

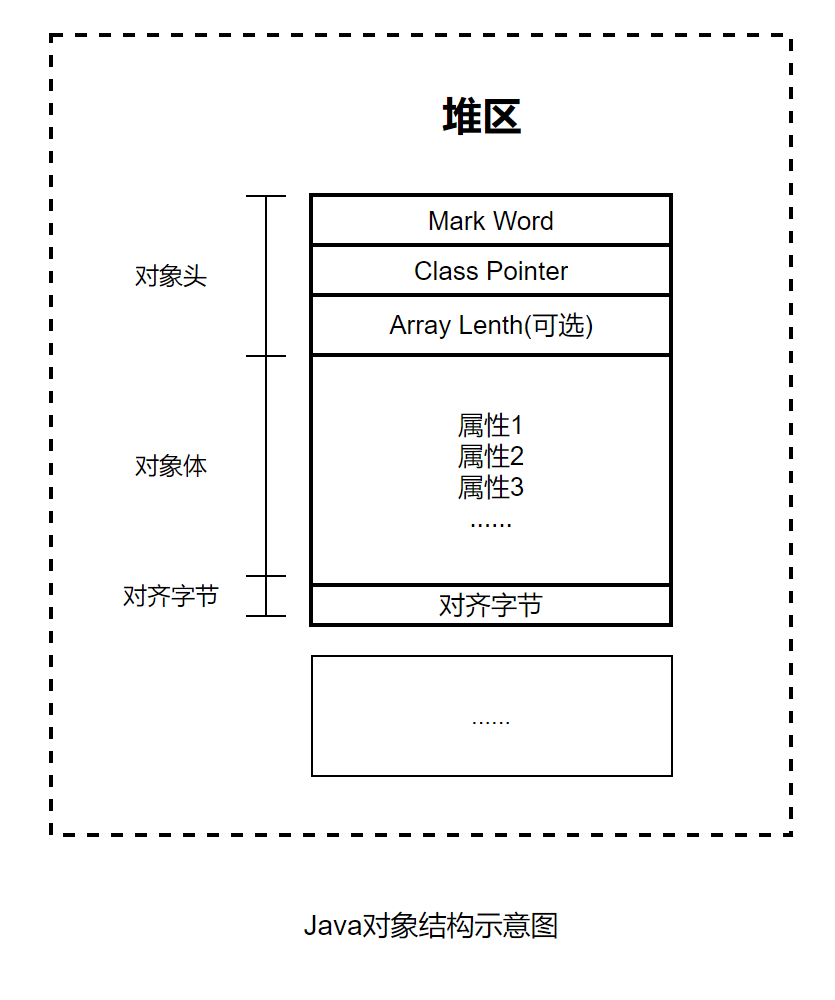
Java對象結構
實例化一個Java對象之後,該對象在內存中的結構是怎麼樣的?Java對象(Object實例)結構包括三部分:對象頭、對象體和對齊字節,具體下圖所示
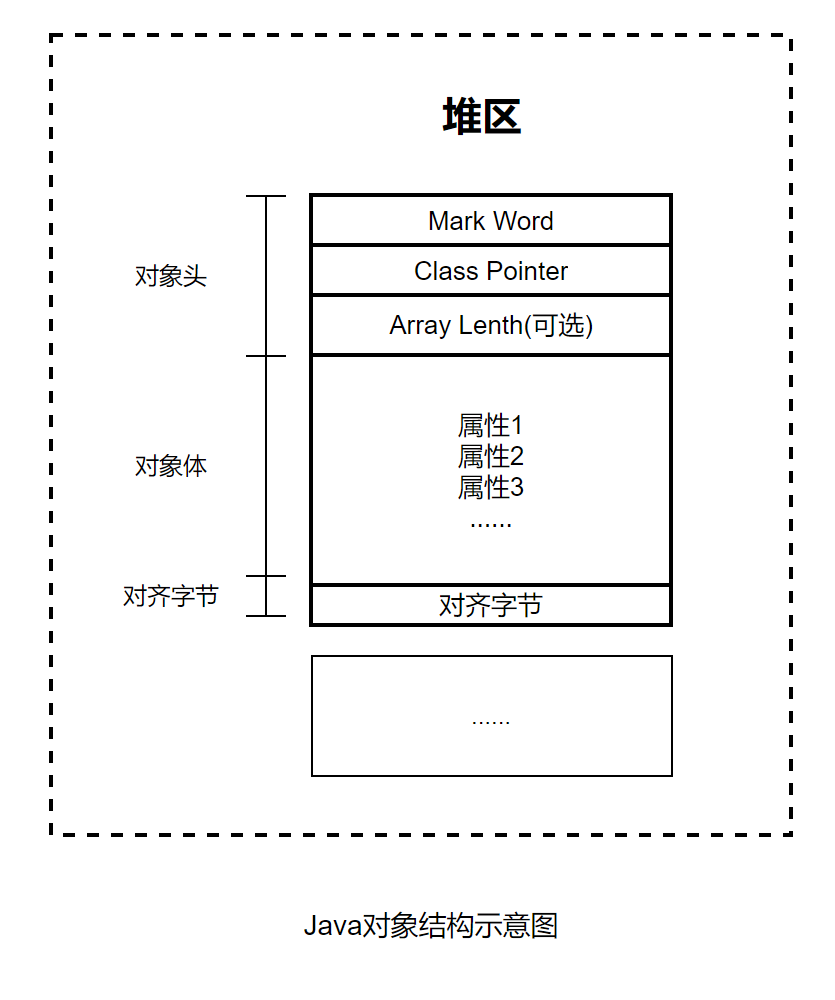
Java對象的三部分
對象頭
對象頭包括三個字段,第一個字段叫作Mark Word(標記字),用於存儲自身運行時的數據,例如GC標誌位、哈希碼、鎖狀態等信息。
第二個字段叫作Class Pointer(類對象指針),用於存放方法區Class對象的地址,虛擬機通過這個指針來確定這個對象是哪個類的實例。
第三個字段叫作Array Length(數組長度)。如果對象是一個Java數組,那麼此字段必須有,用於記錄數組長度的數據;如果對象不是一個Java數組,那麼此字段不存在,所以這是一個可選字段。
對象體
對象體包含對象的實例變量(成員變量),用於成員屬性值,包括父類的成員屬性值。這部分內存按4字節對齊。
對齊字節
對齊字節也叫作填充對齊,其作用是用來保證Java對象所佔內存字節數為8的倍數。HotSpot VM的內存管理要求對象起始地址必須是8字節的整數倍。對象頭本身是8的倍數,當對象的實例變量數據不是8的倍數時,便需要填充數據來保證8字節的對齊。
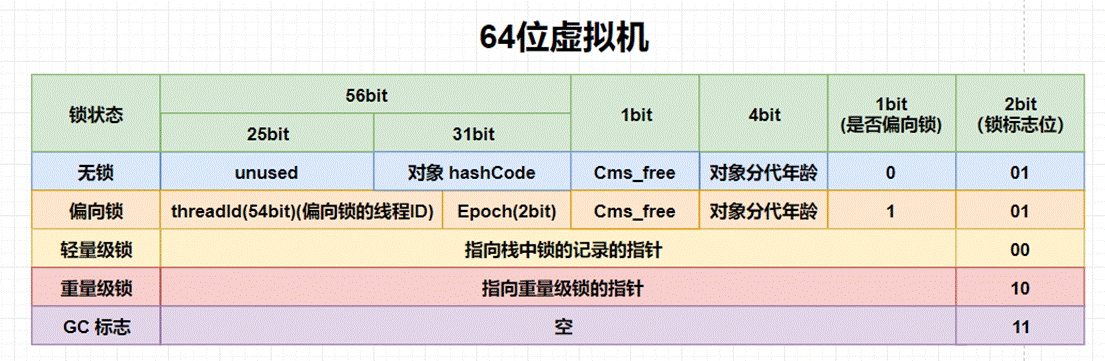
Mark Word的結構信息
用於存儲對象自身運行時數據,如HashCode、GC分代年齡、鎖狀態標誌、線程持有鎖、偏向線程ID、偏向時間戳等信息。這些信息都是與對象自身定義無關的數據,所以Mark Word被設計成一個非固定的數據結構以便在極小的空間內存存儲儘量多的數據。它會根據對象的狀態複用自己的存儲空間,也就是説在運行期間Mark Word裏存儲的數據會隨着鎖標誌位的變化而變化。
Mark Word的位長度為JVM的一個Word大小,也就是説32位JVM的Mark Word為32位,64位JVM為64位。Mark Word的位長度不會受到Oop對象指針壓縮選項的影響。
Java內置鎖的狀態總共有4種,級別由低到高依次為:無鎖、偏向鎖、輕量級鎖和重量級鎖。其實在JDK 1.6之前,Java內置鎖還是一個重量級鎖,是一個效率比較低下的鎖,在JDK 1.6之後,JVM為了提高鎖的獲取與釋放效率,對synchronized的實現進行了優化,引入了偏向鎖和輕量級鎖,從此以後Java內置鎖的狀態就有了4種(無鎖、偏向鎖、輕量級鎖和重量級鎖),並且4種狀態會隨着競爭的情況逐漸升級,而且是不可逆的過程,即不可降級,也就是説只能進行鎖升級(從低級別到高級別)。以下是64位的Mark Word在不同的鎖狀態下的結構信息:
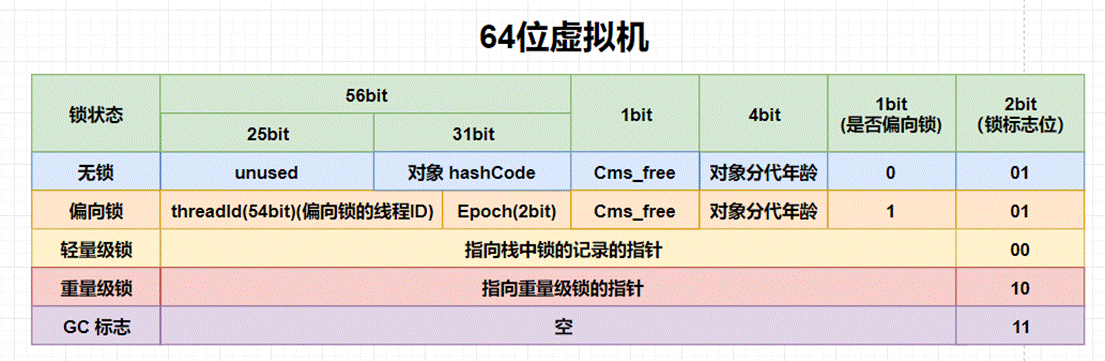
由於目前主流的JVM都是64位,因此我們使用64位的Mark Word。接下來對64位的Mark Word中各部分的內容進行具體介紹。
-
lock:鎖狀態標記位,佔兩個二進制位,由於希望用盡可能少的二進制位表示儘可能多的信息,因此設置了lock標記。該標記的值不同,整個Mark Word表示的含義就不同。
-
biased_lock:對象是否啓用偏向鎖標記,只佔1個二進制位。為1時表示對象啓用偏向鎖,為0時表示對象沒有偏向鎖。lock和biased_lock兩個標記位組合在一起共同表示Object實例處於什麼樣的鎖狀態。二者組合的含義具體如下表所示
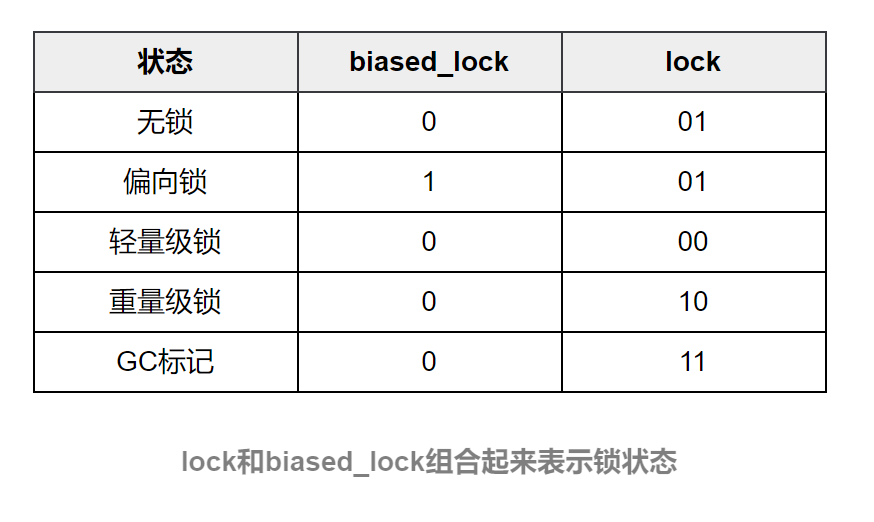
- age:4位的Java對象分代年齡。在GC中,對象在Survivor區複製一次,年齡就增加1。當對象達到設定的閾值時,就會晉升到老年代。默認情況下,並行GC的年齡閾值為15,併發GC的年齡閾值為6。由於age只有4位,因此最大值為15,這就是-XX:MaxTenuringThreshold選項最大值為15的原因。
- identity_hashcode:31位的對象標識HashCode(哈希碼)採用延遲加載技術,當調用Object.hashCode()方法或者System.identityHashCode()方法計算對象的HashCode後,其結果將被寫到該對象頭中。當對象被鎖定時,該值會移動到Monitor(監視器)中。
- thread:54位的線程ID值為持有偏向鎖的線程ID。
- epoch:偏向時間戳。
- ptr_to_lock_record:佔62位,在輕量級鎖的狀態下指向棧幀中鎖記錄的指針。
使用JOL工具查看對象的佈局
JOL工具的使用
JOL工具是一個jar包,使用它提供的工具類可以輕鬆解析出運行時java對象在內存中的結構,使用時首先需要引入maven GAV信息
<!--Java Object Layout -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.17</version>
</dependency>
