

關於 C++ 的編譯和鏈接, 掌握的知識總是零零散散,這裏做個輸出,也總結一下自己的思考和學習。
1. 常見編譯器
對於最常見的 GCC:
- GCC:GNU Compiler Collection(GNU 編譯器集合)的縮寫,可以理解為一組 GNU 操作系統中的編譯器集合,可以用於編譯 C、C++、Java、Go、Fortran、Pascal、Objective-C 等語言。
- gcc:GCC(編譯器集合)中的 GNU C Compiler(C編譯器)
- g++:GCC(編譯器集合)中的 GNU C++ Compiler (C++編譯器)
簡單來説,gcc 調用了 GCC 中的 C Compiler,而 g++ 調用了 GCC 中的 C++ Compiler,對於 .c 和 .cpp 文件,gcc 分別當作 C 和 CPP 文件編譯,而 g++ 則統一當作 CPP 文件編譯。實際上 gcc/g++ 命令是相應後台程序的包裝(例如 C 的預編譯和編譯程序都是 cc1,C++ 則是 cc1plus),它會根據不同的參數要求去調用預編譯,比如編譯 cc1、彙編器 as、鏈接器 ld 等。
另外,在 Windows 系統中常見的是:
- MSVS:微軟的 Microsoft Visual C++ 帶的編譯器,Visual Studio 自帶,編譯 cl.exe、鏈接器 link.exe、目標文件查看工具 dumpbin 等用的就是它的工具鏈;
- MinGW:Minimalist GNU for Windows 是 GCC 編譯器移植到 Windows 下的編譯器,安裝後在 Win 環境下使用的 gcc、g++、gdb、objdump、nm 命令是它的工具鏈;
其他的可以參考 <一文搞懂C/C++常用編譯器>
後文案例主要是在 Linux (Windows 下的 WSL)下用 gcc/g++ 執行的。
2. 構建步驟
從源文件到可運行文件,需要經歷多個步驟:
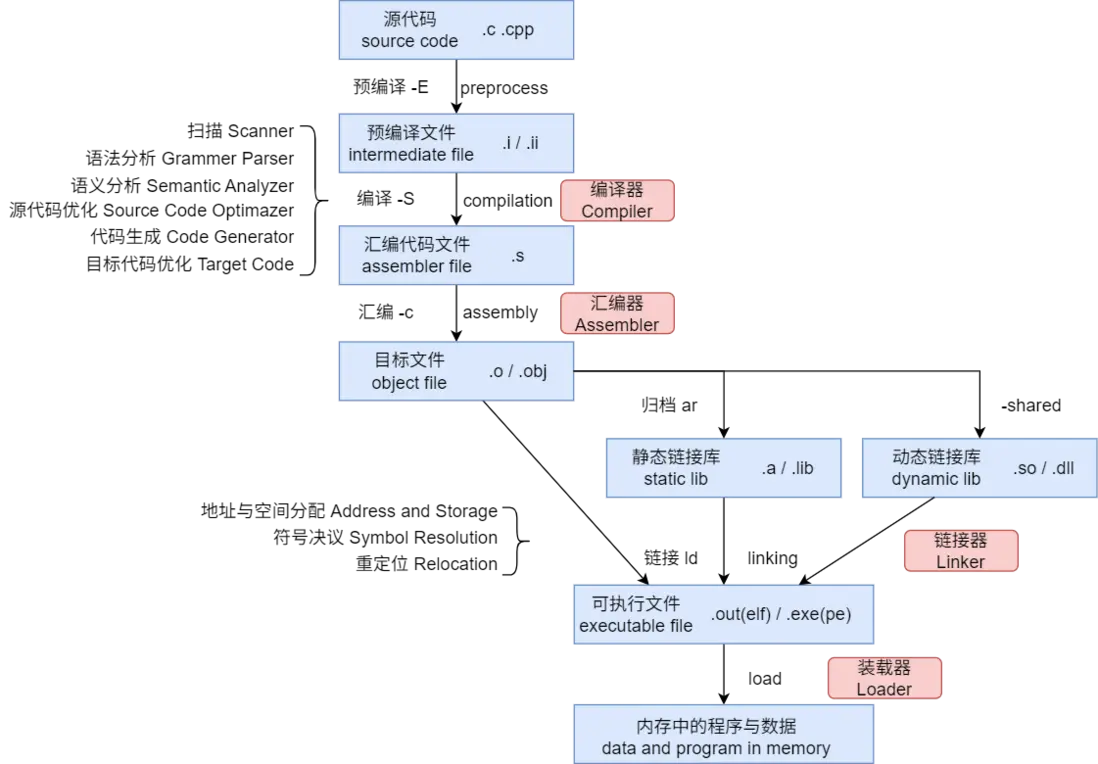
2.1 預編譯 Preprocess
預編譯過程主要處理源文件中的以 # 開始的預編譯指令和註釋:
- 將所有的
#define刪除,並展開所有的宏定義; - 處理所有條件預編譯指令,比如
#if、#ifdef、#elif、#else、#endif; - 處理
#include預編譯指令,將被包含的文件插入(直接複製)到該預編譯指令的位置。注意,這個過程是遞歸進行的,也就是説被包含的文件可能還包含其他文件; - 刪除所有註釋
//和/**/; - 添加行號和文件名標識,比如
#2 "helo.c" 2,以便於編譯時編譯器產生調試用的行號信息及用於編譯時產生編譯錯誤或警告時能夠顯示行號; - 保留所有的
#pragma編譯器指令,因為編譯器需要使用;
我們用兩個示例文件如下,其中有本地符號,也引用了外部符號:
// hello.cpp 文件,其中有本地符號,也有引用了外部的符號,外部符號放在 a.cpp 中定義了
