









前端狀態管理的工具庫紛雜,在開啓一個新項目的時候不禁讓人糾結,該用哪個?其實每個都能達到我的目的,我們想要的無非就是管理好系統內的狀態,使代碼利於維護和拓展,儘可能降低系統的複雜度。
使用 Vue 的同學可能更願意相信其官方的生態,直接上 vuex/pinia,不用過多糾結。由於我平常使用 React 較多,故就當前應用較廣泛的 Redux、Mobx 倆工具庫為例,研讀了一番,記錄下自己的一些閒言碎語。
注意:以下不會涉及到各個庫的具體用法,多是探討各自的設計理念、推崇的模式(patterns),提前説明,以免耽誤大家時間。
Redux、Mobx 或多或少都借鑑了 Flux 理念,比如大家經常聽到的 “單向數據流” 這項原則最開始就是由 Flux 帶入前端領域的,所以我們先來聊聊 Flux。
Flux
Flux 是由 facebook 團隊推出的一種架構理念,並給出一份代碼實現。
為什麼會有 Flux 的誕生?
Facebook 一開始是採用傳統的 MVC 範式進行系統的開發
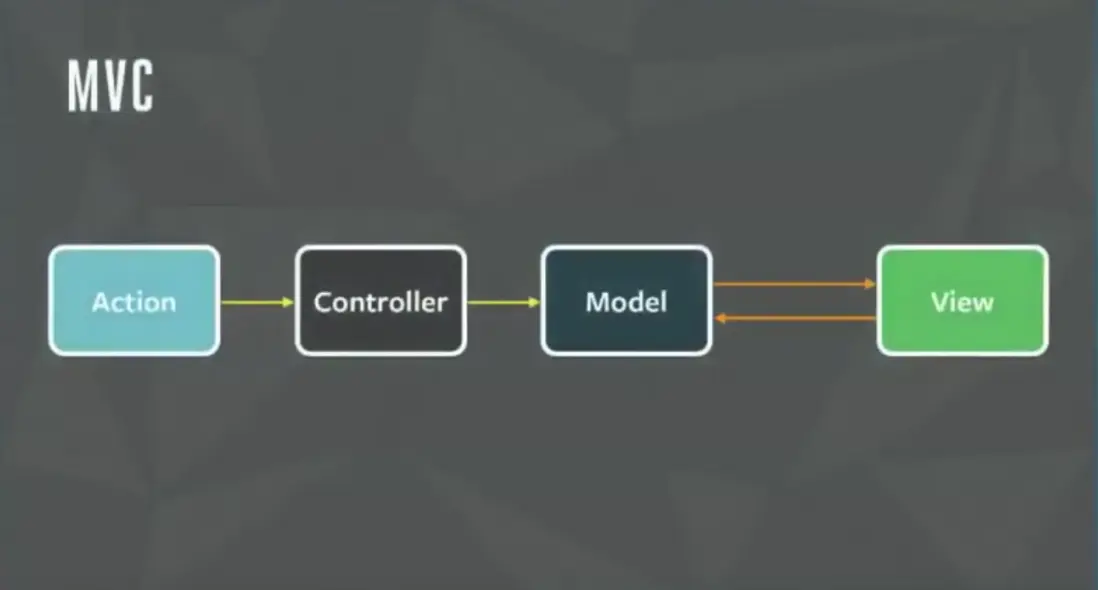
但隨着業務邏輯的複雜,漸漸地發現代碼裏越來越難去加入新功能,很多狀態耦合在了一起,對於狀態的處理也耦合在了一起

造成了 FB 團隊對 MVC 吐槽最深的兩個點:
- Controller 的中心化不利於擴展,核心是因為 Controller 裏需要處理大量複雜的對於 Model 更改的邏輯
- 對於 Model 的更改可能來源於各個方向。 可能是開發者本身想對 Model 進行更改、可能是 View 上的某個回調想對 Model 進行更改,可能是一個 Model 的更改引發了另一個 Model 的更改。
我們可以大概總結出,基於 MVC 的數據流向就有三種:
- Controller -> Model -> View
- Controller -> Model -> View -> Model -> View ... (loop)
- Controller -> Model1 -> Model2 -> View1 -> view2 ...
