

- 本文略長,建議收藏,文末會附上完整前後端代碼(vue2&vue3+springboot)
- 湊合算是一套解決方案吧😁😁😁
- 前端vscode大家都有,後端大家需要下載一個idea,搞一下maven,這一點可以請後端同事幫忙
- 對於普通的單個的大文件上傳需求,應該可以應對
- 筆者本地測試,兩三個G的大文件沒有問題,線上嘛,你懂的
大文件上傳問題描述
問題背景
筆者的一個好友上個月被裁,最近在面試求職,在面試時,最後一個問題是問他有沒有做過大文件上傳功能,我朋友説沒做過...
現在的就業環境不太好,要求都比之前高一些,當然也有可能面試官刷面試KPI的,或者這個崗位不急着找人,慢慢面試唄。畢竟也算是自己的工作量,能寫進週報裏面...
對於我們每個人而言:【生於黑暗,追逐黎明————《異獸迷城》】
既然面試官會問,那咱們就一起來看看,大文件上傳功能如何實現吧...
中等文件上傳解決方案-nginx放行
在我們工作中,上傳功能最常見的就是excel的上傳功能,一般來説,一個excel的大小在10MB以內吧,如果有好幾十MB的excel,就勉強算是中等文件吧,此時,我們需要設置nginx的client_max_body_size值,將其放開,只不過一次上傳一個幾十MB的文件,接口會慢一些,不過也勉強能夠接受。
前端手握狼牙棒,後端手持流星錘,對產品朗聲笑道:要是不能接受,就請忍受🙂🙂🙂
但是,如果一個文件有幾百兆,或者好幾個G呢?上述方式就不合適了。
既然一次性上傳不行,那麼咱們就把大文件拆分開來,進行分批、分堆、分片、一點點上傳的操作,等上傳完了,再將一片片文件合併一起,再恢復成原來的樣子即可
最常見的這個需求,就是視頻的上傳,比如:騰訊視頻創作平台、嗶哩嗶哩後台等...
大文件上傳解決方案-文件分片
一共三步即可:
- 第一步,大文件拆分成一片又一片(分片操作)
- 第二步,每一次請求給後端帶一片文件(分片上傳)
- 第三步,當每一片文件都上傳完,再發請求告知後端將分片的文件合併即可(合併分片)
文件分片操作大致可分為上述三步驟,但在這三步驟中,還有一些細節需要我們注意,這個後文中會一一説到,我們繼續往下閲讀
大文件上傳效果圖
為便於更好理解,我們看一下已經做好的效果圖:

由上述效果圖,我們可以看到,一個58MB的大文件,被分成了12片上傳,很快啊!上傳完成。
思考兩個問題:
- 若某個文件已經存在(曾經上傳過),那我還需要上傳嗎?
- 若同一時刻,兩個人都在分片上傳完大文件,併發起合併請求,如何才能保證不合並錯呢?如A文件分片成a1,a2,a3;B文件分片成b1,b2,b3 。合併操作肯定不能把a1,a2,a3文件內容合併到B文件中去。
解決方案就是:
- 要告知後端我這次上傳的文件是哪一個,下次上傳的文件又是哪一個
- 就像我們去修改表格中的某條數據時,需要有一個固定的參數id,告知後端去update具體的那一條數據
- 知道具體的文件id,就不會操作錯了
那新的問題又來了:
前端如何才能確定文件的id,如何才能得到文件的唯一標識?
如何得到文件唯一標識?
樹上沒有兩片相同的葉子,天上沒有兩朵相同的雲彩,文件是獨一無二的(前提是內容不同,複製一份的不算)
who know?
spark-md5怪笑一聲: 寡人知曉!
什麼是spark-md5?
