意度分析正是數據驅動業務優化的典型場景。本文內容改編自過往客户諮詢項目的技術沉澱並且已通過實際業務校驗,該項目完整代碼與數據已分享至交流社羣。
閲讀原文進羣,可與800+行業人士交流成長;還提供人工答疑,拆解核心原理、代碼邏輯與業務適配思路,幫大家既懂 怎麼做,也懂 為什麼這麼做;遇代碼運行問題,更能享24小時調試支持。
本專題圍繞汽車用户滿意度數據展開全流程分析,從數據預處理入手,通過構建感知質量特徵體系、處理多選題與文本數據,最終基於ACSI模型完成滿意度影響機制建模,並探索量表轉換的普適性。整個分析過程融合了多種數據分析方法,既解決了實際業務中數據缺失、多類型數據融合等問題,也為車企精準提升用户滿意度提供了量化依據。我們還提供24小時響應"代碼運行異常"求助的應急修復服務,讓大家明白"買代碼不如買明白",同時保證人工創作比例,直擊"代碼能運行但怕查重、怕漏洞"的痛點。
分析脈絡流程圖(豎版)
項目文件目錄結構
數據獲取與預處理
數據概況與樣本特徵
本次分析所用數據源自汽車用户調研問卷,涵蓋整車、銷售、售後三類問卷數據,樣本量分別為16907、3295和4059。問卷包含用户特徵、車型特徵、購車決策影響因素及各維度滿意度評價等內容,全面覆蓋用户購車全生命週期體驗。
數據截圖
用户基本情況分析
樣本性別、年齡及城市等級分佈如下:
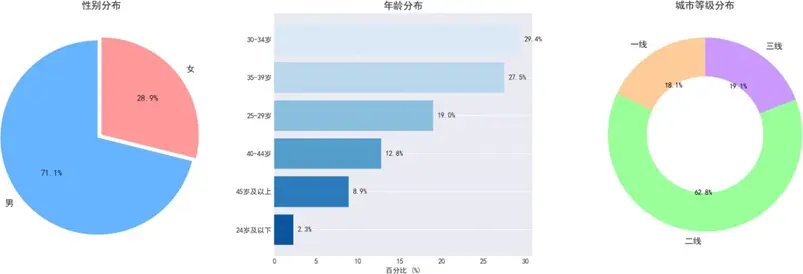
男性用户佔比71.1%,女性佔28.9%,與行業購車用户性別分佈基本吻合,且近60%男性購車會參考配偶意見,車企需重視女性決策影響力。年齡結構上,30-34歲羣體佔比最高(29.4%),30-39歲羣體合計佔比56.9%,成為消費主力。城市等級分佈中,二線城市佔62.8%,一線城市佔18.1%,三線城市佔19.1%,樣本分佈契合不同城市用户的購車需求特徵,為後續分場景分析提供支撐。
受教育程度與職業情況分析如下:
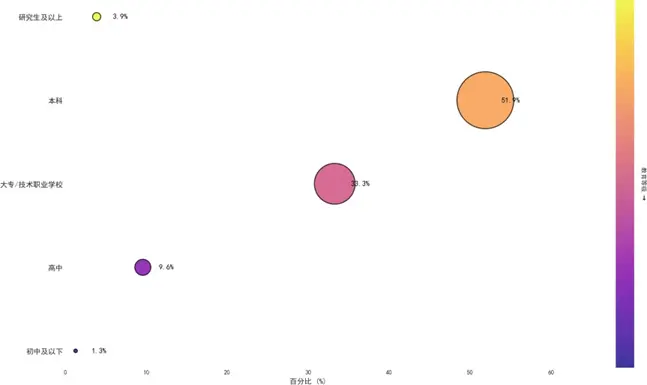

受教育程度以本科學歷為主(51.9%),專科/高職次之(33.3%),與30-39歲主力消費羣體的高等教育普及率相符。職業分佈中,企業一般人員佔比最高(47.8%),其次為企業中高管(22.2%)和個體工商業主(18.2%),這些羣體的收入水平與購車需求高度匹配,為質量可靠性、性能設計、銷售服務等核心維度的分析提供了有效樣本基礎。
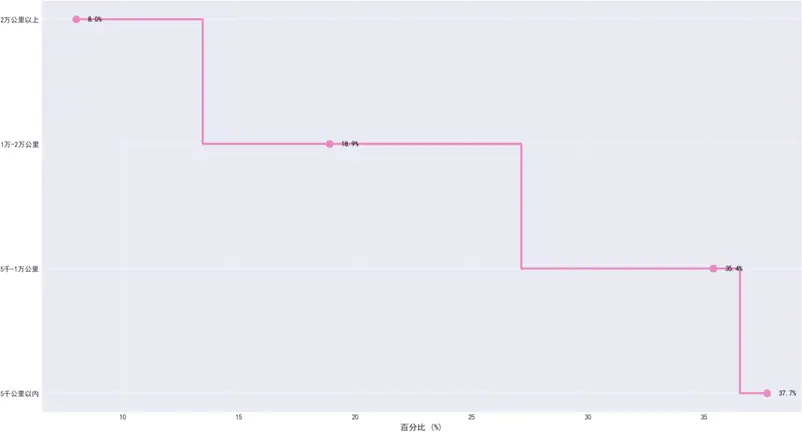
汽車行駛里程分佈
汽車行駛里程分佈中,5千公里以內和5-1萬公里的短期里程佔比73.1%,對應3-12個月新用户;1-2萬公里和2萬公里以上的中長期里程覆蓋1-3年用户,該分佈契合行業新車使用規律,可全面捕捉用户全生命週期體驗變化。
數據預處理實施
缺失值處理
我們首先對三類問卷數據的缺失值進行可視化分析:
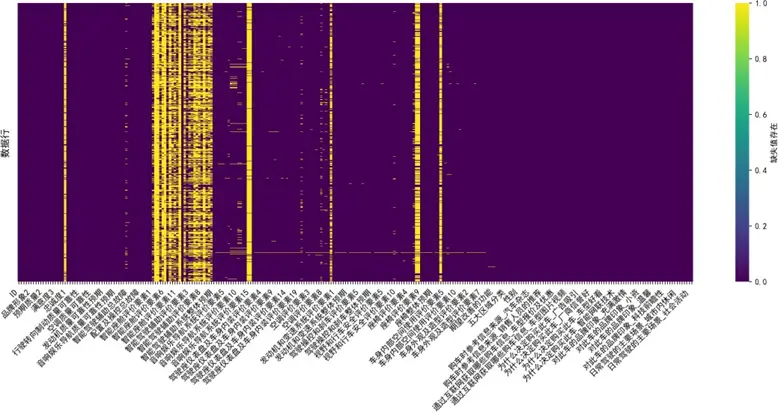
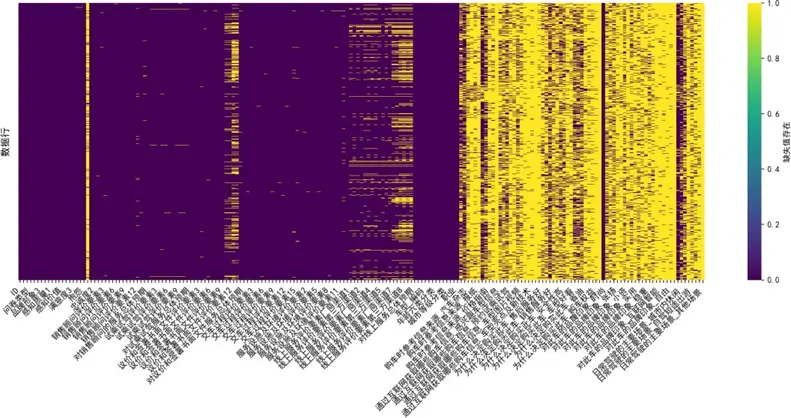

分析發現,缺失值主要集中於"購車決策動因"“信息獲取渠道"及"品牌認知"三個維度,經驗證這些維度為多選題設計,缺失本質為"未選擇該選項”,反映用户真實決策行為,故不進行填補;而感知質量細項指標的缺失值採用列均值填補,確保質量評價數據的完整性,填補後列均值偏差≤0.5%,滿足分析要求。
異常值與重複值處理
通過Python檢索發現,評分數值均在0-10的合理範圍,無異常值;利用duplicated().sum()函數統計並剔除重複行,去重後數據維度無變化,説明原始數據質量良好。
相關文章

專題:2025年遊戲科技的AI革新研究報告
原文鏈接:https://tecdat.cn/?p=44082
感知質量特徵體系構建
核心思路
數據集涵蓋滿意度、品牌形象、感知質量(含質量可靠性、性能設計、銷售服務質量、售後服務質量)等核心指標,我們採用"降維—賦權"兩步法構建各維度綜合得分:先通過因子分析(PCA)降維,剔除冗餘信息,再用熵權法基於數據變異程度客觀賦權,計算綜合得分,確保評價體系的科學性與客觀性。
質量可靠性特徵構建
因子相關性分析
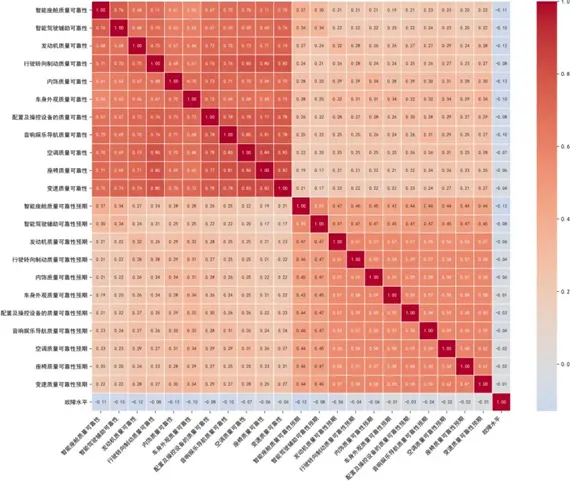
分析發現"智能駕駛輔助總故障"變量存在完全零值分佈,各子系統故障數據也普遍存在高零值佔比現象(平均89.4%)。為此,我們對所有故障變量進行加總轉換,構建複合指標,該指標作為負向代理變量,數值與系統可靠性呈顯著負相關,既解決了高零值分佈的干擾,又保留了故障信息的工程意義。
