

利用萊布尼茨公式(Leibniz formula)計算圓周率 $\pi$。儘管在現代數學計算庫中,萊布尼茨級數因其收斂速度極慢而鮮被用於實際精算 Π 值,但其算法結構——高密度的浮點運算、緊湊的循環邏輯以及對算術邏輯單元(ALU)的持續壓力——使其成為測試 CPU 單核吞吐量、浮點運算單元(FPU)效率以及編譯器自動向量化(Auto-vectorization)能力的絕佳“試金石” 。
GitHub 開源項目 niklas-heer/speed-comparison 在 2025 年 12 月產生的最新數據,涵蓋了從底層系統級語言(如 C++、Rust)到託管型語言(如 Java、C#),再到動態解釋型語言(如 Python、Ruby)的 62 種不同實現。通過對 10 億次迭代運算的詳盡分析,我們不僅試圖排列出“誰最快”,更致力於揭示“為什麼快”背後的深層技術邏輯,探討單指令多數據(SIMD)技術、即時編譯(JIT)機制以及內存模型對計算性能的決定性影響。
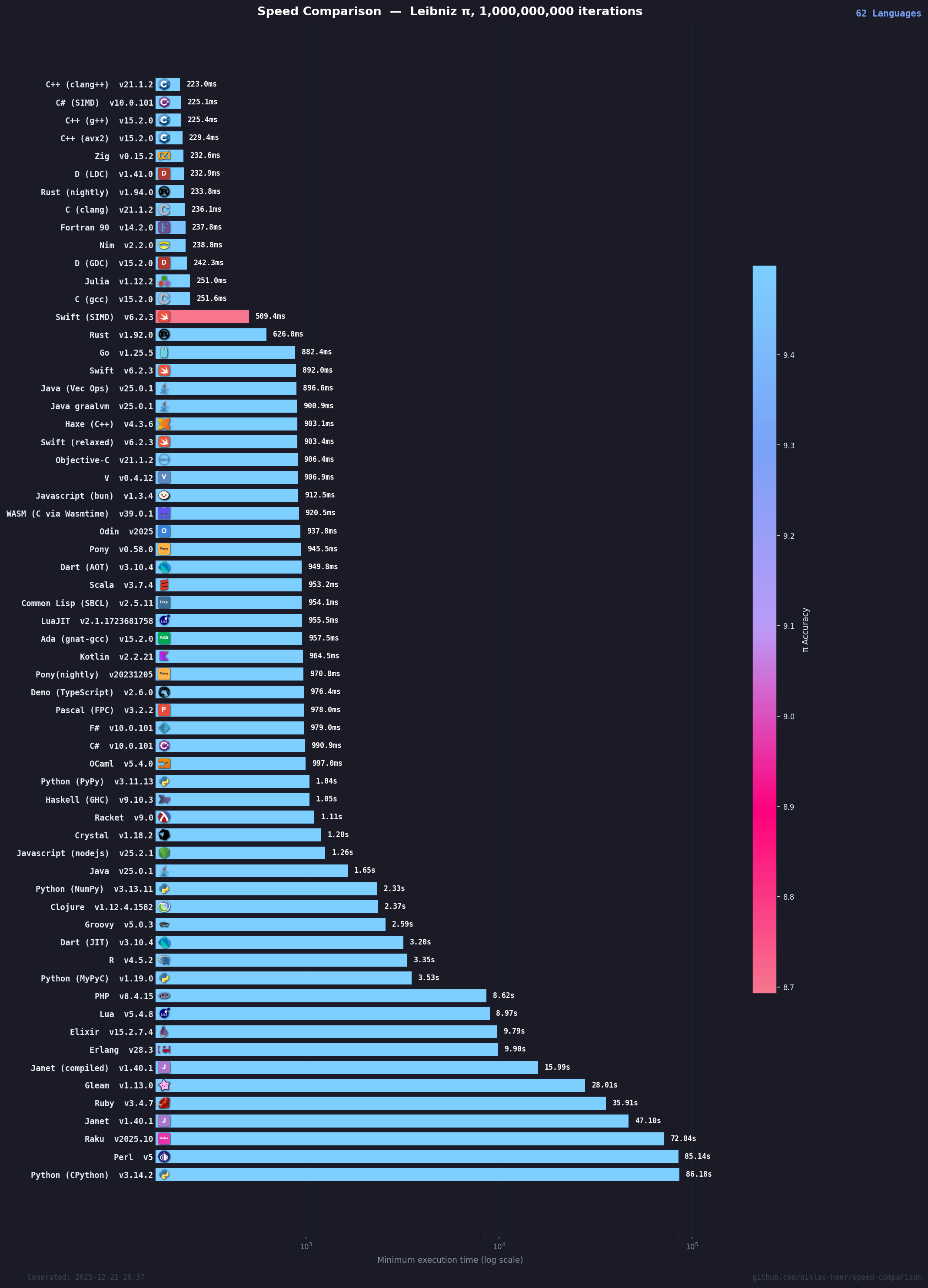
上圖來自:https://niklas-heer.github.io/speed-comparison/
萊布尼茨公式,作為 arctan(x) 的泰勒級數在 x=1時的特例,其數學表達為:

從算法實現的角度審視,該公式具有以下顯著特徵,這些特徵直接決定了其作為基準測試的有效性:
-
極端的計算密集度:算法核心僅包含基本的加、減、乘、除運算,幾乎不涉及複雜的內存分配或系統調用(System Calls)。這使得測試結果能夠高度純粹地反映語言運行時的計算開銷和指令生成質量 。
-
可預測的分支邏輯:公式中的符號交替項 (-1)^k 引入了潛在的分支預測(Branch Prediction)挑戰。樸素的實現可能會在循環內部使用
if (i % 2 == 0)判斷奇偶性,這將導致大量的 CPU 分支預測失敗,從而嚴重拖慢流水線。而高效的實現通常採用無分支(Branchless)技巧,利用位運算或數學變換來消除條件跳轉,這考驗了程序員對底層硬件的理解以及編譯器的優化智能 。 -
浮點精度與收斂性:雖然本基準測試明確聲明“不關注 pi的精確度”,僅關注運算速度,但浮點數(IEEE 754 標準)的累加特性使得計算順序對結果有微小影響。編譯器是否開啓
-ffast-math等激進優化選項(允許改變浮點結合律)對性能有着數量級的影響,這成為了不同語言實現之間性能差異的主要變量之一 。
基於 2025 年 12 月的最新基準測試數據,我們將 62 種語言實現劃分為四個具有顯著特徵的性能梯隊。
第一梯隊:極限性能層 (< 300ms) —— 編譯器的極致
