










《新興數據湖倉設計與實踐手冊·從分層架構到數據湖倉架構設計(2025 年)》 系列文章將聚焦從數據倉庫分層到數據湖倉架構的設計與實踐。手冊將闡述數據倉庫分層的核心價值、常見分層類型,詳解分層下的 ETL 架構及數據轉換環節,介紹數據倉庫分層對應的技術架構,並以貼源層(ODS)、數據倉庫層(DW)、數據服務層(DWS)為例,深入剖析數湖倉分層設計,最後探討數據倉庫技術趨勢並進行小結。
本文為系列文章第三篇,詳細剖析了數據倉庫分層下的貼源層和數據倉庫層設計。
👉上文回顧:《(一)從分層架構到數據湖倉架構:數據倉庫分層的概念與設計》
(二)從分層架構到數據湖倉架構:數據倉庫分層下的技術架構與舉例
貼源層(ODS, Operational Data Store)
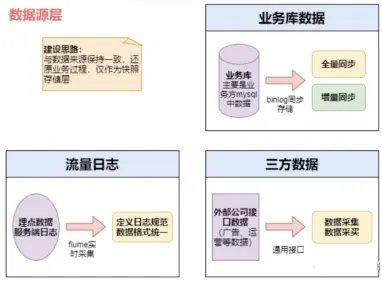
數據引入層(ODS,Operational Data Store),也稱為數據基礎層。
這一層主要存放從源系統引入的原始數據,幾乎不做任何加工處理,目的是將基礎數據直接同步到數據倉庫中,便於後續的數據處理工作。在結構上,ODS層的數據與源系統保持高度一致,是數據倉庫的數據準備區。
在現代數據架構中,ODS層的數據獲取方式逐步向CDC(Change Data Capture,變更數據捕獲)模式轉變,尤其在數據湖和實時數據倉庫的場景中。新型的ETL工具已經可以支持源系統的DDL(數據定義語言)變更,這意味着當源系統的字段發生變化時,ODS層可以自動更新表結構,無需手動調整。例如,WhaleTunnel這樣的工具支持多種系統的DDL變更捕獲,保證了ODS層數據在數據倉庫、數據湖或實時數據倉庫中的一致性,不會因為源系統的改變而中斷ETL流程。
ODS層的數據通常分為當前數據和歷史數據兩部分:
- 當前數據表:用於存儲最近需要處理的數據,保持最新的數據狀態。
- 歷史數據表:保存已處理完的數據以備後續使用,一般保留3-6個月後清理,具體時間視項目需求而定。如果源系統的數據量較小,也可以選擇更長時間的保存,甚至全量保存。
ODS層的作用:數據清洗和規範化
儘管ODS層主要作用在於數據引入,但並非完全不做處理。此層通常會進行基本的數據清洗,例如:
- 處理異常字段、規範化字段命名、統一時間格式
- 確保數據一致性,為後續數據處理和特徵工程奠定基礎
一些公司會選擇在ODS層就進行初步的清洗和過濾,而另一些則將更多的數據加工留在DWD層。選擇在哪裏進行清洗取決於企業的技術規範和需求。在實際開發中,大多數企業會在將數據存入ODS時進行基本處理,以減少後續工作量。
數據來源
- 業務數據庫:公司各業務系統生成的結構化數據。
- 日誌數據:包括用户行為日誌和系統後台日誌。埋點數據首先經由Nginx上報,再由Flume收集並存儲在Kafka等消息隊列中,隨後由SeaTunnel或WhaleTunnel拉取至離線數據倉庫(如HDFS)。
外部數據:包括合作伙伴提供的數據或爬蟲採集的數據,整合後用於補充業務分析。
存儲策略設計
按時間劃分
數據來源可按時間進行分區存儲,通常以日為粒度,也有公司採用年、月、日三級分區以優化存儲效率。數據在進入數據倉庫前進行基礎清洗,如格式錯誤數據的剔除、關鍵信息缺失的過濾等,以保證數據質量。數據可分為實時和離線兩種處理模式。
離線數據處理
離線數據通常通過定時任務(如每日批量任務)從業務系統或數據庫中抽取。典型的日計算任務會在凌晨執行,通過SeaTunnel、DataX或WhaleTunnel從業務數據庫提取數據,計算前一天的業務指標,並生成報表。Hive、Spark常用於批量計算,計算結果存儲於Hive、HBase、MySQL、Elasticsearch或Redis等系統中,供後續分析使用。