截止至24年9月,最新版本是0.17版本,據觀察,它和0.15之前(不包含0.15)的版本輸出信息差異比較大,而普遍現在使用的版本都比較低,但是不妨礙在這裏使用該工具做實驗。
jol-core 常用的幾個方法
ClassLayout.parseInstance(object).toPrintable():查看對象內部信息.GraphLayout.parseInstance(object).toPrintable():查看對象外部信息,包括引用的對象.GraphLayout.parseInstance(object).totalSize():查看對象總大小.VM.current().details():輸出當前虛擬機信息
首先創建一個簡單的類Hello
public class Hello {
private Integer a = 1;
}
接下來寫一個啓動類測試下
import org.openjdk.jol.info.ClassLayout;
import org.openjdk.jol.vm.VM;
public class JalTest {
public static void main(String[] args) {
System.out.println(VM.current().details());
Hello hello = new Hello();
System.out.printf(ClassLayout.parseInstance(hello).toPrintable());
}
}
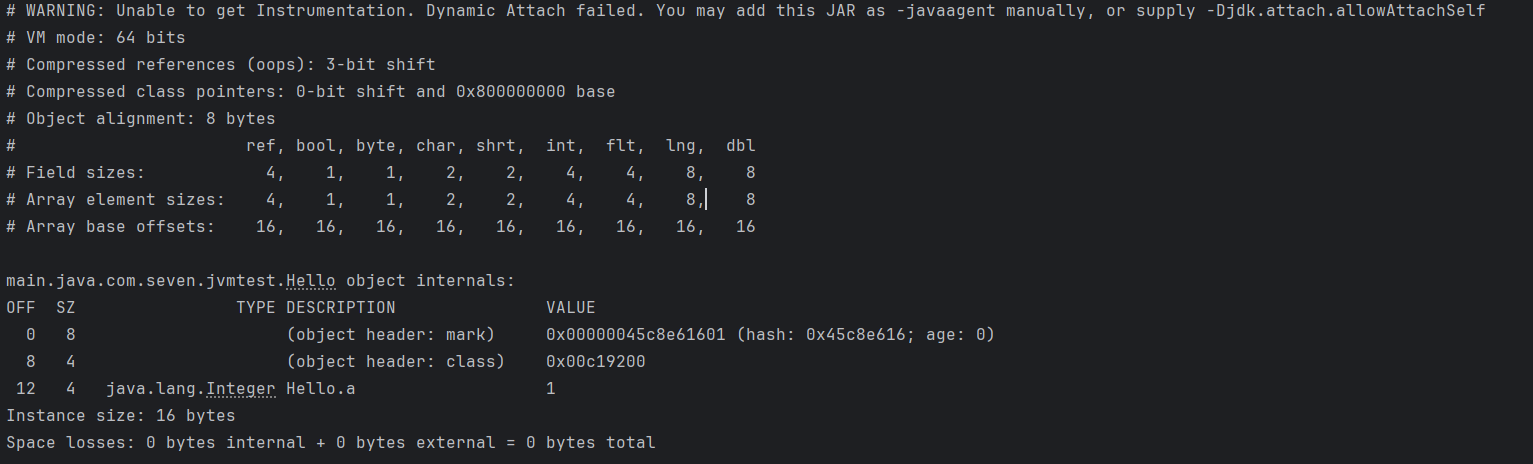
輸出結果:
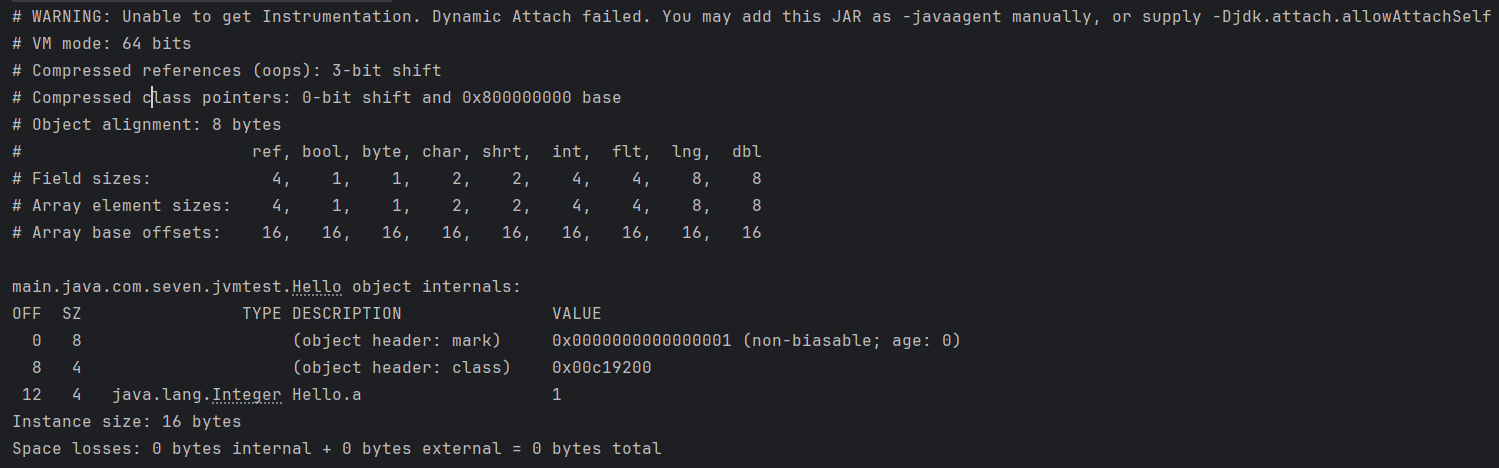
結果分析
在代碼中,首先使用了VM.current().details() 方法獲取到了當前java虛擬機的相關信息:
- VM mode: 64 bits - 表示當前虛擬機是64位虛擬機
- Compressed references (oops): 3-bit shift - 開啓了對象指針壓縮,在64位的Java虛擬機上,對象指針通常需要佔用8字節(64位),但通過使用壓縮指針技術,可以減少對象指針的佔用空間,提高內存利用率。"3-bit shift" 意味着使用3位的位移操作來對對象指針進行壓縮。通過將對象指針右移3位,可以消除指針中的一些無用位,從而減少對象指針的實際大小,使其佔用更少的內存。
