

Python 爬蟲是什麼?
我們在網絡上收集資料的過程其實就稱之為爬蟲(web scraping)。複製粘貼歌詞、摘抄文本或數據都可以算作爬蟲的一部分,但網絡編程背景下的爬蟲,更強調自動化,通過 Python 編程實現自動爬取資源,從而減少人力資源與精力消耗,提高效率。
注:在動手爬蟲之前,程序員們還是需要考慮一些法律相關的問題。一般而言,開源或教育相關用途的爬蟲並不會觸及法律問題,但若用作其他商業用途或涉及一些敏感事物,爬蟲也可能涉及違反服務條款甚至其他法律糾紛。同樣地,有些網站也會避免爬蟲而通過其他手段提高安全門檻。
在法律允許的範圍內,學習使用 Python 實現自動化爬蟲能讓大家在資訊紛雜的網絡世界中,快速地收集自己所需的資料。這篇文章將通過虛構的求職網站 Fake Python 以及使用 Lightly IDE 展示完整的項目代碼,引導大家在無需安裝第三方軟件的情況下,動手在瀏覽器中編寫代碼,瞭解 Python 爬蟲。
Lightly 爬蟲項目代碼:https://538cd3972a-share.lightly.teamcode.com
瞭解網站的基礎結構
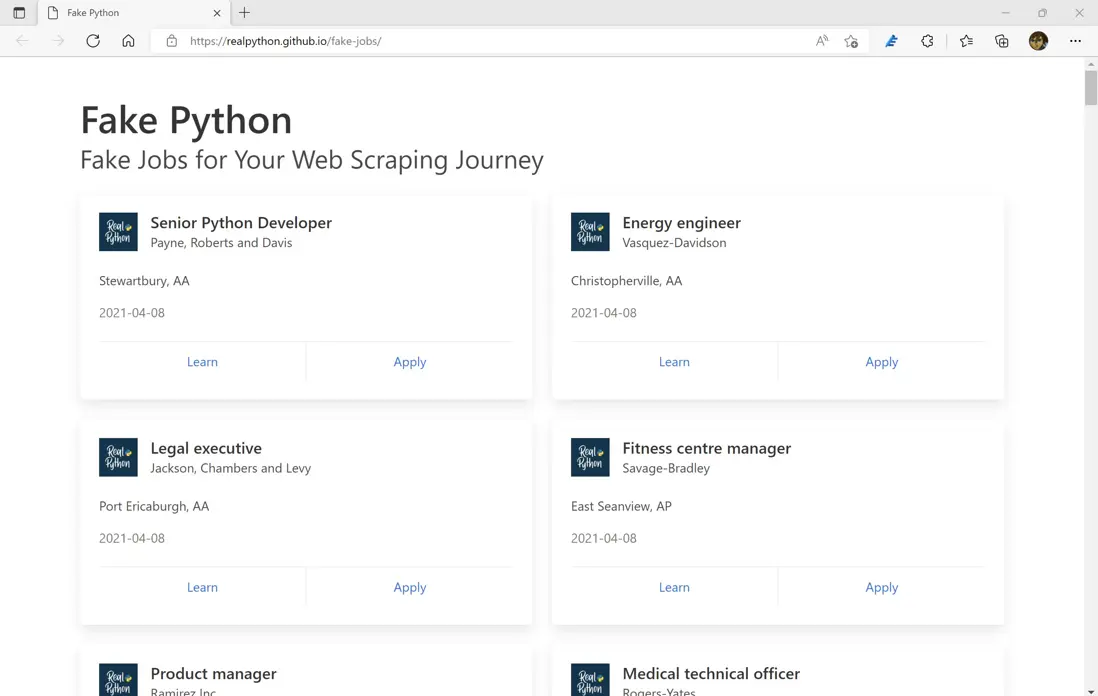
在開始編寫 Python 代碼前,合格的程序員還是需要具備基礎的網頁知識。在這裏打開教程中所使用的網頁:https://realpython.github.io/fake-jobs/
右鍵點擊“查看頁面源代碼”,打開後將展示網頁的 HTML 代碼。
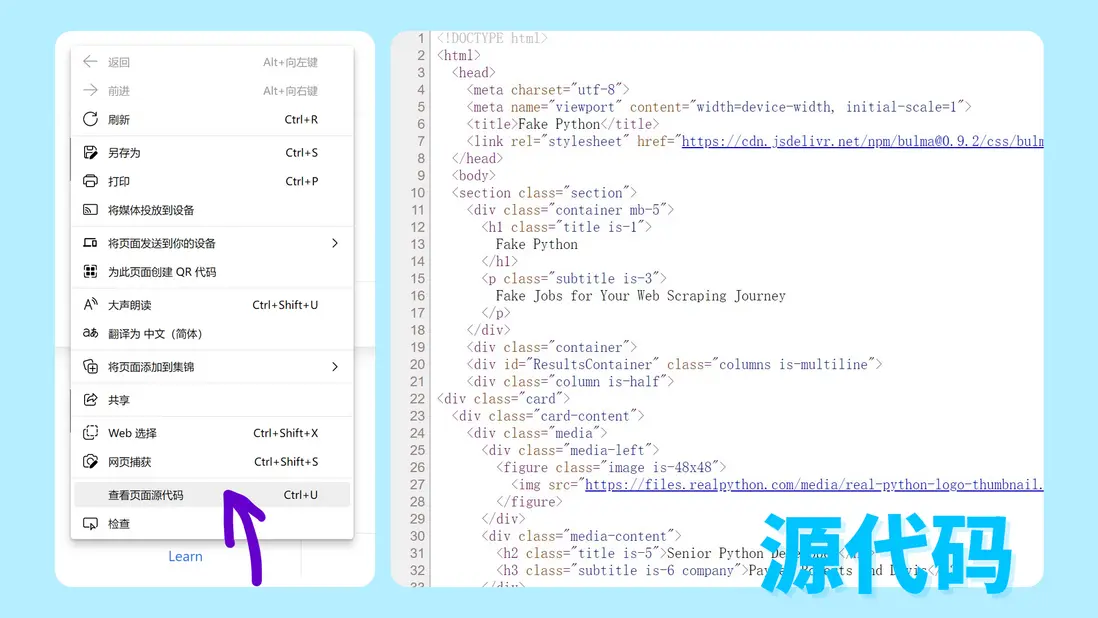
除了右鍵查看外,使用 Windows 的同學也可以通過 Ctrl + Shift + I (MacOS: Cmd + Alt + I)的方式調動開發人員工具,在“元素”中查看源代碼。使用開發人員工具可以摺疊或展開代碼,也可以根據鼠標懸浮展示代碼在網頁中所對應的內容。
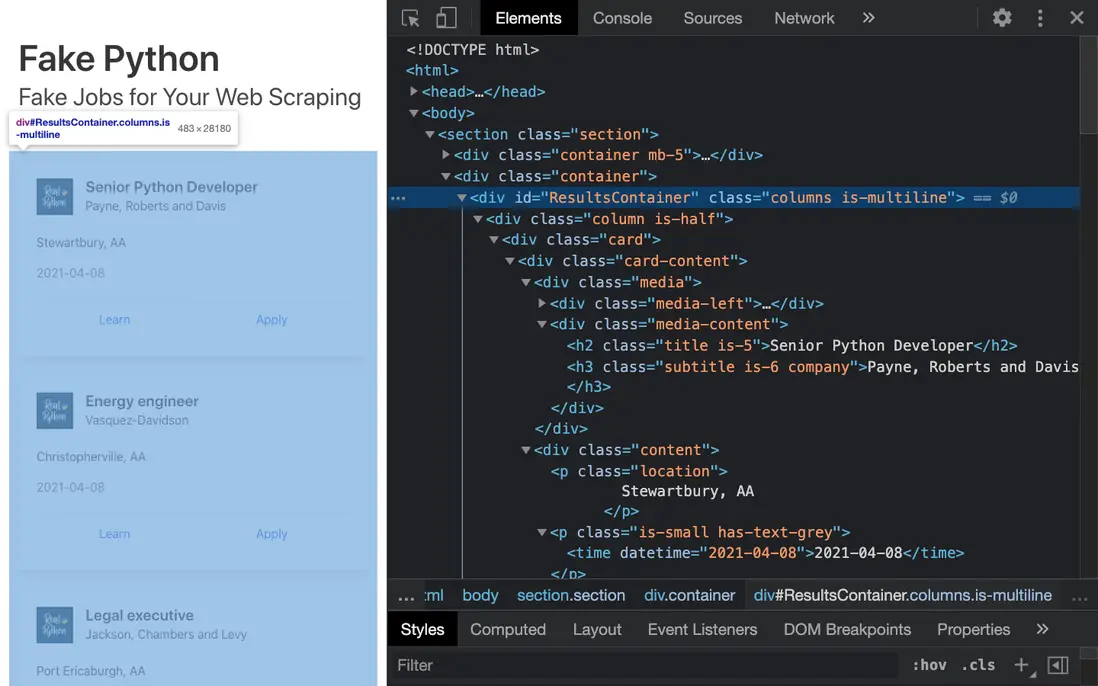
