

需求背景
在智慧園區治理中,管理人員常常面臨多重數據挑戰。各個業務系統的數據壁壘導致企業信息、合同數據、納税記錄等分散存儲,形成數據孤島。更為棘手的是,數據處理過程嚴重依賴IT人員和技術團隊,業務人員即使有分析思路,也難以快速實現。從數據接入到最終可視化展示,往往需要經歷漫長開發週期,無法支持實時決策。當需要計算一些專業指標時,業務人員不得不等待技術團隊開發相應計算邏輯,響應速度慢,成本高昂。
解決方案
smardaten平台中提供了數據交換機功能,針對上述痛點提供了完整的解決方案。數據交換機是平台中的核心數據處理模塊,它通過可視化的方式,讓用户能夠通過簡單拖拽配置複雜的數據處理流程。與傳統編碼方式相比,數據交換機具有以下突出優勢:
• 可視化操作:提供豐富的算子節點(輸入、輸出、基本轉換等),通過拖拽即可完成數據處理流程設計,降低技術門檻;
• 多源數據支持:能夠同時接入數據庫、外部接口、Excel等多種數據源,實現數據統一融合處理;
• 便捷的數據處理能力:內置數據清洗、轉換、關聯、計算等全方位功能,支持複雜業務邏輯實現。
處理場景:入駐企業納税與風險分析
