

一、前言
大家好!我是sum墨,一個一線的底層碼農,平時喜歡研究和思考一些技術相關的問題並整理成文,限於本人水平,如果文章和代碼有表述不當之處,還請不吝賜教。
作為一名從業已達六年的老碼農,我的工作主要是開發後端Java業務系統,包括各種管理後台和小程序等。在這些項目中,我設計過單/多租户體系系統,對接過許多開放平台,也搞過消息中心這類較為複雜的應用,但幸運的是,我至今還沒有遇到過線上系統由於代碼崩潰導致資損的情況。這其中的原因有三點:一是業務系統本身並不複雜;二是我一直遵循某大廠代碼規約,在開發過程中儘可能按規約編寫代碼;三是經過多年的開發經驗積累,我成為了一名熟練工,掌握了一些實用的技巧。
分頁查詢的需求想必大家都做過吧,很簡單,無非就是查詢SQL後面加上limit pageNum,pageSize,複雜點的話加個排序。雖説它簡單吧,但真正封裝過分頁組件的同學應該也不多吧,很多時候都是上網copy一份或者拿前輩封裝好的。這篇文章呢,我就講一下我是怎麼做分頁的,以及分頁有哪些需要注意的點。
由於文章經常被抄襲,開源的代碼甚至被當成收費項,所以源碼裏面不是全部代碼,有需要的同學可以留個郵箱,我給你單獨發!
二、分頁組件設計
1. 查詢參數
查詢的核心參數是:
- pageNum:頁碼
-
pageSize:每頁大小
有了這兩個參數,就可以進行分頁查詢了。
2. 返回結果
結果的核心屬性是:
- totalItems:查詢到的總條數
- totalPages:總頁數
- currentPage:當前頁
- itemsPerPage:每頁條數
-
value:分頁結果
有了這些返回信息,基本上一個分頁表格可以展示了。

這裏我使用一個model表示它
/**
* 分頁
*
* @param <T>
*/
public class Page<T> {
/**
* 查詢到的總條數
*/
private long totalItems;
/**
* 總頁數
*/
private long totalPages;
/**
* 當前頁,PageNum
*/
private int currentPage;
/**
* 每頁條數,PageSize
*/
private int itemsPerPage;
/**
* 分頁結果
*/
private List<T> value;
private Page() {
}
public long getTotalItems() {
return totalItems;
}
public void setTotalItems(long totalItems) {
this.totalItems = totalItems;
}
public long getTotalPages() {
return totalPages;
}
public void setTotalPages(long totalPages) {
this.totalPages = totalPages;
}
public int getCurrentPage() {
return currentPage;
}
public void setCurrentPage(int currentPage) {
this.currentPage = currentPage;
}
public int getItemsPerPage() {
return itemsPerPage;
}
public void setItemsPerPage(int itemsPerPage) {
this.itemsPerPage = itemsPerPage;
}
public List<T> getValue() {
return value;
}
public void setValue(List<T> value) {
this.value = value;
}
@Override
public String toString() {
return "Page{" + "totalItems=" + totalItems + ", totalPages=" + totalPages + ", currentPage=" + currentPage
+ ", itemsPerPage=" + itemsPerPage + ", value=" + value + '}';
