

概述
樹就是一種類似現實生活中的樹的數據結構(倒置的樹)。任何一顆非空樹只有一個根節點。
樹的定義:樹是⼀種數據結構,它是由n(n≥1)個有限節點組成⼀個具有層次關係的集合。把它叫做“樹”是因為它看起來像⼀棵倒掛的樹,也就是説它是根朝上,⽽葉朝下的。
一棵樹具有以下特點:
- 每個節點有零個或多個⼦節點
- 沒有⽗節點的節點稱為根節點
- 每⼀個⾮根節點有且只有⼀個⽗節點
- 除了根節點外,每個⼦節點可以分為多個不相交的⼦樹
- 一棵樹中的任意兩個結點有且僅有唯一的一條路徑連通。
- 一棵樹如果有 n 個結點,那麼它一定恰好有 n-1 條邊。
- 一棵樹不包含迴路。
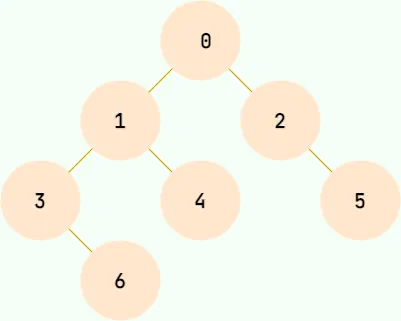
下圖就是一顆樹,並且是一顆二叉樹。
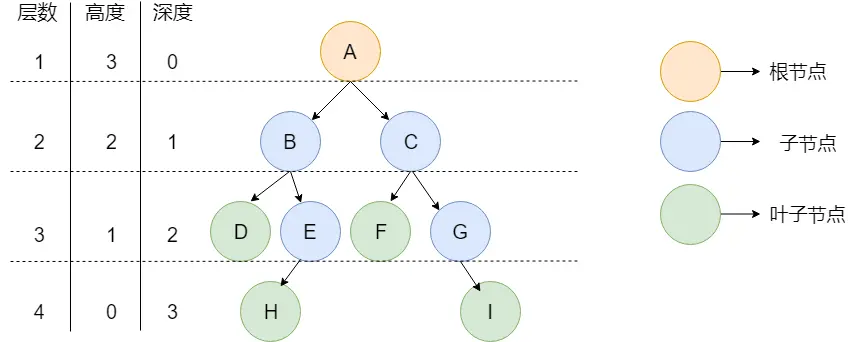
如上圖所示,通過上面這張圖説明一下樹中的常用概念:
- 節點:樹中的每個元素都可以統稱為節點。
- 節點的度:⼀個節點含有的⼦樹的個數稱為該節點的度
- 樹的度:⼀棵樹中,最⼤的節點度稱為樹的度;
- 葉節點或終端節點:度為零的節點;
- ⾮終端節點或分⽀節點:度不為零的節點;
- 根節點:頂層節點或者説沒有父節點的節點。上圖中 A 節點就是根節點。
- 父節點:若一個節點含有子節點,則這個節點稱為其子節點的父節點。上圖中的 B 節點是 D 節點、E 節點的父節點。
- 子節點:一個節點含有的子樹的根節點稱為該節點的子節點。上圖中 D 節點、E 節點是 B 節點的子節點。
- 兄弟節點:具有相同父節點的節點互稱為兄弟節點。上圖中 D 節點、E 節點的共同父節點是 B 節點,故 D 和 E 為兄弟節點。
- 葉子節點:沒有子節點的節點。上圖中的 D、F、H、I 都是葉子節點。
- 節點的高度:該節點到葉子節點的最長路徑所包含的邊數。
- 節點的深度:根節點到該節點的路徑所包含的邊數
- 節點的層數:節點的深度+1。
- 樹的高度:根節點的高度。
關於樹的深度和高度的定義可以看 stackoverflow 上的這個問題:What is the difference between tree depth and height? 。
二叉樹的存儲
二叉樹的存儲主要分為 鏈式存儲 和 順序存儲 兩種:
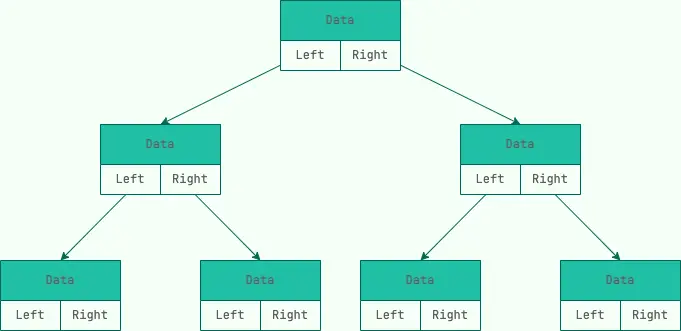
鏈式存儲
和鏈表類似,二叉樹的鏈式存儲依靠指針將各個節點串聯起來,不需要連續的存儲空間。
每個節點包括三個屬性:
- 數據 data。data 不一定是單一的數據,根據不同情況,可以是多個具有不同類型的數據。
- 左節點指針 left
- 右節點指針 right。
可是 JAVA 沒有指針啊!
那就直接引用對象唄(別問我對象哪裏找)
順序存儲
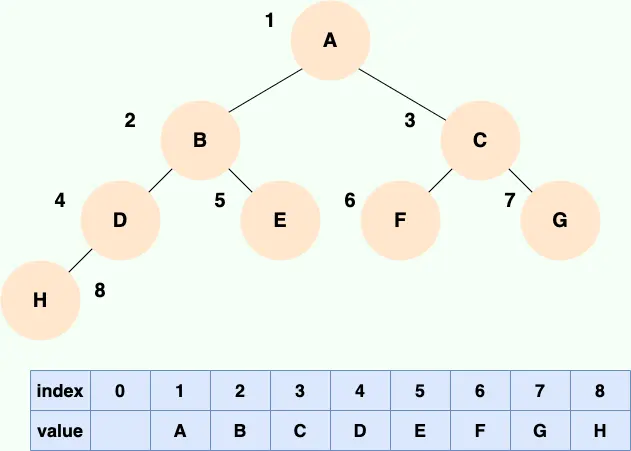
順序存儲就是利用數組進行存儲,數組中的每一個位置僅存儲節點的 data,不存儲左右子節點的指針,子節點的索引通過數組下標完成。根結點的序號為 1,對於每個節點 Node,假設它存儲在數組中下標為 i 的位置,那麼它的左子節點就存儲在 2i 的位置,它的右子節點存儲在下標為 2i+1 的位置。
一棵完全二叉樹的數組順序存儲如下圖所示:
大家可以試着填寫一下存儲如下二叉樹的數組,比較一下和完全二叉樹的順序存儲有何區別:
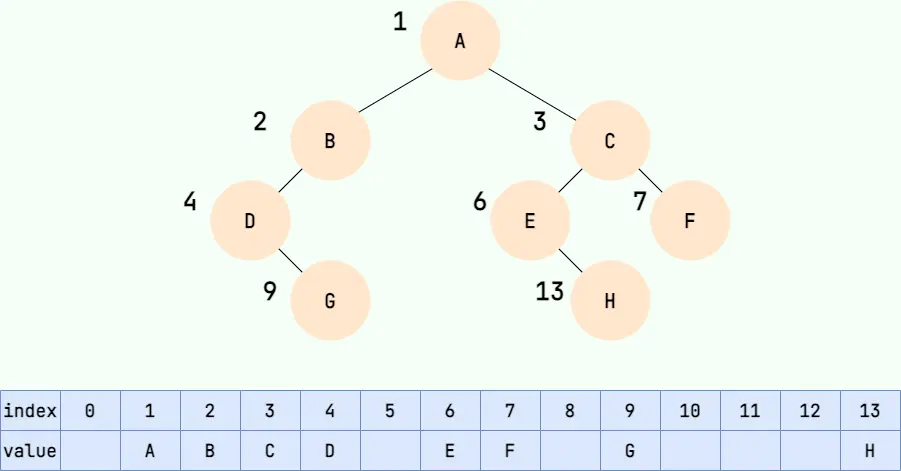
可以看到,如果我們要存儲的二叉樹不是完全二叉樹,在數組中就會出現空隙,導致內存利用率降低
二叉樹的遍歷
遞歸遍歷
先序遍歷
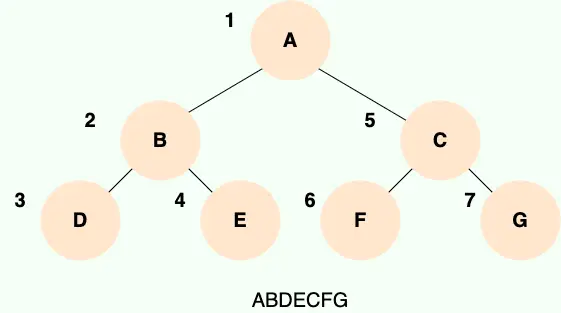
二叉樹的先序遍歷,就是先輸出根結點,再遍歷左子樹,最後遍歷右子樹,遍歷左子樹和右子樹的時候,同樣遵循先序遍歷的規則,也就是説,我們可以遞歸實現先序遍歷。
代碼如下:
public void preOrder(TreeNode root){
if(root == null){
return;
}
system.out.println(root.data);
preOrder(root.left);
preOrder(root.right);
}中序遍歷
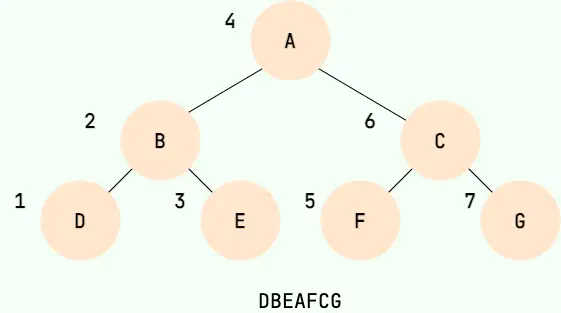
二叉樹的中序遍歷,就是先遞歸中序遍歷左子樹,再輸出根結點的值,再遞歸中序遍歷右子樹,大家可以想象成一巴掌把樹壓扁,父結點被拍到了左子節點和右子節點的中間,如下圖所示:

代碼如下:
public void inOrder(TreeNode root){
if(root == null){
return;
}
inOrder(root.left);
system.out.println(root.data);
inOrder(root.right);
}後序遍歷
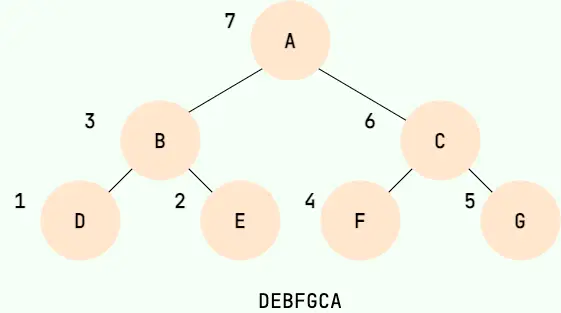
二叉樹的後序遍歷,就是先遞歸後序遍歷左子樹,再遞歸後序遍歷右子樹,最後輸出根結點的值
代碼如下:
public void postOrder(TreeNode root){
if(root == null){
return;
}
postOrder(root.left);
postOrder(root.right);
system.out.println(root.data);
}層序遍歷
層序遍歷屬於迭代遍歷,也比較簡單
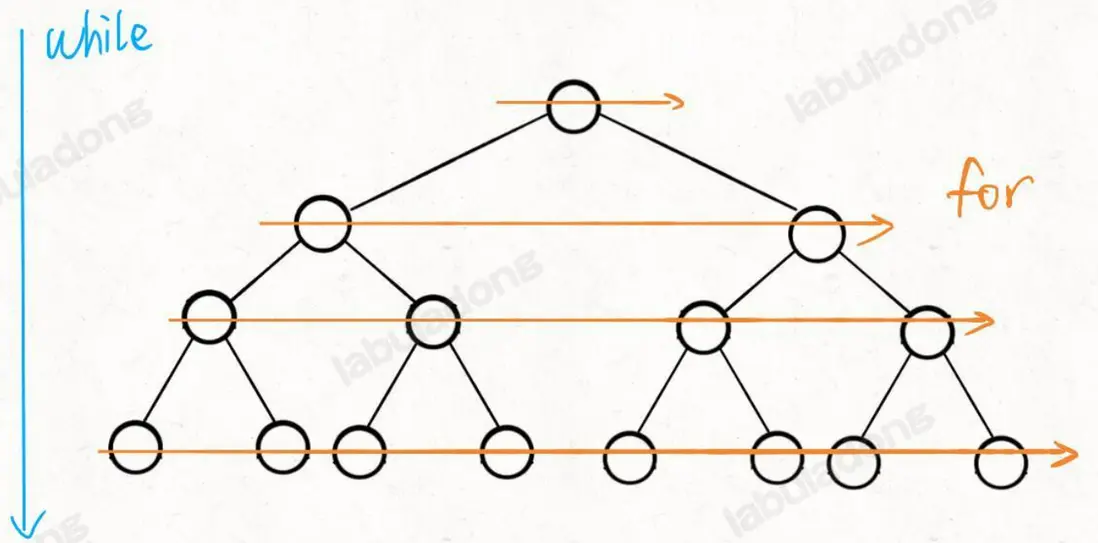
前序遍歷
前序遍歷是中左右,每次先處理的是中間節點,那麼先將根節點放入棧中,然後將右孩子加入棧,再加入左孩子。
// 前序遍歷順序:中-左-右,入棧順序:中-右-左
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null){
return result;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()){
TreeNode node = stack.pop();
result.add(node.val);
if (node.right != null){
stack.push(node.right);
}
if (node.left != null){
stack.push(node.left);
}
}
return result;
}中序遍歷
剛剛在進行前序遍歷迭代的過程中,其實有兩個操作:
- 處理:將元素放進result數組中
- 訪問:遍歷節點
前序遍歷的順序是中左右,先訪問的元素是中間節點,要處理的元素也是中間節點,因為要訪問的元素和要處理的元素順序是一致的,都是中間節點,所以剛剛能寫出相對簡潔的代碼
那麼再看看中序遍歷,中序遍歷是左中右,先訪問的是二叉樹頂部的節點,然後一層一層向下訪問,直到到達樹左面的最底部,再開始處理節點(也就是在把節點的數值放進result數組中),這就造成了處理順序和訪問順序是不一致的。
那麼在使用迭代法寫中序遍歷,就需要借用指針的遍歷來幫助訪問節點,棧則用來處理節點上的元素。
// 中序遍歷順序: 左-中-右 入棧順序: 左-右
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null){
return result;
}
Stack<TreeNode> stack = new Stack<>();
TreeNode cur = root;
while (cur != null || !stack.isEmpty()){
if (cur != null){
stack.push(cur);
cur = cur.left;
}else{
cur = stack.pop();
result.add(cur.val);
cur = cur.right;
}
}
return result;
}後序遍歷
後續遍歷是左右中,那麼我們只需要調整一下先序遍歷的代碼順序,就變成中右左的遍歷順序,然後在反轉result數組,輸出的結果順序就是左右中了
// 後序遍歷順序 左-右-中 入棧順序:中-左-右 出棧順序:中-右-左, 最後翻轉結果
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null){
return result;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()){
TreeNode node = stack.pop();
result.add(node.val);
if (node.left != null){
stack.push(node.left);
}
if (node.right != null){
stack.push(node.right);
}
}
Collections.reverse(result);
return result;
}二叉樹的分類
二叉樹(Binary tree)是每個節點最多隻有兩個分支(即不存在分支度大於 2 的節點)的樹結構。
