


在 Convo AI & RTE2025 大會上,來自產業界和學術界的多位專家深入探討了智能語音技術、大模型時代的語音交互範式變革及其在實時互動場景中的挑戰與機遇。
科大訊飛寰語 AI 研究院副院長孟廷、聲網音頻體驗與方案負責人徐廣健、香港中文大學(深圳)副教授武執政、小米大模型 Core 團隊首席研究員張棟、西北工業大學教授謝磊、上海交通大學特聘教授錢彥旻、 聲繪未來(北京)科技有限公司的 CEO 孫思寧 等分享了他們在各自領域的研究成果和獨到見解。
科大訊飛 AI 工程院副院長劉坤和聲網音頻算法負責人吳渤分別主持了主題分享和圓桌討論環節。

孟廷:訊飛語音合成技術進展
科大訊飛副院長孟廷回顧了訊飛在語音合成領域的技術演進。從早期機械的語音合成,到 21 世紀統計參數方法的突破,再到神經網絡時代的自然度提升,訊飛始終走在行業前沿。2023 年,語音合成已步入大模型時代,核心在於語音的離散化處理,使得語音建模能夠借鑑文本大模型的量化方法。
訊飛構建了以語義 LLM 建模、細粒度聲學建模和波形建模為核心的語音合成大模型底座。該底座通過剝離發言人信息保留語義 token,並能根據歷史語音、語種、風格等屬性實現高度可控的語音合成。尤其在長時多輪對話建模上,能夠感知用户情緒與語氣,顯著提升了語音交互的體驗。目前,訊飛已支持超過 50 種語言,多語種合成自然度大幅提升。
除了傳統的語音合成,訊飛還拓展了文本到音頻生成技術,能夠根據文本提示創造聲音。如今,通過一句話即可實現聲音克隆,甚至僅憑對年齡、性別、音色等描述,就能生成個性化的聲音。這得益於語音合成大模型在屬性解耦上的能力,使得以極少數據即可實現聲音屬性的遷移和控制,例如讓特定音庫學習説方言或模仿特定風格。
「如何將當前高質量的超擬人效果,通過有效的壓縮或優化,下沉到低資源和低功耗設備上,是產業化落地的必經之路。」

孟廷
科大訊飛寰語 AI 研究院副院長
徐廣健:AI 時代 RTC 實時互動智能語音交互挑戰與機遇
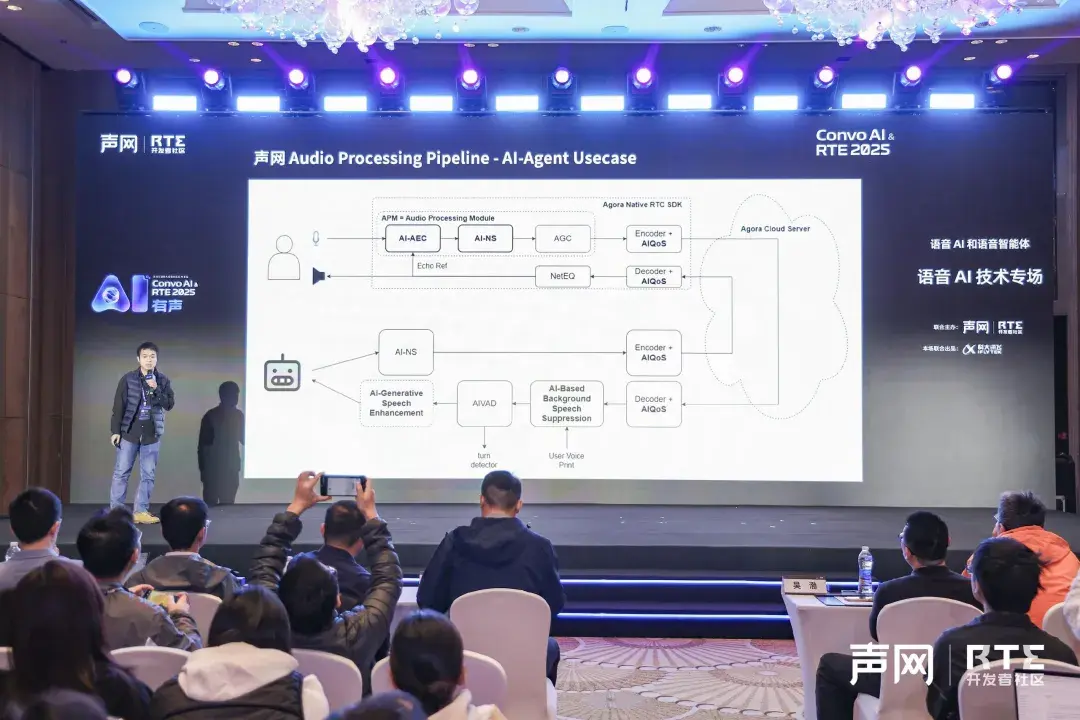
聲網音頻體驗與方案負責人徐廣健在分享中指出,隨着用户對體驗追求的不斷提升,傳統 RTC 拓撲在人機交互及複雜網絡條件下已顯不足。
聲網為此採取了端雲協同策略及多項 AI 技術:一方面,將複雜算法雲端化,並推出 AIQS(AI Quality of Service)弱網對抗方案,可將傳統 7-8 毫秒網絡延時對抗能力提升至 3-4 秒;另一方面,聲網自研並開源的 TEN VAD 模型也為輕量級端側應用提供了高效支持。
在具體語音增強技術上,聲網的核心亮點體現在多個維度,旨在解決傳統語音處理中的痛點:
- AI 回聲消除(AEC):基於深度學習,有效解決產品聲學結構差導致的非線性回聲,在雙講時人聲保留高達 80%以上,回聲殘留低於 0.1%,顯著優於競品及手機原生算法,有效防止人機交互中的語音打斷和誤識別。
- AI 降噪(AINS)與去混響一體化:該模型注重幅度譜與相位譜同步增強,能有效抑制會議室混響、嘯叫、地鐵背景噪音、麥克風摩擦音等複雜問題,顯著提升 ASR 在各種場景下的準確率,並在 GMOS 主客觀測試中表現優異。
- 背景聲消除與開源 TEN VAD 模型:在 AI 智能體陪伴機器人等場景中,能精準鎖定目標人聲,完全過濾背景人聲。此外,聲網開源的 TEN VAD 模型在人聲、音樂檢測方面也達到了業界領先水平。
TEN VAD:
https://github.com/TEN-framework/ten-vad
TEN Turn Detection:
https://github.com/ten-framework/ten-turn-detection
「相較於傳統語音增強的『減法』策略,我們提出生成式的方法,旨在通過『加法』有效還原這些已受損的語音信號。」