某智慧園區需要對企業進行精準評估,識別高潛力企業和高風險企業。核心分析目標包括:
• 計算每家入駐企業2022-2024年的納税複合增長率,並生成排名;
• 結合納税增長率並計算租金收繳率,進行風險分級預警,形成預警清單;
• 將數據處理結果通過列表、圖表等可視化形式進行直觀展示,支持管理決策。
配置過程
1. 納税複合增長率計算
在第一個交換機中,我們需要計算每家企業2022到2024年的納税複合增長率。整個流程將涵蓋數據接入、清洗與轉換、關聯、計算、輸出和可視化展示六個核心環節。
1.1 數據接入
首先,完成多源數據的接入工作。通過“輸入數據源”節點和“Excel抽取”節點,輕鬆導入企業信息表(來自MySQL數據庫)、合同信息表(來自外部接口)和税務年度記錄表(來自Excel)。
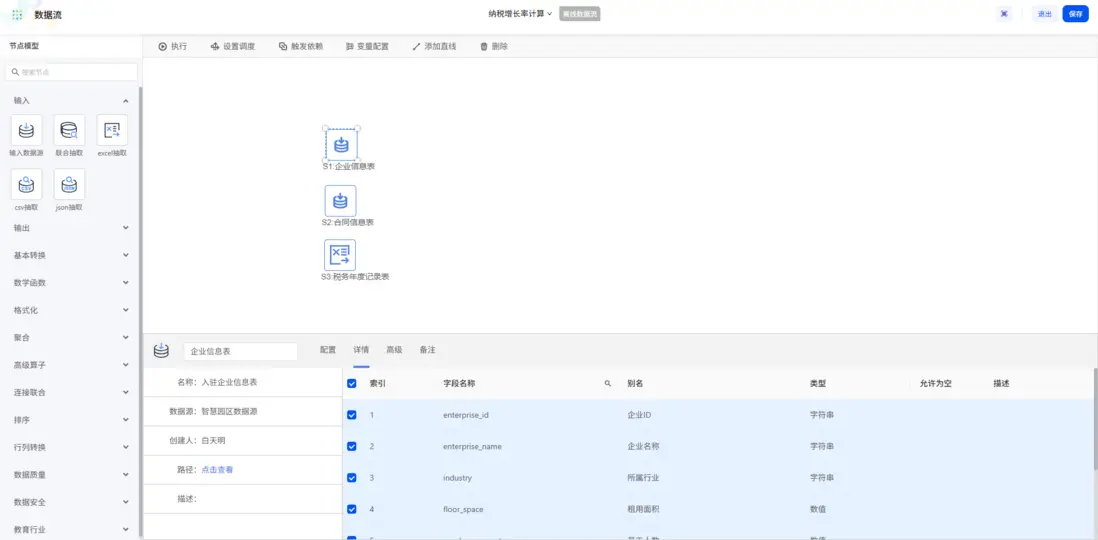
1.2 數據清洗與轉換
原始數據往往雜亂,必須清洗和轉換後才能用於分析,這是確保分析結果準確性的關鍵步驟,能剔除無效數據、規範數據格式。
在“合同信息表”中,“租用地址”字段將園區地址、樓棟號、樓層號通過橫線連接存儲,需要通過該字段獲取到園區名稱。
