


開發者朋友們大家好:
這裏是 「RTE 開發者日報」,每天和大家一起看新聞、聊八卦。我們的社區編輯團隊會整理分享 RTE(Real-Time Engagement) 領域內「有話題的技術」、「有亮點的產品」、「有思考的文章」、「有態度的觀點」、「有看點的活動」,但內容僅代表編輯的個人觀點,歡迎大家留言、跟帖、討論。
本期編輯:@Jerry fong,@鮑勃
01有話題的技術
1、OpenAI 新模型疑似 GPT 5.1,年底或將正式發佈
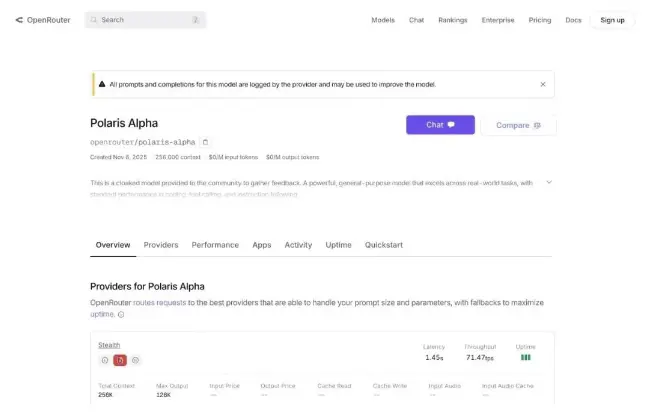
OpenRouter 平台在 11 月 7 日深夜上線了一款全新隱名模型「Polaris Alpha」,被業內普遍認為是 GPT 5.1 的測試版本。
該模型目前已開放 API 調用,最大 context 容量為 256K,單次最大輸出可達 128K,知識庫截止時間為 2024 年 10 月,但暫不支持推理模式。
Polaris 在文本生成、文案創意和編程任務中表現穩定,文風具有典型的「GPT 系」特徵。
部分用户通過測試發現,該模型在處理長文本輸入時具備自我糾錯能力,能夠在二次運行中修正錯誤信息。其在編程場景下可快速生成小遊戲代碼,並支持網頁設計,顯示出一定的美學特色。
值得注意的是,OpenAI CEO Sam Altman 曾在此前明確表示,ChatGPT 將在年底推出 NSFW 模式(成人模式)。在 Polaris 的測試版本中,已有相關功能的跡象出現,這進一步加深了外界對其與 GPT 5.1 關聯的猜測。
據傳,GPT 5.1 預計將在 11 月中正式發佈。
💻 試用鏈接:
https://openrouter.ai/chat
(@APPSO)
2、謝賽寧 x 李飛飛 x LeCun 聯手發佈「空間超感知」AI 框架
據新智元報道,近日,謝賽寧、李飛飛與 Yann LeCun 聯合發佈論文《Cambrian-S:邁向視頻中的空間超感知》,提出全新 AI 範式,旨在突破現有大語言模型在感官建模上的侷限。
三位學者指出,當前基於 LLM 的多模態模型雖具備強大文本與圖像處理能力,但在空間認知與預測性世界建模方面仍存在顯著缺陷。
他們強調「超感知」是邁向超級智能的關鍵環節,AI 必須具備對視頻流進行三維空間理解與長期記憶的能力,才能在現實場景中實現可靠應用。
團隊在 Cambrian-S 框架下構建了 VSI-590K 數據集,涵蓋 59 萬個帶有 3D 標註的訓練樣本,並訓練了從 5 億到 70 億參數規模的模型。實驗結果顯示,其空間推理性能較基座模型提升最高達 30%,即使小規模模型也表現突出。
此外,研究團隊提出「預測性感知」原型,通過潛在幀預測模塊引入「驚異度」機制,用於優化記憶管理與事件切分。該方法在 VSI-Super 基準測試中已超越 Gemini 模型,顯示出在長視頻理解與空間智能方面的潛力。
研究者強調,單純依賴規模化與數據擴展無法解決感知問題,開放科學與跨學科研究才是推動 AGI 的必由之路。此次合作不僅在學術界引發廣泛關注,也被視為對現有 AI 技術路線的深度挑戰。
(@APPSO)
3、Meta AI 推出「全語種」語音識別系統,一口氣支持 1600+語言,打破全球語言壁壘!

