









問題描述
- 兩年前,筆者寫過一篇文章 《面試官桀桀一笑:你沒做過大文件上傳功能?那你回去等通知吧!》
- 當時,後端是用java語言寫的
- 本篇文章,就是講解一下,後端的nodejs如何實現大文件上傳
- 後端使用node的express框架寫
- 完整代碼在github上:https://github.com/shuirongshuifu/bigfile
在看本篇文章之前,建議看一下之前的筆者的大文件上傳文章
思路分析
大文件分片上傳流程圖如下:
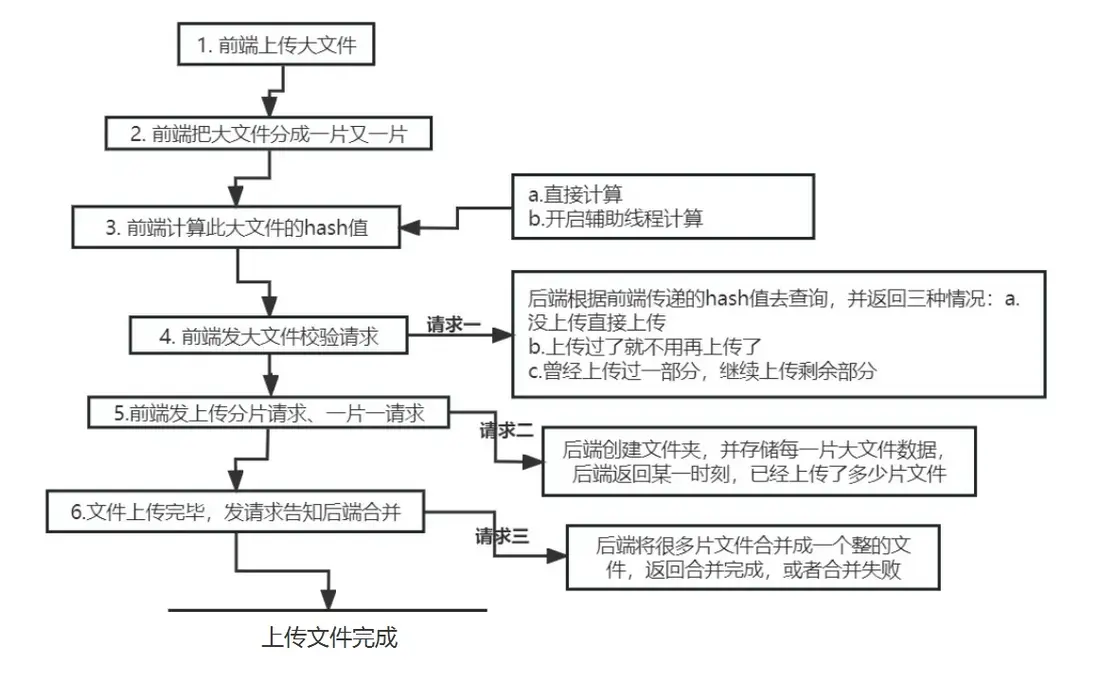
三個接口
- 大文件上傳的接口還是三個接口
-
接口一:檢查文件狀態
- 狀態1 是否完整文件已存在
- 狀態2 是否文件不完整,有碎片文件(上一次沒上傳完)
- 狀態0 文件不存在
-
接口二:分片上傳接口
- 首先,創建分片存儲目錄
- 然後,重命名分片文件(使用索引作為文件名)
- 接着,把上傳的臨時文件移動到分片目錄文件夾裏面(上傳成功了)
- 最後,返回給前端,已經上傳的上傳分片數用於進度計算
-
接口三:把分片文件給合併成一個整個的大文件
- 首先,我們把文件夾中的一堆文件碎片給按照索引排序(要按照索引合併,否則合併好的文件就會損壞)
- 然後,創建合併文件目錄,用於存放即將合併完成的大文件
- 而後,通過管道流的形式,把文件碎片,一個又一個合併
- 最後,告知前端文件合併成功
所用到的包
{
"dependencies": {
"cors": "^2.8.5",
"express": "^5.1.0",
"fs-extra": "^11.3.0",
"multer": "^1.4.5-lts.2",
"path": "^0.12.7"
}
}- cors 用來解決跨域的中間件,方便接口請求看效果
- express node框架,寫起來更快,更方便
- fs-extra 是fs文件系統的升級版,強化版,比如,可以遞歸目錄操作、文件複製或移動等,很強大
- multer 用於處理文件上傳的中間件,很強大
- path 核心模塊,用於處理文件夾和文件的路徑相關的
基本配置
比如,配置存儲合併目錄,用於存放前端上傳的文件以及合併的文件等
const express = require('express');
const multer = require('multer');
const fs = require('fs-extra');
const path = require('path');
const app = express();
const cors = require('cors');
app.use(cors()); // 啓用CORS中間件,允許所有跨域請求
// 配置
const FILE_STORE_PATH = path.join(__dirname, 'uploaded_files'); // 存儲路徑
const mergeDir = path.join(FILE_STORE_PATH, 'merge'); // 合併文件存儲目錄
const upload = multer({ dest: FILE_STORE_PATH }); // multer文件上傳中間件
// 創建必要目錄
fs.ensureDirSync(FILE_STORE_PATH);
fs.ensureDirSync(mergeDir);
// 錯誤響應格式
const errorResponse = (code = -1, message = '失敗') => ({ resultCode: code, message });接口一:檢查文件狀態
// 檢查文件狀態接口
app.post('/bigfile/check', (req, res) => {
const fileMd5 = req.query.fileMd5;
const mergePath = path.join(mergeDir, fileMd5);
const chunkDir = path.join(FILE_STORE_PATH, fileMd5);
try {
// 檢查是否完整文件已存在
if (fs.existsSync(mergePath)) {
return res.json({ resultCode: 1, message: '文件已存在' });
}
// 檢查是否有分片文件
if (fs.existsSync(chunkDir)) {
const chunks = fs.readdirSync(chunkDir);
return res.json({
resultCode: 2,
resultData: chunks.map(c => parseInt(c)) // 返回已經存在的分片索引數組
});
}
// 文件不存在,全新上傳
res.json({ resultCode: 0, resultData: [] });
} catch (error) {
console.error('檢查文件錯誤:', error);
res.status(500).json(errorResponse());