實時數據處理
實時數據源主要來自日誌埋點數據或業務數據庫,常用於實時推薦、用户畫像等業務需求。Spark Streaming和Flink負責實時計算,結果通常寫入Elasticsearch、HBase或Redis。實時數據源可利用WhaleTunnel監控MySQL的Binlog變化,將數據實時寫入Kafka或HDFS。
按方式劃分
在實際應用中,可根據需求選擇增量、全量或拉鍊存儲方式。
增量存儲
增量存儲通常按天分區,以業務日期為分區字段,每日存儲新增的業務數據。例如,用户A在1月1日訪問了店鋪B,生成記錄t1,並於1月2日訪問店鋪C,生成記錄t2。增量存儲會將t1存入1月1日的分區,將t2存入1月2日的分區。如果用户A在1月1日購買商品B(生成t1記錄)並在1月2日退貨(更新t1記錄),增量存儲會將初始購買記錄存於1月1日分區,退貨更新後的記錄則存於1月2日分區。
對於交易日誌和行為日誌等高頻變更的數據表,增量存儲能減少存儲成本和數據冗餘。下游分析需求一般只需聚合後的彙總數據,因此不需要長期保存全量的歷史數據。
全量存儲
全量存儲以日為分區,每個分區記錄當天的完整業務數據快照。例如,1月1日,賣家A發佈了商品B和C,生成記錄t1和t2。1月2日,賣家A下架商品B並上架商品D,此時商品B記錄t1會更新,商品D生成新記錄t3。全量存儲會在1月1日分區保存t1和t2,在1月2日分區保存更新後的t1、t2和t3。
對於數據量較小、變化緩慢的維度數據(如商品分類),全量存儲能夠保證數據完整性和易用性。
拉鍊存儲
拉鍊存儲通過在表中增加開始時間(start_dt)和結束時間(end_dt)兩個時間戳字段,記錄每次數據變更,並以時間為分區字段。這種方式適用於記錄所有變更數據的歷史快照,為分析數據演變過程提供支持。
目前WhaleTunnel已經支持了CDC、增量和全量數據抽取模式,也支持自定義插入規則,是用户使用的快速工具。
緩衝層
概念介紹
緩衝層(也稱接口層或Stage層)用於存儲每天的增量和變更數據。該層暫存從源系統採集的原始數據,以便後續數據處理和ETL流程的使用。
數據生成方式
數據通常通過Kafka直接接入緩衝層,對於包含update、delete和insert操作的業務表,會每日生成變更日誌;而僅有insert操作的業務表,則直接將數據進入明細層。
- 建議方案:Apache SeaTunnel或WhaleTunnel生成的CDC日誌直接進入緩衝層。如果業務涉及拉鍊數據,同樣將其存放於緩衝層,以確保數據變更的準確記錄。
日誌存儲方式
緩衝層的日誌數據以Impala外部表形式存儲,採用Parquet文件格式。這種方式不僅提高了存儲效率,還便於MapReduce等處理引擎對數據的快速訪問和處理。
日誌清理策略
對於日誌數據,通常只保留最近幾天的數據以節省存儲空間。
- 建議方案:考慮長期存儲重要日誌數據,以便於歷史數據回溯和審計。
表的Schema和分區策略
通常按天分區數據,以partitioned by時間字段進行存儲。這樣不僅簡化了數據管理,還能提升查詢效率。表的Schema設計遵循源系統的結構,以確保數據的一致性和完整性。
庫和表的命名規範
- 庫名:ods,表示數據的貼源層。
- 表名:格式建議為ods_日期_業務表名,例如ods_2024_10_sales,便於管理和查詢。
Hive表類型
在緩衝層中使用Hive的外部表管理數據,外部表的文件可以存儲在非默認的HDFS路徑中,這樣當刪除表定義時,實際存儲文件不會被刪除,保障數據安全。