}
}3. 邏輯完善
(1)空分頁
當查詢的數據為空時,返回一個空分頁
/**
* 返回一個空的分頁
*
* @param <T>
* @return
*/
public static <T> Page<T> emptyPage() {
Page<T> result = new Page<T>();
result.setValue(new ArrayList<T>());
return result;
}(2)假分頁
/**
* 根據完整的項目列表創建假分頁。
*
* @param list 完整的項目列表,用於分頁。
* @param pageNum 要檢索的頁碼。
* @param pageSize 每頁的項目數目。
* @return 返回指定頁面的Page對象,包含對應的項目列表。
*/
public static <T> Page<T> startPage(List<T> list, int pageNum, int pageSize) {
int totalItems = list.size();
int totalPages = (int)Math.ceil((double)pageNum / pageSize);
// 計算請求頁面上第一個項目的索引
int startIndex = (pageNum - 1) * pageSize;
// 確保不會超出列表範圍
startIndex = Math.max(startIndex, 0);
// 計算請求頁面上最後一個項目的索引
int endIndex = startIndex + pageSize;
// 確保不會超出列表範圍
endIndex = Math.min(endIndex, totalItems);
// 從完整列表中提取當前頁面的子列表
List<T> pageItems = list.subList(startIndex, endIndex);
// 創建並填充Page對象
Page<T> page = new Page<>();
page.setCurrentPage(pageNum);
page.setItemsPerPage(pageSize);
page.setTotalItems(totalItems);
page.setTotalPages(totalPages);
page.setValue(pageItems);
return page;
}
假分頁沒什麼好説的,就是把數據全部讀取到內存中,在內存中進行分頁,這個代碼不難,網上一搜全是。
(3)真分頁
關於真分頁,有很多種實現方式,這裏我就説一下我常用的PageHelper,使用起來很簡單,直接maven引入就行了,不需要額外配置。
maven依賴如下
<!-- 分頁插件 -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.4.1</version>
</dependency>使用方式也很簡單
//設置分頁參數
PageHelper.startPage(pageNum, pageSize);
//查詢用户列表
List<UserDO> list = userRepository.list();PageHelper 的工作原理基於 MyBatis 攔截器(Interceptor)機制,詳細的我就不展開了,這裏我主要講一下分頁之後如何設置總條數、總頁數等屬性。
回到我們的Page類中來,使用PageHelper分頁完成之後如獲取當前分頁的一些屬性呢,請看代碼
/**
* 真分頁數據轉換
*
* @param doList 原始DO列表
* @param dtoList 返回值DTO列表
* @param <T>
* @return 分頁數據
*/
public static <T> Page<T> resetPage(List doList, List<T> dtoList) {
if (null == doList) {
//如果doList為空,返回空分頁
return emptyPage();
}
Page<T> result = new Page();
//獲取PageHelper的分頁屬性
PageInfo<T> pageInfo = new PageInfo(doList);