特徵變量相關性分析顯示,核心質量可靠性指標(如發動機、行駛轉向制動、智能座艙)呈中高度正相關(相關係數最高達0.75),驗證了整車質量感知的系統協同效應;質量可靠性預期指標間存在中度正相關,體現用户質量預期的"跨系統傳導效應";"故障水平"與質量指標呈負相關,驗證了指標設計合理性,為後續故障影響分析提供支撐。
主成分提取與綜合得分計算
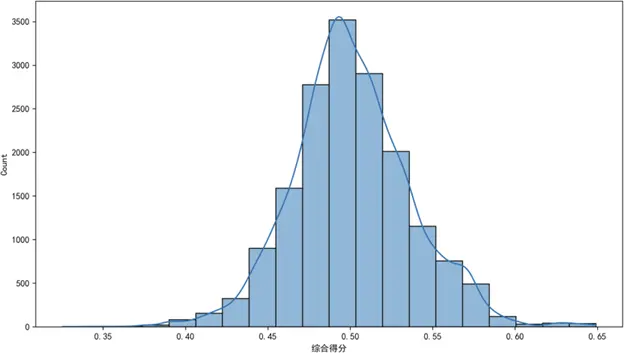
設定保留80%累積方差,通過PCA將23個子因子壓縮為8個主成分,有效降低數據維度並保留核心信息;再用熵權法計算各主成分權重,最終得到質量可靠性綜合得分。得分範圍為0.325-0.649,呈單峯近似正態分佈,峯值位於0.50附近,低分段(<0.40)與高分段(>0.60)樣本佔比均<5%,無極端異常值,數據離散性適中,説明構建的評價體系能有效刻畫用户質量感知的集中趨勢與個體差異。
性能設計特徵構建
性能設計維度含11個主因子(各平均含12個子因子)及3個開放題項。我們先以0.7為閾值剔除高相關變量,減少多重共線性干擾;對開放題採用SnowNLP庫進行情感分析,將文本評價轉換為[0,1]標準化情感分數,實現文本信息的量化。
通過PCA對25個總體評價因子降維,保留8個主成分(累計解釋方差81.24%),滿足信息保留要求;再用熵權法計算各主成分權重,得到性能設計綜合得分。得分範圍為0.288-0.692,呈單峯分佈,峯值集中於0.48-0.52,均值趨近於0.50,反映用户對整車性能設計的綜合感知處於中等偏上區間。得分核心區間為0.35-0.65(累計佔比超95%),核密度曲線近似正態分佈,説明用户對性能設計的評價分佈均勻,未出現"高/低評價雙羣體"的分化特徵,為後續優化策略制定提供了穩定的基礎數據。
性能設計因子相關性可視化
各主因子下屬子因子相關性熱力圖(部分)如下:
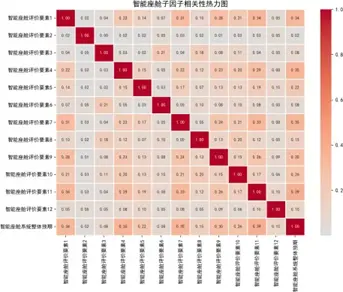
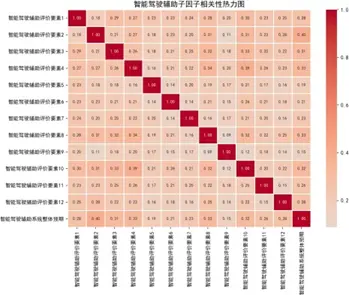
分析顯示,各主因子下屬子因子相關係數整體較低,相對獨立,説明子因子設計具有良好的區分度;而總體評價指標間呈中高強度正相關,如音響娛樂與駕駛艙內飾相關係數達0.9,驗證了用户對性能設計的整體感知一致性。
多選題及文本數據處理
多選題數據處理:MICE鏈式插補
由於三類問卷樣本量不均衡(整車16907份、銷售3295份、售後4059份),直接建模會導致特徵覆蓋不全,我們採用MICE(多組鏈式方程插補)法處理缺失數據。該方法通過建立變量間的條件概率模型,迭代預測並填充缺失值,能更好地保留數據的變異性和變量間的相關性,優於傳統均值填充等方法。
具體實施中,以"客户ID"和"滿意度"為鍵縱向合併數據集,構建定製化預測模型,經10輪迭代插補並約束值在0-1區間,生成邏輯自洽的完整數據集。插補前後數據的核密度對比顯示,填補數據保留了原始數據的分佈特徵,未引入異常值,驗證了插補模型的合理性。
隨後對多選題合計得分進行自然對數變換,合成"購車信息關注度"“互聯網購車信息獲取程度”“購車動機”“品牌認知度”"駕駛場景覆蓋度"5個新指標,這些指標能有效反映用户在購車決策各環節的行為特徵,為後續消費者分羣與滿意度影響因素分析提供了豐富的特徵支撐。
文本數據處理:基於BERT的情感分析
BERT模型原理與適配
BERT(Bidirectional Encoder Representations from Transformers)是基於Transformer編碼器的預訓練語言模型,通過雙向語義建模、掩碼語言模型(MLM)和下一句預測(NSP)等預訓練任務,能精準捕捉文本全局上下文信息,突破傳統單向模型的語義侷限。本次使用的BERT-base-chinese模型針對中文場景優化,採用字向量輸入,避免分詞誤差,可有效處理中文評論文本中的成語、網絡用語等複雜語義單元。
需要説明的是,BERT的官方倉庫Hugging Face國內可訪問,但部分海外服務器資源可能受網絡影響,國內替代品有阿里雲PAI、百度飛槳PaddleNLP等平台提供的中文預訓練模型,功能與適配性均能滿足情感分析需求。
情感分析實施與結果
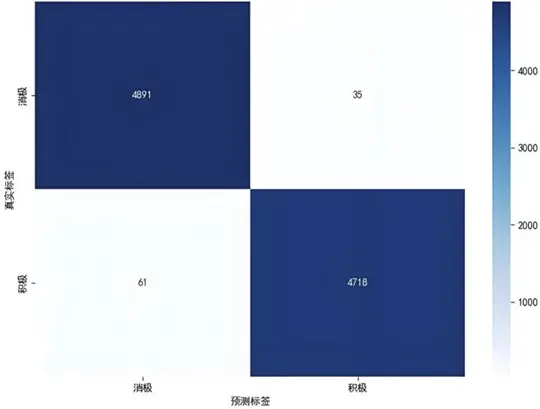
我們將"最滿意""最不滿意"評論文本分別標註為正、負情感樣本,按8:2比例劃分訓練集與驗證集,基於BERT-base-chinese模型微調3輪構建情感分析模型。模型評估結果顯示,消極與積極類別的精確率、召回率及F1分數均達0.99,整體準確率0.99,宏平均與加權平均指標亦維持0.99的高水平,體現模型在正負類別識別中實現了精確性與覆蓋性的卓越平衡。