在 Python 爬蟲中,同學們無需被紛亂的 HTML 代碼勸退。一般而言,我們可以關注 id / class 等元素,從中找到對應的分組,即可借用 Python 和 Lightly IDE,從這些代碼中分析出我們所需的內容。
先行準備:安裝 requests 及 BeautifulSoup 庫
初次使用 Lightly 或此前未安裝 requests 及 bs4 庫的同學,在開始編寫項目代碼前需在終端通過 pip install requests 以及 pip install bs4 分別安裝依賴。
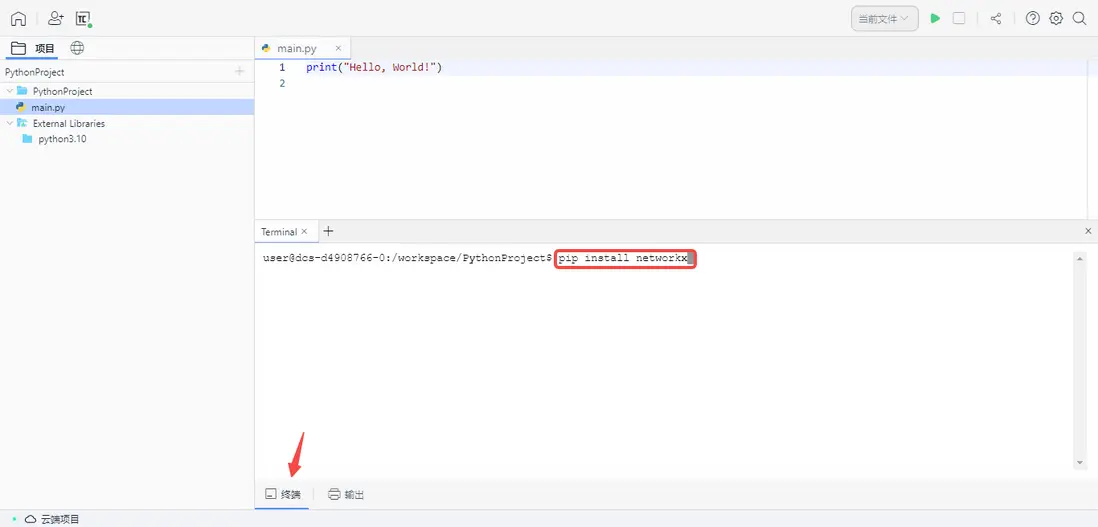
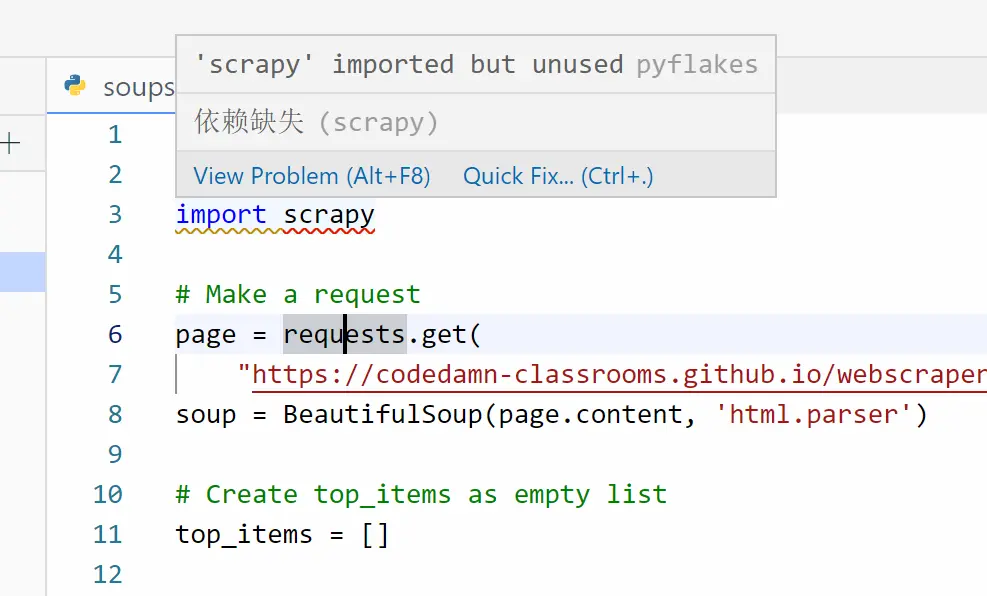
若此前忘了安裝,使用 Lightly 的同學也可以通過 QuickFix 的方式,一鍵安裝缺失依賴。
手把手實操 Python 爬蟲
通過 Lightly 快照中的 Python 項目代碼,複製到個人項目中進行學習:https://538cd3972a-share.lightly.teamcode.com
如何打開並編輯他人用 Lightly 分享的項目?