二叉樹 的分支通常被稱作“左子樹”或“右子樹”。並且,二叉樹 的分支具有左右次序,不能隨意顛倒。
二叉樹 的第 i 層至多擁有 2^(i-1) 個節點,深度為 k 的二叉樹至多總共有 2^(k+1)-1 個節點(滿二叉樹的情況),至少有 2^(k) 個節點(關於節點的深度的定義國內爭議比較多,我個人比較認可維基百科對節點深度的定義)。

⼆叉樹在Java 中表示:
public class TreeLinkNode {
int val;
TreeLinkNode left = null;
TreeLinkNode right = null;
TreeLinkNode next = null;
TreeLinkNode(int val) {
this.val = val;
}
}滿二叉樹
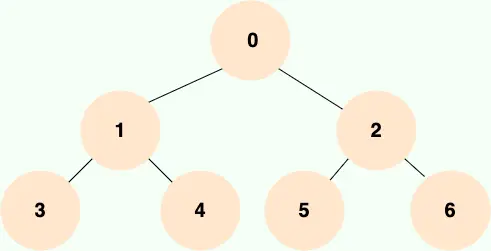
一個二叉樹,如果每一個層的結點數都達到最大值,則這個二叉樹就是 滿二叉樹。也就是説,如果一個二叉樹的層數為 K,且結點總數是(2^k) -1 ,則它就是 滿二叉樹。如下圖所示:
完全二叉樹
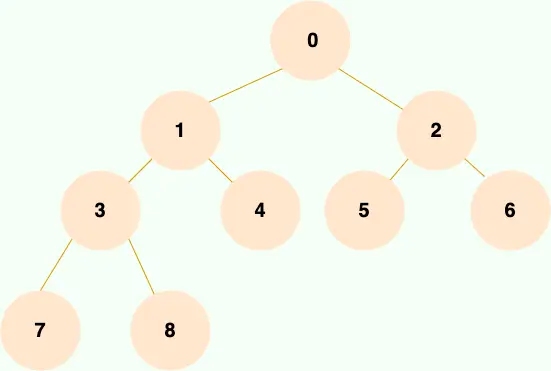
除最後一層外,若其餘層都是滿的,並且最後一層或者是滿的,或者是在右邊缺少連續若干節點,則這個二叉樹就是 完全二叉樹 。
大家可以想象為一棵樹從根結點開始擴展,擴展完左子節點才能開始擴展右子節點,每擴展完一層,才能繼續擴展下一層。如下圖所示:
完全二叉樹有一個很好的性質:父結點和子節點的序號有着對應關係。
細心的小夥伴可能發現了,當根節點的值為 1 的情況下,若父結點的序號是 i,那麼左子節點的序號就是 2i,右子節點的序號是 2i+1。這個性質使得完全二叉樹利用數組存儲時可以極大地節省空間,以及利用序號找到某個節點的父結點和子節點,後續二叉樹的存儲會詳細介紹。
若最底層為第 h 層(h從1開始),則該層包含 1~ 2^(h-1) 個節點。
二叉搜索樹
前面介紹的樹,都沒有數值的,而二叉搜索樹是有數值的了,二叉搜索樹是一個有序樹。
- 若它的左子樹不空,則左子樹上所有結點的值均小於它的根結點的值;
- 若它的右子樹不空,則右子樹上所有結點的值均大於它的根結點的值;
- 它的左、右子樹也分別為二叉排序樹
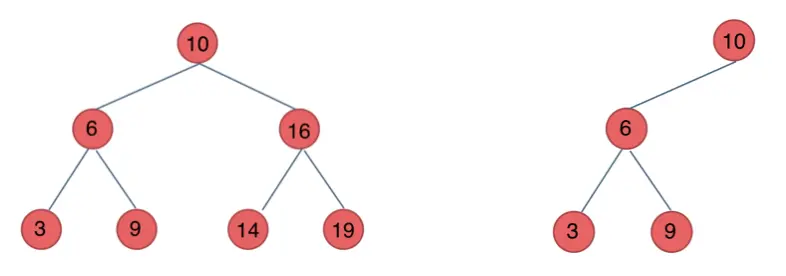
下面這兩棵樹都是搜索樹
平衡二叉搜索樹(AVL樹)
平衡二叉樹 是一棵二叉排序樹,且具有以下性質:
- 可以是一棵空樹
- 如果不是空樹,它的左右兩個子樹的高度差的絕對值不超過 1,並且左右兩個子樹都是一棵平衡二叉樹。
平衡二叉樹的常用實現方法有 紅黑樹、替罪羊樹、加權平衡樹、伸展樹 等。
在給大家展示平衡二叉樹之前,先給大家看一棵樹:
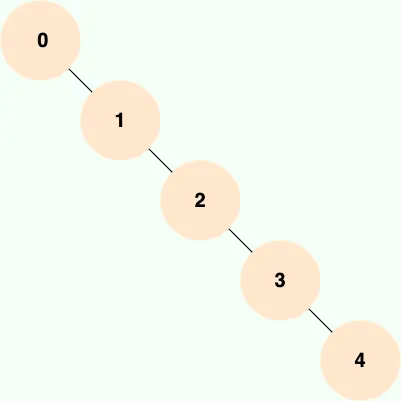
你管這玩意兒叫樹???
沒錯,這玩意兒還真叫樹,只不過這棵樹已經退化為一個鏈表了,我們管它叫 斜樹。
如果這樣,那我為啥不直接用鏈表呢?
誰説不是呢?
二叉樹相比於鏈表,由於父子節點以及兄弟節點之間往往具有某種特殊的關係,這種關係使得我們在樹中對數據進行搜索和修改時,相對於鏈表更加快捷便利。
但是,如果二叉樹退化為一個鏈表了,那麼那麼樹所具有的優秀性質就難以表現出來,效率也會大打折,為了避免這樣的情況,我們希望每個做 “家長”(父結點) 的,都 一碗水端平,分給左兒子和分給右兒子的儘可能一樣多,相差最多不超過一層,如下圖所示:
基本操作
-
查找元素
- 時間複雜度:O(log n)
- 方法:與普通二叉搜索樹相同
-
插入元素
- 時間複雜度:O(log n)
-
步驟:
- 執行標準二叉搜索樹插入
- 更新受影響節點的高度
- 計算平衡因子
- 如失衡,執行旋轉操作恢復平衡
-
刪除元素
- 時間複雜度:O(log n)
-
步驟:
- 執行標準二叉搜索樹刪除
- 更新受影響節點的高度
- 計算平衡因子
- 如失衡,執行旋轉操作恢復平衡
-
旋轉操作
- 左旋(LL):針對右子樹高於左子樹過多
- 右旋(RR):針對左子樹高於右子樹過多
- 左右旋(LR):先對左子樹進行左旋,再對節點進行右旋
- 右左旋(RL):先對右子樹進行右旋,再對節點進行左旋
基礎實現
/**
* AVL樹的Java實現
*/
public class AVLTree {
// 樹節點定義
class Node {
int key; // 節點值
Node left; // 左子節點
Node right; // 右子節點
int height; // 節點高度
Node(int key) {
this.key = key;
this.height = 1; // 新節點高度初始為1
}
}
Node root; // 根節點
// 獲取節點高度,空節點高度為0
private int height(Node node) {
if (node == null) {
return 0;
}
return node.height;
}
// 獲取節點的平衡因子
private int getBalanceFactor(Node node) {
if (node == null) {
return 0;
}
return height(node.left) - height(node.right);
}
// 更新節點高度
private void updateHeight(Node node) {
if (node == null) {
return;
}
node.height = Math.max(height(node.left), height(node.right)) + 1;
}
// 右旋轉(處理左左情況)
private Node rotateRight(Node y) {
Node x = y.left;
Node T2 = x.right;
// 執行旋轉
x.right = y;
y.left = T2;
// 更新高度
updateHeight(y);
updateHeight(x);
return x; // 返回新的根節點
}
// 左旋轉(處理右右情況)
private Node rotateLeft(Node x) {
Node y = x.right;
Node T2 = y.left;
// 執行旋轉
y.left = x;
x.right = T2;
// 更新高度
updateHeight(x);
updateHeight(y);
return y; // 返回新的根節點
}
// 插入節點
public void insert(int key) {
root = insertNode(root, key);
}
private Node insertNode(Node node, int key) {
// 1. 執行標準BST插入
if (node == null) {
return new Node(key);
}
if (key < node.key) {
node.left = insertNode(node.left, key);
} else if (key > node.key) {
node.right = insertNode(node.right, key);
} else {
// 相同鍵值不做處理,或根據需求更新節點
return node;
}
// 2. 更新節點高度
updateHeight(node);
// 3. 獲取平衡因子
int balance = getBalanceFactor(node);
// 4. 如果節點失衡,進行旋轉調整
// 左左情況 - 右旋
if (balance > 1 && getBalanceFactor(node.left) >= 0) {
return rotateRight(node);
}
// 右右情況 - 左旋
if (balance < -1 && getBalanceFactor(node.right) <= 0) {
return rotateLeft(node);
}
// 左右情況 - 左右雙旋
if (balance > 1 && getBalanceFactor(node.left) < 0) {
node.left = rotateLeft(node.left);
return rotateRight(node);
}
// 右左情況 - 右左雙旋
if (balance < -1 && getBalanceFactor(node.right) > 0) {
node.right = rotateRight(node.right);
return rotateLeft(node);
}
// 返回未變化的節點引用
return node;
}
// 查找最小值節點
private Node findMinNode(Node node) {
Node current = node;
while (current.left != null) {
current = current.left;
}
return current;
}
// 刪除節點
public void delete(int key) {