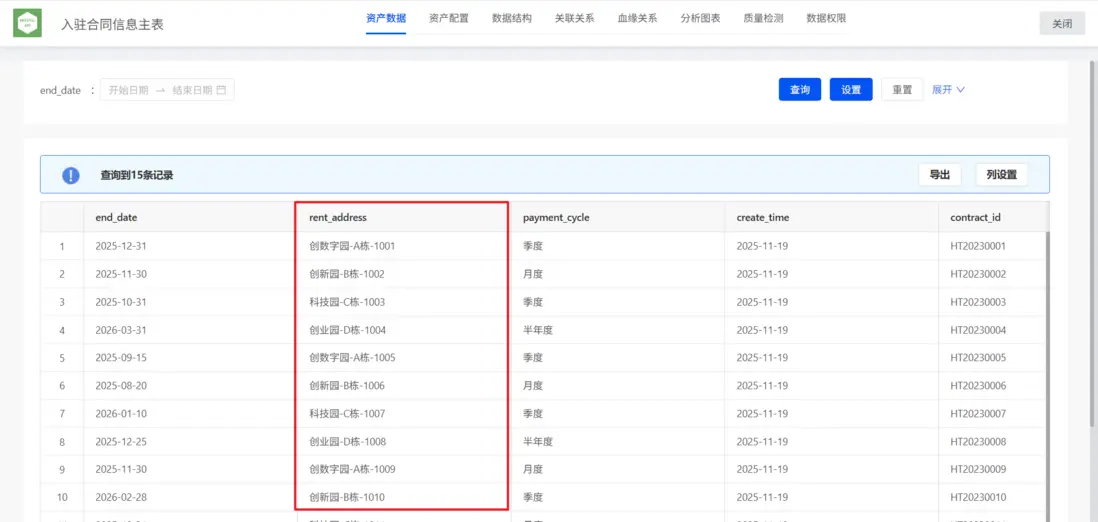
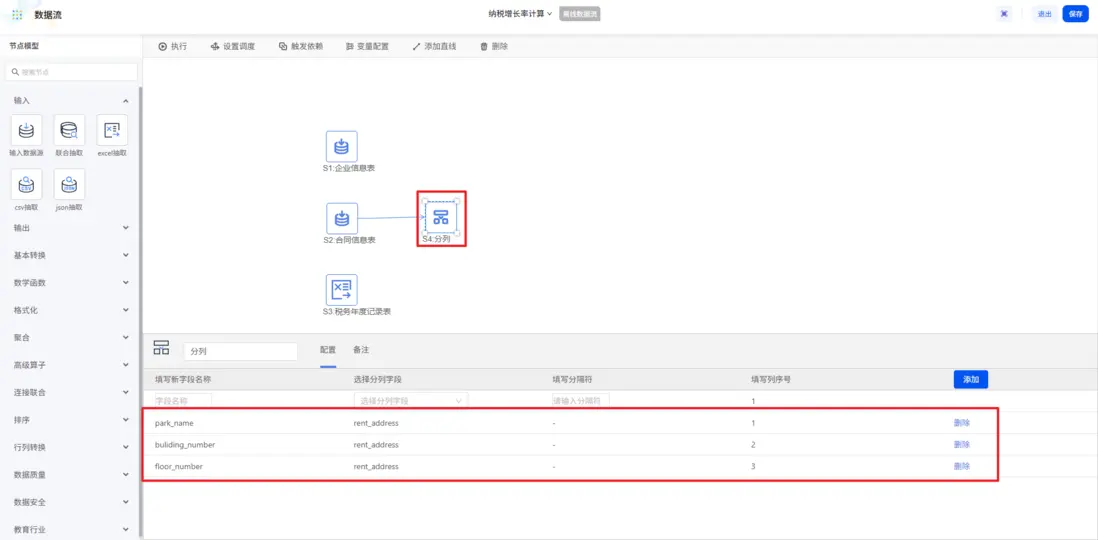
通過「分列」節點,解析合同信息表中的“租用地址”字段,分別定義“園區地址”、“樓棟號”、“樓層號”三個目標字段,以橫線為分隔符進行切分,形成三列數據。右側,處理結果將會自動按列序號遞增分配切分結果。
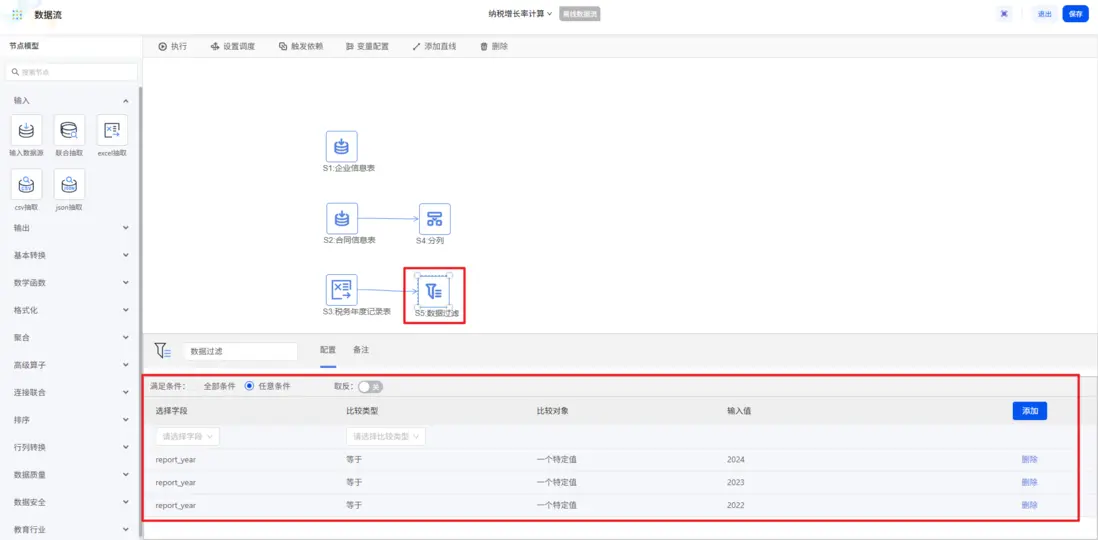
針對“税務年度記錄表”,需要過濾出最近三年的數據以計算有意義的複合增長率。使用「過濾」節點,設置年份條件為2022、2023和2024年,精準篩選出所需數據。
發現税收或營收字段有空值?使用「空值填充」節點,將這些空數據統一填充為 0,保障數據完整性。

原始税務記錄是一年一行,為方便後續納税複合增長率的計算,使用「行轉列」節點,將每個企業三年的納税金額轉為一行三列,結構清晰,方便後續計算。

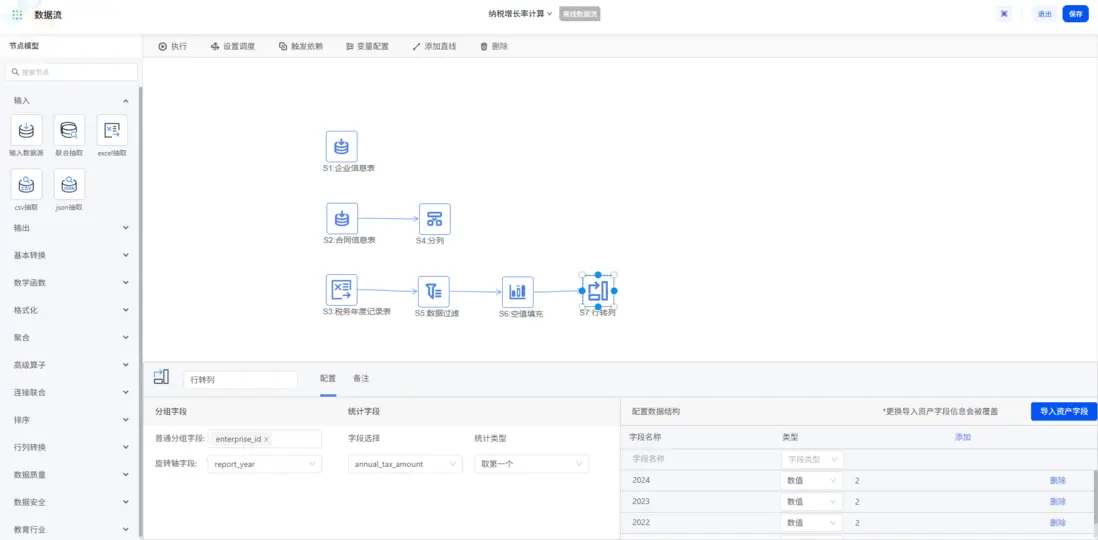
1.3 數據關聯