- Compressed class pointers: 3-bit shift - 開啓了類指針壓縮,其餘同上。
- Object alignment: 8 bytes - 字節對齊使用8字節

這部分輸出表示 引用類型、boolean、byte、char、short、int、float、long、doubl e類型的數據所佔的字節數大小以及在數組中的大小和偏移量。
需要注意的是數組偏移量的概念,數組偏移量的數值其實就是對象頭的大小,在上圖中的16字節表示如果當前對象是數組,那對象頭就是16字節,不要忘了,對象頭中還有數組長度,在未開啓對象指針壓縮的情況下,它要佔據4字節大小。
接下來是對象結構的輸出分析。
對象結構輸出解析
先回顧下對象結構
再來回顧下對象結構輸出結果

- OFF:偏移量,單位字節
- SZ:大小,單位字節
- TYPE DESCRIPTION:類型描述,這裏顯示的比較直觀,甚至可以看到是對象頭的哪一部分
- VALUE:值,使用十六進制字符串表示,注意一個字節是8bit,佔據兩個16進制字符串,JOL0.15版本之前是小端序展示,0.15(包含0.15)版本之後使用大端序展示。
Mark Word解析

因為當前虛擬機是64位的虛擬機,所以Mark Word在對象頭中佔據8字節,也就是64位。它不受指針壓縮的影響,佔據內存大小隻和當前虛擬機有關係。
當前的值是十六進制數值:0x0000000000000001,為了好看點,將它按照字節分割開:00 00 00 00 00 00 00 01,然後,來回顧下mark workd的內存結構:
最後一個字節是十六進制的01,轉化為二進制數,就是00000001,那倒數三個bit就是001,偏向鎖標誌位biased是0,lock標誌位是01,對應的是無鎖狀態下的mark word數據結構。
Class Pointer 解析

該字段在64位虛擬機下開啓指針壓縮佔據4字節,未開啓指針壓縮佔據8字節,它指向方法區的內存地址,即Class對象所在的位置。
對象體解析

Hello類只有一個Integer類型的變量a,它在64位虛擬機下開啓指針壓縮佔據4字節,未開啓指針壓縮佔據8字節大小。需要注意的是,這裏的8字節存儲的是Integer對象指針大小,而非int類型的數值所佔內存大小。
不同條件下的對象結構變化
Mark Word中的hashCode
在無鎖狀態下,對象頭中的mark word字段有31bit是用於存放hashCode的值的,但是在之前的打印輸出中,hashCode全是0,這是為什麼?