result.setTotalPages(pageInfo.getPages());
result.setCurrentPage(pageInfo.getPageNum());
result.setItemsPerPage(pageInfo.getPageSize());
result.setTotalItems(pageInfo.getTotal());
//設置返回值列表
result.setValue(dtoList);
return result;
}
核心代碼是 PageInfo<T> pageInfo = new PageInfo(doList);,這樣可以獲取到PageHelper的PageInfo類,PageInfo類中就有我們需要的屬性了。
(4)小結一下
我先把完整的Page類代碼貼一下
package com.summo.demo.page;
import java.util.ArrayList;
import java.util.List;
import com.github.pagehelper.PageInfo;
/**
* 分頁
*
* @param <T>
*/
public class Page<T> {
/**
* 查詢到的總條數
*/
private long totalItems;
/**
* 總頁數
*/
private long totalPages;
/**
* 當前頁,PageNum
*/
private int currentPage;
/**
* 每頁條數,PageSize
*/
private int itemsPerPage;
/**
* 分頁結果
*/
private List<T> value;
private Page() {
}
/**
* 返回一個空的分頁
*
* @param <T>
* @return
*/
public static <T> Page<T> emptyPage() {
Page<T> result = new Page<T>();
result.setValue(new ArrayList<T>());
return result;
}
/**
* 根據完整的項目列表創建假分頁。
*
* @param list 完整的項目列表,用於分頁。
* @param pageNum 要檢索的頁碼。
* @param pageSize 每頁的項目數目。
* @return 返回指定頁面的Page對象,包含對應的項目列表。
*/
public static <T> Page<T> startPage(List<T> list, int pageNum, int pageSize) {
int totalItems = list.size();
int totalPages = (int)Math.ceil((double)pageNum / pageSize);
// 計算請求頁面上第一個項目的索引
int startIndex = (pageNum - 1) * pageSize;
// 確保不會超出列表範圍
startIndex = Math.max(startIndex, 0);
// 計算請求頁面上最後一個項目的索引
int endIndex = startIndex + pageSize;
// 確保不會超出列表範圍
endIndex = Math.min(endIndex, totalItems);
// 從完整列表中提取當前頁面的子列表
List<T> pageItems = list.subList(startIndex, endIndex);
// 創建並填充Page對象
Page<T> page = new Page<>();
page.setCurrentPage(pageNum);
page.setItemsPerPage(pageSize);
page.setTotalItems(totalItems);
page.setTotalPages(totalPages);
page.setValue(pageItems);
return page;
}
/**
* 真分頁數據轉換
*
* @param doList 原始DO列表
* @param dtoList 返回值DTO列表
* @param <T>
* @return 分頁數據
*/