數據清洗與轉換完成後,需要將分散在三張表中的數據關聯起來,獲取所需的字段,形成完整的數據表。使用「維表關聯」的節點,將三張表根據企業ID關聯起來,輸出所需的字段。
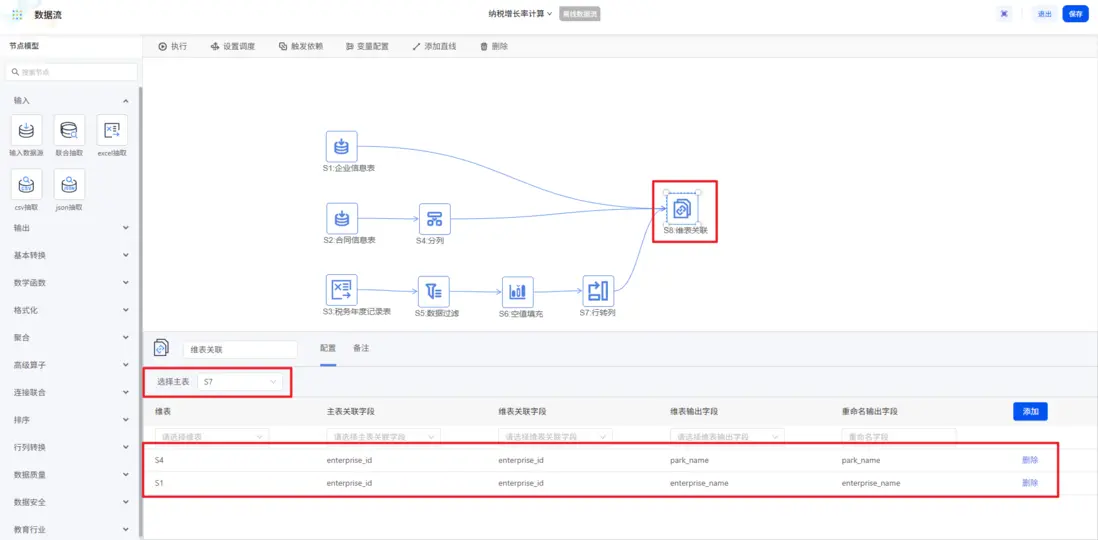
1.4 數據計算
數據整合到位後,進入核心的指標計算環節。通過「函數」節點實現複雜運算,平台內置多種 sparkSQL 函數,無需專業編程能力,只需輸入計算表達式,即可快速完成納税複合增長率計算,非常簡單!
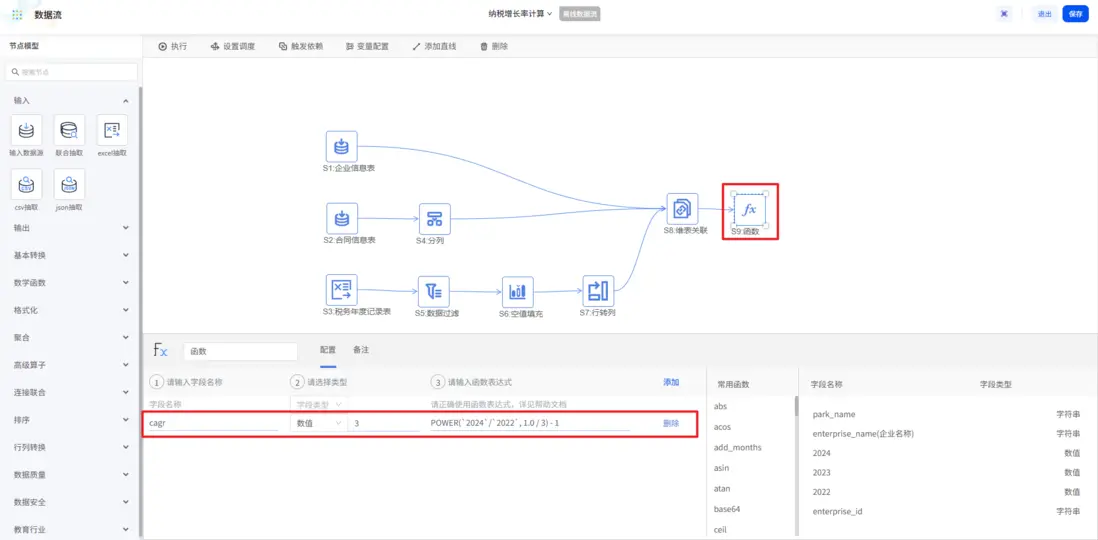
計算完成後,還需兩步優化結果呈現。首先,增長率計算完成後,是小數的展示形式。如果我們更希望展示為百分比的形式,只需使用「度量轉換」節點,新增百分比字段,轉換比例為1比100。
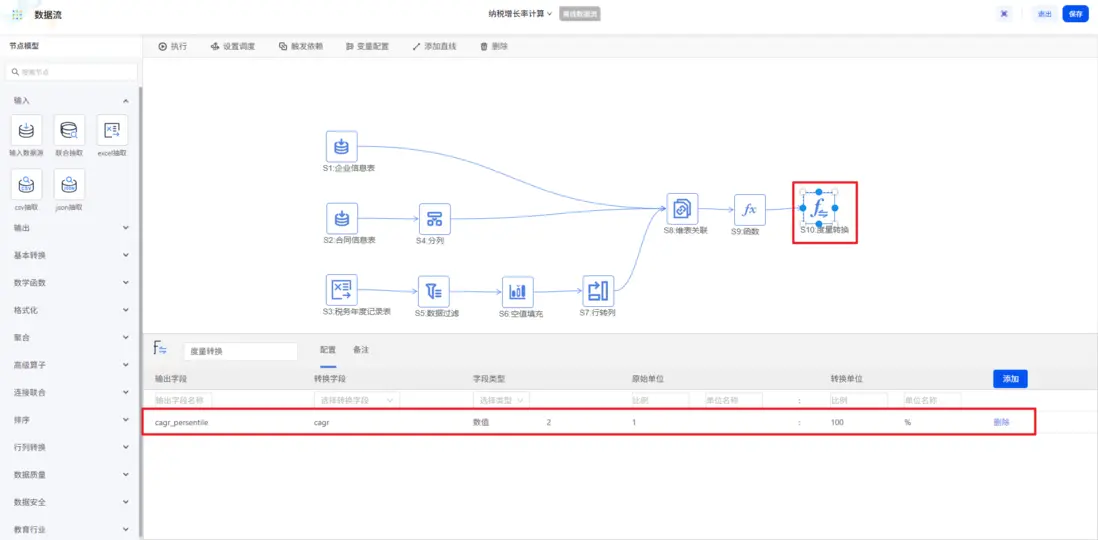
其次,還可以使用「排名」節點,按納税複合增長率百分比進行降序排名,讓高增長企業一目瞭然。
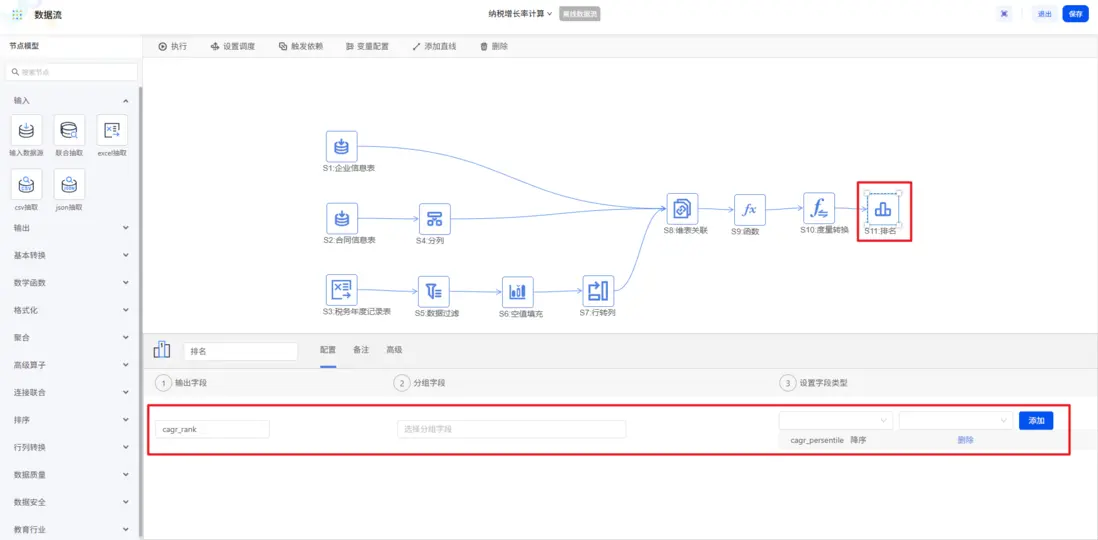
1.5 數據輸出
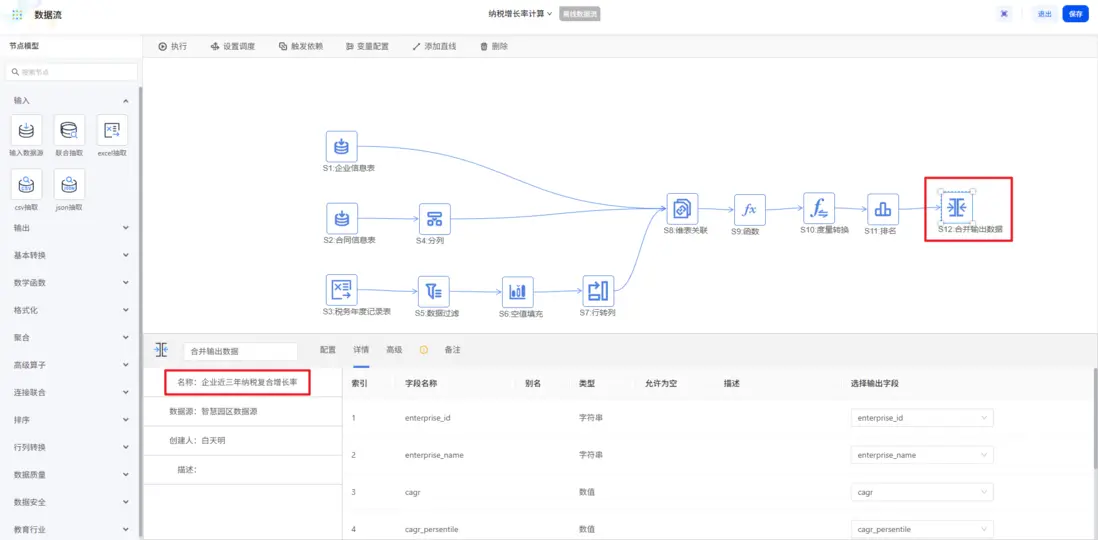