int g_init_var = 1;
extern int g_ref_var; // 外部分超
int func1(int i) { return i; }
int func2(int& i); // 外部符號
int main(void) {
static int static_var = 2;
static int static_var2;
int a = 3;
int b;
b = func1(g_init_var + static_var + static_var2 + g_ref_var + a);
func2(b);
return b;
}
// a.cpp,其中對應了hello.cpp中引用的外部符號
int g_ref_var = 4;
void func2(int& i) { i += 1; }然後預編譯:
gcc -E hello.cpp -o hello.ii這裏 -E 表示只進行預編譯,生成的 .ii 預編譯文件打開是這樣的,註釋被移除了:
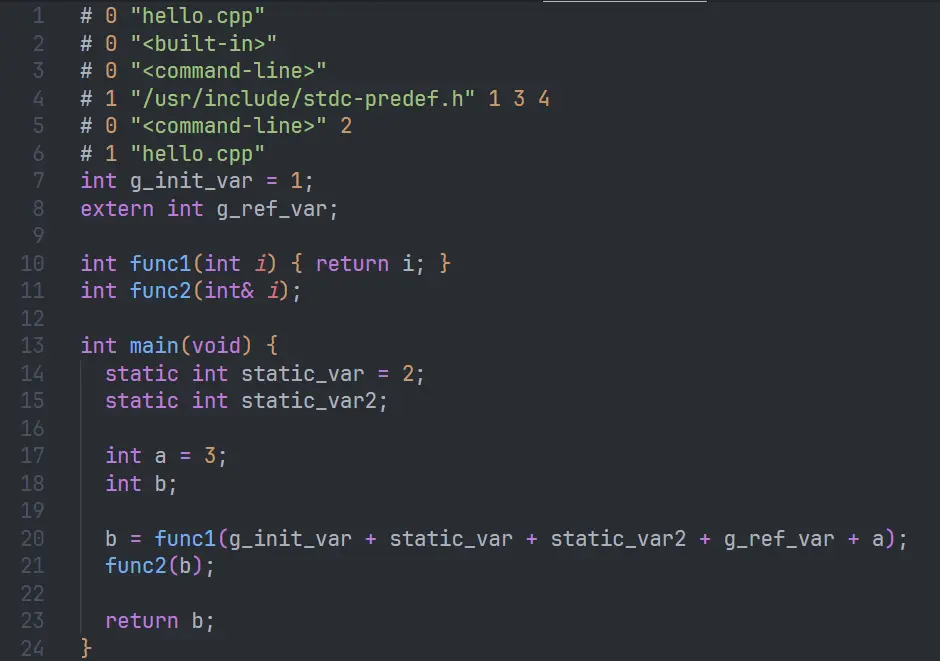
如果引入 iostream 之類的系統頭文件,就會發現文件開頭會多出幾萬行,都是遞歸引入的 iostream 頭信息。
2.2 編譯 Compilation
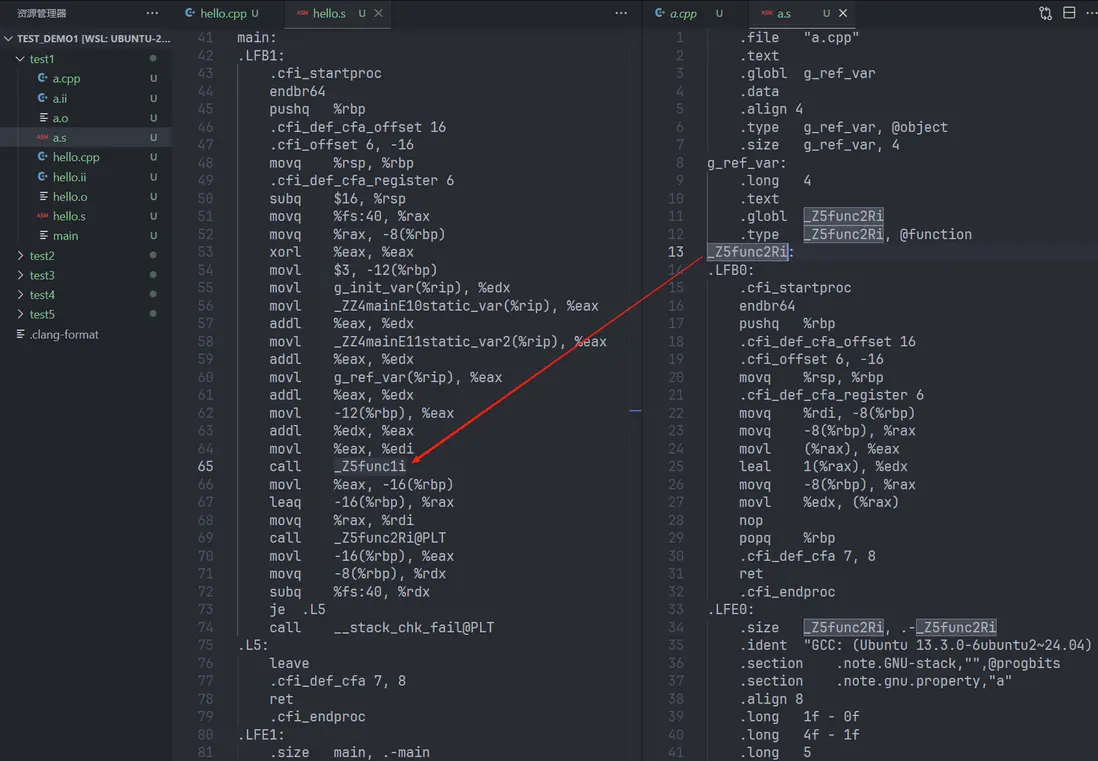
編譯就是把預處理完的文件進行一系列詞法分析、語法分析、語義分析及優化後,產生相應的彙編代碼 Assembly Code:
gcc -S hello.ii -o hello.s編譯 .ii 文件生成了彙編代碼文件 .s,可以打開看一下,裏面都是彙編指令,另外如果留意一下,可以發現一些符號決議的端倪:
編譯過程分為多個步驟:
- 詞法分析,經過掃描器 Scanner 對詞法進行分析,將源碼的字符分割為一系列記號;
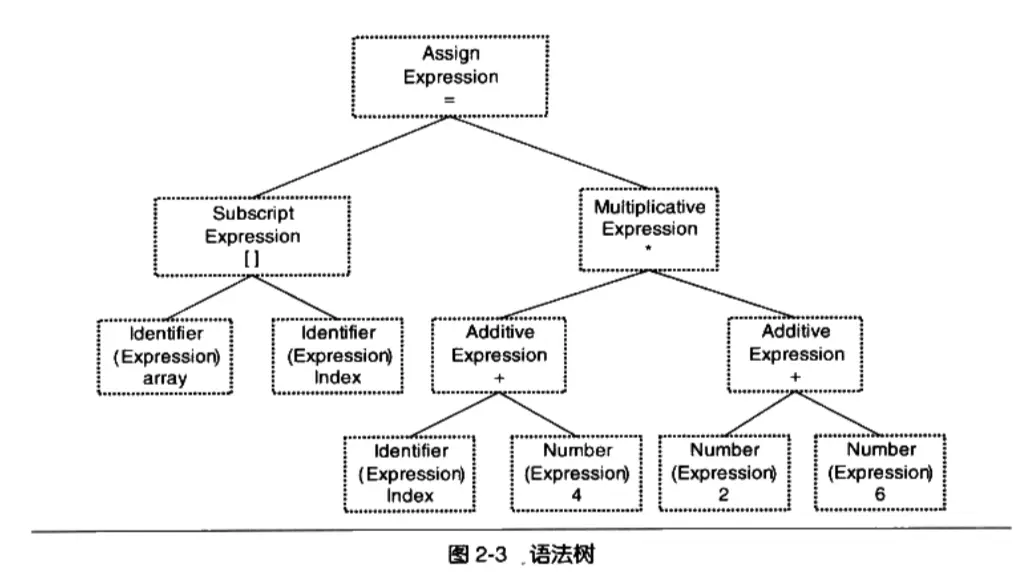
- 語法分析,經過語法分析器 Grammar Parser 將掃描器產生的記號進行語法分析,產生語法樹 Syntax Tree;
比如一個賦值語句可以分解為下面的語法樹:
- 語義分析,經過語義分析器 Semantic Analyzer 分析產生的語法樹,語法分析僅僅是完成了對錶達式的語法層面的分析,但是它並不瞭解這個語句是否真正有意義,比如將浮點型賦值給一個指針將會產生一個靜態語義 Static Semantic 的錯誤,而動態語義 Dynamic Semantic 需要在運行時才會確定,比如將 0 作為除數。經過語義分析後,語法樹的表達式(含符號和數字)都被標識了類型,如果有些類型需要做隱式轉換,語義分析程序會在語法樹中插入相應的轉換節點。另外,語義分析對符號表裏的符號類型也做了更新;
- 源代碼優化,經過源代碼級優化器 Source Code Optimizer 進行源代碼級別的優化,比如