業務表使用Hive的內部表,當刪除表定義時,關聯的HDFS文件也會被刪除。此方式適合臨時或不重要的數據存儲,避免重要數據的誤刪。
數據倉庫層設計(DW,Data Warehouse)
數據倉庫層(DW層)是數據倉庫設計的核心層,負責對來自貼源層(ODS層)的數據進行主題化建模,以支持高效的業務分析和決策。DW層根據業務主題劃分領域,為各主題構建清晰的數據視圖,過濾掉無關決策的數據,專注於支持企業關鍵分析。在該層,通常會存儲業務系統的所有歷史數據,例如保存10年以上的數據,為BI系統提供全面的歷史數據支持。
數據內容和結構
在DW層中,主要存儲三類數據:
- 明細事實數據:基於ODS層的原始數據加工而成,包含業務過程中的細節信息。
- 維表數據:描述性數據(如客户信息、產品分類等),同樣從ODS層加工生成。
- 公共指標彙總數據:基於維表和明細數據彙總而成,為業務分析提供標準化的核心指標。
DW層的細分
DW層通常進一步劃分為三個子層:維度層(DIM)、明細數據層(DWD)和彙總數據層(DWS),並使用維度建模方法為數據設計結構,以確保高效的數據管理和訪問:
- 維度層(DIM):定義維度數據,如用户、產品等,用於描述事實表中的相關業務數據,幫助業務數據的理解和查詢。
- 明細數據層(DWD):存儲經過整理的細粒度數據,保持原始數據的完整性,但格式已適合進一步分析和使用。DWD層中的數據從ODS層數據加工而來,精細化了原始數據,確保高可用性。
- 彙總數據層(DWS):通過彙總維度和明細數據,生成更寬表結構的公共指標,便於多場景複用。這一層根據特定的統計需求,對明細數據進行聚合,減少數據的重複加工,提升查詢和計算的效率。
數據模型設計
DW層採用維度建模,將維度表和事實表建立外鍵關聯關係,以減少數據冗餘、提高數據的組織效率。維度模型不僅簡化了業務分析的複雜性,還提升了DW層的數據易用性。在彙總數據層中,通過寬表設計將不同統計維度關聯,建立高度複用的公共指標數據層,從而減少下游數據開發的重複勞動。
維度層(DIM,Dimension)
維度層以業務維度為建模核心,根據每個維度的業務語義,定義維度屬性和關聯關係,形成標準化的數據分析維表。此層通過為各維度添加屬性、定義關聯關係等,明確計算邏輯,實現一致性的數據描述。為了避免在維度模型中出現冗餘數據,維度表通常採用雪花模型結構,通過拆分屬性表來減少數據重複,實現更加規範的維度建模。
明細數據層(DWD,Data Warehouse Detail)
明細數據層以具體的業務過程為核心進行建模,旨在捕捉業務活動的最細粒度信息,構建詳細的事實表。這些事實表保留了業務過程的每一個細節,確保數據的完整性和精準性。在實際設計中,對於一些關鍵的屬性字段,可以適當進行冗餘處理,即採用寬表化設計,以提升查詢效率,減少多表關聯帶來的性能開銷。這種做法在確保數據精細化的同時,兼顧了系統的易用性和高效性。
彙總數據層(DWS,Data Warehouse Summary)
彙總數據層(DWS)以分析主題為核心進行建模,圍繞業務指標需求,構建標準化的彙總表,為上層應用提供一致的公共指標。這一層基於寬表設計,將統計邏輯物理化,確保數據的命名規範和口徑一致,從而支持高效的分析查詢。彙總數據層包含多種主題的寬表和明細事實表,為業務提供統一的統計視角。
- 主題域:以業務過程為視角,將業務活動進行抽象和分類。例如,下單、支付、退款等事件可歸類為不同的業務主題域,主要針對公共明細層(DWD)進行主題劃分。
- 數據域:以分析需求為導向,將業務過程和維度進一步抽象,形成數據域。數據域劃分在公共彙總層(DWS)中進行,用於滿足各類業務分析需求。