通過詞雲圖探索文本高頻詞彙,直觀呈現用户關注焦點:


“最不滿意"文本中"油耗”"隔音"高頻出現,反映用户核心痛點;“最滿意"文本中"空間”“油耗”"外觀"佔比領先,體現產品核心優勢。同時,"最不滿意"文本中出現"沒有不滿意"表述,需通過規則校準避免誤判。
情感傾向分佈核密度圖顯示:
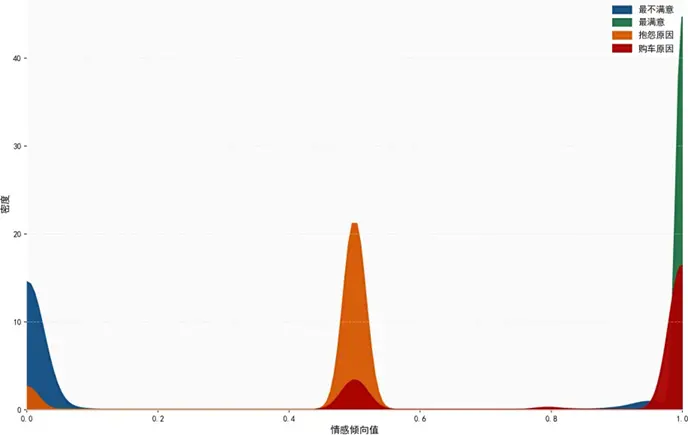
“最不滿意的地方"情感值趨近0(消極),含"無"的"抱怨原因”“購車最主要原因"文本情感值為0.5(中性),“最滿意的地方"情感值趨近1(積極),分佈界限清晰,驗證了模型分類的有效性。
我們將四項情感傾向指標(最滿意、最不滿意、抱怨原因、購車主要原因)合成"整體情感傾向"綜合指標,採用德爾菲法確定權重,綜合反映用户整體情感態度。
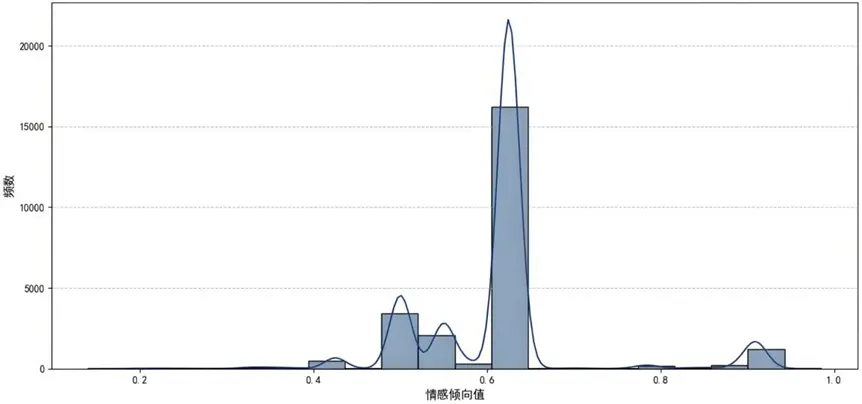
整體情感傾向值在0.6附近形成顯著峯值,超半數樣本屬於"中性偏正面"評價(整體認可但存局部不滿),構成品牌體驗的"基礎共識區間”;[0.4,0.5]區間存在次高峯,10%-20%樣本持"中性偏負面"情感,隱含體驗缺口與流失風險,可定義為"沉默的流失隱患羣體”;極端正面評價([0.8,1.0]區間)佔比極低,但作為品牌口碑核心傳播源具有戰略價值,整體分佈呈現顯著多樣性,反映用户體驗的多維複雜性。
相關代碼(修改後,省略部分訓練細節):
import pandas as pdimport torchfrom torch.utils.data import Dataset, DataLoaderfrom transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArgumentsimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score, classification_report, confusion_matrixfrom wordcloud import WordCloudimport numpy as npimport os# 創建結果文件夾result_dir = "文本情感分析"os.makedirs(result_dir, exist_ok=True)# 設置中文字體plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 本地模型路徑(國內可訪問的本地部署路徑)local_model_path = r"D:\Python\bert-base-chinese"output_model_path = r"D:\Python\bert-base-chinese-finetuned"os.makedirs(output_model_path, exist_ok=True)# 加載分詞器tokenizer = BertTokenizer.from_pretrained(local_model_path)# 定義數據集類class SentimentDataset(Dataset): def __init__(self, texts, labels, tokenizer, max_length=128): self.encodings = tokenizer(texts, truncation=True, padding='max_length', max_length=max_length) self.labels = labels def __getitem__(self, idx): item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()} item['labels'] = torch.tensor(self.labels[idx]) return item def __len__(self): return len(self.labels)# 讀取數據df = pd.read_excel('文本數據.xlsx', sheet_name='Sheet1')# 準備訓練數據positive_texts = df['最滿意的地方_開放題'].dropna().tolist()positive_labels = [1] * len(positive_texts)negative_texts = df['最不滿意的地方_開放題'].dropna().tolist()negative_labels = [0] * len(negative_texts)all_texts = positive_texts + negative_textsall_labels = positive_labels + negative_labels# 劃分訓練集和驗證集train_texts, val_texts, train_labels, val_labels = train_test_split( all_texts, all_labels, test_size=0.2, random_state=42)# 創建數據集train_dataset = SentimentDataset(train_texts, train_labels, tokenizer)val_dataset = SentimentDataset(val_texts, val_labels, tokenizer)# 加載模型model = BertForSequenceClassification.from_pretrained(local_model_path, num_labels=2)# 定義訓練參數(省略部分優化器細節參數)training_args = TrainingArguments( output_dir=output_model_path, learning_rate=2e-5, per_device_train_batch_size=8, num_train_epochs=3, weight_decay=0.01, eval_strategy="epoch", save_strategy="epoch", load_best_model_at_end=True, metric_for_best_model="accuracy",)# 定義評估函數def compute_metrics(eval_pred): predictions, labels = eval_pred predictions = np.argmax(predictions, axis=1) return { 'accuracy': accuracy_score(labels, predictions), 'report': classification_report(labels, predictions, target_names=['消極', '積極']) }# 初始化Trainer並訓練trainer = Trainer( model=model, args=training_args, train_dataset=train_dataset, eval_dataset=val_dataset, compute_metrics=compute_metrics,)trainer.train() # 省略訓練過程中的日誌輸出細節trainer.save_model(output_model_path)# 增強版情感分析函數def enhanced_sentiment_analysis(text): if pd.isna(text) or text == "無": return 0.5 text = str(text).strip() # 自定義規則校準語義複雜性 if "暫時沒有" in text or ("暫時" in text and "沒有" in text): return 0.9 if "沒有" in text and "最滿意" in text: return 0.05 if '沒有' in text and '不滿意' in text: return 0.95 # 雙重否定視為高度積極 # 模型預測核心邏輯(省略輸入預處理細節) inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True) with torch.no_grad(): outputs = model(**inputs) probabilities = torch.softmax(outputs.logits, dim=1) return probabilities[0][1].item()# 批量情感分析與可視化(省略部分重複繪圖代碼)for col in df.columns: if df[col].dtype == object: df[col + '_情感傾向'] = df[col].apply(enhanced_sentiment_analysis)滿意度模型構建與驗證
