

前一段時間羣裏有小夥伴問 lucifer 我一個問題:”immutablejs 是什麼?有什麼用?“。我當時的回答是:immutablejs 就是 tree + sharing,解決了數據可變性帶來的問題,並順便優化了性能。今天給大家來詳細解釋一下這句話。
背景
我們還是通過一個例子來進行説明。如下是幾個普通地不能再普通的賦值語句:
a = 1;
b = 2;
c = 3;
d = {
name: "lucifer",
age: 17,
location: "西湖",
};
e = ["腦洞前端", "力扣加加"];上面代碼的內存結構大概是這樣的:
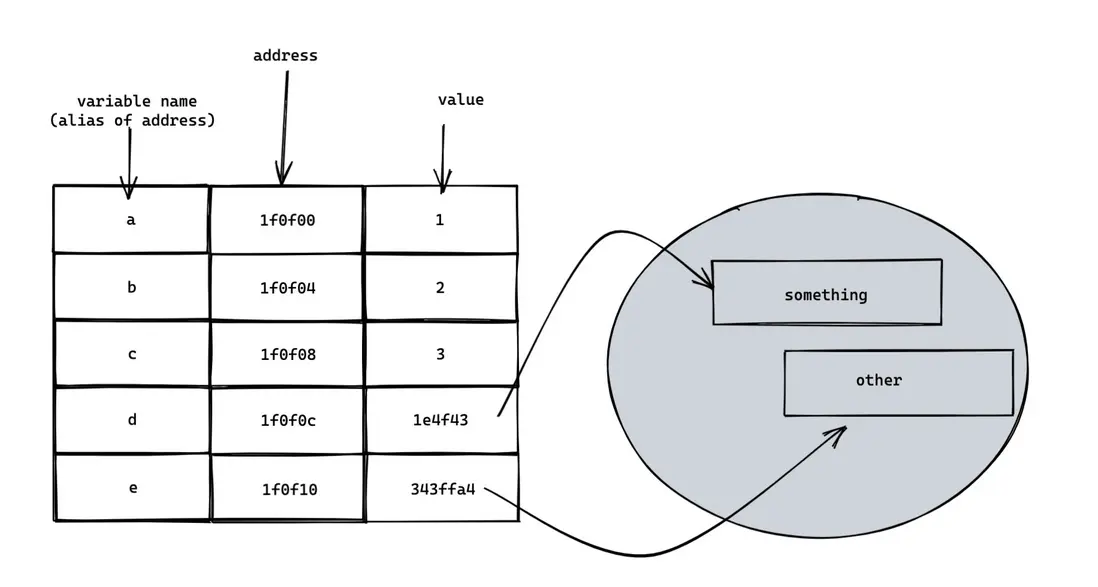
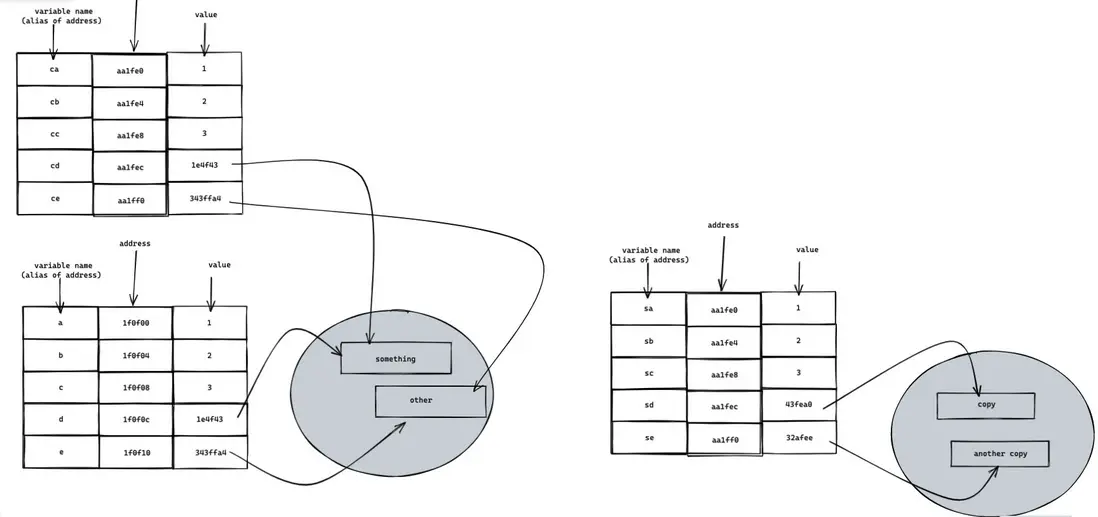
lucifer 小提示:可以看出,變量名( a,b,c,d,e )只是內存地址的別名而已
由於 d 和 e 的值是引用類型,數據長度不確定,因此實際上數據區域會指向堆上的一塊區域。而 a,b,c 由於長度是編譯時確定的,因此可以方便地在棧上存儲。
lucifer 小提示:d 和 e 的數據長度不確定, 但指針的長度是確定的,因此可以在棧上存儲指針,指針指向堆上內存即可。
實際開發我們經常會進行各種賦值操作,比如:
const ca = a;
const cb = b;
const cc = c;
const cd = d;
const ce = e;經過上面的操作,此時的內存結構圖:
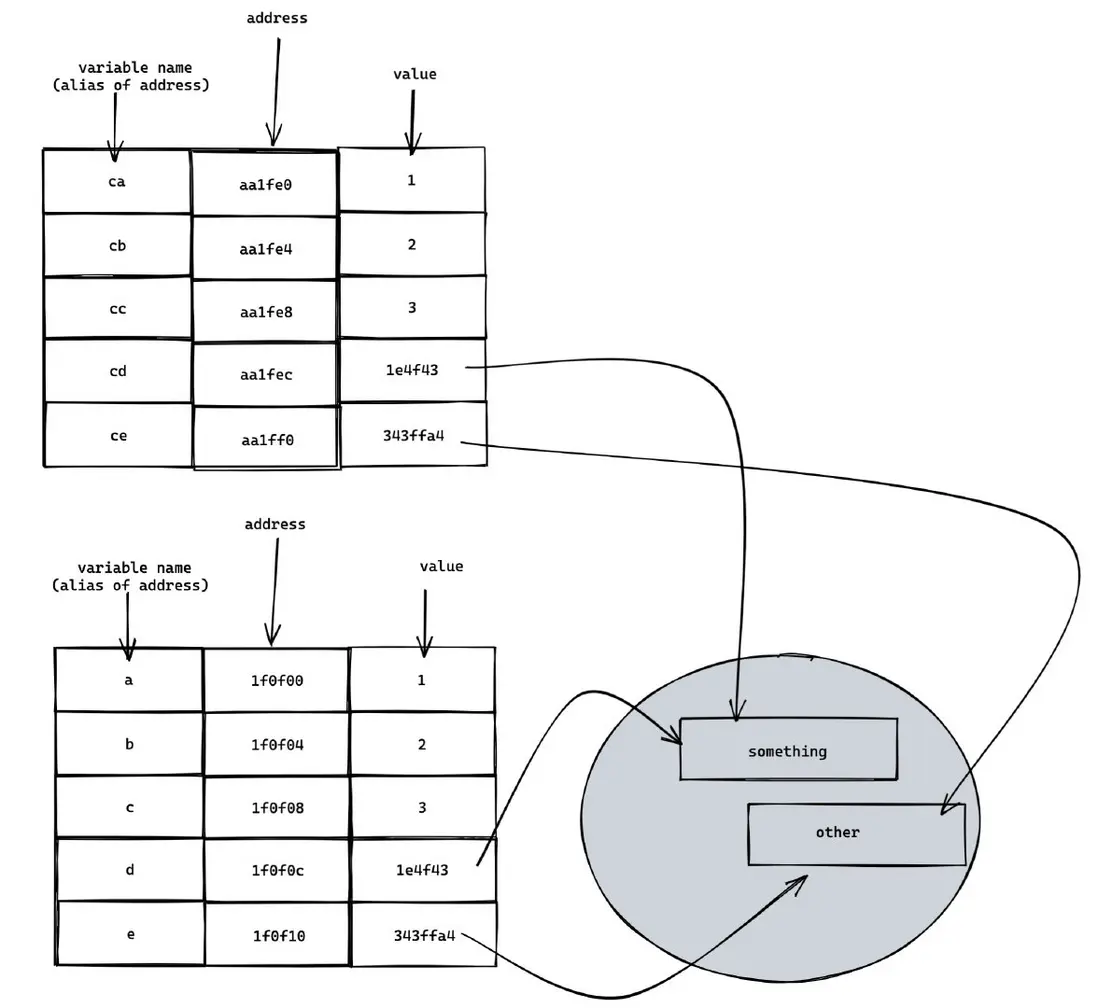
可以看出,ca,cb,cc,cd,ce 的內存地址都變了,但是值都沒變。原因在於變量名只是內存的別名而已,而賦值操作傳遞的是 value。
由於目前 JS 對象操作都是 mutable 的, 因此就有可能會發生這樣的 “bug”:
cd.name = "azl397985856";
console.log(cd.name); // azl397985856
console.log(d.name); // azl397985856上面的 cd.name 原地修改了 cd 的 name 值,這會影響所有指向 ta 的引用。
比如有一個對象被三個指針引用,如果對象被修改了,那麼三個指針都會有影響。
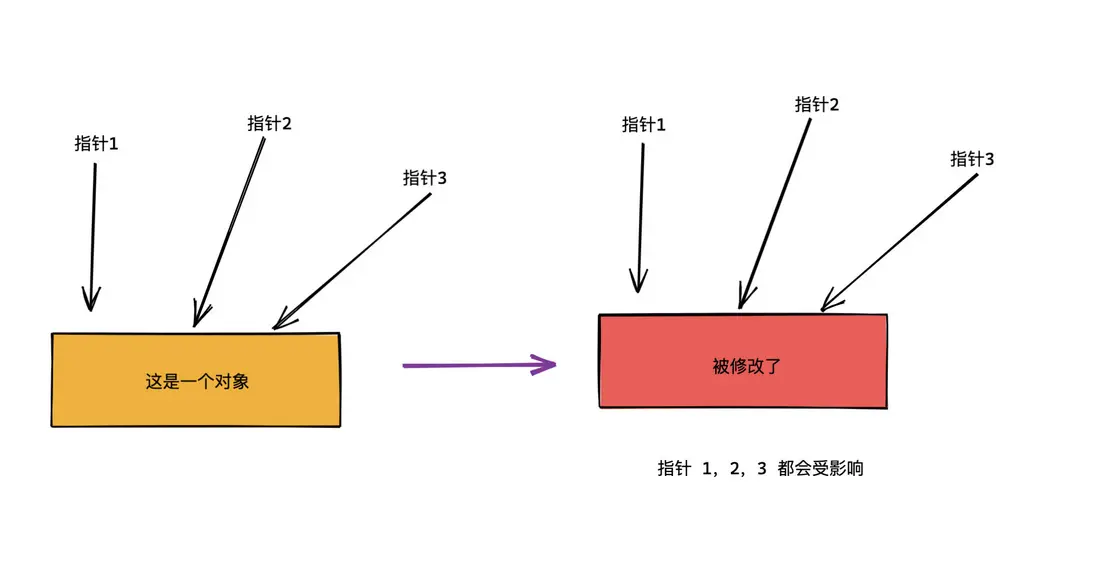
你可以把指針看成線程,對象看成進程資源,資源會被線程共享。 多指針就是多線程,當多個線程同時對一個對象進行讀寫操作就可能會有問題。
於是很多人的做法是 copy(shallow or deep)。這樣多個指針的對象都是不同的,可以看成多進程。
接下來我們進行一次 copy 操作。
const sa = a;
const sb = b;
const sc = c;
const sd = { ...d };
const se = [...e];
// 有的人還覺得不過癮
const sxbk = JSON.parse(JSON.stringify(e));旁觀者: 為啥你代碼那麼多 copy 啊?