spark-md5是基於md5的一種優秀的算法,用處很多,其中就可以去計算文件的唯一身份證標識-hash值
- 只要文件內容不同(包含的二進制01不同),那麼使用spark-md5這個npm包包,得到的結果hash值就不一樣
- 這個獨一無二的hash值,就可以看做大文件的id
- 發請求時,就可以將這個大文件的hash值唯一id帶着傳給後端,後端就知道去操作那個文件了
當然還有別的工具庫,如CryptoJS也可以計算文件的hash值,不過spark-md5更主流、更優秀
使用spark-md5直接計算整個文件的hash值(唯一id身份證標識)
直接計算一整個文件的hash值:
<script src="https://cdn.bootcdn.net/ajax/libs/spark-md5/3.0.2/spark-md5.min.js"></script>
<input type="file" @change="changeFile">
<script>
const inputDom = document.querySelector('input') // 獲取input文件標籤的dom元素
inputDom.onchange = (e) => {
let file = inputDom.files[0] // 拿到文件
let spark = new SparkMD5.ArrayBuffer() // 實例化spark-md5
let fileReader = new FileReader() // 實例化文件閲讀器
fileReader.onload = (e) => {
spark.append(e.target.result) // 添加到spark算法中計算
let hash = spark.end() // 計算完成得到hash結果
console.log('文件的hash值為:', hash);
}
fileReader.readAsArrayBuffer(file) // 開始閲讀這個文件,閲讀完成觸發onload方法
}
</script>直接計算一個整文件的hash值,文件小的話,還是比較快的,但是當文件比較大的時,直接計算一整個文件的hash值,就會比較慢了。
此刻大文件分片的好處,再一次體現出來:大文件分片不僅僅可以用於發送請求傳遞給後端,也可以用於計算大文件的hash值,直接計算一個大文件hash值任務慢,那就拆分成一些小任務,這樣效率也提升了不少
至此,又延伸出一個問題,如何給大文件分片?
當我們想解決一個A問題時,我們發現需要進一步,解決其中包含a1問題,當我們想要解決a1問題時,我們發現需要再進一步解決a1的核心a11問題。當a11問題被解決時,a1也就解決了,與此同時A問題也就迎刃而解了
給文件分片操作
- 文件分片,別名文件分堆,又名文件分塊,也叫作文件拆分
- 類比,一個大的字符串可以截取slice(切割)成好幾個小的字符串
- 同理,一個大文件也可以slice成好多小文件,對應api: file.slice
- 文件file是特殊的二進制blob文件(所以file可以用blob的方法)
- 上代碼
const inputDom = document.querySelector('input') // 獲取input文件標籤的dom元素
inputDom.onchange = (e) => {
let file = inputDom.files[0] // 拿到文件
function sliceFn(file, chunkSize = 1 * 1024 * 1024) {
const result = [];
// 從第0字節開始切割,一次切割1 * 1024 * 1024字節
for (let i = 0; i < file.size; i = i + chunkSize) {
result.push(file.slice(i, i + chunkSize));
}
return result;
}
const chunks = sliceFn(file)
console.log('文件分片成數組', chunks);
}文件分片結果效果圖(比如我選了一個5兆多的文件去分片):
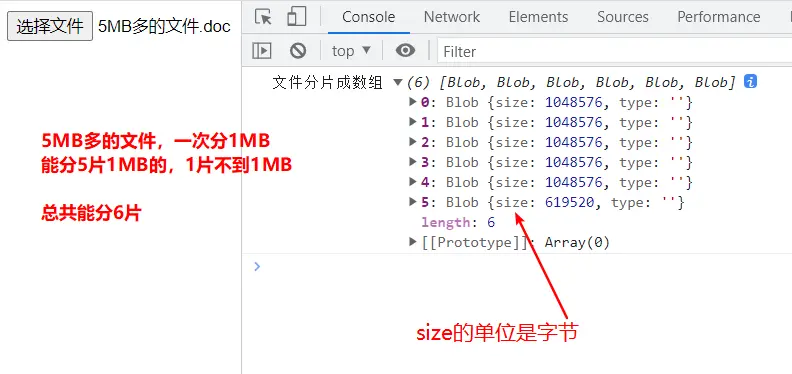
大文件分片後搭配spark-md5計算整個文件的hash值
有了上述分好片的chunks數組(數組中存放一片又一片小文件),再結合spark-md5,使用遞歸的寫法,一片一片的再去讀取計算,最終算出結果
/**
* chunks:文件分好片的數組、progressCallbackFn回調函數方法,用於告知外界進度的
* 因為文件閲讀器是異步的,所以要套一層Promise方便拿到異步的計算結果
**/
function calFileMd5Fn(chunks, progressCallbackFn) {
return new Promise((resolve, reject) => {
let currentChunk = 0 // 準備從第0塊開始讀
let spark = new SparkMD5.ArrayBuffer() // 實例化SparkMD5用於計算文件hash值
let fileReader = new FileReader() // 實例化文件閲讀器用於讀取blob二進制文件