}
});接口二:分片上傳接口
// 分片上傳接口
app.post('/bigfile/upload', upload.single('file'), (req, res) => {
try {
const { chunk, chunks, name, md5 } = req.body;
const chunkIndex = parseInt(chunk);
const chunkDir = path.join(FILE_STORE_PATH, md5);
// 創建分片存儲目錄
fs.ensureDirSync(chunkDir);
// 重命名分片文件(使用索引作為文件名)
const oldPath = req.file.path;
const newPath = path.join(chunkDir, chunkIndex.toString());
fs.renameSync(oldPath, newPath);
// 獲取已上傳分片數量
const uploadedChunks = fs.readdirSync(chunkDir).length;
res.json({
resultCode: 0,
resultData: uploadedChunks // 返回已上傳分片數用於進度計算
});
} catch (error) {
console.error('分片上傳錯誤:', error);
res.status(500).json(errorResponse());
}
});接口三:把分片文件給合併成一個整個的大文件(重點)
// 合併文件接口
app.post('/bigfile/merge', async (req, res) => {
const { fileName, fileMd5 } = req.query;
const chunkDir = path.join(FILE_STORE_PATH, fileMd5);
const mergeFilePath = path.join(mergeDir, fileMd5, fileName);
try {
// 檢查分片目錄是否存在
if (!fs.existsSync(chunkDir)) {
return res.json(errorResponse(1, '分片文件不存在'));
}
// 獲取所有分片文件並按索引排序
const chunkFiles = fs.readdirSync(chunkDir)
.map(f => ({ name: f, index: parseInt(f) }))
.sort((a, b) => a.index - b.index)
.map(f => path.join(chunkDir, f.name));
// 創建合併文件目錄
fs.ensureDirSync(path.dirname(mergeFilePath));
// 創建可寫流
const writeStream = fs.createWriteStream(mergeFilePath);
// 增加監聽器上限(可選,更好的做法是優化流處理)
// writeStream.setMaxListeners(100);
// 使用流管道逐個合併文件
await mergeChunksSequentially(chunkFiles, writeStream);
// // 清理分片文件和目錄
// fs.removeSync(chunkDir);
res.json({ resultCode: 0, message: '文件合併成功' });
} catch (error) {
console.error('合併文件錯誤:', error);
// 清理可能存在的不完整文件
if (fs.existsSync(mergeFilePath)) {
fs.removeSync(mergeFilePath);
}
res.status(500).json(errorResponse());
}
});- 注意,這裏使用管道流,異步,合併分片文件
- 若是考慮性能,可以考慮開一個額外的線程,輔助運算合併文件碎片
- 異步合併如下:
// 順序合併分片文件的輔助函數(避免同時添加過多監聽器)
function mergeChunksSequentially(chunkFiles, writeStream) {
return new Promise((resolve, reject) => {
// 遞歸處理每個分片文件
const processNextChunk = (index) => {
if (index >= chunkFiles.length) {
// 所有分片都已處理完畢
writeStream.end();
return resolve();
}
const chunkPath = chunkFiles[index];
const readStream = fs.createReadStream(chunkPath);
readStream.on('error', (err) => {
reject(err);
});