層次結構與數據處理
- DWD(Data Warehouse Details,數據明細層):以業務過程為驅動,主要從ODS數據層抽取原始數據並進行清洗和規範化處理,確保數據的完整性和一致性。清洗內容包括去除空值、轉換髒數據、枚舉值統一、以及異常值過濾等。
- DWS(Data Warehouse Base,數據基礎層):該層存儲客觀數據,主要作為中間層,為DWS層提供基礎指標支持。可以視為大量中間指標的存儲區,聚焦客觀的業務事實。
- DWS(Data Warehouse Summary數據服務層):基於DWB中的基礎數據,DWS層整合並彙總成以主題域為中心的寬表數據,用於OLAP分析、業務查詢和數據分發。DWS的寬表設計適用於高效查詢和聚合分析,滿足各種業務部門的統計需求。
數據彙總和輕度聚合
彙總數據層在數據服務和分析場景中發揮關鍵作用。主要對ODS和DWD層的數據進行輕度聚合和彙總,確保數據粒度適用於業務需求,支持複雜分析和快速響應上層查詢需求。
1)公共維度層(DIM,Dimension)
公共維度層(DIM)通過維度建模來構建企業的一致性維度,以確保在數據分析和計算過程中口徑統一,避免因算法或指標不一致而引發的偏差。維度層的主要目的是定義和標準化數據分析的基本屬性,例如國家代碼、地理位置、產品分類等。通過為所有業務共享的維表建立統一的結構和命名規範,DIM層成為業務數據的標準參照層。
公共維度層的構成
- 維表:維表是邏輯維度的物理實現,將每個維度及其屬性具體化。為了提高查詢效率和降低數據冗餘,維表通常採用寬表設計原則。高基數的維表(如用户、商品等)可能包含數百萬甚至數億條記錄,而低基數的維表(如枚舉配置、日期等)則記錄數相對較少。
維度層的設計要點
- 維表設計原則
在設計維表時,建議將單表的數據量控制在1000萬條以內。對於高基數表,可採用Map Join操作優化查詢性能。同時,避免頻繁更新維表,針對緩慢變化的維度(如商品分類)可採用拉鍊表方式記錄變更歷史。 - 維表命名規範
公共維度表命名通常以dim_開頭,表示與具體業務無關、可以在各個業務模塊中複用的維度。例如,公共區域表命名為dim_pub_area,商品表命名為dim_asale_item。這種命名規範便於識別表用途和主題,提高數據管理的清晰度。 - 粒度定義
維度表中的數據粒度是業務過程的最小描述單位。例如,一條訂單記錄的粒度可能為“每次下單”。粒度可通過維度屬性組合來描述,如“國家-城市-區縣”組合用於表示地理位置的細節。粒度定義需精細,以滿足後續分析需求。
維度建模步驟
- 選擇業務過程
選擇業務系統中的關鍵業務過程(如下單、支付、物流等)進行建模。中小企業通常會選取所有業務過程,而大企業則聚焦於分析需求的主要業務線,以減少數據冗餘和維護成本。 - 聲明粒度
粒度定義明確數據的細化程度。建議選擇最小粒度,以支持更細粒度的指標計算。例如,在訂單數據中,每個商品項代表一行數據記錄,粒度為“每次下單”。保持細粒度可以靈活支持不同的統計需求,避免數據粒度過粗導致的信息丟失。 - 確定維度
維度用來描述業務中的“誰、何處、何時”等信息,幫助分析不同維度的指標變化。例如,為支持訂單量按時間、區域或用户的統計分析,需定義時間、地區和用户維度。維度表設計遵循星型模型原則,在必要時進行維度退化。 - 確定事實
事實是業務中的度量數據,如訂單金額、購買次數等。事實表中的每條記錄反映某一業務活動的度量結果。通過寬表設計適當冗餘重要字段,以提高查詢效率。DWD層(數據明細層)以業務過程為驅動,而DWS層(彙總層)則是以需求為導向,與維度建模無直接關聯。