最後通過「合併輸出數據」節點將結果輸出到資產表。
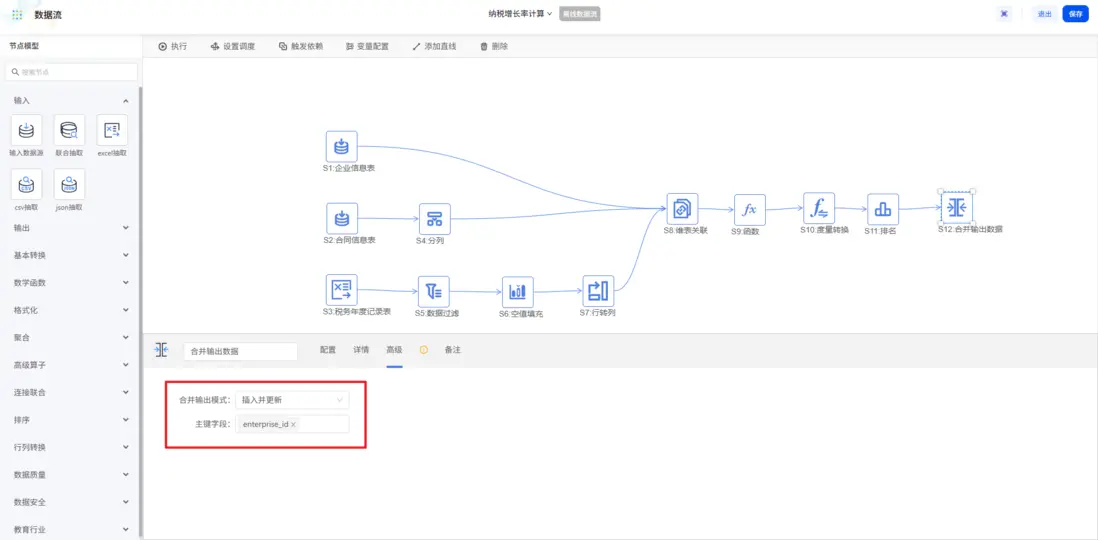
選擇 “插入並更新” 模式,以企業 ID 為主鍵,無相同數據則插入,有相同數據則自動更新,避免數據冗餘。
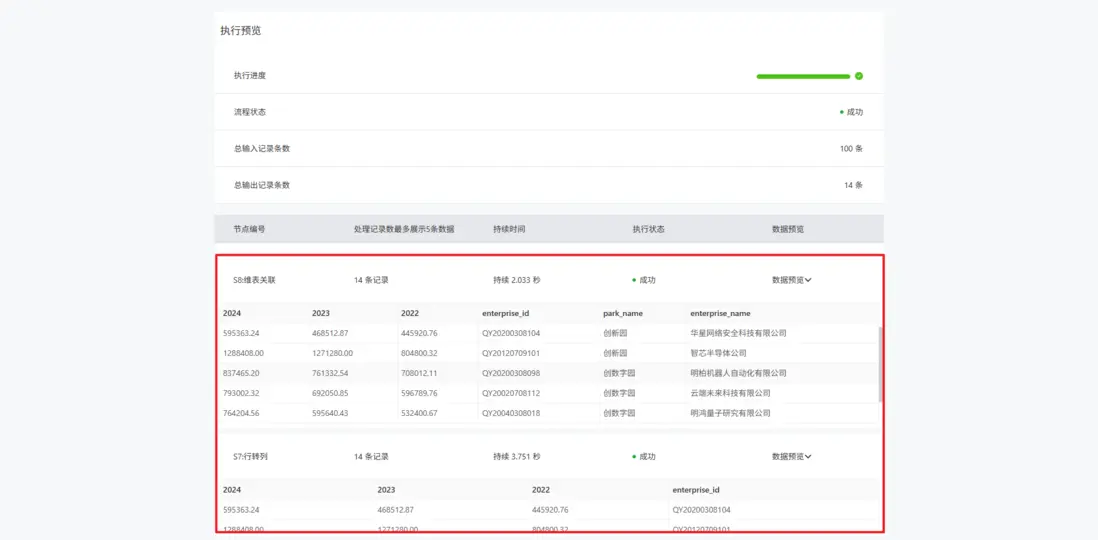
現在我們已經完成了所有節點的配置,執行交換機後,很快就能得到包含企業 ID、園區名稱、企業名稱、納税複合增長率以及排名的完整資產表。

同時下方,支持查看每個處理節點的中間輸出數據,便於校驗與調試。
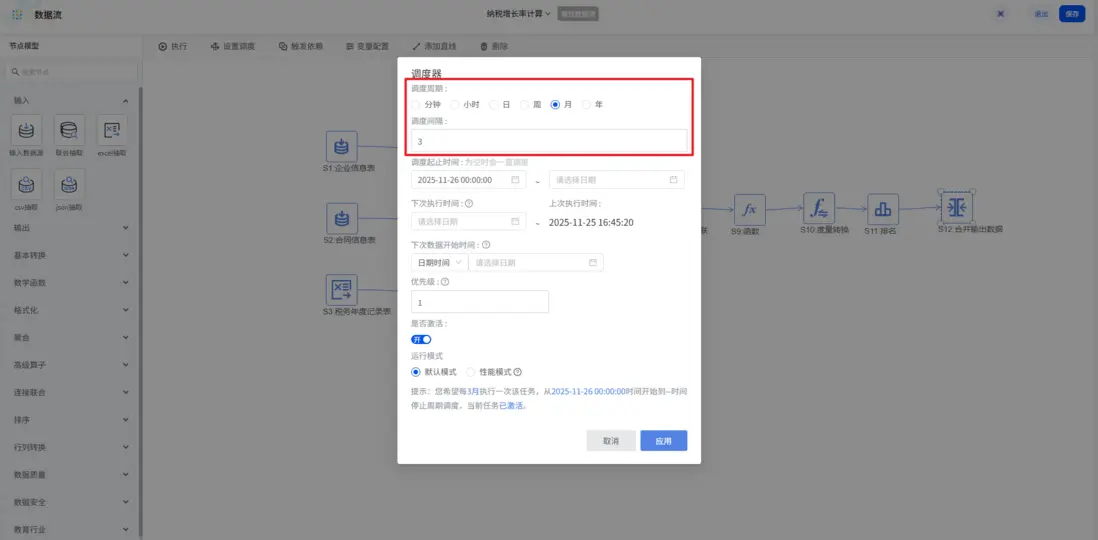
更便捷的是,還支持設定「定時調度」,比如每個季度執行一次,設定起止時間,實現數據自動處理,無需人工重複操作。
1.6 可視化展示
完成數據輸出後,來到智慧園區應用中,進行可視化展示。在工作台頁面的畫布列表中,綁定剛剛生成的資產表。預覽後,可以看到排行榜中直觀展示了不同園區每家企業的納税增長排名和對應的增長率。
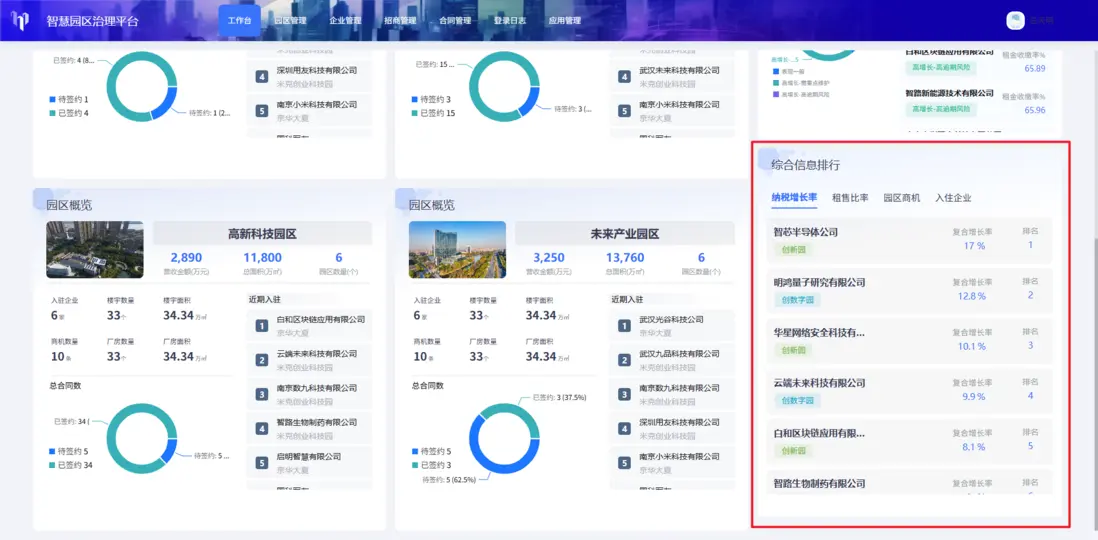