ACSI模型理論基礎
ACSI(美國顧客滿意度指數)模型由顧客期望、感知質量、感知價值、顧客滿意度、顧客抱怨和顧客忠誠六個核心構念組成,基於因果關係理論構建。該模型假設顧客會根據既往消費經驗評估未來產品質量與價值,其中顧客期望、感知質量和感知價值為前置變量,通過影響核心中介變量顧客滿意度,進而作用於顧客抱怨與忠誠兩個結果變量,形成完整的因果傳導鏈條,是國際上廣泛應用的滿意度評價框架。
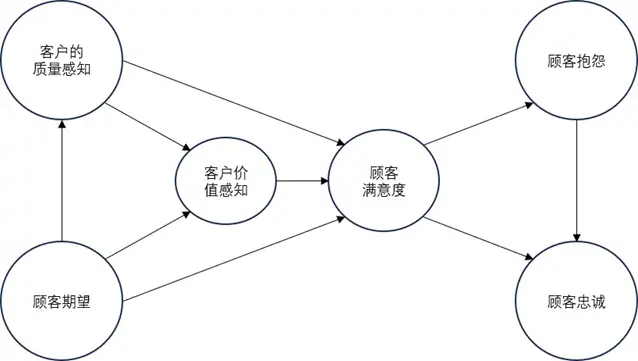
模型假設與實證檢驗
結合汽車行業特點,我們提出四項研究假設:
- 感知質量對顧客滿意度具有顯著正向影響(感知質量涵蓋質量可靠性、性能設計、銷售服務、售後服務四大維度);
- 顧客滿意度對品牌忠誠度具有顯著正向影響(忠誠度體現為重複購買意願與品牌推薦行為);
- 顧客滿意度對抱怨行為具有顯著負向影響(傳統認知中滿意度越高,抱怨越少);
- 顧客抱怨對顧客忠誠有顯著的負向影響(傳統認知中抱怨會降低忠誠度)。
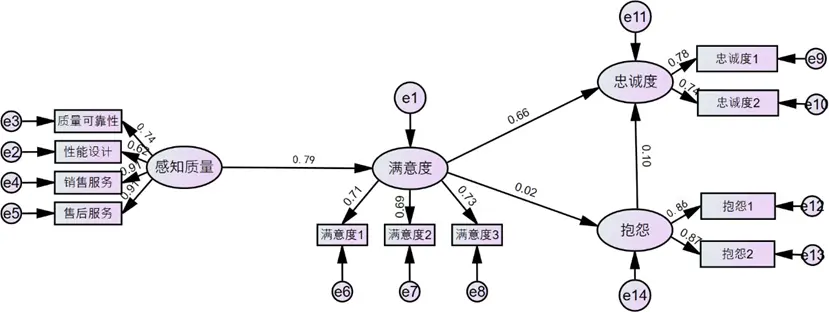
通過Amos28.0軟件進行結構方程模型擬合與檢驗,模型適配性指標均達優良水平:
- 絕對擬合指標:GFI=0.985、AGFI=0.976(均>0.9),RMR=0.01、RMSEA=0.045(均<0.05),表明模型對樣本數據擬合優度極高,殘差極小;
- 相對擬合指標:CFI=0.986、NFI=0.985、TLI=0.981(均遠>0.9),顯著優於獨立模型,證實變量間因果關係的捕捉能力;
- 泛化能力指標:ECVI=0.088<0.1,説明模型避免過擬合,泛化能力良好。
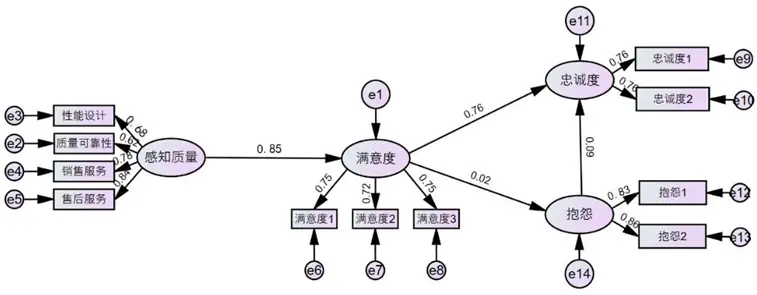
路徑關係檢驗結果如下: - 感知質量對顧客滿意度的路徑係數為0.85(CR=45.235,p<0.001),假設1成立,表明感知質量是影響滿意度的核心驅動因素,用户對產品與服務的實際體驗直接決定滿意度水平;
- 顧客滿意度對忠誠度的路徑係數為0.76(CR=92.947,p<0.001),假設2成立,説明高滿意度能顯著增強用户的品牌忠誠,推動重複購買與口碑傳播;
- 顧客滿意度對抱怨的路徑係數為0.022(CR=3.462,p<0.001),與假設3相反,呈顯著正向影響。這一結果可通過情緒強化理論解釋:滿意的用户更願意提出抱怨以改善體驗,維護自身高期望,而非單純因不滿產生抱怨;
- 顧客抱怨對忠誠度的路徑係數為0.088(CR=13.38,p<0.001),與假設4相反,呈顯著正向影響。結合顧客恢復理論,當用户抱怨得到妥善處理時,會感受到品牌對其需求的重視,進而增強信任與忠誠,將負面體驗轉化為正向情感。
IPA模型補充診斷
為精準定位優化優先級,我們引入重要性—表現分析(IPA)模型,通過計算質量可靠性、性能設計、銷售服務、售後服務四大核心維度的重要性與表現得分,構建二維決策矩陣,劃分優勢區、維持區、機會區、改進區四個象限。
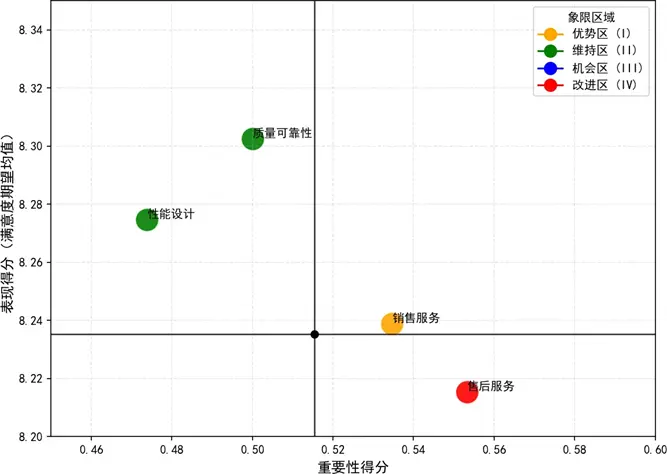
- 優勢區(Ⅰ象限):銷售服務,重要性與表現雙高,是品牌差異化競爭的核心優勢,需通過標準化流程+場景化創新持續強化;
- 維持區(Ⅱ象限):質量可靠性、性能設計,表現超均值但重要性略低,是滿意度的"基礎穩定劑",建議以輕量化迭代維持現有投入,避免資源過度配置;
- 改進區(Ⅳ象限):售後服務,高重要性但低表現,存在明顯體驗缺口,是短期資源投入的戰略優先級領域,需通過優化服務響應效率、構建分層服務方案等措施快速填補短板;
- 機會區(Ⅲ象限):無指標落入,説明核心維度均無"低重要性—低表現"的低效領域,整體佈局相對合理。
感知質量特徵交互效應分析(隨機森林-SHAP聯合框架)
為深入解析感知質量各維度的交互作用機制,我們採用隨機森林與SHAP(SHapley Additive exPlanations)聯合框架,實現"全局趨勢+局部差異"的立體解析,突破單一方法的侷限。
方法體系原理
隨機森林通過Bootstrap抽樣和特徵隨機子空間策略構建多棵決策樹,節點分裂過程天然具備特徵交互捕獲能力;SHAP基於博弈論Shapley值,計算每個特徵對預測結果的邊際貢獻,構建可加性模型,能將黑盒模型的預測結果分解為基準值與各特徵貢獻之和,實現全局與局部層面的可解釋性分析。

PDP全局交互效應可視化
通過部分依賴圖(PDP)解析特徵的邊際效應與交互效應:

單特徵邊際效應分析顯示,質量可靠性、性能設計、銷售服務、售後服務四大維度與感知質量均呈正向關聯,但曲線存在非線性波動,表明特徵與目標值間存在閾值效應或飽和效應等複雜關係,而非簡單線性關聯。