當事人: 我也不知道為啥要 copy 一下,不過這樣做使我安心。
此時引用類型的 value 全部發生了變化,此時內存圖是這樣的:
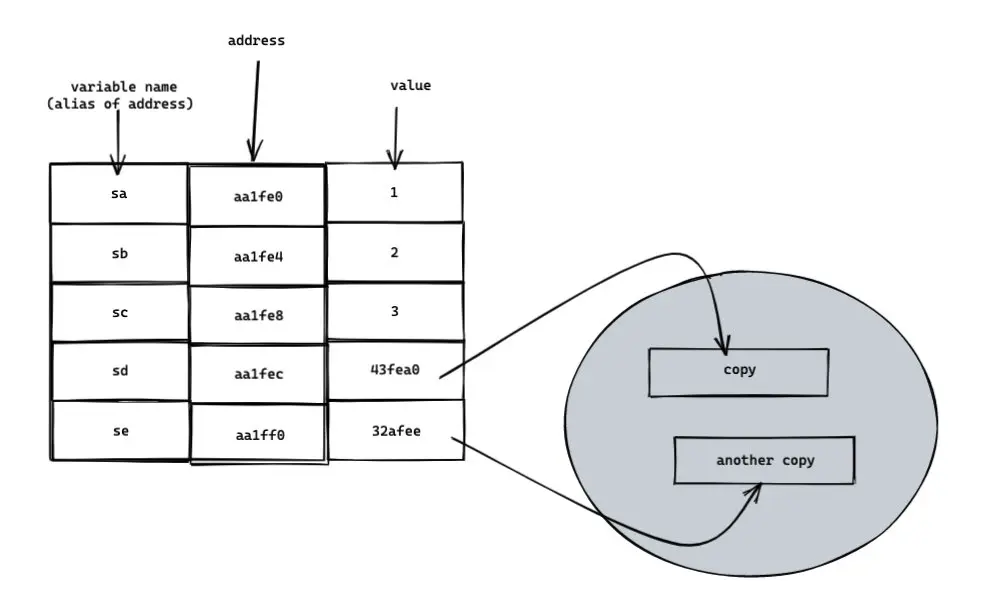
上面的 ”bug“ 成功解決。
lucifer 小提示: 如果你使用的是 shallow copy, 其內層的對象 value 是不會變化的。如果此時你對內層對象進行諸如 a.b.c 的操作,也會有”bug“。
完整內存圖:
(看不清可以嘗試放大)
問題
如果是 shallow copy 還好, 因為你只 copy 一層,但是隨着 key 的增加,性能下降還是比較明顯的。
據測量:
- shallow copy 包含 1w 個 屬性的對象大概要 10 ms。
- deep copy 一個三層的 1w 個屬性的對象大概要 50 ms。
而 immutablejs 可以幫助我們減少這種時間(和內存)開銷,這個我們稍後會講。
數據僅供參考,大家也可以用自己的項目測量一下。
由於普通項目很難達到這個量級,因此基本結論是:如果你的項目對象不會很大, 完全沒必要考慮諸如 immutablejs 進行優化,直接手動 copy 實現 immutable 即可。