我們通過可視化流程,完成了多源數據接入、清洗、關聯,計算等一系列流程,將複雜的數據處理與分析工作從以“天”為單位的傳統開發模式,轉變為業務人員可自主配置、響應速度達分鐘級的新模式,實現對企業發展潛力的實時、量化洞察。
2. 企業風險等級分析
有了核心的納税增長數據,我們進一步延伸分析維度,將 “納税增長能力” 與 “租金履約能力” 結合,精準識別潛在風險企業,讓管理從 “被動應對” 轉向 “主動預警”。
2.1 數據接入
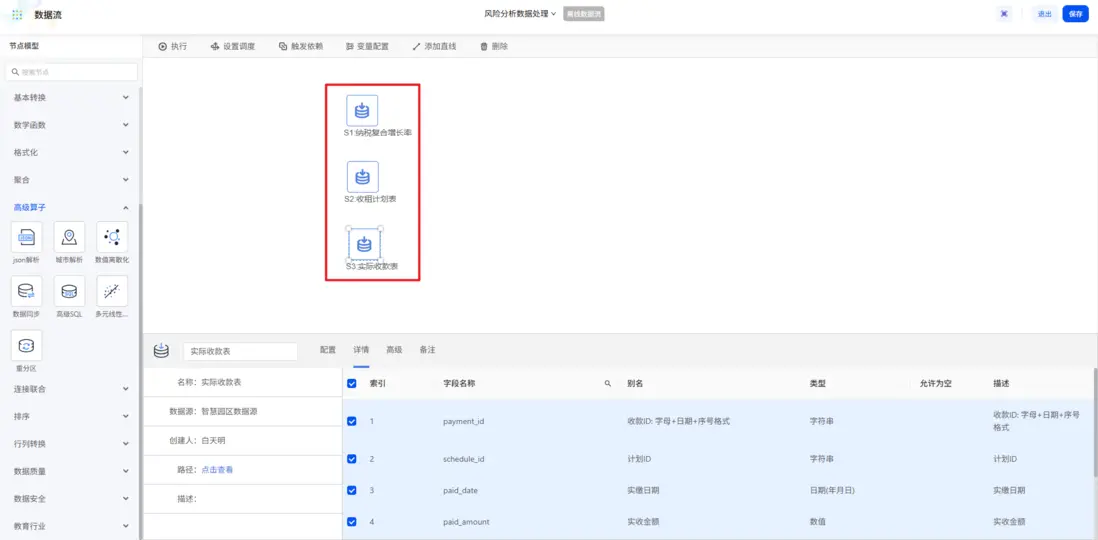
創建一個新的交換機,拖入「輸入數據源」節點,導入下方的數據表:
• 納税複合增長率資產:上一個交換機輸出的資產,包含企業ID、名稱、增長率等數據;
• 收租計劃表:包含應繳日期和應收金額等數據;
• 實際收款表:包含實繳日期和實收金額等數據。
2.2 複雜分析
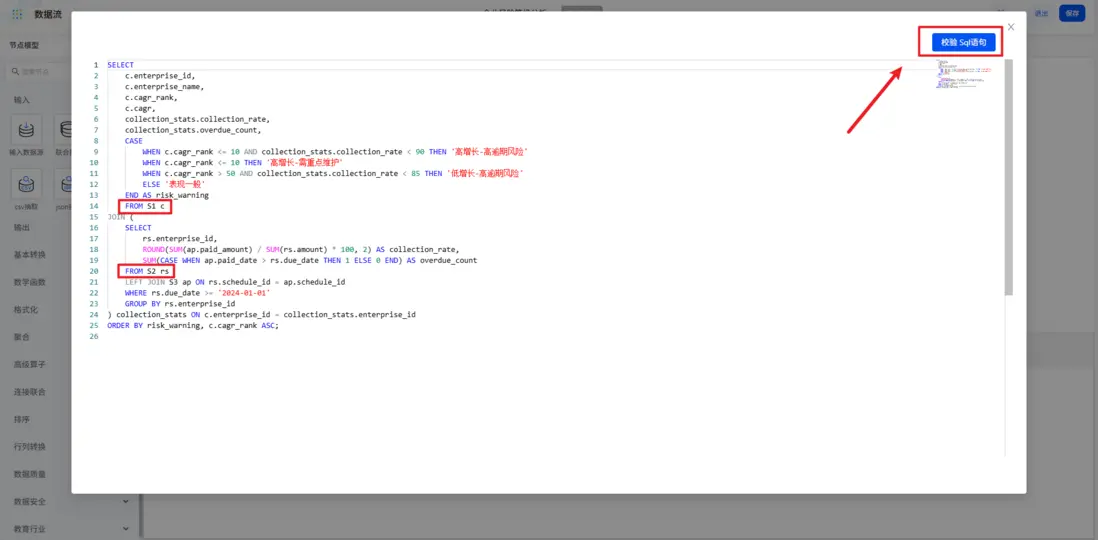