public static <T> Page<T> resetPage(List doList, List<T> dtoList) {
if (null == doList) {
//如果doList為空,返回空分頁
return emptyPage();
}
Page<T> result = new Page();
//獲取PageHelper的分頁屬性
PageInfo<T> pageInfo = new PageInfo(doList);
result.setTotalPages(pageInfo.getPages());
result.setCurrentPage(pageInfo.getPageNum());
result.setItemsPerPage(pageInfo.getPageSize());
result.setTotalItems(pageInfo.getTotal());
//設置返回值列表
result.setValue(dtoList);
return result;
}
public long getTotalItems() {
return totalItems;
}
public void setTotalItems(long totalItems) {
this.totalItems = totalItems;
}
public long getTotalPages() {
return totalPages;
}
public void setTotalPages(long totalPages) {
this.totalPages = totalPages;
}
public int getCurrentPage() {
return currentPage;
}
public void setCurrentPage(int currentPage) {
this.currentPage = currentPage;
}
public int getItemsPerPage() {
return itemsPerPage;
}
public void setItemsPerPage(int itemsPerPage) {
this.itemsPerPage = itemsPerPage;
}
public List<T> getValue() {
return value;
}
public void setValue(List<T> value) {
this.value = value;
}
@Override
public String toString() {
return "Page{" + "totalItems=" + totalItems + ", totalPages=" + totalPages + ", currentPage=" + currentPage
+ ", itemsPerPage=" + itemsPerPage + ", value=" + value + '}';
}
}看到這是不是覺得挺簡單的,別急,複雜點的在下面。
三、深分頁查詢性能優化
"深分頁查詢"通常是指在數據庫查詢中需要獲取結果集很深的頁碼的數據,例如獲取第1000頁或更深的數據。在傳統的分頁查詢中,我們通常使用類似於以下的SQL語句:
SELECT * FROM table LIMIT 1000, 20;這裏,LIMIT 1000, 20 表示跳過前1000條記錄,然後獲取接下來的20條記錄。這種查詢方式在前幾頁的數據獲取時表現良好,但是隨着頁碼的增大,性能會顯著下降。因為數據庫需要掃描並跳過大量的行才能到達指定的位置,這個過程十分耗時,尤其很多時候還需要加上排序。
優化的方法有很多,這裏我推薦使用如下方式優化
- 對排序字段建索引,如create_time、id等;
- 只查詢id字段;
- 根據id反查數據內容;
- 遇到join查詢時,也可以使用該方法進行優化,不過麻煩些;
四、分頁合理化
但大家可能對分頁合理化這個詞有點兒陌生,不過應該都遇到過因為它產生的問題。這些問題不會觸發明顯的錯誤,所以大家一般都忽視了這個問題。
它的定義:分頁合理化通常是指後端在處理分頁請求時會自動校正不合理的分頁參數,以確保用户始終收到有效的數據響應。
那麼啥是分頁合理化,我來舉幾個例子:
1. 舉些例子