fileReader.onerror = reject // 兜一下錯
fileReader.onload = (e) => {
progressCallbackFn(Math.ceil(currentChunk / chunks.length * 100)) // 拋出一個函數,用於告知進度
spark.append(e.target.result) // 將二進制文件追加到spark中(官方方法)
currentChunk = currentChunk + 1 // 這個讀完就加1,讀取下一個blob
// 若未讀取到最後一塊,就繼續讀取;否則讀取完成,Promise帶出結果
if (currentChunk < chunks.length) {
fileReader.readAsArrayBuffer(chunks[currentChunk])
} else {
resolve(spark.end()) // resolve出去告知結果 spark.end官方api
}
}
// 文件讀取器的readAsArrayBuffer方法開始讀取文件,從blob數組中的第0項開始
fileReader.readAsArrayBuffer(chunks[currentChunk])
})
}使用:
inputDom.onchange = (e) => {
let file = inputDom.files[0]
function sliceFn(file, chunkSize = 1 * 1024 * 1024) {
const result = [];
for (let i = 0; i < file.size; i = i + chunkSize) {
result.push(file.slice(i, i + chunkSize));
}
return result;
}
const chunks = sliceFn(file)
// 分好片的大文件數組,去計算hash。progressFn為進度條函數,需額外定義
const hash = await calFileMd5Fn(chunks,progressFn)
// "233075d0c65166792195384172387deb" // 32位的字符串
}至此,我們大文件分片上傳操作,已經完成了三分之一了。我們已經完成了大文件的分片和計算大文件的hash值唯一身份證id(實際上,計算大文件的hash值,還是挺耗費時長的,優化方案就是開一個輔助線程進行異步計算操作,不過這個是優化的點,文末會提到)
接下來,就到了第二步,發請求環節:將已經分好片的每一片和這個大文件的hash值作為參數傳遞給後端(當然還有別的參數,比如文件名、文件分了多少片,每次上傳的是那一片【索引】等---看後端定義)
大文件上傳解決方案:
- 第一步,大文件拆分成一片又一片(分片操作)✔️
- 第二步,每一次請求給後端帶一片文件(分片上傳)
- 第三步,當每一片文件都上傳完,再發請求告知後端將分片的文件合併即可
分片上傳發請求,一片就是一請求
詩曰:
分片上傳發請求,一片就是一請求。
請求之前帶校驗,這樣操作才規範。
分片上傳請求前的校驗請求
校驗邏輯思路如下:
- 大文件分好片以後,在分片文件上傳前,先發個請求帶着大文件的唯一身份證標識hash值,去問問後端有沒有上傳過這個文件,或者服務端的這個文件是否上傳完整(比如曾經上傳一半的時候,突然斷網了,或者刷新網頁導致上傳中斷)
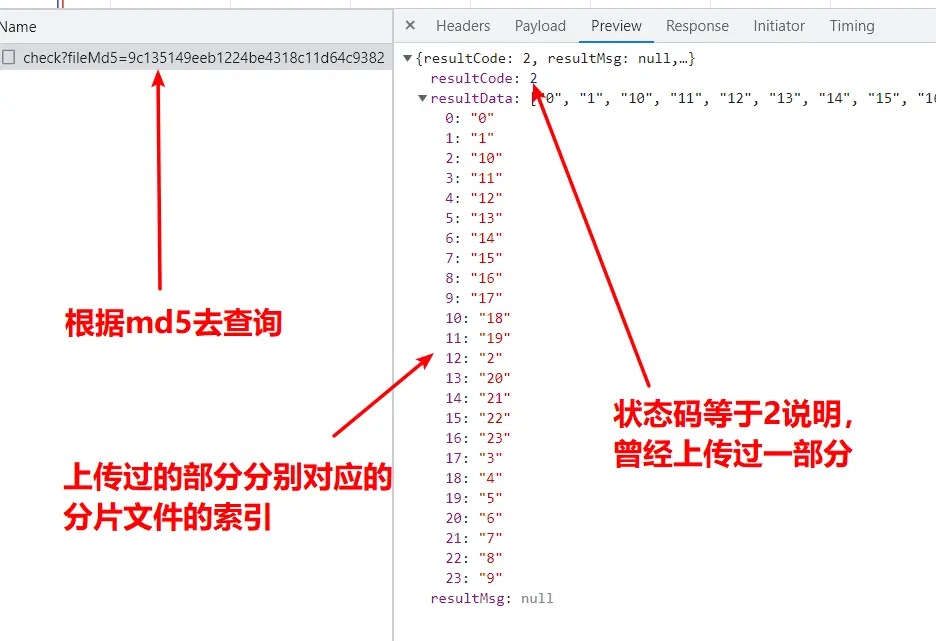
- 後端去看看已經操作完成的文件夾中的文件,有沒有叫做這個hash的,根據有沒有返回不同的狀態碼
比如,如下狀態碼:
- 等於0表示沒有上傳過,直接上傳
- 等於1曾經上傳過,不需要再上傳了(或:障眼法文件秒傳遞)
- 等於2表示曾經上傳過一部分,現在要繼續上傳
對應前端代碼:
以下代碼舉例是vue3的語法舉例,大家知道每一步做什麼即可,文章看完,建議大家去筆者的github倉庫把前後端代碼,都拉下來跑起來,結合代碼中的註釋,才能夠更好的理解
html結構
<template>
<div id="app">
<input ref="inputRef" class="inputFile" type="file" @change="changeFile" />
<div>大文件 <span class="bigFileC">📁</span> 分了{{ chunksCount }}片:</div>
<div class="pieceItem" v-for="index in chunksCount" :key="index">
<span class="a">{{ index - 1 }}</span>
<span class="b">📄</span>
</div>
<div>計算此大文件的hash值進度</div>
<div class="r">結果為: {{ fileHash }}</div>
<progress max="100" :value="hashProgress"></progress> {{ hashProgress }}%
<div>
<div>上傳文件的進度</div>
<div class="r" v-show="fileProgress == 100">文件上傳完成</div>