(2+6)這樣的表達式就可以被優化掉,因為它的值在編譯期就可以被確定。經過優化後將語法樹轉換成機器無關的中間代碼; - 代碼生成與優化,經過代碼生成器 Code Generator 將中間代碼轉換為目標機器代碼。因為不同機器具有不同的字長、寄存器、整數數據類型和浮點數據類型等,代碼優化器 Target Code Optimizer 會將目標機器代碼進行優化,比如選擇合適的尋址方式、使用位移來代替乘法運算、刪除多餘的指令等;
經過這些步驟,將預編譯文件生成了特定目標機器上的彙編代碼,目標機器取決於 CPU 架構、操作系統等,比如 x86、ARM、RISC-V 架構的 CPU 使用的指令集也不同,Win、Linux、MacOS 操作系統上的系統調用機制不同,相互之間的彙編代碼也不能相互通用,比如 x86 的 CPU 上如果要生成 ARM 機器能理解的彙編語言,就需要使用交叉編譯器,或者在虛擬機環境下進行編譯。
舉個例子,比如在 x86 的 64 位 Ubuntu 上編譯的 hello.o 目標文件:
- 在 ARM Android 手機設備上無法運行,因為指令集不兼容;
- 複製到 Windows 設備上無法運行,因為文件格式不識別;
- 複製到 x86 的 32 位系統上無法運行,因為 64 位指令不兼容;
2.3 彙編 Assembly
彙編是彙編器根據彙編指令和機器指令的對照表,將編譯階段得到的 .s 彙編文件翻譯成二進制機器指令 Machine Code。每條彙編語句對應一條或幾條機器指令,不僅如此,還要經過符號處理(彙編語句會引用外部符號)、段組織等步驟,最終生成 .o 目標文件:
# 等價於 as hello.s -o hello.o,gcc -c是調用的as命令
gcc -c hello.s -o hello.o由於此時彙編代碼翻譯成的機器碼會引用外部符號,而彙編器並不知道這些外部符號的具體地址,所以彙編器會將這些外部符號的地址暫時填 0(佔位符機器碼)。在鏈接的時候,這些外部符號的地址在符號決議環節才會被替換為真正的符號地址。
對於目標文件,會在下面單獨進行解釋。
2.4 鏈接 Linking
鏈接是編譯的最後一步,會將前面編譯好的目標文件、系統庫、第三方庫的 .o/.a/.so 文件連接起來,把各個模塊之間相互引用的符號處理好,使得各個模塊之間能夠正確地銜接,最後組成一個可執行文件 Executable File。
# 將兩個目標文件鏈接生成可執行文件
gcc hello.o a.o -o main前面的預編譯、編譯、彙編可以用一個 -c 命令直接完成,也可直接把源碼給到 gcc 命令,直接完成鏈接並生成可執行文件:
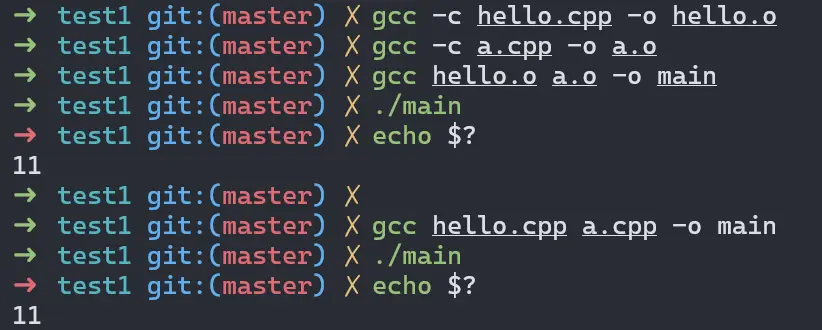
鏈接中,目標文件之間相互的拼合實際上是目標文件之間對地址的引用,即對函數和變量的地址的引用。每個函數或變量都有自己獨特的名字,才能避免鏈接過程中不同變量和函數之間的混淆。函數和變量統稱為符號 Symbol,函數名或變量名就是符號名 Symbol Name。