特徵交互依賴圖(部分)如下:
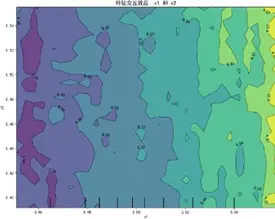
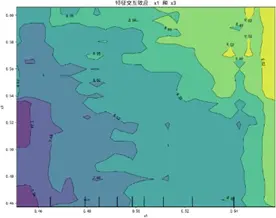
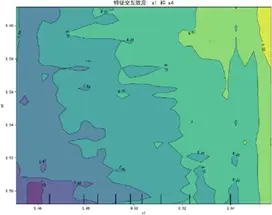
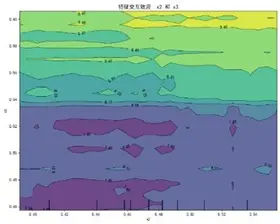
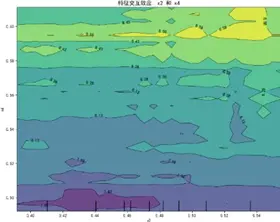
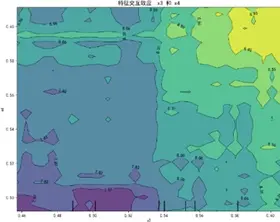
交互圖中暖色調區域對應感知質量預測高值,冷色調對應低值,揭示特徵高值組合普遍呈現正向協同效應——當兩特徵同步處於較高區間時,聯合作用對感知質量的推動更顯著(如質量可靠性與售後服務高值區預測值較低值區提升約15%),表明聚焦特徵協同優化是提升感知質量的核心路徑。
SHAP局部交互效應歸因分析
SHAP蜂羣圖與依賴圖進一步深化分析:
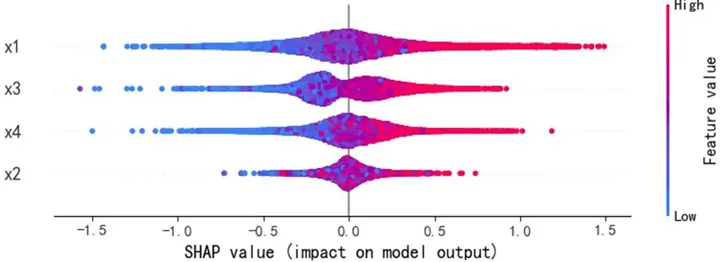
蜂羣圖顯示,質量可靠性(x1)與感知質量呈強正相關,高值(紅色)集中對應正SHAP值(顯著推升預測),低值(藍色)集中對應負SHAP值(顯著抑制預測);銷售服務(x3)、售後服務(x4)呈弱正相關,影響幅度弱於質量可靠性;性能設計(x2)為弱影響特徵,SHAP值持續圍繞0波動,對預測的邊際貢獻差異極小。

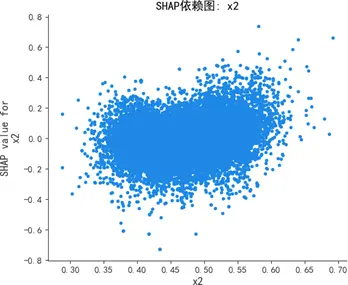
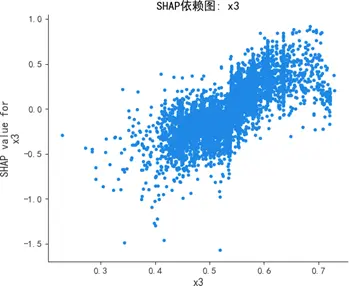
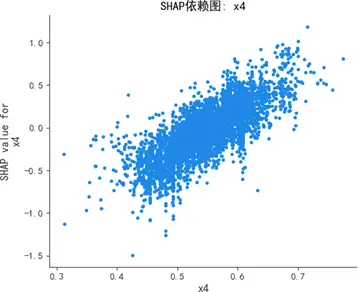
SHAP依賴圖進一步揭示:質量可靠性為線性正向特徵,取值增大時SHAP值持續上升,影響穩定且顯著;銷售服務存在閾值效應,當得分超過某一臨界值時SHAP值躍升,正向貢獻驟增;售後服務弱正向但波動顯著,穩定性較差;性能設計交互效應複雜,SHAP值分散無明確趨勢,邊際效應難以單獨解析。
通過隨機森林與SHAP的互補分析,明確了各特徵的差異化作用模式,為後續業務優化提供了精準的量化依據——如優先強化質量可靠性、突破銷售服務閾值、穩定售後服務質量等。
多模型對比與最優模型選擇
為構建更精準的滿意度預測模型,我們對比了隨機森林、XGBoost、LightGBM、CatBoost四種主流機器學習算法,通過擬合效果圖、學習曲線及性能指標綜合評估模型優劣。
模型擬合效果與學習曲線
各模型預測—真實值擬合效果圖(部分):
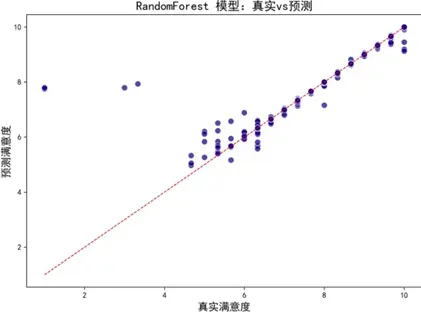
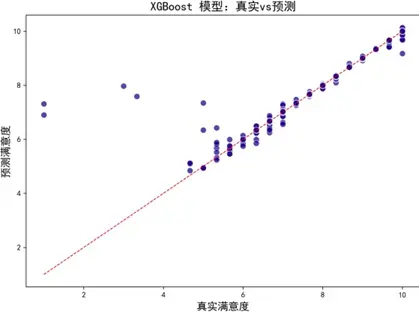
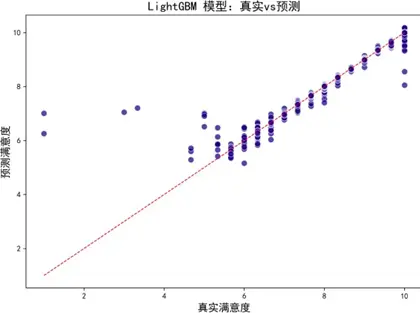
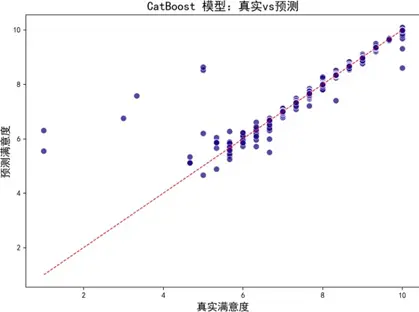
擬合效果圖顯示,各模型預測偏差均較低,與真實值一致性良好。學習曲線進一步評估模型泛化能力:
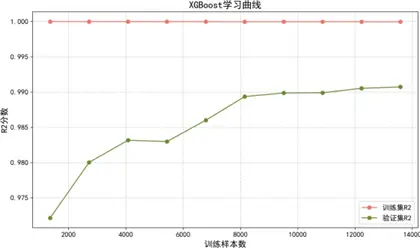
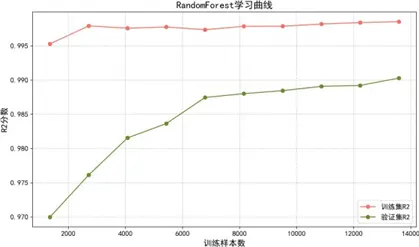
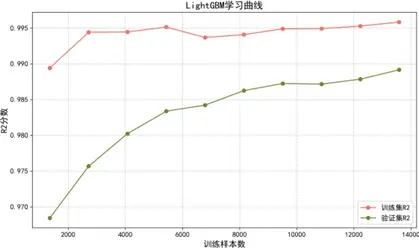
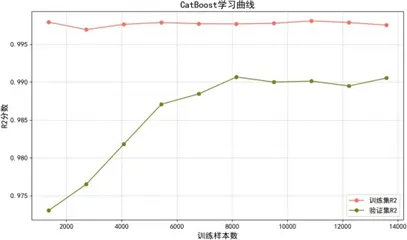
學習曲線分析表明:
- 隨機森林:通過Bagging集成與特徵採樣天然具備正則化效果,小樣本時存在輕微欠擬合,數據量增加後泛化能力穩步提升,無顯著過擬合;
- XGBoost:通過貪心分裂、L1/L2正則及剪枝策略平衡擬合與泛化,數據量增加後方差降低,有效緩解過擬合;
- LightGBM:採用直方圖算法與GOSS採樣優化效率,擬合與泛化平衡最優,訓練集與驗證集性能差異小,方差低;
- CatBoost:通過有序提升與類別編碼處理,對數據分佈變化敏感,中期因樣本分佈波動性能略有震盪,最終穩定收斂,泛化穩健性強。
模型性能評估與超參數調優
基於R²、MAE、MSE三項核心指標評估模型性能:
| 模型 | R² | MAE | MSE |
|---|---|---|---|
| 隨機森林 | 0.9227 | 0.0193 | 0.0285 |
| XGBoost | 0.9568 | 0.0152 | 0.0213 |
| LightGBM | 0.9315 | 0.0173 | 0.0237 |