root = deleteNode(root, key);
}
private Node deleteNode(Node root, int key) {
// 1. 執行標準BST刪除
if (root == null) {
return root;
}
if (key < root.key) {
root.left = deleteNode(root.left, key);
} else if (key > root.key) {
root.right = deleteNode(root.right, key);
} else {
// 找到要刪除的節點
// 情況1:葉子節點或只有一個子節點
if (root.left == null || root.right == null) {
Node temp = (root.left != null) ? root.left : root.right;
// 沒有子節點
if (temp == null) {
root = null;
} else {
// 一個子節點
root = temp;
}
} else {
// 情況2:有兩個子節點
// 找到右子樹的最小節點(中序後繼)
Node temp = findMinNode(root.right);
// 複製中序後繼的值到當前節點
root.key = temp.key;
// 刪除中序後繼
root.right = deleteNode(root.right, temp.key);
}
}
// 如果樹只有一個節點,刪除後直接返回
if (root == null) {
return root;
}
// 2. 更新高度
updateHeight(root);
// 3. 獲取平衡因子
int balance = getBalanceFactor(root);
// 4. 進行旋轉操作保持平衡
// 左左情況
if (balance > 1 && getBalanceFactor(root.left) >= 0) {
return rotateRight(root);
}
// 左右情況
if (balance > 1 && getBalanceFactor(root.left) < 0) {
root.left = rotateLeft(root.left);
return rotateRight(root);
}
// 右右情況
if (balance < -1 && getBalanceFactor(root.right) <= 0) {
return rotateLeft(root);
}
// 右左情況
if (balance < -1 && getBalanceFactor(root.right) > 0) {
root.right = rotateRight(root.right);
return rotateLeft(root);
}
return root;
}
// 查找節點
public boolean search(int key) {
return searchNode(root, key);
}
private boolean searchNode(Node root, int key) {
if (root == null) {
return false;
}
if (key == root.key) {
return true;
}
if (key < root.key) {
return searchNode(root.left, key);
} else {
return searchNode(root.right, key);
}
}
}優點
- 查找效率高:保證O(log n)的查找、插入和刪除操作時間複雜度
- 自平衡:自動調整樹的結構,防止最壞情況出現
- 穩定性:所有操作都有穩定的性能表現
- 可預測性:樹高被嚴格限制,便於分析性能
缺點
- 實現複雜:相比普通二叉搜索樹,實現複雜度高
- 額外空間:每個節點需要存儲高度信息
- 旋轉開銷:插入刪除過程中的旋轉操作增加了額外計算開銷
- 頻繁平衡調整:對於高頻插入刪除的場景,頻繁的平衡調整可能影響性能
應用場景
AVL樹是最早被髮明的自平衡二叉搜索樹之一,適用於許多需要高效查找和維持數據有序性的場景。
比如內存管理器經常使用AVL樹跟蹤內存塊的分配與釋放。
在需要頻繁執行範圍查詢的應用中,AVL樹也比較適用,常用於實現區間查詢功能。
相關的 LeetCode 熱門題目
- 98. 驗證二叉搜索樹 - 要求驗證一個給定的二叉樹是否是有效的二叉搜索樹。
- 700. 二叉搜索樹中的搜索 - 在二叉搜索樹中查找指定值的節點。
- 701. 二叉搜索樹中的插入操作 - 在不破壞二叉搜索樹性質的前提下插入新節點。
- 450. 刪除二叉搜索樹中的節點 - 實現二叉搜索樹的刪除操作。
擴展:其它樹形結構
二叉堆
二叉堆是一種特殊的完全二叉樹,常用於實現優先隊列。最小堆的每個節點的值都小於或等於其子節點的值,最大堆的每個節點的值都大於或等於其子節點的值。二叉堆支持高效的插入、刪除最值和構建操作。
二叉堆是一種特殊的完全二叉樹數據結構,它滿足堆屬性。完全二叉樹是指除了最後一層外,其他層的節點都是滿的,而最後一層的節點都靠左排列。二叉堆主要有兩種類型:
- 最大堆:每個父節點的值都大於或等於其子節點的值
- 最小堆:每個父節點的值都小於或等於其子節點的值
二叉堆的這種特殊結構使得它可以高效地找到最大值或最小值,所以也常被用來實現優先隊列。
二叉堆的核心特性如下:
- 完全二叉樹結構:除最底層外,每層都填滿,且最底層從左到右填充
-
堆序性質:
- 最大堆:父節點值 ≥ 子節點值
- 最小堆:父節點值 ≤ 子節點值
- 高效的頂部元素訪問:可以在O(1)時間內獲取最大/最小元素
- 數組表示:雖然概念上是樹結構,但通常用數組實現,這樣可以節省指針開銷並提高內存局部性
基本操作
-
插入元素(Insert)
- 首先將新元素添加到堆的末尾
- 然後通過"上浮"操作調整堆,直到滿足堆性質
-
刪除頂部元素(Extract-Max/Min):移除並返回堆頂元素(最大/最小值)
- 取出堆頂元素
- 將堆的最後一個元素移到堆頂
- 通過"下沉"操作調整堆,直到滿足堆性質
-
上浮(Heapify-Up):將一個元素向上移動到合適位置的過程
- 比較當前元素與其父節點
- 如果不滿足堆性質,則交換它們
- 重複此過程直到滿足堆性質
-
下沉(Heapify-Down):將一個元素向下移動到合適位置的過程
- 比較當前元素與其最大(或最小)的子節點
- 如果不滿足堆性質,則交換它們
- 重複此過程直到滿足堆性質
基礎實現
public class MinHeap {
private int[] heap;
private int size;
private int capacity;
// 構造函數
public MinHeap(int capacity) {
this.capacity = capacity;
this.size = 0;
this.heap = new int[capacity];
}
// 獲取父節點索引
private int parent(int i) {
return (i - 1) / 2;
}
// 獲取左子節點索引
private int leftChild(int i) {
return 2 * i + 1;
}
// 獲取右子節點索引
private int rightChild(int i) {
return 2 * i + 2;
}
// 交換兩個節點
private void swap(int i, int j) {
int temp = heap[i];
heap[i] = heap[j];
heap[j] = temp;
}
// 插入元素
public void insert(int key) {
if (size == capacity) {
System.out.println("堆已滿,無法插入");
return;
}
// 先將新元素插入到堆的末尾
heap[size] = key;
int current = size;
size++;
// 上浮操作:將元素向上移動到合適位置
while (current > 0 && heap[current] < heap[parent(current)]) {
swap(current, parent(current));
current = parent(current);
}
}
// 獲取最小元素(不刪除)
public int peek() {
if (size <= 0) {
System.out.println("堆為空");
return -1;
}
return heap[0];
}
// 刪除並返回最小元素
public int extractMin() {
if (size <= 0) {
System.out.println("堆為空");
return -1;
}
if (size == 1) {
size--;
return heap[0];
}
// 存儲根節點(最小值)
int root = heap[0];
// 將最後一個元素放到根位置