鏈接過程中很關鍵的一部分就是符號的管理,每一個目標文件都會有一個相應的符號表 Symbol Table,這個表裏面記錄了目標文件中所用到的所有符號。每個定義的符號都有個對應的值,叫做符號值 Symbol Value,對於變量和函數來説,符號值就是它們的地址。
鏈接分為好幾個階段:
- 地址和空間分配 Address and Storage Allocation,為最終輸出文件(可執行文件或共享庫)中的各個段分配運行時內存地址(虛擬地址)和確定它們在文件中的佈局(大小和偏移量),同類型的段(比如代碼段)會被分配在一起,即相似段合併。
- 符號決議 Symbol Resolution,檢查所有輸入目標文件的符號表,將導入符號和導出符號進行決議(或者説地址綁定),確定所有符號的引用關係,確保每個符號引用都能找到唯一且匹配的定義,最終生成一個符號表 Symbol Table,其中所有符號引用都已綁定到具體的定義地址(此時地址可能是臨時的或基於段的偏移量)。
- 重定位 Relocation,根據前兩個階段的結果(段的最終地址和符號的最終地址),修改代碼和數據中的具體地址引用(地址常量、函數調用目標地址、全局變量地址),將其替換為真正的相對偏移或者絕對地址;
這三個階段環環相扣,使得編譯器生成的、各自獨立的目標文件能夠正確地合併為一個可執行文件 .out 或動態鏈接庫 .so。
順便提一句,某種程度上動態鏈接庫和可執行文件內部結構是一樣的都是 ELF 格式,有的工具可以讓動態鏈接庫作為程序運行。
3. 目標文件 .o / .obj
一個源文件對應編譯生成一個可重定位目標文件 .o / .obj,其中包含對其他文件或庫中定義的符號 symbol(如函數、變量)的引用,此時符號引用還未決議和重定位,只是一個待填的空,這裏可以看看目標文件裏的結構和其中的符號表。
3.1 目標文件結構
此時生成的目標文件,可以使用 objdump -h 查看其中的段(Windows 上可以用 MSVC 的 dumpbin /headers 查看):
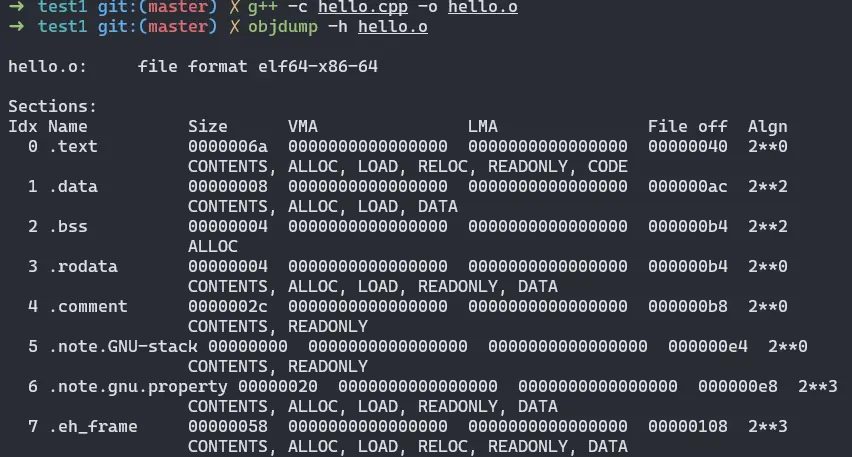
從上述的結果我們可以看出 hello.o 一共有 8 個段,分別是:
.text代碼段 Code Section,源碼編譯後的機器指令通常被放在代碼段;.data數據段 Data Section,已經初始化的全局變量和局部靜態變量數據通常放在數據段;.bss未初始化數據段 BSS,未初始化全局變量、局部靜態變量通常放在未初始化數據段,只申請內存而不佔據文件內容;.rodata只讀數據段,一般是程序裏面的只讀變量(如 const 修飾的變量)和字符串常量;.comment、.note.GNU-stack、.note.gnu.property、.eh_frame為編譯器信息段、堆棧提示段、編譯信息段、異常處理段,是一些編譯輔助信息和錯誤處理相關邏輯;.symtab靜態符號表,包含所有符號(全局、局部、未定義等)。
在每個段的下面都有一行信息,是該段屬性的描述,含義如下:
CONTENTS佔據文件內容,除了未初始化數據段,其他都會佔據文件內容;ALLOC運行時申請內存,除了編譯信息和異常處理段之類的輔助信息的段,其他都會申請內存;LOAD可作為裝載數據使用;RELOC加載時可重定位;READONLY內容只讀,除了數據段和未初始化數據段,都會包含這個屬性;CODE內容為機器碼,比如代碼段就會包含這個屬性;DATA可讀寫程序數據;
可以發現未初始化數據段 .bss 是隻申請內存而不佔據文件內容的,因為 .bss 是未初始化的全局變量和局部靜態變量的預留位置,需要在進程創建的時候申請對應內存空間,在目標文件中不佔用位置。
另外,圖中的 VMA 虛擬地址和 LMA 加載地址都為 0(0x0000000000000000),這是因為此時還沒有進行重定位,需要在鏈接為動態庫或可執行文件後才會有值,可以從下面動態鏈接庫的圖中看到 VMA 和 LMA 已經有值了。
3.2 符號表
注意到上圖 objdump -h 結果裏沒有展示符號表,並不是 .o 文件沒有符號表,而是因為 .symtab 是調試節所以 objdump -h 默認沒有展示,用 readelf -S 就可以看到 .symtab 靜態符號表:
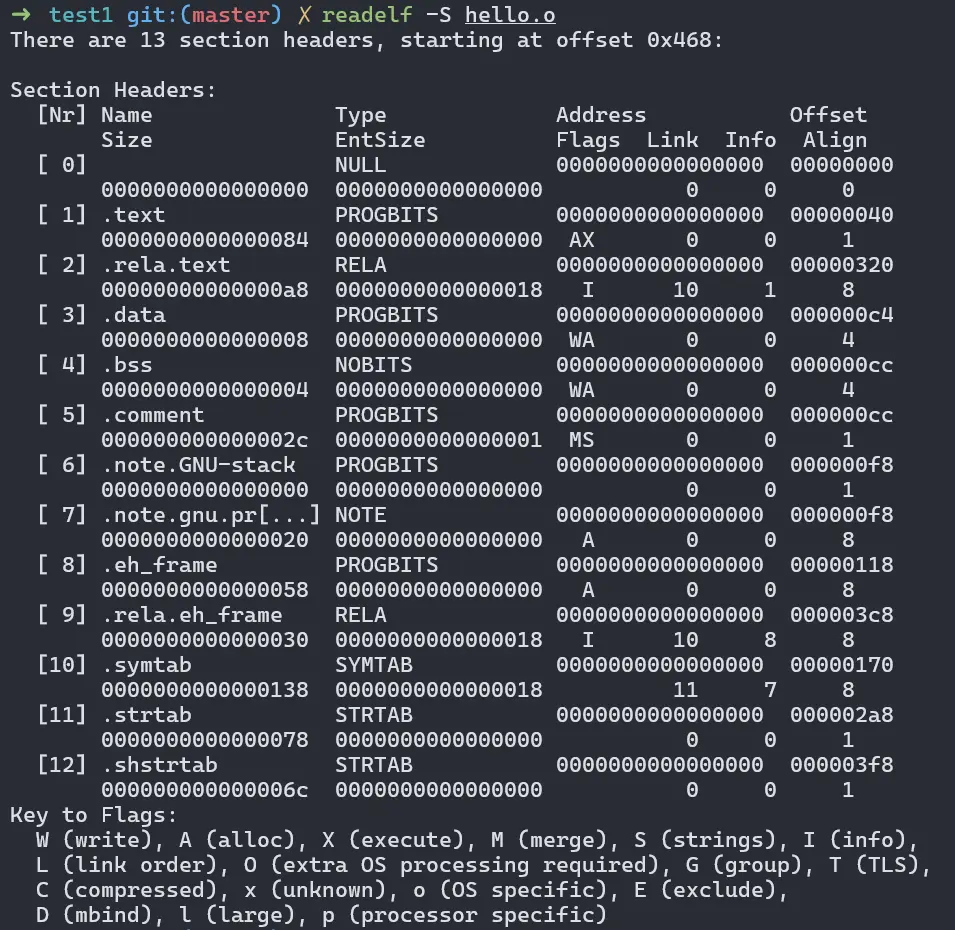
順便説一句,.strtab 字符串表 String Table 用來保存普通字符串。
可以用 objdump -t、nm、readelf -s 命令專門查看目標文件中的符號表:
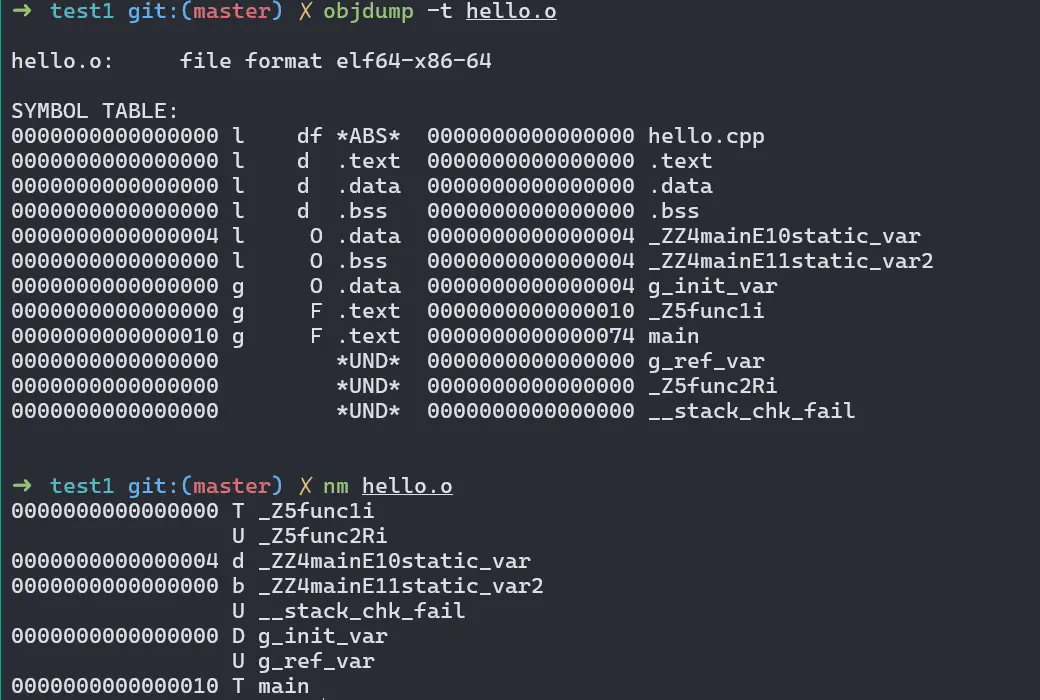
先看看 objdump -t 的返回值:
- 第 1 列為符號在目標文件中的偏移地址,可以看到只有在代碼段的已初始化靜態變量和代碼段有地址;
- 第 2 列為符號的綁定類型,
l表示本地符號 local,只有目標文件內部可見,g表示全局符號 global(如func1、main、g_init_var,Linux 上符號默認對外可見,需要手動在編譯時用-fvisibility=hidden或用__attribute__((visibility("hidden")))將符號設為外部不可見,在 Win 上符號默認對外不可見,需要用__declspec(dllexport)主動將符號標註為外部可見),設為外部不可見之後, objdump -t 或 nm 就找不到這個符號了。 - 第 3 列為符號類型,
F函數,O對象,d節,df文件名。 - 第 4 列為符號所在節,特別要注意的是
*UND*表示未定義符號 undefined,表示外部符號引用(如func2和g_ref_var),這些符號需要在後續的鏈接階段進行符號決議,否則就會看到熟悉的無法解析的外部符號 undefined reference to xxx報錯了,因為鏈接器找不到對應符號。*ABS*表示絕對符號 absolute,比如文件名。 - 第 5 列為佔用大小,以字節為單位,可以看到雖然