並且這三種數據流向在實際業務中還很有可能是交織在一起。
為了改善以上 MVC 在複雜應用中的缺陷,降低系統整體複雜度,FB 團隊推出了 Flux 架構,結合 React 重構了他們的代碼,這就是 Flux 架構誕生的原因。
Flux 具體是什麼
Flux 由幾個部分組成:
- Store
- Action
- View
- Dispatcher
Store 就是存放 Model 的地方,View 和 MVC 的 View 一樣就是視圖,Action 可以理解為操作 Model 的行為,Dispatcher 可以理解為找到 Action 對應 Store 並執行操作的分發執行者。
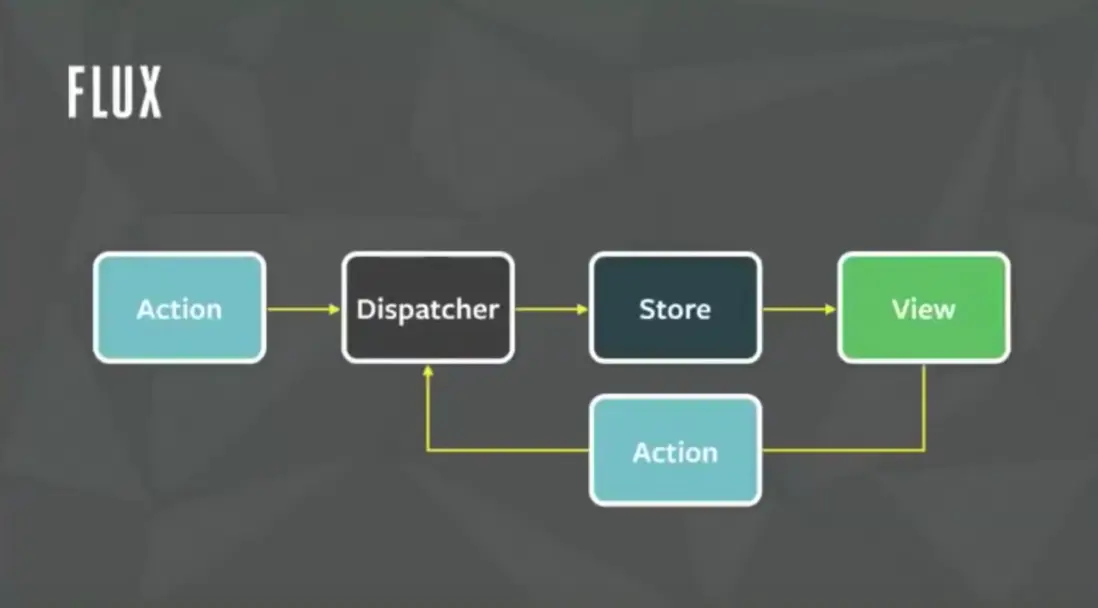
Dispatcher 是 Flux 的核心,它把對 Model 的操作給統一了起來,在 Flux 裏,Dispatcher 與 View 可以視為 Model 的唯一輸入輸出。
那麼相對於 MVC 帶來的變化或者説好處是什麼呢?
首先,數據流統一了,無論誰想要操作 Model,必須通過 disptacher ,同時 dispatcher 與 Action 配合,等同於是給 Model 約定了有限的、分離開的幾種操作。對比 MVC 裏中心化的 Controller 中對大量複雜的 Model 邏輯的操作,在 Flux 中就是被抽象分離到一個個 Action 裏去了。所以狀態在整個系統裏的流向就是:
Action -> dispatcher -> Model -> View -> Action -> dispatcher -> Model -> View ...