如果我的項目真的很大呢?那麼你可以考慮使用 immutable 庫來幫你。 immutablejs 是無數 immutable 庫中的一個。我們來看下 immutablejs 是如何解決這個性能難題的。
immutablejs 是什麼
使用 immutablejs 提供的 API 操作數據,每一次操作都會返回一個新的引用,效果類似 deep copy,但是性能更好。
開頭我説了,immutablejs 就是 tree + sharing,解決了數據可變帶來的問題,並順便提供了性能。 其中這裏的 tree 就是類似 trie 的一棵樹。如果對 trie 不熟悉的,可以看下我之前寫的一篇前綴樹專題。
immutablejs 就是通過樹實現的結構共享。舉個例子:
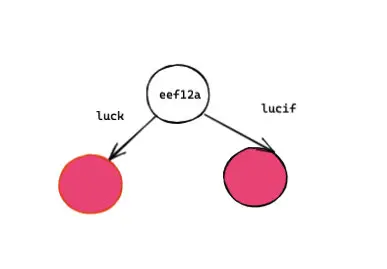
const words = ["lucif", "luck"];我根據 words 構建了一個前綴樹,節點不存儲數據, 數據存儲在路徑上。其中頭節點表示的是對象的引用地址。
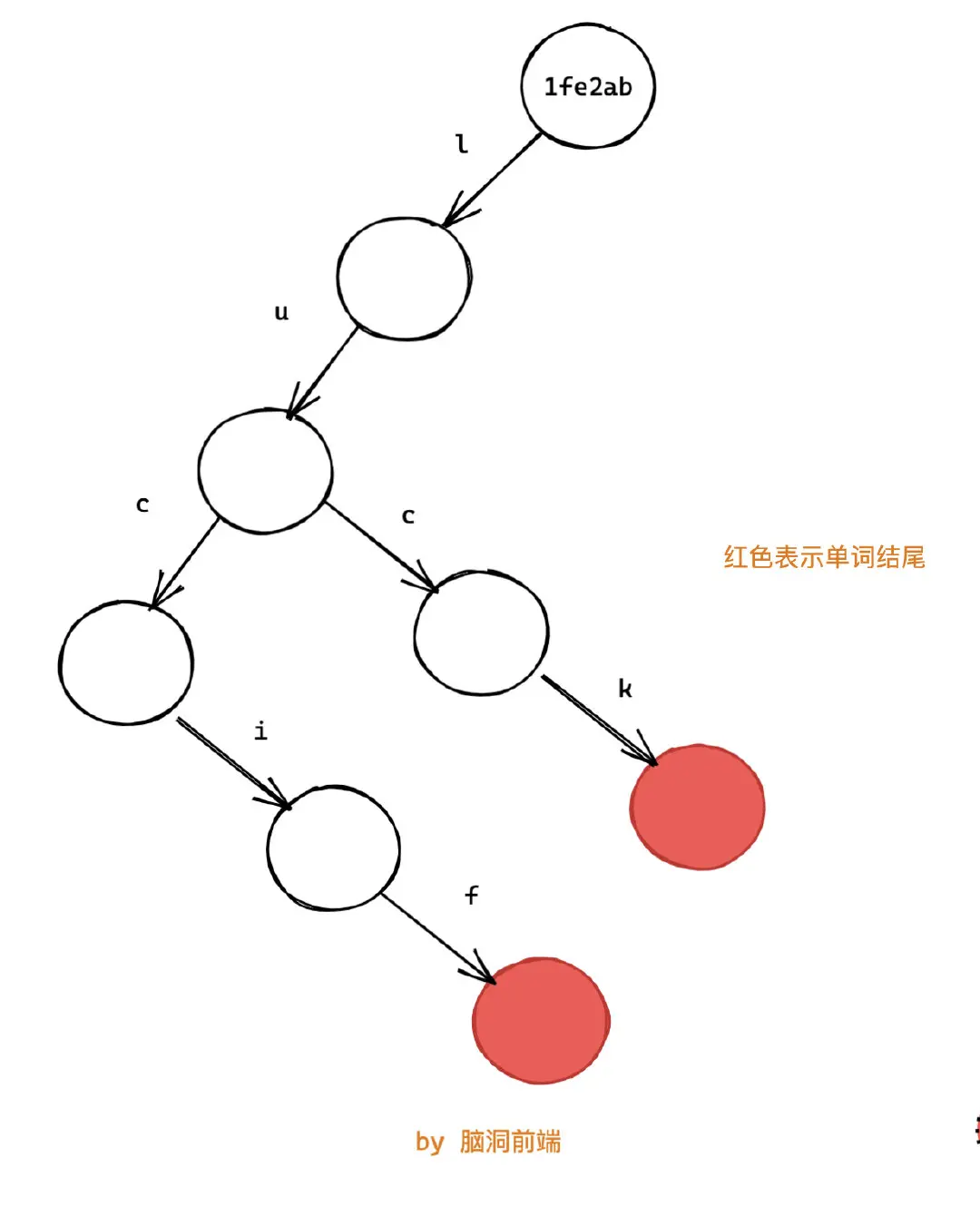
這樣我們就將兩個單詞 lucif 和 luck存到了樹上:
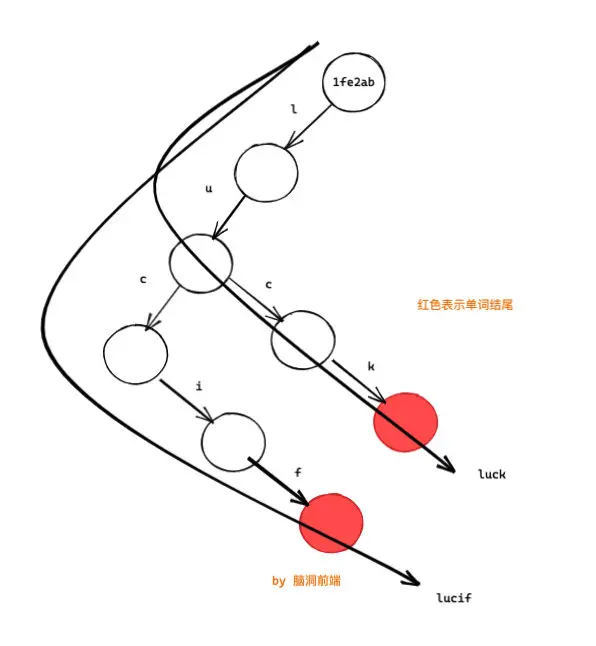
現在我想要將 lucif 改成 lucie,普通的做法是完全 copy 一份,之後修改即可。
newWords = [...words];
newWords[1] = "lucie";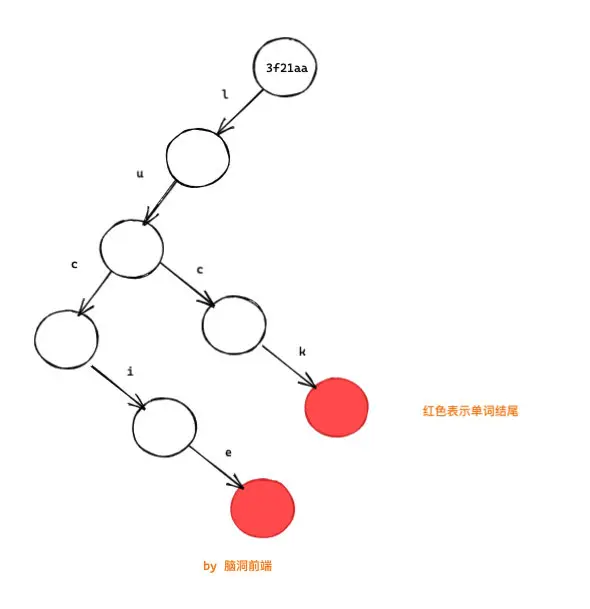
(注意這裏整棵樹都是新的,你看根節點的內存地址已經變了)
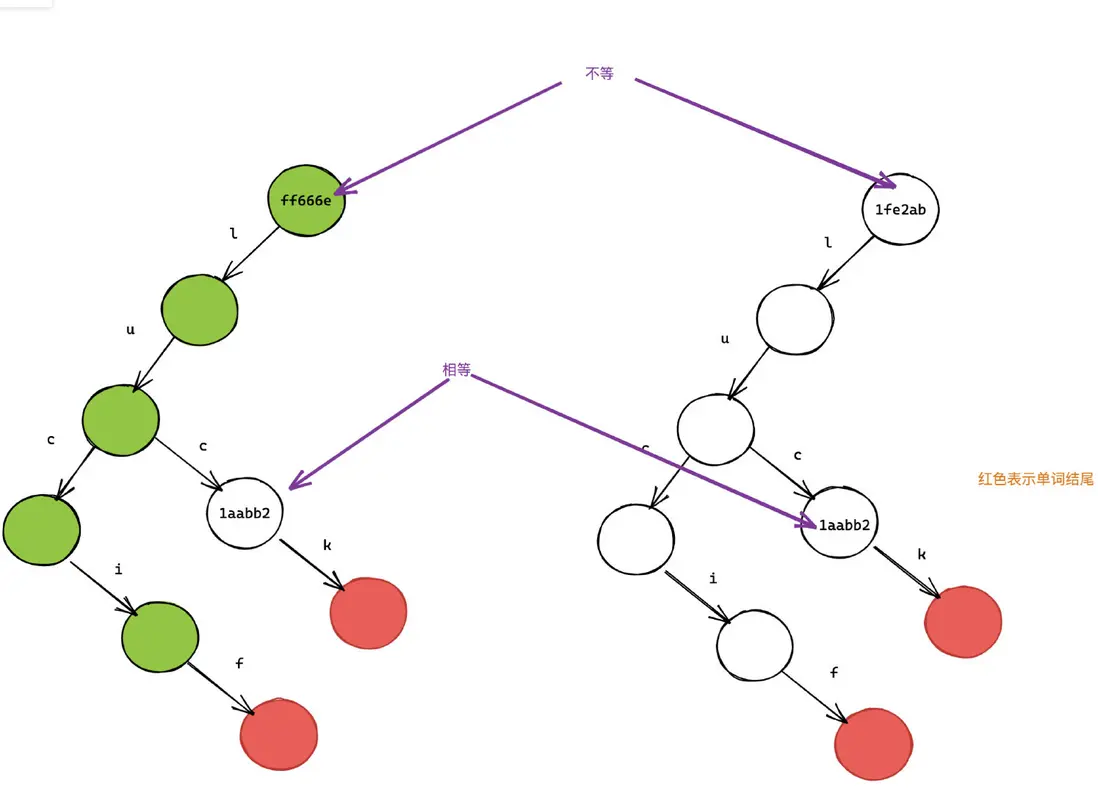
而所謂的狀態共享是:
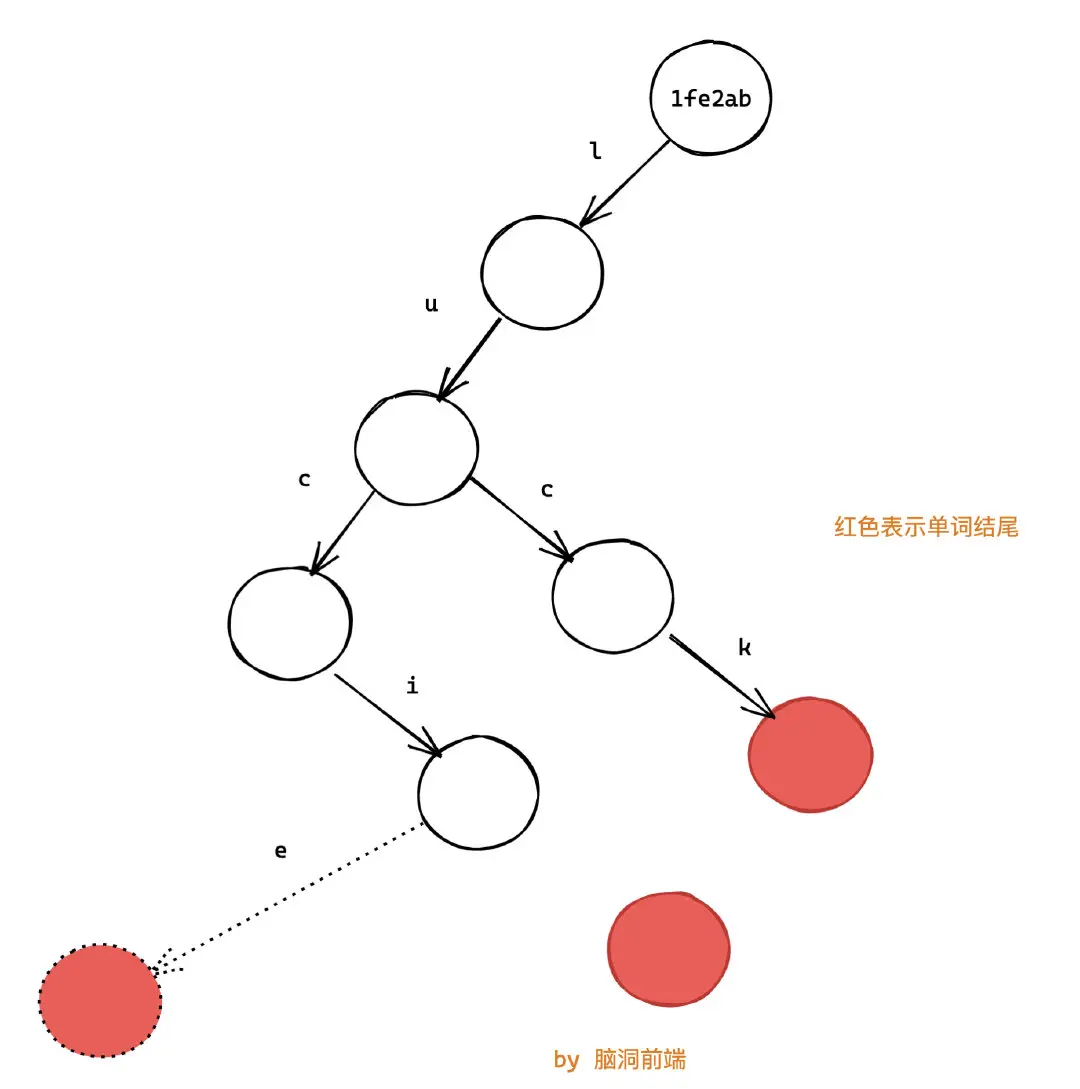
(注意這裏整棵樹除了新增的一個節點, 其他都是舊的,你看根節點的內存地址沒有變)
可以看出,我們只是增加了一個節點,並改變了一個指針而已,其他都沒有變化,這就是所謂的結構共享。
還是有問題
仔細觀察會發現:使用我們的方法,會造成 words 和 newWords 引用相等(都是 1fe2ab),即 words === newWords。
因此我們需要沿着路徑回溯到根節點,並修改沿路的所有節點(綠色部分)。在這個例子,我們僅僅少修改兩個節點。但是隨着樹的節點增加,公共前綴也會隨着增加,那時性能提升會很明顯。