<progress max="100" :value="fileProgress"></progress> {{ fileProgress }}%
</div>
</div>
</template>發校驗請求
/**
* 發請求,校驗文件是否上傳過,分三種情況:見:fileStatus
* */
export function checkFileFn(fileMd5) {
return new Promise((resolve, reject) => {
resolve(axios.post(`http://127.0.0.1:8686/bigfile/check?fileMd5=${fileMd5}`))
})
}
const res = await checkFileFn(fileMd5);
// res.data.resultCode 為0 或1 或2對應後端代碼:
筆者後端代碼是springboot,文末會附上代碼,大家看一下
private String fileStorePath = "F:\kkk\"; // 大文件上傳操作在F盤下的kkk文件夾中操作
/**
* @param fileMd5
* @Title: 判斷文件是否上傳過,是否存在分片,斷點續傳
* @MethodName: checkBigFile
* @Exception
* @Description: 文件已存在,1
* 文件沒有上傳過,0
* 文件上傳中斷過,2 以及現在有的數組分片索引
*/
@RequestMapping(value = "/check", method = RequestMethod.POST)
@ResponseBody
public JsonResult checkBigFile(String fileMd5) {
JsonResult jr = new JsonResult();
// 秒傳
File mergeMd5Dir = new File(fileStorePath + "/" + "merge" + "/" + fileMd5);
if (mergeMd5Dir.exists()) {
mergeMd5Dir.mkdirs();
jr.setResultCode(1);//文件已存在
return jr;
}
// 讀取目錄裏的所有文件
File dir = new File(fileStorePath + "/" + fileMd5);
File[] childs = dir.listFiles();
if (childs == null) {
jr.setResultCode(0);//文件沒有上傳過
} else {
jr.setResultCode(2);//文件上傳中斷過,除了狀態碼為2,還有已上傳的文件分片索引
List<String> list = Arrays.stream(childs).map(f->f.getName()).collect(Collectors.toList());
jr.setResultData(list.toArray());
}
return jr;
}前端根據接口的狀態碼,作相應控制,沒上傳過正常操作,曾經上傳過了,就做個提示文件已上傳。這裏需要特別注意一下,曾經上傳中斷的情況
特別情況:當前上傳的文件曾經中斷過(斷點續傳)
我們來捋一下邏輯就明晰了:
- 假設一個大文件分為了10片,對應文件片的索引是0~9
- 在執行上傳的時候,發了10個請求,分別帶上對應的索引文件片
- 由於不可抗力因素,導致只上傳成功了3片文件,分別是索引0、索引8、索引9
- 還有索引1、2、3、4、5、6、7這七片文件沒上傳成功
- 那麼在檢查文件時,後端除了返回狀態碼2,同時也返回後端已經上傳成功的片的索引有哪些
- 即:
{resultCode:2 , resultData:[0,8,9]} - 我們在執行上傳文件操作時候,去掉這三個已經上傳完成的即可,上傳那些未完成的
// 等於2表示曾經上傳過一部分,現在要繼續上傳
if (res.data.resultCode == 2) {
// 若是文件曾上傳過一部分,後端會返回上傳過得部分的文件索引,前端通過索引可以知道哪些
// 上傳過,做一個過濾,已上傳的文件就不用繼續上傳了,上傳未上傳過的文件片
doneFileList = res.data.resultData.map((item) => {
return item * 1; // 後端給到的是字符串索引,這裏轉成數字索引
});
}doneFileList數組存儲的就是後端返回的,曾經上傳過一部分的數組分片文件索引
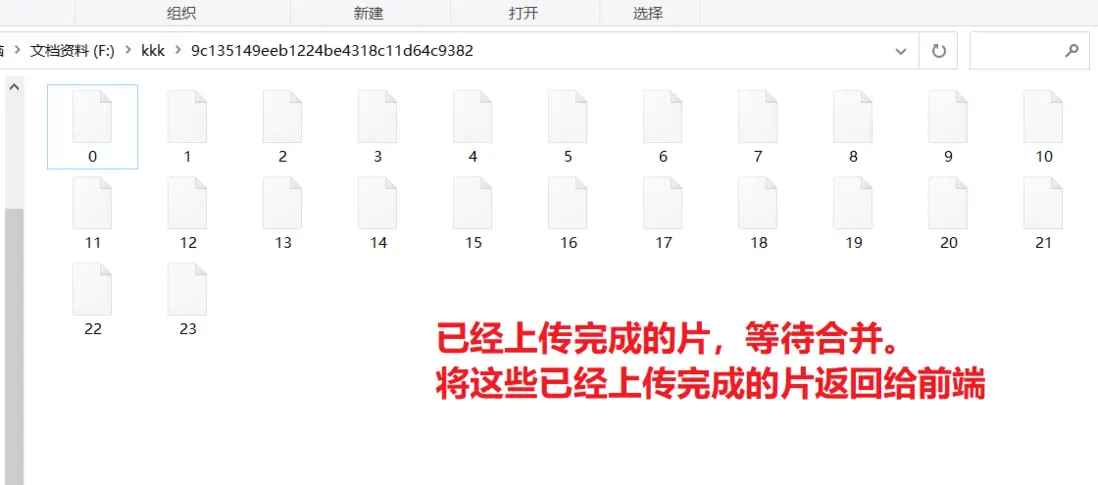
比如下面這兩張圖,就是文件曾經上傳中斷以後的,再次上傳的檢查接口返回的數據
示例圖一:
返回的是分片文件的名,也就是分片的索引,如下圖:
前端根據doneFileList判斷,去準備參數
// 説明沒有上傳過,組裝一下,直接使用
if (doneFileList.length == 0) {
formDataList = chunks.map((item, index) => {
// 後端接參大致有:文件片、文件分的片數、每次上傳是第幾片(索引)、文件名、此完整大文件hash值