這就是所謂的 “單向數據流”。 相對於 MVC 中多種數據流交叉,單向數據流明顯降低了系統的複雜度。
又因為 Action 給 Model 約定了有限的幾種操作,僅根據 Action 的輸入,開發者就知道會發生怎樣的變更,提高了代碼的可預測性。
基於 MVC 範式的代碼,項目的長期維護者可能清楚各個地方狀態變更會引發什麼操作,但是若團隊來了新人,想搞清楚這些肯定需要費不少勁,假如基於 Flux 架構,開發者只需要追蹤一個 Action 是怎樣在整個系統中流動的,就知道系統的其餘部分是怎樣工作的了。因為 Flux 的數據流動是單向的且一致的。比如通過 Action 就知道要對狀態做怎樣的變更,再搜一下哪裏用了變更的狀態就知道這裏的視圖會 rerender,同樣的搜一下哪個地方 disptach 了這個 action,就知道誰想對狀態做出改變。
另外,還可以結合純函數的概念來感受下 Dispatcher 的設計
這在 Redux 的實現中體現地尤為明顯,就是在找到 Action 對應的 Store 後,單純只負責根據 Action 處理對 Model 的改動邏輯,不會改變入參或外部變量,相同的輸入始終對應相同的 Store 更改。意味着之後任意一個時間點做出一個之前時間點的 Action,得到的更改後的狀態與之前得到的是一致的。這就是所謂的 “時間旅行” 功能的原理,“時間旅行” 本質就是記錄下每一次數據修改,只要每次修改都是無狀態的,那麼我們理論上就可以通過修改記錄還原之前任意時刻的數據。
結合純函數的設計至少可以帶來兩點好處:
- 方便開發者調試。我們可以利用 “時間旅行” 復現之前任意時間點的狀態,可以統一地在 dispatcher 里加日誌看到何時做了什麼改變。
- 基於純函數構建的代碼更容易寫單測
Redux
Redux 就是基於 Flux 架構理念的一種函數式地實現,並做出了一些優化,所以 Redux 擁有 Flux 架構的所有優點。

上圖是 Redux 官網給的展示 Redux 工作原理的 gif 圖,樸素一點展示 Redux 的核心組成就是:

其中,Reducer 就是 Flux Dispatcher 的純函數式實現,找到 Action 對應的 Model,返回一個更改後的對象給 Redux,Redux 在 Store 上應用更改。
據以上倆圖,可以明顯感知到 Redux 數據流動是單向的:
action -> middleware -> reducer -> store -> view -> action -> middleware -> reducer -> store -> view ...
解釋 Redux 三個基本原則
Redux 官方表明可以用三個基本原則描述 Redux :“單一數據源“、“只讀的 state“、“使用純函數來執行修改“。
“單一數據源“相對於分散數據源肯定是優勢的,除非各個數據源之間毫無聯繫。但只要是有聯繫的多個數據源,你始終要通過某些操作把各個數據源給聯繫起來,無疑增加了複雜度。
“只讀的 state”也就是不允許直接修改 Model,必須創建個 action ,交給 reducer 處理,保證 Model 只有唯一輸入,這是踐行單向數據流的基本要求。
“使用純函數來執行修改”就是要求用户編寫的 reducer 必須得是純函數,方便方便開發者調試也易於寫單測。
另外,要求開發者編寫純函數的 reducer 還有個想突出點就是 Redux 推崇的 Immutable 特性。
Immutable 與 Mutable
什麼是 Immutable ,什麼是 Mutable ?
Immutable 意為「不可變的」。在編程領域,Immutable Data 是指一種一旦創建就不能更改的數據結構。它的理念是:在更改時,產生一個與原對象完全一樣的新對象,指向不同的內存地址,互不影響。
Mutable 意為 「可變的」。與 Immutable 相反,Mutable Data 就是指一種創建後可以直接更改的數據結構。
對於 JS 而言,所有原始類型 (Undefined, Null, Boolean, Number, BigInt, String, Symbol) 都是 Immutable 的,但是引用類型的值都是 Mutable 的。