readStream.on('end', () => {
// 此分片處理完成,繼續下一個
processNextChunk(index + 1);
});
// 管道傳輸數據
readStream.pipe(writeStream, { end: false });
};
// 開始處理第一個分片
processNextChunk(0);
// 監聽寫入完成事件
writeStream.on('finish', resolve);
writeStream.on('error', reject);
});
}至此,搞定,總結:
- 當然了,實際情況,我們的文件存儲都是放在oss上的
- 也就是説,當後端把文件合併完成後
- 還有把文件存儲到oss上這一步,比如存儲到minio、阿里雲、騰訊雲上等
- 這個,根據大家的實際情況後端做處理
- 這種情況是,後端存整個文件,不存文件碎片
- 還有一種方案是,存文件碎片,不存整個文件,數據庫存儲關聯關係
- 當用户訪問請求某個文件的時候,查詢此文件的關聯碎片,並且通過通過數據流的方式,返回給前端
- 但是這種方案後端會稍微麻煩一些,不過這樣就可以不用一下子算出來前端的大文件的hash值以後,再去發請求了
- 從用户的角度而言,這種方式更快一些
- 筆者有一個示例demo,大家可以拉代碼跑起來,看一下效果:https://github.com/shuirongshuifu/response-stream
完整express代碼
const express = require('express');
const multer = require('multer');
const fs = require('fs-extra');
const path = require('path');
const app = express();
const cors = require('cors');
app.use(cors()); // 啓用CORS中間件,允許所有跨域請求
// 配置
const FILE_STORE_PATH = path.join(__dirname, 'uploaded_files'); // 存儲路徑
const mergeDir = path.join(FILE_STORE_PATH, 'merge'); // 合併文件存儲目錄
const upload = multer({ dest: FILE_STORE_PATH }); // multer文件上傳中間件
// 創建必要目錄
fs.ensureDirSync(FILE_STORE_PATH);
fs.ensureDirSync(mergeDir);
// 錯誤響應格式
const errorResponse = (code = -1, message = '失敗') => ({ resultCode: code, message });
// 檢查文件狀態接口
app.post('/bigfile/check', (req, res) => {
const fileMd5 = req.query.fileMd5;
const mergePath = path.join(mergeDir, fileMd5);
const chunkDir = path.join(FILE_STORE_PATH, fileMd5);
try {
// 檢查是否完整文件已存在
if (fs.existsSync(mergePath)) {
return res.json({ resultCode: 1, message: '文件已存在' });
}
// 檢查是否有分片文件
if (fs.existsSync(chunkDir)) {
const chunks = fs.readdirSync(chunkDir);
return res.json({
resultCode: 2,
resultData: chunks.map(c => parseInt(c)) // 返回已經存在的分片索引數組
});
}
// 文件不存在,全新上傳
res.json({ resultCode: 0, resultData: [] });
} catch (error) {
console.error('檢查文件錯誤:', error);
res.status(500).json(errorResponse());
}
});
// 分片上傳接口
app.post('/bigfile/upload', upload.single('file'), (req, res) => {
try {
const { chunk, chunks, name, md5 } = req.body;
const chunkIndex = parseInt(chunk);
const chunkDir = path.join(FILE_STORE_PATH, md5);
// 創建分片存儲目錄
fs.ensureDirSync(chunkDir);
// 重命名分片文件(使用索引作為文件名)
const oldPath = req.file.path;