現在我們要進行一個複雜分析,除了之前我們綜合使用各個節點進行處理,可靈活使用「高級SQL」節點,直接編寫SQL語句進行處理,兼顧靈活性和效率。在這段查詢SQL中,將針對納税增長率的排名和收繳率兩個指標對企業進行打標。例如,如果增長率排名小於等於10,同時收繳率又小於90%,標記為“高增長-高逾期風險”的企業,招商或客户部門應主動介入,瞭解其是否存在經營困難,防範壞賬風險。最後我們會得到一份預警清單。
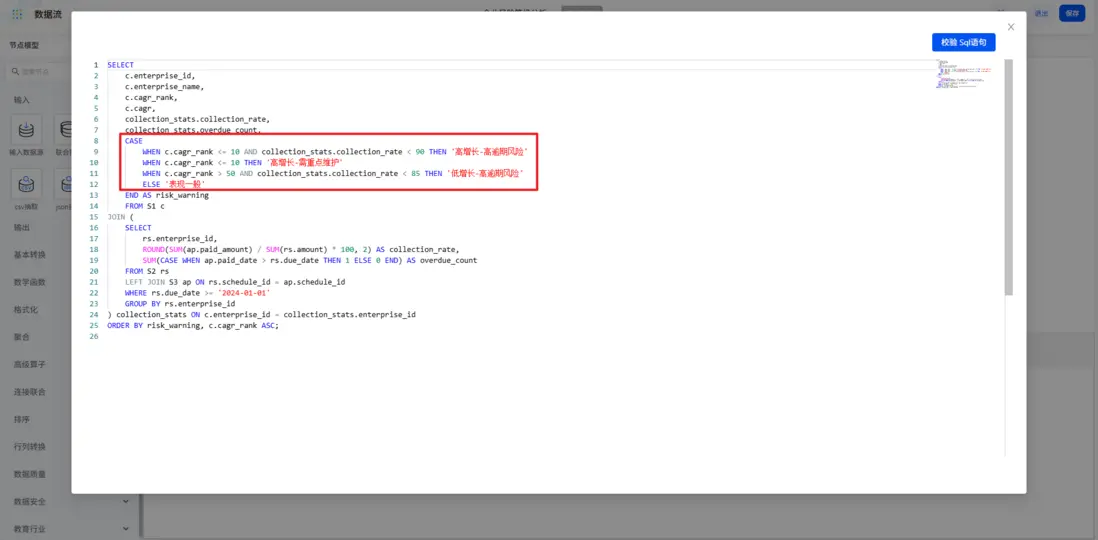
同時 SQL 語句中的表名稱需替換為對應的S1、S2節點,完成後點擊校驗SQL,確認SQL語句可用。
2.3 數據輸出
最後,拖入「輸出數據源」節點,輸出處理後的數據。
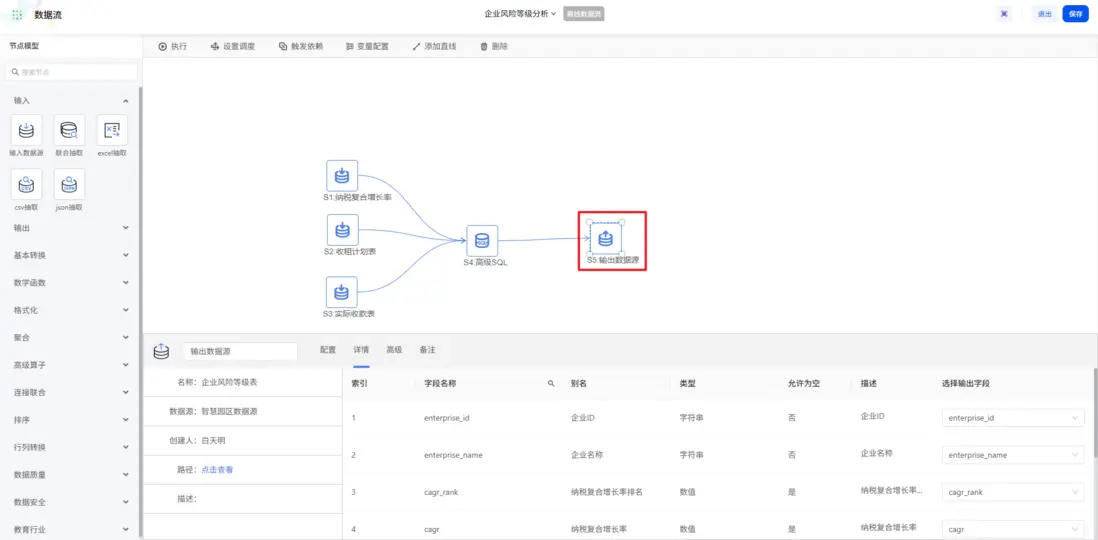
現在我們來執行交換機,查看最終節點的輸出。
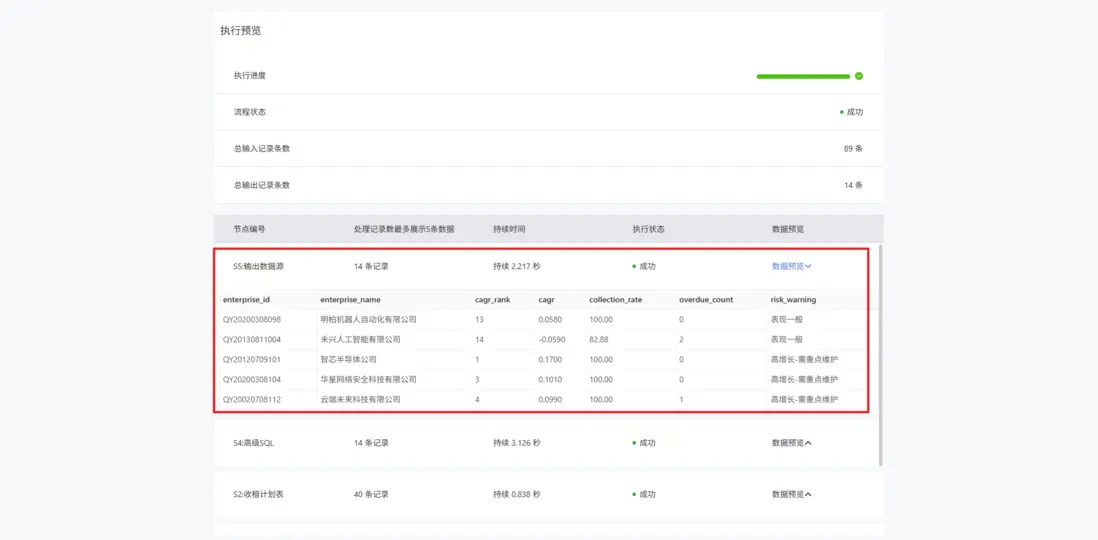
現在已經完成了企業風險等級的分析。我們發現該交換機數據的執行是依賴於前一個交換機輸出的納税增長率資產表,所以在應用配置頁,選中一個交換機開啓觸發依賴,即一旦納税增長率的交換機執行完成後,會立即自動觸發第二個交換機的執行任務,將兩個分析階段無縫銜接,形成一個連貫的自動化管道。