舉兩個例子直觀感受下:
例一:
let a = { x: 1 };
let b = a;
b.x = 6;
a.x // 6例二:
function doSomething(x) { /* 在此處改變 x 會影響到 str 和 obj 嗎? */ };
var str = 'a string';
var obj = { an: 'object' };
doSomething(str); // 基礎類型都是 immutable 的, function 得到的是一個副本
doSomething(obj); // 對象傳遞的是引用,在 function 內是 mutable 的
doAnotherThing(str, obj); // `str` 沒有被改變, 但是 `obj` 可能已經變化了。js 中其實有幾種方式可以讓值變為 Immutable 的,為了不跑題,大家可以去 wikipedia 拓展閲讀。要注意的是,無論是writeable: false 或 Object.freeze 或 const,其修飾/凍結/聲明的屬性/值都只在第一層生效,假如屬性/值嵌套了引用類型值,則需要遞歸去修飾/凍結/聲明才能達到整體 Immutable 的目的。
Immutable 與 Mutable 的優缺
Mutable
其實比較顯而易見,Mutable 的數據,開發者可以直接更改,但是要負擔更改後副作用的思考。
優點:操作便利。
缺點:開發者內心要知道更改了 Mutable 數據後,會導致哪些副作用,會怎樣影響到其他用到該數據的地方。
Immutable
其實就是 Mutable 的相反,不過可以基於 Immutable 特性做一些額外的功能。
優點:
-
避免了數據更改的副作用 (在多線程語言中就是有了所謂 “線程安全性”)
JS 雖然沒有多線程的概念,但有競態的概念。 JS 中引用類型的值都是按引用傳遞的,在一個複雜應用中會有多個變量指向同一個內存地址的情況,如果有多個代碼塊同時更改這個引用,就會產生競態。你需要關心這個對象會在哪個對方被修改,你對它的修改會不會影響其他代碼的運行。使用 Immutable Data 就不會產生這個問題——因為每當狀態更新時,都會產生一個新的對象。
-
狀態可追溯
由於每次修改都會創建一個新對象,且對象不會被修改,那麼變更的記錄就能夠被保存下來,應用的狀態變得可控、可追溯。Redux Dev Tool 和 Git 這兩個能夠實現「時間旅行」的工具就是秉承了 Immutable 的哲學。
缺點也是相對於 Mutable 方式的:
- 額外的CPU、內存開銷
- 達到修改值的目的要做額外的操作
儘管生態內有如 Immutable.js、Immer.js 等庫幫助我們更便捷地操作 Immutable 更改,但是這兩個缺點也是無法避免的,只是儘可能地做優化。
至於是採用 Immutable 還是 Mutable 的方案去寫代碼,個人覺得還是得 case by case 地去聊,顯然 Redux 推崇 Immutable,基於此提供了時間旅行的功能,React 推薦開發者使用 Immutable ,是因為 React 的 UI = fn(states) 模型中,React 對 state 是 shallowMerge 的,如果 mutable state 沒改變引用,React 會認為不需要去 diff,自然不會 rerender 。但是 Mobx 就是推崇 Mutable 的,開發者使用體驗很好。
Mobx
Mobx 是一個推崇自動收集依賴與執行副作用的響應式狀態管理庫,推薦開發者使用 Mutable 直接更改狀態,框架內部幫我們管理(派生)每個 Mutable 的副作用並實現最優處理。
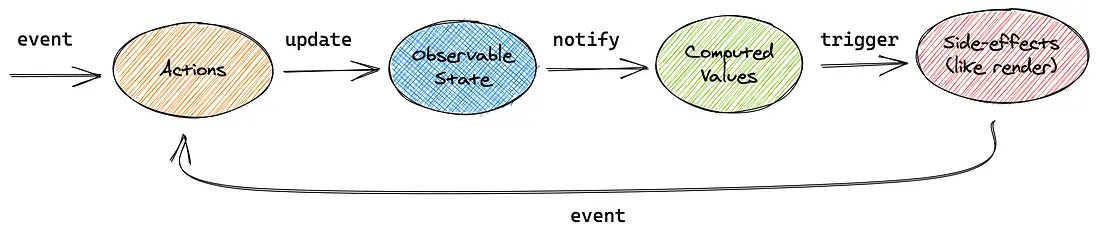
由上圖可感知 Mobx 也是踐行單向數據流的理念:
Action -> State -> Computed Value -> Reaction(like render) -> Action ...