徐廣健
聲網音頻體驗與方案負責人
武執政:語音處理技術研究進展

香港中文大學(深圳)副教授武執政指出當前語音大模型面臨的核心成本問題:語音 Token 的幀率遠高於文本,使得語音模型的訓練和推理成本高企。
語音大模型的核心基建——離散表徵(Codec)是解決這一問題的關鍵。 他介紹了其團隊開發的 DualCodec、TaDiCodec 和 FlexiCodec。新開發的 FlexiCodec 成功地將語音 token 的幀率從傳統的 12.5Hz 降到了 6.25Hz,甚至在推理時可控制在 3.8Hz,大幅節省了計算資源,實現了根據説話者語速和發音邊界建模。TaDiCodec 能夠通過引入文本信息輔助建模,使得在 6.25Hz 的超低幀率下,各項音質指標依然能與 25Hz 甚至 50Hz 的高幀率模型持平。
在語音增強方面,他們將強化學習引入語音增強,通過構造人類偏好對(即正樣本需在多個客觀指標上完全勝出),對生成式模型進行後訓練或偏好對齊,使模型的輸出在人的感知上明顯優於未對齊的版本。
他指出,歌聲增強也是目前最具挑戰性的問題之一,對歌聲增強的深入優化,也會反哺語音增強技術的進步。為此,其團隊主動構建了包含馬路、遊戲廳、酒吧等多種複雜場景的歌聲數據集。
「如果把 token 的幀率從 12.5 赫茲降到 6.25 赫茲,保證它的音質是一樣的,這相當於我的成本降低了一半。」

武執政
香港中文大學(深圳)副教授
張棟:MiMo-Audio 語音領域的 GPT-3 時刻

小米大模型 Core 團隊首席研究員張棟認為,語音預訓練應通過壓縮互聯網上所有的語音數據,讓模型理解不同性格、不同背景的人在各種狀態下是如何説話、如何感知音頻世界的,從而獲得強大的泛化性。
基於此動機,小米團隊將預訓練數據量擴展至超過 1 億小時,以打造 MiMo-Audio-Base 模型。張棟將其稱為語音領域的 「GPT-3 時刻」。他和團隊觀察到一個關鍵的「涌現能力」:在訓練達到大約 1T Token 的臨界點後,模型突然獲得了之前不會的 Few-shot In-context Learning 能力。這意味着,模型能夠通過上下文中的少量(如 5 到 16 個)樣本,快速學習並執行新的語音任務,如音色轉換、語音到語音翻譯等。團隊進一步推出了 MiMo-Audio-Instruct 模型。該模型在 7B 量級中達到了 SOTA 的性能,並在音頻理解、語音對話等多個基準測試上表現出色。
為解決語音 Token 數量遠超文本導致的訓練效率低和模態學習困難,他們設計了 Patch Encoder 和 Patch Decoder 結構。這使得大模型最終見到的語音表示的幀率從 25Hz 降低到了 6.25Hz。此外,他們強調 Tokenizer 的首要原則必須是「信息無損」,保證語音中的信息儘可能完整地被保留下來。
「在訓練達到大約 1T Token 的臨界點後,模型突然獲得了之前不會的 Few-shot In-context Learning 能力。」