heap[0] = heap[size - 1];
size--;
// 下沉操作:將根元素向下移動到合適位置
heapifyDown(0);
return root;
}
// 下沉操作
private void heapifyDown(int i) {
int smallest = i;
int left = leftChild(i);
int right = rightChild(i);
// 找出當前節點、左子節點和右子節點中的最小值
if (left < size && heap[left] < heap[smallest]) {
smallest = left;
}
if (right < size && heap[right] < heap[smallest]) {
smallest = right;
}
// 如果最小值不是當前節點,則交換並繼續下沉
if (smallest != i) {
swap(i, smallest);
heapifyDown(smallest);
}
}
// 打印堆
public void printHeap() {
for (int i = 0; i < size; i++) {
System.out.print(heap[i] + " ");
}
System.out.println();
}
public static void main(String[] args) {
MinHeap minHeap = new MinHeap(10);
minHeap.insert(5);
minHeap.insert(3);
minHeap.insert(8);
minHeap.insert(1);
minHeap.insert(10);
System.out.println("構建的堆:");
minHeap.printHeap();
System.out.println("最小元素:" + minHeap.peek());
System.out.println("提取最小元素:" + minHeap.extractMin());
System.out.println("提取後的堆:");
minHeap.printHeap();
}
}優點
- 高效的優先級操作:O(1) 時間複雜度查找最大/最小元素
- 相對較快的插入和刪除:O(log n) 時間複雜度
- 空間效率高:數組實現不需要額外的指針開銷
- 實現簡單:相比其他高級數據結構,二叉堆實現相對簡單
- 內存局部性好:連續內存存儲提高緩存命中率
缺點
- 有限的操作集:只支持查找最值,不支持高效的搜索、刪除任意元素等操作
- 不支持快速合併:合併兩個堆的操作較為複雜
- 不穩定性:相同優先級的元素,其相對順序可能改變
- 對緩存不友好的訪問模式:特別是在堆較大時,父子節點間的跳躍訪問可能導致緩存未命中
應用場景
二叉堆廣泛應用於各種算法和系統中:
- 優先隊列實現:當需要頻繁獲取最大或最小元素時,二叉堆是最常用的數據結構。操作系統中的進程調度、網絡路由算法都會使用優先隊列來確定下一個處理的任務。
- 排序算法:堆排序利用二叉堆的特性,能夠以O(n log n)的時間複雜度對數據進行排序,且空間複雜度為O(1),適合大數據排序。
- 圖算法:許多圖算法如Dijkstra最短路徑、Prim最小生成樹算法都使用優先隊列來選擇下一個處理的節點,二叉堆是其高效實現。
- 中位數和百分位數計算:通過維護兩個堆(最大堆和最小堆),可以高效地跟蹤數據流的中位數和其他統計值。
- 事件模擬:在離散事件模擬中,事件按時間順序處理,優先隊列可以確保按正確順序處理事件。
- 數據流處理:在處理大量數據流時,如果只需要關注"最重要"的k個元素,可以維護一個大小為k的堆。
Java標準庫中的堆實現
Java 提供了 PriorityQueue 類,它基於二叉堆實現:
import java.util.PriorityQueue;
public class PriorityQueueExample {
public static void main(String[] args) {
// 默認是最小堆
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
// 添加元素
minHeap.add(5);
minHeap.add(3);
minHeap.add(8);
minHeap.add(1);
minHeap.add(10);
System.out.println("優先隊列內容:" + minHeap);
System.out.println("最小元素:" + minHeap.peek());
System.out.println("提取最小元素:" + minHeap.poll());
System.out.println("提取後的優先隊列:" + minHeap);
// 創建最大堆(通過自定義比較器)
PriorityQueue<Integer> maxHeap = new PriorityQueue<>((a, b) -> b - a);
maxHeap.add(5);
maxHeap.add(3);
maxHeap.add(8);
maxHeap.add(1);
maxHeap.add(10);
System.out.println("最大堆內容:" + maxHeap);
System.out.println("最大元素:" + maxHeap.peek());
}
}詳情可以看:PriorityQueue
堆的變種
除了基本的二叉堆,還有幾種重要的堆變種:
- d叉堆(d-ary Heap):每個節點最多有d個子節點,而不是2個。增加d值可以減少堆的高度,在某些應用中可以提高性能。
- 斐波那契堆(Fibonacci Heap):一種更復雜的堆結構,提供了更高效的合併操作和攤銷時間複雜度。許多高級圖算法使用斐波那契堆來提高性能。
- 左偏樹(Leftist Heap):一種支持高效合併操作的堆,常用於並行計算和分佈式系統。
- 配對堆(Pairing Heap):結構簡單但性能優異的堆實現,特別適合需要頻繁合併和減小鍵值的應用。
相關的 LeetCode 熱門題目
- 23. 合併K個排序鏈表 - 使用最小堆來高效合併多個有序鏈表。
- 347. 前 K 個高頻元素 - 使用堆來找出數組中出現頻率最高的K個元素。
- 295. 數據流的中位數 - 使用一個最大堆和一個最小堆來跟蹤數據流的中位數。
B樹
B樹是一種自平衡的多路搜索樹,它是二叉搜索樹的擴展,專為磁盤或其他外部存儲設備設計。B樹的每個節點擁有更多的子節點,這使樹的高度更低,減少訪問磁盤的次數。
B樹中的幾個關鍵概念:
- 階(Order):定義了一個B樹節點最多可以有多少個子節點。具有階為m的B樹也稱為m階B樹。
- 內部節點(Internal Node):除根節點和葉節點外的所有節點。
- 葉節點(Leaf Node):沒有子節點的節點。
- 鍵(Key):存儲在節點中的值,用於指導搜索過程。
- 子節點(Child):節點的直接後代。
一個階為m的B樹滿足以下性質:
- 每個節點最多有m個子節點
- 除了根節點和葉節點,每個節點至少有⌈m/2⌉個子節點
- 如果根節點不是葉節點,則至少有兩個子節點
- 所有葉節點都在同一層
- 具有k個子節點的非葉節點包含k-1個鍵
B樹核心特性:
- 自平衡性:B樹通過分裂和合並操作保持平衡,確保所有操作的對數時間複雜度。
- 多路分支:每個節點可以有多個子節點,而不僅僅是二叉樹的兩個,這降低了樹的高度。
- 有序特性:B樹中的鍵是有序存儲的,使得搜索、插入和刪除操作高效。
- 適合外部存儲:B樹的設計是為了最小化磁盤訪問次數,特別適合處理大量數據時。
- 分塊存儲:鍵和指針組織在塊中,這種結構與磁盤頁面或數據塊的物理特性匹配。
基本操作
-
搜索操作:搜索B樹中的鍵與搜索二叉搜索樹類似,但需要在每個節點中遍歷多個鍵
- 從根節點開始
- 在當前節點內部按順序查找目標鍵
- 如果找到,返回結果
- 如果未找到且節點是葉節點,則鍵不存在
- 否則,根據鍵的大小選擇合適的子樹繼續搜索
-
插入操作
- 找到合適的葉節點位置
- 將鍵插入到葉節點中
-
如果插入導致節點超出最大容量,則分裂節點:
- 選擇中間鍵
- 將中間鍵上移到父節點
- 將原節點分為兩個節點
- 如果父節點也超出容量,則繼續向上分裂
-
刪除操作
- 找到包含要刪除鍵的節點
- 如果節點是葉節點,直接刪除
- 如果節點是內部節點,用前驅或後繼替換要刪除的鍵
-
如果刪除導致節點鍵數量少於最小要求:
- 嘗試從兄弟節點借一個鍵
- 如果無法借用,則合併節點
優點
- 減少磁盤訪問:B樹的高度通常很低,即使存儲大量數據也只需要少量磁盤訪問。
- 適合大數據量:因為每個節點可以包含多個鍵,B樹可以有效地存儲和檢索大量數據。
- 平衡性保證:B樹始終保持平衡,沒有最壞情況性能下降的問題。
- 高效的範圍查詢:由於鍵是有序的,B樹支持高效的範圍查詢操作。
- 適合外部存儲:B樹的結構非常適合磁盤等外部存儲系統,使其成為數據庫索引的理想選擇。
缺點
- 實現複雜:與二叉樹相比,B樹的實現更為複雜,特別是刪除操作。