// 具體後端定義的參數prop屬性名,看他們如何定義的,這個無妨...
let formData = new FormData();
formData.append("file", item); // 使用FormData可以將blob文件轉成二進制binary
formData.append("chunks", chunks.length);
formData.append("chunk", index);
formData.append("name", fileName);
formData.append("md5", fileMd5);
return { formData };
});
}
// 説明曾經上傳過,需要過濾一下,曾經上傳過的就不用再上傳了
else {
formDataList = chunks
.filter((index) => {
return !doneFileList.includes(index);
})
.map((item, index) => {
let formData = new FormData();
// 這幾個是後端需要的參數
formData.append("file", item); // 使用FormData可以將blob文件轉成二進制binary
formData.append("chunks", chunks.length);
formData.append("chunk", index);
formData.append("name", fileName);
formData.append("md5", fileMd5);
return { formData };
});
}
// 帶着分片數組請求參數,和文件名 fileName = file.name
// 準備一次併發很多的請求
fileUpload(formDataList, fileName);上述代碼實現了,正常上傳以及曾經中斷過的文件繼續上傳,這就是斷點續傳
上述代碼實現了,正常上傳以及曾經中斷過的文件繼續上傳,這就是斷點續傳
上述代碼實現了,正常上傳以及曾經中斷過的文件繼續上傳,這就是斷點續傳
使用Promise.allSettled(arr)併發上傳分好片的文件
- 使用Promise.allSettled發請求好一些,掛了的就掛了,不影響後續不掛的分片上傳請求
- Promise.all則不行,一個掛了都掛了
前端代碼
const fileUpload = (formDataList, fileName) => {
const requestListFn = formDataList.map(async ({ formData }, index) => {
const res = await sliceFileUploadFn(formData);
// 每上傳完畢一片文件,後端告知已上傳了多少片,除以總片數,就是進度
fileProgress.value = Math.ceil(
(res.data.resultData / chunksCount.value) * 100
);
return res;
});
// 使用allSettled發請求好一些,掛了的就掛了,不影響後續不掛的請求
Promise.allSettled(requestListFn).then((many) => {
// 都上傳完畢了,文件上傳進度條就為100%了
});
};後端代碼
/**
* 上傳文件
* @param param
* @param request
* @return
* @throws Exception
*/
@RequestMapping(value = "/upload", method = RequestMethod.POST)
@ResponseBody
public JsonResult filewebUpload(MultipartFileParam param, HttpServletRequest request) {
JsonResult jr = new JsonResult();
boolean isMultipart = ServletFileUpload.isMultipartContent(request);
// 文件名
String fileName = param.getName();
// 文件每次分片的下標
int chunkIndex = param.getChunk();
if (isMultipart) {
File file = new File(fileStorePath + "/" + param.getMd5());
if (!file.exists()) { // 沒有文件創建文件
file.mkdir();
}
File chunkFile = new File(
fileStorePath + "/" + param.getMd5() + "/" + chunkIndex);
try {
FileUtils.copyInputStreamToFile(param.getFile().getInputStream(), chunkFile); // 流文件操作
} catch (Exception e) {
jr.setResultCode(-1);
e.printStackTrace();