張棟
小米大模型 Core 團隊首席研究員
謝磊:生成式語音與音樂處理技術前沿

西北工業大學教授、音頻語音與語言處理實驗室負責人謝磊重點介紹了實驗室在共情對話方面的探索。
他認為,對話模型需要從單純的「工具屬性」向「夥伴屬性」跨越,具備感知用户情感並給出恰當、富有同理心響應的能力。鑑於共情數據稀缺,團隊使用相對輕量級的千問 2.5/3B 模型,結合自建的 Easy Turn 200K 共情對話數據集進行微調。通過引入 「Think」機制,模型能夠在理解用户情感的基礎上,給出更具人性的回覆,同時保持「智商」。
他還提到傳統測試集難以反映垂域問題,因此團隊與千問合作構建了已開源的 ContextASR Bench,用於評估 LLM-ASR 處理專有名詞和熱詞的性能。在語音增強方面,他們發佈了 SenSE 語義感知高保真通用語音增強模型,通過注入 Flow Matching 框架,有效解決了突發噪聲和高頻缺失等語音質量損傷。此外,音頻語音與語言處理實驗室聯合 Soul 等機構完成了多方言擬人播客生成,模型基於 130 萬小時多人對話數據訓練,音色克隆效果好,支持多種方言,並具備在文本中加入副語言 Tag(如咳嗽、笑聲)的特色功能。同時團隊還開源了 WenetSppeech 等數據集,並將重點發布上萬小時規模的方言數據集。
在音樂生成方面,謝磊團隊發佈的第二代 DiffRhythm 結合了 Block Flow Matching 和 CrossPair DPO 等技術,進一步提升了音樂性和結構完整性。他們還與上海音樂學院合作,發佈了 SongEval 數據集,用於從音樂美學角度對 AI 生成音樂進行人工評估和打分。
「當一個『咳嗽着但開心地説要去聽音樂會的小朋友』提問時,AI 應該給出穿搭建議,同時關心他是否感冒。」

謝磊
西北工業大學教授、音頻語音與語言處理實驗室負責人
錢彥旻:聽覺認知與計算聲學的前沿進展

上海交通大學特聘教授錢彥旻強調了語音和聲學學科在人工智能時代不可替代的重要性。他指出,儘管生成式 AI 取得了顯著進展,並能處理多種模態,但語音作為人類交互的關鍵通道,其核心地位並未動搖。
針對「大模型能夠一次性解決所有語音任務」的觀點,錢教授認為在實時性、低延時、端側部署等場景下,專有處理方案依然是剛需。
錢教授首先介紹了其團隊自主研發的情感口語對話大模型 LUNA。LUNA 的誕生旨在探索經濟高效的模型開發方式,具備多人對話無縫銜接、多語言及方言支持、角色扮演與情感豐富、知識問答等四大特色。值得關注的是,LUNA 在引入多模態後面臨的「智商下降」問題相對可控,並且在延遲指標上表現出顯著優勢,有效解決了人機對話體驗不佳的痛點。
隨後,錢教授將重點轉向語音翻譯專模型,再次強調大模型在實時性方面存在的侷限性,凸顯了專用模型在語音翻譯領域的不可替代價值。語音翻譯的目標是實現自然、及時、無障礙的語音交互,這要求在精度、表現力(如跨語言語音克隆和副語言保留)以及即時性方面達到高度平衡。為了實現類似同聲傳譯的等時性,團隊開發了基於 MOE 架構的 Read Policy 策略,使模型能夠自主判斷何時進行「聽」(Read)和何時進行「寫」(Write),從而在精度和實時性之間取得最佳平衡。
「我們的語音翻譯模型的目標,是讓世界上各個國家的人在自己的語言體系下但還是可以完成無障礙、自然、即時地交互。」

錢彥旻 上海交通大學特聘教授
圓桌討論:對話式 AI 時代,語音技術的落地挑戰和思考

主題是「對話式 AI 時代,語音技術的落地挑戰和思考」的圓桌討論由聲網音頻算法負責人的吳渤主持,參與討論的嘉賓有聲繪未來(北京)科技有限公司的 CEO 孫思寧、小米大模型 Core 團隊首席研究員張棟以及上海交通大學特聘教授、教育部長江學者錢彥旻。