Meta 的基礎人工智能研究(FAIR)團隊近日宣佈推出Omnilingual ASR,這是一款創新的自動語音識別系統,能夠轉錄超過 1600 種口語語言。此舉旨在彌合現有 AI 工具在語言覆蓋上的巨大差距,正式邁向「通用轉錄系統」的目標。
長期以來,大多數語音識別系統僅專注於少數擁有大量轉錄音頻資源的語言,導致全球 7000 多種語言中,有數千種幾乎得不到 AI 支持。Omnilingual ASR 的發佈將改變這一現狀。Meta 指出,在其支持的 1600 種語言中,有 500 種語言此前從未被任何人工智能系統覆蓋。
Omnilingual ASR 的性能令人矚目:
- 在測試的 1600 種語言中,系統對 78%的語言實現了低於 10 個字符的錯誤率。
- 對於擁有至少 10 小時訓練音頻的「資源豐富」語言,這一準確率標準達到了 95%的覆蓋。
- 即使是音頻時長不足 10 小時的「低資源」語言,也有 36%的語言錯誤率低於 10 個字符的閾值,為這些羣體帶來了實用的語音識別功能。
情境學習:將覆蓋範圍擴展至 5400 種語言。Omnilingual ASR 的一個關鍵創新是其「自帶語言」選項,該功能借鑑大型語言模型的情境學習技術。用户只需提供少量的音頻和文本配對樣本,系統即可直接從這些樣本中學習新語言,無需重新訓練或大量的計算資源。Meta 表示,理論上,這一方法有望將 Omnilingual ASR 的覆蓋範圍擴展到超過 5400 種語言,遠遠超越了當前的行業標準。
模型開源: Omnilingual ASR 以 Apache2.0 許可證發佈,允許研究人員和開發者自由使用、修改和構建模型,包括用於商業用途。模型基於 PyTorch 的 fairseq2 框架構建,提供了從適用於低功耗設備的 3 億參數版本到追求「頂級準確度」的 70 億參數版本。
Github:
https://github.com/facebookresearch/omnilingual-asr
(@麋鹿研究所)
02有亮點的產品
1、AI 教師「會畫圖」了:ChatTutor 上線,邊講邊畫、實時推演,教學效果直逼真人名師
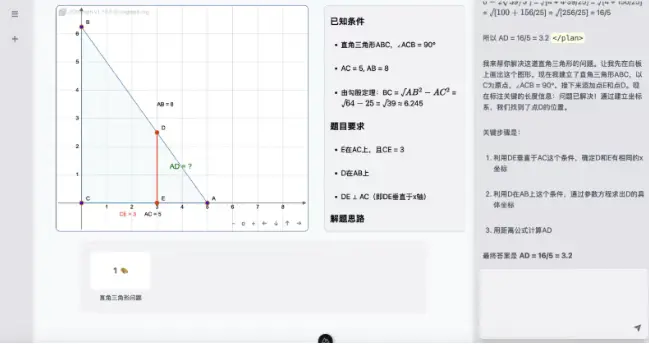
AI 教育迎來質的飛躍。今日,全新一代可視化交互式 AI 教師系統——ChatTutor 正式發佈,徹底打破傳統 AI 問答「純文字輸出」的侷限,通過右側實時同步畫板,實現「邊講解、邊繪製、邊推演」的類人教學體驗。當用户提問「二次函數如何平移」,AI 不僅口述原理,更在畫板上動態繪製曲線、標註頂點、演示變換過程——知識不再抽象,而是看得見、摸得着的視覺邏輯。
五大教學引擎,覆蓋核心學科場景
ChatTutor 依託多模態生成技術,構建起覆蓋多領域的智能教學矩陣:
數學可視化:函數圖像、幾何構造、統計圖表一鍵生成,支持動態推導與參數調節;
物理實驗模擬:即時繪製力學受力圖、運動軌跡、波動傳播等,將抽象定律具象化;
邏輯電路交互:可拖拽門電路元件,實時驗證時序邏輯與狀態轉換;
編程逐行教學:支持 Python、JavaScript 等語言,邊寫代碼邊解釋執行流程與錯誤排查;
思維導圖生成:將複雜概念自動結構化,一鍵導出用於複習或團隊協作。
評測實測:教學邏輯媲美一線教師
AIbase 實測顯示,面對「講解牛頓第二定律在斜面運動中的應用」這類複合問題,ChatTutor 先繪製斜面、標註重力分力與摩擦力,再逐步推導加速度公式,並用顏色區分矢量方向與變量關係。整個過程邏輯清晰、節奏得當,遠超傳統「答案搬運」式 AI 助手。
從「會答題」到「會教學」:AI 教育的分水嶺
過去,AI 教育工具多聚焦於題庫匹配與答案生成;而 ChatTutor 首次將教學法(Pedagogy)融入 AI 內核——通過視覺引導、分步拆解與互動反饋,模擬人類教師的啓發式教學。這不僅提升理解效率,更培養用户的結構化思維能力。
AIbase 認為,ChatTutor 的出現,標誌着 AI 教育正式從「信息檢索工具」升級為「認知協作夥伴」。當 AI 不僅能告訴你「是什麼」,還能清晰展示「為什麼」和「怎麼做」,知識獲取的門檻將前所未有地降低。未來,無論是學生自學、教師備課,還是企業培訓,這樣的「可視化 AI 導師」或將成為標配。教育的智能化,正從這裏真正開始。
項目地址:
https://github.com/sheepbox8646/ChatTutor
(@AIBase)
2、Google TV 正式接入 Gemini,用情境化問答革新家庭娛樂和學習方式