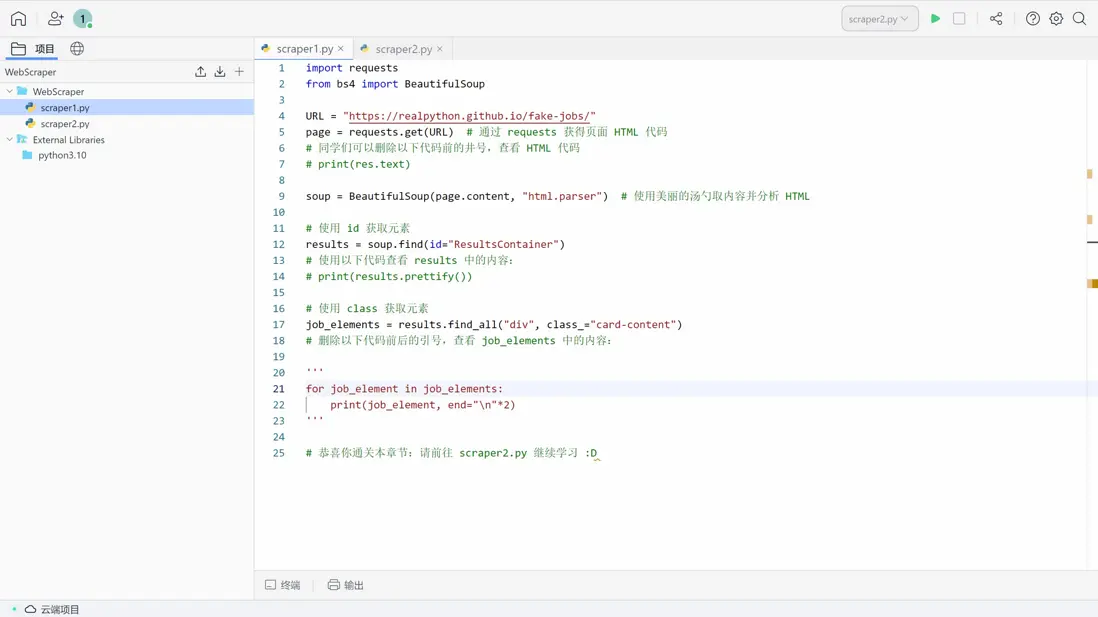
注:快照複製到個人項目後,任何修改都不會影響到原本的快照鏈接,同學們可放心對自己的代碼進行修改,也可以隨時通過快照鏈接再次查看源代碼。
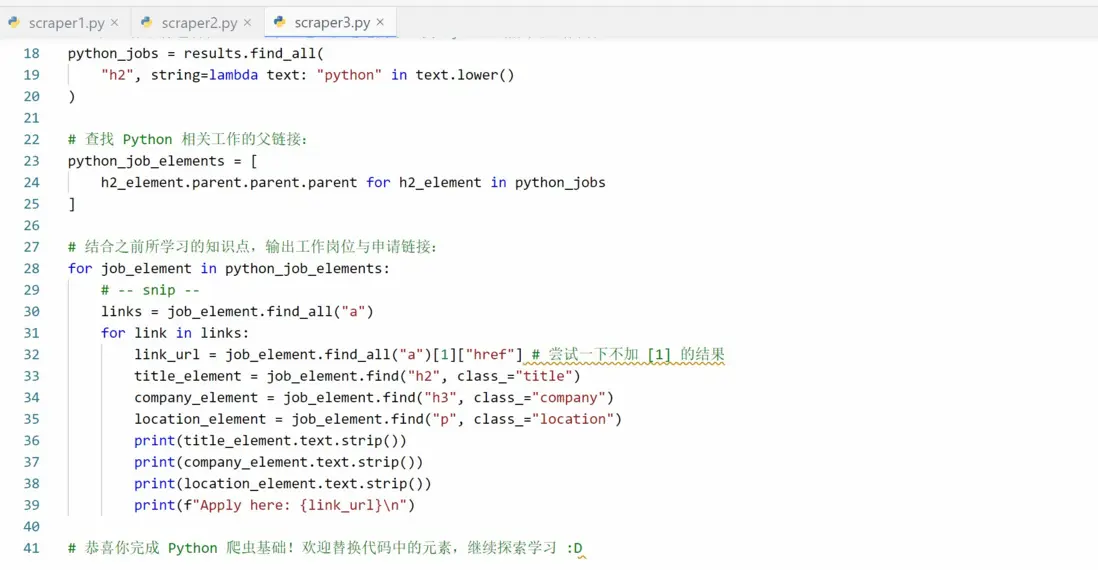
Lightly Python 爬蟲實操項目代碼中,分成多個章節通過代碼中的註釋講解 BeautifulSoup 中的各個元素。
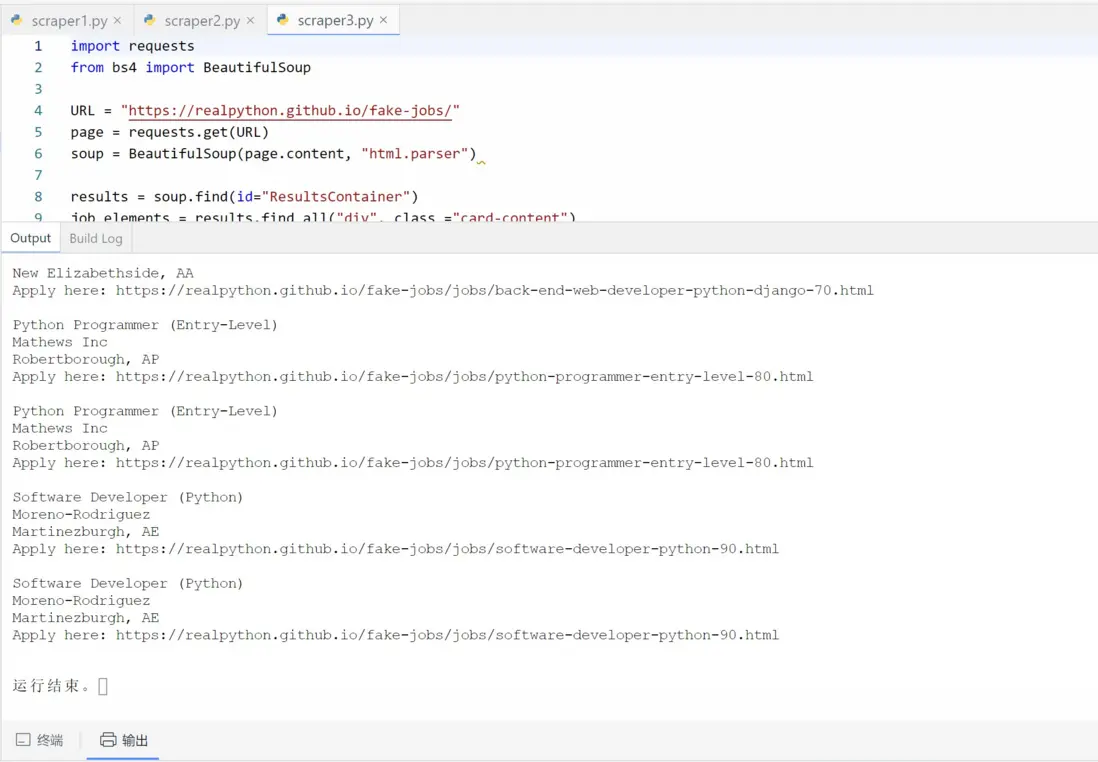
完成學習後的輸出效果如下:
爬蟲的挑戰
此次爬蟲中所使用的練習網站較為簡單,但也展示了基礎 Python 爬蟲中需要具備的知識與應用。現實使用的網頁或許會比練習中的網頁更為複雜,不同編程人員所使用的編程語言、風格、安全係數等都有可能影響爬蟲的難易度。
此外,對於信息更新較為頻繁的網站而言,大家在學習爬蟲的過程中也有可能發現每次運行的內容都可能出現變化。若網站的改動較大,過去所建立好的爬蟲代碼就有可能失效。因此,學習 Python 爬蟲是一個常練常新的過程。在法律法規允許的範圍內,進一步通過已習得的技巧多加練習與交流,才能真正地將爬蟲作為有利於自己的工具,增進工作效率與個人能力。