.bss節中未初始化靜態變量段雖然沒有地址,但也會佔用大小,後續進程運行時會被初始化為 0 並佔用此處記錄的大小的內存空間。 -
第 6 列為符號名,注意:
- 這裏
.bss段的靜態變量為了避免與其他局部變量發生命名衝突,也經過了名稱修飾 Name Mangling; - 對於 C++ 中的函數,為了支持 C++ 的函數重載,也會進行名稱修飾,修飾的規則每個編譯器不一樣,各自有各自的一套規則,一般來説會帶上返回值和參數類型,這也是為什麼 C++ 調用 C 庫中的符號需要
extern "C"的原因; __stack_chk_fail是一個編譯器插入的用來檢測棧溢出等安全問題的棧保護符號;
- 這裏
對於 nm 的返回值:
- 第 1、3 列是偏移地址,和之前一樣;
-
第 2 列是符號類型,可以與 objdump -t 返回值中的屬性一一對應:
T表示全局函數,同前面gF屬性位於.text段的符號。D表示全局已初始化數據,同前面.data段gO屬性的符號。d:已初始化局部靜態數據,同前面.data段lO屬性的符號。b:未初始化數據,同位於.bss段的符號。U:未定義符號,同之前的*UND*。
3.3 重定位表
鏈接器是通過重定位表 Relocation Table 知道哪些指令需要被調整,以及這些指令如何調整。
前面 readelf -S 結果中的 .rela.text 就是重定位表,它包含了代碼段的重定位條目,記錄需要調整的外部符號引用,比如 hello.cpp 中調用的 func2,在編譯時其實是不知道具體地址的,此時在這個重定位表中就會記下這個符號和其所在的相對偏移,後續在鏈接的重定位階段才會知道 func2 的真正地址,再根據重定位表找到之前的符號並回填為真正地址。
對於每個需要重定位的代碼段或數據段,都會有一個相應的重定位表,.rela.text 就是針對 .text 段的重定位表。所以有的目標文件會有 .rela.data 就是針對數據段的重定位表。
用 objdump -r 可以查看目標文件的重定位表:
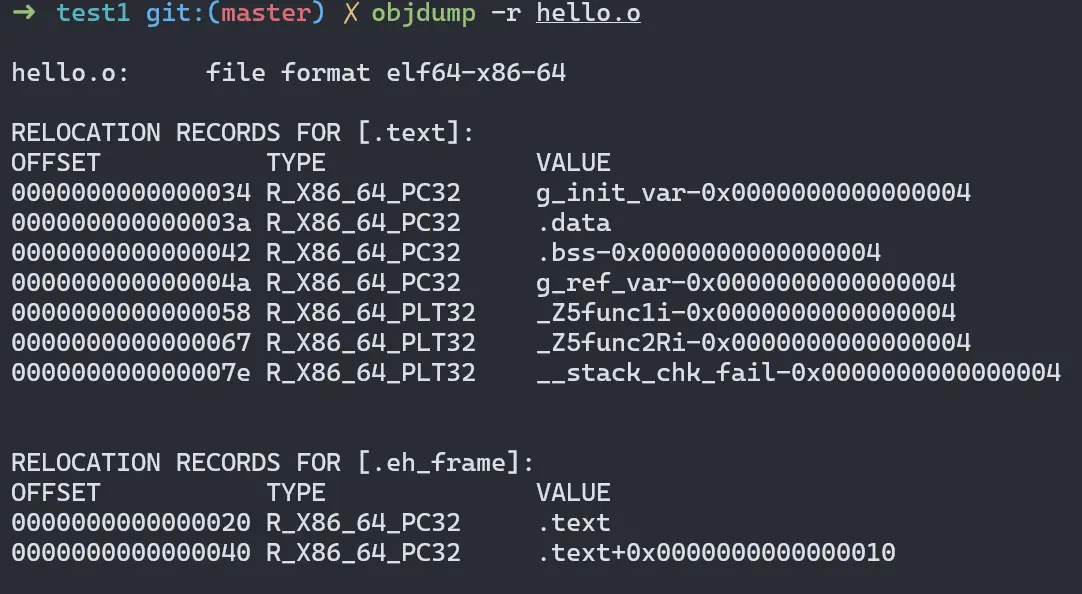
其中的 OFFSET 表示該入口在要被重定位的段中的位置;
3.4 強符號、弱符號
編譯器默認函數和初始化了的全局變量為強符號 Strong Symbol,未初始化的全局變量為弱符號 Weak Symbol。也可以通過 GCC 的 __attribute__((weak)) 來定義任何一個強符號為弱符號。
注意,強符號和弱符號都是針對定義來説的,不是針對符號的引用
extern int ext; // 既非強符號也非弱符號,是一個外部變量的引用
int weak; // 弱符號
int strong = 1; // 強符號
__attribute__((weak)) weak2=2; // 弱符號
void func() { } // 強符號,函數實現針對強弱符號的概念,鏈接器按如下規則處理與選擇被多次定義的全局符號
- 規則1: 不允許強符號被多次定義(即不同的目標文件中不能有同名的強符號),如果有多個強符號定義,則鏈接器報符號重複定義錯誤