- 空間利用率:B樹節點可能未被完全填充,導致一定程度的空間浪費。
- 不適合內存操作:對於完全在內存中的數據結構,B樹的優勢不明顯,可能比其他平衡樹(如紅黑樹)效率低。
- 更新開銷:插入和刪除操作可能導致級聯的節點分裂或合併,增加了操作的複雜性。
應用場景
數據庫系統是B樹最主要的應用領域。幾乎所有主流關係數據庫都使用B樹或其變種來實現索引。數據庫引擎通過B樹索引可以快速定位到數據所在的頁面,極大提升查詢性能。例如,MySQL的InnoDB存儲引擎使用B+樹(B樹的變種)來構建其索引結構。
文件系統也廣泛採用B樹來組織文件和目錄。如NTFS、HFS+等文件系統都使用B樹或其變種來管理文件分配表和目錄結構,有效地支持大型存儲系統中的文件檢索。
時間序列數據庫或地理信息系統中,經常需要檢索特定範圍內的數據點,B樹的有序特性使這類操作變得高效。
鍵值存儲系統如Redis、LevelDB等也借鑑了B樹的設計理念。雖然它們可能使用了不同的變種或混合結構,但基本思想源自B樹的高效查找和範圍操作特性。
B樹的變種
B+樹是B樹的一個重要變種,它在數據庫系統中更為常用:
- 所有數據都存儲在葉節點
- 內部節點僅包含鍵,不包含數據
- 葉節點通過鏈表連接,支持更高效的順序訪問
- 適合範圍查詢和順序掃描
B* 樹對B樹進行了進一步優化:
- 非根節點至少2/3滿(而不是1/2)
- 在節點分裂前先嚐試與兄弟節點重新分配
- 分裂時涉及兩個節點變為三個節點
- 提高了空間利用率
B+樹
B+樹是一種平衡樹數據結構,是B樹的變種,被廣泛應用於數據庫索引和文件系統中。B+樹保持數據有序,而且能夠高效地進行查找、順序訪問、插入和刪除操作。
B+樹的主要組成部分包括:
- 節點:B+樹中的基本單元,分為內部節點和葉子節點
- 內部節點:只存儲鍵值和指向子節點的指針,不存儲數據
- 葉子節點:存儲鍵值和真實數據(或指向數據的指針)
- 階數(order):表示一個節點最多可以有多少個子節點,通常用m表示
- 鏈表:所有葉子節點形成一個有序鏈表,方便範圍查詢
B+樹核心特性
- 所有數據都存儲在葉子節點上:內部節點只存儲鍵值和指針,不存儲實際數據
- 所有葉子節點通過指針連接成有序鏈表:便於範圍查詢和順序遍歷
- 平衡樹結構:所有葉子節點到根節點的距離相同
- 高扇出性(High Fan-out):每個節點可以包含多個鍵值和指針,減少樹的高度
- 自平衡:在插入和刪除操作後自動調整以保持平衡
基本操作
-
查找操作
- 從根節點開始,根據鍵值比較確定應該查找哪個子節點
- 遞歸向下查找,直到到達葉子節點
- 在葉子節點中查找目標數據
-
插入操作
- 找到應插入的葉子節點
- 將數據插入到該葉子節點
-
如果葉子節點溢出(超過最大容量):
- 分裂節點為兩部分
- 選擇一個鍵值上升到父節點
- 如有必要,遞歸向上分裂
-
刪除操作
- 找到包含目標數據的葉子節點
- 從葉子節點中刪除數據
-
如果節點下溢(低於最小容量要求):
- 嘗試從相鄰節點借用數據
- 如果無法借用,則合併節點
- 如有必要,遞歸向上調整
優點
- 高效的範圍查詢:葉子節點構成鏈表,可以快速進行範圍查詢
- 更少的IO操作:高扇出性使樹高度較低,減少磁盤訪問次數
- 適合外部存儲:節點可以映射到磁盤塊,優化磁盤IO
- 動態平衡:插入刪除後自動維持平衡狀態
- 較大的分支因子:每個節點可以存儲更多鍵值,減少樹的高度
缺點
- 實現複雜:相比簡單的樹結構,實現較為複雜
- 修改開銷大:插入和刪除操作可能導致節點分裂或合併,級聯影響多個節點
- 空間利用率:內部節點不存儲數據,可能導致空間利用率不如其他結構
- 不適合頻繁更新的場景:頻繁的插入刪除操作會導致頻繁的樹結構調整
應用場景
B+樹在數據庫系統和文件系統中得到了廣泛應用。在數據庫領域,幾乎所有主流關係型數據庫的索引結構都採用了B+樹或其變種。MySQL的InnoDB存儲引擎使用B+樹作為其主要索引結構,通過將數據按主鍵順序組織在葉子節點中,實現了高效的查詢和範圍掃描操作。
在文件系統中,B+樹被用於管理文件的目錄結構和索引,比如NTFS、ext4等現代文件系統。由於B+樹能夠高效地處理大量數據,同時保持較低的樹高度,使文件系統能夠快速定位和訪問文件。
B+樹還被廣泛應用於地理信息系統(GIS)中的空間索引,快速查找特定地理區域內的對象。
Trie樹
Trie樹,也稱為前綴樹或字典樹,是一種樹形數據結構,專門用於高效存儲和檢索字符串集合。Trie這個名字來源於"retrieval"(檢索)一詞,反映了它的主要用途。
在Trie樹中,每個節點代表一個字符,從根節點到某一節點的路徑上經過的字符連接起來,就是該節點對應的字符串。Trie樹的關鍵特點是,所有擁有相同前綴的字符串,在樹中共享這個前綴的存儲空間。
Trie樹核心特性
- 前綴共享: 具有相同前綴的字符串在Trie樹中共享存儲空間,大大節省了內存
- 快速查找: 查找一個長度為k的字符串的時間複雜度為O(k),與Trie樹中存儲的字符串總數無關
- 詞彙關聯: 通過前綴可以輕鬆找到所有具有該前綴的單詞
- 有序性: Trie樹天然地保持了字典序
基本操作
Trie樹支持以下基本操作:
- 插入(Insert): 將一個字符串添加到Trie樹中
- 查找(Search): 檢查一個完整的字符串是否存在於Trie樹中
- 前綴查找(StartsWith): 檢查Trie樹中是否有以給定前綴開頭的字符串
- 刪除(Delete): 從Trie樹中刪除一個字符串(相對複雜)
基礎實現
class Trie {
private TrieNode root;
// Trie樹的節點結構
class TrieNode {
// 子節點,使用數組實現(假設只包含小寫字母a-z)
private TrieNode[] children;
// 標記該節點是否為某個單詞的結尾
private boolean isEndOfWord;
public TrieNode() {
children = new TrieNode[26]; // 26個英文字母
isEndOfWord = false;
}
}
/** 初始化Trie樹 */
public Trie() {
root = new TrieNode();
}
/** 向Trie樹中插入單詞 */
public void insert(String word) {
TrieNode current = root;
for (int i = 0; i < word.length(); i++) {
char ch = word.charAt(i);
int index = ch - 'a'; // 將字符轉換為索引
// 如果當前字符的節點不存在,創建一個新節點
if (current.children[index] == null) {
current.children[index] = new TrieNode();
}
// 移動到下一個節點
current = current.children[index];
}
// 標記單詞結束
current.isEndOfWord = true;
}
/** 查找Trie樹中是否存在完整單詞 */
public boolean search(String word) {
TrieNode node = searchPrefix(word);
// 節點存在且是單詞結尾
return node != null && node.isEndOfWord;
}
/** 查找Trie樹中是否存在指定前綴 */
public boolean startsWith(String prefix) {
// 只需要節點存在即可
return searchPrefix(prefix) != null;
}
/** 查找前綴對應的節點 */
private TrieNode searchPrefix(String prefix) {
TrieNode current = root;
for (int i = 0; i < prefix.length(); i++) {
char ch = prefix.charAt(i);
int index = ch - 'a';
// 如果當前字符的節點不存在,返回null
if (current.children[index] == null) {
return null;
}
current = current.children[index];
}
return current;
}
/** 從Trie樹中刪除單詞(較複雜的操作) */
public void delete(String word) {
delete(root, word, 0);
}
private boolean delete(TrieNode current, String word, int index) {
// 已經處理完所有字符
if (index == word.length()) {
// 如果不是單詞結尾,單詞不存在
if (!current.isEndOfWord) {
return false;
}
// 取消標記單詞結尾
current.isEndOfWord = false;