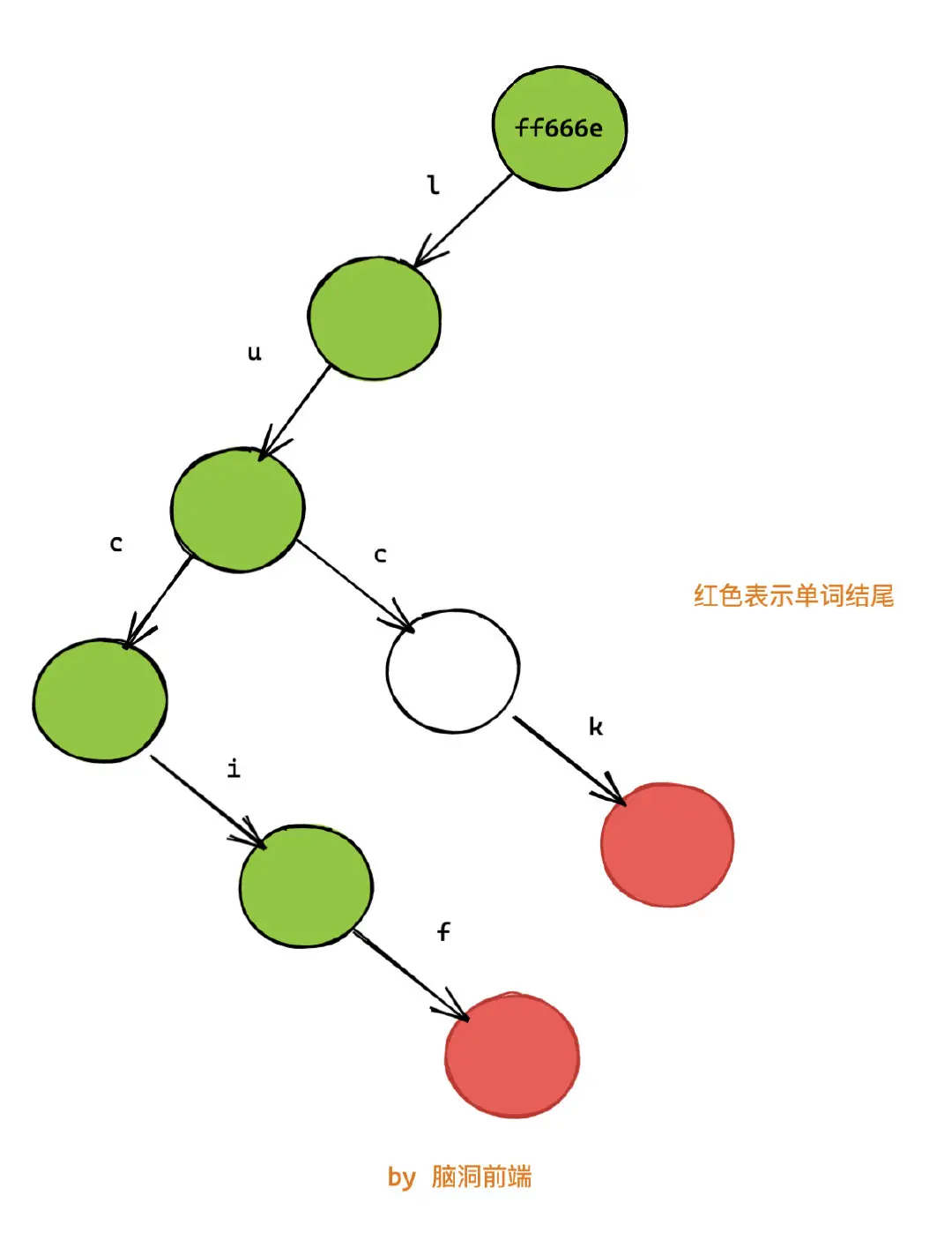
整個過程類似下面的動圖所示:
取捨之間
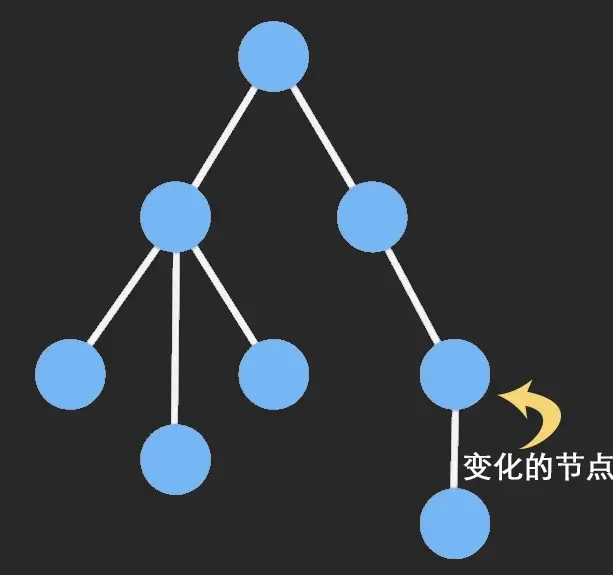
前面提到了 沿着路徑回溯到根節點,並修改沿路的所有節點。由於樹的總節點數是固定的,因此當樹很高的時候,某一個節點的子節點數目會很少,節點的複用率會很低。想象一個極端的情況,樹中所有的節點只有一個子節點,此時退化到鏈表,每次修改的時間複雜度為 O(P),其中 P 為其祖先節點的個數。如果此時修改的是葉子節點,那麼 P 就等於 N,其中 N 為 樹的節點總數。
樹很矮的情況,樹的子節點數目會增加,因此每次回溯需要修改的指針增加。如圖是有四個子節點的情況,相比於上面的兩個子節點,需要多創建兩個指針。
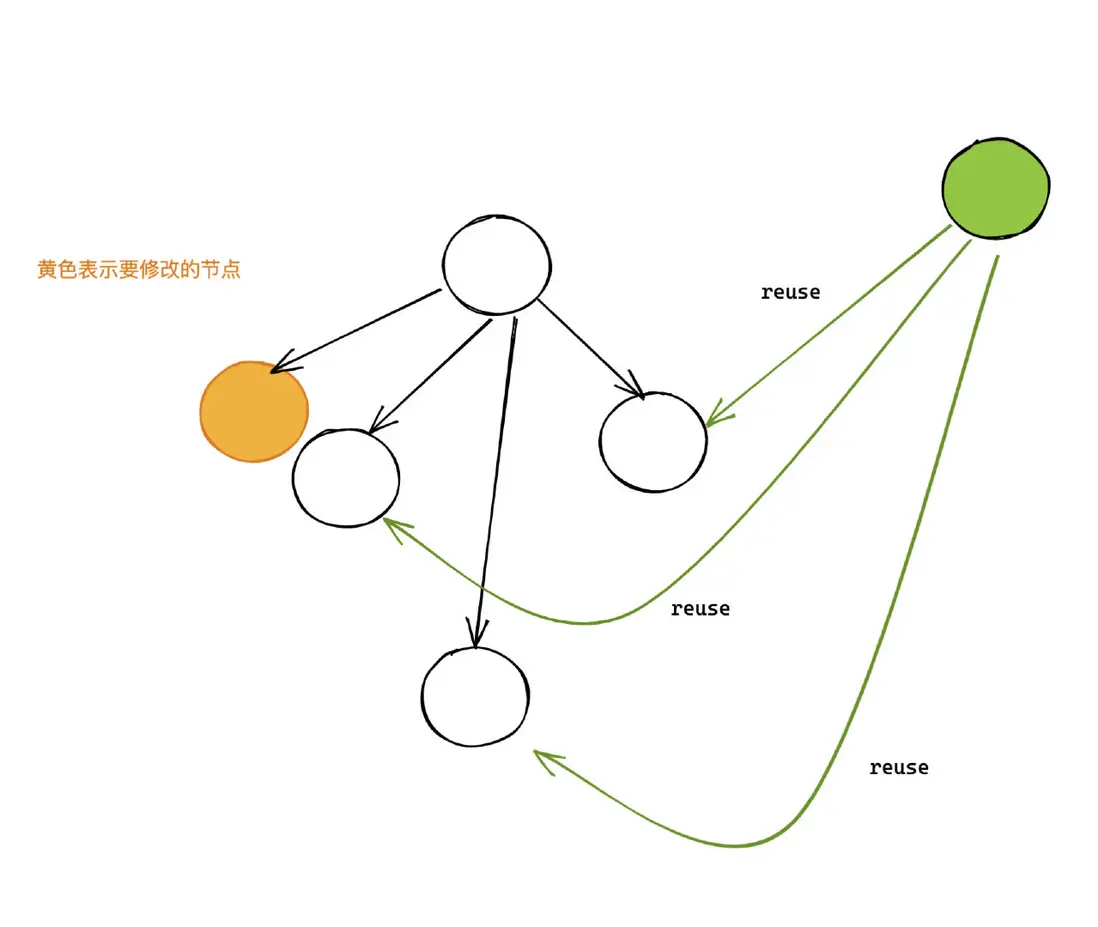
想象一種極端的情況,樹只有一層。還是將 lucif 改成 lucie。我們此時只能重新建立一個全新的 lucie 節點,無法利用已有節點,此時和 deep copy 相比沒有一點優化。
因此合理選擇樹的叉數是一個難點,絕對不是簡單的二叉樹就行了。這個選擇往往需要做很多實驗才能得出一個相對合理的值。