想要hashCode的值能夠在mark word中展示,需要滿足兩個條件:
- 目標類不能重寫hashCode方法
- 目標對象需要調用hashCode方法生成hashCode
上面的實驗中,Hello類很簡單
public class Hello {
private Integer a = 1;
}
沒有重寫hashCode方法,使用JOL工具分析沒有看到hashCode值,是因為沒有調用hashCode()方法生成hashCode值
接下來改下啓動類,調用下hashCode方法,重新輸出解析結果
public class JalTest {
public static void main(String[] args) {
System.out.println(VM.current().details());
Hello hello = new Hello();
hello.hashCode();
System.out.printf(ClassLayout.parseInstance(hello).toPrintable());
}
}
輸出結果
可以看到,Mark Word中已經有了hashCode的值。
字節對齊
從JOL輸出上來看,使用的是8字節對齊,而對象正好是16字節,是8的整數倍,所以並沒有使用字節對齊,為了能看到字節對齊的效果,再給Hello類新增一個成員變量Integer b = 2,已知一個整型變量在這裏佔用4字節大小空間,對象大小會變成20字節,那就不是8的整數倍,會有4字節的對齊字節填充,改下Hello類
public class Hello {
private Integer a = 1;
private Integer b = 2;
}
然後查看運行結果:
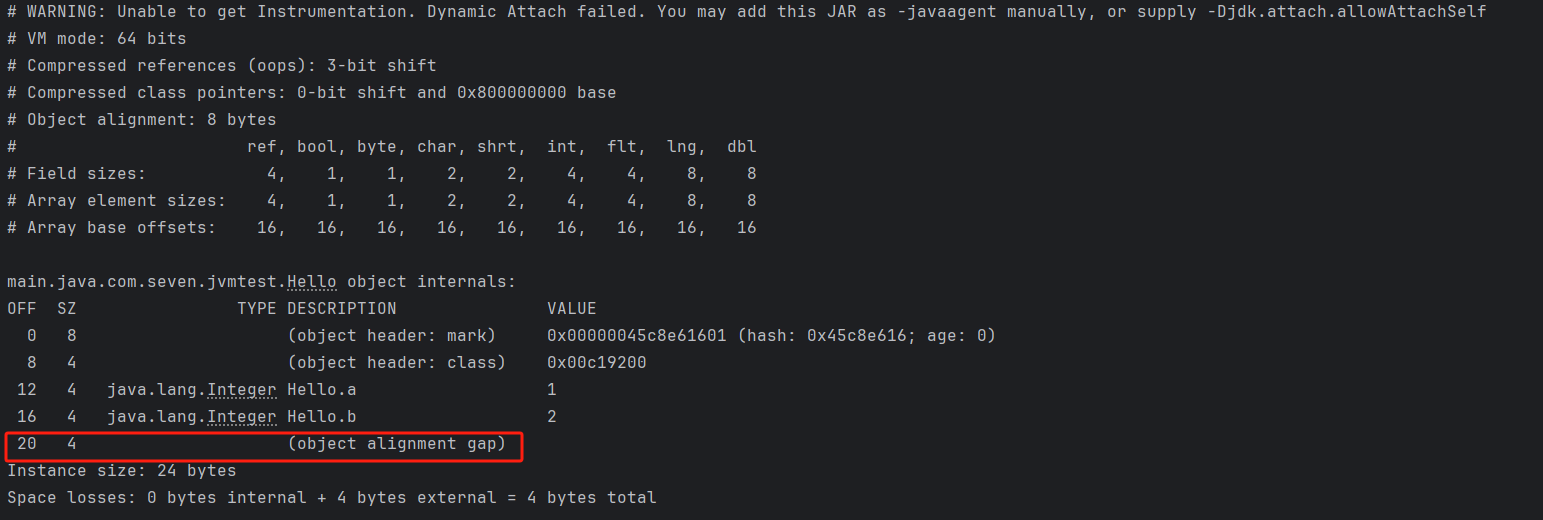
果然,為了對齊8字節,多了4字節的填充,整個對象實例大小變成了24字節。
數組類型的對象結構
數組類型的對象和普通的對象肯定不一樣,甚至在對象頭中專門有個“數組長度”來記錄數組的長度。改變下啓動類,看看Integer數組的對象結構
public class JalTest {
public static void main(String[] args) {
System.out.println(VM.current().details());
Integer[] a = new Integer[]{1, 2, 3};
a.hashCode();
System.out.printf(ClassLayout.parseInstance(a).toPrintable());
}
}
輸出結果
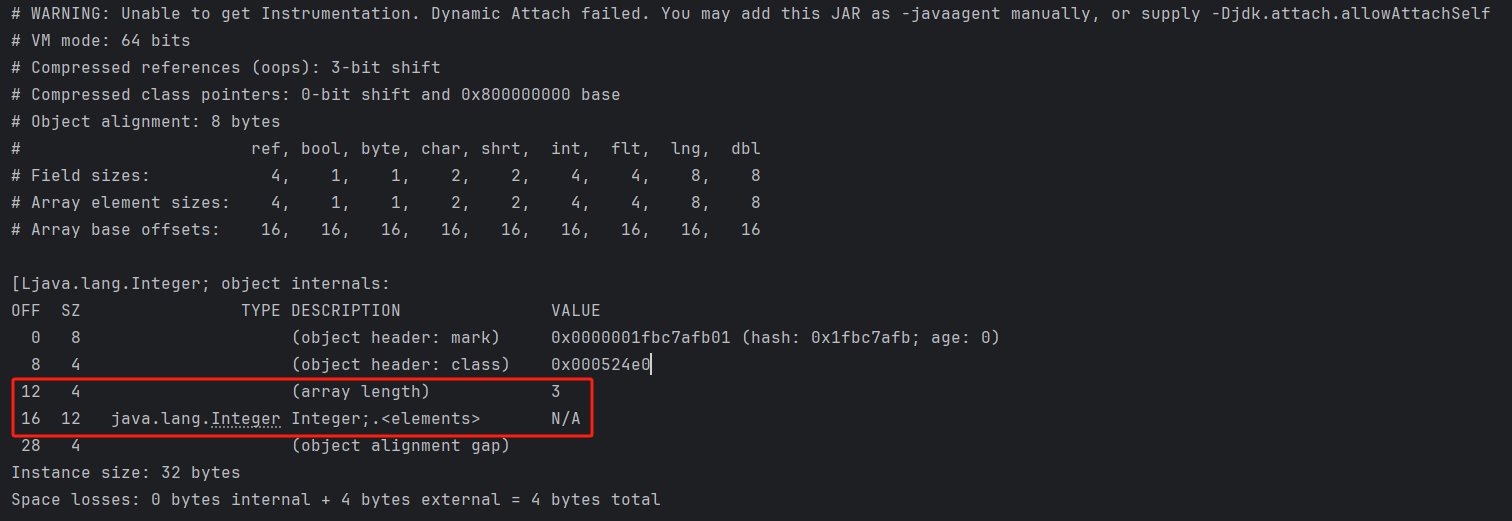
標紅部分相對於普通的對象,數組對象多了個數組長度的字段;而且接下來3個整數,共佔據了12字節大小的內存空間。
再仔細看看,加上數組長度部分,對象頭部分一共佔據了16字節大小的空間,這個和上面的Array base offsets的大小一致,這是因為要想訪問到真正的對象值,從對象開始要經過16字節的對象頭才能讀取到對象,這16字節也就是每個元素讀取的“偏移量”了。