multiple definition; - 規則2: 如果一個符號在某個目標文件中是強符號,在其他文件中都是弱符號,那麼選擇強符號;
- 規則3: 如果一個符號在所有目標文件中都是弱符號,那麼選擇其中佔用空間最大的一個。
4. 靜態鏈接庫 .a / .lib
靜態鏈接庫可以認為是多個目標文件的集合或者説容器,這樣就不需要在每次鏈接目標文件的時候敲寫很多文件名,方便管理,靜態鏈接庫雖然稱為庫,不如説是一個壓縮包,只是把目標文件拼在一起。
# 把兩個目標文件打包成 .a 靜態庫
ar rcs libexample.a file1.o file2.o
然後甚至可以用 ar x 將靜態庫解壓縮還原成兩個 .o 目標文件,然後如果再有一個 file3.o,可以用 ar -q 往靜態鏈接庫裏塞一個新的 .o:
# 把 .a 靜態庫解開,此時目錄下會多出兩個.o文件
ar x libexample.a
# 添加一個新的目標文件到 .a 中
ar -q libexample.a file3.o
# 將靜態庫裏一個目標文件移除
ar -q libexample.a file1.o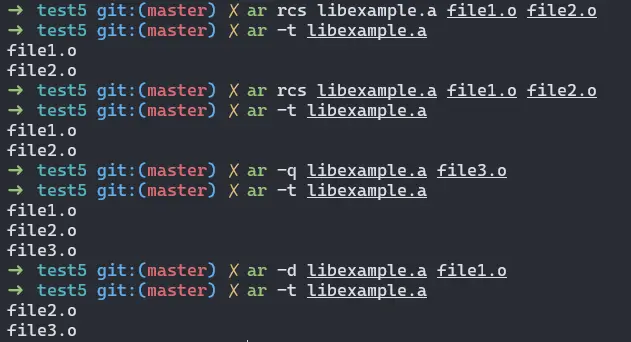
ar 命令是 archive 的縮寫,是歸檔的意思,已經暗示了靜態庫其實是歸檔的含義,只是目標文件的簡單歸檔,沒有做符號決議和重定位等操作,段信息也沒有合併。鏈接器在鏈接靜態鏈接庫的時候,會去庫裏找需要的符號所在的目標文件並解壓出來進行鏈接,也就是説只會提取需要的目標文件出來鏈接。
所以説,靜態鏈接庫只是目標文件的簡單集合,或者説歸檔的容器。
靜態庫的缺點:
- 鏈接器在鏈接靜態庫或者目標文件時是以文件為單位的。若該目標文件中還有其他我們並沒有用到的函數,也會一起被鏈接進可執行文件,造成空間浪費。
- 若多個可執行文件都有依賴同一份目標文件,則該目標文件會被合併到每個可執行文件中,即在每個可執行文件中都會存在一個副本,也會造成空間浪費。
- 如果一個可執行文件依賴的底層靜態庫有一個改動,則靜態庫和可執行文件都需要重新編譯,再部署到設備或發佈給用户,即全量更新。因為經過鏈接階段的地址和空間分配,靜態庫中的相關目標文件部分會嵌入到可執行文件中,所以全量更新是必須的。
為了解決這些問題,後來人們發明了動態鏈接和動態庫。
5. 動態鏈接庫 .so / .dll
通過下面的命令生成動態庫:
gcc -fPIC -shared hello.cpp a.cpp -o hello.so-fPIC 表示位置無關 Position-Independent Code,其中的代碼段可加載到內存的任意地址(加個偏移基址即可),而無需修改指令內容。位置無關使得動態庫非常適合在多進程環境中使用。多個進程引用同一個動態庫時,操作系統只需將庫的代碼段加載到內存一次,所有進程共享動態庫的代碼段,而數據段(.data 和 .bss)則為每個進程分配獨立的內存空間,確保數據隔離。