| CatBoost | 0.9752 | 0.0128 | 0.0172 |
CatBoost模型表現最優,R²達0.9752,較次優模型提升約2%,MSE低至0.0172,較其他模型降低20%-30%,擬合優度與誤差控制能力均領先。
通過網格搜索算法對CatBoost進行超參數調優,定義學習率、最大樹深度、迭代次數等關鍵參數空間,採用五折交叉驗證評估各參數組合性能:
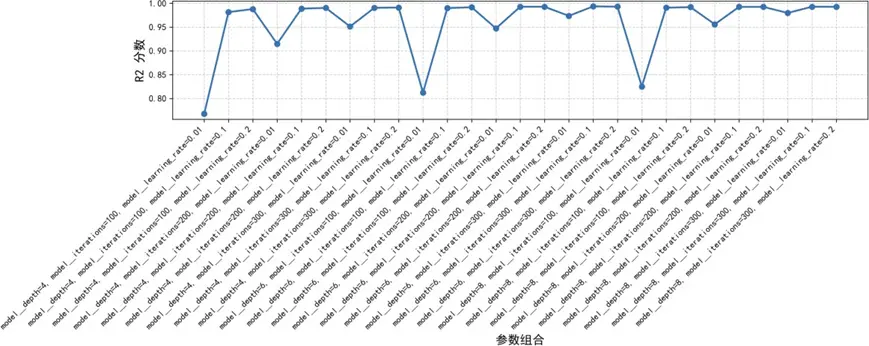
當學習率為0.1、最大深度為6、迭代次數為300時,模型達到最優性能,R²提升至0.9935,進一步提升了預測精度。
CatBoost模型SHAP可解釋性分析
對優化後的CatBoost模型進行SHAP可解釋性分析,揭示核心影響因素:
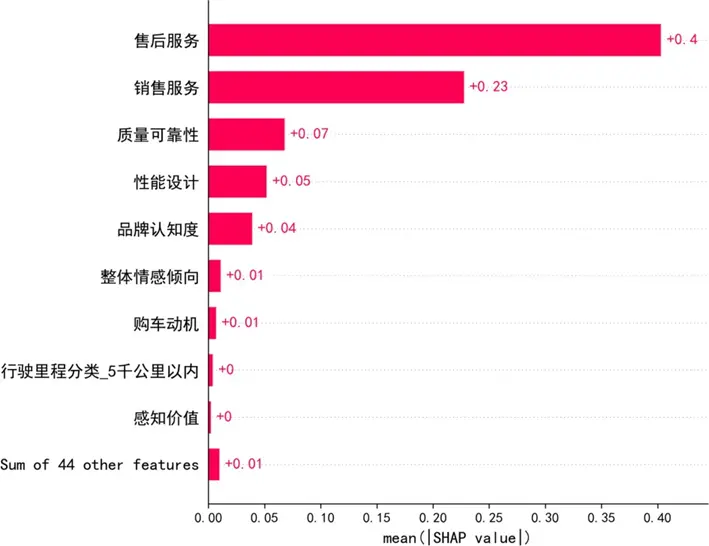
SHAP特徵重要性顯示,售後服務(0.40)、銷售服務(0.23)對滿意度的解釋力最強,是核心驅動因素;質量可靠性(0.07)、性能設計(0.05)、品牌認知度(0.04)等呈顯著正向影響,其餘44項特徵總貢獻僅0.01,邊際效應可忽略。
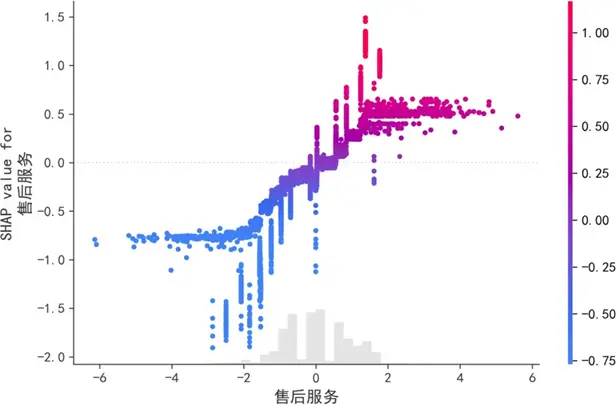
售後服務的SHAP依賴圖表明,其對滿意度的影響呈非線性:評分<2時SHAP值多為負,抑制滿意度;評分>2後,SHAP值隨評分上升呈非線性增長,且增長速率逐漸加快,凸顯售後服務質量突破臨界值後的顯著正向效應。
通過SHAP瀑布圖解析典型樣本的預測邏輯:
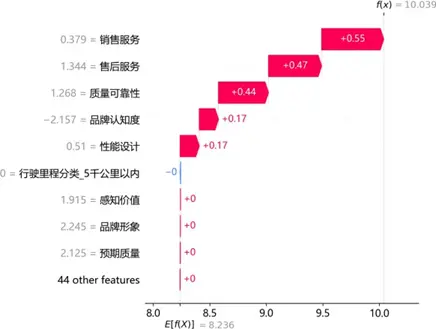
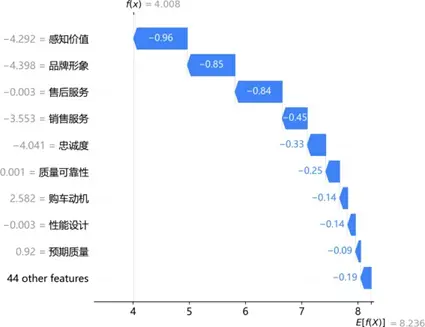
高滿意度樣本中,銷售服務(0.55)、售後服務(0.47)、質量可靠性(0.44)及品牌認知度(0.17)為核心正向驅動,共同推升預測值顯著高於均值;低滿意度樣本中,感知價值(-0.96)、品牌形象(-0.85)、售後服務(-0.84)及銷售服務(-0.45)為關鍵負向拖累,即使質量可靠性等存在微弱正向貢獻,仍無法抵消整體抑制效應。同一特徵(如售後服務)在不同樣本中呈現雙向差異貢獻,印證其影響的非線性與情境依賴性,為精準化服務策略制定提供了微觀層面的依據。
量表轉換策略對比與普適性分析
傳統十級量表調研存在繁瑣性問題,不利於快速收集用户反饋,我們探索通過K-means聚類與GMM(高斯混合模型)將其轉換為更簡潔的二分法(滿意/不滿意)與五級量表,並驗證轉換後模型的有效性與普適性。
K-means二分法量表轉換與建模
轉換規則與驗證
K-means是基於距離的硬聚類算法,通過迭代優化質心位置,將數據劃分為緊湊且分離的簇。我們採用K-means++初始化策略(優化初始質心選擇),將十級量表映射為二分法(0=不滿意,1=滿意),該方法能動態適配數據分佈,較固定閾值法更適應偏態數據特徵。
轉換後各子維度的高—低分組頻率分佈(部分):
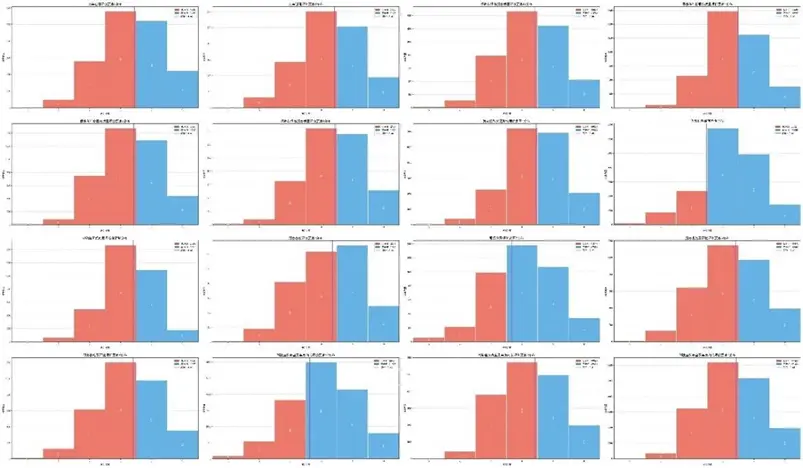
分佈分析顯示,高分組在"交車過程評價""保養服務質量"等維度呈右偏分佈(峯值3-5分),低分組在1-3分佔比顯著,二者邊界清晰;K-means自適應閾值能有效劃分羣體,即使在"智能網聯功能體驗"等偏態分佈維度也能精準區分,驗證了轉換規則的合理性。
通過輪廓係數(多數維度>0.7)與Calinski-Harabasz指數(部分維度突破10,000)評估聚類質量,結果表明簇內緊湊性與簇間分離度良好,聚類結構具有統計顯著性。
品牌偏好交叉分析
二分法分組與品牌屬性的交叉分佈通過桑基圖可視化:
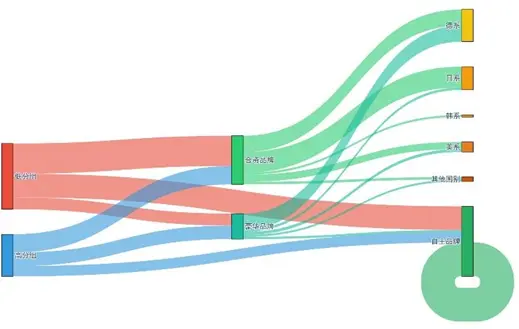
桑基圖清晰呈現:0分組(不滿意)更偏好合資品牌的德系/日系車型,1分組(滿意)更傾向豪華品牌;這種羣體品牌偏好異質性,為車企差異化營銷提供了精準依據——如對0分組用户推送合資品牌優化升級信息,對1分組用户強化豪華品牌專屬服務體驗。
二分法下ACSI模型構建
參照感知質量特徵構建方法,對二分法數據進行PCA降維與熵權法賦權,計算各維度綜合得分:
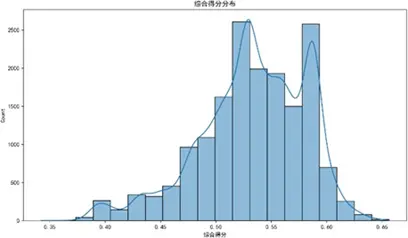
綜合得分分佈特徵顯示,質量可靠性得分集中於0.50-0.60(單峯分佈),表現穩定;性能設計峯值在0.40-0.50(左偏分佈),需突破高分段;銷售服務低分段佔比高,為核心短板;售後服務分佈分散、兩極分化,需強化中間段穩定性。