這裏引入了新的概念是 Computed Value 和 Reaction 。Mobx 是多 Store 的,聯繫多個數據源的數據可以用 Computed Value ,同一個數據源想要多個數據派生出一個新數據也可以用 Computed Value。Reaction 的話就是 state 的所有副作用,可以是 render 方法,可以是 Mobx 自帶的 autorun、when 等。
Mobx 想要達到的目的其實就是開發者能自由地管理狀態、讓修改狀態的行為簡單直接,其餘交給 Mobx。
想要達到這一目的,Mobx 內部就要做更多的事情,其作者 Michel Weststrate 有在一篇推文中闡述過 Mobx 設計原則,但是有點過於細節,不熟悉 Mobx 底層機制的同學可能不太看得懂。以下,在基於這篇推文結合對源碼的探究,我提煉一下,感興趣可以去看原文。
自薦對 Mobx 源碼的解析文章: Mobx 源碼與設計思想。文章較長,建議專門找時間安靜地一口氣看完。
對狀態改變作出反應永遠好過於對狀態改變作出動作
針對這點其實與 Vue 響應式傳遞的理念相同,就是數據驅動。
再分析這句話,“作出反應” 意味着狀態與副作用的綁定關係由框架(庫)給你做好,狀態改變自動通知到副作用,不用使用者(開發者)人為地處理。
“作出動作”則是在使用者已知狀態更改的情況下,手動去通知副作用更新。 這起碼就有一個操作是使用者必做的:手動在副作用內訂閲狀態的變化,這至少帶來兩個缺陷:
- 無法保證訂閲量的冗餘性,可能訂閲多了可能少了,導致應用出現不符合預期的情況。
- 會讓業務代碼變得更 dirty,不好組織
最小的、一致的訂閲集
以 render 作為副作用舉例,假如 render 裏有條件語句:
render() {
if (依賴 A) {
return 組件 1;
}
return 依賴 B ? 組件 2 : 組件 3;
}首先,如果交給用户手動訂閲,必須只能依賴 A、B 的狀態一起訂閲才行,如果訂閲少了無法出現預期的 re-render。
然後交給框架去做處理怎樣才好? 依賴 A、B 一起訂閲當然沒毛病,但是假設依賴 A、B 初始化時都有值,我們有必要讓 render 訂閲依賴 B 的狀態嗎?
沒必要,為什麼?想一想如果此時依賴 B 的狀態變化了 re-render 呈現的效果會有什麼不同嗎?
所以在初始化時就訂閲所有的狀態是冗餘的,假如應用程序複雜、狀態多了,沒必要的內存分配就會更多,對性能有損耗。
故 Mobx 實現了運行時處理依賴的機制,保證副作用綁定的是最小的、一致的訂閲集。源碼見Mobx 源碼與設計思想 中 “getter 裏幹了啥?” 與 “處理依賴” 章節。
派生計算(副作用執行)的合理性
説人話就是:杜絕丟失計算、冗餘計算。
丟失計算:Mobx 的策略是引入狀態機的概念去管理依賴與派生,讓數學的邏輯性保證不會丟失計算。
冗餘計算:
- 對於非計算屬性狀態,引入事務概念,保證同一批次中所有對狀態的同步更改,狀態對應的派生只計算一次。
- 對於計算屬性,計算屬性作為派生時,當其依賴變化,計算屬性不會立即重新計算,會等到計算屬性自身作為狀態所綁定的派生再次用到計算屬性值時才去重新計算。並且計算出相同值會阻止派生繼續處理。
Redux vs Mobx
如上面分析,Redux 是一個重思想輕代碼的狀態管理庫,Mobx 則是相反,框架幫我們做了更多的事,用起來簡單。
稍微總結下區別:
- Redux 要求開發者按它的模式(patterns)寫代碼,Mobx 則自由許多,用起來更簡單。相對地,基於 Redux 開發的系統健壯性要強一些,使用 Mobx 卻管理不好狀態的話,會使系統更難維護(咦,這為啥沒渲染?咦!這為啥渲染了這麼多次??(逃 )。
- Redux 結合函數式與 Immutable 的特性提供了時間旅行功能,更方便開發者調試與回溯狀態。 Mobx 則是有提供一個全局監聽的鈎子,監聽每一個狀態改變與副作用的觸發,我們直接打日誌調試,但是相對於 Redux 肯定是沒那麼方便的。
- Redux 推崇單 Store 管理狀態,降低狀態管理的複雜度。Mobx 則不給開發者設限,開發者可以以任一形式管理狀態,如果是多 Store,提供了 Computed Value 作為多 Store 數據的聯繫橋樑。
- Mobx 框架內部會幫我們實現最優渲染(副作用執行),Redux 則需要我們編寫各種 selector 或用 memo 手動去優化...
以上,歡迎有理有據地指正、補充。
參考:
- Hacker Way: Rethinking Web App Development at Facebook
- Becoming fully reactive: an in-depth explanation of MobX
- Immutable object