這一梯隊的語言代表了當前通用 CPU 單核計算的物理極限。它們幾乎完全消除了語言本身的運行時開銷,性能瓶頸僅在於 CPU 的 ALU 吞吐量和內存帶寬。
深度剖析:
-
LLVM 的霸權:前 10 名中,C++ (Clang)、Zig、D (LDC)、Rust (Nightly) 均依賴 LLVM 編譯器後端。這證明了 LLVM 在現代處理器指令調度和向量化分析上的卓越能力。
-
C# 的驚人逆襲:C# (SIMD) 位列第二,僅落後 C++ 不到 4 毫秒。這打破了“託管語言一定慢”的刻板印象。通過.NET 的
System.Numerics.Vectors庫,C# 能夠生成與 C++ 幾乎相同的 AVX-512 機器碼,同時享受 JIT 針對當前硬件動態優化的優勢 。 -
手寫 vs 自動:排名第 4 的 C++ (avx2) 是手寫 SIMD 代碼,卻輸給了編譯器自動優化的 Clang (第 1)。這説明在簡單的循環邏輯中,現代編譯器對流水線氣泡(Pipeline Bubble)和寄存器分配的掌控已經超越了普通人類專家 。
第二梯隊:亞秒級高性能層 (300ms - 1000ms) —— 標量優化的極限
這一梯隊的語言性能非常出色,通常在 0.5 秒到 1 秒之間。它們大多生成了高效的機器碼,但因未開啓激進的 SIMD 優化或受到運行時輕微拖累,未能進入第一梯隊。
深度剖析:
-
Rust 的版本鴻溝:Rust (Stable) 耗時 633ms,而 Nightly 版僅需 234ms。這種巨大的差距源於 Rust 穩定版對 IEEE 754 浮點行為的嚴格遵守,阻止了編譯器進行改變運算順序的向量化優化。只有在 Nightly 版中顯式啓用相關特性,才能釋放硬件潛力 。
-
Go 的妥協:Go 語言(888ms)穩定地處於這一梯隊。Go 的編譯器(gc)設計初衷是編譯速度快,而非生成的代碼最快。它在自動向量化方面遠不如 LLVM 激進,且 Go 運行時包含的調度器和垃圾回收(GC)屏障(Write Barriers)在微觀層面引入了額外開銷 。
-
JavaScript 的運行時之戰:Bun (928ms) 顯著快於 Node.js (1.28s)。Bun 使用的 JavaScriptCore (JSC) 引擎在特定數值計算優化上表現出了相比 Google V8 的優勢,證明了現代 JS 引擎的 JIT 能力已能逼近原生代碼(僅慢 3-4 倍)。
第三梯隊:解釋與混合層 (1s - 5s) —— JIT 的戰場
這一梯隊主要包含動態類型語言的高性能 JIT 實現,或啓動開銷較大的靜態語言環境。
深度剖析:
-