// 如果節點沒有子節點,可以刪除
return hasNoChildren(current);
}
char ch = word.charAt(index);
int childIndex = ch - 'a';
TrieNode child = current.children[childIndex];
// 如果字符對應的節點不存在,單詞不存在
if (child == null) {
return false;
}
// 遞歸刪除子節點
boolean shouldDeleteChild = delete(child, word, index + 1);
// 如果子節點應該被刪除
if (shouldDeleteChild) {
current.children[childIndex] = null;
// 如果當前節點不是單詞結尾且沒有其他子節點,則它也可以被刪除
return !current.isEndOfWord && hasNoChildren(current);
}
return false;
}
private boolean hasNoChildren(TrieNode node) {
for (TrieNode child : node.children) {
if (child != null) {
return false;
}
}
return true;
}
}優點
- 高效的字符串檢索:查找、插入和刪除操作的時間複雜度與字符串長度成正比(O(k)),而與存儲的字符串總數無關
- 節省空間:通過共享前綴,減少了重複存儲
- 支持按字典序遍歷:可以方便地按字典序輸出所有字符串
- 前綴匹配高效:特別適合前綴查詢和自動補全功能
缺點
- 內存消耗:對於不共享前綴的字符串集合,Trie樹可能消耗大量內存
- 空間複雜度高:每個節點需要存儲所有可能字符的引用(如上例中每個節點存儲26個子節點引用)
- 不適合單次查詢:如果只需要進行單次的精確字符串查詢,哈希表可能是更好的選擇
- 實現較為複雜:特別是刪除操作,需要額外的邏輯來處理節點的清理
應用場景
- 自動補全和拼寫檢查:當用户在搜索框中輸入時,Trie樹可以快速找到所有以當前輸入為前綴的單詞,提供智能提示。輸入法和文本編輯器通常利用這一特性實現單詞補全功能。
- IP路由表:網絡路由器使用類似Trie的結構來存儲IP地址,實現高效的最長前綴匹配。
- 字典和詞彙表:電子字典應用可以使用Trie樹來存儲詞彙,支持快速查找和前綴搜索。
- 文本分析:在自然語言處理中,Trie樹可以用於單詞頻率統計、關鍵詞提取等任務。
- 電話號碼簿:通訊錄應用可以使用Trie樹來存儲聯繫人信息,支持按號碼前綴搜索。
相關的LeetCode熱門題目
- 208. 實現 Trie (前綴樹) - 基礎題,要求實現Trie樹的基本操作。
- 211. 添加與搜索單詞 - 數據結構設計 - 在基本Trie的基礎上增加了通配符匹配功能。
- 212. 單詞搜索 II - 使用Trie樹優化在二維字符網格中搜索單詞的過程。
- 648. 單詞替換 - 使用Trie樹查找詞根並替換單詞。
- 1032. 字符流 - 設計一個數據結構,支持對字符流的查詢,判斷最近添加的字符是否形成了給定單詞集合中的某個單詞的後綴。
樹狀數組
樹狀數組(Binary Indexed Tree),也稱為Fenwick Tree,是一種支持高效的前綴和計算和單點更新的數據結構。它的核心思想是利用二進制的性質來維護數據間的層級關係,從而在O(log n)的時間內完成查詢和更新操作。
樹狀數組的關鍵概念是"父子關係",這種關係是通過二進制表示中的最低位1來確定的。對於任意一個節點i,它的父節點是i + (i & -i),它的子節點是i - (i & -i)。
- i & -i 表達式計算的是i的二進制表示中的最低位1對應的值
- 例如:6的二進制是110,6&(-6) = 6&(010) = 2
樹狀數組通常使用一個一維數組表示,採用1-indexed(即從索引1開始存儲有效數據)的方式:
- BIT[i]存儲了原始數組中某個區間的和
- 每個BIT[i]負責管理的區間長度由i & -i決定
- 例如,BIT[6]管理的區間長度是2,包含原始數組中的A[5]和A[6]
基本操作
-
更新操作(update):更新原始數組中索引i的值時,需要更新樹狀數組中所有包含該索引的節點。
- 從索引i開始
- 不斷地加上i & -i,直到超出數組範圍
- 在每一步都更新對應的樹狀數組值
public void update(int i, int delta) {
i = i + 1; // 轉為1-based索引
while (i <= n) {
bit[i] += delta;
i += i & -i; // 移動到父節點
}
}-
查詢前綴和(query):查詢從1到i的所有元素的和。
- 從索引i開始
- 不斷地減去i & -i,直到i變為0
- 在每一步都累加對應的樹狀數組值
public int query(int i) {
i = i + 1; // 轉為1-based索引
int sum = 0;
while (i > 0) {
sum += bit[i];
i -= i & -i; // 移動到前一個節點
}
return sum;
}時間複雜度:
- 初始化:O(n log n)
- 單點更新:O(log n)
- 前綴和查詢:O(log n)
- 區間查詢:O(log n)
應用場景
樹狀數組在以下場景中特別有用:
- 頻繁的區間查詢和單點更新:如果需要經常計算前綴和並且數組中的值會頻繁變化,樹狀數組是一個很好的選擇。
- 計數應用:如逆序對計數、區間統計等。
- 2D/多維前綴和:樹狀數組可以很容易地擴展到多維空間,處理二維甚至多維的前綴和查詢。
- 動態排名統計:通過樹狀數組可以維護一個動態的排名統計。
樹狀數組的優勢
- 實現簡單:相比於線段樹,樹狀數組的代碼更加簡潔。
- 常數因子小:在實際應用中,樹狀數組通常比線段樹更快,因為它的常數因子更小。
- 空間效率高:樹狀數組只需要與原始數組相同大小的空間。
區間更新
通過差分數組技術,樹狀數組可以支持區間更新,但查詢變為單點查詢,這樣就能在O(log n)時間內完成區間更新操作。
// 創建樹狀數組(假設已實現BinaryIndexedTree類)
BinaryIndexedTree bit = new BinaryIndexedTree(new int[]{0, 2, 1, 4, 3, 6, 5});
// 查詢前綴和
System.out.println("query(2): " + bit.query(2)); // 索引0到2的和: 2+1+4=7
// 更新元素值
bit.update(1, 2); // 將索引1的元素增加2
System.out.println("query(2): " + bit.query(2)); // 現在索引0到2的和: 2+(1+2)+4=9
// 區間查詢
System.out.println("rangeQuery(1, 3): " + bit.rangeQuery(1, 3)); // 索引1到3的和: (1+2)+4+3=10線段樹
線段樹(Segment Tree)是一種高效的數據結構,專門用於解決區間查詢和區間修改問題。與樹狀數組相比,線段樹功能更加強大,可以支持更多種類的區間操作。
線段樹的核心思想是通過分治法將一個區間劃分為多個子區間,並用樹的形式組織這些區間的信息。在這棵樹中,每個節點代表一個區間,根節點代表整個數組區間,葉子節點代表單個元素。
核心概念解釋:
- 區間查詢:查詢數組中某個區間的聚合信息(如區間和、最大值、最小值等)
- 區間修改:修改數組中某個區間內所有元素的值
- 懶惰標記(Lazy Propagation):延遲更新策略,用於提高區間修改的效率
- 樹節點:每個節點存儲其對應區間的信息,如區間和、最大值等
線段樹核心特性:
- 靈活的區間操作:支持各種區間查詢(和、最大值、最小值、異或和等)和區間修改
- 高效的時間複雜度:查詢和修改的時間複雜度均為O(log n)
- 強大的擴展性:可以根據需求自定義區間操作的類型
- 適應動態變化:能夠處理數組內容頻繁變化的情況
線段樹的工作原理
線段樹的結構:
線段樹是一棵完全二叉樹,其中:
- 根節點代表整個數組區間[0, n-1]
- 每個非葉節點的左子節點代表區間的左半部分,右子節點代表右半部分
- 葉子節點代表單個元素(長度為1的區間)
懶惰標記(Lazy Propagation):
懶惰標記是一種優化技術,用於延遲區間修改的傳播。當一個節點的所有子節點都需要被修改時,我們不立即修改這些子節點,而是在節點上標記修改信息,只有在需要訪問子節點時才將修改下推,提高區間修改的效率。
基本操作
- 構建(build):根據初始數組構建線段樹
- 區間查詢(query):查詢某個區間的聚合信息
- 單點修改(update):修改單個元素的值
- 區間修改(updateRange):修改一段區間內所有元素的值(通常使用懶惰標記實現)
基礎實現
下面是線段樹的基礎實現(以區間和為例):
public class SegmentTree {
