

遞歸算法
遞歸算法(Recursion Algorithm)是一種重要的編程方法,核心思想是函數通過調用自身來解決問題。在遞歸中,一個複雜的問題被分解為相同類型但規模更小的子問題,直到達到一個簡單到可以直接解決的基本情況(基準情況)。遞歸算法特別適合解決具有自相似結構的問題,時間複雜度跟遞歸深度和每層處理的複雜度有關。
遞歸算法的妙處在於它能用簡潔優雅的代碼解決看似複雜的問題,但在使用時一定要注意避免無限遞歸和重複計算等問題。
算法步驟
- 定義遞歸函數,明確函數的功能和參數
- 確定遞歸的基準情況(終止條件)
- 將問題分解為更小的子問題
- 調用自身解決子問題
- 將子問題的結果組合起來,得到原問題的解
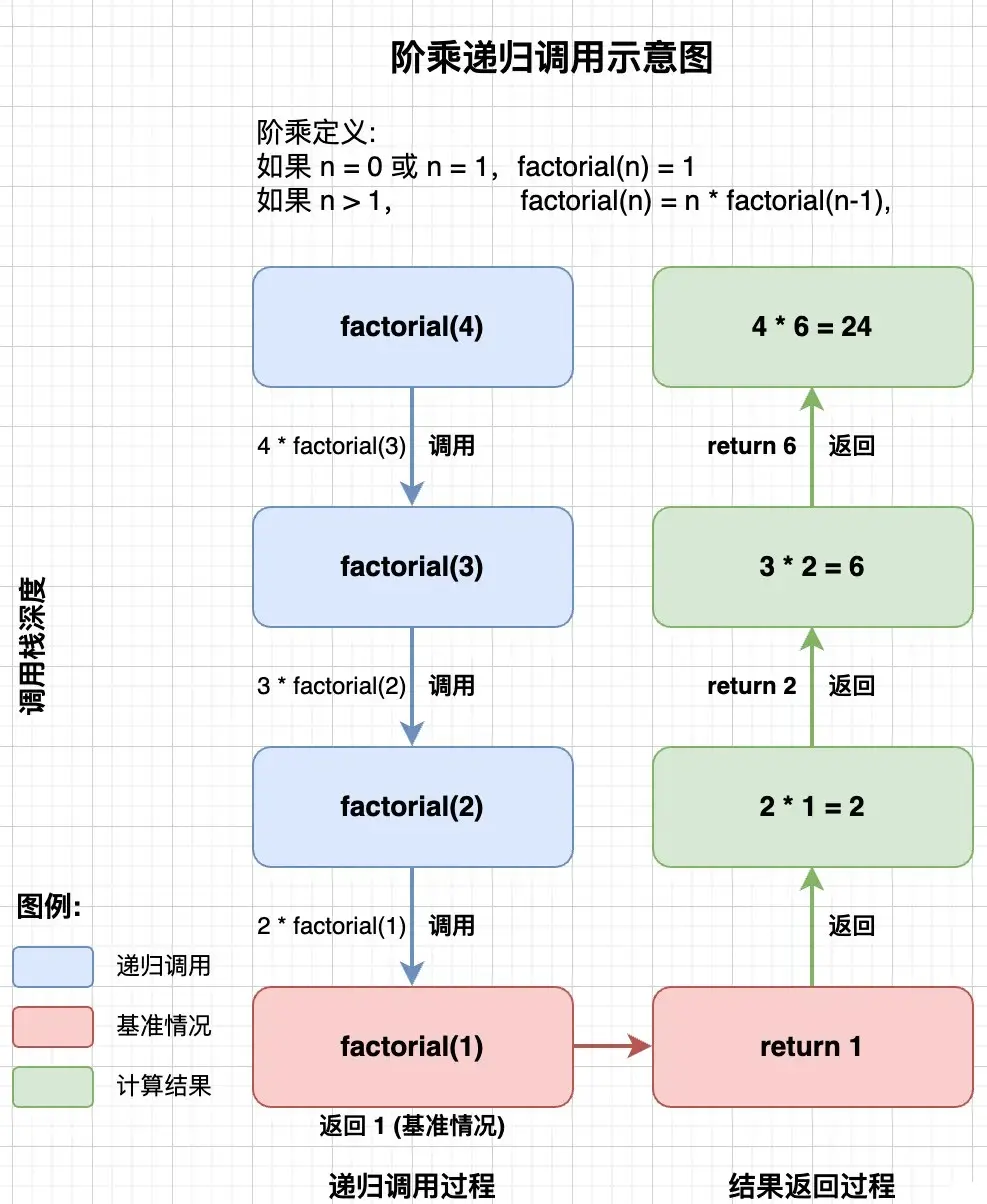
核心特性:
- 自我調用:函數在其定義中直接或間接調用自身
- 終止條件:必須有基準情況使遞歸能夠終止
- 問題分解:將大問題分解為相同類型但規模更小的子問題
- 時間複雜度:與遞歸深度和每層處理的工作量相關
- 空間複雜度:受函數調用棧深度影響,通常與遞歸深度成正比
基礎實現
接下來通過階乘(factorial)計算來展示遞歸算法的實現:
public class Factorial {
public static int factorial(int n) {
// 基準情況
if (n == 0 || n == 1) {
return 1;
}
// 遞歸情況:n! = n * (n-1)!