指針壓縮
開啓指針壓縮: -XX:+UseCompressedOops
關閉指針壓縮: -XX:-UseCompressedOops
在Intelij中,在VM Options中添加該參數即可,需要注意的是,指針壓縮在java8及以後的版本中是默認開啓的。
接下來看看指針壓縮在開啓和沒開啓的情況下,相同的解析代碼打印出來的結果
代碼:
@Slf4j
public class JalTest {
public static void main(String[] args) {
System.out.println(VM.current().details());
Integer[] a = new Integer[]{1, 2, 3};
a.hashCode();
System.out.printf(ClassLayout.parseInstance(a).toPrintable());
}
}
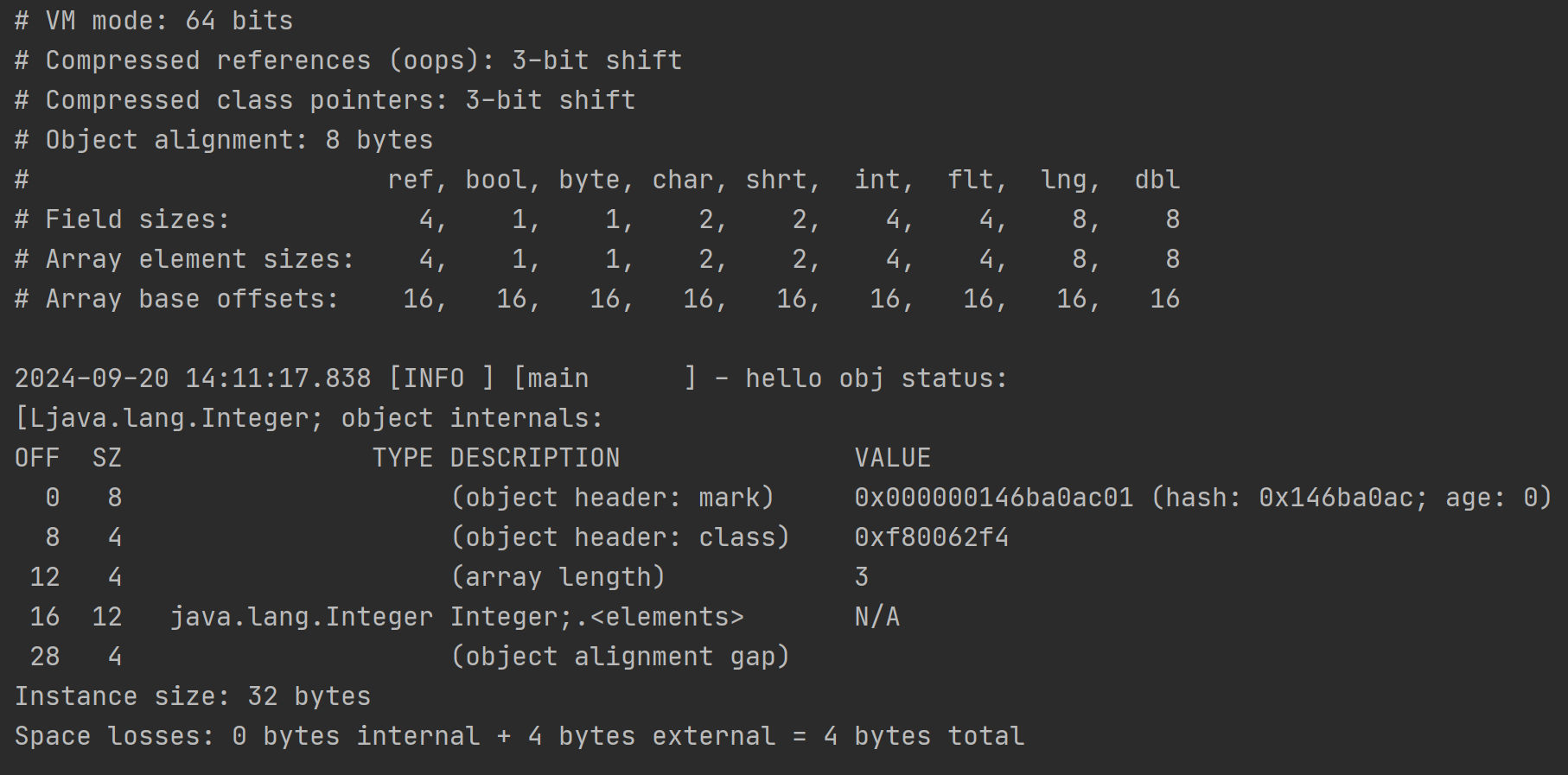
開啓指針壓縮的解析結果:
未開啓指針壓縮的結果:
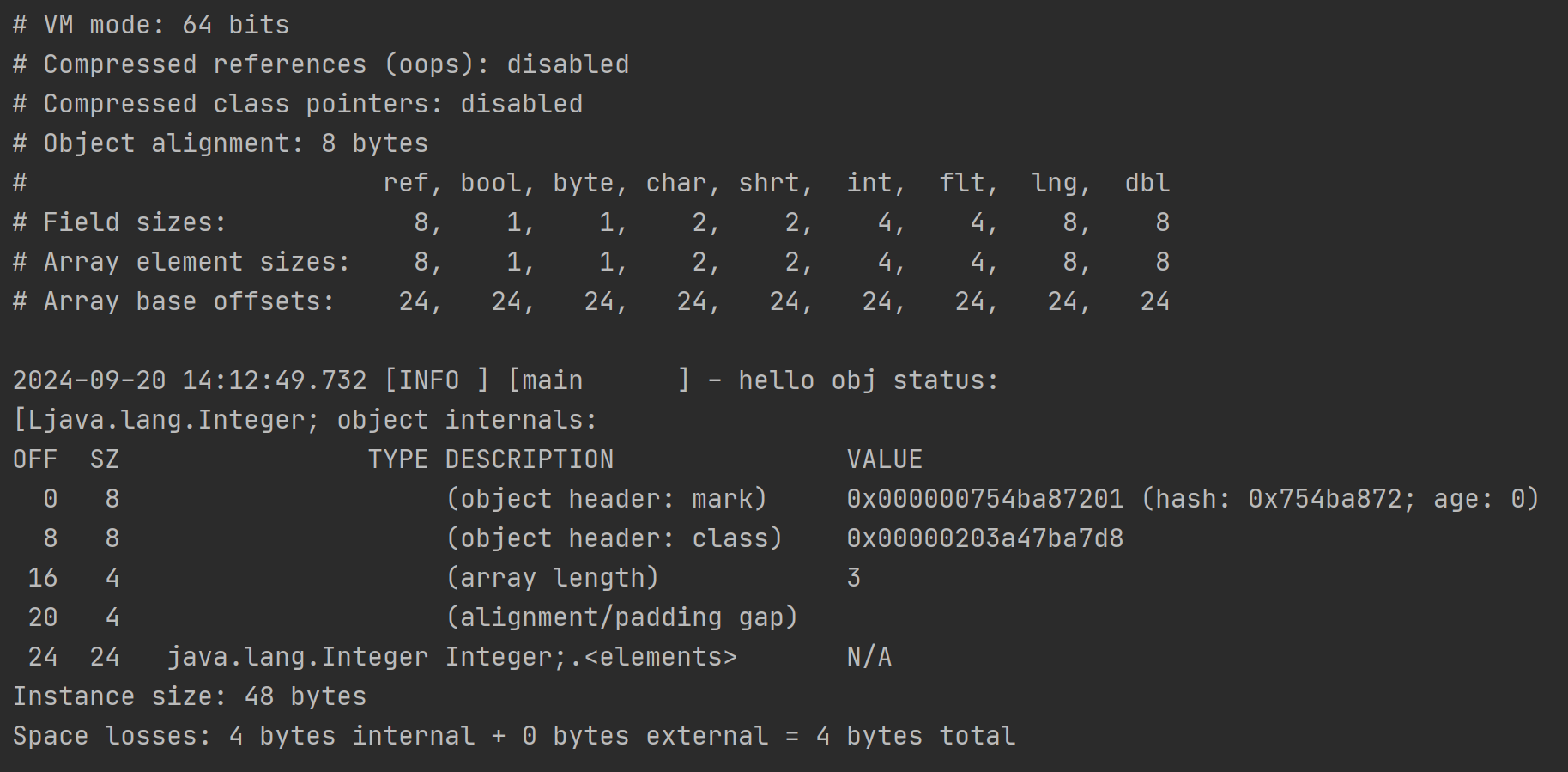
以開啓指針壓縮後的結果為基礎,觀察下未開啓指針壓縮的結果
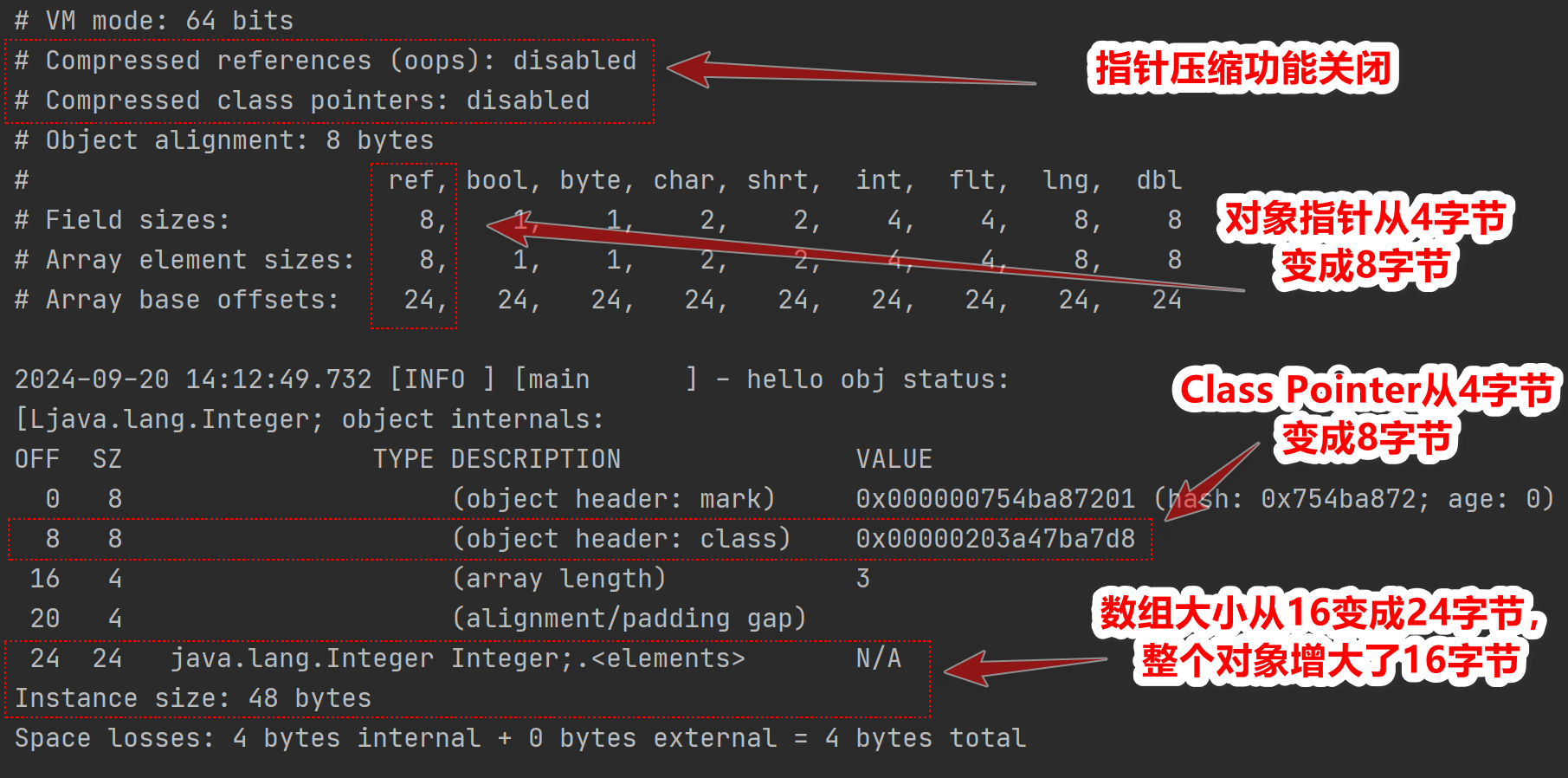