在動態鏈接庫的構建過程中,內部符號已在鏈接階段完成解析。例如,hello.so 中的代碼段、已初始化數據段和 未初始化數據段的內部符號引用已確定相對偏移地址,形成固定的內存佈局。
對於外部符號,比如一些依賴於其他庫或者標準庫函數的符號的解析被推遲到運行時,稱之為延遲綁定機制 Lazy Binding,由動態鏈接器 ld.so 在程序加載時完成,所以在動態庫源碼修改時,只要導出符號不變,只需重新編譯動態庫即可,可執行文件不需要重新編譯,只需要重啓進程,即增量更新。
可以查看一下動態庫的段信息:
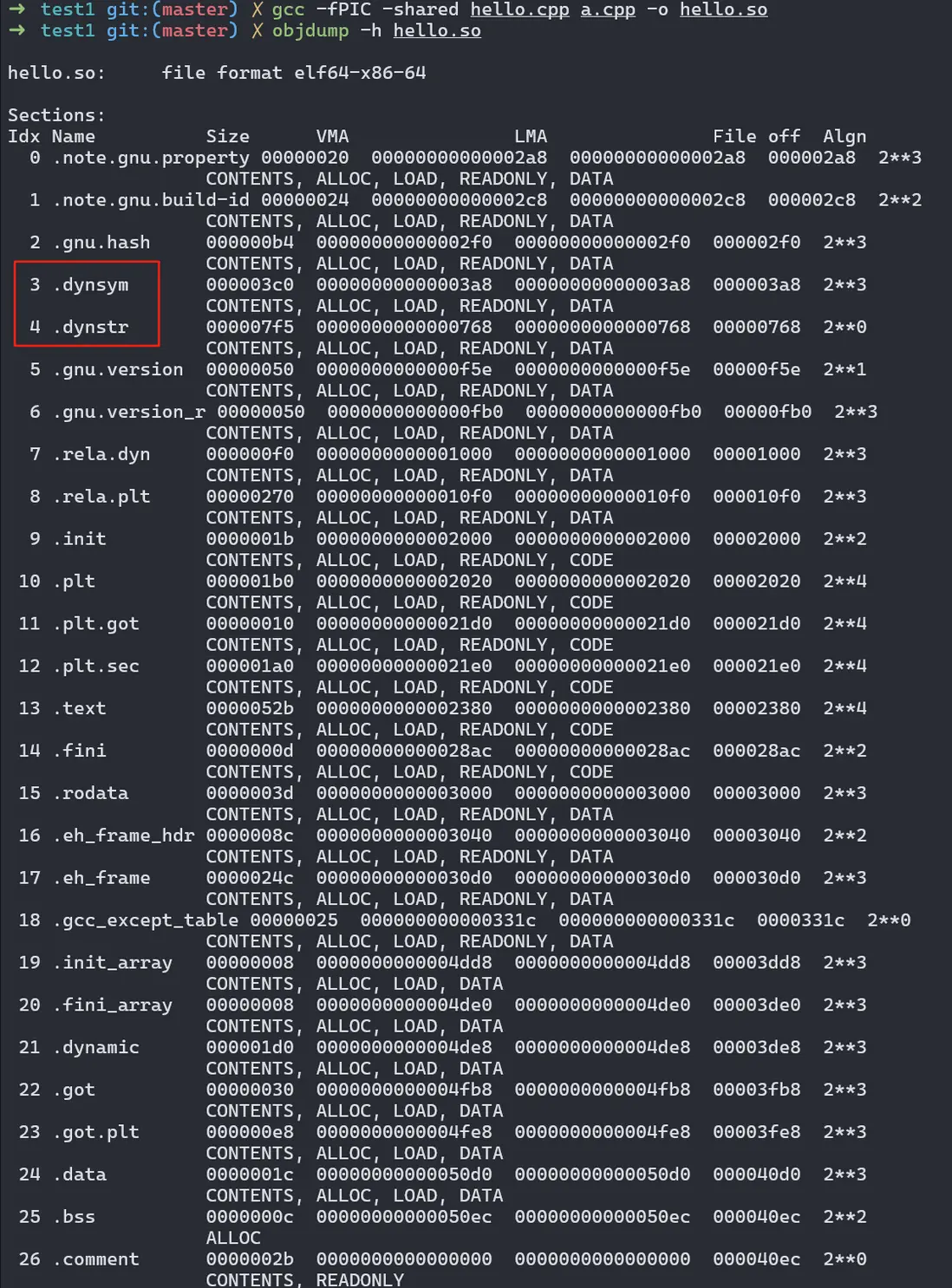
動態鏈接庫通常包含一個動態符號表 .dynsym,記錄了動態鏈接所需的導出符號和導入符號。動態字符串表 .dynstr 會存儲這些符號的名稱。這些表為動態鏈接器提供了必要的信息,以便在運行時完成符號決議和重定位。
表中還有一些帶有 got、plt 關鍵字的表,是提供符號重定位和延遲綁定相關信息的表。
另外,經過鏈接,得到的可執行文件或共享庫已經被重定位過了,不再需要重定位表,因此 .rela.text、.rela.data 沒有了;同時,VMA 和 LMA 已經被具體賦值,不再是 0。
5.1 動態庫鏈接方式
顯式運行時鏈接 Explicit run-time Linking
在代碼中通過 dlopen、dlfree 的方式加載、釋放動態鏈接庫,在 Win 上使用 LoadLibrary、FreeLibrary ,這種使用代碼顯式加載動態庫的方式稱為顯式運行時鏈接 Explicit run-time Linking,這種方式比較靈活,可以在代碼中精準地控制加載和卸載動態庫的所有細節。
優勢是程序在編譯鏈接時完全不需要動態庫的參與,程序在運行時可以根據需要有選擇性地進行加載或卸載動態庫,即使在運行時對某個動態庫的加載失敗也不會導致程序中止。
隱式載入時鏈接 Implicit load-time Linking
隱式加載 Implicit load-time Linking 是最常用的方式,通的 C++ 標準庫等系統中的庫都是採用隱式加載的,程序在編譯時需要添加 -l 選項鍊接到動態庫。在程序啓用時,系統會自動查找並加載對應的動態庫。
隱式加載的優勢是代碼簡單,不需要在代碼中處理加載動態庫的各種細節。但缺點是要求在編譯時動態庫也要參與鏈接,在編譯時和運行時都需要保證動態庫是可以找到並且使用的,編譯時無法找到則編譯失敗,運行時無法找到和使用則程序無法啓動。
網上的帖子大多深淺不一,甚至有些前後矛盾,在下的文章都是學習過程中的總結,如果發現錯誤,歡迎留言指出,如果本文幫助到了你,別忘了點贊支持一下,你的點贊是我更新的最大動力!~
參考文檔:
- 一文搞懂C/C++常用編譯器
- 程序員的自我修養
- 計算機體系結構
- 動態鏈接庫與靜態鏈接庫有什麼區別
PS:本文同步更新於在下的博客 Github - SHERlocked93/blog 系列文章中,共同進步,一起加油~