return n * factorial(n - 1);
}
// 測試
public static void main(String[] args) {
for (int i = 0; i <= 10; i++) {
System.out.printf("%d! = %d
", i, factorial(i));
}
}
}實現遞歸的核心思想,將計算 n! 的問題轉化為計算 (n-1)! 的子問題。同時設置清晰的終止條件 if (n == 0 || n == 1) return 1; 確保遞歸能夠結束。
優化策略
尾遞歸優化
通過將遞歸操作放在函數返回位置,可以被編譯器優化,避免額外的棧空間消耗
public static int factorialTailRecursive(int n) {
return factorialHelper(n, 1);
}
private static int factorialHelper(int n, int accumulator) {
// 基準情況
if (n == 0 || n == 1) {
return accumulator;
}
// 尾遞歸調用
return factorialHelper(n - 1, n * accumulator);
}記憶化遞歸
緩存已計算結果,避免重複計算
public static int factorialMemoization(int n) {
int[] memo = new int[n + 1];
return factorialWithMemo(n, memo);
}
private static int factorialWithMemo(int n, int[] memo) {
// 基準情況
if (n == 0 || n == 1) {
return 1;
}
// 檢查是否已計算
if (memo[n] != 0) {
return memo[n];
}
// 計算並緩存結果
memo[n] = n * factorialWithMemo(n - 1, memo);
return memo[n];
}優點
- 代碼簡潔優雅,易於理解和實現
- 適合處理樹、圖等具有遞歸結構的數據
- 某些問題用遞歸比迭代更直觀(比如樹的遍歷)
缺點
- 函數調用開銷較大,會影響性能
- 遞歸深度過大時可能導致棧溢出
- 重複計算子問題可能導致指數級時間複雜度
- 調試和跟蹤執行流程較為困難
- 資源消耗(特別是棧空間)隨遞歸深度增加
應用場景
1)數學計算:階乘、斐波那契數列、組合數等
2)數據結構操作:樹的遍歷、圖的搜索(DFS)
3)分治算法:歸併排序、快速排序
4)動態規劃:子問題的遞歸求解
5)回溯算法:排列組合、八皇后、數獨求解
相關的 LeetCode 熱門題目
給大家推薦一些可以用來練手的 LeetCode 題目:
- 21. 合併兩個有序鏈表 - 經典的遞歸合併問題
- 104. 二叉樹的最大深度 - 展示遞歸處理樹結構的典型案例
- 509. 斐波那契數 - 遞歸和優化遞歸的經典案例
分治算法
分治法(Divide and Conquer)是一種解決複雜問題的重要算法思想,其核心思想是將一個難以直接解決的大問題,分割成若干個規模較小的子問題,以便各個擊破,最後將子問題的解組合起來,得到原問題的解。分治法的思想可以追溯到古代,但作為一種系統化的算法策略,它在計算機科學領域得到了極大的發展和應用。
算法步驟
分治算法通常遵循以下三個步驟:
- 分解(Divide):將原問題分解為若干個規模較小、相互獨立、與原問題形式相同的子問題。
- 解決(Conquer):若子問題規模較小且容易解決則直接解決,否則遞歸地解各子問題。
- 合併(Combine):將各子問題的解合併為原問題的解。
核心特性:
- 遞歸結構:分治算法通常使用遞歸實現,每個子問題繼續分解直到達到基本情況
- 獨立性:各子問題之間相互獨立,不存在交疊
- 問題等價性:子問題與原問題形式相同,只是規模減小
- 合併操作:需要有效的合併子問題解的方法
- 基本情況處理:當問題規模小到一定程度,可以直接求解
優點
- 高效性:對於許多問題,分治算法能提供較高的效率
- 並行計算:分治算法天然適合並行計算,各子問題可以獨立求解
- 模塊化:問題劃分為相互獨立的模塊,便於理解和實現
- 可複用性:同樣的分治模式可以應用於多種問題求解
缺點
- 遞歸開銷:遞歸調用會導致額外的函數調用開銷和棧空間使用
- 內存使用:某些分治算法實現可能需要額外的內存空間
- 不適用性:不是所有問題都適合使用分治策略,尤其是子問題不獨立的情況
- 合併難度:某些問題的子問題解合併起來可能相當複雜
應用場景
- 排序算法:歸併排序、快速排序
- 搜索算法:二分搜索
- 矩陣運算:Strassen矩陣乘法
- 傅里葉變換:快速傅里葉變換(FFT)
- 最近點對問題:計算幾何中的經典問題
- 大整數乘法:Karatsuba算法
- 棋盤覆蓋問題:使用L型骨牌覆蓋棋盤
- 圖算法:最短路徑、最小生成樹等問題
相關的 LeetCode 熱門題目
- 53. 最大子數組和: 可以用分治法解決的經典問題
- 215. 數組中的第K個最大元素: 可以使用類似快速排序的分治思想解決
- 23. 合併K個升序鏈表: 可以通過分治法將多個鏈表兩兩合併
- 169. 多數元素: 可以使用分治算法解決的投票問題
- 240. 搜索二維矩陣 II: 可以使用分治策略進行矩陣搜索