}
}
logger.info("文件-:{}的小標-:{},上傳成功", fileName, chunkIndex);
File dir = new File(fileStorePath + "/" + param.getMd5());
File[] childs = dir.listFiles();
if(childs!=null){
jr.setResultData(childs.length); // 返回上傳了幾個,即為上傳進度
}
return jr;
}最後別忘了去合併這些文件分片
添一個上傳文件的效果圖
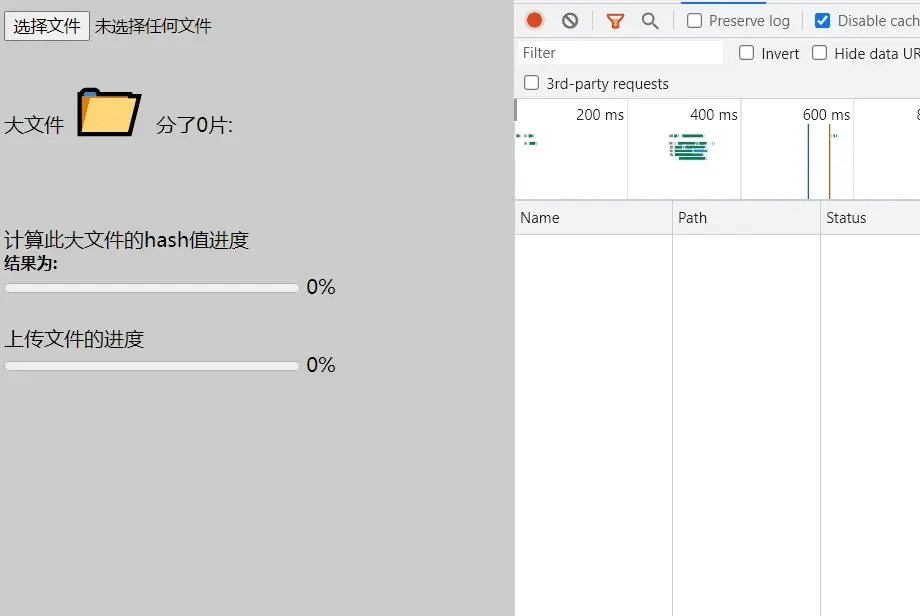
- 由上述動態圖,我們可以看到把文件切割成了12份,所以發送了12個上傳分片請求
- 當然,上傳完成以後,最後,再發一個請求,告知後端去合併這些一片片文件即可
- 即merge請求,當然也要帶上此大文件的hash值
- 告知後端具體合併哪一個文件,這樣才不會出錯
前端代碼
// 使用allSettled發請求好一些,掛了的就掛了,不影響後續不掛的請求
Promise.allSettled(requestListFn).then(async (many) => {
// 都上傳完畢了,文件上傳進度條就為100%了
fileProgress.value = 100;
// 最後再告知後端合併一下已經上傳的文件碎片了即可
const loading = ElLoading.service({
lock: true,
text: "文件合併中,請稍後📄📄📄...",
background: "rgba(0, 0, 0, 0.7)",
});
const res = await tellBackendMergeFn(fileName, fileHash.value);
if (res.data.resultCode === 0) {
console.log("文件併合成功,大文件上傳任務完成");
loading.close();
} else {
console.log("文件併合失敗,大文件上傳任務未完成");
loading.close();
}
});後端代碼
/**
* 分片上傳成功之後,合併文件
* @param request
* @return
*/
@RequestMapping(value = "/merge", method = RequestMethod.POST)
@ResponseBody
public JsonResult filewebMerge(HttpServletRequest request) {
FileChannel outChannel = null;
JsonResult jr = new JsonResult();
int code =0;
try {
String fileName = request.getParameter("fileName");
String fileMd5 = request.getParameter("fileMd5");
// 讀取目錄裏的所有文件
File dir = new File(fileStorePath + "/" + fileMd5);
File[] childs = dir.listFiles();
if (Objects.isNull(childs) || childs.length == 0) {
jr.setResultCode(-1);
return jr;
}
// 轉成集合,便於排序
List<File> fileList = new ArrayList<File>(Arrays.asList(childs));
Collections.sort(fileList, new Comparator<File>() {
@Override
public int compare(File o1, File o2) {
if (Integer.parseInt(o1.getName()) < Integer.parseInt(o2.getName())) {
return -1;
}
return 1;
}
});
// 合併後的文件
File outputFile = new File(fileStorePath + "/" + "merge" + "/" + fileMd5 + "/" + fileName);
// 創建文件
if (!outputFile.exists()) {
File mergeMd5Dir = new File(fileStorePath + "/" + "merge" + "/" + fileMd5);
if (!mergeMd5Dir.exists()) {
mergeMd5Dir.mkdirs();
}
logger.info("創建文件");
outputFile.createNewFile();
}
outChannel = new FileOutputStream(outputFile).getChannel();
FileChannel inChannel = null;
try {
for (File file : fileList) {
inChannel = new FileInputStream(file).getChannel();