主題、主題域與維度模型
- 主題
數據倉庫中的數據組織圍繞不同的主題(如財務、銷售、客户)展開。主題定義了數據倉庫的主要分析方向,每個主題對應一個業務分析領域。例如,“財務分析”是一個主題,涵蓋收入、支出、盈利等指標。 - 主題域
主題域是多個相關主題的集合,便於數據的分層組織和分類管理。主題域的劃分應由業務部門與數據倉庫設計人員共同決定,考慮業務的關聯性和分析需求。例如,銷售主題域可包含訂單分析、客户行為、廣告投放等主題。
主題域劃分原則
主題域的劃分邏輯可以基於不同的業務需求或部門需求:
- 按業務過程:如電商平台可設立“廣告域”、“客户域”等主題域,進一步分為“庫存管理”、“銷售分析”等具體主題。
- 按需求方:如財務部門的主題域可能包含“工資分析”、“投資回報分析”等內容。
- 按功能或應用:如“朋友圈域”可包含用户動態、廣告數據等,適用於社交平台數據的主題劃分。
- 按部門:如運營域、技術域,分別涵蓋與各部門工作相關的主題(如運營域中的“活動效果分析”)。
主題域劃分不必一次性完成,可採用迭代方式,從確定的主題開始逐步擴展,最終形成符合行業標準的主題模型。
2)數據明細層(DWD,Data Warehouse Detail)
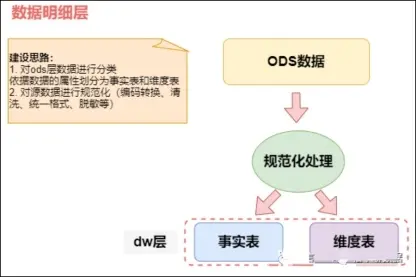
數據明細層(DWD)是數據倉庫和業務系統間的隔離層,主要用於提升數據的質量和一致性,確保存儲的數據符合分析需求。DWD層接收並清洗來自ODS層的原始數據,通過去噪、去重、脱敏等處理後,生成乾淨、準確的明細數據表,以支持業務分析。該層還會適度進行維度退化處理,將一些必要的維度字段直接存儲在事實表中,以減少表關聯,提高查詢性能。
數據清洗與處理
DWD層的數據需要符合嚴格的數據質量標準,數據在裝入前進行多種處理:
-
數據清洗
- 去除空值、髒數據:例如丟失關鍵字段(如訂單ID為空)的記錄、格式錯誤的數據。
- 敏感數據脱敏:對手機號、身份證等敏感信息進行加密或脱敏處理。
- 去除無效數據:如無時間戳的數據(視業務需求)。
- 會話切割:如針對App日誌數據的場景,將用户進入後台再返回前台的操作分割為新的會話,方便後續行為分析。
-
數據映射與轉換
- 地理位置映射:將GPS經緯度轉換為省市區地址,採用geohash或IP地址轉換庫(如ip2region)進行快速定位,也可藉助高德、百度地圖API。
- 時間標準化:將時間戳轉換為年、月、日、周、季度等信息。
- 數據規範化:對來自不同來源的數據進行格式統一,例如布爾值(0/1轉換為true/false)、空值(統一為null)、日期格式(標準化為YYYY-MM-dd HH:mm:ss)。
- 維度退化
對於一些高基數的維度字段(如訂單ID),直接存儲在事實表中而不創建單獨的維度表。這些退化維度可以簡化數據結構,減少關聯,提升數據查詢的效率。
明細粒度事實表設計
DWD層以業務過程為核心進行建模,根據每個業務過程(如下單、支付、退款等)的特點,構建最細粒度的事實表。這些明細事實表保留了業務過程的全部細節,且一般會將一些常用的維度字段冗餘存儲,採用寬表設計以提升性能。這些事實表也被稱為“邏輯事實表”。
數據質量控制
DWD層的數據粒度與ODS層保持一致,但在此基礎上提供更嚴格的數據質量保證。DWD層還會適度進行維度退化,例如將商品類別的多級維度(如一級、二級、三級類別)或時間、地域等常用維度直接存儲在事實表中,簡化關聯,提高數據的使用效率。
- 清洗比例:對於大數據量的數據,建議清洗掉低於0.01%的數據,如每萬條記錄中去除一條不合規數據。