基於二分法數據構建ACSI模型,擬合指標均達優良水平(GFI=0.955、AGFI=0.925、CFI=0.958等),核心路徑關係與原十級量表模型一致,驗證了二分法轉換的有效性。
GMM五級量表轉換與建模
轉換原理與特徵驗證
GMM(高斯混合模型)是概率生成模型,假設觀測數據由K個高斯分佈混合生成,通過EM(期望最大化)算法迭代估計分佈參數(均值、方差、權重),實現軟聚類(每個樣本有屬於各簇的概率)。該方法能捕捉數據的概率分佈特徵,較K-means硬聚類更靈活,適合量表的精細劃分。
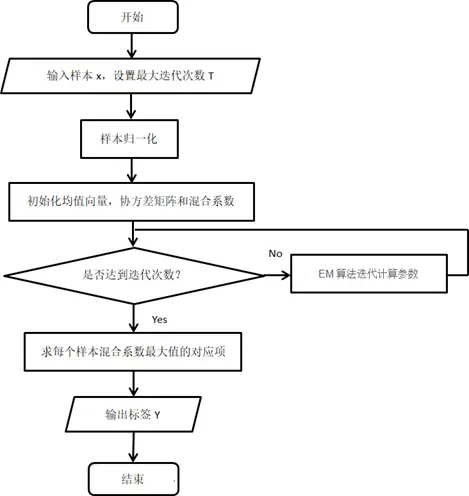
通過GMM將十級量表轉換為五級量表(1=極不滿意至5=極滿意),轉換後各子維度頻率分佈(部分):
多數維度呈"中間集中"的正態分佈(3-4級佔比超60%),與GMM擬合的概率分佈一致;部分維度(如"智能網聯功能體驗")呈偏態分佈,反映用户體驗短板,GMM能精準識別此類差異,較傳統均勻分段法更具科學性。
聚類質量評估顯示,各維度輪廓係數普遍接近1,Calinski-Harabasz指數在體驗型指標(如"服務響應時效")中顯著高於感知型指標(如"品牌感知"),樣本點集中於"高指數—高輪廓係數"區域,驗證了五分類的可靠性。
品牌偏好與綜合得分分析
五分類羣體與品牌屬性的交叉分佈桑基圖:
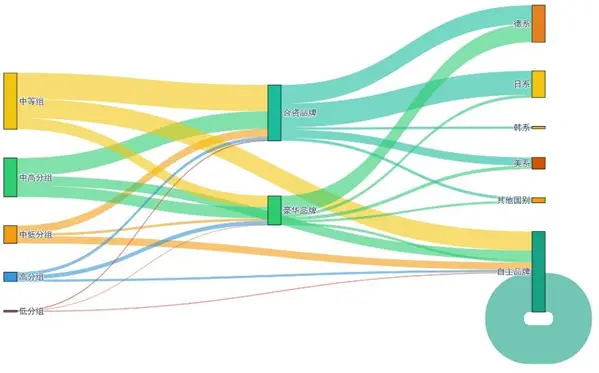
高分組(4-5級)集中選擇豪華品牌(德系/日系為主),中高分組(3-4級)兼顧合資與豪華品牌,中等組(3級)偏好合資德系/日系,中低分組(2-3級)分散選擇合資日系/韓系及自主品牌,低分組(1-2級)多傾向合資韓系/美系與自主品牌,為分層營銷與服務提供了更精細的依據。
對GMM轉換後數據進行PCA降維與熵權法賦權,計算各維度綜合得分,分佈特徵顯示:質量可靠性表現穩定、高分段佔比高;性能設計分佈均衡,需聚焦用户需求優化;銷售服務與售後服務需重點關注中間段體驗修復,提升整體穩定性。
GMM下ACSI模型構建
基於GMM轉換數據構建ACSI模型,擬合指標優良(GFI=0.980、AGFI=0.966、CFI=0.981等),核心路徑關係與原模型一致,進一步驗證了量表轉換的有效性。
普適性分析結論
兩種量表轉換方法代入ACSI模型後,核心結論與原十級量表完全一致,表明尺度轉換未改變潛變量核心結構(如"感知質量→滿意度→忠誠"的因果路徑),僅需區分"高/低表現"即可維持變量影響邏輯。同時,K-means硬聚類與GMM軟聚類的分類結果均支持相同結論,佐證了聚類方法的兼容性與數據羣體分類邊界的明確性。
結構方程模型對觀測變量尺度轉換的包容性是結論普適性的核心原因——只要觀測題項能反映潛變量的"高低水平",無論採用十級、二分還是五級量表,模型的因果推斷基礎均不受影響。這一發現為企業實際調研提供了靈活選擇:可根據調研場景(如快速問卷、深度調研)選擇合適的量表尺度,在降低調研成本的同時,保證分析結論的一致性與可靠性。
總結與業務建議
核心結論
- 感知質量是滿意度的核心驅動因素,其中售後服務與銷售服務的貢獻度最高,質量可靠性與性能設計為基礎支撐,四者協同優化能顯著提升用户滿意度;
- 滿意度與抱怨、忠誠的關係突破傳統認知:滿意用户更願意提出抱怨(正向影響),妥善處理抱怨能增強忠誠(正向影響),形成"滿意→主動反饋→抱怨修復→忠誠強化"的正向循環;
- 量表轉換具有普適性,K-means二分法與GMM五級量表轉換後,ACSI模型結論與原十級量表一致,企業可靈活選擇量表尺度以適配不同調研需求;
- 用户體驗存在顯著異質性:二線城市、30-39歲、企業一般人員/中高管是核心消費羣體,品牌偏好呈現分層特徵,豪華品牌用户更關注服務質量,合資品牌用户重視性價比,自主品牌用户對基礎性能要求較高。
業務建議
- 產品端:構建全鏈路質量閉環管理,通過用户抱怨數據反推產品優化(如針對"油耗"“隔音"等痛點升級技術);將抽象質量轉化為可感知信息(如"50萬公里模擬測試記錄”),強化用户質量感知;
- 服務端:優先改進售後服務短板,建立"24小時智能響應通道"與分層服務方案;鞏固銷售服務優勢,打造標準化+場景化的服務流程;建立高效抱怨處理機制,將抱怨轉化為忠誠提升契機;
- 營銷端:基於用户分層特徵制定差異化策略,對核心消費羣體精準推送產品與服務信息;激活高忠誠用户的口碑傳播價值,授予"品牌體驗官"身份,通過新品試駕、定製化活動等放大口碑效應;
- 調研端:根據實際需求選擇量表尺度,快速調研採用二分法降低用户填寫成本,深度調研採用五級量表獲取更精細的體驗數據,提升調研效率與效果。