谷歌週一宣佈,將開始在其 Google TV 流媒體播放器上推出 Gemini 語音助手,正式取代原有的 Google Assistant,此舉是公司將 Gemini 整合進所有平台戰略的重要一步。
此次升級旨在通過更先進的 AI 能力,使用户能夠以更自然、更像對話的方式訪問內容和各項功能。例如,用户現在可以提出像「我喜歡劇情片,但我妻子喜歡喜劇片。有什麼電影我們可以一起看嗎?」等複雜的跨情境查詢,或者快速瞭解追看劇集的劇情,如「《古戰場傳奇》上一季結尾發生了什麼?」.
Gemini 的功能不僅限於娛樂,它還將手機上 AI 助手的通用能力帶到了電視上,用户可以提問「請給我的三年級孩子解釋一下火山為什麼會噴發」等學習性問題,甚至通過 YouTube 視頻指導 DIY 項目或食譜。用户只需按下遙控器上的麥克風按鈕即可喚醒助手,此次更新將在未來幾周內向 18 歲及以上的用户推出。
這一部署是意料之中的,此前谷歌已在今年的 CES 展會上宣佈 Gemini 將登陸 Google TV,並已確認其將支持包括 Walmart Onn4K Pro 流媒體設備以及未來的 2025 款海信和 TCL 電視機型。
(@AIBase)
03有態度的觀點
1、諮詢巨頭 CEO:不會用 AI 的員工將被清退
據《華爾街日報》報道,諮詢巨頭埃森哲(Accenture)CEO 朱莉·斯威特近日在面向投資者的講話中表示,公司正在加速推動人工智能應用,並將「清退」無法掌握 AI 技能的員工。
她透露,埃森哲已為約 77.9 萬名員工中的 70% 提供了生成式 AI 基礎培訓,但對於那些「再培訓已不可行」的員工,公司將要求其離開崗位。
這一舉措凸顯了企業在數字化轉型中的新趨勢:員工不再僅擔心被 AI 取代,更面臨被懂 AI 的同事取代的壓力。
斯威特強調,AI 技能已成為核心競爭力,公司將繼續在內部推動培訓和應用,以確保整體生產力和市場競爭力。
(@APPSO)
2、摩根大通 CEO:隨着 AI 發展,未來發達國家每週可能只需上班三天半

據《財富》報道,摩根大通 CEO 傑米 · 戴蒙(Jamie Dimon)日前在美國商業論壇上表示,隨着 AI 的快速發展,未來 20 至 40 年內,發達國家的工作周可能縮短至「三天半」。
他強調,AI 將影響「每一項應用、每一個崗位、每一位客户」,並顯著提升生產效率和生活質量。
戴蒙指出,摩根大通已成為「活躍的 AI 實驗室」,目前約有 2,000 名員工專職開發 AI 系統,約 15 萬名員工每週使用大語言模型處理內部文檔,銀行已部署數百個應用場景,包括欺詐檢測、法律審查、對賬與營銷優化等。此外,超過 20 萬名員工正在使用 AI 工具,約 30 萬人接受培訓。
他同時警告,AI 的普及將導致部分崗位消失,企業與政府必須提前規劃再培訓、收入援助、崗位轉移,甚至在某些情況下的提前退休,以避免社會反彈。在經濟層面,戴蒙強調 AI 的建設不同於互聯網,屬於資本與能源密集型產業,部分項目可能因電力不足而受限。
他提醒投資者應逐案評估數據中心與 AI 基礎設施,而非盲目跟風。他直言「部分 AI 項目處於泡沫」,但整體來看,技術最終將帶來回報。
值得注意的是,京東創始人劉強東日前在烏鎮峯會上也提出類似觀點。他預測約 5 年後,中國 90% 家庭將使用智能鎖,機器人可在授權後自主入户完成快遞配送,屆時員工每週可能僅需工作「一天甚至一小時」。
(@APPSO)


閲讀更多 Voice Agent 學習筆記:瞭解最懂 AI 語音的頭腦都在思考什麼
寫在最後:
我們歡迎更多的小夥伴參與 「RTE 開發者日報」 內容的共創,感興趣的朋友請通過開發者社區或公眾號留言聯繫,記得報暗號「共創」。
對於任何反饋(包括但不限於內容上、形式上)我們不勝感激、並有小驚喜回饋,例如你希望從日報中看到哪些內容;自己推薦的信源、項目、話題、活動等;或者列舉幾個你喜歡看、平時常看的內容渠道;內容排版或呈現形式上有哪些可以改進的地方等。

素材來源官方媒體/網絡新聞