const newPath = path.join(chunkDir, chunkIndex.toString());
fs.renameSync(oldPath, newPath);
// 獲取已上傳分片數量
const uploadedChunks = fs.readdirSync(chunkDir).length;
res.json({
resultCode: 0,
resultData: uploadedChunks // 返回已上傳分片數用於進度計算
});
} catch (error) {
console.error('分片上傳錯誤:', error);
res.status(500).json(errorResponse());
}
});
// 合併文件接口
app.post('/bigfile/merge', async (req, res) => {
const { fileName, fileMd5 } = req.query;
const chunkDir = path.join(FILE_STORE_PATH, fileMd5);
const mergeFilePath = path.join(mergeDir, fileMd5, fileName);
try {
// 檢查分片目錄是否存在
if (!fs.existsSync(chunkDir)) {
return res.json(errorResponse(1, '分片文件不存在'));
}
// 獲取所有分片文件並按索引排序
const chunkFiles = fs.readdirSync(chunkDir)
.map(f => ({ name: f, index: parseInt(f) }))
.sort((a, b) => a.index - b.index)
.map(f => path.join(chunkDir, f.name));
// 創建合併文件目錄
fs.ensureDirSync(path.dirname(mergeFilePath));
// 創建可寫流
const writeStream = fs.createWriteStream(mergeFilePath);
// 增加監聽器上限(可選,更好的做法是優化流處理)
// writeStream.setMaxListeners(100);
// 使用流管道逐個合併文件
await mergeChunksSequentially(chunkFiles, writeStream);
// // 清理分片文件和目錄
// fs.removeSync(chunkDir);
res.json({ resultCode: 0, message: '文件合併成功' });
} catch (error) {
console.error('合併文件錯誤:', error);
// 清理可能存在的不完整文件
if (fs.existsSync(mergeFilePath)) {
fs.removeSync(mergeFilePath);
}
res.status(500).json(errorResponse());
}
});
// 順序合併分片文件的輔助函數(避免同時添加過多監聽器)
function mergeChunksSequentially(chunkFiles, writeStream) {
return new Promise((resolve, reject) => {
// 遞歸處理每個分片文件
const processNextChunk = (index) => {
if (index >= chunkFiles.length) {
// 所有分片都已處理完畢
writeStream.end();
return resolve();
}
const chunkPath = chunkFiles[index];
const readStream = fs.createReadStream(chunkPath);
readStream.on('error', (err) => {
reject(err);
});
readStream.on('end', () => {
// 此分片處理完成,繼續下一個
processNextChunk(index + 1);
});
// 管道傳輸數據
readStream.pipe(writeStream, { end: false });
};
// 開始處理第一個分片
processNextChunk(0);
// 監聽寫入完成事件
writeStream.on('finish', resolve);
writeStream.on('error', reject);
});
}
// 啓動服務
const PORT = 8686;
app.listen(PORT, () => {
console.log(`服務器運行在 http://localhost:${PORT}`);
});A good memory is better than a bad pen. Record it down...