inChannel.transferTo(0, inChannel.size(), outChannel);
inChannel.close();
// 刪除分片
file.delete();
}
} catch (Exception e) {
code =-1;
e.printStackTrace();
//發生異常,文件合併失敗 ,刪除創建的文件
outputFile.delete();
dir.delete();//刪除文件夾
} finally {
if (inChannel != null) {
inChannel.close();
}
}
dir.delete(); //刪除分片所在的文件夾
} catch (IOException e) {
code =-1;
e.printStackTrace();
} finally {
try {
if (outChannel != null) {
outChannel.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
jr.setResultCode(code);
return jr;
}
}至此,大文件上傳的三步都完成了
大文件上傳解決方案:
- 第一步,大文件拆分成一片又一片(分片操作)✔️
- 第二步,每一次請求給後端帶一片文件(分片上傳)✔️
- 第三步,當每一片文件都上傳完,再發請求告知後端將分片的文件合併即可✔️
- 筆者用本機測試了一下,兩三個G的文件都是沒有問題的
- 實際項目上線,大文件上傳功能,會受到網絡帶寬、設備性能等各種因素影響
- 一定要注意文件分片時切分的大小,例:
CHUNK_SIZE = 5 * 1024 * 1024; - 這個文件的大小決定了切割多少片,決定了併發多少請求(不可過大,也不可能非常小)
- 太大單個請求就太慢了,太小瀏覽器一次發幾千上萬個請求,也扛不住
輔助線程去優化
開啓輔助線程計算大文件的hash值
首先,定義函數異步,開啓輔助線程,計算
const calFileMd5ByThreadFn = (chunks) => {
return new Promise((resolve) => {
worker = new Worker("./hash.js"); // 實例化一個webworker線程
worker.postMessage({ chunks }); // 主線程向輔助線程傳遞數據,發分片數組用於計算
worker.onmessage = (e) => {
const { hash } = e.data; // 輔助線程將相關計算數據發給主線程
hashProgress.value = e.data.hashProgress; // 更改進度條
if (hash) {
// 當hash值被算出來時,就可以關閉主線程了
worker.terminate();
resolve(hash); // 將結果帶出去
}
};
});
};然後,在public目錄下新建hash.js去撰寫輔助線程代碼
// 使用importScripts引入cdn使用
self.importScripts('https://cdn.bootcdn.net/ajax/libs/spark-md5/3.0.2/spark-md5.min.js')
self.onmessage = e => {
const { chunks } = e.data // 獲取到分片數組
const spark = new self.SparkMD5.ArrayBuffer() // 實例化spark對象用於計算文件hash
let currentChunk = 0
let fileReader = new FileReader()
fileReader.onload = (e) => {
spark.append(e.target.result)
currentChunk = currentChunk + 1
if (currentChunk < chunks.length) {
fileReader.readAsArrayBuffer(chunks[currentChunk])
// 未曾計算完只告知主線程計算進度
self.postMessage({
hashProgress: Math.ceil(currentChunk / chunks.length * 100)
})
} else {
// 計算完了進度和hash結果就都可以告知了
self.postMessage({
hash: spark.end(),
hashProgress: 100
})
self.close();
}
}
fileReader.readAsArrayBuffer(chunks[currentChunk])
}使用的話,直接傳遞分好片文件數組參數即可
const fileMd5 = await calFileMd5ByThreadFn(chunks); // 根據分片計算
console.log('hash',fileMd5) // 得出此大文件的hash值了單純計算加減乘除啥的倒是可以使用vue-worker這個插件,參見筆者之前的文章:https://segmentfault.com/a/1190000043411552
這樣的話,速度就會快一些了...