private int[] tree; // 存儲線段樹節點
private int[] lazy; // 懶惰標記
private int[] nums; // 原始數組的副本
private int n; // 原始數組長度
public SegmentTree(int[] array) {
n = array.length;
// 線段樹數組大小一般為原數組大小的4倍
tree = new int[4 * n];
lazy = new int[4 * n];
nums = array.clone();
build(0, 0, n - 1);
}
// 構建線段樹
private void build(int node, int start, int end) {
if (start == end) {
// 葉子節點,存儲單個元素
tree[node] = nums[start];
return;
}
int mid = (start + end) / 2;
int leftNode = 2 * node + 1;
int rightNode = 2 * node + 2;
// 遞歸構建左右子樹
build(leftNode, start, mid);
build(rightNode, mid + 1, end);
// 合併子節點的信息
tree[node] = tree[leftNode] + tree[rightNode];
}
// 單點修改
public void update(int index, int val) {
// 計算與原值的差值
int diff = val - nums[index];
nums[index] = val;
updateSingle(0, 0, n - 1, index, diff);
}
private void updateSingle(int node, int start, int end, int index, int diff) {
// 檢查索引是否在當前節點範圍內
if (index < start || index > end) {
return;
}
// 更新當前節點的值
tree[node] += diff;
if (start != end) {
int mid = (start + end) / 2;
int leftNode = 2 * node + 1;
int rightNode = 2 * node + 2;
// 遞歸更新子節點
updateSingle(leftNode, start, mid, index, diff);
updateSingle(rightNode, mid + 1, end, index, diff);
}
}
// 區間查詢
public int query(int left, int right) {
return queryRange(0, 0, n - 1, left, right);
}
private int queryRange(int node, int start, int end, int left, int right) {
// 如果當前節點的區間完全在查詢區間外
if (right < start || left > end) {
return 0;
}
// 如果當前節點的區間完全在查詢區間內
if (left <= start && end <= right) {
return tree[node];
}
// 處理懶惰標記
if (lazy[node] != 0) {
tree[node] += (end - start + 1) * lazy[node];
if (start != end) {
lazy[2 * node + 1] += lazy[node];
lazy[2 * node + 2] += lazy[node];
}
lazy[node] = 0;
}
// 查詢範圍部分覆蓋當前節點的區間,需要分別查詢左右子節點
int mid = (start + end) / 2;
int leftSum = queryRange(2 * node + 1, start, mid, left, right);
int rightSum = queryRange(2 * node + 2, mid + 1, end, left, right);
return leftSum + rightSum;
}
// 區間修改
public void updateRange(int left, int right, int val) {
updateRangeTree(0, 0, n - 1, left, right, val);
}
private void updateRangeTree(int node, int start, int end, int left, int right, int val) {
// 處理當前節點的懶惰標記
if (lazy[node] != 0) {
tree[node] += (end - start + 1) * lazy[node];
if (start != end) {
lazy[2 * node + 1] += lazy[node];
lazy[2 * node + 2] += lazy[node];
}
lazy[node] = 0;
}
// 如果當前節點的區間完全在修改區間外
if (right < start || left > end) {
return;
}
// 如果當前節點的區間完全在修改區間內
if (left <= start && end <= right) {
tree[node] += (end - start + 1) * val;
if (start != end) {
lazy[2 * node + 1] += val;
lazy[2 * node + 2] += val;
}
return;
}
// 修改範圍部分覆蓋當前節點的區間,需要分別修改左右子節點
int mid = (start + end) / 2;
updateRangeTree(2 * node + 1, start, mid, left, right, val);
updateRangeTree(2 * node + 2, mid + 1, end, left, right, val);
// 更新當前節點的值
tree[node] = tree[2 * node + 1] + tree[2 * node + 2];
}
}優點
- 功能強大:支持多種區間操作,包括區間求和、最大值、最小值等
- 操作靈活:同時支持區間查詢和區間修改
- 時間效率高:所有操作的時間複雜度均為O(log n)
- 可擴展性好:可以根據具體問題自定義節點存儲的信息和操作方式
缺點
- 內存消耗較大:需要額外的內存來存儲線段樹結構,通常為原數組大小的4倍
- 代碼實現複雜:相比其他數據結構(如樹狀數組),實現和調試更加複雜
- 常數因子較大:雖然時間複雜度是O(log n),但實際運行時間可能比樹狀數組等結構略長
應用場景
線段樹在許多實際問題中有廣泛應用,特別是在需要同時支持區間查詢和區間修改的情況下:
- 範圍檢索系統:在數據庫和信息檢索系統中,線段樹可用於快速查詢滿足特定條件的數據範圍。例如,在時間序列數據庫中,快速查找某一時間段內的最大/最小值或平均值。
- 圖像處理:在處理大型圖像數據時,線段樹可用於快速計算圖像某一區域的統計信息或實現區域性的圖像編輯操作。
- 計算幾何:在處理二維空間中的點、線或矩形等幾何對象時,線段樹可以高效地解決區間查詢問題,如找出與給定區域相交的所有對象。
- 在線算法競賽:線段樹是解決動態範圍查詢問題的標準工具,如區間最大值、區間和等問題。
- 遊戲開發:在大型多人在線遊戲中,線段樹可用於地圖數據的管理和快速查詢,如找出某區域內的所有遊戲對象。
動態線段樹
當區間範圍非常大,但實際有值的點比較稀疏時,可以使用動態線段樹(通常使用指針實現)來節省空間:
public class DynamicSegmentTree {
private class Node {
int val; // 節點值
int lazy; // 懶惰標記
Node left; // 左子節點
Node right; // 右子節點
int start; // 區間起點
int end; // 區間終點
Node(int start, int end) {
this.start = start;
this.end = end;
this.val = 0;
this.lazy = 0;
}
}
private Node root;
public DynamicSegmentTree(int start, int end) {
root = new Node(start, end);
}
// 區間更新
public void update(int left, int right, int val) {
update(root, left, right, val);
}
private void update(Node node, int left, int right, int val) {