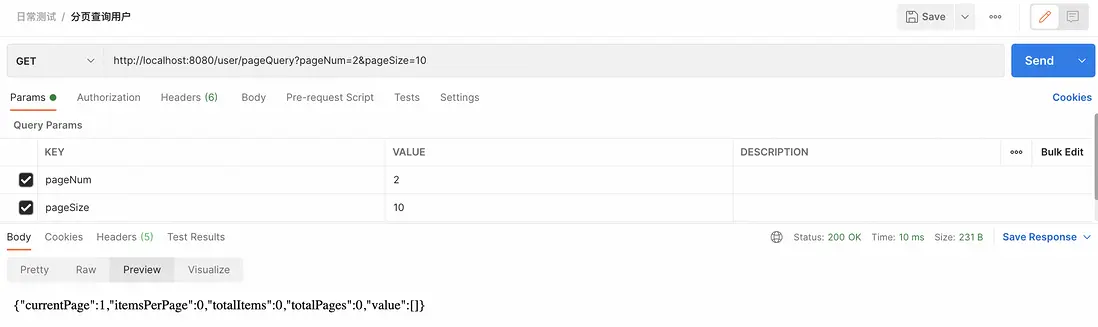
(1)請求頁碼超出範圍
假設數據庫中有100條記錄,每頁展示10條,那麼就應該只有10頁數據。如果用户請求第11頁,不合理化處理可能會返回一個空的數據集,告訴用户沒有更多數據。開啓分頁合理化後,系統可能會返回第10頁的數據(即最後一頁的數據),而不是一個空集。
(2)請求頁碼小於1
用户請求的頁碼如果是0或負數,這在分頁上下文中是沒有意義的。開啓分頁合理化後,系統會將這種請求的頁碼調整為1,返回第一頁的數據。
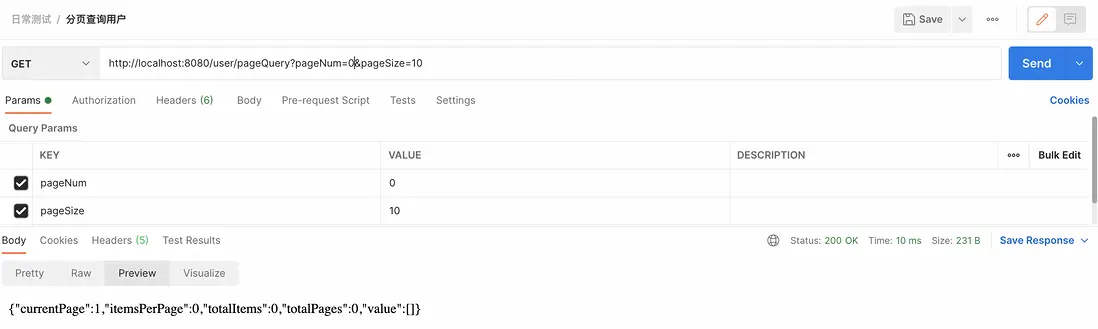
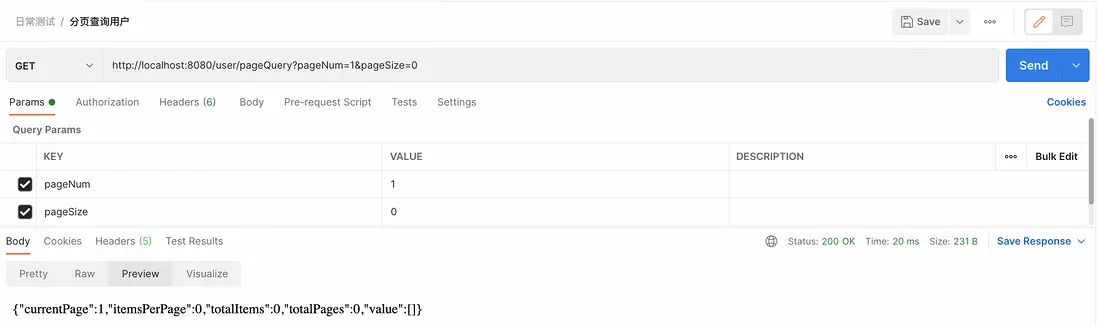
(3)請求的數據大小小於1
如果用户請求的數據大小為0或負數,這也是無效的,因為它意味着用户不希望獲取任何數據。開啓分頁合理化後,系統可能會設置一個默認的頁面大小,比如每頁顯示10條數據。
(4)請求的數據大小不合理
如果用户請求的數據大小非常大,比如一次請求1000條數據,這可能會給服務器帶來不必要的壓力。開啓分頁合理化後,系統可能會限制頁面大小的上限,比如最多隻允許每頁顯示100條數據。
(5)會導致一個BUG
BUG復現
我們先看看前端的分頁組件
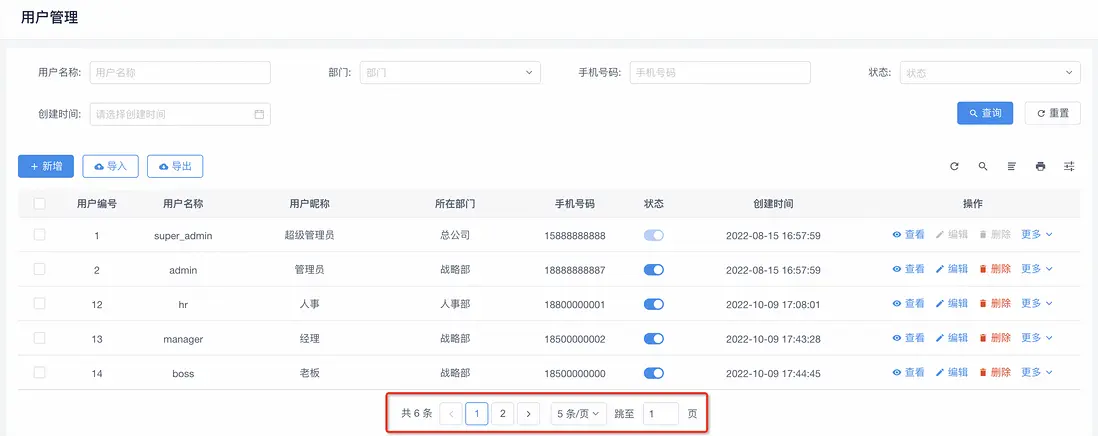
前端的這個分頁組件大家應該很常見,它需要兩個參數:總行數、每頁行數。比如説現在總條數是6條,每頁展示5條,那麼會有2頁,沒啥問題對吧。
那麼,現在我問一個問題:我們切換到第二頁,把第二頁僅剩的一條數據給刪除掉,會出現什麼情況?

理想情況:頁碼自動切換到第1頁,並查詢第一頁的數據;
真實情況:頁碼切換到了第1頁,但是查詢不到數據,這明顯就是一個BUG!

BUG分析
1. 用户切換到第二頁,前端發起了請求,如:http://localhost:8080/user/pageQuery?pageNum=2&pageSize=5 ,此時第2頁有一條數據;
2. 用户刪除第2頁的唯一數據後,前端發起查詢請求,但還是第2頁的查詢,因為總數據的變化前端只能通過下一次的查詢才能知道,但此時數據查詢為空;
3. 雖然第二次查詢的數據集為空,但是總條數已經變化了,只剩下5條,前端分頁組件根據計算得出只剩下一頁,所以自動切換到第1頁;
可以看出這個BUG是分頁查詢的一個臨界狀態產生的,必現、中低頻,屬於必須修復的那一類。不過這個BUG想甩給前端,估計不行,因為總條數的變化只有後端知道,必須得後端修了。
2. 設置分頁合理化
咋一聽這個BUG有點兒複雜,但如果你使用的是PageHelper框架,那麼修復它非常簡單,只需要兩行配置。
在application.yml或application.properties中添加
pagehelper.helper-dialect=mysql
pagehelper.reasonable=true
````
只要加了這兩行配置,這個BUG就能解決。因為配置是全局的,如果你只想對單個查詢場景生效,那就在設置分頁參數的時候,加一個參數,如下:PageHelper.startPage(pageNumber, pageSize, true);
> 這個問題我在三個月前單獨寫過一篇文章分析,想看原理的同學請移步:[分頁合理化是什麼?](https://www.cnblogs.com/wlovet/p/17926629.html)
# 五、列表多行合併
## 1. 舉個例子
現有如下表結構,用户表、角色表、用户角色關聯表。
一個用户有多個角色,一個角色有可以給多個用户,也即常見的``多對多場景``。

現有這樣一個需求,**分頁**查詢用户數據,除了用户ID和用户名稱字段,還要查出這個用户的**所有角色**。

從上面的表格我們可以看出,用户有三個,但每個人的角色不止一個,而且有重複的角色,``這裏角色的數據從多行合併到了1行``。
## 2. 難點分析
SQL存在的問題:
>想使用SQL實現上面的效果不是不可以,但是很複雜且效率低下,尤其這個地方還需要分頁,所以為了保證查詢效率,我們需要把邏輯放到服務端來寫;
服務端存在的問題:
>服務端可以把需要的數據都查詢出來,然後自己判斷整合,首先十分複雜不説,而且這裏有個問題:如何在查詢條件很複雜的情況下保證分頁?