主持人吳渤首先指出現場觀眾對對話式 AI 語音技術的熱情,並向三位經歷了語音技術三次革命的專家拋出了一個「靈魂拷問」:在大模型時代,專業語音技術(如 AI 降噪、混音消除)是會淪為大模型的數據處理工具,還是將繼續以專有能力與大模型共生?
三位嘉賓的觀點趨於一致,均認為未來將是「通專融合」和「長期並存」的格局。
孫思寧直言,傳統技術在一定程度上已成為大模型數據清洗 pipeline 的重要組成部分,但這是一個「好事情」,説明技術在升級,並繼續發揮着其核心價值。他強調,模型質量與數據清洗和積累息息相關。
張棟指出,大模型的能力增長是「鋸齒狀」的,有些任務(如數學)會隨規模變好,但有些底層語音任務可能並非規模越大就能解決。更關鍵的是,語音應用對實時性和可部署性要求極高,大模型越大速率越慢,因此專業技術依然重要。
錢彥旻教授預測,在未來五到十年內,領域必然是通專融合。大模型適合通用、大規模場景,而專有模型憑藉其在一個單點上的高效率和精確度(例如 20k 模型即可實現良好能力),在對延遲、功耗有嚴格要求的應用場景下,優勢無法被大模型方案取代。

圓桌隨後聚焦於兩種主流架構的未來:優勢在於靈活可控的三段式級聯,與優勢在於原生支持「邊聽邊想邊説」、但運算量大的端到端架構。
孫思寧認為兩種架構會長期並存。在對嵌入式、可控性有要求的場景下,級聯仍有優勢。但從學術前沿看,端到端代表未來趨勢,因為長期來看算力將越來越廉價,多模態融合是必然方向。
張棟認為應用場景決定架構選擇。 他強調要分場景看待。對可靠性要求高的場景(如客服、銷售),級聯架構優勢更大;而對於需要更高靈活度的陪伴、閒聊場景,端到端的上限則更高。
錢彥旻回憶了十年前端到端語音識別剛出現時被質疑的歷程,認為現在 LLM 的發展也處於類似階段。儘管目前級聯在靈活性上佔優,但從理論上看,端到端的性能上限更高,未來隨着技術成熟,端到端將會實現全面替代,但目前級聯仍將存在很長一段時間。

在實際落地中,三位專家指出了當前面臨的最大瓶頸:
孫思寧認為挑戰在於用户的直覺與技術相悖——用户認為越簡單的(如區分説話人情緒、背景人聲)AI 越不好做。此外,在非配合的 noisy 場景下,ASR 識別率很低,如何管理長期記憶模塊並從中提取有效信息,是 AI 個性化趨勢下的關鍵難題。
張棟認為最大的瓶頸是評估,尤其是涉及主觀的多模態生成和語音對話。當前的評估缺乏可感知性、實時性、可擴展性和魯棒性,急需開發出強大且能對齊人類偏好的自動化評估模型。
錢彥旻教授關注大模型「大力出奇跡」的低效率問題。他提出,人類大腦在複雜場景下處理信息極為高效,不需要消耗如此多的數據和電量。未來的研究應着眼於新的範式或框架,探索類腦啓發式的理解和生成,以提升 AI 的效率。

在圓桌的最後,各位嘉賓分享了在人機交互和 AI 浪潮下的觀察與展望:
張棟在迴應推理能力時,提出解決語音交互中信息量和速度衝突的方案:利用語音輸出速度固定,通過讓模型輸出思考通道或讓另一個模型接力思考來解決。他更看好利用 「Think」機制來提升模型的情商(如揣測用户意圖)和傳統 TTS 任務(如用思考推斷語氣)。
孫思寧則從創業角度指出,大模型降低了「做出東西」的門檻,但提高了產品成功的門檻。小公司的機會在於垂直領域,因為大公司有其基因限制,難以深入垂直行業。現在的優勢在於 AI 認知土壤已成熟,創業者需要做的就是找到好的切入點,從用户需求出發,避免過度設計。
錢彥旻補充道,人機交互的本質是交互對象從人變成了機器,但由於機器大腦不夠魯棒,傳統語音增強反而可能導致機器識別性能下降。他預言,未來還會出現機機交互場景,例如具身機器人之間的社交,每個場景都會帶來新的挑戰。


閲讀更多 Voice Agent 學習筆記:瞭解最懂 AI 語音的頭腦都在思考什麼