附錄
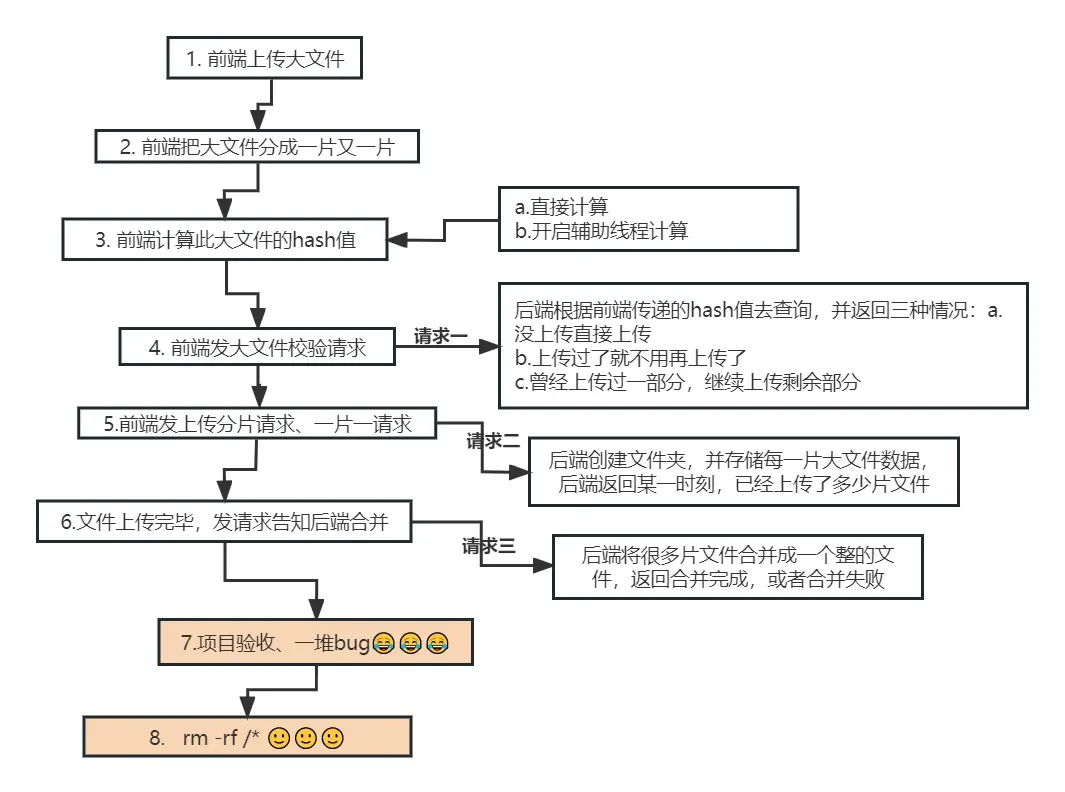
大文件上傳流程圖
- 當我們把上述文章讀完以後,一個大文件上傳的流程圖就清晰的浮現在我們的腦海中了
- 筆者用processOn畫了一個流程圖,如下:
代碼倉庫
代碼倉庫:https://github.com/shuirongshuifu/bigfile
歡迎star,您的認可是咱創作的動力哦
當下後端代碼是java同事濤哥提供的,感謝之。
後續空閒了(star多了),筆者再補充node版本的後端代碼吧
參考資料
- webuploader(百度團隊開源項目):http://fex.baidu.com/webuploader/
- 大文件上傳:https://juejin.cn/post/7177045936298786872
- Buzut:https://github.com/Buzut/huge-uploader
思考
- 到這裏的話,普通公司的大文件上傳需求(一次上傳一個),基本上湊合解決
- 本文的內容也應該基本上能應付面試官了
- 但是如何才能自己做到類似百度網盤那種上傳效果?請研究webuploader源碼
- 道阻且長,還是需要我們持續優化的...