## 3. 解決方案
``核心方案就是使用Mybatis的collection標籤自動實現多行合併。``
下面是collection標籤的一些介紹

常見寫法<resultMap id="ExtraBaseResultMap" type="com.example.mybatistest.entity.UserInfoDO">
<!--
WARNING - @mbg.generated
-->
<result column="user_id" jdbcType="INTEGER" property="userId"/>
<result column="user_name" jdbcType="INTEGER" property="userName"/>
<collection javaType="java.util.ArrayList" ofType="com.example.mybatistest.entity.MyRole"
property="roleList">
<result column="role_id" jdbcType="INTEGER" property="roleId"/>
<result column="role_name" jdbcType="VARCHAR" property="roleName"/>
</collection>
</resultMap>> 這個問題我1年前單獨寫過一篇文章,具體實現請移步:[MyBatis實現多行合併(collection標籤使用)](https://www.cnblogs.com/wlovet/p/16406502.html)
# 六、總結一下
從第一篇的[《優化接口設計的思路》系列:第一篇—接口參數的一些彎彎繞繞](https://www.cnblogs.com/wlovet/p/17700353.html)到今天的[《優化接口設計的思路》系列:第八篇—分頁接口的設計和優化](https://www.cnblogs.com/wlovet/p/18027307.html),這個專欄寫了快半年,產量很低,但我自認為質量還行,但是寫這篇文章的時候我陷入了糾結:只是介紹怎麼分頁太水了,但是多行合併和分頁合理化我之前就單獨寫過文章了,現在又拿出來講豈不是炒冷飯?但是我又轉念一想,都是我寫的文章,又不是抄襲的,咋不能重新寫(水)一篇🤡。那麼既然寫(水)了,那我就多寫(水)一點。
我寫文章都是原創,不轉載,因為我不想(也不需要)去湊網站的活躍度,想到啥寫啥,文章首發基本上都在博客園(園子你還撐得住嗎?),然後是掘金(活躍用户高),當然csdn也發(流量多,也不知道是不是機器人)。但你問我寫技術軟文能不能賺到錢?我不知道,反正我沒有賺到過,興趣使然而已。那寫文章一點用也沒有嗎?也不盡然,有博客的話放在簡歷上可以加分,具體加多少分,看面試官心情。我寫文章的原因在[《優化接口設計的思路》系列:第四篇—接口的權限控制](https://www.cnblogs.com/wlovet/p/17717905.html)的總結部分提到過,但其實還有一個原因:之前實習的時候,部門裏有一個大叔在朋友圈曬過一條博客園把他文章上推薦的朋友圈。我當時看到覺得很牛逼,我就想啥時候我也能上。所以我寫文章,除了積累知識外,還想上推薦,感覺很裝逼。後來真的有文章上了推薦,我卻沒有發朋友圈。
到現在買房、買車、結婚、生小孩等等所謂人生大事,我一件都還沒有辦,原因很簡單,沒錢。按理説“三十而立”,我卻越來越迷茫,我不知道哪些事情要先做,哪些事情是重要的,但在寫文章的時候卻感覺時間過得非常快,我應該是喜歡做這件事,做這件事的時候可以讓我暫時忘記前面的那些煩惱,我想我也是幸運的。我看到很多文章説,程序員應該多寫文章啊、錄視頻課啊...總之想辦法用知識變現等等,我卻想説,先讓自己喜歡上做這件事吧,如果不喜歡的話,怎麼熬得住文章瀏覽不過百,怎麼扛得住別人惡意的評論,一旦賺不到錢就會懷疑自己做這件事的意義。