PyPy 的驚豔表現:PyPy 將 Python 的運行時間壓縮至 1.06 秒,僅比 C# 標準版慢一點。這得益於其 Tracing JIT 技術,能夠動態記錄循環的執行路徑並編譯為機器碼,消除了動態類型檢查的巨大開銷 。
-
NumPy 的陷阱:雖然 NumPy 底層是 C,但在此測試中(2.46s)表現平平。這是因為測試代碼使用了 Python 層的
for循環逐個調用 NumPy 的標量運算。NumPy 的威力在於數組操作(Vectorization),在標量調用場景下,Python 與 C 之間的上下文切換(Function Call Overhead)反而成為了負擔。若允許重寫為數組操作,NumPy 可能會進入第一梯隊,但這違反了“算法一致性”規則 。 -
Java 的啓動與優化:標準 Java (1.70s) 表現中規中矩。HotSpot 編譯器雖然強大,但在無法自動向量化浮點循環的情況下,受限於 JVM 的棧操作開銷。此外,Java 巨大的啓動時間(JVM 初始化、類加載)在短時任務中佔比顯著。
第四梯隊:純解釋器層 (> 10s) —— 動態類型的代價
最慢的梯隊,主要是未優化的腳本語言解釋器。
深度剖析:
-
CPython 的性能瓶頸:標準 Python(CPython)以 86.32 秒墊底,比 C++ 慢了近 400 倍。這歸因於其虛擬機架構:每一次加法操作都需要進行對象類型檢查(Type Checking)、引用計數更新(Reference Counting)和字節碼分發(Dispatch)。對於 10 億次循環,這些微小的開銷累積成了巨大的時間鴻溝 。
-
解釋器的侷限:這一梯隊的語言(PHP, Ruby, Perl, Raku)在處理緊湊循環時,CPU 主要忙於解釋器自身的邏輯(解析字節碼、管理棧),而非執行實際的數學運算。
C#:.NET Core 的高性能復興
在本次測試中,C# (SIMD) 的表現(227ms)是最令人矚目的亮點之一。這主要歸功於.NET Core(現稱為.NET 5/6/7+)引入的硬件內建支持(Hardware Intrinsics)。
-
實現細節:通過引用
System.Runtime.Intrinsics或使用更高級的System.Numerics.Vector<T>,C# 開發者可以編寫出直接映射到 CPU 向量指令的代碼。 -
JIT 的優勢:與 C++ 的 AOT(提前編譯)不同,C# 的 JIT 編譯器在程序運行時知道當前 CPU 確切支持哪些指令集(是 AVX2 還是 AVX-512)。這使得 C# 程序可以在舊機器上安全運行,而在新機器上自動全速狂奔,無需像 C++ 那樣發佈多個二進制版本。基準測試結果證明,這種機制在數值計算領域已經完全成熟 。