需要注意的是這裏的Integer[]數組裏面都是Integer對象,而非int類型的數值,它是Integer基本類型包裝類的實例,這裏的數組內存地址中存儲的是每個Integer對象的指針引用,從輸出的VM信息的對照表中,“ref”類型佔據8字節,所以才是3*8為24字節大小。
可以看到,開啓指針壓縮以後,會產生兩個影響
- 對象引用類型會從8字節變成4字節
- 對象頭中的Class Pointer類型會從8字節變成4字節
確實能節省空間。
擴展閲讀
大端序和小端序
大端序(Big Endian)和小端序(Little Endian)是兩種不同的存儲數據的方式,特別是在多字節數據類型(比如整數)在計算機內存中的存儲順序方面有所體現。
- 大端序(Big Endian):在大端序中,數據的高位字節存儲在低地址,而低位字節存儲在高地址。類比於數字的書寫方式,高位數字在左邊,低位數字在右邊。因此,數據的最高有效字節(Most Significant Byte,MSB)存儲在最低的地址處。
- 小端序(Little Endian):相反地,在小端序中,數據的低位字節存儲在低地址,而高位字節存儲在高地址。這種方式與我們閲讀數字的順序一致,即從低位到高位。因此,數據的最低有效字節(Least Significant Byte,LSB)存儲在最低的地址處。
這兩種存儲方式可以用一個簡單的例子來説明:
假設要存儲一個 4 字節的整數 0x12345678:
- 在大端序中,存儲順序為
12 34 56 78。 - 在小端序中,存儲順序為
78 56 34 12。