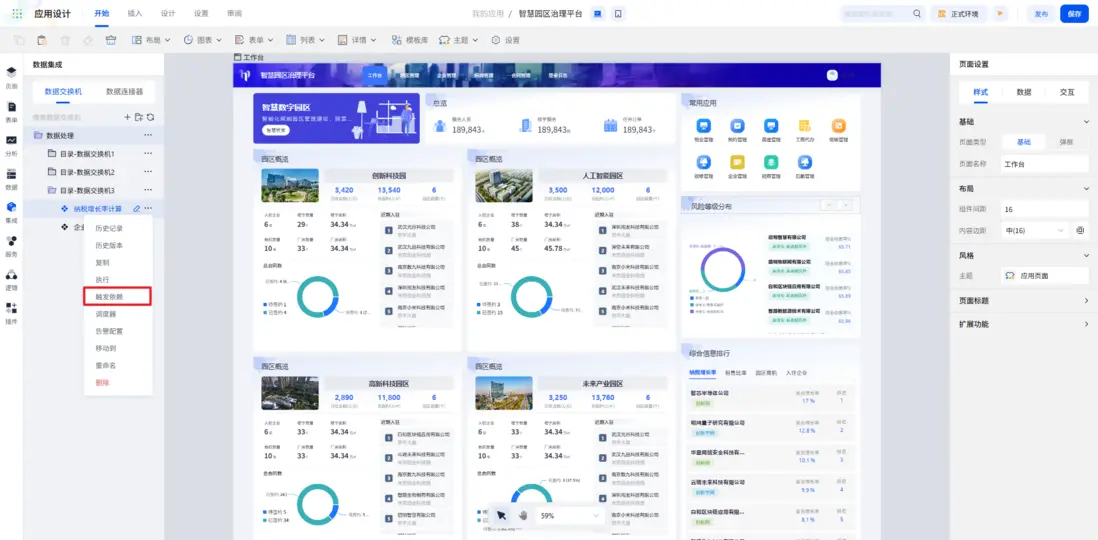
2.4 可視化展示
最後,在工作台頁面的配置頁,將圖表和列表綁定資產。左側環形圖,直觀展示了各風險等級的企業數量分佈,幫助管理者快速把握整體風險輪廓,右側畫布列表則可以直接查看收繳率低於95%的具體企業名單。
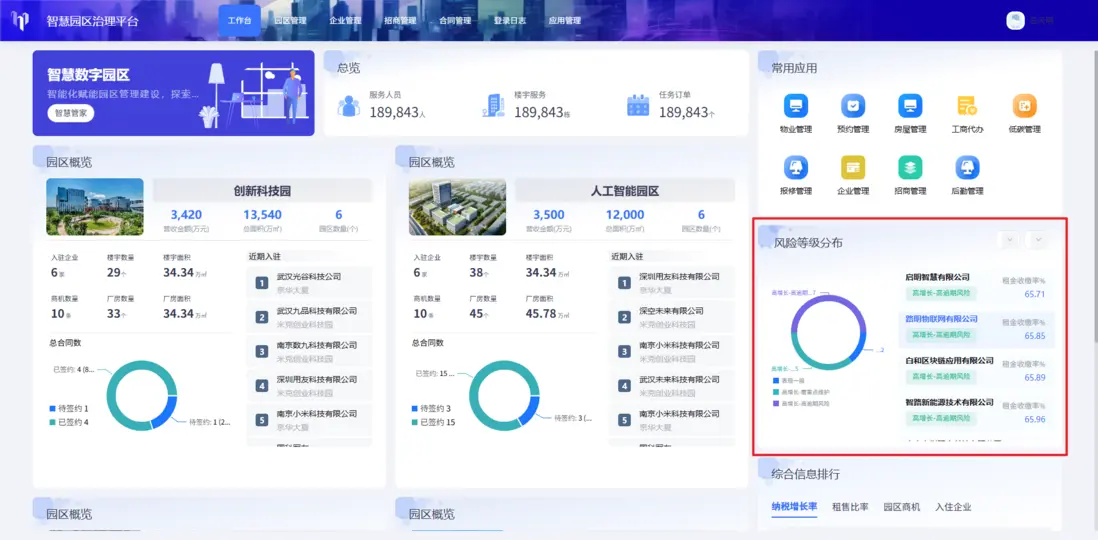
我們通過多種節點與SQL語句結合,成功實現了這一複雜的數據處理與分析,得到了各個企業的收繳率和風險指標,有利於後續對不同風險等級企業的差異化、精準化監管與服務。
體驗總結
通過智慧園區治理平台的數據處理與分析,smardaten數據交換機展現出以下幾方面突出價值:
• 支持敏捷迭代:當業務規則變化時,只需調整相應節點配置即可快速響應,無需重新開發整個流程;• 實現自動化運營:通過配置觸發依賴和定時調度,整個數據處理流程可實現全自動化運行,極大減少人工干預需求。前一個交換機執行完成後可自動觸發後續流程,形成連貫的自動化管道;
• 數用一體:數據處理結果可直接應用於業務場景,簡單直觀,避免了傳統模式下數據平台與應用場景脱節的問題。