- 表數量優化:通過合併相似數據,合理控制表數量,將過多的表精簡為更易管理的結構。例如,將上萬張表優化為三千張或一千張表,以便於後續的維護和擴展。
總結來説,DWD層在保持細粒度的前提下,提供規範化、清洗後的明細數據,為上層的業務應用和分析提供了乾淨、標準化的數據支撐。這一層的優化和處理不僅提升了數據倉庫的性能,還顯著降低了數據冗餘,提高了數據的可用性和易用性。
明細粒度事實表設計原則
- 單維度關聯:每個明細粒度事實表只應與一個核心維度關聯,保持數據模型簡單、清晰。
- 業務過程相關性:僅包含與業務過程直接相關的事實數據,確保每個事實表準確反映其特定業務過程。
- 聲明粒度:在定義維度和事實之前,必須先明確數據粒度,即一行數據代表的具體業務意義。
- 一致性和可加性:確保事實的單位一致,且儘量將不可加的事實分解為可加性組件,以支持更廣泛的統計需求。
- 統一粒度:一個事實表中僅能包含單一粒度的事實數據,避免混合不同粒度的事實。
- 處理Null值:對Null值進行合理處理,以避免數據分析過程中產生意外結果。
- 退化維度應用:使用退化維度(如訂單ID等高頻維度)直接冗餘存儲在事實表中,以簡化數據表關聯,提升查詢效率。
數據處理與存儲方案
- 數據合成:採用全量合成策略,每天合併前天的全量數據和昨天的新增數據,生成一個新的數據表,覆蓋舊錶。同時,使用歷史鏡像按周、月或年存儲快照。
- 日誌存儲方式:使用Impala的外部表和Parquet文件格式存儲日誌數據。建議在DWD層和下層數據均使用Impala內表,以實現更高效的靜態或動態分區管理。
- 分區設計:默認按天創建分區。如果數據沒有時間屬性,可根據業務需求選擇合適的分區字段。
-
庫與表命名規範:庫名為dwd,表名格式建議為dwd_日期_業務表名。對於增量表和全量表,用i表示增量,f表示全量。例如:
- odwd_asale_trd_ordcrt_trip_di:表示A電商公司航旅機票訂單下單的增量事實表,按日更新。
- odwd_asale_itm_item_df:表示A電商公司商品快照的全量事實表,按日刷新。
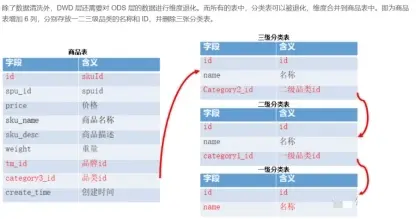
明細粒度事實表設計示例
- 以交易商品信息事實表(dwd_asale_trd_itm_di)為例:
(
item_id BIGINT COMMENT '商品ID',
item_title STRING COMMENT '商品名稱',
item_price DOUBLE COMMENT '商品價格',
item_stuff_status BIGINT COMMENT '商品新舊程度_0全新1閒置2二手',
item_prov STRING COMMENT '商品省份',
item_city STRING COMMENT '商品城市',
cate_id BIGINT COMMENT '商品類目ID',
cate_name STRING COMMENT '商品類目名稱',
commodity_id BIGINT COMMENT '品類ID',
commodity_name STRING COMMENT '品類名稱',
buyer_id BIGINT COMMENT '買家ID'
)
COMMENT '交易商品信息事實表'
PARTITIONED BY (ds STRING COMMENT '日期')
LIFECYCLE 400;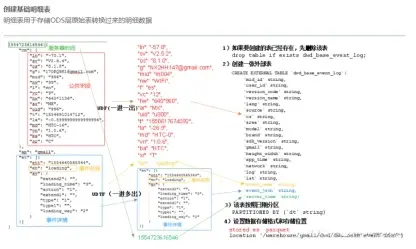
此表設計為按天分區,數據存儲生命週期為400天,用於存儲每日更新的商品交易信息。通過ds字段管理數據的時間分區,便於查詢和管理。