// 如果區間完全在更新範圍外
if (node.end < left || node.start > right) {
return;
}
// 如果區間完全在更新範圍內
if (node.start >= left && node.end <= right) {
node.val += (node.end - node.start + 1) * val;
if (node.start != node.end) {
node.lazy += val;
}
return;
}
// 下推懶惰標記
pushDown(node);
// 更新左右子節點
if (node.left != null) {
update(node.left, left, right, val);
}
if (node.right != null) {
update(node.right, left, right, val);
}
// 更新當前節點的值
node.val = (node.left != null ? node.left.val : 0) +
(node.right != null ? node.right.val : 0);
}
// 區間查詢
public int query(int left, int right) {
return query(root, left, right);
}
private int query(Node node, int left, int right) {
// 如果區間完全在查詢範圍外
if (node.end < left || node.start > right) {
return 0;
}
// 如果區間完全在查詢範圍內
if (node.start >= left && node.end <= right) {
return node.val;
}
// 下推懶惰標記
pushDown(node);
int sum = 0;
if (node.left != null) {
sum += query(node.left, left, right);
}
if (node.right != null) {
sum += query(node.right, left, right);
}
return sum;
}
// 下推懶惰標記
private void pushDown(Node node) {
if (node.lazy == 0) {
return;
}
int mid = (node.start + node.end) / 2;
// 創建左子節點(如果不存在)
if (node.left == null) {
node.left = new Node(node.start, mid);
}
// 創建右子節點(如果不存在)
if (node.right == null) {
node.right = new Node(mid + 1, node.end);
}
// 更新子節點的值和懶惰標記
node.left.val += (node.left.end - node.left.start + 1) * node.lazy;
node.right.val += (node.right.end - node.right.start + 1) * node.lazy;
if (node.left.start != node.left.end) {
node.left.lazy += node.lazy;
}
if (node.right.start != node.right.end) {
node.right.lazy += node.lazy;
}
// 清除當前節點的懶惰標記
node.lazy = 0;
}
}可持久化線段樹(Persistent Segment Tree)
可持久化線段樹是線段樹的一種變體,它可以保存歷史版本,允許查詢任意歷史狀態:
public class PersistentSegmentTree {
private class Node {
int val; // 節點值
Node left; // 左子節點
Node right; // 右子節點
Node(int val) {
this.val = val;
this.left = null;
this.right = null;
}
Node(Node other) {
this.val = other.val;
this.left = other.left;
this.right = other.right;
}
}
private Node[] roots; // 存儲歷史版本的根節點
private int n; // 數組大小
private int versionCount; // 版本數量
public PersistentSegmentTree(int[] array, int maxVersions) {
n = array.length;
roots = new Node[maxVersions];
versionCount = 0;
// 構建初始版本
roots[versionCount++] = build(0, n - 1, array);
}
// 構建線段樹
private Node build(int start, int end, int[] array) {
if (start == end) {
return new Node(array[start]);
}
int mid = (start + end) / 2;
Node node = new Node(0);
node.left = build(start, mid, array);
node.right = build(mid + 1, end, array);
node.val = node.left.val + node.right.val;
return node;
}
// 創建新版本並更新單個元素
public void update(int index, int val) {
roots[versionCount] = update(roots[versionCount - 1], 0, n - 1, index, val);
versionCount++;
}
private Node update(Node node, int start, int end, int index, int val) {
if (index < start || index > end) {
return node;
}
// 創建新節點(路徑複製)
Node newNode = new Node(node);
if (start == end) {
newNode.val = val;
return newNode;
}
int mid = (start + end) / 2;
if (index <= mid) {
newNode.left = update(node.left, start, mid, index, val);
} else {
newNode.right = update(node.right, mid + 1, end, index, val);
}
newNode.val = newNode.left.val + newNode.right.val;
return newNode;
}
// 查詢特定版本的區間和
public int query(int version, int left, int right) {
if (version >= versionCount) {
throw new IllegalArgumentException("版本不存在");
}
return query(roots[version], 0, n - 1, left, right);
}
private int query(Node node, int start, int end, int left, int right) {
if (right < start || left > end) {
return 0;
}
if (left <= start && end <= right) {
return node.val;
}
int mid = (start + end) / 2;
return query(node.left, start, mid, left, right) +
query(node.right, mid + 1, end, left, right);
}
}相關LeetCode熱門題目
- 307. 區域和檢索 - 數組可修改:設計一個支持區間和查詢和單點修改的數據結構,可以使用線段樹高效解決。
- 699. 掉落的方塊:使用線段樹來跟蹤區間的最大高度,解決方塊堆疊問題。
- 715. Range模塊:實現一個數據結構來管理區間的添加、刪除和查詢,線段樹是理想的解決方案。
- 218. 天際線問題:使用線段樹來處理建築物的高度信息,求解城市天際線。
- 1157. 子數組中佔絕大多數的元素:使用線段樹結合分治思想解決區間眾數查詢問題。