React
React 和 Vue 最大的區別之一就是 React 更加 "immutable"。React 更傾向於數據不可變,而 Vue 則相反。如果你恰好兩個框架都使用過,應該明白我的意思。
使用 immutable 的一個好處是未來的操作不會影響之前創建的對象。因此你可以很輕鬆地將應用的數據進行持久化,以便發送給後端做調試分析或者實現時光旅行(感謝可預測的單向數據流)。
結合 Redux 等狀態管理框架,immutablejs 可以發揮更大的作用。這個時候,你的整個 state tree 應該是 immutablejs 對象,不需要使用普通的 JavaScript 對象,並且操作也需要使用 immutablejs 提供的 API 來進行。 並且由於有了 immutablejs,我們可以很方便的使用全等 === 判斷。寫 SCU 也方便多了。
SCU 是 shouldComponentUpdate 的縮寫。
通過我的幾年使用經驗來看,使用類似 immutablejs 的庫,會使得性能有不穩定的提升。並且由於多了一個庫,調試成本或多或少有所增加,並且有一定的理解和上手成本。因此我的建議是技術咱先學着,如果項目確實需要使用,團隊成員技術也可以 Cover的話,再接入也不遲,不可過早優化。
總結
由於數據可變性,當多個指針指向同一個引用,其中一個指針修改了數據可能引發”不可思議“的效果。隨着項目規模的增大,這種情況會更加普遍。並且由於未來的操作可能會修改之前創建的對象,因此無法獲取中間某一時刻的狀態,這樣就缺少了中間的鏈路,很難進行調試 。數據不可變則是未來的操作不會影響之前創建的對象,這就減少了”不可思議“的現象,並且由於我們可以知道任何中間狀態,因此調試也會變得輕鬆。
手動實現”數據不可變“可以應付大多數情況。在極端情況下,才會有性能問題。immutablejs 就是 tree + sharing,解決了數據可變帶來的問題,並順便優化了性能。它不但解決了手動 copy 的性能問題,而且可以在 $O(1)$ 的時間比較一個對象是否發生了變化。因此搭配 React 的 SCU 優化 React 應用會很香。
最後推薦我個人感覺不錯的另外兩個 immutable 庫 seamless-immutable 和 Immer。
關注我
大家也可以關注我的公眾號《腦洞前端》獲取更多更新鮮的前端硬核文章,帶你認識你不知道的前端。
知乎專欄【 Lucifer - 知乎】
點關注,不迷路!